Esta publicación está coescrita con Mahima Agarwal, ingeniero de aprendizaje automático, y Deepak Mettem, gerente sénior de ingeniería, en VMware Carbon Black
Negro carbón VMware es una solución de seguridad de renombre que ofrece protección contra todo el espectro de ciberataques modernos. Con terabytes de datos generados por el producto, el equipo de análisis de seguridad se enfoca en crear soluciones de aprendizaje automático (ML) para detectar ataques críticos y detectar amenazas emergentes del ruido.
Es fundamental que el equipo de VMware Carbon Black diseñe y cree una canalización de MLOps integral personalizada que organice y automatice los flujos de trabajo en el ciclo de vida de ML y permita la capacitación, las evaluaciones y las implementaciones de modelos.
Hay dos propósitos principales para construir esta tubería: apoyar a los científicos de datos para el desarrollo de modelos de última etapa y las predicciones de modelos de superficie en el producto al servir modelos en gran volumen y en tráfico de producción en tiempo real. Por lo tanto, VMware Carbon Black y AWS optaron por crear una canalización de MLOps personalizada utilizando Amazon SageMaker por su facilidad de uso, versatilidad e infraestructura completamente administrada. Orquestamos nuestras canalizaciones de capacitación e implementación de ML utilizando Flujos de trabajo administrados por Amazon para Apache Airflow (Amazon MWAA), lo que nos permite centrarnos más en la creación programática de flujos de trabajo y canalizaciones sin tener que preocuparnos por el escalado automático o el mantenimiento de la infraestructura.
Con esta canalización, lo que una vez fue la investigación de ML impulsada por portátiles Jupyter ahora es un proceso automatizado que implementa modelos en producción con poca intervención manual de los científicos de datos. Anteriormente, el proceso de capacitación, evaluación e implementación de un modelo podía llevar más de un día; con esta implementación, todo está a solo un disparo de distancia y ha reducido el tiempo total a unos pocos minutos.
En esta publicación, los arquitectos de VMware Carbon Black y AWS analizan cómo creamos y administramos flujos de trabajo de aprendizaje automático personalizados utilizando Gitlab, Amazon MWAA y SageMaker. Discutimos lo que hemos logrado hasta ahora, mejoras adicionales a la tubería y lecciones aprendidas a lo largo del camino.
Resumen de la solución
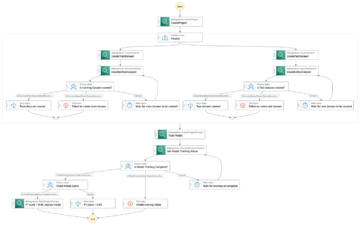
El siguiente diagrama ilustra la arquitectura de la plataforma ML.

Diseño de soluciones de alto nivel
Esta plataforma de ML fue concebida y diseñada para ser consumida por diferentes modelos en varios repositorios de código. Nuestro equipo utiliza GitLab como herramienta de gestión de código fuente para mantener todos los repositorios de código. Cualquier cambio en el código fuente del repositorio de modelos se integra continuamente mediante el CI de Gitlab, que invoca los flujos de trabajo posteriores en la canalización (entrenamiento, evaluación e implementación del modelo).
El siguiente diagrama de arquitectura ilustra el flujo de trabajo de extremo a extremo y los componentes involucrados en nuestra canalización de MLOps.

Flujo de trabajo de extremo a extremo
Las canalizaciones de capacitación, evaluación e implementación del modelo ML se organizan mediante Amazon MWAA, denominado Gráfico acíclico dirigido (TROZO DE CUERO). Un DAG es una colección de tareas juntas, organizadas con dependencias y relaciones para decir cómo deben ejecutarse.
A un alto nivel, la arquitectura de la solución incluye tres componentes principales:
- Repositorio de código de canalización de ML
- Pipeline de evaluación y entrenamiento del modelo ML
- Canalización de implementación del modelo ML
Analicemos cómo se administran estos diferentes componentes y cómo interactúan entre sí.
Repositorio de código de canalización de ML
Después de que el repositorio modelo integre el repositorio MLOps como su canalización descendente, y un científico de datos confirme el código en su repositorio modelo, un ejecutor de GitLab realiza la validación y las pruebas de código estándar definidas en ese repositorio y activa la canalización MLOps en función de los cambios de código. Usamos la canalización de proyectos múltiples de Gitlab para habilitar este activador en diferentes repositorios.
La canalización de MLOps GitLab ejecuta un determinado conjunto de etapas. Realiza la validación básica del código mediante pylint, empaqueta el código de inferencia y entrenamiento del modelo dentro de la imagen de Docker y publica la imagen del contenedor en Registro de contenedores elásticos de Amazon (Amazon ECR). Amazon ECR es un registro de contenedores totalmente administrado que ofrece alojamiento de alto rendimiento, por lo que puede implementar artefactos e imágenes de aplicaciones de manera confiable en cualquier lugar.
Pipeline de evaluación y entrenamiento del modelo ML
Una vez que se publica la imagen, se activa el entrenamiento y la evaluación. Flujo de aire Apache tubería a través de la AWS Lambda función. Lambda es un servicio informático basado en eventos y sin servidor que le permite ejecutar código para prácticamente cualquier tipo de aplicación o servicio de back-end sin aprovisionar ni administrar servidores.
Una vez que la canalización se activa correctamente, ejecuta el DAG de capacitación y evaluación, que a su vez inicia la capacitación del modelo en SageMaker. Al final de esta canalización de capacitación, el grupo de usuarios identificado recibe una notificación con los resultados de la evaluación del modelo y la capacitación por correo electrónico a través de Servicio de notificación simple de Amazon (Amazon SNS) y Slack. Amazon SNS es un servicio de publicación/suscripción completamente administrado para mensajería A2A y A2P.
Después de un análisis minucioso de los resultados de la evaluación, el científico de datos o el ingeniero de ML pueden implementar el nuevo modelo si el rendimiento del modelo recién entrenado es mejor en comparación con la versión anterior. El rendimiento de los modelos se evalúa en función de las métricas específicas del modelo (como puntuación F1, MSE o matriz de confusión).
Canalización de implementación del modelo ML
Para comenzar la implementación, el usuario inicia el trabajo de GitLab que activa el DAG de implementación a través de la misma función de Lambda. Una vez que la canalización se ejecuta correctamente, crea o actualiza el extremo de SageMaker con el nuevo modelo. Esto también envía una notificación con los detalles del punto final por correo electrónico utilizando Amazon SNS y Slack.
En caso de falla en cualquiera de las tuberías, los usuarios son notificados a través de los mismos canales de comunicación.
SageMaker ofrece inferencia en tiempo real que es ideal para cargas de trabajo de inferencia con baja latencia y requisitos de alto rendimiento. Estos puntos finales están totalmente administrados, tienen equilibrio de carga y se escalan automáticamente, y se pueden implementar en varias zonas de disponibilidad para lograr una alta disponibilidad. Nuestra canalización crea un punto final de este tipo para un modelo después de que se ejecuta correctamente.
En las siguientes secciones, ampliamos los diferentes componentes y profundizamos en los detalles.
GitLab: modelos de paquetes y canalizaciones de activación
Usamos GitLab como nuestro repositorio de código y para la canalización para empaquetar el código del modelo y activar los DAG de flujo de aire posteriores.
Canalización de varios proyectos
La característica de canalización de varios proyectos de GitLab se usa cuando la canalización principal (ascendente) es un repositorio modelo y la canalización secundaria (descendente) es el repositorio de MLOps. Cada repositorio mantiene un .gitlab-ci.yml, y el siguiente bloque de código habilitado en la canalización ascendente activa la canalización MLOps descendente.
La canalización ascendente envía el código del modelo a la canalización descendente donde se activan los trabajos de CI de empaquetado y publicación. El canal de MLOps mantiene y administra el código para contener el código del modelo y publicarlo en Amazon ECR. Envía las variables como ACCESS_TOKEN (se puede crear bajo Ajustes, Access), JOB_ID (para acceder a los artefactos ascendentes) y $CI_PROJECT_ID (el ID del proyecto del repositorio del modelo), para que la canalización de MLOps pueda acceder a los archivos de código del modelo. Con el artefactos de trabajo función de Gitlab, el repositorio descendente accede a los artefactos remotos mediante el siguiente comando:
El repositorio de modelos puede consumir canalizaciones descendentes para varios modelos del mismo repositorio al extender la etapa que lo activa mediante el Se extiende palabra clave de GitLab, que le permite reutilizar la misma configuración en diferentes etapas.
Después de publicar la imagen del modelo en Amazon ECR, la canalización de MLOps activa la canalización de capacitación de Amazon MWAA mediante Lambda. Después de la aprobación del usuario, también activa la canalización Amazon MWAA de implementación del modelo utilizando la misma función de Lambda.
Control de versiones semánticas y paso de versiones aguas abajo
Desarrollamos código personalizado para versionar imágenes ECR y modelos SageMaker. La canalización de MLOps administra la lógica de versiones semánticas para imágenes y modelos como parte de la etapa en la que el código del modelo se almacena en contenedores y pasa las versiones a etapas posteriores como artefactos.
Reentrenamiento
Debido a que el reentrenamiento es un aspecto crucial de un ciclo de vida de ML, hemos implementado capacidades de reentrenamiento como parte de nuestra canalización. Usamos la API de modelos de lista de SageMaker para identificar si se está reentrenando según el número de versión y la marca de tiempo del reentrenamiento del modelo.
Gestionamos la programación diaria de la tubería de reentrenamiento usando Tuberías de programación de GitLab.
Terraform: configuración de la infraestructura
Además de un clúster de Amazon MWAA, repositorios de ECR, funciones de Lambda y temas de SNS, esta solución también utiliza Gestión de identidades y accesos de AWS (IAM) roles, usuarios y políticas; Servicio de almacenamiento simple de Amazon (Amazon S3) baldes y un Reloj en la nube de Amazon reenviador de registros.
Para agilizar la configuración y el mantenimiento de la infraestructura de los servicios involucrados en toda nuestra cartera, utilizamos Terraform para implementar la infraestructura como código. Cada vez que se requieren actualizaciones de infraestructura, los cambios en el código desencadenan una canalización de GitLab CI que configuramos, que valida e implementa los cambios en varios entornos (por ejemplo, agregar un permiso a una política de IAM en cuentas de desarrollo, etapa y producción).
Amazon ECR, Amazon S3 y Lambda: facilitación de canalización
Utilizamos los siguientes servicios clave para facilitar nuestra canalización:
- ECR de Amazon – Para mantener y permitir recuperaciones convenientes de las imágenes del contenedor del modelo, las etiquetamos con versiones semánticas y las cargamos en repositorios ECR configurados por
${project_name}/${model_name}a través de Terraform. Esto habilita una buena capa de aislamiento entre diferentes modelos y nos permite usar algoritmos personalizados y formatear solicitudes y respuestas de inferencia para incluir la información de manifiesto del modelo deseado (nombre del modelo, versión, ruta de datos de entrenamiento, etc.). - Amazon S3 – Usamos depósitos S3 para conservar los datos de entrenamiento del modelo, los artefactos del modelo entrenado por modelo, los DAG de Airflow y otra información adicional requerida por las canalizaciones.
- lambda – Debido a que nuestro clúster de Airflow se implementa en una VPC separada por consideraciones de seguridad, no se puede acceder a los DAG directamente. Por lo tanto, usamos una función Lambda, también mantenida con Terraform, para activar cualquier DAG especificado por el nombre de DAG. Con la configuración adecuada de IAM, el trabajo de CI de GitLab activa la función Lambda, que pasa a través de las configuraciones hasta los DAG de implementación o capacitación solicitados.
Amazon MWAA: canalizaciones de capacitación e implementación
Como se mencionó anteriormente, usamos Amazon MWAA para orquestar las canalizaciones de capacitación e implementación. Usamos los operadores de SageMaker disponibles en el Paquete de proveedor de Amazon para Airflow para integrarse con SageMaker (para evitar plantillas jinja).
Usamos los siguientes operadores en esta canalización de capacitación (que se muestra en el siguiente diagrama de flujo de trabajo):

Línea de capacitación de MWAA
Usamos los siguientes operadores en la canalización de implementación (que se muestra en el siguiente diagrama de flujo de trabajo):

Canalización de implementación de modelos
Usamos Slack y Amazon SNS para publicar los mensajes de error/éxito y los resultados de la evaluación en ambas canalizaciones. Slack ofrece una amplia gama de opciones para personalizar los mensajes, incluidas las siguientes:
- SnsPublishOperador - Usamos SnsPublishOperador para enviar notificaciones de éxito/fallo a los correos electrónicos de los usuarios
- API de holgura – Creamos el URL de webhook entrante para obtener las notificaciones de canalización en el canal deseado
CloudWatch y VMware Wavefront: monitoreo y registro
Usamos un panel de CloudWatch para configurar el registro y la supervisión de puntos finales. Ayuda a visualizar y realizar un seguimiento de varias métricas de rendimiento operativas y de modelos específicas para cada proyecto. Además de las políticas de escalado automático configuradas para rastrear algunos de ellos, monitoreamos continuamente los cambios en el uso de la CPU y la memoria, las solicitudes por segundo, las latencias de respuesta y las métricas del modelo.
CloudWatch incluso está integrado con un tablero VMware Tanzu Wavefront para que pueda visualizar las métricas para los puntos finales del modelo, así como otros servicios a nivel de proyecto.
Beneficios comerciales y lo que sigue
Las canalizaciones de ML son muy importantes para los servicios y características de ML. En esta publicación, discutimos un caso de uso de ML de extremo a extremo utilizando capacidades de AWS. Creamos una canalización personalizada con SageMaker y Amazon MWAA, que podemos reutilizar en proyectos y modelos, y automatizamos el ciclo de vida de ML, lo que redujo el tiempo desde la capacitación del modelo hasta la implementación de producción a tan solo 10 minutos.
Con el cambio de la carga del ciclo de vida de ML a SageMaker, proporcionó una infraestructura optimizada y escalable para el entrenamiento y la implementación del modelo. El servicio de modelos con SageMaker nos ayudó a hacer predicciones en tiempo real con latencias de milisegundos y capacidades de monitoreo. Usamos Terraform por la facilidad de configuración y para administrar la infraestructura.
Los siguientes pasos para esta canalización serían mejorar la canalización de entrenamiento de modelos con capacidades de reentrenamiento, ya sea que esté programado o basado en la detección de desviación del modelo, admitir la implementación oculta o las pruebas A/B para una implementación de modelos más rápida y calificada, y el seguimiento del linaje de ML. También planeamos evaluar Canalizaciones de Amazon SageMaker porque la integración de GitLab ahora es compatible.
Lecciones aprendidas
Como parte de la construcción de esta solución, aprendimos que debe generalizar temprano, pero no generalizar en exceso. Cuando terminamos el diseño de la arquitectura por primera vez, intentamos crear y aplicar plantillas de código para el código del modelo como práctica recomendada. Sin embargo, fue tan temprano en el proceso de desarrollo que las plantillas eran demasiado generales o demasiado detalladas para ser reutilizables para modelos futuros.
Después de entregar el primer modelo a través de la canalización, las plantillas surgieron de forma natural en función de los conocimientos de nuestro trabajo anterior. Una tubería no puede hacer todo desde el primer día.
La experimentación y la producción de modelos a menudo tienen requisitos muy diferentes (o, a veces, incluso contradictorios). Es crucial equilibrar estos requisitos desde el principio como equipo y priorizar en consecuencia.
Además, es posible que no necesite todas las funciones de un servicio. Usar características esenciales de un servicio y tener un diseño modularizado son claves para un desarrollo más eficiente y una canalización flexible.
Conclusión
En esta publicación, mostramos cómo creamos una solución MLOps con SageMaker y Amazon MWAA que automatizó el proceso de implementación de modelos en producción, con poca intervención manual de los científicos de datos. Le recomendamos que evalúe varios servicios de AWS como SageMaker, Amazon MWAA, Amazon S3 y Amazon ECR para crear una solución MLOps completa.
*Apache, Apache Airflow y Airflow son marcas comerciales registradas o marcas comerciales de Apache Software Foundation en los Estados Unidos y / o en otros países.
Acerca de los autores
 Deepak Mettem es gerente sénior de ingeniería en VMware, unidad de negro de carbón. Él y su equipo trabajan en la creación de aplicaciones y servicios basados en transmisión que sean altamente disponibles, escalables y resistentes para brindarles a los clientes soluciones basadas en aprendizaje automático en tiempo real. Él y su equipo también son responsables de crear las herramientas necesarias para que los científicos de datos construyan, entrenen, implementen y validen sus modelos ML en producción.
Deepak Mettem es gerente sénior de ingeniería en VMware, unidad de negro de carbón. Él y su equipo trabajan en la creación de aplicaciones y servicios basados en transmisión que sean altamente disponibles, escalables y resistentes para brindarles a los clientes soluciones basadas en aprendizaje automático en tiempo real. Él y su equipo también son responsables de crear las herramientas necesarias para que los científicos de datos construyan, entrenen, implementen y validen sus modelos ML en producción.
 mahima agarwal es ingeniero de aprendizaje automático en VMware, unidad de negro de carbón.
mahima agarwal es ingeniero de aprendizaje automático en VMware, unidad de negro de carbón.
Trabaja en el diseño, la creación y el desarrollo de los componentes principales y la arquitectura de la plataforma de aprendizaje automático para VMware CB SBU.
 Vamshi Krishna Enabothala es Arquitecto Sr. Especialista en IA Aplicada en AWS. Trabaja con clientes de diferentes sectores para acelerar iniciativas de datos, análisis y aprendizaje automático de alto impacto. Le apasionan los sistemas de recomendación, la PNL y las áreas de visión por computadora en IA y ML. Fuera del trabajo, Vamshi es un entusiasta de RC, construye equipos de RC (aviones, automóviles y drones) y también disfruta de la jardinería.
Vamshi Krishna Enabothala es Arquitecto Sr. Especialista en IA Aplicada en AWS. Trabaja con clientes de diferentes sectores para acelerar iniciativas de datos, análisis y aprendizaje automático de alto impacto. Le apasionan los sistemas de recomendación, la PNL y las áreas de visión por computadora en IA y ML. Fuera del trabajo, Vamshi es un entusiasta de RC, construye equipos de RC (aviones, automóviles y drones) y también disfruta de la jardinería.
 Sahil Thapar es Arquitecto de Soluciones Empresariales. Trabaja con los clientes para ayudarlos a crear aplicaciones altamente disponibles, escalables y resistentes en la nube de AWS. Actualmente se centra en contenedores y soluciones de aprendizaje automático.
Sahil Thapar es Arquitecto de Soluciones Empresariales. Trabaja con los clientes para ayudarlos a crear aplicaciones altamente disponibles, escalables y resistentes en la nube de AWS. Actualmente se centra en contenedores y soluciones de aprendizaje automático.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/how-vmware-built-an-mlops-pipeline-from-scratch-using-gitlab-amazon-mwaa-and-amazon-sagemaker/
- :es
- $ UP
- 1
- 10
- 100
- 7
- 8
- a
- Sobre
- acelerar
- de la máquina
- visitada
- en consecuencia
- Cuentas
- alcanzado
- a través de
- acíclico
- adición
- Adicionales
- Información adicional
- Después
- en contra
- AI
- algoritmos
- Todos
- permite
- Amazon
- Amazon SageMaker
- análisis
- Analytics
- y
- dondequiera
- APACHE
- abejas
- Aplicación
- aplicaciones
- aplicada
- IA aplicada
- aprobación
- arquitectura
- somos
- áreas
- AS
- aspecto
- At
- ataques
- autoría
- auto
- Confirmación de Viaje
- automatiza
- disponibilidad
- Hoy Disponibles
- evitar
- AWS
- Backend
- Balance
- basado
- básica
- BE
- porque
- Comienzo
- beneficios
- MEJOR
- mejores
- entre
- Negro
- Bloquear
- Rama
- llevar
- build
- Construir la
- construido
- carga
- by
- PUEDEN
- no puede
- capacidades
- carbono
- carros
- case
- CB
- a ciertos
- Cambios
- canales
- sus hijos
- eligió
- Soluciones
- Médico
- código
- --
- Comunicación
- en comparación con
- completar
- componentes
- Calcular
- computadora
- Visión por computador
- conduce
- Configuración
- externa (Biomet XNUMXi)
- Contradictorio
- confusión
- consideraciones
- consumir
- consumido
- Envase
- Contenedores
- continuamente
- Conveniente
- Core
- podría
- países
- CPU
- Para crear
- creado
- crea
- Creamos
- crítico
- crucial
- En la actualidad
- personalizado
- Clientes
- personalizan
- Ataques ciberneticos
- DÍA
- todos los días
- página de información de sus operaciones
- datos
- científico de datos
- día
- se define
- entregar
- desplegar
- desplegado
- Desplegando
- despliegue
- Despliegues
- despliega
- Diseño
- diseñado
- diseño
- detallado
- detalles
- Detección
- Dev
- desarrollado
- el desarrollo
- Desarrollo
- una experiencia diferente
- directamente
- discutir
- discutido
- Docker
- No
- DE INSCRIPCIÓN
- Drones
- cada una
- Más temprano
- Temprano en la
- facilidad de uso
- eficiente
- ya sea
- emergentes
- habilitar
- facilita
- permite
- fomentar
- de extremo a extremo
- Punto final
- ingeniero
- Ingeniería
- Empresa
- Soluciones Empresariales
- entusiasta
- ambientes
- equipo
- esencial
- Éter (ETH)
- evaluar
- evaluado
- evaluación
- evaluación
- evaluaciones
- Incluso
- Evento
- Cada
- todo
- ejemplo
- Expandir
- extensión
- f1
- facilitar
- Fracaso
- muchos
- más rápida
- Feature
- Caracteristicas
- pocos
- archivos
- Nombre
- flexible
- Focus
- centrado
- se centra
- siguiendo
- formato
- en
- ser completados
- full spectrum
- completamente
- función
- funciones
- promover
- futuras
- generado
- obtener
- candidato
- Grupo procesos
- Tienen
- es
- ayuda
- ayudado
- ayuda
- Alta
- Alto rendimiento
- altamente
- hosting
- Cómo
- Sin embargo
- HTML
- http
- HTTPS
- AMI
- ID
- ideal
- no haber aun identificado una solucion para el problema
- Identifique
- Identidad
- imagen
- imágenes
- implementar
- implementación
- implementado
- in
- incluir
- incluye
- Incluye
- información
- EN LA MINA
- iniciativas
- Insights
- integrar
- COMPLETAMENTE
- Integra
- integración
- interactuar
- intervención
- invoca
- involucra
- solo
- IT
- SUS
- Trabajos
- Empleo
- jpg
- Guardar
- Clave
- claves
- Estado latente
- .
- aprendido
- aprendizaje
- Lecciones
- Lecciones aprendidas
- Permíteme
- Nivel
- ciclo de vida
- como
- pequeño
- carga
- Baja
- máquina
- máquina de aprendizaje
- Inicio
- mantener
- mantiene
- un mejor mantenimiento.
- para lograr
- gestionan
- gestionado
- Management
- gerente
- gestiona
- administrar
- manual
- Matrix
- Salud Cerebral
- mencionado
- la vida
- mensajería
- Métrica
- podría
- milisegundo
- minutos
- ML
- MLOps
- modelo
- modelos
- Moderno
- Monitorear
- monitoreo
- más,
- más eficiente
- múltiples
- nombre
- naturalmente
- necesario
- ¿ Necesita ayuda
- Nuevo
- Next
- nlp
- ruido
- .
- notificaciones
- número
- of
- que ofrece
- Ofertas
- on
- ONE
- operativos.
- operadores
- optimizado
- Opciones
- orquestado
- Organizado
- Otro
- afuera
- total
- paquete
- paquetes
- embalaje
- parte
- pasa
- Pasando (Paso)
- apasionado
- camino
- actuación
- permiso
- industrial
- plan
- Aviones
- plataforma
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- políticas
- política
- Publicación
- Predicciones
- anterior
- priorizar
- Producto
- Producción
- proyecto
- proyecta
- apropiado
- Protección
- previsto
- proveedor
- proporciona un
- publicar
- publicado
- Publica
- DTP
- fines
- calificado
- distancia
- en tiempo real
- Recomendación
- Reducción
- referido
- registrado
- registro
- Relaciones
- sanaciones
- Renombrado
- repositorio
- pedido
- solicitudes
- Requisitos
- Requisitos
- la investigación
- resistente
- respuesta
- responsable
- Resultados
- reentrenamiento
- reutilizables
- También soy miembro del cuerpo docente de World Extreme Medicine (WEM) y embajadora europea de igualdad para The Transformational Travel Council (TTC). En mi tiempo libre, soy una incansable aventurera, escaladora, patrona de día, buceadora y defensora de la igualdad de género en el deporte y la aventura. En XNUMX, fundé Almas Libres, una ONG nacida para involucrar, educar y empoderar a mujeres y niñas a través del deporte urbano, la cultura y la tecnología.
- Ejecutar
- corredor
- sabio
- mismo
- escalable
- la ampliación
- programa
- programada
- Científico
- los científicos
- Segundo
- (secciones)
- Sectores
- EN LINEA
- mayor
- separado
- Sin servidor
- Servidores
- de coches
- Servicios
- servicio
- set
- Configure
- Shadow
- CAMBIANDO
- tienes
- mostrado
- sencillos
- flojo
- So
- hasta aquí
- Software
- a medida
- Soluciones
- algo
- Fuente
- código fuente
- especialista
- soluciones y
- especificado
- Spectrum
- Spotlight
- Etapa
- etapas
- estándar
- comienzo
- comienza
- Zonas
- pasos
- STORAGE
- Estrategia
- en streaming
- aerodinamizar
- posterior
- Con éxito
- tal
- SOPORTE
- Soportado
- Superficie
- Todas las funciones a su disposición
- ETIQUETA
- ¡Prepárate!
- tareas
- equipo
- plantillas
- Terraform
- Pruebas
- esa
- El
- su
- Les
- por lo tanto
- Estas
- amenazas
- Tres
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- a lo largo de
- rendimiento
- equipo
- fecha y hora
- a
- juntos
- demasiado
- del IRS
- parte superior
- tema
- seguir
- Seguimiento
- marcas comerciales
- tráfico
- Entrenar
- entrenado
- Formación
- detonante
- desencadenados
- GIRO
- bajo
- unidad
- United
- Estados Unidos
- Actualizaciones
- us
- Uso
- utilizan el
- caso de uso
- Usuario
- usuarios
- VALIDAR
- validación
- las variables
- diversos
- versión
- virtualmente
- visión
- visualizar
- vmware
- volumen
- Camino..
- WELL
- ¿
- sean
- que
- amplio
- Amplia gama
- dentro de
- sin
- Actividades:
- flujo de trabajo
- flujos de trabajo
- funciona
- se
- zephyrnet
- Zip
- zonas