Introducción
El mundo de la auditoría de datos puede ser complejo, con muchos desafíos que superar. Uno de los mayores desafíos es manejar atributos categóricos al tratar con conjuntos de datos. En este artículo, profundizaremos en el mundo de la auditoría de datos, la detección de anomalías y el impacto de la codificación de atributos categóricos en los modelos.
Uno de los principales desafíos asociados con la detección de anomalías para la auditoría de datos es el manejo de atributos categóricos. La codificación de atributos categóricos es obligatoria porque los modelos no pueden interpretar la entrada de texto. Por lo general, esto se hace mediante la codificación de etiquetas o la codificación One Hot. Sin embargo, en un conjunto de datos grande, la codificación One-hot puede generar un rendimiento deficiente del modelo debido a la maldición de la dimensionalidad.
OBJETIVOS DE APRENDIZAJE
-
Comprender el concepto de auditoría de datos y el desafío
- Evaluar diferentes métodos de detección de anomalías profundas no supervisadas.
- Comprender el impacto de la codificación de atributos categóricos en los modelos utilizados para la detección de anomalías en los datos de auditoría.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Índice del contenido
- ¿Qué es Auata?
- ¿Qué es la detección de anomalías?
- Principales desafíos enfrentados durante la auditoría de datos
- Conjuntos de datos de auditoría para la detección de anomalías
- Codificación de atributos categóricos
- Codificaciones categóricas
- Modelos de detección de anomalías no supervisados
- ¿Cómo afecta la codificación de atributos categóricos a los modelos?
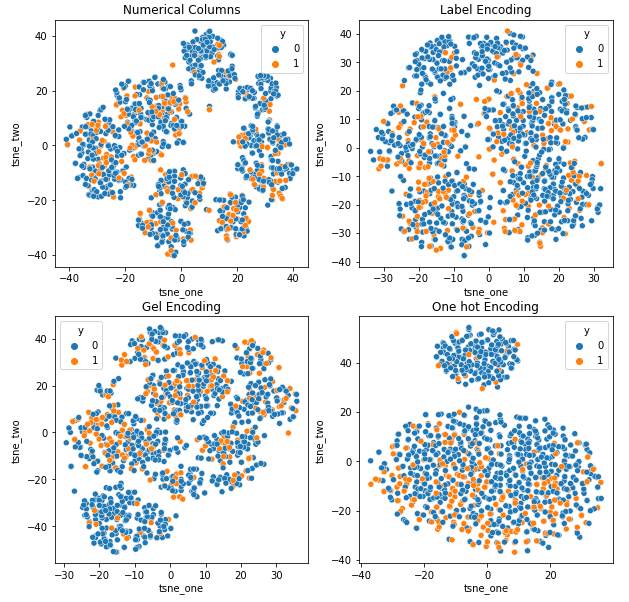
8.1 Representación t-SNE del conjunto de datos de seguros de automóviles
8.2 Representación t-SNE del conjunto de datos de seguros de vehículos
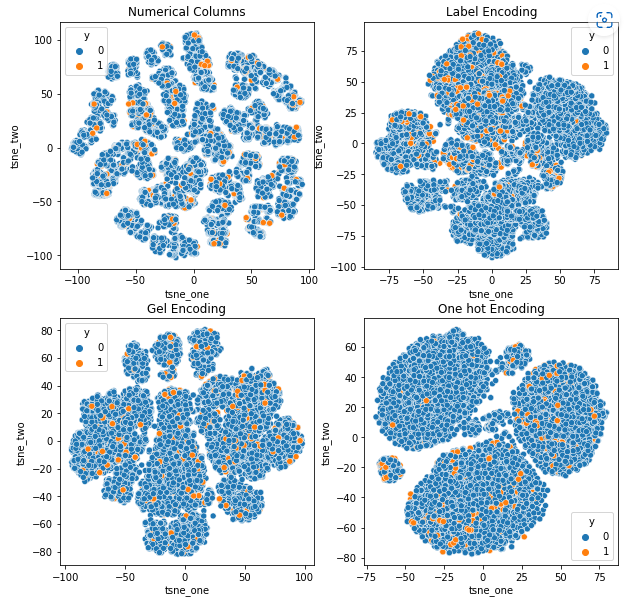
8.3 Representación t-SNE del conjunto de datos de reclamaciones de vehículos - Conclusión
¿Qué es la auditoría de datos?
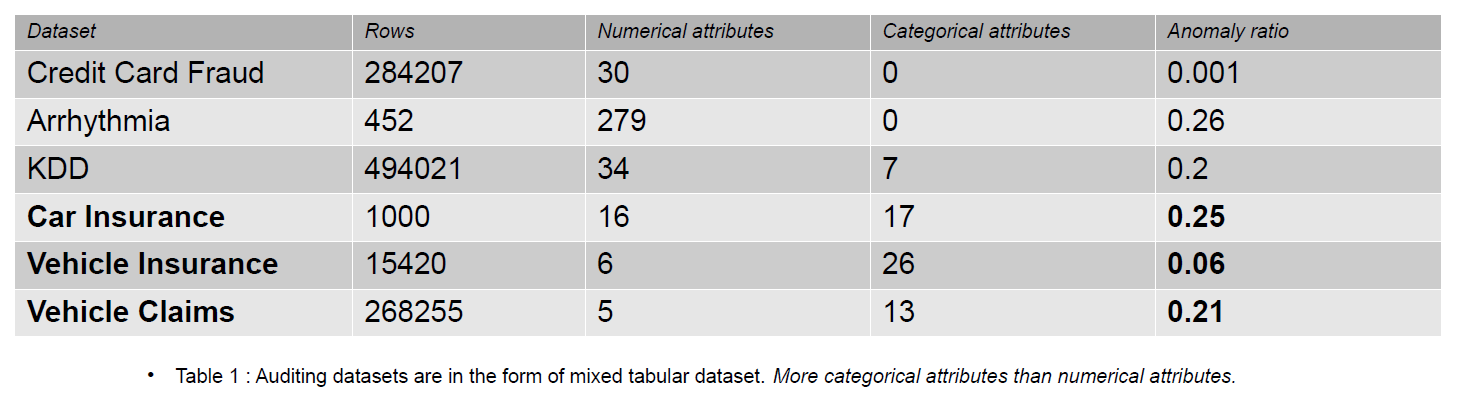
Los datos de auditoría pueden incluir diarios, reclamaciones de seguros y datos de intrusión para sistemas de información; en este artículo, los ejemplos proporcionados son reclamos de seguros de vehículos. Las reclamaciones de seguros se distinguen de los conjuntos de datos de detección de anomalías, por ejemplo, KDD, por una mayor cantidad de características categóricas.
Las características categóricas se discuten en nuestros datos que pueden ser de tipo entero o carácter. Las características numéricas son atributos continuos en nuestros datos que siempre tienen un valor real. Los conjuntos de datos con características numéricas son populares en la comunidad de detección de anomalías, como los datos de fraude de tarjetas de crédito. La mayoría de los conjuntos de datos disponibles públicamente contienen menos características categóricas que los datos de reclamos de seguros. Las características categóricas son más numerosas que numéricas en los conjuntos de datos de reclamaciones de seguros.
Un reclamo de seguro incluye características como modelo, marca, ingresos, costo, emisión, color, etc. La cantidad de características categóricas es mayor en los datos de auditoría que en los conjuntos de datos de tarjeta de crédito y KDD. Estos conjuntos de datos son puntos de referencia en los métodos de detección de anomalías no supervisados. Como se ve en la siguiente tabla, los conjuntos de datos de reclamos de seguros tienen características más categóricas, que son importantes para comprender el comportamiento de los datos fraudulentos.
Los conjuntos de datos de auditoría utilizados para evaluar el impacto de las codificaciones categóricas son seguros de automóviles, seguros de vehículos y reclamaciones de vehículos.
¿Qué es la detección de anomalías?
Una anomalía es una observación ubicada lejos de los datos normales en un conjunto de datos por una distancia específica (Umbral). En términos de datos de auditoría, preferimos el término datos fraudulentos. La detección de anomalías distingue entre datos normales y fraudulentos mediante el aprendizaje automático o el modelo de aprendizaje profundo. Diferentes métodos se puede utilizar para la detección de anomalías, como la estimación de la densidad, el error de reconstrucción y los métodos de clasificación.
- Estimación de densidad – Estos métodos estiman la distribución normal de datos y clasifican los datos anómalos si no se han muestreado de la distribución aprendida.
- error de reconstrucción – Los métodos basados en errores de reconstrucción se basan en el principio de que los datos normales se pueden reconstruir con pérdidas menores que los datos anómalos. Cuanto mayor sea la pérdida de reconstrucción, mayores serán las posibilidades de que los datos sean una anomalía.
- Métodos de clasificación – Métodos de clasificación como Bosque al azar, Isolation Forest, One Class – Support Vector Machines y Local Outlier Factors se pueden utilizar para la detección de anomalías. La clasificación en la detección de anomalías implica identificar una de las clases como la anomalía. Aún así, las clases se dividen en dos grupos (0 y 1) en el escenario multiclase, y la clase con menos datos es la clase anómala.
El resultado de los métodos anteriores son puntuaciones de anomalías o errores de reconstrucción. Entonces tenemos que decidir sobre un umbral, según el cual clasificamos los datos anómalos.
Principales desafíos enfrentados durante la auditoría de datos
- Manejo de Atributos Categóricos: La codificación de atributos categóricos es obligatoria porque el modelo no puede interpretar la entrada de texto. Por lo tanto, los valores se codifican con la codificación Label o la codificación One Hot. Pero en un conjunto de datos grande, One hot encoding transforma los datos en un espacio de gran dimensión al aumentar la cantidad de atributos. El modelo funciona mal debido a la maldición de dimensionalidad.
- Selección del umbral para la clasificación: Si los datos no están etiquetados, es difícil evaluar el rendimiento del modelo porque no sabemos la cantidad de anomalías presentes en el conjunto de datos. El conocimiento previo sobre el conjunto de datos facilita la determinación del umbral. Digamos que tenemos 5 de 10 muestras anómalas en nuestros datos. Entonces, podemos seleccionar el umbral en la puntuación del percentil 50.
- Conjuntos de datos públicos: La mayoría de los conjuntos de datos de auditoría son confidenciales porque pertenecen a empresas corporativas y contienen información confidencial y personal. Una forma posible de mitigar los problemas de confidencialidad es entrenar usando conjuntos de datos sintéticos (reclamaciones de vehículos).
Conjuntos de datos de auditoría para la detección de anomalías
Las reclamaciones de seguros para vehículos incluyen información sobre las propiedades del vehículo, como el modelo, la marca, el precio, el año y el tipo de combustible. Incluye información sobre el conductor, fecha de nacimiento, género y profesión. Además, la reclamación puede incluir información sobre el costo total de la reparación. Los conjuntos de datos utilizados en este artículo son todos de un solo dominio, pero varían en la cantidad de atributos y la cantidad de instancias.
-
El conjunto de datos de Reclamaciones de vehículos es grande, contiene más de 250,000 1171 filas y sus atributos categóricos tienen una cardinalidad de XNUMX. Debido a su gran tamaño, este conjunto de datos sufre la maldición de la dimensionalidad.
- El conjunto de datos de seguros de vehículos es de tamaño mediano, con 15,420 151 filas y XNUMX valores categóricos únicos. Esto lo hace menos propenso a sufrir la maldición de la dimensionalidad.
- El conjunto de datos de seguros de automóviles es pequeño, con etiquetas y un 25 % de muestras anómalas, y contiene una cantidad similar de características numéricas y categóricas. Con 169 categorías únicas, no sufre la maldición de la dimensionalidad.
Codificación de atributos categóricos
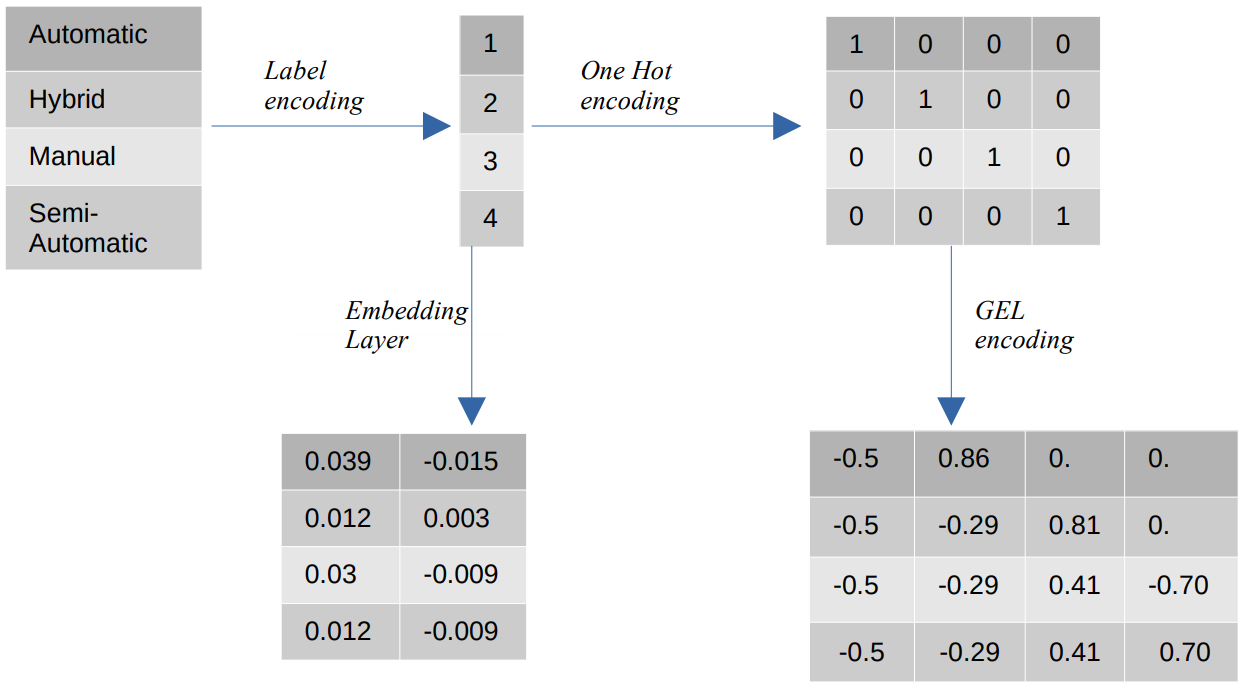
Diferentes codificaciones de valores categóricos
- Codificación de etiquetas – En la codificación de etiquetas, los valores categóricos se reemplazan con valores numéricos enteros entre 1 y el número de categorías. La codificación de etiquetas representa las categorías de la forma prevista para los valores ordinales. Aún así, cuando las características son nominales, la representación es incorrecta ya que los valores categóricos no se ajustan a un orden específico.
Por ejemplo, si tenemos categorías como Automático, Híbrido, Manual y Semiautomático en una función, la codificación de etiquetas transforma estos valores en {1: Automático, 2: Híbrido, 3: Manual, 4: Semiautomático}. Esta representación no proporciona información sobre los valores categóricos, pero una representación como {0: Bajo, 1: Medio, 2: Alto} proporciona una representación clara porque a la variable de entidad Bajo se le asigna un valor numérico más bajo. Por lo tanto, la codificación de etiquetas es mejor para valores ordinales pero desventajosa para valores nominales. - Una codificación en caliente – La codificación One Hot se utiliza para abordar el problema de los valores de codificación nominales, que transforma cada valor categórico en una característica distinta en el conjunto de datos que consta de valores binarios. Por ejemplo, en el caso de cuatro categorías diferentes codificadas como {1, 2, 3, 4}, la codificación One Hot crearía nuevas funciones como {Automático: [1,0,0,0], Híbrido: [0,1,0,0 ,0,0,1,0], Manual: [0,0,0,1], Semiautomático: [XNUMX]}.
La dimensión del conjunto de datos depende directamente del número de categorías presentes en el conjunto de datos. Como resultado, la codificación One Hot puede provocar la maldición de la dimensionalidad, que es un inconveniente de este método de codificación. - Codificación GEL – La codificación GEL es una técnica de incrustación que se puede utilizar en métodos de aprendizaje supervisados y no supervisados. Se basa en el principio de la codificación One Hot y se puede utilizar para disminuir la dimensionalidad de las características categóricas que se han codificado mediante la codificación One Hot.
- Capa de incrustación – Las incrustaciones de palabras proporcionan una forma de utilizar una representación compacta y densa en la que palabras similares tienen codificaciones similares. Una incrustación es un vector denso de valores de punto flotante que son parámetros entrenables. Las incrustaciones de palabras pueden variar desde 8 dimensiones (para conjuntos de datos pequeños) hasta 1024 dimensiones (para conjuntos de datos grandes).
Una incrustación de mayor dimensión puede capturar relaciones más detalladas entre palabras, pero requiere más datos para aprender. La capa de incrustación es una tabla de búsqueda que convierte cada palabra presente en la matriz en un vector de un tamaño específico.
Modelos de detección de anomalías no supervisados
En el mundo real, los datos no están etiquetados en la mayoría de los casos, y el etiquetado de datos es costoso y requiere mucho tiempo. Por lo tanto, utilizaremos modelos no supervisados para nuestras evaluaciones.
- SOM – El mapa autoorganizado (SOM) es un método de aprendizaje competitivo en el que los pesos de las neuronas se actualizan de forma competitiva en lugar de utilizar el aprendizaje de retropropagación. SOM consiste en un mapa de neuronas, cada una con un vector de peso del mismo tamaño que el vector de entrada. El vector de peso se inicializa con pesos aleatorios antes de que comience el entrenamiento. Durante el entrenamiento, cada entrada se compara con las neuronas del mapa en función de una métrica de distancia (por ejemplo, la distancia euclidiana) y se asigna a la mejor unidad de coincidencia (BMU), que es la neurona con la distancia mínima al vector de entrada.
Los pesos de la BMU se actualizan con los pesos del vector de entrada, y las neuronas vecinas se actualizan en función del radio de vecindad (sigma). Dado que las neuronas compiten entre sí para ser la mejor unidad de emparejamiento, este proceso se conoce como aprendizaje competitivo. Al final, las neuronas de las muestras normales están más cerca que las anómalas. Las puntuaciones de anomalías se definen por el error de cuantificación, que es la diferencia entre la muestra de entrada y los pesos de la mejor unidad coincidente. Un mayor error de cuantificación indica una mayor probabilidad de que la muestra sea una anomalía. - DAGMM – El modelo de mezcla gaussiana de codificación automática profunda (DAGMM) es un método de estimación de densidad que asume que las anomalías se encuentran en una región de baja probabilidad. La red se divide en dos partes: una red de compresión, que se utiliza para proyectar datos en dimensiones más bajas mediante un codificador automático, y una red de estimación, que se utiliza para estimar los parámetros del modelo de mezcla gaussiana. DAGMM estima k número de mezclas gaussianas, donde k puede ser cualquier número de 1 a N (el número de puntos de datos), y se supone que los puntos normales se encuentran en una región de alta densidad, lo que significa que la probabilidad de ser muestreado de un La mezcla gaussiana es mayor para los puntos normales que para las muestras anómalas. Las puntuaciones de anomalía se definen por la energía estimada de la muestra.
- RSRAE – La capa robusta de recuperación de superficie para la detección de anomalías no supervisadas es un método de reconstrucción de errores que primero proyecta los datos a una dimensión inferior mediante un codificador automático. Luego, la representación latente se somete a una proyección ortogonal en un subespacio lineal que es resistente a los valores atípicos. Luego, el decodificador reconstruye la salida del subespacio lineal. En este método, un mayor error de reconstrucción indica una mayor probabilidad de que la muestra sea una anomalía.
- SOM-DAGMM- Un mapa autoorganizado (SOM): el modelo de mezcla gaussiana de codificación automática profunda (DAGMM) también es un modelo de estimación de densidad. Al igual que DAGMM, también estima la distribución de probabilidad de puntos de datos normales y clasifica un punto de datos como una anomalía si tiene una baja probabilidad de ser muestreado de la distribución aprendida. La principal diferencia entre SOM-DAGMM y DAGMM es que SOM-DAGMM incluye las coordenadas normalizadas de SOM para la muestra de entrada, lo que proporciona la información topológica faltante en el caso de DAGMM a la red de estimación. El objetivo también es similar a DAGMM en que las puntuaciones de anomalías se definen por la energía estimada de la muestra, y una energía baja indica una mayor probabilidad de que la muestra sea una anomalía.
A continuación, abordaremos el desafío de manejar atributos categóricos.
¿Cómo afecta la codificación de atributos categóricos a los modelos?
Para comprender el impacto de diferentes codificaciones en conjuntos de datos, utilizaremos t-SNE para visualizar las representaciones de baja dimensión de los datos para diferentes codificaciones. t-SNE proyecta datos de alta dimensión en un espacio de menor dimensión, lo que facilita su visualización. Al comparar las visualizaciones de t-SNE y los resultados numéricos de diferentes codificaciones del mismo conjunto de datos, se observa la diferencia en las representaciones resultantes y la comprensión del impacto de la codificación en el conjunto de datos.
Representación t-SNE del conjunto de datos de seguros de automóviles
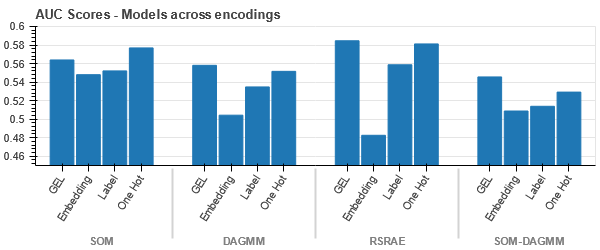
Representación t-SNE del conjunto de datos de seguros de vehículos
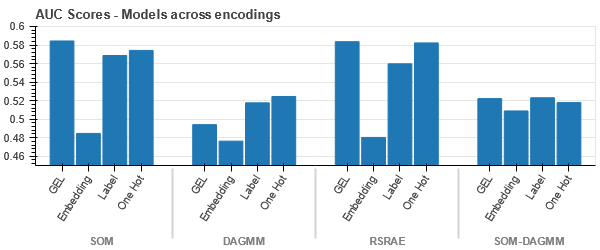
-
Los datos están más cerca unos de otros porque el número de filas es mayor que en el conjunto de datos de seguros de automóviles. Se vuelve difícil de separar con una mayor dimensionalidad en la codificación One Hot.
-
La codificación GEL es mejor que la codificación One Hot en todos los casos excepto DAGMM.
Representación t-SNE del conjunto de datos de reclamaciones de vehículos
-
Los datos están estrechamente vinculados en todos los casos, lo que dificulta su separación con una mayor dimensionalidad. Esta es una de las razones del bajo rendimiento de los modelos debido al aumento de la dimensionalidad.
- SOM supera a todos los demás modelos para este conjunto de datos. Aún así, la capa de incrustación es más adecuada en la mayoría de los casos, lo que nos permite una alternativa a la codificación. atributos categóricos para la detección de anomalías.
Conclusión
Este artículo presenta una breve descripción general de los datos de auditoría, la detección de anomalías y las codificaciones categóricas. Es importante comprender que el manejo de atributos categóricos en la auditoría de datos es un desafío. Al comprender el impacto de codificar los atributos en los modelos, podemos mejorar la precisión de detección de anomalías en los conjuntos de datos. Los puntos clave de este artículo son:
- A medida que aumenta el tamaño de los datos, es importante utilizar enfoques de codificación alternativos para los atributos categóricos, como la codificación GEL y las capas incrustadas, porque la codificación One Hot no es adecuada.
- Un modelo no funciona para todos los conjuntos de datos. Para conjuntos de datos tabulares, el conocimiento del dominio es extremadamente importante.
- La elección del método de codificación depende de la elección del modelo.
El código para la evaluación de modelos está disponible en GitHub.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/01/impact-of-categorical-encodings-on-anomaly-detection-methods/
- 000
- 1
- 10
- 420
- a
- Nuestra Empresa
- arriba
- Conforme
- la exactitud
- Adicionalmente
- dirección
- Todos
- permite
- alternativa
- hacerlo
- Analytics
- Analítica Vidhya
- y
- Detección de anomalías
- enfoques
- artículo
- asigna
- asociado
- ficticio
- atributos
- auditoría
- Automático
- Hoy Disponibles
- basado
- porque
- se convierte en
- antes
- "Ser"
- a continuación
- los puntos de referencia
- MEJOR
- mejores
- entre
- Mayor
- obligado
- marca
- no puede
- capturar
- de
- seguro de auto
- tarjeta
- case
- cases
- categoría
- Reto
- retos
- desafiante
- posibilidades
- personaje
- manera?
- reclamo
- reclamaciones
- clase
- privadas
- clasificación
- clasificar
- limpiar
- más cerca
- código
- Color
- comúnmente
- vibrante e inclusiva
- Empresas
- en comparación con
- comparar
- competir
- competitivos
- integraciones
- concepto
- confidencialidad
- Que consiste
- contiene
- continuo
- Sector empresarial
- Cost
- Para crear
- crédito
- .
- datos
- puntos de datos
- conjuntos de datos
- Fecha
- tratar
- disminuir
- profundo
- deep learning
- depende
- detallado
- Detección
- Determinar
- un cambio
- una experiencia diferente
- difícil
- Dimensiones
- dimensiones
- directamente
- discreción
- distancia
- distinto
- dividido
- dominio
- conductor
- durante
- cada una
- más fácil
- ya sea
- energía
- error
- Errores
- estimación
- estimado
- estima
- etc.
- evaluar
- evaluación
- evaluaciones
- ejemplo
- ejemplos
- Excepto
- costoso
- extremadamente
- enfrentado
- factores importantes
- Feature
- Caracteristicas
- Nombre
- bosque
- fraude
- fraudulento
- en
- Combustible
- Género
- Grupo
- Manejo
- Alta
- más alto
- HOT
- Sin embargo
- HTTPS
- Híbrido
- identificar
- Impacto
- importante
- mejorar
- in
- incluir
- incluye
- por
- aumentado
- Los aumentos
- creciente
- Indica
- información
- Sistemas De Información
- Las opciones de entrada
- aseguradora
- solo
- cuestiones
- IT
- Clave
- Saber
- especialistas
- conocido
- Label
- etiquetado
- Etiquetas
- large
- mayores
- .
- ponedoras
- Lead
- APRENDE:
- aprendido
- aprendizaje
- local
- situados
- búsqueda
- de
- pérdidas
- Baja
- máquina
- máquina de aprendizaje
- Máquinas
- Inicio
- HACE
- Realizar
- obligatorio
- manual
- muchos
- mapa
- pareo
- Matrix
- sentido
- Medios
- mediano
- Método
- métodos
- métrico
- mínimo
- que falta
- Mitigar las
- mezcla
- modelo
- modelos
- más,
- MEJOR DE TU
- del sistema,
- Neuronas
- Nuevo
- Nuevas características
- normal
- número
- objetivo
- ONE
- solicite
- Otro
- Supera
- Superar
- visión de conjunto
- propiedad
- parámetros
- parte
- partes
- actuación
- realiza
- con
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- punto
- puntos
- pobre
- Popular
- posible
- preferir
- presente
- regalos
- precio
- principio
- Anterior
- probabilidades
- Problema
- profesión
- proyecto
- datos del proyecto
- Proyección
- proyecta
- propiedades
- proporcionar
- previsto
- proporciona un
- publicado
- azar
- distancia
- real
- mundo real
- razones
- recuperación
- región
- Relaciones
- reparación
- reemplazados
- representación
- representa
- requiere
- resultado
- resultante
- Resultados
- robusto
- mismo
- Ciencia:
- sensible
- separado
- mostrado
- Sigma
- similares
- desde
- soltero
- Tamaño
- chica
- menores
- So
- Espacio
- soluciones y
- comienza
- Sin embargo
- tal
- Sufre
- adecuado
- SOPORTE
- Superficie
- sintético
- Todas las funciones a su disposición
- mesa
- Takeaways
- términos
- El
- el mundo
- por lo tanto
- umbral
- fuertemente
- prolongado
- a
- Total
- Entrenar
- Formación
- entender
- comprensión
- único
- unidad
- aprendizaje sin supervisión
- actualizado
- us
- utilizan el
- propuesta de
- Valores
- vehículo
- Vehículos
- peso
- ¿
- Que es
- que
- mientras
- seguirá
- Palabra
- palabras
- Actividades:
- mundo
- se
- año
- zephyrnet