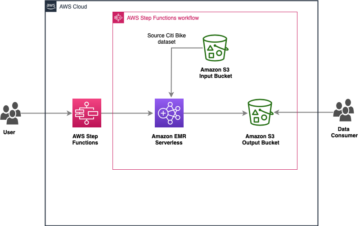
Recientemente anunciamos la disponibilidad general de Amazon OpenSearch sin servidor , una nueva opción para Servicio Amazon OpenSearch eso facilita la ejecución de cargas de trabajo de búsqueda y análisis a gran escala sin tener que configurar, administrar o escalar clústeres de OpenSearch. Con OpenSearch Serverless, obtiene los mismos tiempos de respuesta interactivos en milisegundos que OpenSearch Service con la simplicidad de un entorno sin servidor.
En esta publicación, aprenderá a migrar sus índices existentes de un dominio de clúster administrado por OpenSearch Service a una colección sin servidor mediante Logstash.
Con los dominios de OpenSearch, obtiene clústeres seguros y dedicados configurados y optimizados para sus cargas de trabajo en minutos. Tiene control total sobre la configuración de recursos informáticos, de memoria y de almacenamiento en clústeres para optimizar el costo y el rendimiento de sus aplicaciones. OpenSearch Serverless proporciona una forma aún más sencilla de ejecutar cargas de trabajo de búsqueda y análisis, sin tener que pensar en clústeres. Simplemente cree una colección y un grupo de índices, y puede comenzar a ingerir y consultar los datos.
Resumen de la solución
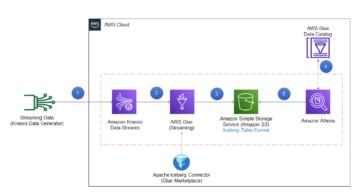
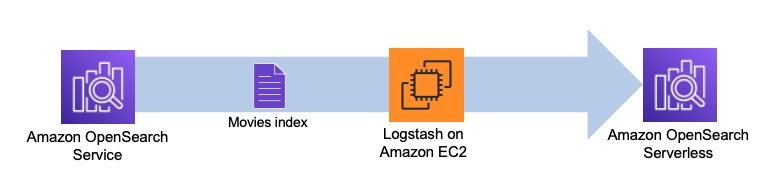
Logstash es un software de código abierto que proporciona ETL (extracción, transformación y carga) para sus datos. Puede configurar Logstash para conectarse a una fuente y un destino a través de complementos de entrada y salida. En el medio, configura filtros que pueden transformar sus datos. Esta publicación lo guía a través de los pasos que necesita para configurar Logstash para conectar un dominio de OpenSearch Service (entrada) a una colección OpenSearch Serverless (salida).
Establece los complementos de origen y destino en el archivo de configuración de Logstash. El archivo de configuración tiene secciones para Input, Filtery Output. Una vez configurado, Logstash enviará una solicitud al dominio del servicio OpenSearch y leerá los datos de acuerdo con la consulta que haya realizado en el input sección. Después de leer los datos del servicio OpenSearch, puede enviarlos opcionalmente a la siguiente etapa Filter para transformaciones como agregar o eliminar un campo de los datos de entrada o actualizar un campo con diferentes valores. En este ejemplo, no utilizará el Filter enchufar. El siguiente es el Output enchufar. La versión de código abierto de Logstash (Logstash OSS) proporciona una manera conveniente de usar la API masiva para cargar datos en sus colecciones. OpenSearch Serverless admite la logstash-salida-opensearch complemento de salida, que admite Gestión de identidades y accesos de AWS (IAM) credenciales para el control de acceso a datos.
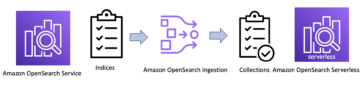
El siguiente diagrama ilustra el flujo de trabajo de nuestra solución.
Requisitos previos
Antes de comenzar, asegúrese de haber completado los siguientes requisitos previos:
- Anote el ARN, el nombre de usuario y la contraseña de su dominio OpenSearch Service.
- Cree una colección sin servidor de OpenSearch. Si es nuevo en OpenSearch Serverless, consulte Análisis de registros de forma fácil con Amazon OpenSearch Serverless para obtener detalles sobre cómo configurar su colección.
Configure Logstash y los complementos de entrada y salida para OpenSearch
Complete los siguientes pasos para configurar Logstash y sus complementos:
- Descargar
logstash-oss-with-opensearch-output-plugin. (Este ejemplo usa la distribución para macos-x64. Para otras distribuciones, consulte el artefactos.) - Extrae el tarball descargado:
- Actualizar el
logstash-output-opensearchcomplemento a la última versión: - Instale la
logstash-input-opensearchenchufar:
Prueba el complemento
Entremos en acción y veamos cómo funciona el complemento. El siguiente archivo de configuración recupera datos del movies index en su dominio de OpenSearch Service e indexa esos datos en su colección OpenSearch Serverless con el mismo nombre de índice, movies.
Cree un nuevo archivo y agregue el siguiente contenido, luego guarde el archivo como opensearch-serverless-migration.conf. Proporcione los valores para el extremo del dominio del servicio OpenSearch en HOST, NOMBRE DE USUARIOy CONTRASEÑA existentes input y los detalles del extremo de la recopilación de OpenSearch Serverless en HOST para cada año fiscal junto con la REGIÓN, AWS_ACCESS_KEY_IDy AWS_SECRET_ACCESS_KEY existentes output .
Puede especificar una consulta en el input sección de la configuración anterior. El match_all consulta coincide con todos los datos en el movies índice. Puede cambiar la consulta si desea seleccionar un subconjunto de los datos. También puede usar la consulta para paralelizar la transferencia de datos ejecutando varios procesos de Logstash con configuraciones que especifican diferentes segmentos de datos. También puede realizar la paralelización mediante la ejecución de procesos de Logstash en varios índices, si los tiene.
Iniciar Logstash
Use el siguiente comando para iniciar Logstash:
Después de ejecutar el comando, Logstash recuperará los datos del índice de origen de su dominio de OpenSearch Service y escribirá en el índice de destino en su colección de OpenSearch Serverless. Cuando se completa la transferencia de datos, Logstash se apaga. Ver el siguiente código:
Verificar los datos en OpenSearch Serverless
Puede verificar que Logstash copió todos sus datos comparando el recuento de documentos en su dominio y su colección. Ejecute la siguiente consulta desde el herramientas de desarrollo pestaña, o con curl, postman, o un cliente HTTP similar. La siguiente consulta le ayuda a buscar todos los documentos de la movies index y devuelve los documentos principales junto con el recuento. De forma predeterminada, OpenSearch devolverá el recuento de documentos hasta un máximo de 10,000. Agregando el track_total_hits flag le ayuda a obtener el recuento exacto de documentos si el recuento de documentos supera los 10,000.
Conclusión
En esta publicación, migró datos de su dominio de OpenSearch Service a su colección de OpenSearch Serverless usando los complementos de entrada y salida de OpenSearch de Logstash.
Esté atento a una serie de publicaciones que se centran en las diversas opciones disponibles para que pueda crear análisis de registros y soluciones de búsqueda efectivos utilizando OpenSearch Serverless. También puede consultar la Primeros pasos con Amazon OpenSearch Serverless taller para saber más sobre OpenSearch Serverless.
Si tiene comentarios sobre esta publicación, envíelos en la sección de comentarios. Si tiene preguntas sobre esta publicación, inicie un nuevo hilo en el Foro del servicio Amazon OpenSearch or póngase en contacto con el soporte de AWS.
Sobre los autores
 Prashant Agrawal es Arquitecto de Soluciones Sr. Especialista en Búsqueda con Amazon OpenSearch Service. Trabaja en estrecha colaboración con los clientes para ayudarlos a migrar sus cargas de trabajo a la nube y ayuda a los clientes existentes a ajustar sus clústeres para lograr un mejor rendimiento y ahorrar costos. Antes de unirse a AWS, ayudó a varios clientes a usar OpenSearch y Elasticsearch para sus casos de uso de búsqueda y análisis de registros. Cuando no está trabajando, puedes encontrarlo viajando y explorando nuevos lugares. En resumen, le gusta hacer Comer → Viajar → Repetir.
Prashant Agrawal es Arquitecto de Soluciones Sr. Especialista en Búsqueda con Amazon OpenSearch Service. Trabaja en estrecha colaboración con los clientes para ayudarlos a migrar sus cargas de trabajo a la nube y ayuda a los clientes existentes a ajustar sus clústeres para lograr un mejor rendimiento y ahorrar costos. Antes de unirse a AWS, ayudó a varios clientes a usar OpenSearch y Elasticsearch para sus casos de uso de búsqueda y análisis de registros. Cuando no está trabajando, puedes encontrarlo viajando y explorando nuevos lugares. En resumen, le gusta hacer Comer → Viajar → Repetir.
 jon manejador (@_searchgeek) es Arquitecto principal de soluciones sénior en Amazon Web Services con sede en Palo Alto, CA. Jon trabaja en estrecha colaboración con los equipos de CloudSearch y Elasticsearch, brindando ayuda y orientación a una amplia gama de clientes que tienen cargas de trabajo de búsqueda que desean trasladar a la nube de AWS. Antes de unirse a AWS, la carrera de Jon como desarrollador de software incluyó cuatro años de codificación de un motor de búsqueda de comercio electrónico a gran escala.
jon manejador (@_searchgeek) es Arquitecto principal de soluciones sénior en Amazon Web Services con sede en Palo Alto, CA. Jon trabaja en estrecha colaboración con los equipos de CloudSearch y Elasticsearch, brindando ayuda y orientación a una amplia gama de clientes que tienen cargas de trabajo de búsqueda que desean trasladar a la nube de AWS. Antes de unirse a AWS, la carrera de Jon como desarrollador de software incluyó cuatro años de codificación de un motor de búsqueda de comercio electrónico a gran escala.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/migrate-your-indexes-to-amazon-opensearch-serverless-with-logstash/
- 000
- 10
- 100
- 28
- 39
- 7
- a
- Nuestra Empresa
- de la máquina
- Conforme
- Lograr
- la columna Acción
- Después
- en contra
- Agente
- Todos
- Amazon
- Amazon Web Services
- Analytics
- y
- anunció
- abejas
- aplicaciones
- disponibilidad
- Hoy Disponibles
- AWS
- basado
- antes
- mejores
- entre
- general
- build
- CA
- Propósito
- cases
- CD
- el cambio
- cliente
- de cerca
- Soluciones
- Médico
- código
- Codificación
- --
- colecciones
- comentarios
- comparar
- completar
- Completado
- Calcular
- Configuración
- Contacto
- contenido
- control
- Conveniente
- Cost
- Para crear
- Referencias
- Clientes
- datos
- acceso a los datos
- a dedicados
- Predeterminado
- destino
- detalles
- Developer
- una experiencia diferente
- discapacitados
- documento
- documentos
- "Hacer"
- dominio
- dominios
- DE INSCRIPCIÓN
- comer
- comercio electrónico
- Eficaz
- ya sea
- Elasticsearch
- Punto final
- Motor
- Entorno
- Éter (ETH)
- Incluso
- NUNCA
- ejemplo
- excede
- existente
- Explorar
- extraerlos
- realimentación
- campo
- Archive
- filtros
- Encuentre
- enfoque
- siguiendo
- Desde
- ser completados
- General
- obtener
- conseguir
- Grupo procesos
- es
- ayuda
- ayudado
- ayuda
- Cómo
- Como Hacer
- HTTPS
- AMI
- Identidad
- in
- incluido
- índice
- índices
- Indices
- info
- Las opciones de entrada
- instalar
- interactivo
- IT
- unión
- Saber
- Gran escala
- más reciente
- APRENDE:
- carga
- Inicio
- para lograr
- HACE
- gestionan
- gestionado
- máximas
- Salud Cerebral
- migrado
- milisegundo
- minutos
- más,
- movimiento
- Películas
- múltiples
- nombre
- ¿ Necesita ayuda
- Nuevo
- Next
- de código abierto
- Software de código abierto
- Optimización
- optimizado
- Optión
- Opciones
- Oss
- Otro
- Palo Alto
- Contraseña
- actuación
- industrial
- Lugares
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- plugin
- plugins
- Publicación
- Artículos
- requisitos previos
- Director de la escuela
- Anterior
- en costes
- proporcionar
- proporciona un
- proporcionando
- poner
- Preguntas
- distancia
- Leer
- recientemente
- región
- registro
- Remoto
- la eliminación de
- repetir
- solicita
- Recursos
- respuesta
- volvemos
- devoluciones
- Ejecutar
- corredor
- correr
- mismo
- Guardar
- Escala
- Buscar
- motor de búsqueda
- Sección
- (secciones)
- seguro
- Serie
- Sin servidor
- de coches
- Servicios
- set
- En Corto
- cerrar
- Se calla
- similares
- sencillez
- simplemente
- Software
- a medida
- Soluciones
- Fuente
- especialista
- Etapa
- comienzo
- fundó
- pasos
- STORAGE
- enviar
- Con éxito
- tal
- soportes
- equipos
- El
- La Fuente
- su
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- veces
- a
- parte superior
- transferir
- Transformar
- transformaciones
- viajes
- Viajar
- verdadero
- bajo
- Actualizar
- actualización
- utilizan el
- Usuario
- Valores
- diversos
- verificar
- versión
- vía
- web
- servicios web
- que
- QUIENES
- seguirá
- sin
- flujo de trabajo
- trabajando
- funciona
- taller
- Talleres
- escribir
- años
- tú
- zephyrnet