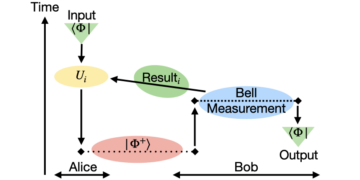
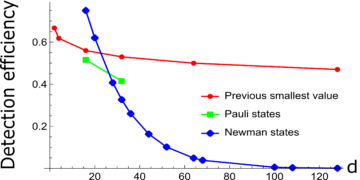
1Centro de Tecnologías Cuánticas, Universidad Nacional de Singapur, Singapur
2Departamento de Ingeniería Eléctrica e Informática, Facultad de Ingeniería, Universidad Nacional de Singapur, Singapur
¿Encuentra este documento interesante o quiere discutirlo? Scite o deje un comentario en SciRate.
Resumen
Iniciamos el estudio de las compensaciones entre exploración y explotación en el aprendizaje en línea de las propiedades de los estados cuánticos. Dado el acceso secuencial del oráculo a un estado cuántico desconocido, en cada ronda, tenemos la tarea de elegir un observable de un conjunto de acciones con el objetivo de maximizar su valor esperado en el estado (la recompensa). La información obtenida sobre el estado desconocido de las rondas anteriores se puede utilizar para mejorar gradualmente la elección de la acción, reduciendo así la brecha entre la recompensa y la recompensa máxima alcanzable con el conjunto de acciones dado (el arrepentimiento). Proporcionamos varios límites inferiores teóricos de la información sobre el arrepentimiento acumulativo en el que debe incurrir un alumno óptimo, y mostramos que escala al menos como la raíz cuadrada del número de rondas jugadas. También investigamos la dependencia del arrepentimiento acumulativo en el número de acciones disponibles y la dimensión del espacio subyacente. Además, mostramos estrategias que son óptimas para bandidos con un número finito de armas y estados mixtos generales.
[Contenido incrustado]
► datos BibTeX
► referencias
[ 1 ] T. Lattimore y C. Szepesvári. “Algoritmos bandidos”. Prensa de la Universidad de Cambridge. (2020).
https: / / doi.org/ 10.1017 / 9781108571401
[ 2 ] A. Slivkins. “Introducción a los bandidos de múltiples brazos”. Fundamentos y tendencias en aprendizaje automático 12, 1–286 (2019).
https: / / doi.org/ 10.1561 / 2200000068
[ 3 ] S. Bubeck y N. Cesa-Bianchi. “Análisis de arrepentimiento de problemas de bandidos de múltiples brazos estocásticos y no estocásticos”. Fundamentos y tendencias en aprendizaje automático 5, 1–122 (2012).
https: / / doi.org/ 10.1561 / 2200000024
[ 4 ] D. Bouneffouf, I. Rish y C. Aggarwal. “Encuesta sobre aplicaciones de bandidos polivalentes y contextuales”. En 2020 Congreso IEEE sobre Computación Evolutiva (CEC). Páginas 1–8. (2020).
https:///doi.org/10.1109/CEC48606.2020.9185782
[ 5 ] L. Tang, R. Rosales, A. Singh y D. Agarwal. “Selección automática de formato de anuncio a través de bandidos contextuales”. En Actas de la 22ª Conferencia Internacional ACM sobre Gestión de la Información y el Conocimiento. Página 1587-1594. Asociación de Maquinaria de Computación (2013).
https: / / doi.org/ 10.1145 / 2505515.2514700
[ 6 ] M. Cohen, I. Lobel y R. Paes Leme. “Precio dinámico basado en funciones”. Ciencias de la gestión 66, 4921–4943 (2020).
https: / / doi.org/ 10.1287 / mnsc.2019.3485
[ 7 ] W. Thompson. “Sobre la probabilidad de que una probabilidad desconocida supere a otra a la vista de la evidencia de dos muestras”. Biometrika 25, 285–294 (1933).
https://doi.org/10.1093/biomet/25.3-4.285
[ 8 ] H. Robbins. “Algunos Aspectos del Diseño Secuencial de Experimentos”. Boletín de la Sociedad Matemática Estadounidense 58, 527–535 (1952).
https://doi.org/10.1090/S0002-9904-1952-09620-8
[ 9 ] TL Lai y H. Robbins. “Reglas de asignación adaptativa asintóticamente eficientes”. Avances en Matemáticas Aplicadas 6, 4–22 (1985).
https://doi.org/10.1016/0196-8858(85)90002-8
[ 10 ] P. Auer, N. Cesa-Bianchi y P. Fischer. “Análisis en tiempo finito del problema del bandido con múltiples brazos”. Mach. Aprender. 47, 235–256 (2002).
https: / / doi.org/ 10.1023 / A: 1013689704352
[ 11 ] B. Casalé, G. Di Molfetta, H. Kadri, and L. Ralaivola. “Bandidos cuánticos”. Mach cuántico. Intel. 2 (2020).
https://doi.org/10.1007/s42484-020-00024-8
[ 12 ] D. Wang, X. You, T. Li y A. Childs. “Algoritmos de exploración cuántica para bandidos de múltiples brazos”. En Actas de la Conferencia AAAI sobre Inteligencia Artificial. Volumen 35, páginas 10102–10110. (2021).
[ 13 ] P. Rebentrost, Y. Hamoudi, M. Ray, X. Wang, S. Yang y M. Santha. “Algoritmos cuánticos para cobertura y aprendizaje de modelos ising”. física Rev. A 103, 012418 (2021).
https: / / doi.org/ 10.1103 / PhysRevA.103.012418
[ 14 ] O.Shamir. “Sobre la complejidad de la optimización lineal de bandidos”. En Actas de la 28ª Conferencia sobre Teoría del Aprendizaje. Volumen 40 de Proceedings of Machine Learning Research, páginas 1523–1551. PMLR (2015).
[ 15 ] P. Rusmevichientong y J. Tsitsiklis. “Bandidos linealmente parametrizados”. Matemáticas de la Investigación Operativa 35 (2008).
https: / / doi.org/ 10.1287 / moor.1100.0446
[ 16 ] J. Barry, DT Barry y S. Aaronson. “Procesos de decisión markov parcialmente observables cuánticos”. física Rev. A 90, 032311 (2014).
https: / / doi.org/ 10.1103 / PhysRevA.90.032311
[ 17 ] M. Ying, Y. Feng y S. Ying. “Políticas óptimas para procesos de decisión de quantum markov”. Revista internacional de automatización y computación 18, 410–421 (2021).
https: / / doi.org/ 10.1007 / s11633-021-1278-z
[ 18 ] M. París y J. Rehacek. “Estimación del estado cuántico”. Springer Publishing Company, Incorporada. (2010). 1ra edición
https: / / doi.org/ 10.1007 / b98673
[ 19 ] S. Aaronson. “Tomografía de sombra de estados cuánticos”. En Actas del 50º Simposio Anual ACM SIGACT sobre Teoría de la Computación. Página 325–338. STOC 2018. Asociación de Maquinaria de Computación (2018).
https: / / doi.org/ 10.1145 / 3188745.3188802
[ 20 ] S. Aaronson, X. Chen, E. Hazan, S. Kale y A. Nayak. “Aprendizaje en línea de estados cuánticos”. Revista de mecánica estadística: teoría y experimento 2019 (2018).
https: / / doi.org/ 10.1088 / 1742-5468 / ab3988
[ 21 ] J. Bretagnolle y C. Huber. “Estimation des densités: risque minimax”. Zeitschrift für Wahrscheinlichkeitstheorie und verwandte Gebiete 47, 119–137 (1979).
https: / / doi.org/ 10.1007 / BF00535278
[ 22 ] M. Müller-Lennert, F. Dupuis, O. Szehr, S. Fehr y M. Tomamichel. “Sobre las entropías cuánticas de Rényi: una nueva generalización y algunas propiedades”. Revista de Física Matemática 54, 122203 (2013).
https: / / doi.org/ 10.1063 / 1.4838856
[ 23 ] M. Wilde, A. Winter y D. Yang. "Converso fuerte para la capacidad clásica de romper el enredo y los canales de Hadamard a través de una entropía relativa de Rényi intercalada". Comunicaciones en física matemática 331, 593–622 (2014).
https: / / doi.org/ 10.1007 / s00220-014-2122-x
[ 24 ] W. Hoeffding. "Las desigualdades de probabilidad para sumas de variables aleatorias delimitadas". Revista de la Asociación Estadounidense de Estadística 58, 13–30 (1963).
https: / / doi.org/ 10.1080 / 01621459.1963.10500830
[ 25 ] P. Auer. “Uso de límites de confianza para las compensaciones de explotación-exploración”. J. Mach. Aprender. Res. 3, 397–422 (2003).
https: / / doi.org/ 10.5555 / 944919.944941
[ 26 ] D. Varsha, T. Hayes y S. Kakade. "Optimización lineal estocástica bajo retroalimentación de bandidos". En Actas de la 21ª Conferencia sobre Teoría del Aprendizaje. Páginas 355–366. (2008).
[ 27 ] P. Rusmevichientong y JN Tsitsiklis. “Bandidos linealmente parametrizados”. Matemáticas de la investigación operativa 35, 395–411 (2010).
https: / / doi.org/ 10.1287 / moor.1100.0446
[ 28 ] Y. Abbasi-Yadkori, D. Pál y Cs. Szepesvári. “Algoritmos mejorados para bandidos estocásticos lineales”. En Avances en Sistemas de Procesamiento de Información Neural. Volumen 24. Curran Associates, Inc. (2011).
[ 29 ] TL Lai. “Asignación de Tratamiento Adaptativo y el Problema del Bandido de Armas Múltiples”. Los Anales de Estadística 15, 1091 - 1114 (1987).
https: / / doi.org/ 10.1214 / aos / 1176350495
[ 30 ] M. Guţă, J. Kahn, R. Kueng y JA Tropp. “Tomografía de estado rápido con límites de error óptimos”. Journal of Physics A: Mathematical and Theoretical 53, 204001 (2020).
https: / / doi.org/ 10.1088 / 1751-8121 / ab8111
[ 31 ] T. Lattimore y B. Hao. “Recuperación de la fase Bandit”. En Avances en Sistemas de Procesamiento de Información Neural. Volumen 34, páginas 18801–18811. Curran Associates, Inc. (2021).
Citado por
[1] Zongqi Wan, Zhijie Zhang, Tongyang Li, Jialin Zhang y Xiaoming Sun, “Quantum Multi-Armed Bandits and Stochastic Linear Bandits Enjoy Logarithmic Regrets”, arXiv: 2205.14988.
[2] Xinyi Chen, Elad Hazan, Tongyang Li, Zhou Lu, Xinzhao Wang y Rui Yang, “Aprendizaje adaptativo en línea de los estados cuánticos”, arXiv: 2206.00220.
Las citas anteriores son de ANUNCIOS SAO / NASA (última actualización exitosa 2022-07-24 00:26:50). La lista puede estar incompleta ya que no todos los editores proporcionan datos de citas adecuados y completos.
On Servicio citado por Crossref no se encontraron datos sobre las obras citadas (último intento 2022-07-24 00:26:48).
Este documento se publica en Quantum bajo el Creative Commons Reconocimiento 4.0 Internacional (CC BY 4.0) licencia. Los derechos de autor permanecen con los titulares de derechos de autor originales, como los autores o sus instituciones.