¿Alguna vez ha esperado ese paquete costoso que dice "enviado", pero no tiene idea de dónde está? El historial de seguimiento dejó de actualizarse hace cinco días y casi has perdido la esperanza. Pero espera, 11 días después, lo tienes en la puerta de tu casa. Deseaba que la trazabilidad hubiera sido mejor para aliviarle de toda la espera ansiosa. Aquí es donde entra en juego la “observabilidad”.
En un panorama técnico, querrá evitar que esto le suceda a su software o sistemas de datos. Y, por lo tanto, adopta herramientas de monitoreo, que recopilan los registros y las métricas de sus sistemas y le informan sobre su estado interno. El monitoreo funciona mejor cuando desea que sus sistemas le informen cuál es el error, dónde y cuándo ocurrió, pero no le dice cómo resolver el error.
Hace más de una década, las herramientas de monitoreo carecían del contexto y la previsión de los problemas subyacentes del sistema y los equipos se limitaban a depurar los errores operativos cotidianos. Hoy, trabajamos y vivimos en un mundo distribuido de microservicios y canalizaciones de datos; incluso el empleo de múltiples herramientas de monitoreo no lo ayudará a responder sus preguntas comerciales como "¿Por qué mi aplicación siempre es lenta?" o "¿En qué etapa ocurrió el problema y qué tan profundo está en la pila?" o "¿Cómo puedo mejorar el rendimiento general del entorno?" Se vuelve necesario ser proactivo al tomar estas decisiones y tener una visibilidad general de sus sistemas, aplicaciones y datos.
Este del blog por Etsy fue publicado hace una década, y establece el hecho mismo en el segundo párrafo:
“Las métricas de aplicación suelen ser las más difíciles, pero las más importantes, de las tres. Son muy específicos para su negocio y cambian a medida que cambian sus aplicaciones (y Etsy cambia mucho)".
Entonces, ¿cómo medimos todo y cualquier cosa? Empezamos con la observabilidad.
¿Qué es la observabilidad?
El término “observabilidad” fue acuñado por Rudolf Emil Kálmán en 1960 en su artículo de ingeniería para describir los sistemas de control matemático. Lo definió como una medida de qué tan bien se pueden inferir los estados internos de un sistema a partir del conocimiento de sus salidas externas. ¿Pero no suena como monitoreo? Básicamente, sí, es monitoreo.
En estos días, la observabilidad se ha convertido en un tema bastante candente. Según varias encuestas de mercado, es una plataforma de mil millones de dólares. Muchas organizaciones han adoptado el concepto y lo han empleado como marco para la visibilidad de extremo a extremo de sus sistemas distribuidos y canalizaciones. Sin embargo, la observabilidad se confunde con el seguimiento. Por ahora, puedo decir que el monitoreo es un subconjunto de la observabilidad, donde la observabilidad es un gran término general.
La observabilidad permite el seguimiento distribuido mediante la recopilación y agregación de seguimientos, registros y métricas. Veamos qué infieren estos:
- Rastros: Cuando un sistema recibe una solicitud, los seguimientos le indican cómo fluye esa solicitud, a lo largo de su ciclo de vida, desde el origen hasta el destino. Las trazas se representan mediante "intervalos". Un seguimiento es un árbol de intervalos y un intervalo es una sola operación dentro de un seguimiento. Le ayudan a localizar errores, latencia o cuellos de botella en el sistema.
- Registros: Estos son eventos con marca de tiempo generados por máquinas que le informan sobre las operaciones o cambios que ocurrieron en el sistema. Los registros se utilizan a menudo para consultar estos errores o cambios en el sistema.
- Métrica: Estos proporcionan información cuantitativa sobre la CPU, la memoria, el uso del disco y el rendimiento del sistema durante un período de tiempo.
Estos atributos mejoran el marco de seguimiento con trazabilidad. La trazabilidad le brinda los lentes para rastrear una solicitud que realiza una llamada a su sistema, cuánto tiempo lleva pasar de un componente a otro, qué otros servicios invoca, arroja algún error, qué registros produce, en qué estado está, cuándo comenzó y finalizó, cuál es la línea de tiempo que permaneció en su sistema, etc. Cuando recopila, agrega y analiza estos rastros, puede tomar decisiones informadas valiosas, como la línea de tiempo del cliente en un sitio web de comercio electrónico. , cuánto tiempo les tomó buscar un producto, cuánto tiempo vieron el producto, la página HTML cargó los detalles completos como imágenes o videos incrustados, cuánto tiempo tardó el sistema en autenticar y procesar el pago, etc.
¿Qué logramos con la observabilidad en un entorno distribuido?
La evolución de los sistemas distribuidos comenzó cuando las organizaciones comenzaron a alejarse de su arquitectura monolítica centralizada a una arquitectura de microservicio distribuida y descentralizada. Y este es todavía un trabajo en progreso en el que muchas organizaciones están adoptando la naturaleza de microservicio de los sistemas y aplicaciones. Y todo esto se puede atribuir a grandes volúmenes de datos y escalado. La gestión de un entorno distribuido requiere aprendizaje continuo, mano de obra adicional, cambios en marcos y políticas, gestión de TI, etc. De hecho, es un gran cambio.
Anteriormente, en el entorno monolítico limitado, el hardware, el software, los datos y las bases de datos vivían todos bajo un mismo techo. Con la llegada de Big Data en la década de 2000, los sistemas de monitoreo y escalado comenzaron a convertirse en una gran preocupación. A menudo, las organizaciones emplearon diferentes herramientas de monitoreo para satisfacer las necesidades de sus diversas aplicaciones. Como resultado, pronto se convirtió en una sobrecarga operativa con escasa resiliencia, visibilidad y confiabilidad.
Todas estas cuestiones dieron lugar a la adopción de la observabilidad. En la actualidad, existen múltiples herramientas de observabilidad para canalizaciones de datos, aplicaciones, redes y seguridad para el seguimiento distribuido en un entorno complejo. Coexisten con su primo, las herramientas de monitoreo, y aprovechan la recopilación de información de su primo y agregan información adicional de sus propios datos de rastreo.
Hay muchos componentes móviles en todos estos sistemas, cuyas huellas, cuando se capturan, pueden ilustrar la historia de las 5 W: cuándo, dónde, por qué, qué y cómo. Por ejemplo, va al sitio web de DATAVERSITY a la 1:43 p. m. para leer algunas publicaciones de blog. Cuando accede a dataversity.net, la solicitud HTTP se registra en el sistema. Comienza a buscar una publicación de blog y va a una publicación de Gobierno de datos, donde pasa 17 minutos leyendo esa publicación y luego cierra la pestaña a las 2:00 p.m.
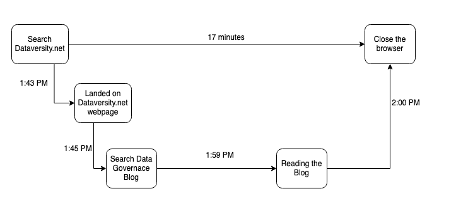
También se realizarán otras llamadas al sistema de red para la captura de paquetes de red. Las herramientas de observabilidad recopilan todos los tramos y los unifican en un rastro o rastros, lo que le permite ver el camino que formó durante su ciclo de vida. Si tiene un problema como la latencia de la red o un defecto del sistema, ahora es más fácil diseccionar (pelar la cebolla) y depurar el problema (error en qué capa).
Ahora, en un entorno distribuido grande, cuando sus aplicaciones reciben millones de solicitudes, los datos de seguimiento crecen en gran volumen. Recopilar y analizar estos rastros es costoso para el consumo de almacenamiento y la transferencia de datos. Entonces, para ahorrar costos, se muestrean los datos de seguimiento, porque en la mayoría de los casos, los equipos de ingeniería solo necesitan algunas de las piezas para investigar qué salió mal o cuál es el patrón de error.
Con ese pequeño ejemplo, entendemos que obtenemos conocimientos mucho más profundos sobre nuestros sistemas. Entonces, considerando una escala mayor de sistemas, los equipos de ingeniería pueden capturar y trabajar en los datos de muestra para mejorar la estructura actual del sistema, aplicar o retirar nuevos componentes, agregar otra capa de seguridad, eliminar cuellos de botella, etc.
¿Deberían las organizaciones elegir la observabilidad?
Todos debemos entender que los objetivos finales son una mejor experiencia de usuario y una mayor satisfacción del usuario. Y el camino para lograr estos objetivos se puede facilitar con un marco de observabilidad automatizado y proactivo. Establecer una cultura de optimización y mejora continua se considera el enfoque empresarial y de liderazgo óptimo.
En esta era de transformación digital, la observabilidad se ha vuelto imprescindible para que una empresa tenga éxito en su viaje digital. Al proporcionarle rastros perspicaces, la observabilidad también lo maniobra para que esté informado por los datos en lugar de solo impulsado por los datos.
Conclusión
Aunque hemos usado los términos monitoreo y observabilidad indistintamente, hemos visto que mientras el monitoreo lo ayuda con información sobre la salud del sistema y los eventos que ocurren en él, la observabilidad le facilita hacer inferencias basadas en evidencia recopilada de capas más profundas de un final. entorno final.
La observabilidad es y también puede ser percibida como un componente del marco de Data Governance. En esta generación, donde el volumen de datos en constante aumento reside en una red de hardware básico, es vital mantener las arquitecturas lo más simples posible. Y, evidentemente, se convierte en una tarea imposible gestionar el medio ambiente en el futuro. Por lo tanto, implementar políticas y reglas de gobierno apropiadas y automatizadas para mantener su gran malla de sistemas, canalizaciones y datos ordenados llama a la acción más temprano que tarde.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.dataversity.net/observability-traceability-for-distributed-systems/
- 1
- 11
- a
- Poder
- Sobre
- Conforme
- Lograr
- el logro de
- la columna Acción
- Adicionales
- Información adicional
- adoptar
- adoptado
- Adopción
- adviento
- Todos
- permite
- hacerlo
- analizar
- el análisis de
- y
- Otra
- https://www.youtube.com/watch?v=xB-eutXNUMXJtA&feature=youtu.be
- Aplicación
- aplicaciones
- Aplicá
- enfoque
- adecuado
- arquitectura
- atributos
- autenticar
- Confirmación de Viaje
- evitar
- basado
- Básicamente
- porque
- a las que has recomendado
- se convierte en
- comenzó
- MEJOR
- mejores
- Big
- Big Data
- Blog
- Entradas De Blog
- cuellos de botella
- llamar al
- Calls
- capturar
- cases
- centralizado
- el cambio
- Cambios
- Elige
- Cerrar
- recoger
- El cobro
- mercancía
- completar
- integraciones
- componente
- componentes
- concepto
- Protocolo de Tratamiento
- confundido
- considerado
- en vista de
- consumo
- contexto
- continuo
- control
- Precio
- podría
- CPU
- Cultura
- Current
- cliente
- datos
- basada en datos
- bases de datos
- VERSIDAD DE DATOS
- día a día
- Días
- década
- Descentralizado
- decisiones
- profundo
- más profundo
- se define
- describir
- destino
- detalles
- HIZO
- una experiencia diferente
- digital
- Transformación Digital
- distribuidos
- sistemas distribuidos
- No
- DE INSCRIPCIÓN
- durante
- comercio electrónico
- más fácil
- integrado
- que abarca
- permitiendo
- de extremo a extremo
- Ingeniería
- Entorno
- error
- Errores
- el establecimiento
- etc.
- Incluso
- Eventos
- NUNCA
- siempre creciente
- todo
- evidencia sólida
- evolución
- ejemplo
- costoso
- experience
- externo
- facilita
- Flujos
- formado
- Marco conceptual
- marcos
- en
- generación de AHSS
- obtener
- Go
- Goals
- gobierno
- mayor
- crece
- pasó
- En Curso
- Materiales
- Salud
- ayuda
- ayuda
- historia
- Golpear
- esperanza
- HOT
- Cómo
- Como Hacer
- Sin embargo
- HTML
- HTTPS
- enorme
- imágenes
- implementación
- importante
- imposible
- mejorar
- es la mejora continua
- in
- información
- informó
- Insights
- interno
- investigar
- invoca
- cuestiones
- IT
- Gestión de las TI
- Guardar
- especialistas
- paisaje
- large
- mayores
- Estado latente
- .
- ponedoras
- Liderazgo
- aprendizaje
- lentes
- Apalancamiento
- ciclo de vida
- Limitada
- línea
- para vivir
- carga
- Largo
- Lote
- hecho
- para lograr
- HACE
- Realizar
- gestionan
- Management
- administrar
- muchos
- Mercado
- matemático
- max-ancho
- medir
- Salud Cerebral
- Métrica
- microservicios
- millones
- minutos
- monitoreo
- Monolítico
- MEJOR DE TU
- movimiento
- emocionante
- múltiples
- Must-Have
- Naturaleza
- necesario
- ¿ Necesita ayuda
- red
- del sistema,
- sistema de redes
- Nuevo
- ONE
- Inteligente
- operativos.
- Operaciones
- óptimo
- optimización
- para las fiestas.
- Otro
- total
- EL DESARROLLADOR
- Papel
- camino
- Patrón de Costura
- pago
- percibidas
- actuación
- realizar
- período
- piezas
- plataforma
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- Jugar
- políticas
- pobre
- posible
- Publicación
- Artículos
- Proactiva
- Problema
- Producto
- Progreso
- proporcionar
- proporciona un
- proporcionando
- publicado
- XNUMX% automáticos
- Preguntas
- más bien
- Leer
- Reading
- recepción
- recibe
- fiabilidad
- remove
- representado
- solicita
- solicitudes
- requiere
- resiliencia y se la estamos enseñando a nuestro hijos e hijas.
- límite
- resultado
- Subir
- techo
- reglas
- satisfacción
- Guardar
- Escala
- la ampliación
- Buscar
- búsqueda
- Segundo
- EN LINEA
- Servicios
- Varios
- tienes
- Shows
- sencillos
- soltero
- lento
- chica
- So
- Software
- RESOLVER
- algo
- Pronto
- Aislamiento de Sonido
- Fuente
- se extiende
- soluciones y
- pasar
- montón
- Etapa
- comienzo
- fundó
- Estado
- Zonas
- se quedó
- Sin embargo
- detenido
- STORAGE
- Historia
- estructura
- exitosos
- te
- Todas las funciones a su disposición
- ¡Prepárate!
- toma
- Tarea
- equipos
- Técnico
- términos
- El
- la información
- La Fuente
- su
- de este modo
- Tres
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- a lo largo de
- equipo
- calendario
- a
- hoy
- tema
- rastrear
- Trazabilidad
- Rastreo
- Seguimiento
- transferir
- paraguas
- bajo
- subyacente
- entender
- actualización
- Uso
- Usuario
- experiencia como usuario
- generalmente
- Valioso
- diversos
- Videos
- la visibilidad
- vital
- volumen
- esperar
- Esperando
- Página web
- ¿
- Que es
- que
- mientras
- seguirá
- dentro de
- Actividades:
- Empleados
- funciona
- mundo
- se
- Mal
- tú
- zephyrnet











