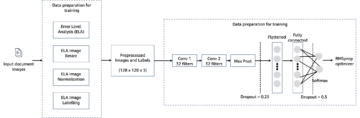
amazona kendra es un servicio de búsqueda inteligente fácil de usar que le permite integrar capacidades de búsqueda con sus aplicaciones para que los usuarios puedan encontrar información almacenada en fuentes de datos como Servicio de almacenamiento simple de Amazon , OneDrive y Google Drive; aplicaciones como SalesForce, SharePoint y Service Now; y bases de datos relacionales como Servicio de base de datos relacional de Amazon (Amazon RDS). El uso de conectores de Amazon Kendra le permite sincronizar datos de varios repositorios de contenido con su índice de Amazon Kendra. Cuando los usuarios finales hacen preguntas en lenguaje natural, Amazon Kendra utiliza algoritmos de aprendizaje automático (ML) para comprender el contexto y brindar las respuestas más relevantes.
El conector S3 de Amazon Kendra admite la indexación de documentos y sus metadatos asociados almacenados en un depósito S3. A menudo, desea asegurarse de que las aplicaciones que se ejecutan dentro de una VPC solo tengan acceso a depósitos S3 específicos y, en muchos casos, la conexión no debe atravesar Internet para llegar a los puntos finales públicos. Muchos clientes, sin embargo, poseen varios cubos S3, algunos de los cuales son accesibles por Puntos de enlace de la VPC para Amazon S3. En esta publicación, describimos cómo usar el conector Amazon Kendra S3 actualizado con compatibilidad con VPC para usar puntos finales de VPC.
Esta publicación proporciona los pasos para ayudarlo a crear un motor de búsqueda empresarial en AWS utilizando Amazon Kendra conectando documentos almacenados en un depósito S3 al que solo se puede acceder desde una VPC. Para más información, ver mejora de la búsqueda empresarial con Amazon Kendra. La publicación también demuestra cómo configurar su conector para Amazon S3 y configurar cómo su índice se sincroniza con su fuente de datos cuando cambia el contenido de su fuente de datos.
Resumen de la solución
Hay tres mejoras principales en el Conector Amazon Kendra S3 :
- Soporte de VPC – El conector ahora admite el uso de su Nube privada virtual de Amazon (Amazon VPC) redes. Ahora puede conectarse de forma segura a Amazon S3 usando Puntos de enlace de la VPC para Amazon S3 especificando la conexión VPC, la subred y los grupos de seguridad.
- Dos modos de sincronización: Cuando programa la sincronización de una fuente de datos en Amazon S3 con un índice de Amazon Kendra, ahora puede elegir ejecutar en modo de sincronización completa o en modo de sincronización de documentos nuevos, modificados y eliminados. En el modo de sincronización completa, cada vez que se ejecuta la sincronización, se analizan los objetos de todas las carpetas de la ruta raíz que se configuró para rastrear y se vuelven a ingerir todos los documentos. La actualización completa le permite restablecer el índice sin necesidad de eliminar y crear una nueva fuente de datos. En el modo de sincronización de documentos nuevos, modificados y eliminados, cada vez que se ejecuta el trabajo de sincronización, solo procesa los objetos que se agregaron, modificaron o eliminaron desde el último rastreo. Los rastreos incrementales pueden reducir el tiempo de ejecución y el costo cuando se usan con conjuntos de datos que agregan nuevos objetos a las fuentes de datos existentes de forma regular.
- Patrones de inclusión y exclusión adicionales para documentos: además de los prefijos, estamos introduciendo patrones para la inclusión o exclusión de documentos de su índice. Dos tipos de patrones admitidos son los tipos de archivo o glob de estilo Unix. Ahora puede agregar un patrón de expresión regular para incluir carpetas específicas o excluir carpetas, tipos de archivos o archivos específicos de su fuente de datos. Esto puede ser útil para repositorios de datos compartidos que contienen contenido perteneciente a diferentes categorías, clasificaciones y tipos de archivos.
Requisitos previos
Para este tutorial, debe tener los siguientes requisitos previos:
Crea y configura tu repositorio de documentos
Antes de poder crear un índice en Amazon Kendra, debe cargar documentos en un bucket S3. Esta sección contiene instrucciones para crear un depósito S3, obtener los archivos y cargarlos en el depósito. Después de completar todos los pasos de esta sección, tiene una fuente de datos que Amazon Kendra puede usar.
- En Consola de administración de AWS, en la lista Región, elija EE.UU. Este (Norte de Virginia) o cualquier Región de su elección que Amazon Kendra está disponible en.
- Elige Servicios.
- under Almacenamiento, escoger S3.
- En la consola de Amazon S3, elija Crear cubeta.
- under Configuración general, provee la siguiente informacion:
- Para el nombre del depósito, entrar
kendrapost-{your account id}. - Para Región, elija la misma Región que usa para implementar su índice de Amazon Kendra (esta publicación usa
us-east-1). - under ajustes del cubo, para Bloquear acceso público, deje todo con los valores predeterminados.
- Para el nombre del depósito, entrar
- under Configuración avanzada, deje todo con los valores predeterminados.
- Elige Crear cubeta.
- Descargar AWS_Whitepapers.zip y descomprimir los archivos.
- En la consola de Amazon S3, seleccione el depósito que acaba de crear y elija Subir.
- Sube las carpetas
Best Practices,Databases,GeneralyMachine Learningdel archivo descomprimido.
Dentro de su cubo, ahora debería ver cuatro carpetas.
Agregar una fuente de datos
A fuente de datos es una ubicación que almacena los documentos para su indexación. Puede sincronizar las fuentes de datos automáticamente con un índice de Amazon Kendra para asegurarse de que las búsquedas reflejen correctamente documentos nuevos, actualizados o eliminados en los repositorios de fuentes.
Después de completar todos los pasos de esta sección, tendrá una fuente de datos vinculada a Amazon Kendra. Para más información, ver Agregar documentos desde una fuente de datos.
Antes de continuar, asegúrese de que la creación del índice esté completa y que el índice se muestre como Active. Para más información, consulte la Creación de un índice.
- En la consola de Amazon Kendra, vaya a su índice (para esta publicación,
kendra-blog-index). - En
kendra-blog-indexpágina, elige Agregar orígenes de datos.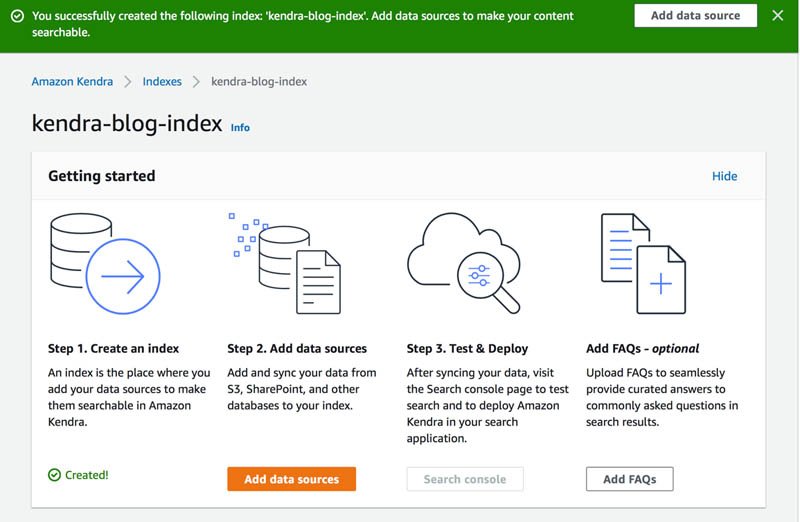
- En Amazon S3, elija Agregar conector.

Para obtener más información sobre las diferentes fuentes de datos que admite Amazon Kendra, consulte Agregar documentos desde una fuente de datos.
- En Especificar los detalles de la fuente de datos sección, para Nombre de fuente de datos, introduzca
aws_white_paper. - Descripción, introduzca
AWS White Paper documentation. - Elige Siguiente.
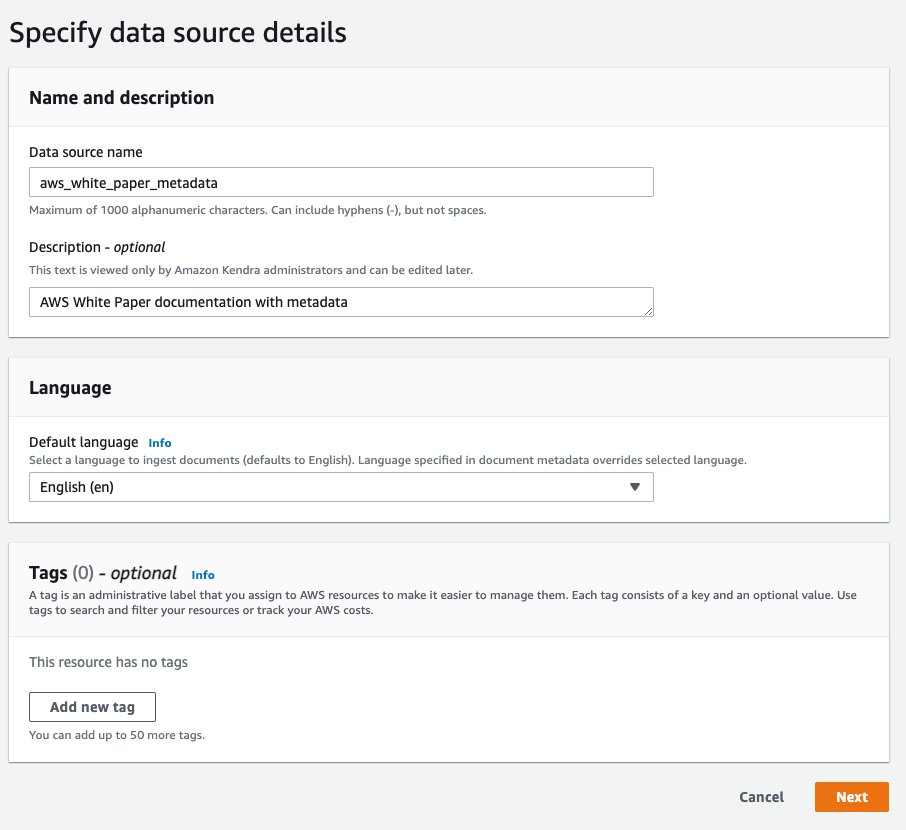
Ahora creas un Gestión de identidades y accesos de AWS (IAM) rol para Amazon Kendra.
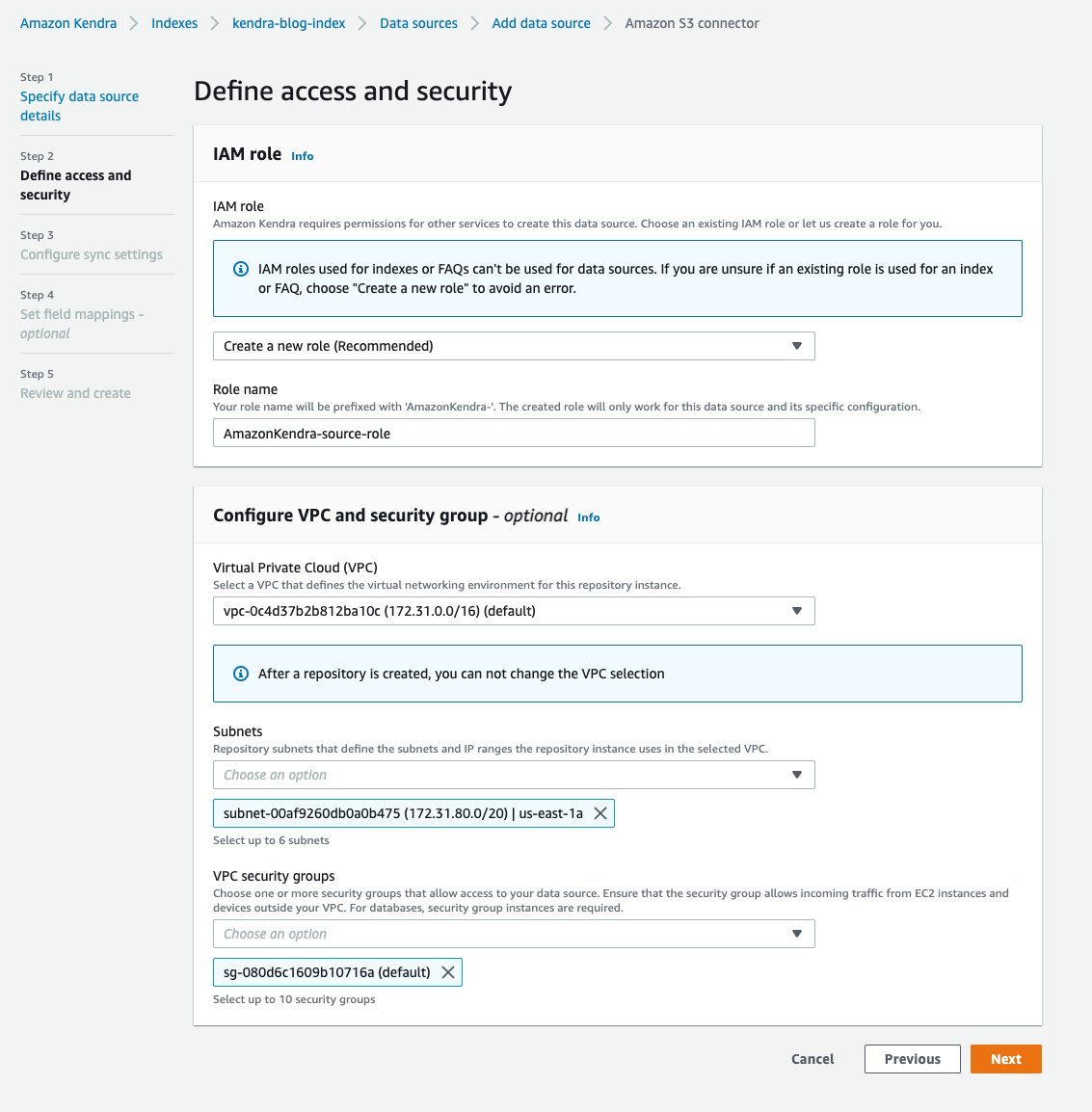
- En Definir acceso y seguridad. página, para Rol de IAM sección, elija Crear un nuevo rol.
- Para Nombre de rol, ingrese
source-role(el nombre de su rol tiene el prefijoAmazonKendra-). - En Configurar VPC y seguridad sección, elige tu VPC, y entra tu Subredes y grupos de seguridad de VPC.
Para obtener más información sobre cómo conectar su Amazon Kendra a su Amazon Virtual Private Cloud, consulte Configuración de Amazon Kendra para usar una VPC.
- Elige Siguiente.
- En Configurar ajustes de sincronización página, para Ingrese la ubicación de la fuente de datos, ingrese el bucket S3 que creó:
kendrapost-{your account id}. - Abandonar Ubicación de la carpeta del prefijo de los archivos de metadatos blanco.
Por defecto, los archivos de metadatos se almacenan en el mismo directorio que los documentos. Si desea colocar estos archivos en una carpeta diferente, puede agregar un prefijo. Para más información, ver Metadatos de documentos de Amazon S3.
- Seleccionar clave de descifrado, déjalo sin seleccionar.
- Configuración adicional, puede agregar un patrón para incluir o excluir ciertas carpetas o archivos. Para esta publicación, mantenga los valores predeterminados.
- Modo de sincronización escoger Sincronización de documentos nuevos, modificados o eliminados.
- Frecuencia, escoger Ejecutar bajo demanda.
Este paso define la frecuencia con la que la fuente de datos se sincroniza con el índice de Amazon Kendra.
- Elige Siguiente.

- En Establecer asignaciones de campo página, mantenga los valores predeterminados.
- Elige Siguiente.

- En Revisar y crear página, elige Añadir fuente de datos.
- Vuelva a su índice de Kendra.
- Escoge tu Fuente de datos, A continuación, elija Sincronizar ahora para sincronizar los documentos con el índice de Amazon Kendra.

La duración de este proceso depende de la cantidad de documentos que indexe. Para este caso de uso, puede tardar 15 minutos, después de lo cual debería ver un mensaje que indica que la sincronización se realizó correctamente. En la sección Historial de ejecución de sincronización, puede ver que se sincronizaron 40 documentos.

Su índice de Amazon Kendra ahora está listo para consultas en lenguaje natural. Cuando busca en su índice, Amazon Kendra utiliza todos los datos y metadatos proporcionados para devolver las respuestas más precisas a su consulta de búsqueda. En la consola de Amazon Kendra, elija Buscar contenido indexado. En el campo de consulta, comience con una consulta como "¿Qué servicio de AWS tiene 11 nueves de durabilidad?"
Para obtener más información sobre cómo consultar el índice, consulte Consultar un índice
Sincronice los cambios de la fuente de datos para buscar en el índice
Su fuente de datos está configurada para sincronizar cualquier dato nuevo, modificado o eliminado. Antes de poder sincronizar su fuente de datos de forma incremental con un índice en Amazon Kendra, debe cargar nuevos documentos en un depósito S3.
- En la consola de Amazon S3, seleccione el depósito que acaba de crear y elija Subir.
- Sube las carpetas
SecurityyWell_Architecteddel archivo descomprimido.
Ahora puede sincronizar los nuevos documentos agregados al depósito S3:
- En la consola de Amazon Kendra, elija Fuentes de datos y luego seleccione su fuente de datos S3.
- Elige Sincronizar ahora.
La duración de este proceso depende de la cantidad de documentos que indexe. Para este caso de uso, puede llevar 15 minutos, después de lo cual debería ver un mensaje que indica que la sincronización se realizó correctamente.
En Sincronizar historial de ejecución sección, puede ver que 20 documentos fueron sincronizados.

Vuelva a indexar la fuente de datos
En un escenario donde la fuente de datos tiene información obsoleta, ahora puede volver a indexar la fuente de datos sin tener que eliminar y crear una nueva fuente de datos. Para modificar el modo de sincronización y volver a indexar la fuente de datos, complete los siguientes pasos:
- En la consola de Amazon Kendra, elija Fuentes de datos y luego seleccione su fuente de datos S3.
- En Acciones menú, seleccione Editar.
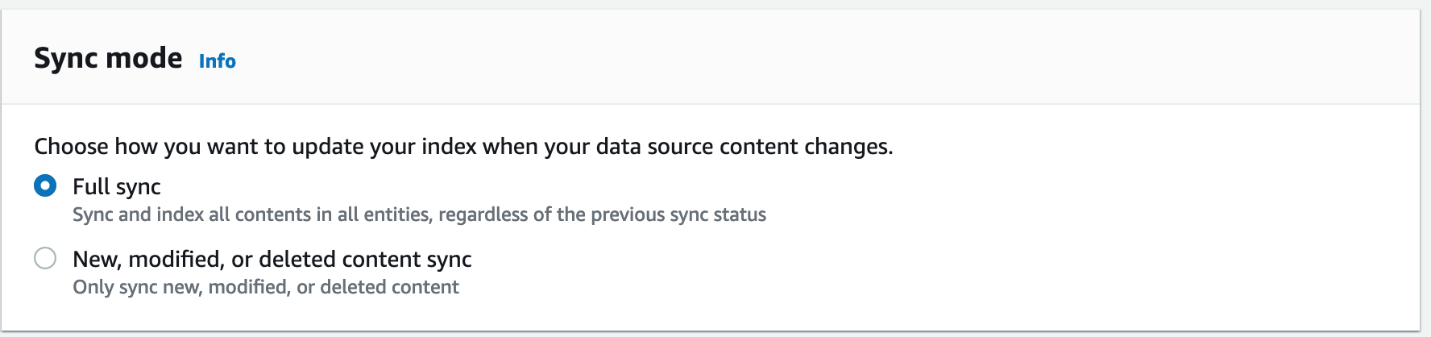
- Elige Siguiente para pasar a Paso 3: configure la página de configuración de sincronización.
- Para el modo de sincronización, seleccione Sincronización completa.
- Frecuencia, escoger Ejecutar bajo demanda.
- Elige Siguiente.
- En Establecer asignaciones de campo página, mantenga los valores predeterminados.
- Elige Siguiente.
- En Revisar y crear página, elige Actualizar.
Ahora puede sincronizar los nuevos documentos agregados al depósito S3.
- En la consola de Amazon Kendra, elija Fuentes de datos y luego seleccione su fuente de datos S3.
- Elige Sincronizar ahora.
En Sincronizar historial de ejecución sección, puede ver que todos los documentos se sincronizaron independientemente del estado de sincronización anterior en la columna modificada.

Limpiar
Para evitar incurrir en cargos futuros y eliminar las funciones y políticas no utilizadas, elimine los recursos que creó:
- En el índice de Amazon Kendra, elija Índices en el panel de navegación.
- Seleccione el índice que creó y en el Acciones menú, seleccione Borrar.
- Para confirmar la eliminación, ingrese Eliminar cuando se le solicite y elija Borrar.
Espere hasta que reciba el mensaje de confirmación; El proceso puede tomar hasta 15 minutos.
- En la consola de Amazon S3, eliminar el cubo S3.
- En la consola de IAM, elimine los roles de IAM correspondientes.
Conclusión
En esta publicación, aprendió a usar Amazon Kendra para implementar un servicio de búsqueda empresarial mediante una conexión segura a Amazon S3 que no requiere una puerta de enlace de Internet ni un dispositivo de traducción de direcciones de red (NAT). Puede habilitar sincronizaciones más rápidas para sus documentos usando el modo de sincronización.
Hay muchas características adicionales que no cubrimos. Por ejemplo:
- Puede habilitar el control de acceso basado en el usuario para su índice de Amazon Kendra y restringir el acceso a los documentos según los controles de acceso que ya haya configurado.
- Puede asignar atributos de objetos a los atributos de índice de Amazon Kendra y habilitarlos para facetas, búsquedas y visualización en los resultados de búsqueda.
- Puede encontrar rápidamente información de páginas web (tablas HTML) utilizando la búsqueda tabular de Amazon Kendra
Para obtener más información sobre Amazon Kendra, consulte Guía para desarrolladores de Amazon Kendra.
Acerca de los autores
 maran chandrasekaran es Arquitecto de Soluciones Sénior en Amazon Web Services y trabaja con nuestros clientes empresariales. Fuera del trabajo, le encanta viajar.
maran chandrasekaran es Arquitecto de Soluciones Sénior en Amazon Web Services y trabaja con nuestros clientes empresariales. Fuera del trabajo, le encanta viajar.
 Arjun Agrawal es ingeniero de software en AWS y actualmente trabaja con un equipo de Amazon Kendra en un motor de búsqueda empresarial. Le apasionan las nuevas tecnologías y la resolución de problemas del mundo real. Fuera del trabajo, le encanta caminar y viajar.
Arjun Agrawal es ingeniero de software en AWS y actualmente trabaja con un equipo de Amazon Kendra en un motor de búsqueda empresarial. Le apasionan las nuevas tecnologías y la resolución de problemas del mundo real. Fuera del trabajo, le encanta caminar y viajar.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/search-for-answers-accurately-using-amazon-kendra-s3-connector-with-vpc-support/
- 10
- 100
- 11
- 7
- a
- Nuestra Empresa
- de la máquina
- accesible
- Mi Cuenta
- preciso
- precisamente
- a través de
- adicional
- adición
- Adicionales
- dirección
- Después
- algoritmos
- Todos
- permite
- ya haya utilizado
- Amazon
- amazona kendra
- RDS de Amazon
- Amazon Web Services
- y
- respuestas
- aplicaciones
- asociado
- atributos
- automáticamente
- Hoy Disponibles
- evitar
- AWS
- Atrás
- basado
- base
- antes
- capacidades
- case
- cases
- categoría
- a ciertos
- Cambios
- cargos
- manera?
- Elige
- clasificación
- Soluciones
- Columna
- completar
- completando
- Confirmar
- Contacto
- Conectándote
- conexión
- Consola
- contiene
- contenido
- contexto
- continuo
- control
- controles
- correctamente
- Correspondiente
- Cost
- Protectora
- Para crear
- creado
- creación
- En la actualidad
- Clientes
- datos
- Base de datos
- bases de datos
- conjuntos de datos
- Predeterminado
- Define
- demuestra
- depende
- desplegar
- describir
- Developer
- dispositivo
- una experiencia diferente
- Pantalla
- documento
- documentos
- No
- el lado de la transmisión
- durabilidad
- Este
- fácil de usar
- habilitar
- permite
- Motor
- ingeniero
- Participar
- Empresa
- clientes empresariales
- Búsqueda de empresas
- Éter (ETH)
- Cada
- todo
- ejemplo
- existente
- Caracteristicas
- campo
- Archive
- archivos
- Encuentre
- siguiendo
- Frecuencia
- en
- ser completados
- futuras
- puerta
- obtener
- Grupo
- es
- ayuda
- Caminata
- historia
- Cómo
- Como Hacer
- Sin embargo
- HTML
- HTTPS
- AMI
- Identidad
- mejoras
- in
- incluir
- inclusión
- índice
- información
- Instrucciones
- integrar
- De Operación
- Internet
- Presentamos
- desconsiderado
- IT
- Trabajos
- Guardar
- idioma
- Apellido
- APRENDE:
- aprendido
- aprendizaje
- Abandonar
- vinculado
- Lista
- carga
- Ubicación
- máquina
- máquina de aprendizaje
- Inicio
- para lograr
- Management
- muchos
- mapa
- Menú
- mensaje
- metadatos
- minutos
- ML
- Moda
- los modos
- modificado
- modificar
- más,
- MEJOR DE TU
- movimiento
- múltiples
- nombre
- Natural
- Lenguaje natural
- Navegar
- Navegación
- ¿ Necesita ayuda
- del sistema,
- telecomunicaciones
- Nuevo
- número
- objeto
- objetos
- onedrive
- afuera
- EL DESARROLLADOR
- cristal
- Papel
- apasionado
- camino
- Patrón de Costura
- .
- Colocar
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- políticas
- Publicación
- requisitos previos
- anterior
- privada
- problemas
- en costes
- proporcionar
- previsto
- proporciona un
- público
- Preguntas
- más rápido
- con rapidez
- en comunicarse
- ready
- mundo real
- reducir
- reflejar
- región
- regular
- exigir
- Recursos
- restringir
- Resultados
- volvemos
- Función
- También soy miembro del cuerpo docente de World Extreme Medicine (WEM) y embajadora europea de igualdad para The Transformational Travel Council (TTC). En mi tiempo libre, soy una incansable aventurera, escaladora, patrona de día, buceadora y defensora de la igualdad de género en el deporte y la aventura. En XNUMX, fundé Almas Libres, una ONG nacida para involucrar, educar y empoderar a mujeres y niñas a través del deporte urbano, la cultura y la tecnología.
- raíz
- Ejecutar
- correr
- fuerza de ventas
- mismo
- guión
- programa
- Buscar
- motor de búsqueda
- Sección
- seguro
- segura
- EN LINEA
- mayor
- de coches
- Servicios
- set
- ajustes
- compartido
- sharepoint
- tienes
- Shows
- sencillos
- desde
- So
- Software
- Ingeniero de Software
- Soluciones
- Resolver
- algo
- Fuente
- Fuentes
- soluciones y
- comienzo
- Estado
- paso
- pasos
- STORAGE
- almacenados
- tiendas
- papa
- subred
- subredes
- exitosos
- tal
- SOPORTE
- Soportado
- soportes
- sincronización
- ¡Prepárate!
- equipo
- Tecnología
- El
- La Fuente
- su
- Tres
- equipo
- a
- Traducción
- viajes
- tipos
- bajo
- entender
- UNIX
- no usado
- actualizado
- us
- utilizan el
- caso de uso
- usuarios
- Valores
- Virginia
- Virtual
- tutorial
- web
- servicios web
- que
- complejo de salvador blanco
- detalles de la moneda
- dentro de
- sin
- Actividades:
- trabajando
- tú
- zephyrnet
- Zip