Las organizaciones utilizan soluciones de creación de documentos colaborativos como Salesforce Sofismo para incrustar documentos colaborativos en tiempo real dentro de los registros de Salesforce. Quip es la plataforma de productividad de Salesforce que transforma la forma en que las empresas trabajan juntas, ofreciendo una colaboración moderna de forma segura y sencilla en cualquier dispositivo. Un repositorio de Quip captura conocimientos organizacionales invaluables en forma de documentos y flujos de trabajo colaborativos. Sin embargo, encontrar este conocimiento organizativo de forma fácil y segura junto con otros repositorios de documentos, como Box o Servicio de almacenamiento simple de Amazon (Amazon S3), puede ser un desafío. Además, la naturaleza conversacional de los flujos de trabajo colaborativos hace que el enfoque tradicional basado en palabras clave para buscar sea ineficaz debido a que tiene información fragmentada y dispersa en varios lugares.
Nos complace anunciar que ahora puede utilizar el amazona kendra conector para Quip para buscar mensajes y documentos en su repositorio de Quip. En esta publicación, le mostramos cómo encontrar la información que necesita en su repositorio de Quip mediante la función de búsqueda inteligente de Amazon Kendra, con tecnología de aprendizaje automático.
Resumen de la solución
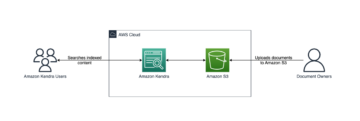
Con Amazon Kendra, puede configurar múltiples fuentes de datos para proporcionar un lugar central para buscar en su repositorio de documentos. Para nuestra solución, demostramos cómo configurar un repositorio de Quip como fuente de datos de un índice de búsqueda mediante el conector de Amazon Kendra para Quip.
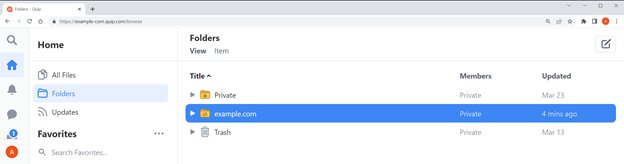
La siguiente captura de pantalla muestra un repositorio de Quip de ejemplo.

El espacio de trabajo de este ejemplo tiene una carpeta privada que no se comparte. Esa carpeta tiene una subcarpeta que se usa para guardar los recibos de gastos. Otra carpeta llamada ejemplo.com se comparte con otros y se usa para colaborar con el equipo. Esta carpeta tiene cinco subcarpetas que contienen documentación para el desarrollo.
Para configurar el conector de Quip, primero anotamos el nombre de dominio, los ID de carpeta y el token de acceso del repositorio de Quip. Luego, simplemente creamos el índice de Amazon Kendra y agregamos Quip como fuente de datos.
Requisitos previos
Para comenzar a usar el conector de Quip para Amazon Kendra, debe tener un repositorio de Quip.
Recopilar información de Quip
Antes de configurar la fuente de datos de Quip, necesitamos algunos detalles sobre su repositorio. Reunámoslos por adelantado.
Nombre de dominio y certificado SSL
Averigüe el nombre de dominio. Por ejemplo, para la URL de Quip https://example-com.quip.com/browse, el nombre de dominio es quip. Dependiendo de cómo esté configurado el inicio de sesión único (SSO) en su organización, el nombre de dominio puede variar. Guarde este nombre de dominio para usarlo más tarde.
ID de carpeta
Las carpetas en Quip tienen una identificación única asociada a ellas. Necesitamos configurar el conector de Quip para acceder a las carpetas correctas proporcionando los ID de carpeta correctos. Para esta publicación, indexamos la carpeta example.com.
Para encontrar el ID de la carpeta, seleccione la carpeta. La URL cambia para mostrar el ID de la carpeta.

El ID de la carpeta en este caso es xj1vOyaCGB3u. Haga una lista de las ID de carpetas para escanear; usamos estos ID cuando configuramos el conector.
Token de acceso
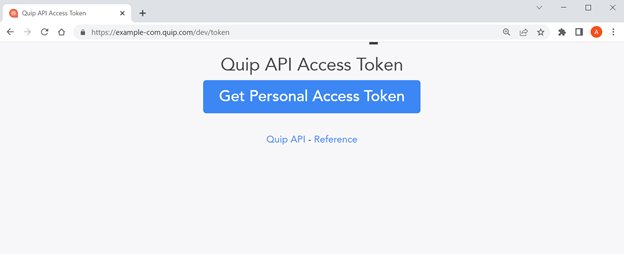
Inicie sesión en Quip y abra https://{subdomain.domain}/dev/token en un navegador web. En el siguiente ejemplo, navegamos a https://example-com.quip.com/dev/token. Entonces escoge Obtener token de acceso personal.
Copie el token para usarlo en un paso posterior.
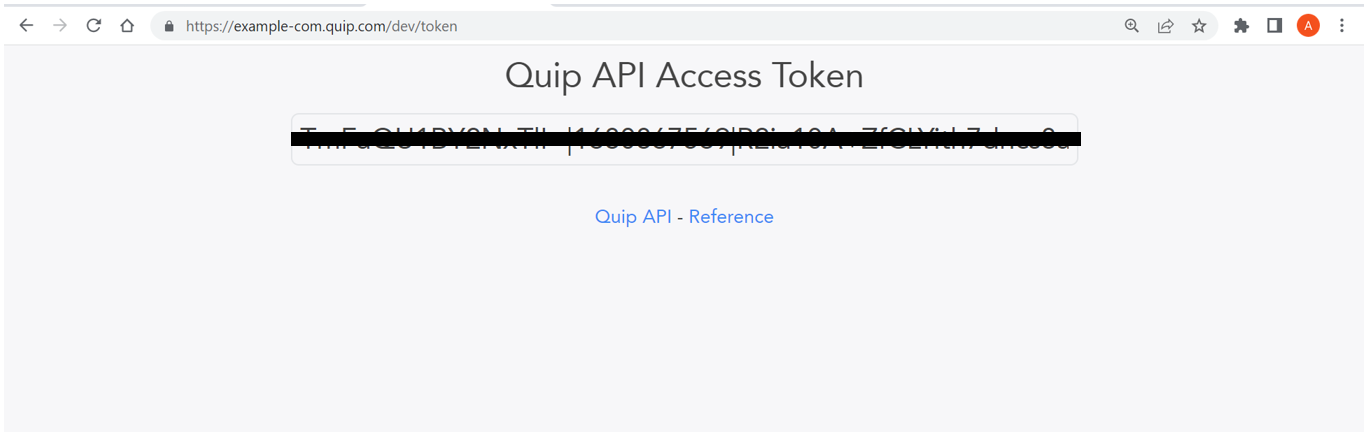
Ahora tenemos la información que necesitamos para configurar la fuente de datos.
Crear un índice de Amazon Kendra
Para configurar su índice de Amazon Kendra, complete los siguientes pasos:
- Inicia sesión en el Consola de administración de AWS y abra la consola de Amazon Kendra.
Si está utilizando Amazon Kendra por primera vez, debería ver la siguiente captura de pantalla.
- Elige Crea un índice.
- Nombre del índice, introduzca
my-quip-example-index. - Descripción, ingrese una descripción opcional.
- Rol de IAM, use un rol existente o cree uno nuevo.
- Elige Siguiente.

- under Configuraciones de control de acceso, seleccione No para que todo el contenido indexado esté disponible para todos los usuarios.
- Expansión de grupos de usuarios, seleccione Ninguna.
- Elige Siguiente.

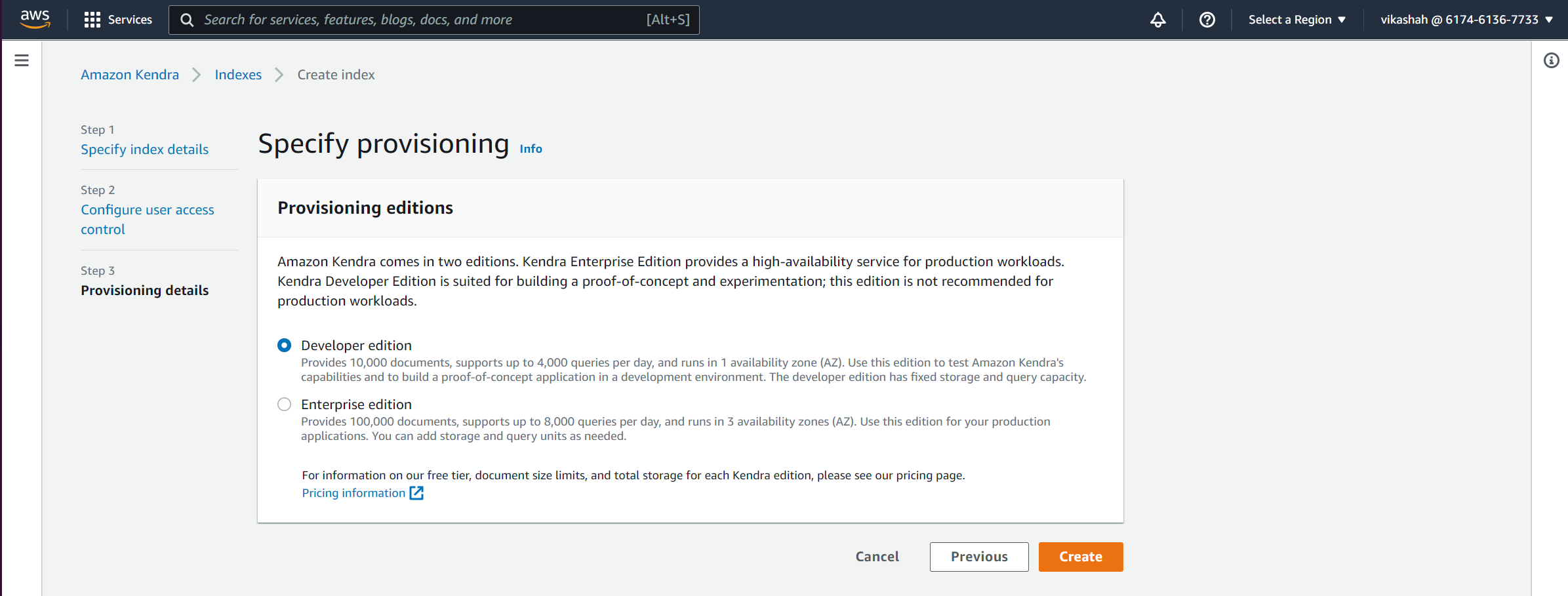
Ediciones de aprovisionamiento, puedes elegir entre dos opciones según el volumen del contenido y la frecuencia de acceso.
- Para esta publicación, seleccione Edición para desarrolladores.
- Elige Crear.
La creación de funciones tarda aproximadamente 30 segundos; la creación del índice puede tardar hasta 30 minutos. Cuando termine, puede ver su índice en la consola de Amazon Kendra.

Agregar Quip como fuente de datos
Ahora agreguemos Quip como fuente de datos al índice.
- En la consola de Amazon Kendra, en Gestión de datos en el panel de navegación, elija Fuentes de datos.
- Elige Agregar conector bajo Sofismo.

- Nombre de fuente de datos, introduzca
my-quip-data-source. - Descripción, ingrese una descripción opcional.
- Elige Siguiente.
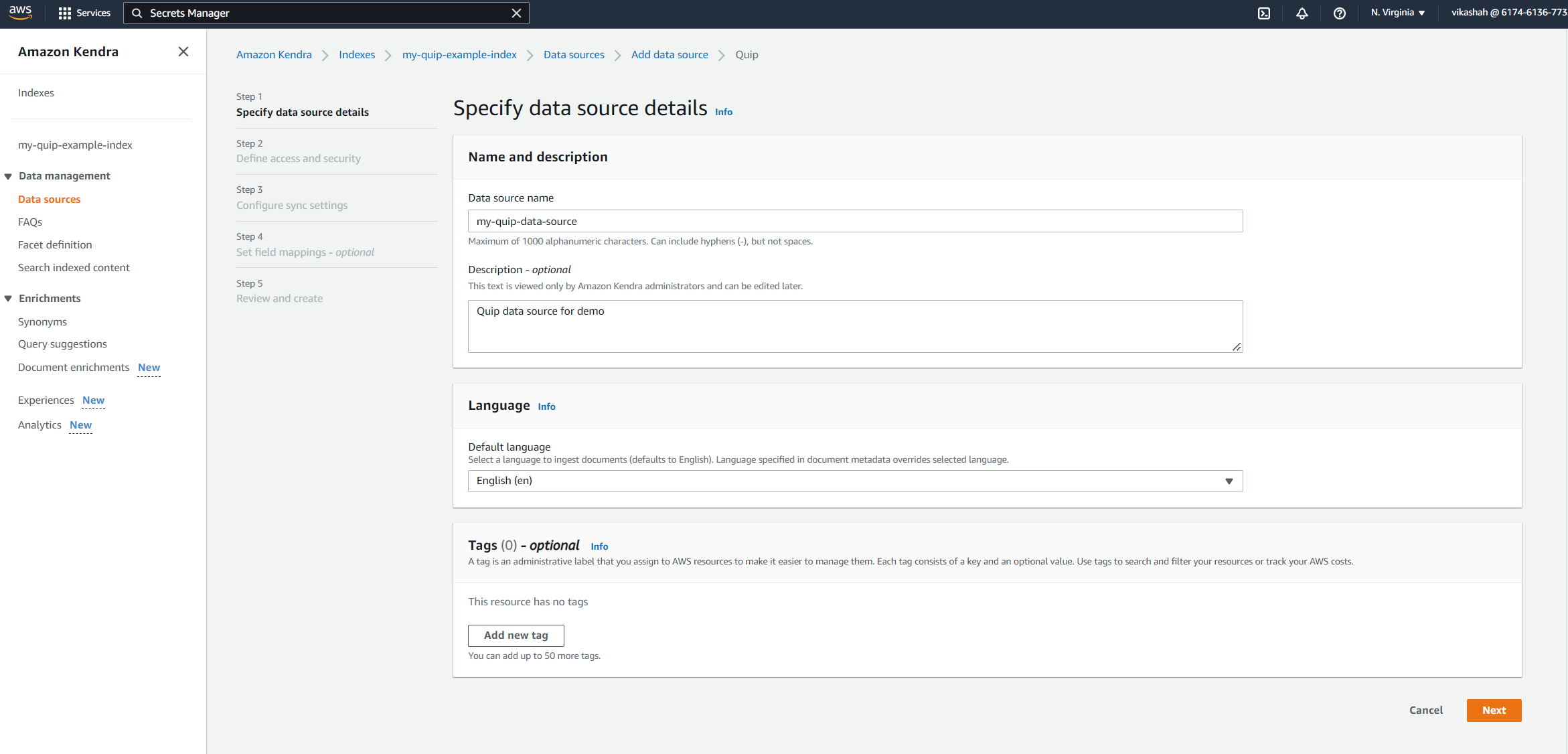
- Ingrese el nombre de dominio de Quip que guardó anteriormente.
- under Misterios, escoger Crear y agregar un nuevo secreto de Secrets Manager.
- Nombre secreto, ingrese el nombre de su secreto.
- token de broma, ingrese el token de acceso que guardó anteriormente.
- Elige Guardar y agregar secreto.

- under Rol de IAM, elige un rol o crea uno nuevo.
- Elige Siguiente.

- under Ámbito de sincronización, Para Agregar ID de carpeta para rastrear, ingrese los ID de carpeta que guardó anteriormente.
- under Programación de ejecución sincronizadapara Frecuencia, seleccione Ejecutar bajo demanda.
- Elige Siguiente.
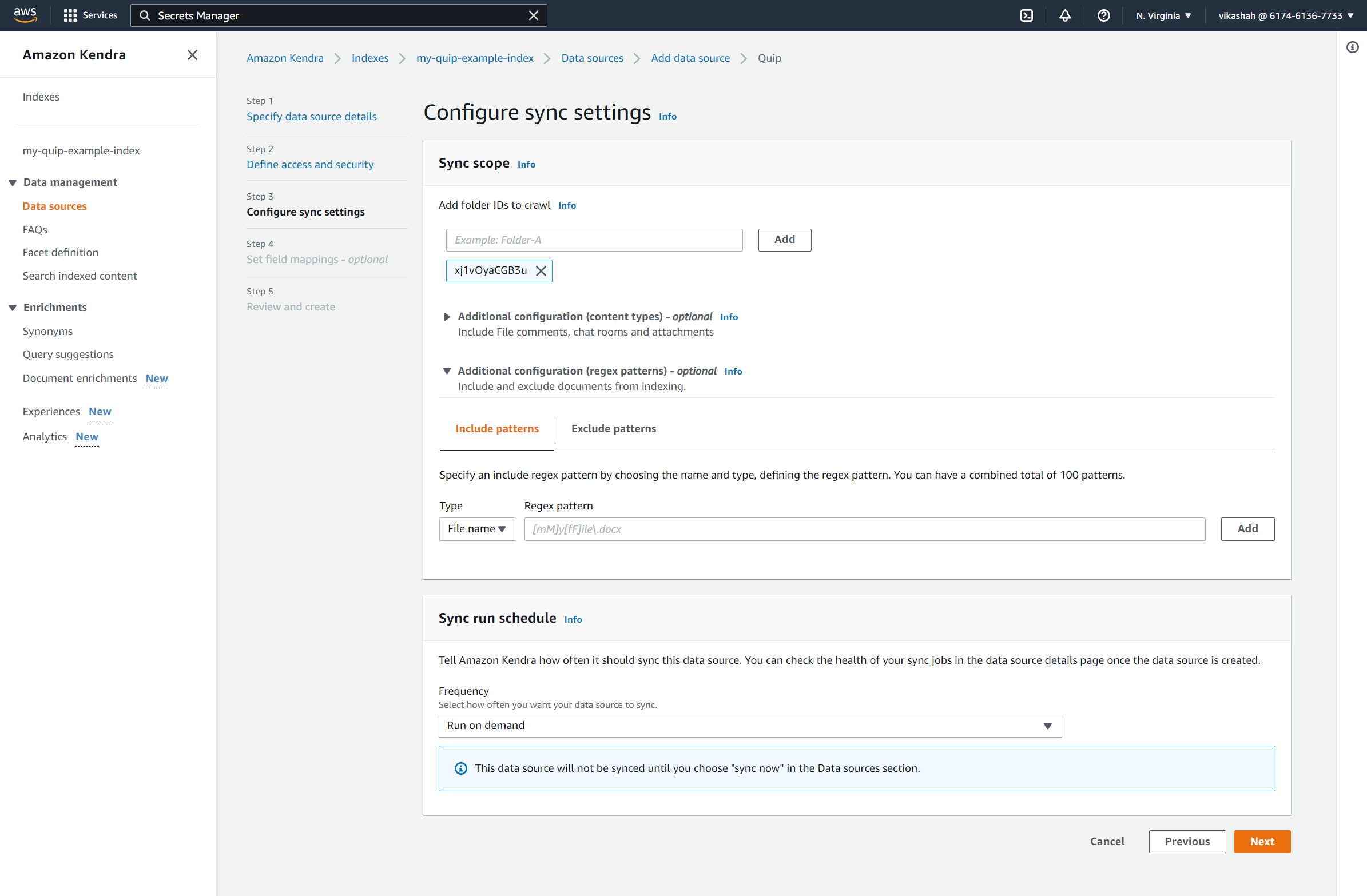
El conector de Quip le permite capturar campos adicionales como autores, categorías y nombres de carpetas (e incluso cambiar el nombre según sea necesario).
- Para esta publicación, no configuramos ninguna asignación de campo.
- Elige Siguiente.

- Confirme todas las opciones y agregue la fuente de datos.
Su fuente de datos estará lista en unos minutos.
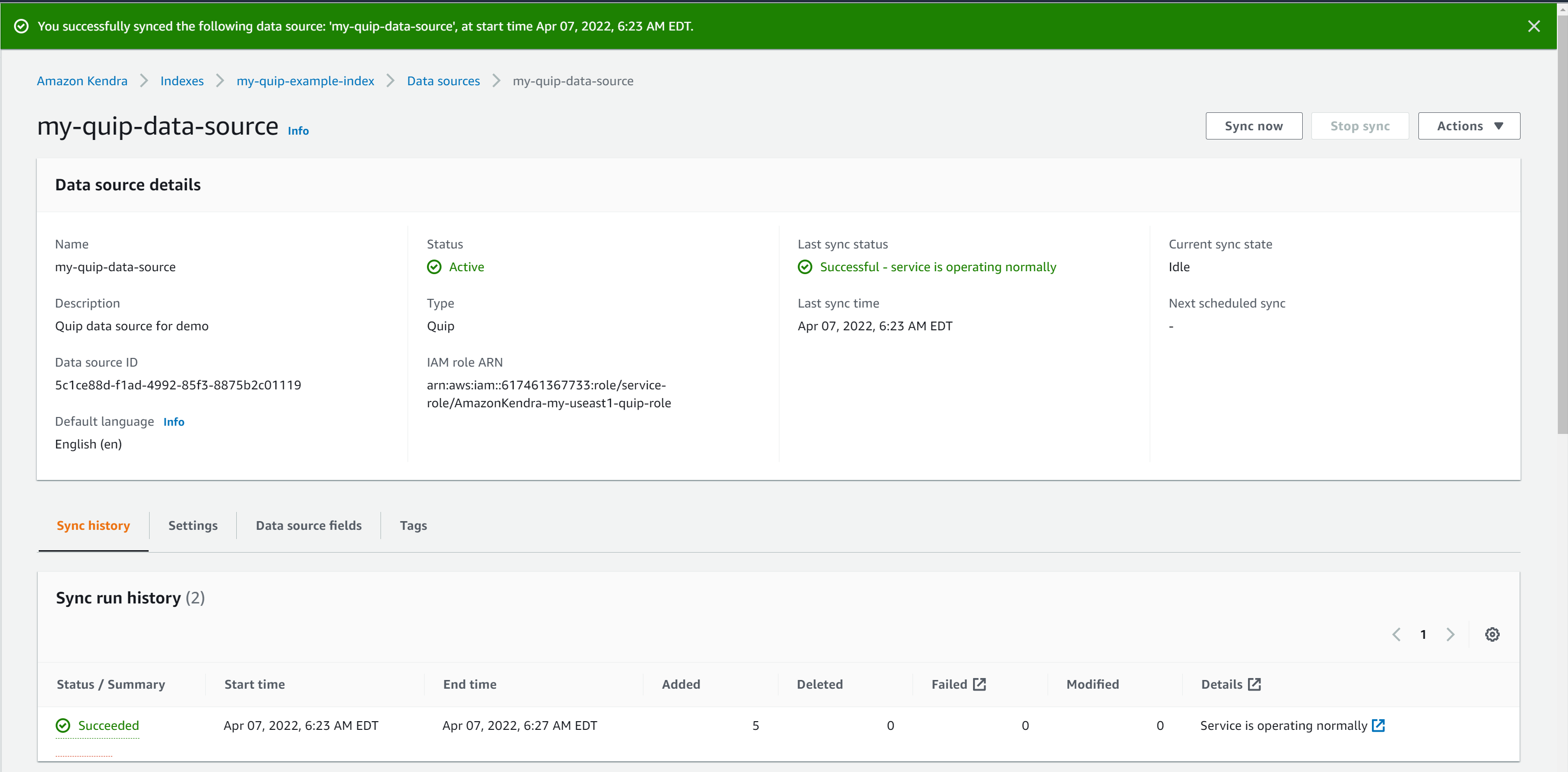
- Cuando su fuente de datos esté lista, elija Sincronizar ahora.

Según el tamaño de los datos en el repositorio de Quip, este proceso puede demorar entre unos minutos y algunas horas. La sincronización es un proceso de dos pasos. En primer lugar, se rastrean los documentos para determinar los que se van a indexar. Luego se indexan los documentos seleccionados. Algunos factores que afectan la velocidad de sincronización incluyen el rendimiento y la limitación del repositorio, el ancho de banda de la red y el tamaño de los documentos.
El estado de sincronización se muestra como exitoso cuando se completa la sincronización. Su repositorio de Quip ahora está conectado.
Ejecutar una búsqueda en Amazon Kendra
Probemos el conector ejecutando algunas búsquedas.
- En la consola de Amazon Kendra, en Gestión de datos en el panel de navegación, elija Buscar contenido indexado.
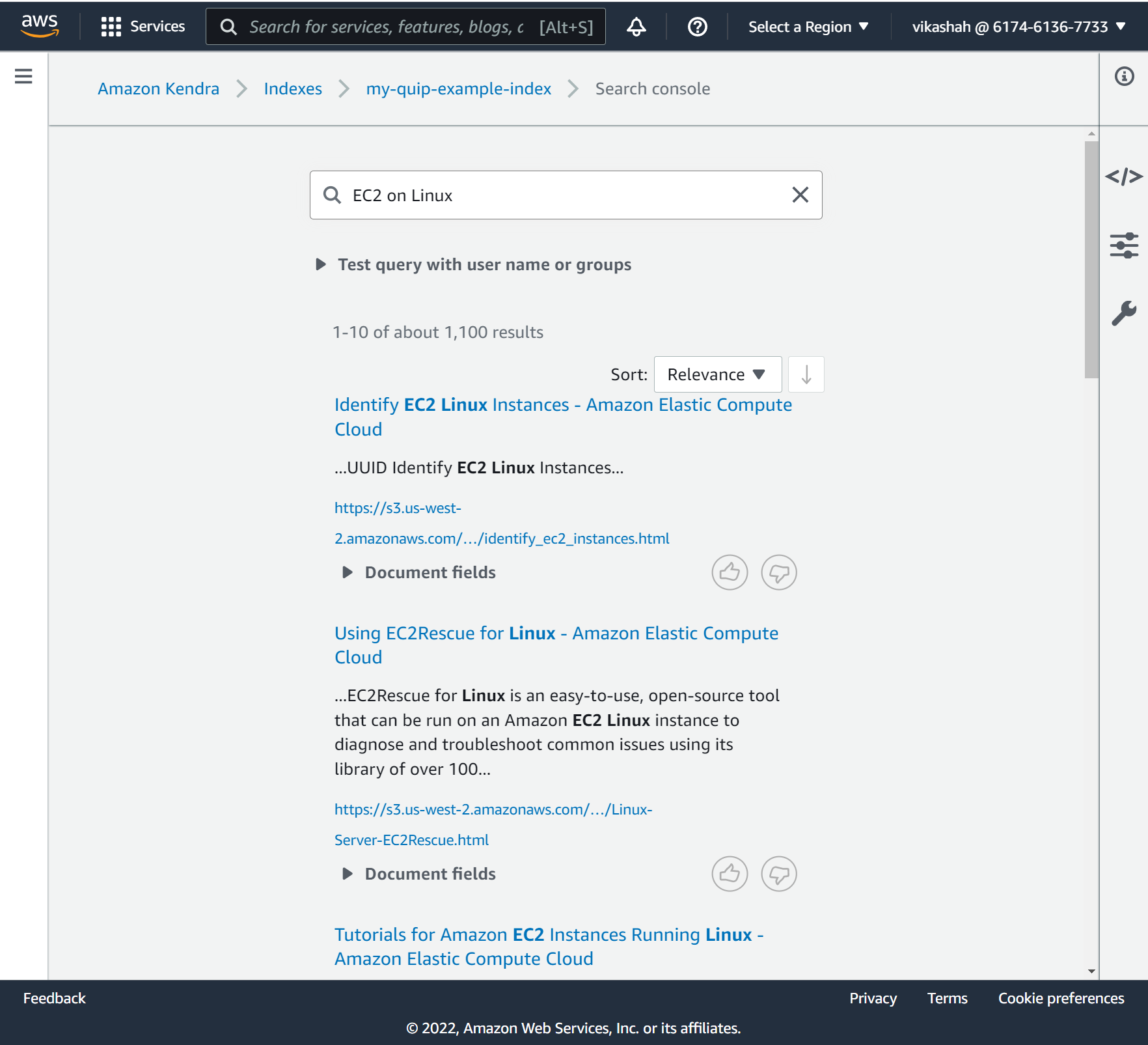
- Introduzca su búsqueda en el campo de búsqueda. Para esta publicación, buscamos
EC2 on Linux.

La siguiente captura de pantalla muestra nuestros resultados.
Limitaciones
Existen algunas limitaciones conocidas para la ingestión de fuentes de datos. Algunas limitaciones se deben a la necesidad de acceso de administrador para acceder a parte del contenido, otras se deben a detalles de implementación específicos. Son los siguientes:
- Solo se admiten rastreos completos. Si desea que el conector admita rastreos de registro de cambios, se requiere acceso a la API de administración y debe habilitar la API de administración en el sitio web de Quip.
- Solo se rastrean las carpetas compartidas. Incluso si usamos el token de acceso personal de un usuario administrador, no podemos rastrear datos en las carpetas privadas de otros usuarios.
- La solución no admite la especificación de tipos de archivos para inclusión y exclusión, porque Quip no almacena la extensión del tipo de archivo, solo el nombre del archivo.
- Los eventos en tiempo real requieren una suscripción y acceso a la API de administración.
Conclusión
El conector de Amazon Kendra para Quip permite a las organizaciones hacer que la valiosa información almacenada en los documentos de Quip esté disponible para sus usuarios de forma segura mediante la búsqueda inteligente con la tecnología de Amazon Kendra. El conector también proporciona facetas para los atributos del repositorio de Quip, como autores, tipo de archivo, URI de origen, fechas de creación, archivos principales y categoría para que los usuarios puedan refinar de forma interactiva los resultados de la búsqueda en función de lo que buscan.
Para obtener más información sobre cómo puede crear, modificar y eliminar datos y metadatos mediante el enriquecimiento de documentos personalizados a medida que el contenido se ingiere desde el repositorio de Quip, consulte Personalización de metadatos de documentos durante el proceso de ingesta y Enriquezca su contenido y metadatos para mejorar su experiencia de búsqueda con el enriquecimiento de documentos personalizados en Amazon Kendra.
Acerca de los autores
 Ashish Lagwankar es arquitecto sénior de soluciones empresariales en AWS. Sus principales intereses incluyen tecnologías de contenedores, AI/ML y sin servidor. Ashish vive en el área de Boston, MA, y disfruta leer, estar al aire libre y pasar tiempo con su familia.
Ashish Lagwankar es arquitecto sénior de soluciones empresariales en AWS. Sus principales intereses incluyen tecnologías de contenedores, AI/ML y sin servidor. Ashish vive en el área de Boston, MA, y disfruta leer, estar al aire libre y pasar tiempo con su familia.
 vikas shah es Arquitecto de Soluciones Empresariales en los servicios web de Amazon. Es un entusiasta de la tecnología que disfruta ayudando a los clientes a encontrar soluciones innovadoras para desafíos comerciales complejos. Sus áreas de interés son ML, IoT, robótica y almacenamiento. En su tiempo libre, a Vikas le gusta construir robots, hacer caminatas y viajar.
vikas shah es Arquitecto de Soluciones Empresariales en los servicios web de Amazon. Es un entusiasta de la tecnología que disfruta ayudando a los clientes a encontrar soluciones innovadoras para desafíos comerciales complejos. Sus áreas de interés son ML, IoT, robótica y almacenamiento. En su tiempo libre, a Vikas le gusta construir robots, hacer caminatas y viajar.
- Coinsmart. El mejor intercambio de Bitcoin y criptografía de Europa.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. ACCESO LIBRE.
- CriptoHawk. Radar de altcoins. Prueba gratis.
- Fuente: https://aws.amazon.com/blogs/machine-learning/search-for-knowledge-in-quip-documents-with-intelligent-search-using-the-quip-connector-for-amazon-kendra/
- "
- 10
- 100
- Nuestra Empresa
- de la máquina
- a través de
- Adicionales
- Admin
- Todos
- Amazon
- Amazon Web Services
- Anunciar
- Otra
- abejas
- Acceso API
- enfoque
- aproximadamente
- Reservada
- atributos
- Autorzy
- Hoy Disponibles
- AWS
- frontera
- Boston
- Box
- cada navegador
- Construir la
- capturar
- capturas
- Categoría
- retos
- desafiante
- Elige
- colaboran
- colaboración
- integraciones
- conectado
- Consola
- Envase
- contenido
- control
- Core
- creación
- personalizado
- Clientes
- datos
- Fechas
- entregar
- demostrar
- Dependiente
- Desarrollo
- dispositivo
- documentos
- No
- dominio
- Nombre de dominio
- pasan fácilmente
- habilitar
- Participar
- Empresa
- Eventos
- ejemplo
- experience
- factores importantes
- familia
- Terrenos
- la búsqueda de
- Nombre
- primer vez
- siguiendo
- formulario
- ser completados
- función
- es
- ayudando
- mantener
- Cómo
- Como Hacer
- HTTPS
- implementación
- incluir
- inclusión
- índice
- información
- originales
- De Operación
- intereses
- intereses
- IOT
- especialistas
- conocido
- aprendizaje
- Lista
- mirando
- máquina
- máquina de aprendizaje
- Management
- gerente
- ML
- más,
- múltiples
- nombres
- Naturaleza
- Navegación
- del sistema,
- habiertos
- Opciones
- organización
- organizativo
- para las fiestas.
- Otro
- al exterior
- con
- plataforma
- privada
- productividad
- proporcionar
- proporciona un
- Reading
- en tiempo real
- archivos
- repositorio
- exigir
- Requisitos
- Resultados
- robótica
- Ejecutar
- correr
- escanear
- Buscar
- segundos
- segura
- seleccionado
- Sin servidor
- Servicios
- set
- compartido
- sencillos
- Tamaño
- So
- a medida
- Soluciones
- algo
- velocidad
- Gastos
- fundó
- Estado
- STORAGE
- tienda
- suscripción
- exitosos
- abastecimiento
- SOPORTE
- Soportado
- equipo
- Tecnologías
- Tecnología
- test
- equipo
- juntos
- ficha
- tradicional
- Viajar
- único
- utilizan el
- usuarios
- Ver
- volumen
- web
- navegador web
- servicios web
- Página web
- ¿
- QUIENES
- Actividades: