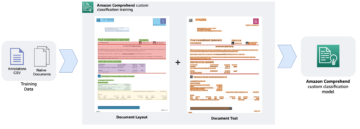
En visión por computadora, la segmentación semántica es la tarea de clasificar cada píxel en una imagen con una clase de un conjunto conocido de etiquetas, de modo que los píxeles con la misma etiqueta comparten ciertas características. Genera una máscara de segmentación de las imágenes de entrada. Por ejemplo, las siguientes imágenes muestran una máscara de segmentación del cat etiqueta.
 |
 |
En noviembre 2018, Amazon SageMaker anunció el lanzamiento del algoritmo de segmentación semántica SageMaker. Con este algoritmo, puede entrenar sus modelos con un conjunto de datos público o con su propio conjunto de datos. Los conjuntos de datos de segmentación de imágenes populares incluyen el conjunto de datos de objetos comunes en contexto (COCO) y las clases de objetos visuales PASCAL (PASCAL VOC), pero las clases de sus etiquetas son limitadas y es posible que desee entrenar un modelo en objetos de destino que no están incluidos en el conjuntos de datos públicos. En este caso, puede utilizar Verdad fundamental de Amazon SageMaker para etiquetar su propio conjunto de datos.
En esta publicación, demuestro las siguientes soluciones:
- Uso de Ground Truth para etiquetar un conjunto de datos de segmentación semántica
- Transformar los resultados de Ground Truth al formato de entrada requerido para el algoritmo de segmentación semántica integrado de SageMaker
- Uso del algoritmo de segmentación semántica para entrenar un modelo y realizar inferencias
Etiquetado de datos de segmentación semántica
Para construir un modelo de aprendizaje automático para la segmentación semántica, necesitamos etiquetar un conjunto de datos a nivel de píxel. Ground Truth le da la opción de usar anotadores humanos a través de Amazon Mechanical Turk, proveedores externos o su propia mano de obra privada. Para obtener más información sobre la fuerza laboral, consulte Crear y administrar la fuerza laboral. Si no desea administrar la fuerza laboral de etiquetado por su cuenta, Amazon SageMaker Tierra Verdad Plus es otra excelente opción como un nuevo servicio de etiquetado de datos llave en mano que le permite crear rápidamente conjuntos de datos de entrenamiento de alta calidad y reduce los costos hasta en un 40 %. Para esta publicación, le muestro cómo etiquetar manualmente el conjunto de datos con la función de segmento automático de Ground Truth y el etiquetado de colaboración colectiva con una fuerza laboral de Mechanical Turk.
Etiquetado manual con Ground Truth
En diciembre de 2019, Ground Truth agregó una función de segmento automático a la interfaz de usuario de etiquetado de segmentación semántica para aumentar el rendimiento del etiquetado y mejorar la precisión. Para obtener más información, consulte Segmentación automática de objetos al realizar el etiquetado de segmentación semántica con Amazon SageMaker Ground Truth. Con esta nueva función, puede acelerar su proceso de etiquetado en tareas de segmentación. En lugar de dibujar un polígono bien ajustado o usar la herramienta de pincel para capturar un objeto en una imagen, solo dibuja cuatro puntos: en los puntos más arriba, más abajo, más a la izquierda y más a la derecha del objeto. Ground Truth toma estos cuatro puntos como entrada y utiliza el algoritmo Deep Extreme Cut (DEXTR) para producir una máscara ajustada alrededor del objeto. Para ver un tutorial sobre el uso de Ground Truth para el etiquetado de segmentación semántica de imágenes, consulte Segmentación semántica de imágenes. El siguiente es un ejemplo de cómo la herramienta de segmentación automática genera una máscara de segmentación automáticamente después de elegir los cuatro puntos extremos de un objeto.


Etiquetado de crowdsourcing con una fuerza laboral de Mechanical Turk
Si tiene un gran conjunto de datos y no desea etiquetar manualmente cientos o miles de imágenes usted mismo, puede usar Mechanical Turk, que proporciona una fuerza laboral humana escalable y bajo demanda para completar trabajos que los humanos pueden hacer mejor que las computadoras. El software de Mechanical Turk formaliza las ofertas de trabajo a los miles de trabajadores dispuestos a realizar un trabajo fragmentado a su conveniencia. El software también recupera el trabajo realizado y lo compila para usted, el solicitante, quien paga a los trabajadores por un trabajo satisfactorio (únicamente). Para comenzar con Mechanical Turk, consulte Introducción a Amazon Mechanical Turk.
Crear un trabajo de etiquetado
El siguiente es un ejemplo de un trabajo de etiquetado de Mechanical Turk para un conjunto de datos de tortugas marinas. El conjunto de datos de tortugas marinas es de la competencia Kaggle. Detección de rostros de tortugas marinas, y seleccioné 300 imágenes del conjunto de datos con fines de demostración. La tortuga marina no es una clase común en los conjuntos de datos públicos, por lo que puede representar una situación que requiere el etiquetado de un conjunto de datos masivo.
- En la consola de SageMaker, elija Etiquetado de trabajos en el panel de navegación.
- Elige Crear trabajo de etiquetado.
- Introduzca un nombre para su trabajo.
- Configuración de datos de entrada, seleccione Configuración de datos automatizada.
Esto genera un manifiesto de datos de entrada. - Ubicación de S3 para conjuntos de datos de entrada, ingrese la ruta para el conjunto de datos.

- Categoría de tarea, escoger Imagen.
- Selección de tareas, seleccione Segmentación semántica.

- Tipos de trabajadores, seleccione Amazon Mechanical Turk.
- Configure sus ajustes para el tiempo de espera de la tarea, el tiempo de vencimiento de la tarea y el precio por tarea.

- Agregue una etiqueta (para esta publicación,
sea turtle), y proporcionar instrucciones de etiquetado. - Elige Crear.

Después de configurar el trabajo de etiquetado, puede comprobar el progreso del etiquetado en la consola de SageMaker. Cuando está marcado como completo, puede elegir el trabajo para verificar los resultados y usarlos para los siguientes pasos.

Transformación de conjuntos de datos
Después de obtener el resultado de Ground Truth, puede usar los algoritmos integrados de SageMaker para entrenar un modelo en este conjunto de datos. Primero, debe preparar el conjunto de datos etiquetado como la interfaz de entrada solicitada para el algoritmo de segmentación semántica de SageMaker.
Canales de datos de entrada solicitados
La segmentación semántica de SageMaker espera que su conjunto de datos de entrenamiento se almacene en Servicio de almacenamiento simple de Amazon (Amazon S3). Se espera que el conjunto de datos en Amazon S3 se presente en dos canales, uno para train y uno para validation, utilizando cuatro directorios, dos para imágenes y dos para anotaciones. Se espera que las anotaciones sean imágenes PNG sin comprimir. El conjunto de datos también puede tener un mapa de etiquetas que describa cómo se establecen las asignaciones de anotaciones. Si no, el algoritmo usa un valor predeterminado. Para la inferencia, un punto final acepta imágenes con un image/jpeg tipo de contenido. La siguiente es la estructura requerida de los canales de datos:
Cada imagen JPG en los directorios de tren y validación tiene una imagen de etiqueta PNG correspondiente con el mismo nombre en el train_annotation y validation_annotation directorios. Esta convención de nomenclatura ayuda al algoritmo a asociar una etiqueta con su imagen correspondiente durante el entrenamiento. El tren, train_annotation, validación y validation_annotation Los canales son obligatorios. Las anotaciones son imágenes PNG de un solo canal. El formato funciona siempre que los metadatos (modos) en la imagen ayuden al algoritmo a leer las imágenes de anotación en un número entero sin signo de 8 bits de un solo canal.
Salida del trabajo de etiquetado de Ground Truth
Los resultados generados a partir del trabajo de etiquetado de Ground Truth tienen la siguiente estructura de carpetas:
Las máscaras de segmentación se guardan en s3://turtle2022/labelturtles/annotations/consolidated-annotation/output. Cada imagen de anotación es un archivo .png que lleva el nombre del índice de la imagen de origen y la hora en que se completó el etiquetado de esta imagen. Por ejemplo, las siguientes son la imagen de origen (Imagen_1.jpg) y su máscara de segmentación generada por la fuerza laboral de Mechanical Turk (0_2022-02-10T17:41:04.724225.png). Tenga en cuenta que el índice de la máscara es diferente al número en el nombre de la imagen de origen.
 |
 |
El manifiesto de salida del trabajo de etiquetado está en el /manifests/output/output.manifest expediente. Es un archivo JSON y cada línea registra una asignación entre la imagen de origen y su etiqueta y otros metadatos. La siguiente línea JSON registra una asignación entre la imagen de origen que se muestra y su anotación:
La imagen de origen se llama Image_1.jpg y el nombre de la anotación es 0_2022-02-10T17:41: 04.724225.png. Para preparar los datos como los formatos de canal de datos necesarios del algoritmo de segmentación semántica de SageMaker, debemos cambiar el nombre de la anotación para que tenga el mismo nombre que las imágenes JPG de origen. Y también necesitamos dividir el conjunto de datos en train y validation directorios para las imágenes de origen y las anotaciones.
Transforme la salida de un trabajo de etiquetado de Ground Truth al formato de entrada solicitado
Para transformar la salida, complete los siguientes pasos:
- Descargue todos los archivos del trabajo de etiquetado de Amazon S3 a un directorio local:
- Lea el archivo de manifiesto y cambie los nombres de la anotación a los mismos nombres que las imágenes de origen:
- Dividir los conjuntos de datos de tren y validación:
- Cree un directorio en el formato requerido para los canales de datos del algoritmo de segmentación semántica:
- Mueva las imágenes de tren y validación y sus anotaciones a los directorios creados.
- Para las imágenes, utilice el siguiente código:
- Para las anotaciones, utilice el siguiente código:
- Cargue los conjuntos de datos de capacitación y validación y sus conjuntos de datos de anotación en Amazon S3:
Entrenamiento del modelo de segmentación semántica de SageMaker
En esta sección, repasamos los pasos para entrenar su modelo de segmentación semántica.
Siga el cuaderno de muestra y configure canales de datos
Puede seguir las instrucciones en El algoritmo de segmentación semántica ya está disponible en Amazon SageMaker para implementar el algoritmo de segmentación semántica en su conjunto de datos etiquetado. esta muestra cuaderno muestra un ejemplo de extremo a extremo que presenta el algoritmo. En el cuaderno, aprenderá a entrenar y alojar un modelo de segmentación semántica utilizando la red totalmente convolucional (FCN) algoritmo usando el Conjunto de datos de VOC de Pascal para entrenamiento. Debido a que no planeo entrenar un modelo a partir del conjunto de datos VOC de Pascal, omití el Paso 3 (preparación de datos) en este cuaderno. En cambio, creé directamente train_channel, train_annotation_channe, validation_channely validation_annotation_channel usando las ubicaciones de S3 donde almacené mis imágenes y anotaciones:
Ajuste los hiperparámetros para su propio conjunto de datos en el estimador de SageMaker
Seguí el cuaderno y creé un objeto estimador de SageMaker (ss_estimator) para entrenar mi algoritmo de segmentación. Una cosa que necesitamos personalizar para el nuevo conjunto de datos está en ss_estimator.set_hyperparameters: tenemos que cambiar num_classes=21 a num_classes=2 (turtle y background), y también cambié epochs=10 a epochs=30 porque 10 es solo para fines de demostración. Luego usé la instancia p3.2xlarge para el entrenamiento del modelo configurando instance_type="ml.p3.2xlarge". El entrenamiento se completó en 8 minutos. Lo mejor MIOU (Intersección media sobre la unión) de 0.846 se logra en la época 11 con un pix_acc (el porcentaje de píxeles en su imagen que se clasifican correctamente) de 0.925, que es un resultado bastante bueno para este pequeño conjunto de datos.
Resultados de la inferencia del modelo
Alojé el modelo en una instancia ml.c5.xlarge de bajo costo:
Finalmente, preparé un conjunto de prueba de 10 imágenes de tortugas para ver el resultado de la inferencia del modelo de segmentación entrenado:
Las siguientes imágenes muestran los resultados.

Las máscaras de segmentación de las tortugas marinas parecen precisas y estoy contento con este resultado entrenado en un conjunto de datos de 300 imágenes etiquetado por trabajadores de Mechanical Turk. También puede explorar otras redes disponibles como red de análisis de escena piramidal (PSP) or DeepLab-V3 en el cuaderno de muestra con su conjunto de datos.
Limpiar
Elimine el punto final cuando haya terminado con él para evitar incurrir en costos continuos:
Conclusión
En esta publicación, mostré cómo personalizar el etiquetado de datos de segmentación semántica y el entrenamiento de modelos con SageMaker. En primer lugar, puede configurar un trabajo de etiquetado con la herramienta de segmentación automática o utilizar una mano de obra de Mechanical Turk (así como otras opciones). Si tiene más de 5,000 objetos, también puede utilizar el etiquetado de datos automatizado. Luego, transforma los resultados de su trabajo de etiquetado de Ground Truth en los formatos de entrada requeridos para el entrenamiento de segmentación semántica integrado de SageMaker. Después de eso, puede usar una instancia informática acelerada (como p2 o p3) para entrenar un modelo de segmentación semántica con lo siguiente cuaderno e implemente el modelo en una instancia más rentable (como ml.c5.xlarge). Por último, puede revisar los resultados de la inferencia en su conjunto de datos de prueba con unas pocas líneas de código.
Comience con la segmentación semántica de SageMaker etiquetado de datos y entrenamiento modelo con su conjunto de datos favorito!
Sobre la autora
 kara yang es científico de datos en los servicios profesionales de AWS. Le apasiona ayudar a los clientes a lograr sus objetivos comerciales con los servicios en la nube de AWS. Ha ayudado a las organizaciones a crear soluciones de aprendizaje automático en múltiples industrias, como la fabricación, la automoción, la sostenibilidad medioambiental y la industria aeroespacial.
kara yang es científico de datos en los servicios profesionales de AWS. Le apasiona ayudar a los clientes a lograr sus objetivos comerciales con los servicios en la nube de AWS. Ha ayudado a las organizaciones a crear soluciones de aprendizaje automático en múltiples industrias, como la fabricación, la automoción, la sostenibilidad medioambiental y la industria aeroespacial.
- Coinsmart. El mejor intercambio de Bitcoin y criptografía de Europa.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. ACCESO LIBRE.
- CriptoHawk. Radar de altcoins. Prueba gratis.
- Fuente: https://aws.amazon.com/blogs/machine-learning/semantic-segmentation-data-labeling-and-model-training-using-amazon-sagemaker/
- '
- "
- 000
- 10
- 100
- 11
- 2019
- a
- Sobre
- acelerar
- acelerado
- preciso
- Lograr
- alcanzado
- a través de
- adicional
- Aeroespacial
- algoritmo
- algoritmos
- Todos
- Amazon
- anunció
- Otra
- en torno a
- Consejos
- Confirmación de Viaje
- automáticamente
- automotor
- Hoy Disponibles
- AWS
- fondo
- porque
- MEJOR
- mejores
- entre
- build
- incorporado
- capturar
- case
- a ciertos
- el cambio
- canales
- Elige
- clase
- privadas
- clasificado
- Soluciones
- servicios en la nube
- código
- Algunos
- competencia
- completar
- computadora
- computadoras
- informática
- confianza
- Consola
- contenido
- comodidad
- Correspondiente
- rentable
- Precio
- Para crear
- creado
- Clientes
- personalizan
- datos
- científico de datos
- profundo
- demostrar
- desplegar
- una experiencia diferente
- directamente
- dibujo
- durante
- cada una
- permite
- de extremo a extremo
- Punto final
- Participar
- ambientales
- se establece
- ejemplo
- Excepto
- esperado
- espera
- explorar
- extremo
- Cara
- Feature
- Nombre
- seguir
- siguiendo
- formato
- en
- generado
- Goals
- candidato
- gris
- maravillosa
- Ahorrar
- ayudado
- ayudando
- ayuda
- alta calidad
- organizado
- Cómo
- Como Hacer
- HTTPS
- humana
- Humanos
- Cientos
- imagen
- imágenes
- implementar
- mejorar
- incluir
- incluido
- aumente
- índice
- industrias
- información
- Las opciones de entrada
- ejemplo
- Interfaz
- intersección
- Presentamos
- IT
- Trabajos
- Empleo
- conocido
- Label
- etiquetado
- Etiquetas
- large
- lanzamiento
- APRENDE:
- aprendizaje
- Nivel
- Limitada
- línea
- líneas
- Lista
- local
- Ubicación
- .
- Largo
- Mira
- máquina
- máquina de aprendizaje
- gestionan
- obligatorio
- a mano
- Fabricación
- mapa
- cartografía
- máscara
- Mascarillas
- masivo
- mecánico
- podría
- ML
- modelo
- modelos
- más,
- múltiples
- nombres
- nombrando
- Navegación
- del sistema,
- telecomunicaciones
- Next
- cuaderno
- número
- Ofertas
- Optión
- Opciones
- para las fiestas.
- Otro
- EL DESARROLLADOR
- apasionado
- por ciento
- realizar
- puntos
- Polígono
- Popular
- Preparar
- bastante
- precio
- privada
- producir
- Profesional
- proporcionar
- proporciona un
- público
- fines
- con rapidez
- RE
- archivos
- representar
- Requisitos
- requiere
- Resultados
- una estrategia SEO para aparecer en las búsquedas de Google.
- mismo
- escalable
- Científico
- MAR
- segmentación
- seleccionado
- de coches
- Servicios
- set
- pólipo
- Compartir
- Mostrar
- mostrado
- sencillos
- situación
- chica
- So
- Software
- Soluciones
- dividido
- fundó
- STORAGE
- Sostenibilidad
- Target
- tareas
- equipo
- test
- El
- La Fuente
- cosa
- terceros.
- miles
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- rendimiento
- equipo
- del IRS
- Entrenar
- Formación
- Transformar
- unión
- utilizan el
- validación
- vendedores
- visión
- QUIENES
- Actividades:
- los trabajadores.
- Empleados
- funciona
- tú