Desplazamiento al rojo de Amazon es un servicio de almacenamiento de datos en la nube de nivel empresarial y escala de petabytes que ofrece la mejor relación calidad-precio. Hoy en día, decenas de miles de clientes ejecutan cargas de trabajo críticas para el negocio en Amazon Redshift para analizar sus datos de manera rápida y rentable utilizando SQL estándar y herramientas de inteligencia empresarial (BI) existentes.
Amazon Redshift ahora le facilita la ejecución de consultas en lagos de datos de AWS montando automáticamente el Catálogo de datos de AWS Glue. Ya no es necesario crear un esquema externo en Amazon Redshift para utilizar las tablas del lago de datos catalogadas en el catálogo de datos. Ahora puedes usar tu Gestión de identidades y accesos de AWS (IAM) o función de IAM para explorar el catálogo de datos de Glue y consultar tablas del lago de datos directamente desde Editor de consultas de Amazon Redshift v2 o sus editores SQL preferidos.
Esta característica ahora está disponible en todas las regiones comerciales de AWS y de la nube del gobierno de EE. UU. donde Amazon Redshift RA3, Amazon Redshift sin servidory Pegamento AWS están disponibles. Para obtener más información sobre el montaje automático del catálogo de datos en Amazon Redshift, consulte Consultar el catálogo de datos de AWS Glue.
Permitir análisis sencillos para todos
Amazon Redshift está ayudando a decenas de miles de clientes a gestionar análisis a escala. Amazon Redshift ofrece una potente solución de análisis que brinda acceso a información valiosa para usuarios de todos los niveles. Podrás aprovechar los siguientes beneficios:
- Permite a las organizaciones analizar diversas fuentes de datos, incluidos datos estructurados, semiestructurados y no estructurados, lo que facilita la exploración integral de datos.
- Con sus capacidades de procesamiento de alto rendimiento, Amazon Redshift maneja conjuntos de datos grandes y complejos, lo que garantiza tiempos de respuesta rápidos a las consultas y admite análisis en tiempo real.
- Amazon Redshift proporciona características como Multi-AZ (vista previa) y copia de instantáneas entre regiones para alta disponibilidad y recuperación ante desastres, y proporciona mecanismos de autenticación y autorización para que sea confiable y seguro.
- Con características como Aprendizaje automático de Amazon Redshift, democratiza las capacidades de aprendizaje automático en una variedad de usuarios
- La flexibilidad para utilizar diferentes formatos de tabla, como apache hudi, Delta Lakey Apache Iceberg (vista previa) optimiza el rendimiento de las consultas y la eficiencia del almacenamiento
- La integración con herramientas analíticas avanzadas le permite aplicar técnicas sofisticadas y crear modelos predictivos.
- La escalabilidad y la elasticidad permiten una expansión perfecta a medida que crecen los datos y las cargas de trabajo.
En general, Amazon Redshift permite a las organizaciones descubrir información valiosa, mejorar la toma de decisiones y obtener una ventaja competitiva en el panorama actual basado en datos.

Principales beneficios de Amazon Redshift
El nuevo montaje automático de la función AWS Glue Data Catalog le permite consultar directamente objetos de AWS Glue en Amazon Redshift sin la necesidad de crear un esquema externo para cada base de datos de AWS Glue que desee consultar. Con el montaje automático del catálogo de datos, Amazon Redshift monta automáticamente el catálogo de datos predeterminado de la cuenta del clúster durante el arranque o la suscripción del usuario como una base de datos externa, denominada awsdatacatalog.
Casos de uso relevantes para el montaje automático de la función AWS Glue Data Catalog
Puede utilizar herramientas como EMR de Amazon para crear nuevos esquemas de lago de datos en varios formatos, como Apache Hudi, Delta Lake y Apache Iceberg (versión preliminar). Sin embargo, cuando los analistas quieren ejecutar consultas en estos esquemas, es necesario que los administradores creen esquemas externos para cada base de datos de AWS Glue en Amazon Redshift. Ahora puede simplificar esta integración mediante el montaje automático del catálogo de datos de AWS Glue.
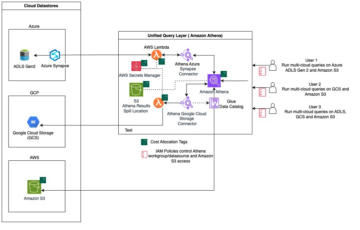
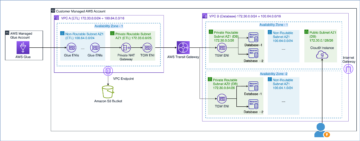
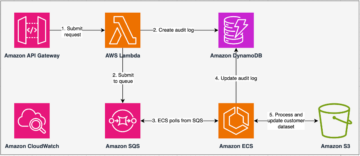
El siguiente diagrama ilustra esta arquitectura.

Resumen de la solución
Ahora puede utilizar clientes SQL como Amazon Redshift Query Editor v2 para explorar y consultar awsdatacatalog. En Query Editor V2, para conectarse al awsdatacatalog base de datos, elija lo siguiente:
Complete los siguientes pasos de alto nivel para integrar el montaje automático del catálogo de datos utilizando Query Editor V2 y un cliente SQL de terceros:
- Proveer recursos con Formación en la nube de AWS para rellenar objetos del catálogo de datos.
- Conecte Redshift Serverless y consulte el catálogo de datos como usuario federado mediante Query Editor V2.
- Conéctese con el clúster aprovisionado de Redshift y consulte el catálogo de datos mediante Query Editor V2.
- Configure permisos en los recursos del catálogo usando Formación del lago AWS.
- Federe con Redshift Serverless y consulte el catálogo de datos mediante Query Editor V2 y un cliente SQL de terceros.
- Descubra los objetos automontados.
- Conéctese con el clúster aprovisionado de Redshift y consulte el catálogo de datos como usuario federado mediante un cliente de terceros.
- Conéctese con Amazon Redshift y consulte el catálogo de datos como usuario de IAM mediante clientes de terceros.
El siguiente diagrama ilustra el flujo de trabajo de la solución.

Requisitos previos
Debe tener los siguientes requisitos previos:
Aprovisione recursos con AWS CloudFormation para completar objetos del catálogo de datos
En esta publicación utilizamos un Rastreador de AWS Glue para crear la tabla externa ny_pub almacenado en formato Apache Parquet en el Servicio de almacenamiento simple de Amazon (Amazon S3) ubicación s3://redshift-demos/data/NY-Pub/. En este paso, creamos los recursos de la solución utilizando AWS CloudFormation para crear una pila denominada CrawlS3Source-NYTaxiData en cualquiera us-east-1 (utilizar el yml descargar o pila de lanzamiento) o us-west-2 (utilizar el yml descargar o pila de lanzamiento). La creación de la pila realiza las siguientes acciones:
- Crea el rastreador
NYTaxiCrawlerjunto con el nuevo rol de IAMAWSGlueServiceRole-RedshiftAutoMount - crea
automountdbcomo la base de datos de AWS Glue

Cuando la pila esté completa, realice los siguientes pasos:
- En la consola de AWS Glue, debajo de Catálogo de datos en el panel de navegación, elija Rastreadores.
- Abierto
NYTaxiCrawlery elige Ejecutar rastreador.

Una vez completado el rastreador, podrá ver una nueva tabla llamada ny_pub en el catálogo de datos bajo el automountdb base de datos.


Alternativamente, puede seguir el instrucciones manuales de los laboratorios de Amazon Redshift para crear el ny_pub mesa.
Conéctese con Redshift Serverless y consulte el catálogo de datos como usuario federado mediante Query Editor V2
En esta sección, utilizamos una función de IAM con etiquetas principales para habilitar la autenticación federada detallada en Redshift Serverless para acceder a objetos de montaje automático de AWS Glue.
Complete los siguientes pasos:
- Cree una función de IAM y agregue los siguientes permisos. Para esta publicación, agregamos permisos completos de AWS Glue, Amazon Redshift y Amazon S3 con fines de demostración. En un escenario de producción real, se recomienda aplicar permisos más granulares.


- En Etiquetas pestaña, cree una etiqueta con Clave as
RedshiftDbRolesy Valor asautomount.
- En Query Editor V2, ejecute la siguiente instrucción SQL como usuario administrador para crear una función de base de datos denominada
automount: - Otorgue privilegios de uso al rol de base de datos:
- cambiar el rol a
automountrolepasando el número de cuenta y el nombre del rol.
- En el Editor de consultas v2, elija su punto final Redshift Serverless (haga clic con el botón derecho) y elija Crear conexión.
- Autenticación, seleccione usuario federado.
- Base de datos, ingrese el nombre de la base de datos a la que desea conectarse.
- Elige Crear conexión.
Ahora está listo para explorar y consultar el montaje automático del catálogo de datos en Redshift Serverless.

Conéctese con el clúster aprovisionado de Redshift y consulte el catálogo de datos mediante Query Editor V2
Para conectarse con el clúster aprovisionado de Redshift y acceder al catálogo de datos, asegúrese de haber completado los pasos de la sección anterior. Luego complete los siguientes pasos:
- Conéctese a Redshift Query Editor V2 utilizando el método de autenticación de nombre de usuario y contraseña de la base de datos. Por ejemplo, conéctese al
devbase de datos utilizando el usuario administrador y la contraseña. - En una pestaña del editor, suponiendo que el usuario está presente en Amazon Redshift, ejecute la siguiente declaración SQL para otorgar acceso a un usuario de IAM al catálogo de datos:
- Como usuario administrador, elija el Ajustes icono, elegir Configuración de la cuentay seleccione Autenticarse con credenciales de IAM.
- Elige Guardar.

- Cambiar roles a
automountrolepasando el número de cuenta y el nombre del rol. - Cree o edite la conexión y utilice el método de autenticación Credenciales temporales con su identidad de IAM.
Para obtener más información sobre este método de autenticación, consulte Conexión a una base de datos de Amazon Redshift.
Está listo para explorar y consultar el montaje automático del catálogo de datos en Amazon Redshift.

Descubre los objetos automontados
Esta sección ilustra los comandos MOSTRAR para el descubrimiento de objetos montados automáticamente. Vea el siguiente código:

Configure permisos en recursos del catálogo utilizando AWS Lake Formation
Para mantener la compatibilidad con versiones anteriores de AWS Glue, Lake Formation tiene la siguiente configuración de seguridad inicial:
- La
Superse concede permiso al grupoIAMAllowedPrincipalsen todos los recursos existentes del catálogo de datos - La Usar solo el control de acceso de IAM la configuración está habilitada para nuevos recursos del catálogo de datos
Esta configuración hace que el acceso a los recursos del catálogo de datos y a las ubicaciones de Amazon S3 esté controlado únicamente por políticas de IAM. Los permisos individuales de Lake Formation no están vigentes.
En este paso, configuraremos permisos en los recursos del catálogo utilizando AWS Lake Formation. Antes de crear el catálogo de datos, debe actualizar la configuración predeterminada de Lake Formation para que el acceso a los recursos del catálogo de datos (bases de datos y tablas) sea administrado por los permisos de Lake Formation:
- Cambie la configuración de seguridad predeterminada para nuevos recursos. Para obtener instrucciones, consulte Cambiar el modelo de permiso predeterminado.
- Cambie la configuración de los recursos existentes del catálogo de datos. Para obtener instrucciones, consulte Actualización de los permisos de datos de AWS Glue al modelo de AWS Lake Formation.
Para obtener más información, consulte Cambiar la configuración predeterminada para su lago de datos.
Federe con Redshift Serverless y consulte el catálogo de datos mediante Query Editor V2 y un cliente SQL de terceros
Con Redshift Serverless, puede conectarse a awsdatacatalog de un cliente de terceros como usuario federado de cualquier proveedor de identidad (IdP). En esta sección, configuraremos el permiso en los recursos del catálogo para el rol de IAM federado en AWS Lake Formation. Al utilizar AWS Lake Formation con Redshift, actualmente el permiso se puede aplicar en el nivel de usuario o rol de IAM.
Para conectarnos como usuario federado, usaremos Redshift Serverless. Para obtener instrucciones de configuración, consulte Inicio de sesión único con Amazon Redshift Serverless con Okta utilizando Amazon Redshift Query Editor v2 y clientes SQL de terceros.
Se requieren cambios adicionales en los siguientes recursos:
- En Amazon Redshift, como usuario administrador, otorgue el uso a cada usuario federado que necesite acceso en
awsdatacatalog:
Si el usuario no existe en Amazon Redshift, es posible que deba crear el usuario de IAM con la contraseña deshabilitada como se muestra en el siguiente código y luego otorgarle el uso en awsdatacatalog:
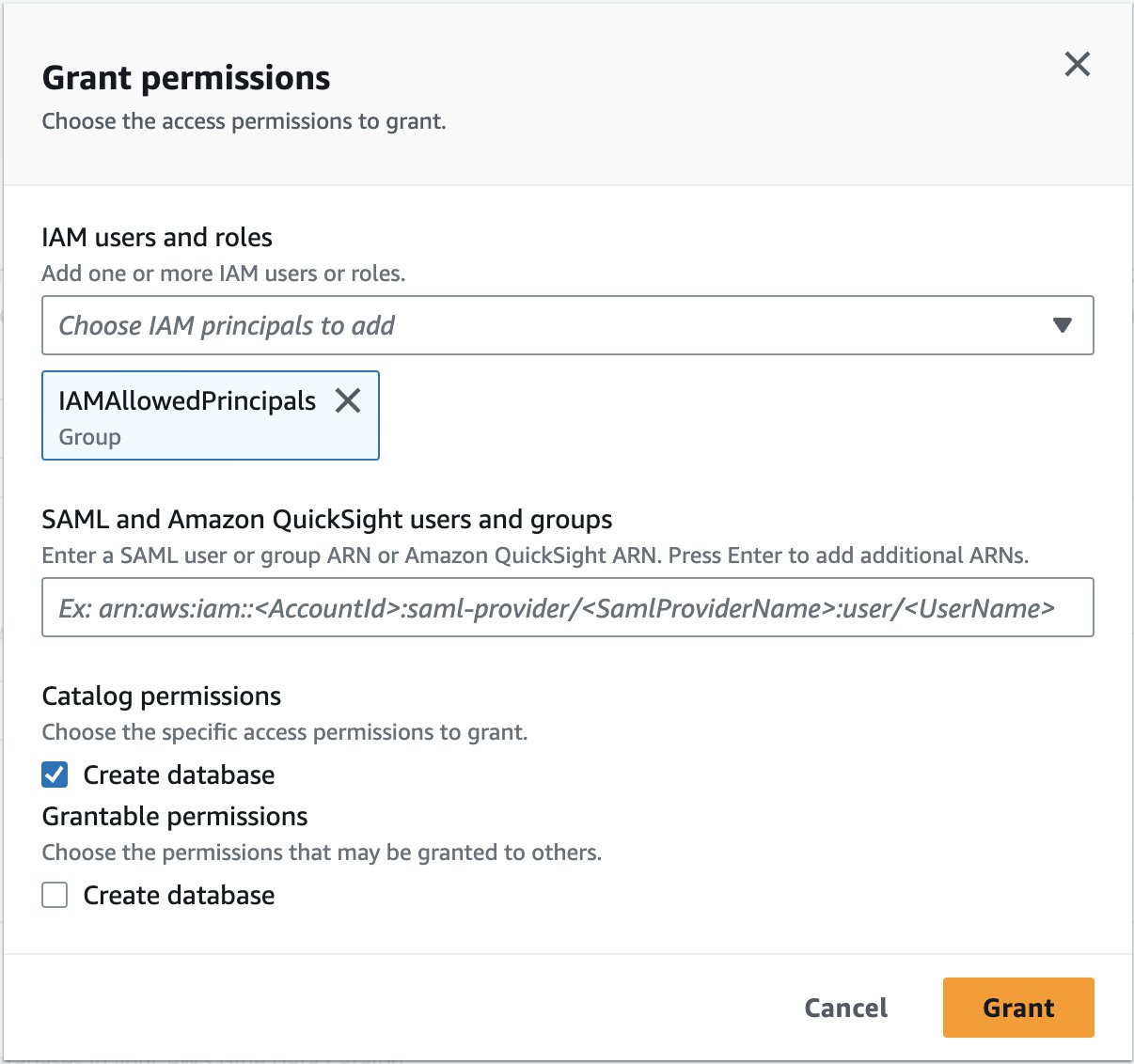
- En la consola de Lake Formation, asigne permisos en la base de datos de AWS Glue al Rol de IAM que creó como parte de la configuración federada.
- under Directores, seleccione Usuarios y roles de IAM.
- Elija el rol de IAM
oktarole. - Aplicar permisos de recursos del catálogo, seleccionando
automountdbbase de datos y otorgando permisos de tabla apropiados.
- Actualice la función de IAM utilizada en la configuración de la federación. Además de los permisos agregados a la función de IAM, debe agregar permisos de AWS Glue y permisos de Amazon S3 para acceder a objetos desde Amazon S3. Para esta publicación, agregamos permisos completos de AWS Glue y AWS S3 con fines de demostración. En un escenario de producción real, se recomienda aplicar permisos más granulares.

Ahora está listo para conectarse a Redshift Serverless mediante Query Editor V2 y el inicio de sesión federado.
- Utilice la URL de SSO de Okta e inicie sesión en su cuenta de Okta con sus credenciales de usuario. Para esta demostración, iniciamos sesión con el usuario.
Ethan. - En Query Editor v2, elija su instancia de Redshift Serverless (haga clic con el botón derecho) y elija Crear conexión.
- Autenticación, seleccione usuario federado.
- Base de datos, ingrese el nombre de la base de datos a la que desea conectarse.
- Elige Crear conexión.
- Ejecuta el comando
select current_userpara validar que ha iniciado sesión como usuario federado.
Usuario Ethan podrá explorar y acceder awsdatacatalog datos.

Para conectar Redshift Serverless con un cliente de terceros, asegúrese de haber seguido todos los pasos anteriores.
Para la configuración de SQLWorkbench, consulte la sección Configurar el cliente SQL (SQL Workbench/J) in Inicio de sesión único con Amazon Redshift Serverless con Okta utilizando Amazon Redshift Query Editor v2 y clientes SQL de terceros.
La siguiente captura de pantalla muestra que el usuario federado ethan es capaz de consultar el awsdatacatalog tablas que utilizan notación de tres partes:

Conéctese con el clúster aprovisionado de Redshift y consulte el catálogo de datos como usuario federado utilizando clientes de terceros.
Con el clúster aprovisionado de Redshift, puede conectarse con awsdatacatalog desde un cliente de terceros como usuario federado desde cualquier IdP.
Para conectarse como usuario federado con el clúster aprovisionado de Redshift, debe seguir los pasos de la sección anterior que detallan cómo conectarse con Redshift Serverless y consultar el catálogo de datos como usuario federado utilizando Query Editor V2 y un cliente SQL de terceros. .
Se requieren cambios adicionales en la política de IAM. Actualice la política de IAM con el siguiente código para utilizar la GetClusterCredentialsWithIAM API:
Ahora está listo para conectarse al clúster aprovisionado de Redshift mediante un cliente SQL de terceros como usuario federado.
Para la configuración de SQLWorkbench, consulte la sección Configurar el cliente SQL (SQL Workbench/J) en el post Inicio de sesión único con Amazon Redshift Serverless con Okta utilizando Amazon Redshift Query Editor v2 y clientes SQL de terceros.
Realice los siguientes cambios:
- Utilice el controlador JDBC de Redshift más reciente porque solo admite la consulta de la tabla del catálogo de datos montada automáticamente para usuarios federados.
- Enlance, introduzca
jdbc:redshift:iam://<cluster endpoint>:<port>:<databasename>?groupfederation=true. Por ejemplo,jdbc:redshift:iam://redshift-cluster-1.abdef0abc0ab.us-east-2.redshift.amazonaws.com:5439/dev?groupfederation=true.
En la URL anterior, groupfederation es un parámetro obligatorio que le permite autenticarse con las credenciales de IAM.

La siguiente captura de pantalla muestra que el usuario federado ethan es capaz de consultar el awsdatacatalog tablas usando notación de tres partes.
Conecte y consulte el catálogo de datos como usuario de IAM utilizando clientes de terceros
En esta sección, proporcionamos instrucciones para configurar un cliente SQL para consultar el archivo montado automáticamente. awsdatacatalog.
Utilice la notación de tres partes para hacer referencia a la tabla awsdatacatalog en su instrucción SELECT. La primera parte es el nombre de la base de datos, la segunda parte es el nombre de la base de datos de AWS Glue y la tercera parte es el nombre de la tabla de AWS Glue:
Puede realizar varios escenarios que leen los datos del catálogo de datos y completan las tablas de Redshift.
Para esta publicación, utilizamos SQLWorkbench/J como cliente SQL para consultar el catálogo de datos. Para configurar SQL Workbench/J, complete los siguientes pasos:
- Cree una nueva conexión en SQL Workbench / J y elija Amazon Redshift como controlador.
- Elige Administrar conductores y agregue todos los archivos del archivo .zip del paquete de controladores AWS JDBC descargado (recuerde descomprimir el archivo .zip).
Debe utilizar el controlador Redshift JDBC más reciente porque solo admite la consulta de la tabla del catálogo de datos montada automáticamente.
- Enlance, introduzca
jdbc:redshift:iam://<cluster endpoint>:<port>:<databasename>?profile=<profilename>&groupfederation=true. Por ejemplo,jdbc:redshift:iam://redshift-cluster-1.abdef0abc0ab.us-east-2.redshift.amazonaws.com:5439/dev?profile=user2&groupfederation=true.

Estamos utilizando credenciales basadas en perfiles como ejemplo. Puede utilizar cualquier perfil de AWS o autenticación basada en credenciales de IAM según sus necesidades. Para obtener más información sobre las credenciales de IAM, consulte Opciones para proporcionar credenciales de IAM.
La siguiente captura de pantalla muestra que el usuario de IAM johndoe es capaz de enumerar los awsdatacatalog tablas usando el comando MOSTRAR.

La siguiente captura de pantalla muestra que el usuario de IAM johndoe es capaz de consultar el awsdatacatalog tablas que utilizan notación de tres partes:

Si recibe el siguiente error mientras usa groupfederation=true, debe utilizar el controlador Redshift más reciente:
Limpiar
Complete los siguientes pasos para limpiar sus recursos:
- Eliminar la función de IAM
automountrole. - Eliminar la pila de CloudFormation
CrawlS3Source-NYTaxiDatapara limpiar el rastreadorNYTaxiCrawler, la base de datos automountdb del catálogo de datos y la función de IAMAWSGlueServiceRole-RedshiftAutoMount.
- Actualice la configuración predeterminada de Lake Formation:
- En el panel de navegación, debajo Catálogo de datos, escoger Ajustes.
- Seleccione ambas opciones de control de acceso elija Guardar.

- En el panel de navegación, debajo Permisos, escoger Funciones y tareas administrativas.
- En creadores de bases de datos sección, elija Grant.
- Busque
IAMAllowedPrincipalsy seleccionar Crear base de datos permiso. - Elige Grant.
Consideraciones
Tenga en cuenta las siguientes consideraciones:
- El montaje automático del catálogo de datos proporciona facilidad de uso a los analistas o usuarios de bases de datos. La configuración de seguridad (configuración del modelo de permisos o gobierno de datos) es propiedad de los administradores de cuentas y bases de datos.
- Para lograr un control de acceso detallado, cree un modelo de permisos en AWS Lake Formation.
- Si los permisos deben mantenerse en el nivel de la base de datos de Redshift, deje la configuración predeterminada de AWS Lake Formation como está y luego ejecute otorgar/revocar en Amazon Redshift.
- Si está utilizando un editor SQL de terceros y su herramienta de consulta no admite la exploración de varias bases de datos, puede utilizar los comandos "MOSTRAR" para enumerar sus bases de datos y tablas de AWS Glue. También puedes consultar
awsdatacatalogobjetos usando notación de tres partes (SELECT * FROM awsdatacatalog.<aws-glue-db-name>.<aws-glue-table-name>;) siempre que tenga acceso a los objetos externos según el modelo de permiso.
Conclusión
En esta publicación, presentamos el montaje automático de Catálogo de datos de AWS Glue, lo que facilita a los clientes ejecutar consultas en sus lagos de datos. Esta característica agiliza la gobernanza de datos y el control de acceso, eliminando la necesidad de crear un esquema externo en Amazon Redshift para utilizar las tablas del lago de datos catalogadas en AWS Glue Data Catalog. Mostramos cómo puede administrar los permisos en objetos basados en AWS Glue montados automáticamente utilizando Lake Formation. Los administradores pueden gestionar y organizar fácilmente el modelo de permisos, lo que permite a los usuarios de la base de datos acceder sin problemas a los objetos externos a los que se les ha concedido acceso.
Mientras nos esforzamos por mejorar la usabilidad en Amazon Redshift, priorizamos la gobernanza de datos unificada y el control de acceso detallado. Esta característica minimiza el esfuerzo manual y al mismo tiempo garantiza que se implementen las medidas de seguridad necesarias para su organización.
Para obtener más información sobre el montaje automático del catálogo de datos en Amazon Redshift, consulte Consultar el catálogo de datos de AWS Glue.
Acerca de los autores
 Maneesh Sharma es ingeniero sénior de bases de datos en AWS con más de una década de experiencia en el diseño e implementación de soluciones de almacenamiento y análisis de datos a gran escala. Colabora con varios socios y clientes de Amazon Redshift para impulsar una mejor integración.
Maneesh Sharma es ingeniero sénior de bases de datos en AWS con más de una década de experiencia en el diseño e implementación de soluciones de almacenamiento y análisis de datos a gran escala. Colabora con varios socios y clientes de Amazon Redshift para impulsar una mejor integración.
 Debu Panda es gerente sénior de administración de productos en AWS. Es un líder de la industria en análisis, plataforma de aplicaciones y tecnologías de bases de datos, y tiene más de 25 años de experiencia en el mundo de TI.
Debu Panda es gerente sénior de administración de productos en AWS. Es un líder de la industria en análisis, plataforma de aplicaciones y tecnologías de bases de datos, y tiene más de 25 años de experiencia en el mundo de TI.
 Rohit Vashishta es arquitecto sénior de soluciones especialista en análisis en AWS con sede en Dallas, Texas. Tiene 17 años de experiencia en la arquitectura, construcción, liderazgo y mantenimiento de plataformas de big data. Rohit ayuda a los clientes a modernizar sus cargas de trabajo analíticas utilizando la amplitud de los servicios de AWS y garantiza que los clientes obtengan la mejor relación precio/rendimiento con la máxima seguridad y control de datos.
Rohit Vashishta es arquitecto sénior de soluciones especialista en análisis en AWS con sede en Dallas, Texas. Tiene 17 años de experiencia en la arquitectura, construcción, liderazgo y mantenimiento de plataformas de big data. Rohit ayuda a los clientes a modernizar sus cargas de trabajo analíticas utilizando la amplitud de los servicios de AWS y garantiza que los clientes obtengan la mejor relación precio/rendimiento con la máxima seguridad y control de datos.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/simplify-external-object-access-in-amazon-redshift-using-automatic-mounting-of-the-aws-glue-data-catalog/
- :posee
- :es
- :no
- :dónde
- $ UP
- 10
- 100
- 167
- 17
- 25
- 32
- 500
- 7
- 8
- a
- Poder
- Nuestra Empresa
- de la máquina
- Acceso a los datos
- Mi Cuenta
- Lograr
- a través de
- la columna Acción
- acciones
- real
- add
- adicional
- adición
- Adicionales
- Admin
- administradores
- avanzado
- Ventaja
- en contra
- Todos
- permitir
- Permitir
- permite
- a lo largo de
- también
- Amazon
- Amazon Web Services
- an
- Analistas
- Analítico
- Pruebas analíticas
- Analytics
- analizar
- y
- cualquier
- APACHE
- abejas
- Aplicación
- aplicada
- Aplicá
- adecuado
- arquitectura
- somos
- AS
- At
- autenticar
- Autenticación
- autorización
- Automático
- automáticamente
- disponibilidad
- Hoy Disponibles
- AWS
- Formación en la nube de AWS
- Pegamento AWS
- Formación del lago AWS
- basado
- BE
- porque
- esto
- antes
- beneficios
- MEJOR
- mejores
- Big
- Big Data
- ambas
- amplitud
- Navegador
- build
- Construir la
- inteligencia empresarial
- by
- , que son
- PUEDEN
- capacidades
- cases
- catalogar
- Causa
- Cambios
- Elige
- cliente
- clientes
- Soluciones
- Médico
- código
- Columnas
- COM
- completo
- compatibilidad
- competitivos
- completar
- Completado
- integraciones
- exhaustivo
- Contacto
- conexión
- consideraciones
- Consola
- control
- controlado
- rastreador
- Para crear
- creado
- creación
- Referencias
- En la actualidad
- Clientes
- Dallas
- datos
- Lago de datos
- almacenamiento de datos
- basada en datos
- Base de datos
- bases de datos
- conjuntos de datos
- década
- Toma de Decisiones
- Predeterminado
- entregar
- Delta
- De demostración
- democratiza
- diseño
- detallado
- una experiencia diferente
- directamente
- discapacitados
- desastre
- descubrimiento
- diverso
- sí
- No
- descargar
- el lado de la transmisión
- conductor
- durante
- cada una
- facilidad
- facilidad de uso
- más fácil
- pasan fácilmente
- de forma sencilla
- Southern Implants
- editor
- efecto
- de manera eficaz
- esfuerzo
- ya sea
- eliminando
- empodera
- habilitar
- facilita
- permite
- Punto final
- ingeniero
- mejorar
- mejorado
- asegura
- asegurando que
- Participar
- grado empresarial
- error
- Éter (ETH)
- ejemplo
- excepción
- existe
- existente
- expansión
- experience
- explorar
- externo
- facilitando
- FALLO
- RÁPIDO
- Feature
- Caracteristicas
- Federación
- Archive
- archivos
- Nombre
- Flexibilidad
- seguir
- seguido
- siguiendo
- formato
- formación
- Desde
- ser completados
- Obtén
- obtener
- gif
- gobierno
- conceder
- concedido
- concesión
- Grupo procesos
- Manijas
- Tienen
- he
- ayudando
- ayuda
- Alta
- de alto nivel
- Alto rendimiento
- Cómo
- Como Hacer
- Sin embargo
- HTML
- http
- HTTPS
- AMI
- ICON
- Identidad
- ilustra
- implementación
- in
- Incluye
- INSTRUMENTO individual
- energético
- líder de la industria
- información
- inicial
- Insights
- ejemplo
- Instrucciones
- integrar
- integración
- Intelligence
- Introducido
- IT
- SUS
- jpg
- labs
- lago
- paisaje
- large
- Gran escala
- más reciente
- líder
- líder
- APRENDE:
- Abandonar
- Nivel
- como
- Lista
- Ubicación
- Ubicaciones
- log
- conectado
- Inicie sesión
- por más tiempo
- mantener
- el mantenimiento de
- para lograr
- HACE
- gestionan
- gestionado
- Management
- gerente
- obligatorio
- manual
- Puede..
- medidas
- los mecanismos de
- Método
- ML
- modelo
- modernizar
- más,
- múltiples
- debe
- nombre
- Llamado
- Navegación
- necesario
- ¿ Necesita ayuda
- Nuevo
- no
- ahora
- número
- objeto
- objetos
- se produjo
- of
- Ofertas
- OCTA
- on
- , solamente
- Optimiza
- Opciones
- or
- organización
- para las fiestas.
- Organizado
- propiedad
- .
- cristal
- parámetro
- parte
- socios
- Pasando (Paso)
- Contraseña
- para
- realizar
- actuación
- realiza
- permiso
- permisos
- Colocar
- plataforma
- Plataformas
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- Por favor
- plugin
- políticas
- política
- Publicación
- poderoso
- preferido
- requisitos previos
- presente
- Vista previa
- anterior
- Director de la escuela
- priorizar
- privilegios
- tratamiento
- Producto
- gestión de producto
- Producción
- Mi Perfil
- proporcionar
- previsto
- proveedor
- proporciona un
- proporcionando
- fines
- consultas
- con rapidez
- Leer
- ready
- en tiempo real
- recomendado
- recuperación
- referencia
- regiones
- confianza
- recordarlo
- reporte
- Requisitos
- requisito
- requiere
- Recurso
- Recursos
- respuesta
- tiempos de respuesta
- Haga clic con el botón
- Función
- También soy miembro del cuerpo docente de World Extreme Medicine (WEM) y embajadora europea de igualdad para The Transformational Travel Council (TTC). En mi tiempo libre, soy una incansable aventurera, escaladora, patrona de día, buceadora y defensora de la igualdad de género en el deporte y la aventura. En XNUMX, fundé Almas Libres, una ONG nacida para involucrar, educar y empoderar a mujeres y niñas a través del deporte urbano, la cultura y la tecnología.
- Ejecutar
- Escala
- guión
- escenarios
- sin costura
- sin problemas
- Segundo
- Sección
- EN LINEA
- medidas de seguridad
- ver
- seleccionar
- mayor
- Sin servidor
- de coches
- Servicios
- set
- pólipo
- ajustes
- Configure
- tienes
- Mostrar
- mostró
- mostrado
- Shows
- sencillos
- simplificar
- habilidad
- Instantánea
- So
- únicamente
- a medida
- Soluciones
- sofisticado
- Fuentes
- especialista
- SQL
- montón
- estándar
- Posicionamiento
- paso
- pasos
- STORAGE
- almacenados
- esforzarse
- estructurado
- tal
- SOPORTE
- Soportado
- Apoyar
- soportes
- seguro
- sintaxis
- mesa
- ETIQUETA
- ¡Prepárate!
- técnicas
- Tecnologías
- tener
- Texas
- que
- esa
- La
- la seguridad
- su
- luego
- Estas
- ellos
- Código
- terceros.
- así
- miles
- veces
- a
- hoy
- de hoy
- del IRS
- parte superior
- descubrir
- bajo
- unificado
- insólito
- Actualizar
- Enlance
- us
- usabilidad
- Uso
- utilizan el
- usado
- Usuario
- usuarios
- usando
- utilizar
- VALIDAR
- Valioso
- variedad
- diversos
- versión
- quieres
- Manejo de
- we
- web
- servicios web
- cuando
- que
- mientras
- QUIENES
- seguirá
- sin
- flujo de trabajo
- Talleres
- mundo
- años
- Usted
- tú
- zephyrnet
- Zip