El análisis exploratorio de datos (EDA) es una tarea común que realizan los analistas de negocios para descubrir patrones, comprender relaciones, validar suposiciones e identificar anomalías en sus datos. En el aprendizaje automático (ML), es importante comprender primero los datos y sus relaciones antes de entrar en la creación de modelos. Los ciclos tradicionales de desarrollo de ML a veces pueden llevar meses y requieren habilidades avanzadas de ciencia de datos e ingeniería de ML, mientras que las soluciones de ML sin código pueden ayudar a las empresas a acelerar la entrega de soluciones de ML a días o incluso horas.
Lienzo de Amazon SageMaker es una herramienta de aprendizaje automático sin código que ayuda a los analistas de negocios a generar predicciones precisas de aprendizaje automático sin tener que escribir código o sin necesidad de experiencia en aprendizaje automático. Canvas proporciona una interfaz visual fácil de usar para cargar, limpiar y transformar los conjuntos de datos, seguido de la creación de modelos ML y la generación de predicciones precisas.
En esta publicación, explicamos cómo realizar EDA para obtener una mejor comprensión de sus datos antes de construir su modelo ML, gracias a las visualizaciones avanzadas integradas de Canvas. Estas visualizaciones lo ayudan a analizar las relaciones entre las características en sus conjuntos de datos y comprender mejor sus datos. Esto se hace de manera intuitiva, con la capacidad de interactuar con los datos y descubrir información que puede pasar desapercibida con consultas ad hoc. Se pueden crear rápidamente a través del 'Visualizador de datos' dentro de Canvas antes de construir y entrenar modelos ML.
Resumen de la solución
Estas visualizaciones se suman a la gama de capacidades para la preparación y exploración de datos que ya ofrece Canvas, incluida la capacidad de corregir valores faltantes y reemplazar valores atípicos; filtrar, unir y modificar conjuntos de datos; y extraer valores de tiempo específicos de las marcas de tiempo. Para obtener más información sobre cómo Canvas puede ayudarlo a limpiar, transformar y preparar su conjunto de datos, consulte Prepare datos con transformaciones avanzadas.
Para nuestro caso de uso, analizamos por qué los clientes abandonan cualquier negocio e ilustramos cómo EDA puede ayudar desde el punto de vista de un analista. El conjunto de datos que utilizamos en esta publicación es un conjunto de datos sintéticos de un operador de telefonía móvil de telecomunicaciones para la predicción de abandono de clientes que puede descargar (abandono.csv), o traes tu propio conjunto de datos para experimentar. Para obtener instrucciones sobre cómo importar su propio conjunto de datos, consulte Importación de datos en Amazon SageMaker Canvas.
Requisitos previos
Siga las instrucciones en Requisitos previos para configurar Amazon SageMaker Canvas antes de continuar.
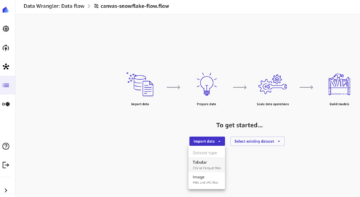
Importe su conjunto de datos a Canvas
Para importar el conjunto de datos de muestra a Canvas, complete los siguientes pasos:
- Inicie sesión en Canvas como usuario comercialPrimero, cargamos el conjunto de datos mencionado anteriormente desde nuestra computadora local a Canvas. Si desea utilizar otras fuentes, como Desplazamiento al rojo de Amazon, Referirse a Conectarse a una fuente de datos externa.
- Elige Importa.

- Elige Subir, A continuación, elija Seleccione archivos de su computadora.
- Seleccione su conjunto de datos (churn.csv) y elija Importar fechas.

- Seleccione el conjunto de datos y elija Crear modelo.

- Nombre del modelo, ingrese un nombre (para esta publicación, le hemos dado el nombre de predicción Churn).
- Elige Crear.

Tan pronto como seleccione su conjunto de datos, se le presenta una descripción general que describe los tipos de datos, los valores faltantes, los valores no coincidentes, los valores únicos y los valores medios o modales de las columnas respectivas.
Desde la perspectiva de EDA, puede observar que no faltan valores o no coinciden en el conjunto de datos. Como analista de negocios, es posible que desee obtener una visión inicial de la creación del modelo incluso antes de comenzar la exploración de datos para identificar cómo funcionará el modelo y qué factores contribuyen al rendimiento del modelo. Canvas le brinda la capacidad de obtener información de sus datos antes de crear un modelo al obtener una vista previa del modelo. - Antes de realizar cualquier exploración de datos, elija Modelo de vista previa.

- Seleccione la columna para predecir (abandono). Canvas detecta automáticamente que se trata de una predicción de dos categorías.
- Elige Modelo de vista previa. SageMaker Canvas usa un subconjunto de sus datos para construir un modelo rápidamente para verificar si sus datos están listos para generar una predicción precisa. Con este modelo de muestra, puede comprender la precisión del modelo actual y el impacto relativo de cada columna en las predicciones.
La siguiente captura de pantalla muestra nuestra vista previa.

La vista previa del modelo indica que el modelo predice el objetivo correcto (¿abandono?) el 95.6 % de las veces. También puede ver el impacto de la columna inicial (la influencia que tiene cada columna en la columna de destino). Hagamos un poco de exploración, visualización y transformación de datos, y luego procedamos a construir un modelo.
Exploración de datos
Canvas ya proporciona algunas visualizaciones básicas comunes, como la distribución de datos en una vista de cuadrícula en el Construcción pestaña. Estos son excelentes para obtener una descripción general de alto nivel de los datos, comprender cómo se distribuyen los datos y obtener una descripción general resumida del conjunto de datos.
Como analista empresarial, es posible que necesite obtener información de alto nivel sobre cómo se distribuyen los datos y cómo se refleja la distribución en la columna de destino (abandono) para comprender fácilmente la relación de datos antes de crear el modelo. Ahora puedes elegir Vista en cuadrícula para obtener una visión general de la distribución de datos.
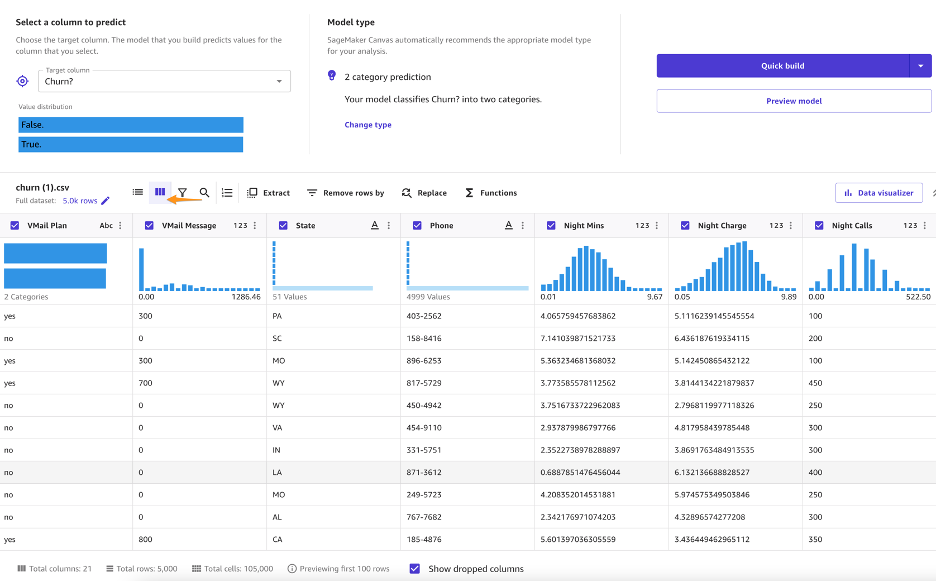
La siguiente captura de pantalla muestra la descripción general de la distribución del conjunto de datos.

Podemos hacer las siguientes observaciones:
- El teléfono adquiere demasiados valores únicos para tener un uso práctico. Sabemos que el teléfono es una identificación de cliente y no queremos crear un modelo que pueda considerar a clientes específicos, sino aprender en un sentido más general lo que podría conducir a la deserción. Puede eliminar esta variable.
- La mayoría de las características numéricas están bien distribuidas, siguiendo un Gauss curva de campana. En ML, desea que los datos se distribuyan normalmente porque cualquier variable que muestre una distribución normal se puede pronosticar con mayor precisión.
Profundicemos y veamos las visualizaciones avanzadas disponibles en Canvas.
Visualización de datos
Como analista de negocios, desea ver si existen relaciones entre los elementos de datos y cómo se relacionan con la rotación. Con Canvas, puede explorar y visualizar sus datos, lo que lo ayuda a obtener información avanzada sobre sus datos antes de crear sus modelos de ML. Puede visualizar utilizando diagramas de dispersión, gráficos de barras y diagramas de caja, que pueden ayudarlo a comprender sus datos y descubrir las relaciones entre las características que podrían afectar la precisión del modelo.
Para comenzar a crear sus visualizaciones, complete los siguientes pasos:
- En Construcción pestaña de la aplicación Canvas, elija visualizador de datos.

Un acelerador clave de la visualización en Canvas es el visualizador de datos. Cambiemos el tamaño de la muestra para tener una mejor perspectiva.
- Elija el número de filas junto a Ejemplo de visualización.
- Utilice el control deslizante para seleccionar el tamaño de muestra deseado.

- Elige Actualizar para confirmar el cambio en el tamaño de su muestra.
Es posible que desee cambiar el tamaño de la muestra en función de su conjunto de datos. En algunos casos, es posible que tenga entre cientos y miles de filas donde puede seleccionar todo el conjunto de datos. En algunos casos, puede tener varios miles de filas, en cuyo caso puede seleccionar unos cientos o miles de filas según su caso de uso.

Un diagrama de dispersión muestra la relación entre dos variables cuantitativas medidas para los mismos individuos. En nuestro caso, es importante comprender la relación entre los valores para verificar la correlación.
Debido a que tenemos llamadas, minutos y carga, trazaremos la correlación entre ellos para el día, la tarde y la noche.
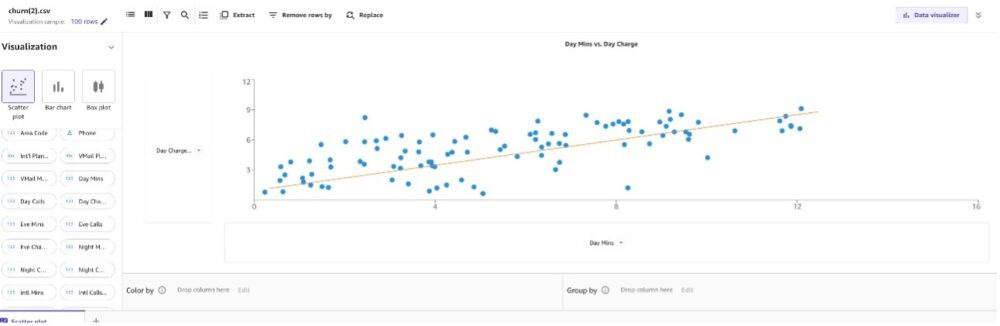
Primero, creemos un gráfico de dispersión entre el cargo por día y los minutos por día.

Podemos observar que a medida que aumenta Day Mins, Day Charge también aumenta.
Lo mismo se aplica a las llamadas nocturnas.

Las llamadas nocturnas también tienen el mismo patrón.

Debido a que los minutos y la carga parecen aumentar linealmente, puede observar que tienen una alta correlación entre sí. La inclusión de estos pares de características en algunos algoritmos de ML puede requerir almacenamiento adicional y reducir la velocidad del entrenamiento, y tener información similar en más de una columna puede hacer que el modelo enfatice demasiado los impactos y genere un sesgo no deseado en el modelo. Quitemos una característica de cada uno de los pares altamente correlacionados: Carga diurna del par con Minutos diurnos, Carga nocturna del par con Minutos nocturnos y Carga internacional del par con Minutos internacionales.
Saldo y variación de datos
Un gráfico de barras es un gráfico entre una variable categórica en el eje x y una variable numérica en el eje y para explorar la relación entre ambas variables. Vamos a crear un gráfico de barras para ver cómo se distribuyen las llamadas en nuestra columna objetivo Churn for True y False. Elegir Gráfico de barras y arrastre y suelte las llamadas diarias y abandone el eje y y el eje x, respectivamente.
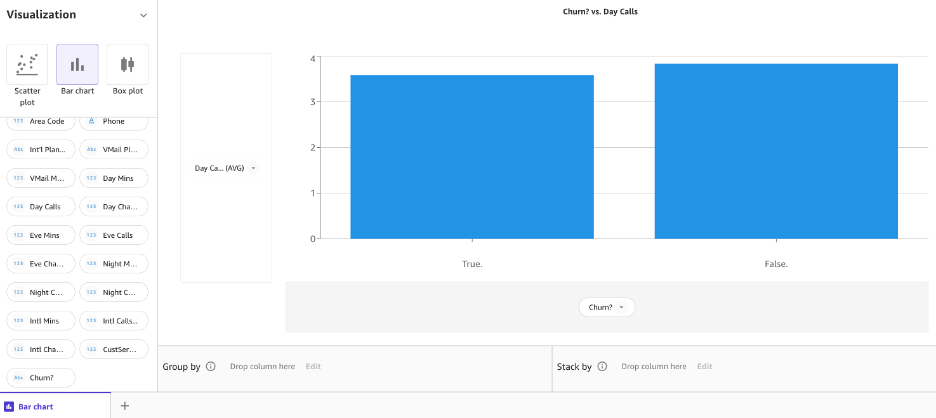
Ahora, vamos a crear el mismo gráfico de barras para las llamadas nocturnas frente al abandono.
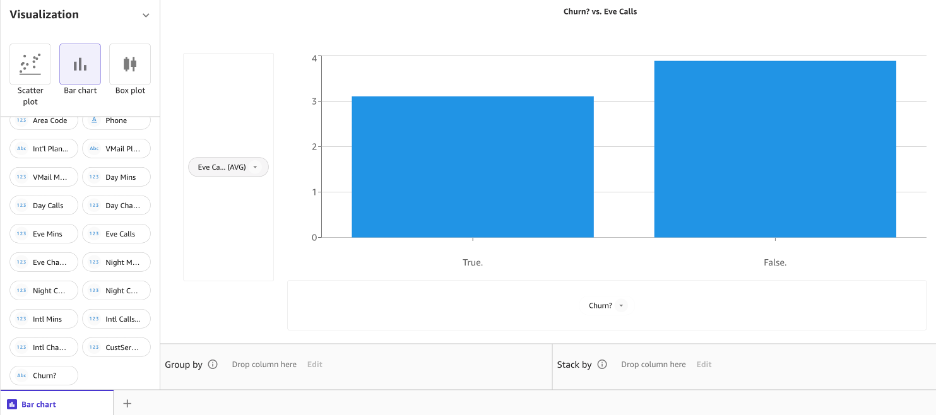
A continuación, creemos un gráfico de barras para las llamadas nocturnas frente al abandono.

Parece que hay una diferencia de comportamiento entre los clientes que se han ido y los que no.
Los diagramas de caja son útiles porque muestran diferencias en el comportamiento de los datos por clase (cambio o no). Debido a que vamos a predecir la rotación (columna de destino), vamos a crear un gráfico de caja de algunas características en comparación con nuestra columna de destino para inferir estadísticas descriptivas en el conjunto de datos, como la media, el máximo, el mínimo, la mediana y los valores atípicos.
Elige Diagrama de caja y arrastre y suelte Day mins y Churn en el eje y y el eje x, respectivamente.

También puede probar el mismo enfoque con otras columnas contra nuestra columna de destino (abandono).
Ahora vamos a crear un diagrama de caja de los minutos diarios frente a las llamadas de servicio al cliente para comprender cómo las llamadas de servicio al cliente se extienden a lo largo del valor de los minutos diarios. Puede ver que las llamadas de servicio al cliente no tienen una dependencia o correlación en el valor de los minutos del día.

A partir de nuestras observaciones, podemos determinar que el conjunto de datos está bastante equilibrado. Queremos que los datos se distribuyan uniformemente entre valores verdaderos y falsos para que el modelo no esté sesgado hacia un valor.
Transformaciones
Según nuestras observaciones, eliminamos la columna Teléfono porque es solo un número de cuenta y las columnas Cargo diurno, Cargo vespertino y Cargo nocturno porque contienen información superpuesta, como las columnas de minutos, pero podemos volver a ejecutar una vista previa para confirmar.

Después del análisis y la transformación de datos, volvamos a obtener una vista previa del modelo.

Puede observar que la precisión estimada del modelo cambió de 95.6 % a 93.6 % (esto podría variar), sin embargo, el impacto de la columna (importancia de la función) para columnas específicas ha cambiado considerablemente, lo que mejora la velocidad de entrenamiento, así como la influencia de las columnas en la predicción a medida que avanzamos a los siguientes pasos de la construcción del modelo. Nuestro conjunto de datos no requiere una transformación adicional, pero si lo necesita, puede aprovechar Transformaciones de datos de ML para limpiar, transformar y preparar sus datos para la creación de modelos.
Construye el modelo
Ahora puede proceder a construir un modelo y analizar los resultados. Para obtener más información, consulte Prediga la rotación de clientes con aprendizaje automático sin código utilizando Amazon SageMaker Canvas.
Limpiar
Para evitar incurrir en el futuro cargos de sesión, finalizar la sesión de Lona.

Conclusión
En esta publicación, mostramos cómo puede usar las capacidades de visualización de Canvas para EDA para comprender mejor sus datos antes de la construcción del modelo, crear modelos ML precisos y generar predicciones utilizando una interfaz visual sin código, de apuntar y hacer clic.
Acerca de los autores
 Rajakumar Sampathkumar es Gerente Técnico Principal de Cuentas en AWS, brinda orientación a los clientes sobre la alineación de la tecnología comercial y apoya la reinvención de sus modelos y procesos de operación en la nube. Le apasiona la nube y el aprendizaje automático. Raj también es especialista en aprendizaje automático y trabaja con clientes de AWS para diseñar, implementar y administrar sus cargas de trabajo y arquitecturas de AWS.
Rajakumar Sampathkumar es Gerente Técnico Principal de Cuentas en AWS, brinda orientación a los clientes sobre la alineación de la tecnología comercial y apoya la reinvención de sus modelos y procesos de operación en la nube. Le apasiona la nube y el aprendizaje automático. Raj también es especialista en aprendizaje automático y trabaja con clientes de AWS para diseñar, implementar y administrar sus cargas de trabajo y arquitecturas de AWS.
 Raúl Nabera es consultor de análisis de datos en los servicios profesionales de AWS. Su trabajo actual se centra en permitir que los clientes creen sus cargas de trabajo de datos y aprendizaje automático en AWS. En su tiempo libre, le gusta jugar al cricket y al voleibol.
Raúl Nabera es consultor de análisis de datos en los servicios profesionales de AWS. Su trabajo actual se centra en permitir que los clientes creen sus cargas de trabajo de datos y aprendizaje automático en AWS. En su tiempo libre, le gusta jugar al cricket y al voleibol.
 Raviteja Yelamanchilí es Arquitecto de Soluciones Empresariales con Amazon Web Services con sede en Nueva York. Trabaja con grandes clientes empresariales de servicios financieros para diseñar e implementar aplicaciones altamente seguras, escalables, confiables y rentables en la nube. Aporta más de 11 años de experiencia en gestión de riesgos, consultoría tecnológica, análisis de datos y aprendizaje automático. Cuando no está ayudando a los clientes, disfruta viajar y jugar PS5.
Raviteja Yelamanchilí es Arquitecto de Soluciones Empresariales con Amazon Web Services con sede en Nueva York. Trabaja con grandes clientes empresariales de servicios financieros para diseñar e implementar aplicaciones altamente seguras, escalables, confiables y rentables en la nube. Aporta más de 11 años de experiencia en gestión de riesgos, consultoría tecnológica, análisis de datos y aprendizaje automático. Cuando no está ayudando a los clientes, disfruta viajar y jugar PS5.
- Avanzado (300)
- AI
- arte ai
- generador de arte ai
- robot ai
- Amazon SageMaker
- Lienzo de Amazon SageMaker
- inteligencia artificial
- certificación de inteligencia artificial
- inteligencia artificial en banca
- robots de inteligencia artificial
- robots de inteligencia artificial
- software de inteligencia artificial
- Aprendizaje automático de AWS
- blockchain
- conferencia blockchain ai
- Coingenius
- inteligencia artificial conversacional
- criptoconferencia ai
- de dall
- deep learning
- google ai
- máquina de aprendizaje
- Platón
- platón ai
- Inteligencia de datos de Platón
- Juego de Platón
- PlatónDatos
- juego de platos
- escala ia
- sintaxis
- Procedimientos técnicos
- zephyrnet