iceberg apache es un formato de tabla abierta para conjuntos de datos analíticos muy grandes, que captura información de metadatos sobre el estado de los conjuntos de datos a medida que evolucionan y cambian con el tiempo. Agrega tablas a motores de cómputo, incluidos Spark, Trino, PrestoDB, Flink y Hive, utilizando un formato de tabla de alto rendimiento que funciona como una tabla SQL. Iceberg se ha vuelto muy popular por su soporte para transacciones ACID en lagos de datos y características como evolución de esquemas y particiones, viaje en el tiempo y reversión.
La integración de Apache Iceberg es compatible con los servicios de análisis de AWS, incluidos EMR de Amazon, Atenea amazónicay Pegamento AWS. Amazon EMR puede aprovisionar clústeres con Spark, Hive, Trino y Flink que pueden ejecutar Iceberg. A partir de la versión 6.5.0 de Amazon EMR, puede use Iceberg con su clúster EMR sin requerir una acción de arranque. A principios de 2022, AWS anunció la disponibilidad general de las transacciones ACID de Athena, con la tecnología de Apache Iceberg. El recientemente lanzado Motor de consultas Athena versión 3 proporciona una mejor integración con el formato de mesa Iceberg. AWS Glue 3.0 y posterior es compatible con el marco Apache Iceberg para lagos de datos.
En esta publicación, analizamos lo que los clientes quieren en los lagos de datos modernos y cómo Apache Iceberg ayuda a abordar las necesidades de los clientes. Luego, analizamos una solución para crear un lago de datos Iceberg de alto rendimiento y en evolución en Servicio de almacenamiento simple de Amazon (Amazon S3) y procese datos incrementales mediante la ejecución de instrucciones SQL de inserción, actualización y eliminación. Finalmente, le mostramos cómo ajustar el rendimiento del proceso para mejorar el rendimiento de lectura y escritura.
Cómo Apache Iceberg aborda lo que los clientes quieren en los lagos de datos modernos
Cada vez más clientes crean lagos de datos, con datos estructurados y no estructurados, para admitir muchos usuarios, aplicaciones y herramientas de análisis. Existe una mayor necesidad de lagos de datos que admitan funciones similares a bases de datos, como transacciones ACID, actualizaciones y eliminaciones a nivel de registros, viajes en el tiempo y reversiones. Apache Iceberg está diseñado para admitir estas funciones en lagos de datos rentables a escala de petabytes en Amazon S3.
Apache Iceberg aborda las necesidades de los clientes mediante la captura de información rica en metadatos sobre el conjunto de datos en el momento en que se crean los archivos de datos individuales. Hay tres capas en la arquitectura de una tabla Iceberg: el catálogo Iceberg, la capa de metadatos y la capa de datos, como se muestra en la siguiente figura (fuente).

El catálogo de Iceberg almacena el puntero de metadatos al archivo de metadatos de la tabla actual. Cuando una consulta de selección lee una tabla Iceberg, el motor de consulta primero va al catálogo de Iceberg y luego recupera la ubicación del archivo de metadatos actual. Cada vez que hay una actualización de la tabla Iceberg, se crea una nueva instantánea de la tabla y el puntero de metadatos apunta al archivo de metadatos de la tabla actual.
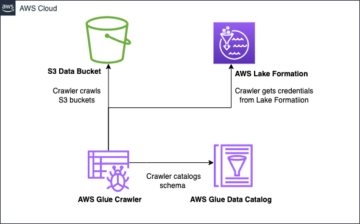
El siguiente es un ejemplo de catálogo de Iceberg con implementación de AWS Glue. Puede ver el nombre de la base de datos, la ubicación (ruta S3) de la tabla Iceberg y la ubicación de los metadatos.

La capa de metadatos tiene tres tipos de archivos: el archivo de metadatos, la lista de manifiesto y el archivo de manifiesto en una jerarquía. En la parte superior de la jerarquía se encuentra el archivo de metadatos, que almacena información sobre el esquema de la tabla, la información de partición y las instantáneas. La instantánea apunta a la lista de manifiestos. La lista de manifiestos tiene información sobre cada archivo de manifiesto que compone la instantánea, como la ubicación del archivo de manifiesto, las particiones a las que pertenece y los límites inferior y superior de las columnas de partición para los archivos de datos que rastrea. El archivo de manifiesto realiza un seguimiento de los archivos de datos, así como detalles adicionales sobre cada archivo, como el formato del archivo. Los tres archivos funcionan en una jerarquía para realizar un seguimiento de las instantáneas, el esquema, la partición, las propiedades y los archivos de datos en una tabla Iceberg.
La capa de datos tiene los archivos de datos individuales de la tabla Iceberg. Iceberg admite una amplia gama de formatos de archivo, incluidos Parquet, ORC y Avro. Debido a que la tabla Iceberg realiza un seguimiento de los archivos de datos individuales en lugar de solo señalar la ubicación de la partición con los archivos de datos, aísla las operaciones de escritura de las operaciones de lectura. Puede escribir los archivos de datos en cualquier momento, pero solo confirmar el cambio de forma explícita, lo que crea una nueva versión de los archivos de instantáneas y metadatos.
Resumen de la solución
En esta publicación, lo guiaremos a través de una solución para crear un lago de datos Apache Iceberg de alto rendimiento en Amazon S3; procesar datos incrementales con instrucciones SQL de inserción, actualización y eliminación; y ajuste la tabla Iceberg para mejorar el rendimiento de lectura y escritura. El siguiente diagrama ilustra la arquitectura de la solución.

Para demostrar esta solución, usamos el Amazon Comentarios de clientes conjunto de datos en un depósito S3 (s3://amazon-reviews-pds/parquet/). En un caso de uso real, serían datos sin procesar almacenados en su depósito S3. Podemos verificar el tamaño de los datos con el siguiente código en el Interfaz de línea de comandos de AWS (CLI de AWS):
El recuento total de objetos es 430 y el tamaño total es 47.4 GiB.
Para configurar y probar esta solución, completamos los siguientes pasos de alto nivel:
- Configure un depósito S3 en la zona seleccionada para almacenar datos convertidos en formato de tabla Iceberg.
- Inicie un clúster de EMR con las configuraciones adecuadas para Apache Iceberg.
- Cree un cuaderno en EMR Studio.
- Configure la sesión de Spark para Apache Iceberg.
- Convierta los datos al formato de tabla Iceberg y mueva los datos a la zona seleccionada.
- Ejecute consultas de inserción, actualización y eliminación en Athena para procesar datos incrementales.
- Realice ajustes de rendimiento.
Requisitos previos
Para seguir este tutorial, debe tener un Cuenta de AWS con una Gestión de identidades y accesos de AWS (IAM) que tiene acceso suficiente para aprovisionar los recursos necesarios.
Configure el depósito de S3 para los datos de Iceberg en la zona seleccionada de su lago de datos
Elija la región en la que desea crear el depósito de S3 y proporcione un nombre único:
Inicie un clúster de EMR para ejecutar trabajos de Iceberg con Spark
Puede crear un clúster de EMR desde el Consola de administración de AWS, la CLI de Amazon EMR o Kit de desarrollo en la nube de AWS (CDK de AWS). Para esta publicación, lo guiaremos a través de cómo crear un clúster de EMR desde la consola.
- En la consola de Amazon EMR, elija Crear clúster.
- Elige Opciones avanzadas.
- Configuración del software, elija la versión más reciente de Amazon EMR. A partir de enero de 2023, la última versión es 6.9.0. Iceberg requiere la versión 6.5.0 y superior.
- Seleccione Puerta de enlace empresarial de Jupyter y Spark como el software a instalar.
- Editar la configuración del software, seleccione Entrar en configuración e introduzca
[{"classification":"iceberg-defaults","properties":{"iceberg.enabled":true}}]. - Deje otras configuraciones en sus valores predeterminados y elija Siguiente.

- Materiales, utilice la configuración predeterminada.
- Elige Siguiente.
- Nombre del clúster, ingresa un nombre. Usamos
iceberg-blog-cluster. - Deje las configuraciones restantes sin cambios y elija Siguiente.
- Elige Crear clúster.
Crear un cuaderno en EMR Studio
Ahora lo guiaremos a través de cómo crear un cuaderno en EMR Studio desde la consola.
- En la consola de IAM, crear un rol de servicio de EMR Studio.
- En la consola de Amazon EMR, elija Estudio EMR.
- Elige ¡Empieza aquí!.
El ¡Empieza aquí! la página aparece en una nueva pestaña.
- Elige Crear estudio en la nueva pestaña.
- Ingresa un nombre. Usamos iceberg-studio.
- Elija la misma VPC y subred que las del clúster de EMR y el grupo de seguridad predeterminado.
- Elige Administración de acceso e identidad de AWS (IAM) para la autenticación y elija el rol de servicio de EMR Studio que acaba de crear.
- Elija una ruta de S3 para Copia de seguridad de espacios de trabajo.
- Elige Crear estudio.
- Después de crear Studio, elija la URL de acceso de Studio.
- En el tablero de EMR Studio, elija Crear espacio de trabajo.
- Introduzca un nombre para su espacio de trabajo. Usamos
iceberg-workspace. - Expandir Configuracion avanzada y elige Asociar Workspace a un clúster de EMR.
- Elija el clúster de EMR que creó anteriormente.
- Elige Crear espacio de trabajo.
- Elija el nombre del espacio de trabajo para abrir una nueva pestaña.
En el panel de navegación, hay un cuaderno que tiene el mismo nombre que el Área de trabajo. En nuestro caso, es iceberg-workspace.
- Abra el cuaderno.
- Cuando se le pida que elija un kernel, elija Spark.
Configurar una sesión de Spark para Apache Iceberg
Utilice el siguiente código y proporcione su propio nombre de depósito de S3:
Esto establece las siguientes configuraciones de sesión de Spark:
- chispa.sql.catalog.demo – Registra un catálogo de Spark llamado demo, que utiliza el complemento de catálogo de Iceberg Spark.
- chispa.sql.catalog.demo.catalog-impl – El catálogo de demostración de Spark utiliza AWS Glue como catálogo físico para almacenar la información de la tabla y la base de datos de Iceberg.
- chispa.sql.catalog.demo.warehouse – El catálogo de demostración de Spark almacena todos los metadatos y archivos de datos de Iceberg en la ruta raíz definida por esta propiedad:
s3://iceberg-curated-blog-data. - chispa.sql.extensiones – Agrega compatibilidad con las extensiones SQL de Iceberg Spark, lo que le permite ejecutar procedimientos de Iceberg Spark y algunos comandos SQL exclusivos de Iceberg (usará esto en un paso posterior).
- chispa.sql.catalog.demo.io-impl – Iceberg permite a los usuarios escribir datos en Amazon S3 a través de S3FileIO. El catálogo de datos de AWS Glue utiliza este FileIO de forma predeterminada, y otros catálogos pueden cargar este FileIO mediante la propiedad de catálogo io-impl.
Convertir datos a formato de tabla Iceberg
Puede usar Spark en Amazon EMR o Athena para cargar la tabla Iceberg. En la sesión de Spark del cuaderno EMR Studio Workspace, ejecute los siguientes comandos para cargar los datos:
Después de ejecutar el código, debe encontrar dos prefijos creados en la ruta S3 de su almacén de datos (s3://iceberg-curated-blog-data/reviews.db/all_reviews): datos y metadatos.
Procese datos incrementales mediante instrucciones SQL de inserción, actualización y eliminación en Athena
Athena es un motor de consulta sin servidor que puede usar para realizar tareas de lectura, escritura, actualización y optimización en tablas Iceberg. Para demostrar cómo el formato del lago de datos Apache Iceberg admite la ingesta de datos incrementales, ejecutamos declaraciones SQL de inserción, actualización y eliminación en el lago de datos.
Vaya a la consola de Athena y elija Editor de consultas. Si es la primera vez que utiliza el editor de consultas de Athena, debe configurar la ubicación del resultado de la consulta para ser el depósito S3 que creó anteriormente. Debería poder ver que la tabla reviews.all_reviews está disponible para realizar consultas. Ejecute la siguiente consulta para verificar que ha cargado correctamente la tabla Iceberg:
Procese datos incrementales ejecutando instrucciones SQL de inserción, actualización y eliminación:
Ajuste de rendimiento
En esta sección, analizamos diferentes formas de mejorar el rendimiento de lectura y escritura de Apache Iceberg.
Configurar las propiedades de la tabla Apache Iceberg
Apache Iceberg es un formato de tabla y admite propiedades de tabla para configurar el comportamiento de la tabla, como lectura, escritura y catalogación. Puede mejorar el rendimiento de lectura y escritura en las tablas Iceberg ajustando las propiedades de la tabla.
Por ejemplo, si nota que escribe demasiados archivos pequeños para una tabla Iceberg, puede configurar el tamaño del archivo de escritura para escribir menos archivos pero de mayor tamaño, para ayudar a mejorar el rendimiento de las consultas.
| Propiedades | Predeterminado | Descripción |
| escribir.target-file-size-bytes | 536870912 (512MB) | Controla el tamaño de los archivos generados para apuntar a esta cantidad de bytes |
Utilice el siguiente código para modificar el formato de la tabla:
Particionamiento y clasificación
Para que una consulta se ejecute rápidamente, cuantos menos datos se lean, mejor. Iceberg aprovecha los ricos metadatos que captura en el momento de la escritura y facilita técnicas como la planificación de análisis, la partición, la poda y las estadísticas a nivel de columna, como valores mínimos/máximos, para omitir archivos de datos que no tienen registros de coincidencia. Le mostramos cómo funcionan la planificación y el particionamiento del análisis de consultas en Iceberg y cómo los usamos para mejorar el rendimiento de las consultas.
Planificación de exploración de consultas
Para una consulta dada, el primer paso en un motor de consultas es la planificación de exploración, que es el proceso para encontrar los archivos en una tabla necesarios para una consulta. La planificación en una tabla Iceberg es muy eficiente, porque los metadatos enriquecidos de Iceberg se pueden usar para eliminar archivos de metadatos que no son necesarios, además de filtrar archivos de datos que no contienen datos coincidentes. En nuestras pruebas, observamos que Athena escaneó el 50 % o menos de los datos para una consulta determinada en una tabla Iceberg en comparación con los datos originales antes de la conversión al formato Iceberg.
Hay dos tipos de filtrado:
- Filtrado de metadatos – Iceberg utiliza dos niveles de metadatos para rastrear los archivos en una instantánea: la lista de manifiesto y los archivos de manifiesto. Primero utiliza la lista de manifiestos, que actúa como un índice de los archivos de manifiesto. Durante la planificación, Iceberg filtra los manifiestos utilizando el rango de valores de partición en la lista de manifiestos sin leer todos los archivos de manifiesto. Luego usa archivos de manifiesto seleccionados para obtener archivos de datos.
- Filtrado de datos – Después de seleccionar la lista de archivos de manifiesto, Iceberg usa los datos de partición y las estadísticas de nivel de columna para cada archivo de datos almacenado en los archivos de manifiesto para filtrar los archivos de datos. Durante la planificación, los predicados de consulta se convierten en predicados en los datos de partición y se aplican primero a los archivos de datos de filtro. Luego, las estadísticas de columna, como los recuentos de valores a nivel de columna, los recuentos nulos, los límites inferiores y los límites superiores, se usan para filtrar los archivos de datos que no pueden coincidir con el predicado de la consulta. Mediante el uso de límites superiores e inferiores para filtrar archivos de datos en el momento de la planificación, Iceberg mejora enormemente el rendimiento de las consultas.
Particionamiento y clasificación
La partición es una forma de agrupar registros con los mismos valores de columna clave juntos por escrito. El beneficio de la partición es consultas más rápidas que acceden solo a una parte de los datos, como se explicó anteriormente en la planificación del análisis de consultas: filtrado de datos. Iceberg simplifica la partición al admitir la partición oculta, de la misma manera que Iceberg produce valores de partición tomando un valor de columna y, opcionalmente, transformándolo.
En nuestro caso de uso, primero ejecutamos la siguiente consulta en la tabla Iceberg no particionada. Luego dividimos la tabla Iceberg por la categoría de las reseñas, que se usará en la condición de consulta WHERE para filtrar los registros. Con la partición, la consulta podría escanear muchos menos datos. Ver el siguiente código:
Ejecute la siguiente declaración de selección en la tabla all_reviews no particionada frente a la tabla particionada para ver la diferencia de rendimiento:
La siguiente tabla muestra la mejora del rendimiento de la partición de datos, con una mejora del rendimiento de aproximadamente un 50 % y un 70 % menos de datos escaneados.
| Nombre del conjunto de datos | Conjunto de datos no particionado | Conjunto de datos particionado |
| Tiempo de ejecución (segundos) | 8.20 | 4.25 |
| Datos escaneados (MB) | 131.55 | 33.79 |
Tenga en cuenta que el tiempo de ejecución es el tiempo de ejecución promedio con múltiples ejecuciones en nuestra prueba.
Vimos una buena mejora en el rendimiento después de la partición. Sin embargo, esto se puede mejorar aún más mediante el uso de estadísticas a nivel de columna de los archivos de manifiesto de Iceberg. Para usar las estadísticas de nivel de columna de manera efectiva, desea ordenar aún más sus registros en función de los patrones de consulta. Ordenar todo el conjunto de datos usando las columnas que se usan a menudo en las consultas reordenará los datos de tal manera que cada archivo de datos termine con un rango único de valores para las columnas específicas. Si estas columnas se utilizan en la condición de consulta, permite que los motores de consulta omitan aún más los archivos de datos, lo que permite consultas aún más rápidas.
Copiar al escribir frente a leer al fusionar
Al implementar la actualización y eliminación en tablas Iceberg en el lago de datos, existen dos enfoques definidos por las propiedades de la tabla Iceberg:
- Copiar en escrito – Con este enfoque, cuando haya cambios en la tabla Iceberg, ya sea actualizaciones o eliminaciones, los archivos de datos asociados con los registros afectados se duplicarán y actualizarán. Los registros se actualizarán o eliminarán de los archivos de datos duplicados. Se creará una nueva instantánea de la tabla Iceberg y apuntará a la versión más reciente de los archivos de datos. Esto hace que las escrituras generales sean más lentas. Puede haber situaciones en las que se necesiten escrituras simultáneas con conflictos, por lo que se debe volver a intentar, lo que aumenta aún más el tiempo de escritura. Por otro lado, al leer los datos, no se necesita ningún proceso adicional. La consulta recuperará datos de la última versión de los archivos de datos.
- Fusionar en lectura – Con este enfoque, cuando haya actualizaciones o eliminaciones en la tabla Iceberg, los archivos de datos existentes no se reescribirán; en su lugar, se crearán nuevos archivos de eliminación para realizar un seguimiento de los cambios. Para las eliminaciones, se creará un nuevo archivo de eliminación con los registros eliminados. Al leer la tabla Iceberg, el archivo de eliminación se aplicará a los datos recuperados para filtrar los registros de eliminación. Para las actualizaciones, se creará un nuevo archivo de eliminación para marcar los registros actualizados como eliminados. Luego se creará un nuevo archivo para esos registros pero con valores actualizados. Al leer la tabla Iceberg, tanto los archivos eliminados como los nuevos se aplicarán a los datos recuperados para reflejar los últimos cambios y producir los resultados correctos. Por lo tanto, para cualquier consulta posterior, se realizará un paso adicional para fusionar los archivos de datos con la eliminación y los nuevos archivos, lo que generalmente aumentará el tiempo de consulta. Por otro lado, las escrituras pueden ser más rápidas porque no es necesario volver a escribir los archivos de datos existentes.
Para probar el impacto de los dos enfoques, puede ejecutar el siguiente código para establecer las propiedades de la tabla Iceberg:
Ejecute las declaraciones SQL de actualización, eliminación y selección en Athena para mostrar la diferencia de tiempo de ejecución para copiar en escritura frente a fusionar en lectura:
La siguiente tabla resume los tiempos de ejecución de las consultas.
| Consulta | Copiar en escrito | Fusionar en lectura | ||||
| ACTUALIZAR | BORRAR | SELECCIONAR | ACTUALIZAR | BORRAR | SELECCIONAR | |
| Tiempo de ejecución (segundos) | 66.251 | 116.174 | 97.75 | 10.788 | 54.941 | 113.44 |
| Datos escaneados (MB) | 494.06 | 3.07 | 137.16 | 494.06 | 3.07 | 137.16 |
Tenga en cuenta que el tiempo de ejecución es el tiempo de ejecución promedio con múltiples ejecuciones en nuestra prueba.
Como muestran los resultados de nuestras pruebas, siempre hay compensaciones en los dos enfoques. El enfoque a utilizar depende de sus casos de uso. En resumen, las consideraciones se reducen a la latencia en la lectura frente a la escritura. Puede consultar la siguiente tabla y tomar la decisión correcta.
| . | Copiar en escrito | Fusionar en lectura |
| Para Agencias y Operadores | Lecturas más rápidas | Escrituras más rápidas |
| Desventajas | Escrituras caras | Mayor latencia en las lecturas |
| Cuándo usarlos | Bueno para lecturas frecuentes, actualizaciones y eliminaciones poco frecuentes o actualizaciones de lotes grandes | Bueno para tablas con actualizaciones y eliminaciones frecuentes |
compactación de datos
Si el tamaño de su archivo de datos es pequeño, podría terminar con miles o millones de archivos en una tabla Iceberg. Esto aumenta drásticamente la operación de E/S y ralentiza las consultas. Además, Iceberg rastrea cada archivo de datos en un conjunto de datos. Más archivos de datos conducen a más metadatos. Esto, a su vez, aumenta la sobrecarga y la operación de E/S al leer archivos de metadatos. Para mejorar el rendimiento de las consultas, se recomienda compactar los archivos de datos pequeños en archivos de datos más grandes.
Al actualizar y eliminar registros en la tabla Iceberg, si se utiliza el enfoque de lectura al fusionar, es posible que termine con muchas eliminaciones pequeñas o nuevos archivos de datos. Ejecutar la compactación combinará todos estos archivos y creará una versión más nueva del archivo de datos. Esto elimina la necesidad de reconciliarlos durante las lecturas. Se recomienda tener trabajos de compactación regulares para impactar las lecturas lo menos posible mientras se mantiene una velocidad de escritura más rápida.
Ejecute el siguiente comando de compactación de datos, luego ejecute la consulta de selección de Athena:
La siguiente tabla compara el tiempo de ejecución antes y después de la compactación de datos. Puede ver una mejora del rendimiento de alrededor del 40%.
| Consulta | Antes de la compactación de datos | Después de la compactación de datos |
| Tiempo de ejecución (segundos) | 97.75 | 32.676 segundos |
| Datos escaneados (MB) | 137.16 m | 189.19 m |
Tenga en cuenta que las consultas de selección se ejecutaron en el all_reviews tabla después de las operaciones de actualización y eliminación, antes y después de la compactación de datos. El tiempo de ejecución es el tiempo de ejecución promedio con múltiples ejecuciones en nuestra prueba.
Limpiar
Después de seguir el tutorial de la solución para realizar los casos de uso, complete los siguientes pasos para limpiar sus recursos y evitar costos adicionales:
- Suelte las tablas y la base de datos de AWS Glue desde Athena o ejecute el siguiente código en su cuaderno:
- En la consola de EMR Studio, elija Espacios de trabajo en el panel de navegación.
- Seleccione el espacio de trabajo que creó y elija Borrar.
- En la consola EMR, navegue hasta el Estudios .
- Seleccione el estudio que creó y elija Borrar.
- En la consola EMR, seleccione Clusters en el panel de navegación.
- Seleccione el clúster y elija Terminar.
- Elimine el depósito de S3 y cualquier otro recurso que haya creado como parte de los requisitos previos para esta publicación.
Conclusión
En esta publicación, presentamos el marco Apache Iceberg y cómo ayuda a resolver algunos de los desafíos que tenemos en un lago de datos moderno. Luego, lo guiamos a través de una solución para procesar datos incrementales en un lago de datos usando Apache Iceberg. Finalmente, nos sumergimos profundamente en el ajuste del rendimiento para mejorar el rendimiento de lectura y escritura para nuestros casos de uso.
Esperamos que esta publicación le brinde información útil para decidir si desea adoptar Apache Iceberg en su solución de lago de datos.
Acerca de los autores
 flora wu es arquitecto residente sénior en AWS Data Lab. Ayuda a los clientes empresariales a crear estrategias de análisis de datos y crear soluciones para acelerar los resultados de sus negocios. En su tiempo libre, le gusta jugar tenis, bailar salsa y viajar.
flora wu es arquitecto residente sénior en AWS Data Lab. Ayuda a los clientes empresariales a crear estrategias de análisis de datos y crear soluciones para acelerar los resultados de sus negocios. En su tiempo libre, le gusta jugar tenis, bailar salsa y viajar.
 Daniel Li es Arquitecto de Soluciones Sr. en Amazon Web Services. Se enfoca en ayudar a los clientes a desarrollar, adoptar e implementar servicios y estrategias en la nube. Cuando no está trabajando, le gusta pasar tiempo al aire libre con su familia.
Daniel Li es Arquitecto de Soluciones Sr. en Amazon Web Services. Se enfoca en ayudar a los clientes a desarrollar, adoptar e implementar servicios y estrategias en la nube. Cuando no está trabajando, le gusta pasar tiempo al aire libre con su familia.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/use-apache-iceberg-in-a-data-lake-to-support-incremental-data-processing/
- 10
- 100
- 11
- 2022
- 2023
- 7
- 9
- a
- Poder
- Sobre
- arriba
- acelerar
- de la máquina
- Gestión de Acceso
- la columna Acción
- hechos
- adición
- Adicionales
- dirección
- direcciones
- Añade
- adoptar
- Ventaja
- Después
- en contra
- Todos
- permite
- hacerlo
- Amazon
- EMR de Amazon
- Amazon Web Services
- Analítico
- Analytics
- y
- anunció
- APACHE
- aplicaciones
- aplicada
- enfoque
- enfoques
- adecuado
- arquitectura
- asociado
- Autenticación
- disponibilidad
- Hoy Disponibles
- promedio
- evitar
- AWS
- Pegamento AWS
- basado
- porque
- a las que has recomendado
- antes
- es el beneficio
- mejores
- entre
- más grande
- Bootstrap
- build
- Construir la
- negocios
- capturas
- Capturando
- case
- cases
- catalogar
- catálogos
- Categoría
- retos
- el cambio
- Cambios
- comprobar
- manera?
- Elige
- clasificación
- Soluciones
- servicios en la nube
- Médico
- código
- Columna
- Columnas
- combinar
- cómo
- hacer
- en comparación con
- completar
- Calcular
- competidor
- condición
- externa (Biomet XNUMXi)
- consideraciones
- Consola
- Conversión
- convertido
- rentable
- Precio
- podría
- Para crear
- creado
- crea
- comisariada
- Current
- cliente
- Clientes
- danza
- página de información de sus operaciones
- datos
- Data Analytics
- Lago de datos
- proceso de datos
- almacenamiento de datos
- Base de datos
- conjuntos de datos
- profundo
- bucear profundo
- Predeterminado
- se define
- De demostración
- demostrar
- depende
- diseñado
- detalles
- desarrollar
- Desarrollo
- un cambio
- una experiencia diferente
- discutir
- No
- DE INSCRIPCIÓN
- dramáticamente
- Soltar
- durante
- cada una
- Más temprano
- Temprano en la
- editor
- de manera eficaz
- eficiente
- ya sea
- elimina
- facilita
- permitiendo
- termina
- Motor
- motores
- Participar
- Empresa
- clientes empresariales
- Éter (ETH)
- Incluso
- evolución
- evoluciona
- evolución
- ejemplo
- existente
- existe
- explicado
- extensiones
- extra
- facilita
- familia
- RÁPIDO
- más rápida
- Caracteristicas
- Figura
- Archive
- archivos
- filtrar
- filtración
- filtros
- Finalmente
- Encuentre
- Nombre
- primer vez
- se centra
- seguir
- siguiendo
- formato
- Marco conceptual
- frecuente
- en
- promover
- Además
- General
- generado
- obtener
- dado
- Va
- candidato
- muy
- Grupo procesos
- mano
- suceder
- ayuda
- ayudando
- ayuda
- Oculto
- jerarquía
- de alto nivel
- Alto rendimiento
- alto rendimiento
- Colmena
- esperanza
- Cómo
- Como Hacer
- Sin embargo
- HTML
- HTTPS
- AMI
- Identidad
- Gestión de identidad y acceso.
- Impacto
- impactados
- implementar
- implementación
- implementación
- mejorar
- mejorado
- es la mejora continua
- mejora
- in
- Incluye
- aumente
- aumentado
- Los aumentos
- índice
- INSTRUMENTO individual
- información
- instalar
- integración
- Introducido
- Aíslados
- IT
- Enero
- Empleo
- Clave
- el lab
- lago
- large
- mayores
- Estado latente
- más reciente
- último lanzamiento
- .
- ponedoras
- Lead
- LIMITE LAS
- línea
- Lista
- pequeño
- carga
- Ubicación
- para lograr
- HACE
- Management
- muchos
- marca
- mercado
- Match
- pareo
- ir
- metadatos
- podría
- millones
- Moderno
- más,
- movimiento
- múltiples
- nombre
- Llamado
- Navegar
- Navegación
- ¿ Necesita ayuda
- Nuevo
- cuaderno
- objeto
- habiertos
- Inteligente
- Operaciones
- optimización
- Optimización
- solicite
- reconocida por
- Otro
- al exterior
- total
- EL DESARROLLADOR
- cristal
- parte
- camino
- .
- realizar
- actuación
- los libros físicos
- planificar
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- jugando
- plugin
- puntos
- Popular
- posible
- Publicación
- alimentado
- requisitos previos
- procedimientos
- tratamiento
- producir
- propiedades
- perfecta
- proporcionar
- proporciona un
- proporcionando
- provisión
- distancia
- Crudo
- datos en bruto
- Leer
- Reading
- real
- recientemente
- recomendado
- archivos
- reflejar
- región
- registros
- regular
- ,
- liberado
- restante
- Requisitos
- requiere
- Recursos
- resultado
- Resultados
- Reseñas
- Rico
- Función
- raíz
- Ejecutar
- correr
- mismo
- escanear
- segundos
- Sección
- EN LINEA
- seleccionado
- seleccionar
- Sin servidor
- de coches
- Servicios
- Sesión
- set
- Sets
- pólipo
- ajustes
- tienes
- Mostrar
- Shows
- sencillos
- circunstancias
- Tamaño
- disminuye
- chica
- Instantánea
- So
- Software
- a medida
- Soluciones
- algo
- Spark
- soluciones y
- velocidad
- Gastos
- SQL
- Comience a
- Estado
- Posicionamiento
- declaraciones
- estadísticas
- paso
- pasos
- Sin embargo
- STORAGE
- tienda
- almacenados
- tiendas
- estrategias
- Estrategia
- estructurado
- datos estructurados y no estructurados
- estudio
- subred
- posterior
- Con éxito
- tal
- suficiente
- RESUMEN
- SOPORTE
- Soportado
- Apoyar
- soportes
- mesa
- toma
- toma
- Target
- tareas
- técnicas
- tenis
- test
- Pruebas
- pruebas
- El
- la información
- El Estado
- su
- de este modo
- miles
- Tres
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- equipo
- el tiempo de viaje
- a
- juntos
- demasiado
- parte superior
- Total
- seguir
- Transacciones
- transformadora
- viajes
- Viajar
- GIRO
- tipos
- bajo
- único
- Actualizar
- actualizado
- Actualizaciones
- actualización
- Enlance
- utilizan el
- caso de uso
- usuarios
- generalmente
- VAL
- propuesta de
- Valores
- verificar
- versión
- caminado
- tutorial
- Manejo de
- relojes
- formas
- web
- servicios web
- ¿
- sean
- que
- mientras
- amplio
- Amplia gama
- seguirá
- sin
- Actividades:
- trabajando
- funciona
- se
- escribir
- la escritura
- tú
- zephyrnet