bruce warrington vía Unsplash
La razón por la que los modelos de aprendizaje automático en general se están volviendo más inteligentes se debe a su dependencia del uso de datos etiquetados para ayudarlos a distinguir entre dos objetos similares.
Sin embargo, sin estos conjuntos de datos etiquetados, encontrará grandes obstáculos al crear el modelo de aprendizaje automático más efectivo y confiable. Los conjuntos de datos etiquetados durante la fase de entrenamiento de un modelo son importantes.
El aprendizaje profundo se ha utilizado ampliamente para resolver tareas como la visión artificial mediante el aprendizaje supervisado. Sin embargo, como muchas cosas en la vida, viene con restricciones. La clasificación supervisada requiere una gran cantidad y calidad de datos de entrenamiento etiquetados para producir un modelo robusto. Esto significa que el modelo de clasificación no puede manejar clases no vistas.
Y todos sabemos cuánto poder computacional, reentrenamiento, tiempo y dinero se necesitan para entrenar un modelo de aprendizaje profundo.
Pero, ¿puede un modelo aún ser capaz de discernir entre dos objetos sin haber usado datos de entrenamiento? Sí, se llama aprendizaje de tiro cero. El aprendizaje de disparo cero es la capacidad de un modelo para poder completar una tarea sin haber recibido o utilizado ningún ejemplo de capacitación.
Los humanos son naturalmente capaces de aprender sin tener que esforzarse demasiado. Nuestros cerebros ya almacenan diccionarios y nos permiten diferenciar objetos al observar sus propiedades físicas debido a nuestra base de conocimiento actual. Podemos usar esta base de conocimiento para ver las similitudes y diferencias entre los objetos y encontrar el vínculo entre ellos.
Por ejemplo, digamos que estamos tratando de construir un modelo de clasificación de especies animales. De acuerdo a Nuestro mundo en datos, había 2.13 millones de especies calculadas en 2021. Por lo tanto, si queremos crear el modelo de clasificación más efectivo para las especies animales, necesitaríamos 2.13 millones de clases diferentes. También se necesitarán muchos datos. Los datos de gran cantidad y calidad son difíciles de encontrar.
Entonces, ¿cómo resuelve este problema el aprendizaje de tiro cero?
Debido a que el aprendizaje de disparo cero no requiere que el modelo haya aprendido los datos de entrenamiento y cómo clasificar las clases, nos permite depender menos de la necesidad del modelo de datos etiquetados.
Lo siguiente es en qué deberán consistir sus datos para continuar con el aprendizaje de disparo cero.
Clases vistas
Consiste en las clases de datos que se han utilizado previamente para entrenar un modelo.
Clases invisibles
Esto consiste en las clases de datos que NO se han usado para entrenar un modelo y el nuevo modelo de aprendizaje de disparo cero se generalizará.
Información Auxiliar
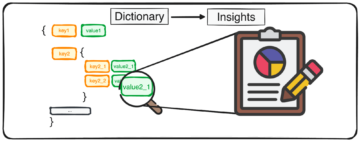
Como los datos en las clases invisibles no están etiquetados, el aprendizaje de tiro cero requerirá información auxiliar para aprender y encontrar correlaciones, enlaces y propiedades. Esto puede ser en forma de incrustaciones de palabras, descripciones e información semántica.
Métodos de aprendizaje de tiro cero
El aprendizaje de tiro cero se usa típicamente en:
- Métodos basados en clasificadores
- Métodos basados en instancias
Cíclos
El aprendizaje de tiro cero se usa para construir modelos para clases que no entrenan usando datos etiquetados, por lo tanto, requiere estas dos etapas:
1. Formación
La etapa de entrenamiento es el proceso del método de aprendizaje que trata de capturar tanto conocimiento como sea posible sobre las cualidades de los datos. Podemos ver esto como la fase de aprendizaje.
2. Inferencia
Durante la etapa de inferencia, todo el conocimiento aprendido en la etapa de entrenamiento se aplica y utiliza para clasificar los ejemplos en un nuevo conjunto de clases. Podemos ver esto como la fase de hacer predicciones.
¿Cómo Funciona?
El conocimiento de las clases vistas se transferirá a las clases no vistas en un espacio vectorial de alta dimensión; esto se llama espacio semántico. Por ejemplo, en la clasificación de imágenes, el espacio semántico junto con la imagen pasará por dos pasos:
1. Espacio de empotramiento conjunto
Aquí es donde se proyectan los vectores semánticos y los vectores de la característica visual.
2. Mayor similitud
Aquí es donde las características se comparan con las de una clase invisible.
Para ayudar a comprender el proceso con las dos etapas (entrenamiento e inferencia), apliquémoslas en el uso de la clasificación de imágenes.
Formación

Jari Hytonen vía Unsplash
Como ser humano, si leyeras el texto de la derecha en la imagen de arriba, asumirías instantáneamente que hay 4 gatitos en una canasta marrón. Pero digamos que no tienes idea de lo que es un 'gatito'. Supondrás que hay una cesta marrón con 4 cosas dentro, que se llaman 'gatitos'. Una vez que encuentre más imágenes que contengan algo parecido a un 'gatito', podrá diferenciar un 'gatito' de otros animales.
Esto es lo que sucede cuando usas Preentrenamiento de imagen-lenguaje contrastivo (CLIP) de OpenAI para el aprendizaje de tiro cero en la clasificación de imágenes. Se conoce como información auxiliar.
Podría estar pensando, 'bueno, eso es solo datos etiquetados'. Entiendo por qué pensarías eso, pero no lo son. La información auxiliar no son etiquetas de los datos, son una forma de supervisión para ayudar al modelo a aprender durante la etapa de entrenamiento.
Cuando un modelo de aprendizaje de tiro cero ve una cantidad suficiente de parejas de imagen y texto, podrá diferenciar y comprender frases y cómo se correlacionan con ciertos patrones en las imágenes. Usando la técnica CLIP 'aprendizaje contrastivo', el modelo de aprendizaje de disparo cero ha podido acumular una buena base de conocimiento para poder hacer predicciones sobre tareas de clasificación.
Este es un resumen del enfoque CLIP en el que entrenan juntos un codificador de imágenes y un codificador de texto para predecir los emparejamientos correctos de un lote de ejemplos de entrenamiento (imagen, texto). Por favor, vea la imagen a continuación:

Aprendizaje de modelos visuales transferibles a partir de la supervisión del lenguaje natural
Inferencia
Una vez que el modelo ha pasado por la etapa de entrenamiento, tiene una buena base de conocimientos sobre el emparejamiento de imagen y texto y ahora se puede usar para hacer predicciones. Pero antes de que podamos comenzar a hacer predicciones, debemos configurar la tarea de clasificación creando una lista de todas las etiquetas posibles que el modelo podría generar.
Por ejemplo, siguiendo con la tarea de clasificación de imágenes en especies animales, necesitaremos una lista de todas las especies de animales. Cada una de estas etiquetas estará codificada, T? a T? usando el codificador de texto preentrenado que ocurrió en la etapa de entrenamiento.
Una vez que se han codificado las etiquetas, podemos ingresar imágenes a través del codificador de imágenes previamente entrenado. Usaremos la similitud del coseno de la métrica de distancia para calcular las similitudes entre la codificación de la imagen y la codificación de cada etiqueta de texto.
La clasificación de la imagen se realiza en base a la etiqueta con mayor similitud con la imagen. Y así es como se consigue el aprendizaje zero-shot, concretamente en la clasificación de imágenes.
Escasez de datos
Como se mencionó anteriormente, es difícil obtener datos de gran cantidad y calidad. A diferencia de los humanos que ya poseen la capacidad de aprendizaje de tiro cero, las máquinas requieren datos etiquetados de entrada para aprender y luego poder adaptarse a las variaciones que pueden ocurrir naturalmente.
Si miramos el ejemplo de las especies animales, había tantos. Y a medida que la cantidad de categorías continúa creciendo en diferentes dominios, se necesitará mucho trabajo para mantenerse al día con la recopilación de datos anotados.
Debido a esto, el aprendizaje de tiro cero se ha vuelto más valioso para nosotros. Cada vez más investigadores están interesados en el reconocimiento automático de atributos para compensar la falta de datos disponibles.
Etiquetado de datos
Otro beneficio del aprendizaje de disparo cero son sus propiedades de etiquetado de datos. El etiquetado de datos puede ser laborioso y muy tedioso, por lo que puede dar lugar a errores durante el proceso. El etiquetado de datos requiere expertos, como profesionales médicos que trabajan en un conjunto de datos biomédicos, lo cual es muy costoso y requiere mucho tiempo.
El aprendizaje de disparo cero se está volviendo más popular debido a las limitaciones de datos anteriores. Hay algunos documentos que le recomendaría leer si está interesado en sus habilidades:
nisha aria es científico de datos y escritor técnico independiente. Ella está particularmente interesada en proporcionar consejos o tutoriales sobre la carrera de Data Science y conocimiento basado en la teoría sobre Data Science. También desea explorar las diferentes formas en que la Inteligencia Artificial es o puede beneficiar la longevidad de la vida humana. Una estudiante entusiasta que busca ampliar sus conocimientos tecnológicos y sus habilidades de escritura, mientras ayuda a guiar a otros.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.kdnuggets.com/2022/12/zeroshot-learning-explained.html?utm_source=rss&utm_medium=rss&utm_campaign=zero-shot-learning-explained
- 2021
- a
- <del>
- capacidad
- Poder
- Sobre
- arriba
- Conforme
- Acumular
- alcanzado
- a través de
- adaptar
- consejos
- en contra
- Todos
- permite
- ya haya utilizado
- cantidad
- y
- animal
- animales
- aplicada
- Aplicá
- enfoque
- en torno a
- artificial
- inteligencia artificial
- Automático
- Hoy Disponibles
- bases
- basado
- canasta
- a las que has recomendado
- cada vez
- antes
- "Ser"
- a continuación
- es el beneficio
- entre
- biomédica
- ampliar
- build
- calculado
- , que son
- Puede conseguir
- no puede
- capaz
- capturar
- Propósito
- categoría
- a ciertos
- clase
- privadas
- clasificación
- clasificar
- El cobro
- cómo
- completar
- potencia de cálculo
- Calcular
- computadora
- Visión por computador
- continúa
- podría
- Para crear
- Creamos
- Current
- datos
- Ciencia de los datos
- científico de datos
- conjuntos de datos
- profundo
- deep learning
- Dependencia
- diferencias
- una experiencia diferente
- diferenciar
- distancia
- dominios
- durante
- cada una
- Eficaz
- esfuerzo
- Errores
- ejemplo
- ejemplos
- costoso
- expertos
- explicado
- explorar
- Feature
- Caracteristicas
- pocos
- Encuentre
- siguiendo
- formulario
- freelance
- en
- General
- obtener
- candidato
- mayores
- Crecer
- guía
- encargarse de
- Manos
- que sucede
- Difícil
- es
- ayuda
- ayudando
- Alta
- más alto
- altamente
- Cómo
- Como Hacer
- Sin embargo
- HTTPS
- humana
- Humanos
- idea
- imagen
- Clasificación de la imagen
- imágenes
- importante
- in
- información
- Las opciones de entrada
- Intelligence
- interesado
- IT
- Keen
- Guardar
- Saber
- especialistas
- conocido
- Label
- etiquetado
- Etiquetas
- Falta
- idioma
- Lead
- APRENDE:
- aprendido
- aprendizaje
- Vida
- limitaciones
- LINK
- Etiqueta LinkedIn
- enlaces
- Lista
- longevidad
- Mira
- mirando
- MIRADAS
- Lote
- máquina
- máquina de aprendizaje
- Máquinas
- gran
- para lograr
- Realizar
- muchos
- significa
- servicios
- mencionado
- Método
- métodos
- métrico
- podría
- millones
- modelo
- modelos
- dinero
- más,
- MEJOR DE TU
- Natural
- ¿ Necesita ayuda
- Nuevo
- número
- objetos
- obstáculos
- se produjo
- ONE
- OpenAI
- solicite
- Otro
- Otros
- emparejamiento
- emparejamientos
- papeles
- particularmente
- .
- (PDF)
- fase
- frases
- los libros físicos
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- Por favor
- Popular
- posible
- industria
- predecir
- Predicciones
- previamente
- Problema
- producir
- profesionales
- proyectado
- propiedades
- proporcionando
- poner
- cualidades
- calidad
- la cantidad
- Leer
- razón
- recibido
- reconocimiento
- recomiendan
- exigir
- requiere
- investigadores
- restricciones
- robusto
- Ciencia:
- Científico
- la búsqueda de
- ve
- set
- similares
- similitudes
- habilidades
- más inteligente
- So
- RESOLVER
- algo
- Espacio
- específicamente
- Etapa
- etapas
- pasos
- pega
- Sin embargo
- tienda
- tal
- suficiente
- RESUMEN
- supervisión
- ¡Prepárate!
- toma
- Tarea
- tareas
- tecnología
- Técnico
- El
- su
- por lo tanto
- cosas
- Ideas
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- equipo
- prolongado
- a
- juntos
- Entrenar
- Formación
- transferido
- digno de confianza
- Tutoriales
- típicamente
- entender
- us
- utilizan el
- utilizado
- Valioso
- vía
- Ver
- visión
- formas
- ¿
- que
- Aunque que la
- QUIENES
- extensamente
- seguirá
- sin
- Palabra
- Actividades:
- trabajando
- se
- escritor
- la escritura
- tú
- zephyrnet
- Aprendizaje de tiro cero