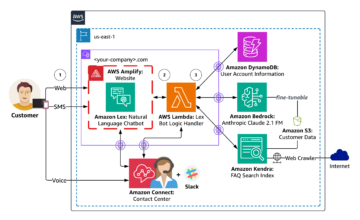
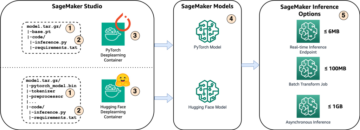
Amazon SageMaker on täielikult hallatav masinõppe (ML) teenus. SageMakeriga saavad andmeteadlased ja arendajad kiiresti ja lihtsalt luua ja koolitada ML-mudeleid ning seejärel juurutada need otse tootmisvalmis hostitud keskkonda. See pakub integreeritud Jupyteri loomismärkmiku eksemplari, mis võimaldab hõlpsalt juurdepääsu teie andmeallikatele uurimiseks ja analüüsimiseks, nii et te ei pea servereid haldama. See pakub ka ühist ML algoritmid mis on optimeeritud töötama tõhusalt jaotatud keskkonnas äärmiselt suurte andmetega.
SageMakeri reaalajas järeldus on ideaalne töökoormuste jaoks, millel on reaalajas, interaktiivsed ja madala latentsusajaga nõuded. SageMakeri reaalajas järelduse abil saate juurutada REST-i lõpp-punkte, mida toetab konkreetne eksemplaritüüp koos teatud arvutus- ja mälumahuga. SageMakeri reaalajas lõpp-punkti juurutamine on paljude klientide jaoks alles esimene samm teel tootmiseni. Soovime, et oleks võimalik maksimeerida lõpp-punkti jõudlust, et saavutada sihttehingute arv sekundis (TPS), järgides samas latentsusnõudeid. Suur osa jõudluse optimeerimisest järelduste tegemiseks seisneb selles, et valite õige eksemplari tüübi ja loendate lõpp-punkti tagasi.
See postitus kirjeldab SageMakeri lõpp-punkti koormustestimise parimaid tavasid, et leida eksemplaride arvu ja suuruse jaoks õige konfiguratsioon. See võib aidata meil mõista minimaalseid ette nähtud eksemplari nõudeid, et vastata meie latentsus- ja TPS-i nõuetele. Sealt uurime, kuidas saate jälgida ja mõista SageMakeri lõpp-punkti mõõdikuid ja jõudlust, kasutades Amazon CloudWatch mõõdikud.
Esmalt võrdleme oma mudeli toimivust ühel eksemplaril, et tuvastada TPS, mida see meie vastuvõetavate latentsusnõuete kohaselt suudab käsitleda. Seejärel ekstrapoleerime tulemused, et otsustada, mitu eksemplari vajame oma tootmisliikluse haldamiseks. Lõpuks simuleerime tootmistaseme liiklust ja seadistame reaalajas SageMakeri lõpp-punkti koormustestid, et kinnitada, et meie lõpp-punkt suudab tootmistaseme koormusega hakkama saada. Kogu näite koodikomplekt on saadaval järgmises GitHubi hoidla.
Ülevaade lahendusest
Selle postituse jaoks kasutame eelkoolitatud Kallistav nägu DistilBERT mudel alates Kallistamine Face Hub. See mudel suudab täita mitmeid ülesandeid, kuid saadame kasuliku koormuse spetsiaalselt sentimentide analüüsiks ja teksti klassifitseerimiseks. Selle proovi kasuliku koormusega püüame saavutada 1000 TPS-i.
Juurutage reaalajas lõpp-punkt
See postitus eeldab, et tunnete mudeli juurutamist. Viitama Looge oma lõpp-punkt ja juurutage oma mudel et mõista lõpp-punkti hostimise sisemisi tegureid. Praegu saame Hugging Face Hubis kiiresti sellele mudelile osutada ja järgmise koodilõigu abil juurutada reaalajas lõpp-punkti:
Testime oma lõpp-punkti kiiresti proovi kasuliku koormusega, mida tahame koormustestimiseks kasutada:

Pange tähele, et me toetame lõpp-punkti singli abil Amazon Elastic Compute Cloud (Amazon EC2) tüüpi ml.m5.12xlarge eksemplar, mis sisaldab 48 vCPU-d ja 192 GiB mälu. VCPU-de arv näitab hästi samaaegsust, mida eksemplar suudab käsitleda. Üldiselt on soovitatav testida erinevaid eksemplaritüüpe, veendumaks, et meil on eksemplar, mille ressursse kasutatakse õigesti. SageMakeri eksemplaride täieliku loendi ja nende vastava arvutusvõimsuse vaatamiseks reaalajas järelduste tegemiseks vaadake Amazon SageMakeri hinnakujundus.
Mõõdikud, mida jälgida
Enne koormustesti alustamist on oluline mõista, milliseid mõõdikuid jälgida, et mõista SageMakeri lõpp-punkti jõudluse jaotust. CloudWatch on peamine logimistööriist, mida SageMaker kasutab, et aidata teil mõista erinevaid mõõdikuid, mis kirjeldavad teie lõpp-punkti jõudlust. Saate kasutada CloudWatchi logisid lõpp-punkti kutsete silumiseks; siin on salvestatud kõik logimis- ja printimisväited, mis teie järelduskoodis on. Lisateabe saamiseks vaadake Kuidas Amazon CloudWatch töötab.
CloudWatch hõlmab SageMakeri jaoks kahte erinevat tüüpi mõõdikuid: eksemplaritaseme ja kutsumismõõdikud.
Eksemplaritaseme mõõdikud
Esimene parameetrite komplekt, mida tuleb arvesse võtta, on eksemplaritaseme mõõdikud. CPUUtilization ja MemoryUtilization (GPU-põhiste eksemplaride puhul GPUUtilization). Sest CPUUtilization, võite alguses CloudWatchis näha protsente üle 100%. Oluline on teadvustada CPUUtilization, kuvatakse kõigi CPU tuumade summa. Näiteks kui teie lõpp-punkti taga olev eksemplar sisaldab 4 vCPU-d, tähendab see, et kasutusvahemik on kuni 400%. MemoryUtilizationseevastu jääb vahemikku 0–100%.
Täpsemalt saate kasutada CPUUtilization et saada sügavamalt aru, kas teil on piisavalt või isegi liiga palju riistvara. Kui teil on vähekasutatud eksemplar (alla 30%), võite oma eksemplari tüüpi vähendada. Ja vastupidi, kui teie kasutusaste on umbes 80–90%, oleks kasulik valida suurema arvutus-/mälumahuga eksemplar. Meie testide põhjal soovitame teie riistvara kasutada umbes 60–70%.
Kutsumismõõdikud
Nagu nimigi viitab, on kutsumõõdikud koht, kus saame jälgida teie lõpp-punkti kõigi väljakutsete latentsusaega. Saate kasutada kutsumismõõdikuid, et jäädvustada vigade arv ja seda, millist tüüpi tõrkeid (5xx, 4xx jne), mida teie lõpp-punkt võib kogeda. Veelgi olulisem on see, et saate aru lõpp-punkti kõnede latentsusaja jaotusest. Palju sellest saab jäädvustada ModelLatency ja OverheadLatency mõõdikud, nagu on näidatud järgmisel diagrammil.

. ModelLatency mõõdik kajastab aega, mis kulub järelduste tegemiseks SageMakeri lõpp-punkti taga olevas mudelikonteineris. Pange tähele, et mudelikonteiner sisaldab ka kõiki kohandatud järelduskoode või skripte, mille olete järelduste tegemiseks edastanud. Seda ühikut jäädvustatakse kutsumismõõdikuna mikrosekundites ja üldiselt saate CloudWatchi (p99, lk 90 ja nii edasi) protsentiili joonistada, et näha, kas saavutate sihtlatentsuse. Pange tähele, et mudeli ja konteineri latentsusaega võivad mõjutada mitmed tegurid, näiteks järgmised.
- Kohandatud järeldusskript – Olenemata sellest, kas olete juurutanud oma konteineri või kasutanud SageMakeri-põhist konteinerit koos kohandatud järelduste töötlejatega, on parim tava skripti profiili koostamine, et püüda kinni kõik toimingud, mis lisavad teie latentsusele palju aega.
- Sideprotokoll – Kaaluge REST vs. gRPC ühendusi mudeliserveriga mudeli konteineris.
- Mudeli raamistiku optimeerimine – See on raamistikuspetsiifiline, näiteks koos TensorFlow, saate häälestada mitmeid keskkonnamuutujaid, mis on TF-i teenindamise spetsiifilised. Kontrollige kindlasti, millist konteinerit te kasutate ja kas skripti või keskkonnamuutujatena saate konteinerisse sisestada raamistikupõhiseid optimeerimisi.
OverheadLatency mõõdetakse ajast, mil SageMaker päringu saab, kuni kliendile vastuse tagastamiseni, millest on maha arvatud mudeli latentsusaeg. See osa on suures osas väljaspool teie kontrolli ja jääb SageMakeri üldkulude alla.
Otsast lõpuni latentsusaeg tervikuna sõltub paljudest teguritest ja ei pruugi olla nende summa ModelLatency pluss OverheadLatency. Näiteks kui teie klient teeb InvokeEndpoint API-kõne Interneti kaudu, kliendi vaatenurgast oleks lõpp-otsani latentsusaeg internet + ModelLatency + OverheadLatency. Seetõttu on lõpp-punkti koormustestimisel soovitatav lõpp-punkti enda täpseks võrdlusuuringuks keskenduda lõpp-punkti mõõdikutele (ModelLatency, OverheadLatencyja InvocationsPerInstance), et SageMakeri lõpp-punkti täpselt võrrelda. Seejärel saab kõik otsast lõpuni latentsusega seotud probleemid eraldi eraldada.
Mõned küsimused, mida tuleks täieliku latentsusaja jaoks kaaluda.
- Kus on klient, kes kasutab teie lõpp-punkti?
- Kas teie kliendi ja SageMakeri käitusaja vahel on vahekihte?
Automaatne skaleerimine
Me ei käsitle selles postituses konkreetselt automaatset skaleerimist, kuid see on oluline kaalutlus, et varustada töökoormuse põhjal õige arv eksemplare. Sõltuvalt teie liiklusmustrist saate lisada automaatse skaleerimise poliitika teie SageMakeri lõpp-punkti. Skaleerimise võimalusi on erinevaid, nt TargetTrackingScaling, SimpleScalingja StepScaling. See võimaldab teie lõpp-punktil teie liiklusmustri alusel automaatselt sisse ja välja skaleerida.
Levinud valik on sihtmärgi jälgimine, kus saate määrata CloudWatchi mõõdiku või kohandatud mõõdiku, mille olete määratlenud ja selle alusel skaleerida. Automaatse skaleerimise sage kasutamine on jälgimine InvocationsPerInstance meetriline. Kui olete teatud TPS-is kitsaskoha tuvastanud, saate seda sageli kasutada mõõdikuna, et skaleerida suuremale arvule eksemplaridele, et tulla toime liikluse tippkoormusega. Automaatse skaleerimise SageMakeri lõpp-punktide põhjalikuma jaotuse saamiseks vaadake Automaatse skaleerimise järelduste lõpp-punktide konfigureerimine rakenduses Amazon SageMaker.
Koormustestimine
Kuigi me kasutame Locusti, et kuvada, kuidas saame testi mastaapselt laadida, kui proovite oma lõpp-punkti taga olevat eksemplari õiget suurust määrata, SageMakeri järelduste soovitus on tõhusam variant. Kolmanda osapoole koormuse testimise tööriistadega peate lõpp-punktid erinevates eksemplarides käsitsi juurutama. Inference Recommenderiga saate lihtsalt edastada massiivi eksemplaritüüpidest, mille vastu soovite laadida testi, ja SageMaker hakkab tööle töökohti iga sellise juhtumi puhul.
rändrohutirts
Selle näite puhul kasutame rändrohutirts, avatud lähtekoodiga koormuse testimise tööriist, mida saate Pythoni abil rakendada. Locust on sarnane paljude teiste avatud lähtekoodiga koormuse testimise tööriistadega, kuid sellel on mõned konkreetsed eelised.
- Lihtne üles seada – Nagu selles postituses demonstreerime, anname edasi lihtsa Pythoni skripti, mida saab hõlpsasti teie konkreetse lõpp-punkti ja kasuliku koormuse jaoks ümber kujundada.
- Hajutatud ja skaleeritav - Locust on sündmustepõhine ja kasutab gevent kapoti all. See on väga kasulik väga samaaegsete töökoormuste testimiseks ja tuhandete samaaegsete kasutajate simuleerimiseks. Kõrge TPS-i saate saavutada ühe Locusti käivitava protsessiga, kuid sellel on ka a hajutatud koormuse genereerimine funktsioon, mis võimaldab teil skaleerida mitmele protsessile ja kliendi masinale, nagu me selles postituses uurime.
- Jaanileivapuu mõõdikud ja kasutajaliides – Locust jäädvustab mõõdikuna ka otsast lõpuni latentsust. See võib aidata teie CloudWatchi mõõdikuid täiendada, et luua teie testidest täielik pilt. See kõik on jäädvustatud Locusti kasutajaliidesesse, kus saate jälgida samaaegseid kasutajaid, töötajaid ja palju muud.
Locusti paremaks mõistmiseks vaadake neid dokumentatsioon.
Amazon EC2 seadistamine
Saate Locusti seadistada mis tahes teie jaoks sobivas keskkonnas. Selle postituse jaoks seadistasime EC2 eksemplari ja installime sinna oma testide läbiviimiseks Locusti. Kasutame c5.18xlarge EC2 eksemplari. Arvestada tuleb ka kliendipoolse arvutusvõimsusega. Mõnikord, kui kliendi poolel saab arvutusvõimsus otsa, seda sageli ei salvestata ja seda peetakse ekslikult SageMakeri lõpp-punkti veaks. Oluline on paigutada klient piisava arvutusvõimsusega kohta, mis suudab taluda testitavat koormust. Meie EC2 eksemplari puhul kasutame Ubuntu Deep Learning AMI-d, kuid võite kasutada mis tahes AMI-d, kui suudate Locusti masinas õigesti seadistada. EC2 eksemplari käivitamise ja sellega ühenduse loomise mõistmiseks vaadake õpetust Alustage Amazon EC2 Linuxi eksemplaridega.
Locusti kasutajaliidesele pääseb juurde pordi 8089 kaudu. Saame selle avada, kohandades EC2 eksemplari sissetuleva turvarühma reegleid. Avame ka pordi 22, et saaksime SSH-i EC2 eksemplari. Kaaluge allika ulatust kuni konkreetse IP-aadressini, millelt EC2 eksemplarile juurde pääsete.

Pärast ühenduse loomist oma EC2 eksemplariga seadistame Pythoni virtuaalse keskkonna ja installime avatud lähtekoodiga Locust API CLI kaudu:
Oleme nüüd valmis Locustiga meie lõpp-punkti koormustestimiseks koostööd tegema.
Jaanileiva testimine
Kõik Locusti koormustestid viiakse läbi a Jaanileiva fail mida pakute. See Locusti fail määratleb koormustesti ülesande; siin määratleme oma Boto3 invoke_endpoint API kutse. Vaadake järgmist koodi:
Eelmises koodis kohandage oma väljakutse lõpp-punkti kõne parameetreid, et need sobiksid teie konkreetse mudeli kutsumisega. Me kasutame InvokeEndpoint API, mis kasutab Locusti failis järgmist koodijuppi; see on meie koormustesti tööpunkt. Locusti fail, mida me kasutame, on locust_script.py.
Nüüd, kui meil on Locusti skript valmis, tahame käitada hajutatud Locusti teste, et testida meie üksikut eksemplari, et teada saada, kui suure liiklusega meie eksemplar hakkama saab.
Locust'i hajutatud režiim on pisut nüansirikkam kui ühe protsessiga Locust test. Hajutatud režiimis on meil üks peamine ja mitu töötajat. Peamine töötaja juhendab töötajaid päringu saatvate samaaegsete kasutajate loomise ja kontrollimise kohta. Meie levitatud.sh skripti, näeme vaikimisi, et 240 kasutajat jaotatakse 60 töötaja vahel. Pange tähele, et --headless lipp Locusti CLI-s eemaldab Locusti kasutajaliidese funktsiooni.
./distributed.sh huggingface-pytorch-inference-2022-10-04-02-46-44-677 #to execute Distributed Locust test
Esmalt käivitame hajutatud testi ühel eksemplaril, mis toetab lõpp-punkti. Siin on mõte, et tahame täielikult maksimeerida ühte eksemplari, et mõista eksemplaride arvu, mida vajame oma siht-TPS-i saavutamiseks, jäädes samas latentsusnõuete piiresse. Pange tähele, et kui soovite kasutajaliidesele juurde pääseda, muutke Locust_UI keskkonnamuutuja väärtuseks Tõene ja määrake oma EC2 eksemplari avalik IP ja seostage port 8089 URL-iga.
Järgmine ekraanipilt näitab meie CloudWatchi mõõdikuid.

Lõpuks märkame, et kuigi algselt saavutame TPS-i 200, hakkame oma EC5 kliendipoolsetes logides märkama 2xx vigu, nagu on näidatud järgmisel ekraanipildil.
Samuti saame seda kontrollida, vaadates konkreetselt meie eksemplari tasemel mõõdikuid CPUUtilization.
 Siin me märkame
Siin me märkame CPUUtilization peaaegu 4,800%. Meie eksemplaris ml.m5.12x.large on 48 vCPU-d (48 * 100 = 4800~). See küllastab kogu eksemplari, mis aitab selgitada ka meie 5xx vigu. Samuti näeme kasvu ModelLatency.
Näib, et meie üksik eksemplar kukub ümber ja tal pole arvutusi, et taluda koormust, mis ületab 200 TPS-i, mida jälgime. Meie siht-TPS on 1000, nii et proovime oma eksemplaride arvu suurendada 5-ni. Tootmisseades võib see olla veelgi suurem, sest pärast teatud punkti jälgisime 200 TPS-i juures vigu.

Nii Locusti kasutajaliidese kui ka CloudWatchi logides näeme, et meie TPS on peaaegu 1000 ja lõpp-punkti toetab viis eksemplari.

 Kui teil hakkab isegi selle riistvaraseadistuse korral vigu ilmnema, jälgige kindlasti
Kui teil hakkab isegi selle riistvaraseadistuse korral vigu ilmnema, jälgige kindlasti CPUUtilization et mõista oma lõpp-punkti hostimise taga olevat täielikku pilti. Väga oluline on mõista oma riistvara kasutust, et näha, kas teil on vaja suurendada või isegi vähendada. Mõnikord põhjustavad konteineritaseme probleemid 5xx-vigu, kuid kui CPUUtilization on madal, näitab see, et need probleemid võib põhjustada mitte teie riistvara, vaid miski konteineri või mudeli tasemel (näiteks õige keskkonnamuutuja töötajate arvu jaoks pole määratud). Teisest küljest, kui märkate, et teie eksemplar hakkab täielikult täis saama, on see märk sellest, et peate kas suurendama praegust eksemplariparki või proovima suuremat eksemplari väiksema pargiga.
Kuigi suurendasime 5 TPS-i käsitlemiseks eksemplaride arvu 100-ni, näeme, et ModelLatency mõõdik on endiselt kõrge. Selle põhjuseks on eksemplaride küllastumine. Üldiselt soovitame kasutada eksemplari ressursse 60–70%.
Koristage
Pärast koormustestimist puhastage kindlasti kõik ressursid, mida te ei kasuta SageMakeri konsooli või delete_endpoint Boto3 API kõne. Lisaks peatage kindlasti oma EC2 eksemplar või mis tahes kliendi seadistus, et teil ei tekiks ka seal täiendavaid tasusid.
kokkuvõte
Selles postituses kirjeldasime, kuidas saate oma SageMakeri reaalajas lõpp-punkti laadida. Arutasime ka, milliseid mõõdikuid peaksite oma lõpp-punkti koormustestimisel hindama, et jõudluse jaotust mõista. Kontrollige kindlasti SageMakeri järelduste soovitus eksemplari õige suuruse määramise ja jõudluse optimeerimise tehnikate paremaks mõistmiseks.
Autoritest
 Marc Karp on SageMaker Service meeskonnaga ML arhitekt. Ta keskendub klientide abistamisele ML-töökoormuste ulatuslikul kavandamisel, juurutamisel ja haldamisel. Vabal ajal meeldib talle reisida ja avastada uusi kohti.
Marc Karp on SageMaker Service meeskonnaga ML arhitekt. Ta keskendub klientide abistamisele ML-töökoormuste ulatuslikul kavandamisel, juurutamisel ja haldamisel. Vabal ajal meeldib talle reisida ja avastada uusi kohti.
 Ram Vegiraju on SageMaker Service meeskonnaga ML arhitekt. Ta keskendub sellele, et aidata klientidel luua ja optimeerida oma AI/ML-lahendusi Amazon SageMakeris. Vabal ajal armastab ta reisimist ja kirjutamist.
Ram Vegiraju on SageMaker Service meeskonnaga ML arhitekt. Ta keskendub sellele, et aidata klientidel luua ja optimeerida oma AI/ML-lahendusi Amazon SageMakeris. Vabal ajal armastab ta reisimist ja kirjutamist.
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- Platoblockchain. Web3 metaversiooni intelligentsus. Täiustatud teadmised. Juurdepääs siia.
- Allikas: https://aws.amazon.com/blogs/machine-learning/best-practices-for-load-testing-amazon-sagemaker-real-time-inference-endpoints/
- 1
- 10
- 100
- 11
- 9
- a
- Võimalik
- üle
- vastuvõetav
- juurdepääs
- juurdepääsetav
- Ligipääs
- täpselt
- Saavutada
- üle
- lisamine
- aadress
- pärast
- vastu
- AI / ML
- Eesmärk
- Materjal: BPA ja flataatide vaba plastik
- võimaldab
- Kuigi
- Amazon
- Amazon EC2
- Amazon SageMaker
- summa
- analüüs
- ja
- API
- ümber
- Array
- kinnitage
- autor
- auto
- automaatselt
- saadaval
- AWS
- tagasi
- tagatud
- toetus
- põhineb
- sest
- taga
- on
- võrrelda
- kasu
- Kasu
- BEST
- parimaid tavasid
- vahel
- keha
- Lagunema
- ehitama
- C + +
- helistama
- Kutsub
- Saab
- lüüa
- lööb
- maadlus
- kindel
- muutma
- koormuste
- kontrollima
- klass
- klassifikatsioon
- klient
- kood
- ühine
- kokkusobiv
- Arvutama
- konkurent
- Läbi viima
- konfiguratsioon
- Kinnitama
- Võta meiega ühendust
- seotud
- Side
- Arvestama
- tasu
- konsool
- Konteiner
- sisaldab
- kontekst
- kontrollida
- Vastav
- võiks
- cover
- kaaned
- Protsessor
- looma
- otsustav
- Praegune
- tava
- Kliendid
- andmed
- sügav
- sügav õpe
- sügavam
- vaikimisi
- Määratleb
- näitama
- Olenevalt
- sõltub
- juurutada
- juurutamine
- kirjeldama
- kirjeldatud
- Disain
- Arendajad
- erinev
- otse
- arutatud
- Ekraan
- jagatud
- Ei tee
- Ära
- alla
- iga
- kergesti
- tõhus
- tõhusalt
- kumbki
- võimaldab
- Lõpuks-lõpuni
- Lõpp-punkt
- Kogu
- keskkond
- viga
- vead
- oluline
- Eeter (ETH)
- Isegi
- näide
- erand
- täitma
- kogevad
- Selgitama
- uurimine
- uurima
- Avastades
- eksport
- äärmiselt
- nägu
- tegurid
- juga
- tuttav
- tunnusjoon
- vähe
- fail
- Lõpuks
- leidma
- esimene
- FLEET
- Keskenduma
- keskendub
- Järel
- formaat
- Raamistik
- sage
- Alates
- täis
- täielikult
- edasi
- Üldine
- üldiselt
- saama
- saamine
- hea
- graafik
- suurem
- Grupp
- Grupi omad
- käepide
- õnnelik
- riistvara
- aitama
- aidates
- aitab
- siin
- Suur
- kõrgelt
- kapuuts
- võõrustaja
- võõrustas
- Hosting
- Kuidas
- Kuidas
- HTML
- HTTPS
- Keskus
- idee
- ideaalne
- tuvastatud
- identifitseerima
- mõju
- rakendada
- rakendatud
- import
- oluline
- in
- hõlmab
- Suurendama
- kasvanud
- näitab
- näidustus
- info
- esialgu
- paigaldama
- Näiteks
- integreeritud
- interaktiivne
- Internet
- kutsub
- IP
- IP-aadress
- isoleeritud
- küsimustes
- IT
- ise
- Json
- suur
- suurelt jaolt
- suurem
- Hilinemine
- algatama
- kihid
- viima
- juhtivate
- õppimine
- Tase
- Linux
- nimekiri
- vähe
- koormus
- saadetised
- liising
- Pikk
- otsin
- Partii
- Madal
- masin
- masinõpe
- masinad
- tegema
- Tegemine
- juhtima
- juhitud
- käsitsi
- palju
- kaart
- Maksimeerima
- vahendid
- Vastama
- koosolekul
- Mälu
- meetriline
- Meetrika
- võib
- miinimum
- ML
- viis
- mudel
- mudelid
- Jälgida
- rohkem
- tõhusam
- mitmekordne
- nimi
- peaaegu
- tingimata
- Vajadus
- Uus
- märkmik
- number
- ONE
- avatud
- avatud lähtekoodiga
- Operations
- optimeerimine
- optimeerima
- optimeeritud
- valik
- Valikud
- et
- Muu
- väljaspool
- enda
- maalima
- parameetrid
- osa
- Vastu võetud
- minevik
- tee
- Muster
- mustrid
- tipp
- täitma
- jõudlus
- perspektiiv
- valima
- pilt
- tükk
- Koht
- Kohad
- Platon
- Platoni andmete intelligentsus
- PlatoData
- pluss
- Punkt
- post
- potentsiaalselt
- võim
- tava
- tavad
- Predictor
- esmane
- trükk
- probleeme
- protsess
- Protsessid
- Produktsioon
- profiil
- korralik
- korralikult
- anda
- annab
- säte
- avalik
- Python
- Küsimused
- kiiresti
- valik
- valmis
- reaalajas
- mõistma
- saab
- soovitatav
- piirkond
- seotud
- taotleda
- Nõuded
- Vahendid
- vastus
- REST
- kaasa
- Tulemused
- Tulu
- eeskirjade
- jooks
- jooksmine
- salveitegija
- SageMakeri järeldus
- Skaala
- ketendamine
- teadlased
- Reguleerimisala
- skripte
- Teine
- turvalisus
- tundub
- SELF
- saatmine
- tunne
- teenus
- teenindavad
- komplekt
- kehtestamine
- seaded
- seade
- mitu
- peaks
- näidatud
- Näitused
- kirjutama
- sarnane
- lihtne
- lihtsalt
- ühekordne
- SUURUS
- väiksem
- So
- Lahendused
- midagi
- allikas
- Allikad
- Lõimetis
- konkreetse
- eriti
- Spin
- standard
- algus
- alustatud
- avaldused
- Samm
- Veel
- Peatus
- stress
- püüdma
- selline
- piisav
- Kostüüm
- super
- täiendamine
- Võtma
- võtab
- sihtmärk
- Ülesanne
- ülesanded
- meeskond
- tehnikat
- test
- Katsetamine
- Testimine
- testid
- Teksti liigitus
- .
- Allikas
- oma
- kolmanda osapoole
- tuhandeid
- Läbi
- aeg
- korda
- et
- tööriist
- töövahendid
- tps
- jälgida
- Jälgimine
- liiklus
- Rong
- Tehingud
- Reisimine
- tõsi
- juhendaja
- liigid
- Ubuntu
- ui
- all
- mõistma
- mõistmine
- üksus
- URL
- us
- kasutama
- Kasutajad
- ära kasutama
- kasutatud
- kasutab ära
- kasutades
- sort
- kontrollima
- kaudu
- virtuaalne
- M
- kas
- mis
- kuigi
- will
- jooksul
- Töö
- töötaja
- töötajate
- oleks
- kirjutamine
- Sinu
- sephyrnet