See artikkel avaldati osana Andmeteaduse ajaveebi
Sissejuhatus

Konvolutsioonilised närvivõrgud, mida nimetatakse ka ConvNetideks, võttis esmakordselt kasutusele 1980. aastatel taustal töötanud arvutiteaduste uurija Yann LeCun. LeCun tugines Jaapani teadlase Kunihiko Fukushima tööle, pildituvastuse põhivõrgule.
CNN-i vana versioon nimega LeNet (LeCuni järgi) näeb käsitsi kirjutatud numbreid. CNN aitab leida posti teel PIN-koode. Kuid vaatamata oma teadmistele püsisid ConvNets arvutinägemise ja tehisintellekti lähedal, sest nad seisid silmitsi suure probleemiga: nad ei saanud palju skaleerida. CNN-id vajavad suurte piltide jaoks hästi toimimiseks palju andmeid ja integreerivad ressursse.
Sel ajal oli see meetod rakendatav ainult madala eraldusvõimega piltide jaoks. Pytorch on raamatukogu, mis suudab teha süvaõppe toiminguid. Saame seda kasutada konvolutsiooniliste närvivõrkude teostamiseks. Konvolutsioonilised närvivõrgud sisaldavad palju tehisneuronite kihte. Sünteetilised neuronid, bioloogiliste vastete keerulised simulatsioonid, on matemaatilised funktsioonid, mis arvutavad mitme sisendi kaalutud massi ja toote väärtuse aktiveerimise.

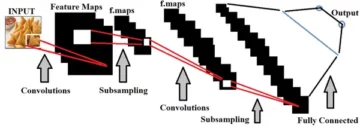
Ülaltoodud pilt näitab meile CNN-i mudelit, mis võtab numbriga sarnase kujutise 2 ja annab meile tulemuse, millist numbrit pildil näidati numbrina. Selles artiklis arutame üksikasjalikult, kuidas seda teha.
CIFAR-10 on andmestik, mis sisaldab 10 erinevat klassi kujutist. Seda andmekogumit kasutatakse laialdaselt uurimiseesmärkidel erinevate masinõppemudelite testimiseks ja eriti arvuti nägemisprobleemide jaoks. Selles artiklis proovime Pytorchi abil luua närvivõrgu mudeli ja testida seda CIFAR-10 andmekogumis, et kontrollida, millist ennustuse täpsust on võimalik saada.
PyTorchi teegi importimine
import numpy as np import pandad pd-na
import tõrvik import torch.nn.functional as F from torchvision import andmestik, teisendub taskulampist import nn import matplotlib.pyplot as plt import numpy as np import seaborn as sns #from tqdm.notebook import tqdm from tqdm import tqdm
Selles etapis impordime vajalikud teegid. Näeme, et kasutame numbriliste operatsioonide jaoks NumPyt ja andmeraami operatsioonide jaoks pandasid. Torchi teeki kasutatakse Pytorchi importimiseks.
Pytorchis on nn-komponent, mida kasutatakse masinõppe operatsioonide ja funktsioonide abstraktsiooniks. See imporditakse kui F. Torchvisioni teeki kasutatakse selleks, et saaksime importida CIFAR-10 andmekogumit. Sellel raamatukogul on palju pildiandmekogumeid ja seda kasutatakse laialdaselt uurimistöös. Teisendusi saab importida, et saaksime muuta pildi suurust kõigi piltide jaoks võrdseks. Tqdm-i kasutatakse selleks, et saaksime treeningu ajal edenemist jälgida ja seda kasutatakse visualiseerimiseks.
Lugege nõutav andmestik
trainData = pd.read_csv('cifar-10/trainLabels.csv') trainData.head()
Kui oleme andmestiku lugenud, näeme erinevaid silte, nagu konn, veoauto, hirv, auto jne.
Andmete analüüsimine PyTorchiga
print("Punktide arv:",trainData.shape[0]) print("Omaduste arv:",trainData.shape[1]) print("Features:",trainData.columns.values) print("Number of Unikaalsed väärtused") veeru jaoks in trainData: print(col,":",len(trainData[col].unique())) plt.figure(figsize=(12,8))
Väljund:
Punktide arv: 50000 Funktsioonide arv: 2 Funktsioonid: ['id' 'silt'] Unikaalsete väärtuste arv id : 50000 silt : 10
Selles etapis analüüsime andmekogumit ja näeme, et meie rongiandmetes on ligikaudu 50000 10 rida koos nende ID ja seotud sildiga. Kokku on 10 klassi nagu nimes CIFAR-XNUMX.
Valideerimiskomplekti hankimine PyTorchi abil
failist torch.utils.data import random_split val_size = 5000 rongi_suurus = len(andmestik) - val_size train_ds, val_ds = random_split(andmeset, [train_size, val_size]) len(train_ds), len(val_ds)
See samm on sama, mis koolitusetapp, kuid me tahame jagada andmed koolitus- ja valideerimiskomplektideks.
(45000, 5000)
failist torch.utils.data.dataloader import DataLoader batch_size=64 train_dl = DataLoader(train_ds, batch_size, shuffle=True, num_workers=4, pin_memory=True) val_dl = DataLoader(val_ds, num_workmeize=4, num_Trueory)
Rakendusel torch.utils on andmelaadija, mis aitab meil laadida vajalikke andmeid, jättes mööda erinevatest parameetritest, nagu töötaja number või partii suurus.
Vajalike funktsioonide määratlemine
@torch.no_grad() def täpsus(väljundid, sildid): _, preds = torch.max(väljundid, dim=1) return torch.tensor(torch.sum(preds == sildid).item() / len(preds )) class ImageClassificationBase(nn.Module): def training_step(self, batch): images, labels = batch out = self(images) # Prognooside loomine loss = F.cross_entropy(out, labels) # Arvuta kadu accu = accuracy(out ,labels) return loss,accu def validation_step(self, batch): images, labels = batch out = self(images) # Loo ennustusi loss = F.cross_entropy(out, labels) # Arvuta kadu acc = accuracy(out, labels) # Arvuta täpsuse tootlus {'Loss': loss.detach(), 'Täpsus': acc} def validation_epoch_end(self, outputs): batch_losses = [x['Loss'] x jaoks väljundis] epoch_loss = torch.stack(batch_losses) ).mean() # Kombineeri kadud batch_accs = [x['Täpsus'] x jaoks väljundis] epoch_acc = torch.stack(batch_accs).mean() # Kombineeri täpsused return {'Loss': epoch_loss.item(), ' Täpsus': epoch_acc.item()} def epoch_end(self, epoch, result): pr int("Epoch :",epoch + 1) print(f'Rongi täpsus:{tulemus["rongi_täpsus"]*100:.2f}% Valideerimistäpsus:{tulemus["Täpsus"]*100:.2f}%' ) print(f'Rongi kadu:{tulemus["rongi_kaotus"]:.4f} Valideerimiskaotus:{tulemus["Kadu"]:.4f}')
Nagu näeme siin, oleme kasutanud ImageClassification klassi rakendamist ja see võtab ühe parameetri, milleks on nn.Module. Selles klassis saame rakendada erinevaid funktsioone või erinevaid samme, nagu koolitus, valideerimine jne. Funktsioonid on siin lihtsad pythoni teostused.
Koolitusetapis võetakse pilte ja silte partiidena. kasutame kahjufunktsiooni jaoks ristentroopiat ning arvutame kadu ja tagastame kahju. See sarnaneb valideerimisetapiga, nagu näeme funktsioonis. Ajastu lõpud ühendavad kaotused ja täpsused ning lõpuks trükime täpsused ja kaod.
Konvolutsioonilise närvivõrgu mooduli rakendamine
klass Cifar10CnnModel(ImageClassificationBase): def __init__(self): super().__init__() self.network = nn.Sequential( nn.Conv2d(3, 32, kernel_size=3, padding=1), nn.ReLU(), nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1), nn.ReLU(), nn.MaxPool2d(2, 2), # väljund: 64 x 16 x 16 nn.BatchNorm2d(64) , nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1), nn.ReLU(), nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1), nn .ReLU(), nn.MaxPool2d(2, 2), # väljund: 128 x 8 x 8 nn.BatchNorm2d(128), nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1), nn.ReLU(), nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1), nn.ReLU(), nn.MaxPool2d(2, 2), # väljund: 256 x 4 x 4 nn.BatchNorm2d(256), nn.Flatten(), nn.Lineaarne(256*4*4, 1024), nn.ReLU(), nn.Lineaarne(1024, 512), nn.ReLU(), nn.Lineaarne (512, 10)) def forward(self, xb): return self.network(xb)
See on närvivõrgu rakendamise kõige olulisem osa. Kogu aeg kasutame taskulambist imporditud nn-moodulit. Nagu näeme esimesel real, on Conv2d moodul, mis aitab rakendada konvolutsioonilist närvivõrku. Esimene parameeter 3 tähistab siin seda, et pilt on värviline ja RGB-vormingus. Kui see oleks olnud halltoonides pilt, oleksime valinud 1.
32 on algse väljundkanali suurus ja kui me läheme järgmise conv2d kihi juurde, oleks meil see 32 sisendkanaliks ja 64 väljundkanaliks.
Kolmandat parameetrit esimesel real nimetatakse kerneli suuruseks ja see aitab meil kasutatavate filtrite eest hoolt kanda. Täitmise toiming on viimane parameeter.
Konvolutsioonioperatsioon on ühendatud aktiveerimiskihiga ja siin on Relu. Pärast kahte Conv2d kihti on meil maksimaalne kogumisoperatsioon suurusega 2 * 2. Sellest tulenev väärtus normaliseeritakse stabiilsuse ja sisemise ühismuutuja nihke vältimiseks. Neid toiminguid korratakse rohkemate kihtidega, et võrk süvendada ja suurust vähendada. Lõpuks tasandame kihi nii, et saame luua lineaarse kihi, et kaardistada väärtused 10 väärtusega. Nende 10 neuroni iga neuroni tõenäosus määrab maksimaalse tõenäosuse alusel, millisesse klassi konkreetne kujutis kuulub.
Treeni modelli
@torch.no_grad() def hindama(mudel, andmete_laadur): model.eval() outputs = [modell.validation_step(batch) partii jaoks andmelaaduris] return model.validation_epoch_end(outputs) def fit(modell, train_loader, val_loader,epochs) =10,õppe_määr=0.001): parim_kehtiv = ajalugu puudub = [] optimeerija = torch.optim.Adam(modell.parameters(), learning_rate,weight_decay=0.0005) epohhi jaoks vahemikus (epohhid): # Treeningfaas model.train( ) train_losses = [] train_accuracy = [] partii jaoks tqdm(rongi_laadur): loss,accu = model.training_step(batch) train_losses.append(loss) train_accuracy.append(accu) loss.backward() optimeerija.step() optimeerija .zero_grad() # Valideerimisfaasi tulemus = hinda(mudel, val_loader) result['train_loss'] = torch.stack(train_losses).mean().item() result['train_accuracy'] = torch.stack(train_accuracy). mean().item() model.epoch_end(epoch, result) if(best_valid == None või best_valid
ajalugu = sobiv(mudel, rongi_dl, val_dl)
See on põhietapp meie mudeli väljaõpetamiseks, et saada vajalikku tulemust. siin olev sobivusfunktsioon sobitab rongi ja Vali andmed meie loodud mudeliga. Sobivusfunktsioon võtab algselt loendi nimega ajalugu, mis hoolitseb iga epohhi iteratsiooniandmete eest. Käitame for-silmust, et saaksime iga ajastu itereerida. Iga partii puhul näitame kindlasti edenemist tqdm abil. Nimetame varem rakendatud koolitusetapi ja arvutame täpsuse ja kadu. Eelnevalt määratletud tagurpidi levitamine ja optimeerija käivitamine. Kui oleme seda teinud, jälgime oma loendit ja funktsioonid aitavad meil üksikasju ja edenemist printida.
Hindamisfunktsioon seevastu kasutab eval funktsiooni ja iga sammu jaoks võtame andmelaadijast laaditud partii ja väljund arvutatakse. Seejärel edastatakse väärtus meie varem määratletud valideerimisperioodi lõppu ja vastav väärtus tagastatakse.
Tulemuste joonistamine
Selles etapis visualiseerime täpsust iga ajastu suhtes. Võib täheldada, et epohhi kasvades suureneb süsteemi täpsus ja samamoodi väheneb kadu. Punane joon tähistab siin treeningandmete edenemist ja sinine valideerimiseks. Näeme, et meie tulemustes on olnud palju ülepaigutamist, kuna treeninguandmed on valideerimistulemusest üsna paremad ja samamoodi ka kaotuse korral. 10 ajaperioodi järel näivad rongiandmed ületavat 90% täpsust, kuid nende kadu on umbes 0.5. Katseandmed on umbes 81% ja kaod on 0.2 lähedal.
def plot_accuracies(ajalugu): Validation_accuracies = [x['Täpsus'] x jaoks ajaloos] Training_Accuracies = [x['train_accuracy'] x jaoks ajaloos] plt.plot(Treening_accuracies, '-rx') plt.plot(Validation_accura , '-bx') plt.xlabel('epohh') plt.ylabel('täpsus') plt.legend(['Treening', 'Validation']) plt.title('Täpsus vs. ajastute arv') ; plot_accuracies (ajalugu)

def plot_losses(ajalugu): train_losses = [x.get('train_loss') x jaoks ajaloos] val_losses = [x['Loss'] jaoks x ajaloos] plt.plot(train_losses, '-bx') plt.plot (val_losses, '-rx') plt.xlabel('epoch') plt.ylabel('loss') plt.legend(['Treening', 'Validation']) plt.title('Kaotus vs. ajastute arv '); plot_losses(ajalugu)
test_dataset = ImageFolder(data_dir+'/test', transform=ToTensor()) test_loader = DeviceDataLoader(DataLoader(test_dataset, partii_suurus), seade) result = hindama(lõplik_mudel, test_loader) print(f'Testi täpsus:{tulemus"["A ]*100:.2f}%')
Testi täpsus: 81.07%
Näeme, et saame lõpuks 81.07% täpsusega.
Järeldus:
pilt:https://unsplash.com/photos/5L0R8ZqPZHk
Endast: Olen teadusüliõpilane, kes on huvitatud süvaõppe ja loomuliku keele töötlemise valdkonnast ning jätkan praegu tehisintellekti eriala lõpetamist.
Pildi allikas
- Image 1: https://becominghuman.ai/cifar-10-image-classification-fd2ace47c5e8
- Pilt 2: https://www.analyticsvidhya.com/blog/2021/05/convolutional-neural-networks-cnn/
Võtke minuga julgelt ühendust aadressil:
- Linkedin: https://www.linkedin.com/in/siddharth-m-426a9614a/
- Github: https://github.com/Siddharth1698
Selles artiklis näidatud meediumid ei kuulu Analytics Vidhyale ja neid kasutatakse autori äranägemisel.
seotud
- "
- Materjal: BPA ja flataatide vaba plastik
- analytics
- ümber
- artikkel
- tehisintellekti
- ehitama
- helistama
- mis
- CNN
- tulevad
- komponent
- Arvutiteadus
- Arvuti visioon
- konvolutsioonneuraalvõrk
- andmed
- sügav õpe
- Hirv
- detail
- Arv
- numbrit
- lõppeb
- jms
- FUNKTSIOONID
- Filtrid
- Lõpuks
- esimene
- sobima
- formaat
- tasuta
- funktsioon
- GitHub
- hea
- Halltoonid
- siin
- ajalugu
- Kuidas
- HTTPS
- pilt
- Kujutise tuvastamine
- Suurendama
- Intelligentsus
- IT
- Labels
- keel
- suur
- õppimine
- Raamatukogu
- joon
- nimekiri
- koormus
- masinõpe
- peamine
- kaart
- Meedia
- mudel
- Loomulik keel
- Natural Language Processing
- Lähedal
- võrk
- võrgustikud
- Neural
- Närvivõrgus
- närvivõrgud
- Operations
- Muu
- ennustus
- Ennustused
- Toode
- Python
- pütorch
- vähendama
- teadustöö
- Vahendid
- Tulemused
- jooks
- Skaala
- teadus
- komplekt
- suunata
- lihtne
- SUURUS
- So
- jagada
- Stabiilsus
- õpilane
- süsteem
- test
- aeg
- tõrvik
- jälgida
- koolitus
- veoauto
- us
- väärtus
- nägemus
- visualiseerimine
- WHO
- jooksul
- Töö
- X