Sissejuhatus
Töötate konsultatsioonifirmas andmeteadlasena. Projekt, millesse teid praegu määrati, sisaldab andmeid õpilastelt, kes on hiljuti lõpetanud rahandusalased kursused. Kursusi läbi viiv finantsettevõte soovib mõista, kas on ühiseid tegureid, mis mõjutavad õpilasi samu kursusi või erinevaid kursusi ostma. Nendest teguritest aru saades saab ettevõte luua õpilase profiili, liigitada iga õpilast profiili järgi ja soovitada kursuste loendit.
Erinevate õpilasrühmade andmete kontrollimisel olete kohanud kolme punktide paigutust, nagu allolevates punktides 1, 2 ja 3:
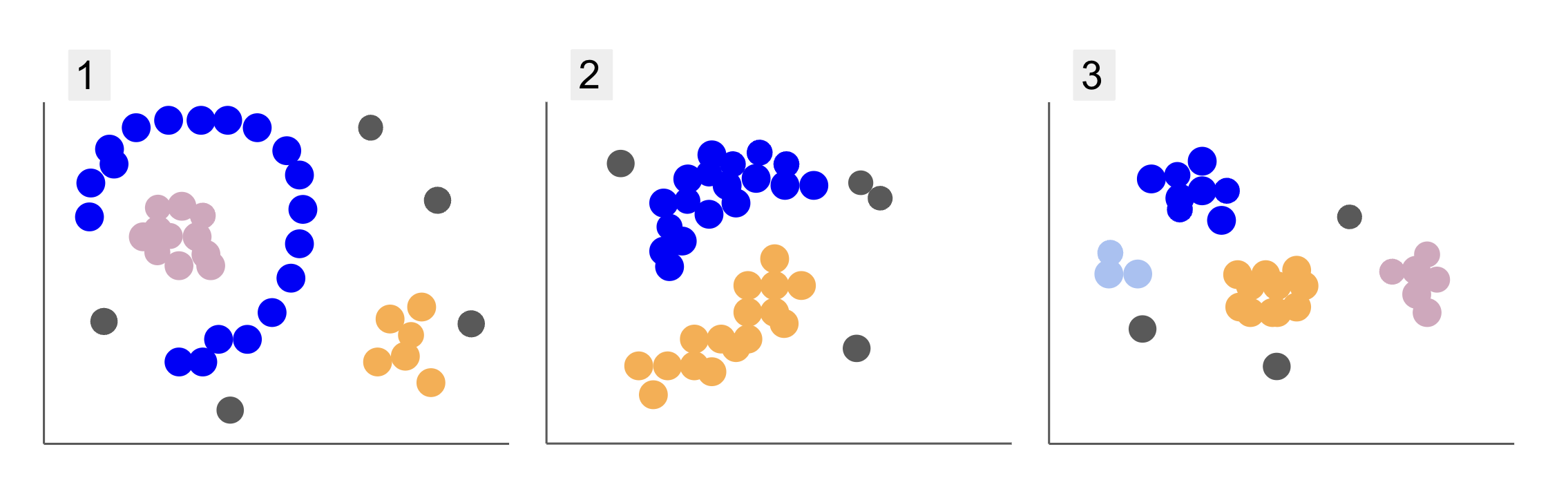
Pange tähele, et joonisel 1 on poolringiks korraldatud lillad punktid, mille sees on roosade punktide mass, sellest poolringist väljaspool on väike oranžide punktide kontsentratsioon ja viis halli punkti, mis on kõigist teistest kaugel.
Joonisel 2 on ümmargune mass lillasid punkte, teine oranži punkte ja samuti neli halli punkti, mis on kõigist teistest kaugel.
Ja joonisel 3 näeme nelja punktide kontsentratsiooni, lillat, sinist, oranži, roosa ja kolme kaugemat halli punkti.
Kui nüüd valida mudel, mis suudaks mõista uusi õpilaste andmeid ja määrata sarnaseid rühmi, kas on olemas rühmitusalgoritm, mis annaks sellistele andmetele huvitavaid tulemusi?
Kruntide kirjeldamisel mainisime selliseid termineid nagu punktide mass ja punktide kontsentratsioon, mis näitab, et kõikidel graafikutel on suurema tihedusega alasid. Viitasime ka ring- ja poolringikujuline kujundeid, mida on raske tuvastada sirgjoone tõmbamise või pelgalt lähimate punktide uurimisega. Lisaks on mõned kauged punktid, mis tõenäoliselt kalduvad kõrvale põhiandmete jaotusest, mis toob kaasa rohkem väljakutseid või müra rühmade määramisel.
Tiheduspõhine algoritm, mis suudab välja filtreerida müra, nt DBSCAN (Desitus-Bpiirata Ssisemine Cläikiv Arakendused koos Noise) on tugev valik olukordades, kus on tihedamad alad, ümarad kujundid ja müra.
DBSCANi kohta
DBSCAN on üks enim tsiteeritud algoritme uurimistöös, selle esimene väljaanne ilmus 1996. aastal, see on originaal DBSCAN paber. Artiklis näitavad teadlased, kuidas algoritm suudab tuvastada mittelineaarseid ruumiklastreid ja käsitleda tõhusalt suuremate mõõtmetega andmeid.
DBSCANi põhiidee seisneb selles, et on olemas minimaalne arv punkte, mis jäävad kindlaksmääratud kaugusele või raadius kõige "kesksemast" klastri punktist, mida nimetatakse põhipunkt. Selles raadiuses olevad punktid on naabruspunktid ja selle naabruskonna serval olevad punktid piiripunktid or piiripunktid. Raadiust või naabruskonna kaugust nimetatakse epsiloni naabruskond, ε-naabruskond või lihtsalt ε (kreeka tähe epsilon sümbol).
Lisaks, kui on punkte, mis ei ole põhipunktid või piiripunktid, kuna need ületavad määratud klastrisse kuulumise raadiuse ja neil ei ole põhipunktiks vajalikku minimaalset punktide arvu, võetakse need arvesse. mürapunktid.
See tähendab, et meil on kolme erinevat tüüpi punkte, nimelt tuum, piir ja müra. Lisaks on oluline märkida, et põhiidee põhineb põhimõtteliselt raadiusel või kaugusel, mis muudab DBSCANi – nagu enamiku klastrite mudelite – sellest kauguse mõõdikust sõltuvaks. See mõõdik võib olla Eukleidiline, Manhattan, Mahalanobis ja palju muud. Seetõttu on ülioluline valida sobiv kaugusmõõdik, mis arvestab andmete konteksti. Näiteks kui kasutate GPS-i sõidukauguse andmeid, võib olla huvitav kasutada mõõdikut, mis võtab arvesse tänavate paigutust, näiteks Manhattani kaugust.

Märge: Kuna DBSCAN kaardistab punktid, mis moodustavad müra, saab seda kasutada ka kõrvalekallete tuvastamise algoritmina. Näiteks kui proovite kindlaks teha, millised pangatehingud võivad olla petturlikud ja pettuste määr on väike, võib DBSCAN olla lahendus nende punktide tuvastamiseks.
Tuumpunkti leidmiseks valib DBSCAN esmalt juhuslikult punkti, kaardistab kõik selle ε-naabruses olevad punktid ja võrdleb valitud punkti naabrite arvu minimaalse punktide arvuga. Kui valitud punktil on minimaalsest punktide arvust võrdne arv või rohkem naabreid, märgitakse see põhipunktiks. See põhipunkt ja selle naabruspunktid moodustavad esimese klastri.
Algoritm uurib seejärel esimese klastri iga punkti ja vaatab, kas sellel on võrdne arv või rohkem naaberpunkte kui minimaalne punktide arv ε piires. Kui see nii on, lisatakse need naaberpunktid ka esimesse klastrisse. See protsess jätkub seni, kuni esimese klastri punktidel on vähem naabreid kui minimaalne punktide arv ε piires. Kui see juhtub, lõpetab algoritm sellesse klastrisse punktide lisamise, tuvastab teise tuumpunkti väljaspool seda klastrit ja loob selle uue tuumikpunkti jaoks uue klastri.
DBSCAN kordab seejärel esimese klastri protsessi, et leida kõik punktid, mis on ühendatud teise klastri uue tuumpunktiga, kuni sellesse klastrisse pole enam punkte vaja lisada. Seejärel kohtab see teise põhipunkti ja loob kolmanda klastri või kordab läbi kõik punktid, mida ta pole varem vaadanud. Kui need punktid on klastrist ε kaugusel, lisatakse need sellesse klastrisse, muutudes piiripunktideks. Kui neid ei ole, peetakse neid mürapunktideks.
Nõuanne: DBSCAN-i ideega on seotud palju reegleid ja matemaatilisi demonstratsioone. Kui soovite süveneda, võiksite heita pilgu algsele paberile, mille link on ülal.
Huvitav on teada, kuidas DBSCAN-algoritm töötab, kuigi õnneks pole algoritmi vaja kodeerida, kui Pythoni Scikit-Learn teegil on juba rakendus olemas.
Vaatame, kuidas see praktikas toimib!
Andmete import rühmitamiseks
Et näha, kuidas DBSCAN praktikas töötab, muudame veidi projekte ja kasutame väikest kliendiandmestikku, mille žanr, vanus, aastasissetulek ja kuluskoor on 200 klienti.
Kulutusskoor jääb vahemikku 0–100 ja näitab, kui sageli inimene kulutab raha kaubanduskeskuses skaalal 1–100. Teisisõnu, kui kliendi skoor on 0, ei kuluta ta kunagi raha ja kui skoor on 100, kulutavad nad kõige rohkem.
Märge: Saate andmestiku alla laadida siin.
Pärast andmekogumi allalaadimist näete, et tegemist on CSV-failiga (komaeraldusega väärtused). shopping-data.csv, laadime selle Pandade abil DataFrame'i ja salvestame selle kausta customer_data muutuja:
import pandas as pd path_to_file = '../../datasets/dbscan/dbscan-with-python-and-scikit-learn-shopping-data.csv'
customer_data = pd.read_csv(path_to_file)
Meie andmete esimese viie rea vaatamiseks võite käivitada customer_data.head():
Selle tulemuseks on:
CustomerID Genre Age Annual Income (k$) Spending Score (1-100)
0 1 Male 19 15 39
1 2 Male 21 15 81
2 3 Female 20 16 6
3 4 Female 23 16 77
4 5 Female 31 17 40
Andmeid uurides näeme kliendi ID-numbreid, žanri, vanust, sissetulekuid k$-des ja kuluskoore. Pidage meeles, et mudelis kasutatakse mõnda või kõiki neist muutujatest. Näiteks kui me peaksime kasutama Age ja Spending Score (1-100) DBSCANi muutujatena, mis kasutab kauguse mõõdikut, on oluline viia need ühisele skaalale, et vältida moonutusi, kuna Age mõõdetakse aastates ja Spending Score (1-100) on piiratud vahemikuga 0 kuni 100. See tähendab, et teostame mingisuguse andmete skaleerimise.
Samuti saame kontrollida, kas andmed vajavad lisaks skaleerimisele veel eeltöötlust, kontrollides, kas andmete tüüp on järjepidev ja kontrollides, kas puuduvad väärtused, mida tuleb Panda käivitamisega töödelda. info() meetod:
customer_data.info()
See kuvab:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 200 entries, 0 to 199
Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 CustomerID 200 non-null int64 1 Genre 200 non-null object 2 Age 200 non-null int64 3 Annual Income (k$) 200 non-null int64 4 Spending Score (1-100) 200 non-null int64 dtypes: int64(4), object(1)
memory usage: 7.9+ KB
Näeme, et puuduvad väärtused, kuna iga kliendi funktsiooni kohta on 200 mitte-null-kirjet. Samuti näeme, et ainult žanri veerus on tekstisisu, kuna tegemist on kategoorilise muutujaga, mis kuvatakse kui object, ja kõik muud funktsioonid on numbrilised, seda tüüpi int64. Seega on andmetüüpide järjepidevuse ja nullväärtuste puudumise osas meie andmed edasiseks analüüsiks valmis.
Saame jätkata andmete visualiseerimist ja määrata, milliseid funktsioone oleks huvitav DBSCANis kasutada. Pärast nende funktsioonide valimist saame neid skaleerida.
See kliendiandmestik on sama, mida kasutati meie lõplikus hierarhilise klastrite juhendis. Nende andmete, nende uurimise ja kaugusmõõdikute kohta lisateabe saamiseks vaadake Lõplik Pythoni ja Scikit-Learni hierarhilise rühmitamise juhend!
Andmete visualiseerimine
Seaborni kasutades pairplot(), saame iga tunnuste kombinatsiooni jaoks joonistada hajuvusgraafiku. Alates CustomerID on lihtsalt tunnus, mitte funktsioon, eemaldame selle koos drop() enne joonistamist:
import seaborn as sns customer_data = customer_data.drop('CustomerID', axis=1) sns.pairplot(customer_data);
See annab väljundi:

Kui vaadata funktsioonide kombinatsiooni, mille toodab pairplot, graafik Annual Income (k$) koos Spending Score (1-100) näib kuvavat umbes 5 punktide rühma. See näib olevat kõige lootustandvam funktsioonide kombinatsioon. Saame luua nende nimedega loendi, valida need loendist customer_data DataFrame ja salvestage valik kausta customer_data muutuja uuesti kasutamiseks meie tulevases mudelis.
selected_cols = ['Annual Income (k$)', 'Spending Score (1-100)']
customer_data = customer_data[selected_cols]
Pärast veergude valimist saame teha eelmises jaotises käsitletud skaleerimise. Funktsioonide samale skaalale toomiseks või standardima neid, saame importida Scikit-Learni StandardScaler, looge see, sobitage meie andmed selle keskmise ja standardhälbe arvutamiseks ning teisendage andmed, lahutades selle keskmise ja jagades need standardhälbega. Seda saab teha ühes etapis rakendusega fit_transform() meetod:
from sklearn.preprocessing import StandardScaler ss = StandardScaler() scaled_data = ss.fit_transform(customer_data)
Muutujad on nüüd skaleeritud ja saame neid uurida, trükkides lihtsalt faili sisu scaled_data muutuv. Teise võimalusena saame need lisada ka uuele scaled_customer_data DataFrame koos veergude nimedega ja kasutage head() meetod uuesti:
scaled_customer_data = pd.DataFrame(columns=selected_cols, data=scaled_data)
scaled_customer_data.head()
See annab väljundi:
Annual Income (k$) Spending Score (1-100)
0 -1.738999 -0.434801
1 -1.738999 1.195704
2 -1.700830 -1.715913
3 -1.700830 1.040418
4 -1.662660 -0.395980 Need andmed on rühmitamiseks valmis! DBSCANi tutvustamisel mainisime minimaalset punktide arvu ja epsilonit. Need kaks väärtust tuleb valida enne mudeli loomist. Vaatame, kuidas see tehtud on.
Min. Proovid ja Epsilon
DBSCAN-i klastrite jaoks minimaalse punktide arvu valimiseks kehtib rusikareegel, mis ütleb, et see peab olema võrdne andmete dimensioonide arvuga pluss üks või suurem, nagu:
$$
tekst{min. punktid} >= tekst{andmete mõõtmed} + 1
$$
Mõõtmed on andmeraami veergude arv, me kasutame 2 veergu, seega min. punktid peaksid olema kas 2+1, mis on 3 või rohkem. Selle näite puhul kasutame 5 min. punktid.
$$
tekst{5 (min punktid)} >= tekst{2 (andmete mõõtmed)} + 1
$$
Tutvuge meie praktilise ja praktilise Giti õppimise juhendiga, mis sisaldab parimaid tavasid, tööstusharus aktsepteeritud standardeid ja kaasas olevat petulehte. Lõpetage Giti käskude guugeldamine ja tegelikult õppima seda!
Nüüd on ε väärtuse valimiseks meetod, milles a Lähimad naabrid Algoritmi kasutatakse iga punkti jaoks etteantud arvu lähimate punktide kauguste leidmiseks. See eelmääratletud naabrite arv on min. punktid, mille me just valisime miinus 1. Seega meie puhul leiab algoritm iga meie andmete punkti kohta 5-1 ehk 4 lähimat punkti. need on k-naabrid ja meie k võrdub 4.
$$
tekst{k-naabrid} = tekst{min. punktid} – 1
$$
Pärast naabrite leidmist järjestame nende kaugused suurimast väiksemani ning joonistame y-telje ja punktide kaugused x-teljel. Graafikut vaadates leiame, kus see sarnaneb küünarnuki paindumisega ja y-telje punkt, mis kirjeldab, et küünarnukk on painutatud, on soovitatud ε väärtus.
märkused: on võimalik, et ε väärtuse leidmise graafikul on kas üks või mitu küünarnuki painutust, kas suured või väikesed, kui see juhtub, saate väärtused leida, neid testida ja valida need, mille tulemused kirjeldavad klastreid kõige paremini, kas siis graafikute mõõdikuid vaadates.
Nende toimingute tegemiseks saame importida algoritmi, sobitada selle andmetega ja seejärel eraldada iga punkti kaugused ja indeksid. kneighbors() meetod:
from sklearn.neighbors import NearestNeighbors
import numpy as np nn = NearestNeighbors(n_neighbors=4) nbrs = nn.fit(scaled_customer_data)
distances, indices = nbrs.kneighbors(scaled_customer_data)
Pärast vahemaade leidmist saame need järjestada suurimast väiksemani. Kuna kauguste massiivi esimene veerg on punktist iseendale (see tähendab, et kõik on 0) ja teine veerg sisaldab väikseimaid vahemaid, millele järgneb kolmas veerg, mille kaugused on suuremad kui teisel jne, saame valida ainult teise veeru väärtused ja salvestage need kausta distances muutuja:
distances = np.sort(distances, axis=0)
distances = distances[:,1] Nüüd, kui meie väikseimad vahemaad on sorteeritud, saame importida matplotlib, joonistage vahemaad ja tõmmake punane joon küünarnuki kõvera kohale:
import matplotlib.pyplot as plt plt.figure(figsize=(6,3))
plt.plot(distances)
plt.axhline(y=0.24, color='r', linestyle='--', alpha=0.4) plt.title('Kneighbors distance graph')
plt.xlabel('Data points')
plt.ylabel('Epsilon value')
plt.show();
See on tulemus:

Pange tähele, et joone tõmbamisel saame teada ε väärtuse, antud juhul see on nii 0.24.
Lõpuks on meil oma miinimumpunktid ja ε. Mõlema muutujaga saame luua ja käivitada mudeli DBSCAN.
DBSCAN-mudeli loomine
Mudeli loomiseks saame selle importida Scikit-Learnist, luua selle ε-ga, mis on sama mis eps argument ja miinimumpunktid, milleni on mean_samples argument. Seejärel saame selle salvestada muutujasse, nimetagem seda dbs ja sobitage see skaleeritud andmetega:
from sklearn.cluster import DBSCAN dbs = DBSCAN(eps=0.24, min_samples=5)
dbs.fit(scaled_customer_data)
Just nii on meie DBSCAN-mudel loodud ja andmete põhjal koolitatud! Tulemuste eraldamiseks pääseme juurde labels_ vara. Samuti saame luua uue labels veerg scaled_customer_data andmeraamistik ja täitke see ennustatud siltidega:
labels = dbs.labels_ scaled_customer_data['labels'] = labels
scaled_customer_data.head()
See on lõpptulemus:
Annual Income (k$) Spending Score (1-100) labels
0 -1.738999 -0.434801 -1
1 -1.738999 1.195704 0
2 -1.700830 -1.715913 -1
3 -1.700830 1.040418 0
4 -1.662660 -0.395980 -1
Pange tähele, et meil on sildid -1 väärtused; need on mürapunktid, need, mis ei kuulu ühtegi klastrisse. Et teada saada, mitu mürapunkti algoritm leidis, saame lugeda, mitu korda kuvatakse väärtus -1 meie siltide loendis:
labels_list = list(scaled_customer_data['labels'])
n_noise = labels_list.count(-1)
print("Number of noise points:", n_noise)
See annab väljundi:
Number of noise points: 62
Teame juba, et 62 punkti meie esialgsetest 200-punktilistest andmetest peeti müraks. See on palju müra, mis näitab, et võib-olla ei pidanud DBSCAN-i klasterdamine paljusid punkte klastri osaks. Mis juhtus, saame aru varsti, kui andmeid joonistame.
Algselt, kui me andmeid vaatlesime, tundus, et sellel on 5 punktide klastrit. Et teada saada, kui palju klastreid DBSCAN on moodustanud, saame kokku lugeda nende siltide arvu, mis ei ole -1. Selle koodi kirjutamiseks on palju viise; siin oleme kirjutanud for-tsükli, mis töötab ka andmete puhul, milles DBSCAN on leidnud palju klastreid:
total_labels = np.unique(labels) n_labels = 0
for n in total_labels: if n != -1: n_labels += 1
print("Number of clusters:", n_labels)
See annab väljundi:
Number of clusters: 6
Näeme, et algoritm ennustas andmetel 6 klastrit, millel on palju mürapunkte. Kujutagem seda ette, joonistades selle seaborniga scatterplot:
sns.scatterplot(data=scaled_customer_data, x='Annual Income (k$)', y='Spending Score (1-100)', hue='labels', palette='muted').set_title('DBSCAN found clusters');
Selle tulemuseks on:

Graafikut vaadates näeme, et DBSCAN on püüdnud kinni punktid, mis olid tihedamalt ühendatud, ja punktid, mida võiks pidada sama klastri osaks, olid kas müra või peeti teise väiksema klastri moodustamiseks.

Kui tõstame klastrid esile, märkige, kuidas DBSCAN saab täielikult klastri 1, mis on klastri, mille punktide vahel on vähem ruumi. Siis saab ta klastrite 0 ja 3 osad, kus punktid on tihedalt koos, võttes müraks kaugemal asuvaid punkte. Samuti käsitleb see alumises vasakpoolses osas olevaid punkte mürana ja jagab alumises paremas osas olevad punktid kolmeks klastriks, jäädvustades taas klastrid 3, 4 ja 2, kus punktid on üksteisele lähemal.
Võime hakata jõudma järeldusele, et DBSCAN oli suurepärane klastrite tihedate alade hõivamiseks, kuid mitte niivõrd andmete suurema skeemi, 5 klastri piiritlemise tuvastamiseks. Oleks huvitav testida meie andmetega rohkem rühmitamisalgoritme. Vaatame, kas mõõdik kinnitab seda hüpoteesi.
Algoritmi hindamine
DBSCANi hindamiseks kasutame silueti skoori mis võtab arvesse sama klastri punktide vahelist kaugust ja klastrite vahelisi kaugusi.
Märge: Praegu ei ole enamik rühmitusmõõdikuid DBSCAN-i hindamiseks tegelikult sobitatud, kuna need ei põhine tihedusel. Siin kasutame silueti skoori, kuna see on Scikit-learnis juba rakendatud ja kuna see püüab vaadata klastri kuju.
Sobivama hinnangu saamiseks võite seda kasutada või kombineerida Tiheduspõhine klastrite valideerimine (DBCV) mõõdik, mis on loodud spetsiaalselt tiheduspõhiseks klastriteks. Selle jaoks on saadaval DBCV rakendus GitHub.
Esiteks saame importida silhouette_score Scikit-Learnist, edastage see meie veergudele ja siltidele:
from sklearn.metrics import silhouette_score s_score = silhouette_score(scaled_customer_data, labels)
print(f"Silhouette coefficient: {s_score:.3f}")
See annab väljundi:
Silhouette coefficient: 0.506
Selle skoori järgi näib, et DBSCAN suudab hõivata umbes 50% andmetest.
Järeldus
DBSCANi eelised ja puudused
DBSCAN on väga ainulaadne rühmitusalgoritm või mudel.
Kui vaatame selle eeliseid, siis on see väga hea andmete ja teistest kaugel asuvate punktide tihedate alade korjamiseks. See tähendab, et andmetel ei pea olema kindlat kuju ja need võivad olla ümbritsetud muude punktidega, kui need on samuti tihedalt ühendatud.
See nõuab meilt miinimumpunktide ja ε määramist, kuid klastrite arvu pole eelnevalt vaja täpsustada, nagu näiteks K-Meansis. Seda saab kasutada ka väga suurte andmebaasidega, kuna see on mõeldud suuremõõtmeliste andmete jaoks.
Mis puutub selle miinustesse, siis oleme näinud, et see ei suutnud samas klastris erinevaid tihedusi tabada, mistõttu on tal raske suurte tiheduseerinevustega toime tulla. See sõltub ka kauguse mõõdikust ja punktide skaleerimisest. See tähendab, et kui andmed ei ole hästi arusaadavad, nende mastaabis on erinevusi ja kaugusmõõdik on mõttetu, siis tõenäoliselt ei saa ta neist aru.
DBSCANi laiendused
Algoritme on teisigi, nt Hierarhiline DBSCAN (HDBSCAN) ja Punktide tellimine klastristruktuuri tuvastamiseks (OPTICS), mida peetakse DBSCANi laiendusteks.
Nii HDBSCAN kui ka OPTICS suudavad tavaliselt paremini toimida, kui andmetes on erineva tihedusega klastreid ja nad on ka valiku või algse min. punktid ja ε parameetrid.
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- Platoblockchain. Web3 metaversiooni intelligentsus. Täiustatud teadmised. Juurdepääs siia.
- Allikas: https://stackabuse.com/dbscan-with-scikit-learn-in-python/
- :on
- $ UP
- 1
- 10
- 100
- 11
- 1996
- 39
- 7
- 77
- 8
- 9
- a
- MEIST
- üle
- juurdepääs
- üle
- tegelikult
- lisatud
- Lisaks
- eelised
- pärast
- Häire
- algoritm
- algoritme
- Materjal: BPA ja flataatide vaba plastik
- juba
- Kuigi
- analüüs
- ja
- aastane
- Teine
- asjakohane
- umbes
- OLEME
- valdkondades
- argument
- ümber
- Array
- AS
- määratud
- At
- saadaval
- vältima
- Pank
- PANGATEHINGUD
- põhineb
- BE
- sest
- saada
- taga
- alla
- BEST
- Parem
- vahel
- Suur
- suurem
- Natuke
- sinine
- piir
- tooma
- by
- arvutama
- helistama
- kutsutud
- CAN
- lüüa
- Püüdmine
- juhul
- kesk-
- väljakutseid
- muutma
- kontrollima
- valik
- Vali
- valitud
- Ring
- Tsiteeritud
- klass
- Klassifitseerige
- lähedalt
- lähemale
- Cluster
- Klastrite loomine
- kood
- Veerg
- Veerud
- kombinatsioon
- ühendama
- Tulema
- ühine
- ettevõte
- võrdlema
- täiesti
- kontsentratsioon
- järeldus
- dirigeerib
- seotud
- Arvestama
- tasu
- kaaluda
- arvestades
- arvab
- järjepidev
- moodustama
- nõustamine
- sisaldab
- sisu
- kontekst
- jätkama
- tuum
- kinnitama
- võiks
- kursused
- looma
- loodud
- loob
- loomine
- otsustav
- Praegu
- klient
- Kliendid
- andmed
- andmepunktid
- andmebaasid
- DBS
- sügavam
- lõplik
- näitama
- Tihedus
- sõltuv
- kirjeldama
- kavandatud
- Detection
- Määrama
- kindlaksmääratud
- määrates kindlaks
- kõrvalekalle
- erinevused
- erinev
- raske
- DIG
- mõõdud
- arutatud
- Ekraan
- Näidikute
- kaugus
- Kaugel
- jaotus
- lae alla
- joonistus
- sõidu
- iga
- serv
- tõhusalt
- kumbki
- kohtumine
- Võrdub
- hindama
- hindamine
- Uurimine
- näide
- ületama
- täitma
- hukkamine
- uurima
- laiendused
- väljavõte
- tegurid
- FAIL
- kaugele
- tunnusjoon
- FUNKTSIOONID
- naine
- fail
- täitma
- filtreerida
- lõplik
- Lõpuks
- Finances
- finants-
- leidma
- leidmine
- esimene
- sobima
- Keskenduma
- Järgneb
- eest
- vorm
- moodustatud
- Õnneks
- avastatud
- FRAME
- pettusega
- Alates
- põhimõtteliselt
- edasi
- Pealegi
- tulevik
- Git
- Andma
- hea
- GPS
- graafik
- graafikud
- hall
- suur
- suurem
- Grupi omad
- suunata
- Pool
- käepide
- käed-
- juhtus
- juhtub
- Raske
- Olema
- siin
- rohkem
- kõrgeim
- Esile tõstma
- hõljuma
- Kuidas
- Kuidas
- HTTPS
- ICON
- ID
- idee
- Identifitseerimine
- identifitseerib
- identifitseerima
- identifitseerimiseks
- täitmine
- rakendatud
- import
- oluline
- in
- Teistes
- lisatud
- tulu
- näitab
- Indeksid
- mõju
- esialgne
- Näiteks
- huvitav
- sisse
- Sissejuhatus
- seotud
- IT
- ITS
- ise
- hoidma
- Laps
- Teadma
- Labels
- suur
- suurem
- suurim
- Õppida
- õppimine
- kiri
- LG
- Raamatukogu
- nagu
- Tõenäoliselt
- piiratud
- joon
- seotud
- nimekiri
- vähe
- koormus
- Pikk
- Vaata
- Vaatasin
- otsin
- Partii
- põhiline
- tegema
- TEEB
- palju
- kaart
- kaardid
- märgitud
- Mass
- matemaatiline
- matplotlib
- tähendus
- vahendid
- Mälu
- mainitud
- ainult
- meetod
- meetriline
- Meetrika
- võib
- meeles
- miinimum
- puuduvad
- mudel
- mudelid
- raha
- rohkem
- kõige
- nimelt
- nimed
- Vajadus
- vajadustele
- naabrid
- Uus
- müra
- number
- numbrid
- tuim
- objekt
- jälgima
- of
- on
- ONE
- optika
- oranž
- et
- Korraldatud
- originaal
- Muu
- teised
- väljaspool
- pandas
- Paber
- parameetrid
- osa
- osad
- täitma
- ehk
- inimene
- valima
- Platon
- Platoni andmete intelligentsus
- PlatoData
- pluss
- Punkt
- võrra
- võimalik
- Praktiline
- tava
- ennustada
- eelmine
- varem
- Eelnev
- tõenäoliselt
- protsess
- Toodetud
- profiil
- projekt
- projektid
- paljutõotav
- kinnisvara
- avaldamine
- ostma
- Python
- juhuslik
- valik
- määr
- valmis
- hiljuti
- soovitama
- Red
- nimetatud
- kõrvaldama
- kordama
- esindab
- Vajab
- teadustöö
- Teadlased
- meenutab
- kaasa
- Tulemused
- ring
- ümber
- Eeskiri
- eeskirjade
- jooks
- s
- sama
- Skaala
- ketendamine
- kava
- skikit õppima
- meres sündinud
- Teine
- Osa
- nägemine
- tundus
- tundub
- väljavalitud
- valides
- valik
- tunne
- tundlik
- vari
- kuju
- kuju
- peaks
- sarnane
- lihtsalt
- alates
- olukordades
- väike
- väiksem
- väikseim
- So
- lahendus
- mõned
- Varsti
- Ruum
- ruumiline
- konkreetse
- eriti
- kulutama
- Kulutused
- Poolitab
- Stackabus
- standard
- standardite
- algus
- Ühendriigid
- Samm
- Sammud
- Peatus
- Peatab
- salvestada
- otse
- tänav
- tugev
- struktuur
- õpilane
- Õpilased
- selline
- ümbritsetud
- SVG
- sümbol
- Võtma
- võtab
- tingimused
- test
- et
- .
- Graafik
- oma
- Neile
- seetõttu
- Need
- Kolmas
- kolm
- Läbi
- aeg
- korda
- et
- kokku
- Summa
- koolitatud
- Tehingud
- Muutma
- üleminek
- tõsi
- liigid
- mõistma
- mõistmine
- arusaadav
- ainulaadne
- us
- Kasutus
- kasutama
- tavaliselt
- väärtus
- Väärtused
- muutujad
- Ve
- kontrollimine
- visualiseeri
- kuidas
- Hästi
- M
- mis
- WHO
- will
- koos
- jooksul
- sõnad
- Töö
- töö
- töötab
- oleks
- kirjutama
- kirjalik
- aastat
- sephyrnet