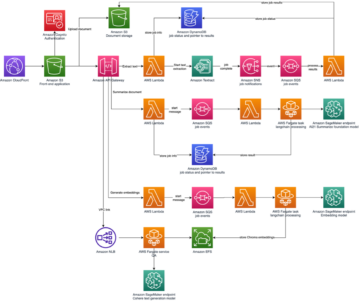
Novembris 2022, meie teatas millega AWS-i kliendid saavad tekstist pilte luua Stabiilne difusioon mudelid sisse Amazon SageMaker JumpStart. Stable Diffusion on süvaõppemudel, mis võimaldab luua realistlikke, kvaliteetseid pilte ja vapustavat kunsti vaid mõne sekundiga. Kuigi muljetavaldavate piltide loomine leiab kasutust erinevates tööstusharudes, alates kunstist kuni NFT-ni ja mujalgi, eeldame tänapäeval ka AI isikupärastamist. Täna anname teada, et saate pildi genereerimise mudelit isikupärastada vastavalt oma kasutusjuhtudele, viimistledes seda oma kohandatud andmekogumis Amazon SageMaker JumpStart. See võib olla kasulik kunsti, logode, kohandatud kujunduste, NFT-de jms loomisel või lõbusate asjade (nt lemmikloomadest kohandatud AI-piltide või enda avatarite) loomisel.
Selles postituses anname ülevaate sellest, kuidas stabiilse difusiooni mudelit kahel viisil peenhäälestada: programmiliselt läbi KiirStardi API-d saadaval SageMaker Python SDKja JumpStarti kasutajaliides (UI) sisse Amazon SageMaker Studio. Samuti arutame, kuidas teha disainivalikuid, sealhulgas andmestiku kvaliteeti, koolitusandmestiku suurust, hüperparameetrite väärtuste valikut ja rakendatavust mitme andmestiku jaoks. Lõpetuseks käsitleme enam kui 80 avalikult kättesaadavat erinevate sisestuskeelte ja stiilidega peenhäälestatud mudelit, mis on hiljuti JumpStartis lisatud.
Stabiilne difusiooni- ja ülekandeõpe
Stabiilne hajutamine on tekst-pildiks mudel, mis võimaldab teil luua fotorealistlikke pilte pelgalt tekstiviipast. Difusioonimudel treenib, õppides eemaldama pärispildile lisatud müra. See müra eemaldamise protsess loob realistliku pildi. Need mudelid võivad genereerida ka ainult tekstist pilte, määrates genereerimisprotsessi tekstile. Näiteks stabiilne difusioon on varjatud difusioon, mille käigus mudel õpib puhtal mürapildil kujundeid ära tundma ja toob need kujundid järk-järgult fookusesse, kui kujundid vastavad sisendteksti sõnadele. Tekst tuleb esmalt keelemudeli abil varjatud ruumi põimida. Seejärel tehakse U-Neti arhitektuuriga varjatud ruumis müra lisamise ja eemaldamise toiminguid. Lõpuks dekodeeritakse müravaba väljund piksliruumi.
Masinõppes (ML) nimetatakse oskust ühest valdkonnast õpitud teadmisi teisele üle kanda ülekandmisõpe. Saate kasutada ülekandeõpet, et luua oma väiksematele andmekogumitele täpseid mudeleid, mille koolituskulud on palju väiksemad kui algse mudeli väljaõppega seotud omad. Ülekandeõppe abil saate oma andmestiku stabiilset difusioonimudelit viimistleda vaid viie pildiga. Näiteks vasakul on Doppleri-nimelise koera treeningpildid, mida kasutatakse mudeli peenhäälestamiseks, keskel ja paremal on peenhäälestatud mudeli poolt genereeritud pildid, kui palutakse ennustada Doppleri kujutist rannas ja pliiatsivisand.

Vasakul on kujutised valgest toolist, mida kasutatakse mudeli peenhäälestamiseks, ja tooli kujutis punase värviga, mille on genereerinud peenhäälestatud mudel. Paremal on kujutised otomanist, mida kasutatakse mudeli peenhäälestamiseks, ja pilt otomanil istuvast kassist.

Suurte mudelite (nt Stable Diffusion) peenhäälestamiseks peate tavaliselt esitama koolitusskripte. Probleeme on palju, sealhulgas mälu lõppemise, kasuliku koormuse suuruse ja palju muud. Lisaks peate läbima täielikud testid, et veenduda skripti, mudeli ja soovitud eksemplari tõhusas koostöös. JumpStart lihtsustab seda protsessi, pakkudes kasutusvalmis skripte, mida on tugevalt testitud. Stabiilse difusiooni mudelite JumpStart peenhäälestusskript põhineb peenhäälestusskriptil unistuste putka. Nendele skriptidele pääsete juurde ühe klõpsuga Studio kasutajaliidese kaudu või väga väheste koodiridade abil KiirStardi API-d.
Pange tähele, et kasutades stabiilse difusiooni mudelit, nõustute CreativeML Open RAIL++-M litsents.
Kasutage KiirStarti programmiliselt koos SageMaker SDK-ga
Selles jaotises kirjeldatakse, kuidas mudelit rakendusega koolitada ja juurutada SageMaker Python SDK. Valime JumpStartis sobiva eelkoolitatud mudeli, koolitame selle mudeli välja SageMakeri koolitustööga ja juurutame koolitatud mudeli SageMakeri lõpp-punkti. Lisaks teeme juurutatud lõpp-punkti kohta järeldusi, kasutades SageMaker Python SDK-d. Järgmised näited sisaldavad koodilõike. Täieliku koodi koos kõigi selle demo etappidega leiate aadressilt KiirStardi sissejuhatus – tekst pildiks näidismärkmik.
Treenige ja viimistlege stabiilse difusiooni mudelit
Iga mudelit identifitseerib kordumatu model_id. Järgmine kood näitab, kuidas peenhäälestada Stable Diffusion 2.1 baasmudelit, mille tuvastas model_id model-txt2img-stabilityai-stable-diffusion-v2-1-base kohandatud treeninguandmestikul. Täieliku loendi jaoks model_id väärtusi ja millised mudelid on peenhäälestatud, vaadake Sisseehitatud algoritmid koos eelkoolitatud mudelitabeliga. Igaühele model_id, et käivitada SageMakeri koolitustöö läbi Hindaja klassi SageMaker Python SDK, peate SageMakeris pakutavate utiliitide kaudu hankima Dockeri pildi URI, koolitusskripti URI ja eelkoolitatud mudeli URI. Treeningskripti URI sisaldab kogu vajalikku koodi andmetöötluseks, eelkoolitatud mudeli laadimiseks, mudeli väljaõppeks ja treenitud mudeli järelduste tegemiseks salvestamiseks. Eelkoolitatud mudeli URI sisaldab eelkoolitatud mudeli arhitektuuri määratlust ja mudeli parameetreid. Eelkoolitatud mudeli URI on konkreetse mudeli jaoks spetsiifiline. Eelkoolitatud mudeli tarballid on Hugging Face'ist eelnevalt alla laaditud ja salvestatud koos vastava mudeli allkirjaga Amazoni lihtne salvestusteenus (Amazon S3) ämbrid, et koolitustöö toimuks võrgust eraldatult. Vaadake järgmist koodi:
Nende mudelispetsiifiliste koolitusartefaktide abil saate konstrueerida objekti Hindaja klass:
Koolituse andmestik
Järgmised juhised treeningandmete vormindamiseks:
- Sisend - kataloog, mis sisaldab eksemplari pilte,
dataset_info.json, järgmise konfiguratsiooniga:- Pildid võivad olla .png-, .jpg- või .jpeg-vormingus
- .
dataset_info.jsonfail peab olema vormingus{'instance_prompt':<<instance_prompt>>}
- Väljund – Koolitatud mudel, mida saab järelduste tegemiseks kasutada
S3 tee peaks välja nägema s3://bucket_name/input_directory/. Pange tähele lõppu / on nõutud.
Järgmine on treeningandmete vormingu näide:
Juhised andmete vormindamise kohta eelneva säilitamise ajal leiate jaotisest Eelnev Säilitamine selles postituses.
Pakume kassipiltide vaikeandmestiku. See koosneb kaheksast pildist (eksemplaripildid, mis vastavad eksemplari viipale) ühest kassist, millel puuduvad klassipildid. Seda saab alla laadida aadressilt GitHub. Kui kasutate vaikeandmestikku, proovige demomärkmikus järeldusi tehes käsku „foto riobuggeri kassist”.
litsents: MIT.
Hüperparameetrid
Järgmiseks peate võib-olla kohandatud andmekogumis õppimise ülekandmiseks muutma treeningu hüperparameetrite vaikeväärtusi. Nende hüperparameetrite Pythoni sõnastiku koos vaikeväärtustega saate hankida helistades hyperparameters.retrieve_default, värskendage neid vastavalt vajadusele ja edastage need seejärel klassile Hindaja. Vaadake järgmist koodi:
Peenhäälestusalgoritm toetab järgmisi hüperparameetreid:
- eelneva_säilitamisega – Eelneva säilituskao lisamiseks märgistage. Eelnev säilitamine on regulaator, mis väldib ülepaigutamist. (Valikud:
[“True”,“False”], vaikimisi:“False”.) - klassi_piltide arv – Minimaalne pildiklass eelneva säilituskao jaoks. Kui
with_prior_preservation = Trueja seal pole juba piisavalt pilteclass_data_dir, proovitakse täiendavaid pilteclass_prompt. (Väärtused: positiivne täisarv, vaikimisi: 100.) - Epohhid – Läbimiste arv, mille peenhäälestusalgoritm läbib treeningu andmestiku. (Väärtused: positiivne täisarv, vaikimisi: 20.)
- Max_sammud – sooritatavate treeningetappide koguarv. Kui ei
None, alistab epohhid. (Väärtused:“None”või täisarvu string, vaikimisi:“None”.) - Partii suurus –: enne mudeli kaalude värskendamist läbi töötatud treeningnäidete arv. Sama mis partii suurus klassi piltide genereerimise ajal, kui
with_prior_preservation = True. (Väärtused: positiivne täisarv, vaikimisi: 1.) - õppimise_määr – Mudeli kaalude värskendamise kiirus pärast iga treeningnäidete partii läbitöötamist. (Väärtused: positiivne ujuv, vaikeväärtus: 2e-06.)
- eelnev_kaotus_kaal – eelneva säilituskao kaal. (Väärtused: positiivne ujuv, vaikeväärtus: 1.0.)
- center_crop – Kas kärpida pilte enne suuruse muutmist soovitud eraldusvõimeni. (Valikud:
[“True”/“False”], vaikimisi:“False”.) - lr_planeerija – õppimiskiiruse ajakava tüüp. (Valikud:
["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"], vaikimisi:"constant".) Lisateavet vt Õppimiskiiruse plaanijad. - Adam_weight_cay – Kaalu vähenemine (kui mitte null), mida rakendatakse kõikidele kihtidele, välja arvatud kõik nihked ja
LayerNormraskused sisseAdamWoptimeerija. (Väärtus: ujuv, vaikimisi: 1e-2.) - adam_beta1 – beeta1 hüperparameeter (eksponentsiaalne sumbumiskiirus esimese hetke hinnangute jaoks) jaoks
AdamWoptimeerija. (Väärtus: ujuv, vaikeväärtus: 0.9.) - adam_beta2 – beeta2 hüperparameeter (eksponentsiaalne sumbumiskiirus esimese hetke hinnangute jaoks) jaoks
AdamWoptimeerija. (Väärtus: ujuv, vaikeväärtus: 0.999.) - adam_epsilon -
epsilonhüperparameeter jaoksAdamWoptimeerija. Tavaliselt seatakse see väikesele väärtusele, et vältida 0-ga jagamist. (Väärtus: float, vaikimisi: 1e-8.) - gradient_akumulatsiooni_sammud – Värskendustoimingute arv, mis tuleb koguda enne tagasikäigu/värskenduskäigu sooritamist. (Väärtus: täisarv, vaikimisi: 1.)
- max_grad_norm – Maksimaalne gradiendi norm (kaldelõikuse jaoks). (Väärtus: ujuv, vaikeväärtus: 1.0.)
- seeme – Fikseerige juhuslik olek, et saavutada treeningul reprodutseeritavad tulemused. (Väärtus: täisarv, vaikimisi: 0.)
Kasutage hästi väljaõppinud mudelit
Kui mudeli koolitus on lõppenud, saate mudeli otse püsivasse reaalajas lõpp-punkti juurutada. Toome vajalikud Docker Image URI-d ja skripti URI-d ning juurutame mudeli. Vaadake järgmist koodi:
Vasakul on riobuggeri nimelise kassi treeningpildid, mida kasutatakse mudeli peenhäälestamiseks (vaikeparameetrid v.a. max_steps = 400). Keskel ja paremal on peenhäälestatud mudeli loodud pildid, kui neil palutakse ennustada riobuggeri kujutist rannas ja pliiatsivisand.

Lisateavet järelduste, sealhulgas toetatud parameetrite, vastuse vormingu ja muu kohta leiate aadressilt Looge tekstist pilte Amazon SageMaker JumpStarti stabiilse difusioonimudeli abil.
JumpStartile pääsete juurde Studio kasutajaliidese kaudu
Selles jaotises näitame, kuidas treenida ja juurutada JumpStart mudeleid Studio kasutajaliidese kaudu. Järgmises videos näidatakse, kuidas leida JumpStartis eelkoolitatud Stable Diffusion mudel, seda koolitada ja seejärel kasutusele võtta. Mudelileht sisaldab väärtuslikku teavet mudeli ja selle kasutamise kohta. Pärast SageMakeri koolituseksemplari konfigureerimist valige Rong. Pärast mudeli väljaõpetamist saate koolitatud mudeli valides kasutusele võtta juurutada. Pärast seda, kui lõpp-punkt on teenistuses, on see valmis järeldamistaotlustele vastama.
Järelduste tegemise aja kiirendamiseks pakub JumpStart näidismärkmiku, mis näitab, kuidas vastloodud lõpp-punktis järeldusi teha. Märkmikule Studios juurdepääsuks valige Avage märkmik aasta Kasutage Studio Endpointi mudeli lõpp-punkti lehe jaotist.
JumpStart pakub ka lihtsat sülearvutit, mida saate kasutada stabiilse difusioonimudeli viimistlemiseks ja sellest tuleneva peenhäälestatud mudeli juurutamiseks. Saate seda kasutada oma koerast lõbusate piltide loomiseks. Märkmikule juurdepääsuks otsige KiirStardi otsinguribalt „Looge lõbusaid pilte oma koerast”. Märkmiku käivitamiseks võite kasutada vaid viit treeningpilti ja laadida need üles kohalikku stuudiokausta. Kui teil on rohkem kui viis pilti, saate ka need üles laadida. Sülearvuti laadib treeningkujutised üles S3-sse, koolitab mudeli teie andmekogumis ja juurutab saadud mudeli. Treeningu lõpetamine võib kesta 20 minutit. Treeningu kiirendamiseks saate sammude arvu muuta. Märkmik pakub juurutatud mudeliga proovimiseks mõningaid näidisviipasid, kuid võite proovida mis tahes viipasid, mis teile meeldivad. Samuti saate sülearvutit kohandada, et luua endast või oma lemmikloomadest avatare. Näiteks saate oma koera asemel esimese sammuna üles laadida pilte oma kassist ja seejärel muuta viipad koertelt kassidele ja mudel genereerib teie kassist pilte.
Peenhäälestuskaalutlused
Treening Stable Diffusion mudelid kipuvad kiiresti üle sobima. Kvaliteetsete piltide saamiseks peame leidma hea tasakaalu olemasolevate treeningu hüperparameetrite, näiteks treeningsammude arvu ja õppimiskiiruse vahel. Selles jaotises näitame mõningaid katsetulemusi ja anname juhiseid nende parameetrite määramiseks.
Soovitused
Kaaluge järgmisi soovitusi:
- Alustage treeningpiltide hea kvaliteediga (4–20). Kui treenite inimeste nägudel, võib teil vaja minna rohkem pilte.
- Treenige 200–400 sammu, kui treenite koertel või kassidel ja muudel inimestel, kes ei ole inimesed. Kui treenite inimeste nägudel, võib teil vaja minna rohkem samme. Kui toimub ülepaigutamine, vähendage sammude arvu. Kui toimub alasobitamine (peenhäälestatud mudel ei suuda luua sihtobjekti kujutist), suurendage sammude arvu.
- Kui treenite mitte-inimese nägudel, võite määrata
with_prior_preservation = Falsesest see ei mõjuta oluliselt jõudlust. Inimeste nägudel peate võib-olla seadistamawith_prior_preservation=True. - Kui seade
with_prior_preservation=True, kasutage eksemplari tüüpi ml.g5.2xlarge. - Mitmel järjestikusel teemal treenides, kui katsealused on väga sarnased (näiteks kõik koerad), jätab mudel alles viimase katsealuse ja unustab eelmised. Kui katsealused on erinevad (näiteks esmalt kass, siis koer), jääb mudelisse mõlemad katsealused.
- Soovitame kasutada madalat õppimiskiirust ja järk-järgult suurendada sammude arvu, kuni tulemused on rahuldavad.
Koolituse andmestik
Peenhäälestatud mudeli kvaliteeti mõjutab otseselt treeningpiltide kvaliteet. Seetõttu peate heade tulemuste saamiseks koguma kvaliteetseid pilte. Hägused või madala eraldusvõimega kujutised mõjutavad peenhäälestatud mudeli kvaliteeti. Pidage meeles järgmisi täiendavaid parameetreid:
- Treeningpiltide arv – Saate mudelit peenhäälestada kõigest neljal treeningpildil. Katsetasime nii väikese kui 4- ja kuni 16-kujuliste andmekogumitega. Mõlemal juhul suutis peenhäälestus kohandada mudelit objektiga.
- Andmekogumi vormingud – Testisime peenhäälestusalgoritmi .png-, .jpg- ja .jpeg-vormingus piltidel. Samuti võivad töötada muud vormingud.
- Pildi eraldusvõime – Treeningpildid võivad olla mis tahes eraldusvõimega. Peenhäälestusalgoritm muudab enne peenhäälestuse alustamist kõigi treeningpiltide suurust. Sellegipoolest, kui soovite treeningpiltide kärpimise ja suuruse muutmise üle suuremat kontrolli omada, soovitame piltide suurust ise muuta mudeli põhiresolutsioonile (selles näites 512 × 512 pikslit).
Katse seaded
Selle postituse katses kasutame peenhäälestamisel hüperparameetrite vaikeväärtusi, kui pole täpsustatud. Lisaks kasutame ühte neljast andmekogumist:
- Koer1-8 – Koer 1 8 pildiga
- Koer1-16 – Koer 1 16 pildiga
- Koer2-4 – Koer 2 nelja pildiga
- Kass-8 - 8 pildiga kass
Segaduse vähendamiseks näitame igas jaotises koos andmestiku nimega ainult ühte tüüpilist pilti andmekogumist. Täieliku treeningkomplekti leiate rubriigist Katseandmed selles postituses.
Liigne paigaldamine
Stabiilse hajutusega mudelid kipuvad mõne pildi peenhäälestamisel üle sobima. Seetõttu peate valima sellised parameetrid nagu epochs, max_epochsja õppimiskiirust hoolikalt. Selles jaotises kasutasime andmekogumit Dog1-16.

Mudeli toimivuse hindamiseks hindame peenhäälestatud mudelit nelja ülesande jaoks:
- Kas peenhäälestatud mudel saab luua pilte subjektist (Doppleri koer) samas seades, milles teda treeniti?
- Tähelepanek — Jah saab. Väärib märkimist, et mudeli jõudlus suureneb koos treeningsammude arvuga.
- Kas peenhäälestatud mudel võib luua pildistatavast pildist erinevas keskkonnas, kui seda õpetati? Kas see võib näiteks luua rannas Doppleri pilte?
- Tähelepanek — Jah saab. Väärib märkimist, et mudeli jõudlus suureneb treeningsammude arvuga kuni teatud punktini. Kui mudelit treenitakse liiga kaua, aga mudeli jõudlus halveneb, kuna mudel kipub üle sobima.
- Kas peenhäälestatud mudel suudab luua pilte klassist, kuhu koolitusaine kuulub? Kas see võib näiteks luua üldise koera kuvandi?
- Tähelepanek – Kui suurendame treeningsammude arvu, hakkab mudel üle sobima. Selle tulemusena unustab see koera üldise klassi ja loob ainult teemaga seotud pilte.
- Kas peenhäälestatud mudel saab luua pilte klassist või õppeainest, mis pole koolitusandmekogus? Kas see võib näiteks luua kassi kujutise?
- Tähelepanek – Kui suurendame treeningsammude arvu, hakkab mudel üle sobima. Selle tulemusena toodab see ainult teemaga seotud pilte, olenemata määratud klassist.
Täpsustame mudelit erineva arvu etappide jaoks (seadistades max_steps hüperparameetrid) ja iga peenhäälestatud mudeli jaoks genereerime kujutised kõigil neljal järgmisel viibal (näidatud järgmistes näidetes vasakult paremale):
- "Foto Doppleri koerast"
- "Foto Doppleri koerast rannas"
- "Foto koerast"
- "Foto kassist"
Järgmised pildid on 50 sammuga treenitud mudelilt.

Järgmist mudelit treeniti 100 sammuga.

Järgmist mudelit treenisime 200 sammuga.

Järgmised pildid on 400 sammuga treenitud mudelilt.

Lõpuks on järgmised pildid 800 sammu tulemus.

Treenige mitme andmekogumiga
Peenhäälestamise ajal võite soovida peenhäälestada mitut objekti ja lasta peenhäälestatud mudelil luua pilte kõigist objektidest. Kahjuks piirdub KiirStart praegu ühe teema koolitusega. Mudelit ei saa korraga mitmel teemal peenhäälestada. Veelgi enam, mudeli peenhäälestamine erinevate subjektide jaoks toob kaasa selle, et mudel unustab esimese katsealuse, kui katsealused on sarnased.
Selles jaotises käsitleme järgmisi katseid:
- Täpsustage subjekti A mudelit.
- Peenhäälestage saadud mudel 1. sammust subjekti B jaoks.
- Looge subjekti A ja subjekti B kujutised, kasutades 2. sammu väljundmudelit.
Järgmistes katsetes täheldame, et:
- Kui A on koer 1 ja B on koer 2, sarnanevad kõik sammus 3 loodud pildid koeraga 2
- Kui A on koer 2 ja B on koer 1, sarnanevad kõik sammus 3 loodud pildid koeraga 1
- Kui A on koer 1 ja B on kass, siis koera viipadega genereeritud pildid sarnanevad koeraga 1 ja kassi viipadega genereeritud pildid kassiga
Treeni koeraga 1 ja seejärel koeraga 2
1. toimingus peenhäälestame mudelit 200 sammu võrra kaheksa koera 1 kujutise puhul. 2. toimingus peenhäälestame mudelit edasi 200 sammu võrra neljal koera 2 kujutisel.

Järgmised on 2. toimingu lõpus peenhäälestatud mudeli poolt erinevate viipade jaoks loodud pildid.

Treeni koeraga 2 ja seejärel koeraga 1
1. sammus peenhäälestame mudelit 200 sammu võrra neljal koera 2 kujutisel. 2. toimingus peenhäälestame mudelit edasi 200 sammu võrra kaheksal koera 1 kujutisel.

Järgmised on 2. toimingu lõpus peenhäälestatud mudeli loodud pildid erinevate viipadega.

Treeni koerte ja kasside peal
1. sammus viimistleme mudelit 200 sammu võrra kaheksal kassi kujutisel. Seejärel viimistleme mudelit edasi 200 sammu võrra kaheksal koera 1 kujutisel.

Järgmised on 2. toimingu lõpus peenhäälestatud mudeli loodud pildid. Kassiga seotud viipadega pildid näevad välja nagu peenhäälestuse 1. etapis olevad kassid ja koeraga seotud viipadega pildid näevad välja nagu koer Peenhäälestuse 2. etapp.

Eelnev konserveerimine
Eelnev säilitamine on tehnika, mis kasutab sama klassi lisapilte, mida proovime treenida. Näiteks kui koolitusandmed koosnevad konkreetse koera kujutistest, mis on eelnevalt säilitatud, lisame tavaliste koerte klassipildid. See püüab vältida liigsobimist, näidates konkreetse koera treenimise ajal erinevate koerte pilte. Klassiviibal puudub märgend, mis näitab eksemplari viipas konkreetset koera. Näiteks võib eksemplari viip olla "foto kassist kassist" ja klassiviip võib olla "foto kassist". Saate lubada eelneva säilitamise, määrates hüperparameetri with_prior_preservation = True. Kui seade with_prior_preservation = True, peate lisama class_prompt in dataset_info.json ja võib sisaldada teile saadaolevaid klassipilte. Järgmine on treeningu andmestiku vorming seadistamisel with_prior_preservation = True:
- Sisend - kataloog, mis sisaldab eksemplari pilte,
dataset_info.jsonja (valikuline) kataloogclass_data_dir. Pange tähele järgmist.- Pildid võivad olla .png-, .jpg-, .jpeg-vormingus.
- .
dataset_info.jsonfail peab olema vormingus{'instance_prompt':<<instance_prompt>>,'class_prompt':<<class_prompt>>}. - .
class_data_dirkataloogis peavad olema klassipildid. Kuiclass_data_direi ole olemas või pole juba piisavalt pilteclass_data_dir, proovitakse täiendavaid pilteclass_prompt.
Andmekogumite (nt kassid ja koerad) puhul ei mõjuta eelnev säilitamine oluliselt peenhäälestatud mudeli toimivust ja seetõttu saab seda vältida. Nägu treenides on see aga vajalik. Lisateabe saamiseks vaadake Stabiilse difusiooni treenimine Dreamboothiga difuusorite abil.
Eksemplaride tüübid
Stabiilse difusiooni mudelite peenhäälestus nõuavad kiirendatud arvutusi, mida pakuvad GPU-toega eksemplarid. Katsetame oma peenhäälestamist eksemplaridega ml.g4dn.2xlarge (16 GB CUDA mälu, 1 GPU) ja ml.g5.2xlarge (24 GB CUDA mälu, 1 GPU). Mälunõue on klassipiltide genereerimisel suurem. Seega, kui seade with_prior_preservation=True, kasutage eksemplari tüüpi ml.g5.2xlarge, sest koolituse puhul ilmneb eksemplari ml.g4dn.2xlarge CUDA mälu otsa probleem. JumpStarti peenhäälestusskript kasutab praegu ühte GPU-d ja seetõttu ei too mitme GPU eksemplari peenhäälestus jõudluse kasvu. Erinevate eksemplaritüüpide kohta lisateabe saamiseks vaadake Amazon EC2 eksemplaritüübid.
Piirangud ja eelarvamus
Kuigi Stable Diffusionil on piltide loomisel muljetavaldav jõudlus, on sellel mitmeid piiranguid ja eelarvamusi. Nende hulka kuuluvad, kuid mitte ainult:
- Mudel ei pruugi luua täpseid nägusid või jäsemeid, kuna treeninguandmed ei sisalda nende funktsioonidega piisavalt pilte
- Modell on koolitatud LAION-5B andmestik, millel on täiskasvanutele mõeldud sisu ja mis ei pruugi ilma täiendavate kaalutlusteta sobida toote kasutamiseks
- Mudel ei pruugi hästi töötada muude kui inglise keeltega, kuna mudelit õpetati ingliskeelse tekstiga
- Mudel ei saa piltides head teksti luua
Lisateavet piirangute ja eelarvamuste kohta vt Stabiilse difusiooni v2-1-aluse mudelikaart. Need eelkoolitatud mudeli piirangud võivad üle kanda ka peenhäälestatud mudelitele.
Koristage
Kui olete märkmiku käitamise lõpetanud, kustutage kindlasti kõik protsessi käigus loodud ressursid, et tagada arveldamise peatamine. Kood lõpp-punkti puhastamiseks on esitatud seotud jaotises KiirStardi sissejuhatus – tekst pildiks näidismärkmik.
JumpStartis avalikult saadaval peenhäälestatud mudelid
Isegi kui Stable Diffusion mudelid on välja antud StabiilsusAI neil on muljetavaldav jõudlus, neil on piirangud keele või domeeni osas, milles seda koolitati. Näiteks Stabiilse hajutuse mudeleid õpetati ingliskeelse tekstiga, kuid teil võib tekkida vajadus luua pilte mitteingliskeelsest tekstist. Alternatiivina õpetati stabiilse difusiooni mudeleid fotorealistlike piltide genereerimiseks, kuid teil võib tekkida vajadus luua animeeritud või kunstilisi pilte.
JumpStart pakub üle 80 avalikult kättesaadava mudeli, millel on erinevad keeled ja teemad. Need mudelid on sageli Stable Diffusioni mudelite peenhäälestatud versioonid, mille on välja andnud StabilityAI. Kui teie kasutusjuhtum ühtib mõne peenhäälestatud mudeliga, ei pea te oma andmestikku koguma ja seda täpsustama. Saate ühe neist mudelitest lihtsalt juurutada Studio kasutajaliidese kaudu või lihtsalt kasutatavate JumpStart API-de abil. Eelkoolitatud stabiilse difusiooni mudeli juurutamiseks KiirStartis vt Looge tekstist pilte Amazon SageMaker JumpStarti stabiilse difusioonimudeli abil.
Järgnevalt on toodud mõned näited piltidest, mis on loodud erinevate JumpStartis saadaolevate mudelite abil.


Pange tähele, et neid mudeleid ei peenhäälestata JumpStart skriptide või DreamBoothi skriptidega. Avalikult saadaolevate peenhäälestatud mudelite täieliku loendi koos näidisviipadega saate alla laadida aadressilt siin.
Nendest mudelitest loodud piltide näiteid leiate jaotisest Avatud lähtekoodiga peenhäälestatud mudelid lisas.
Järeldus
Selles postituses näitasime, kuidas Stable Diffusion mudelit teksti-pildiks kohandada ja seejärel JumpStarti abil juurutada. Lisaks arutasime mõningaid kaalutlusi, mida peaksite mudeli peenhäälestamisel arvesse võtma ja kuidas see võib mõjutada peenhäälestatud mudeli jõudlust. Arutasime ka enam kui 80 kasutusvalmis peenhäälestatud mudelit, mis on saadaval JumpStartis. Näitasime selles postituses koodilõike – täielikku koodi koos kõigi selle demo etappidega vaadake jaotisest KiirStardi sissejuhatus – tekst pildiks näidismärkmik. Proovige lahendust ise ja saatke meile oma kommentaarid.
Mudeli ja DreamBoothi peenhäälestuse kohta lisateabe saamiseks vaadake järgmisi ressursse:
JumpStarti kohta lisateabe saamiseks vaadake järgmisi ajaveebi postitusi:
Autoritest
 Dr Vivek Madan on Amazon SageMaker JumpStart meeskonna rakendusteadlane. Ta sai doktorikraadi Illinoisi ülikoolist Urbana-Champaignis ja oli Georgia Techi järeldoktor. Ta on aktiivne masinõppe ja algoritmide kujundamise uurija ning avaldanud ettekandeid EMNLP, ICLR, COLT, FOCS ja SODA konverentsidel.
Dr Vivek Madan on Amazon SageMaker JumpStart meeskonna rakendusteadlane. Ta sai doktorikraadi Illinoisi ülikoolist Urbana-Champaignis ja oli Georgia Techi järeldoktor. Ta on aktiivne masinõppe ja algoritmide kujundamise uurija ning avaldanud ettekandeid EMNLP, ICLR, COLT, FOCS ja SODA konverentsidel.
 Heiko Hotz on tehisintellekti ja masinõppe lahenduste vanemarhitekt, kes keskendub spetsiaalselt loomuliku keele töötlemisele (NLP), suurtele keelemudelitele (LLM) ja generatiivsele AI-le. Enne seda rolli oli ta Amazoni EL-i klienditeeninduse andmeteaduse juht. Heiko aitab meie klientidel olla edukas AI/ML teekonnal AWS-is ning on töötanud organisatsioonidega paljudes tööstusharudes, sealhulgas kindlustus, finantsteenused, meedia ja meelelahutus, tervishoid, kommunaalteenused ja tootmine. Vabal ajal reisib Heiko nii palju kui võimalik.
Heiko Hotz on tehisintellekti ja masinõppe lahenduste vanemarhitekt, kes keskendub spetsiaalselt loomuliku keele töötlemisele (NLP), suurtele keelemudelitele (LLM) ja generatiivsele AI-le. Enne seda rolli oli ta Amazoni EL-i klienditeeninduse andmeteaduse juht. Heiko aitab meie klientidel olla edukas AI/ML teekonnal AWS-is ning on töötanud organisatsioonidega paljudes tööstusharudes, sealhulgas kindlustus, finantsteenused, meedia ja meelelahutus, tervishoid, kommunaalteenused ja tootmine. Vabal ajal reisib Heiko nii palju kui võimalik.
Lisa: Katse andmekogumid
See jaotis sisaldab selle postituse katsetes kasutatud andmekogumeid.
Koer1-8

Koer1-16

Koer2-4

Koer3-8

Lisa: avatud lähtekoodiga peenhäälestatud mudelid
Järgnevalt on toodud mõned näited piltidest, mis on loodud erinevate JumpStartis saadaolevate mudelite abil. Igal pildil on pealkiri a model_id alustades eesliitega huggingface-txt2img- millele järgneb järgmisel real pildi genereerimiseks kasutatav viip.

























- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- Platoblockchain. Web3 metaversiooni intelligentsus. Täiustatud teadmised. Juurdepääs siia.
- Allikas: https://aws.amazon.com/blogs/machine-learning/fine-tune-text-to-image-stable-diffusion-models-with-amazon-sagemaker-jumpstart/
- 1
- 100
- 11
- 2022
- 9
- a
- võime
- Võimalik
- MEIST
- kiirendama
- kiirendatud
- juurdepääs
- Kogunema
- täpne
- Saavutada
- aktiivne
- kohandama
- lisatud
- lisamine
- Täiendavad lisad
- Täiskasvanud
- pärast
- AI
- Tehisintellekt ja masinõpe
- AI / ML
- algoritm
- algoritme
- Materjal: BPA ja flataatide vaba plastik
- võimaldab
- üksi
- juba
- Kuigi
- Amazon
- Amazon SageMaker
- Amazon SageMaker JumpStart
- ja
- Teatama
- Teine
- API-liidesed
- rakendatud
- kehtima
- asjakohane
- arhitektuur
- kunst
- kunstiline
- seotud
- automaatselt
- saadaval
- Avatarid
- vältima
- vältida
- AWS
- Saldo
- baar
- baas
- rand
- sest
- enne
- on
- vahel
- Peale
- erapoolikus
- arvete
- Blogi
- Blogi postitused
- Toob
- Ehitab
- kutsutud
- kutsudes
- hoolikalt
- viima
- juhul
- juhtudel
- CAT
- Kassid
- kindel
- Tool
- muutma
- kontrollima
- valik
- valikuid
- Vali
- valimine
- klass
- segadus
- kood
- koguma
- kommentaarid
- arvutamine
- konverentsid
- konfiguratsioon
- Arvestama
- kaalutlused
- pidev
- ehitama
- Konteiner
- sisaldab
- sisu
- kontrollida
- Vastav
- kulud
- looma
- loodud
- loomine
- põllukultuur
- Praegu
- tava
- klient
- Kasutajatugi
- Kliendid
- andmed
- andmetöötlus
- andmeteadus
- andmekogumid
- sügav
- sügav õpe
- vaikimisi
- Demo
- näitama
- juurutada
- lähetatud
- Disain
- disainilahendused
- detailid
- erinev
- Diffusion
- otse
- arutama
- arutatud
- jaotus
- laevalaadija
- Dockeri konteiner
- Ei tee
- koer
- Koerad
- teeme
- domeen
- Ära
- lae alla
- ajal
- iga
- lihtne-to-use
- tõhus
- varjatud
- võimaldama
- võimaldab
- Lõpuks-lõpuni
- Lõpp-punkt
- Inglise
- piisavalt
- tagama
- meelelahutus
- kanne
- ajajärgud
- hinnangul
- jms
- Eeter (ETH)
- EU
- hindama
- näide
- näited
- Välja arvatud
- täitma
- ootama
- eksperiment
- eksponentsiaalne
- nägu
- nägu
- vähe
- fail
- Faile
- Lõpuks
- finants-
- finantsteenused
- leidma
- lõpetama
- esimene
- sobima
- Määrama
- Float
- Keskenduma
- Järgneb
- Järel
- formaat
- Alates
- täis
- lõbu
- funktsioonid
- edasi
- Pealegi
- kasu
- tekitama
- loodud
- genereerib
- teeniva
- põlvkond
- generatiivne
- Generatiivne AI
- Georgia
- saama
- GitHub
- hea
- GPU
- järk-järgult
- Käsitsemine
- juhtub
- juhataja
- tervishoid
- aitab
- kvaliteetne
- rohkem
- võõrustaja
- Kuidas
- Kuidas
- aga
- HTML
- HTTPS
- inim-
- ICLR
- tuvastatud
- Illinois
- pilt
- pildi genereerimine
- pildid
- mõju
- mõjutatud
- import
- muljetavaldav
- in
- sisaldama
- hõlmab
- Kaasa arvatud
- lisada
- Suurendama
- Tõstab
- kasvav
- tööstusharudes
- info
- sisend
- Näiteks
- selle asemel
- juhised
- kindlustus
- Interface
- seotud
- isolatsioon
- probleem
- küsimustes
- IT
- töö
- teekond
- Json
- hoidma
- teadmised
- keel
- Keeled
- suur
- viimane
- algatama
- kihid
- Õppida
- õppinud
- õppimine
- piirangud
- piiratud
- joon
- liinid
- nimekiri
- vähe
- laadimine
- kohalik
- Pikk
- Vaata
- näeb välja
- kaotus
- Madal
- masin
- masinõpe
- tegema
- viis
- käsitsi
- tootmine
- palju
- Vastama
- maksimaalne
- Meedia
- Mälu
- Kesk-
- võib
- meeles
- miinimum
- puuduvad
- ML
- mudel
- mudelid
- hetk
- rohkem
- mitmekordne
- nimi
- Nimega
- Natural
- Loomulik keel
- Natural Language Processing
- vajalik
- Vajadus
- vaja
- võrk
- järgmine
- NFT-d
- nlp
- müra
- märkmik
- November
- number
- objekt
- jälgima
- ONE
- avatud
- Operations
- et
- organisatsioonid
- originaal
- Muu
- ülevaade
- enda
- dokumendid
- parameetrid
- eriline
- möödub
- Mööduv
- tee
- täitma
- jõudlus
- esitades
- personaliseerida
- Majapidamine
- Fotorealistlik
- piksel
- Platon
- Platoni andmete intelligentsus
- PlatoData
- palun
- Punkt
- positiivne
- võimalik
- post
- Postitusi
- ennustada
- esitada
- eelmine
- Eelnev
- protsess
- töötlemine
- tootma
- Toode
- järk-järgult
- anda
- tingimusel
- annab
- pakkudes
- avalikult
- avaldatud
- Python
- kvaliteet
- kiiresti
- juhuslik
- alates
- määr
- valmis
- reaalne
- reaalajas
- realistlik
- hiljuti
- tunnistama
- soovitama
- soovitused
- Red
- vähendama
- Sõltumata sellest
- seotud
- vabastatud
- eemaldamine
- kõrvaldama
- esindaja
- Taotlusi
- nõudma
- nõutav
- nõue
- Vajab
- uurija
- resolutsioon
- Vahendid
- Reageerida
- vastus
- kaasa
- tulemuseks
- Tulemused
- Roll
- jooks
- jooksmine
- salveitegija
- Ütlesin
- sama
- säästmine
- teadus
- teadlane
- skripte
- SDK
- Otsing
- sekundit
- Osa
- vanem
- Seeria
- teenus
- Teenused
- komplekt
- kehtestamine
- mitu
- kuju
- peaks
- näitama
- näidatud
- Näitused
- märgatavalt
- sarnane
- lihtne
- lihtsalt
- ühekordne
- Istung
- SUURUS
- väike
- väiksem
- So
- lahendus
- Lahendused
- mõned
- Ruum
- eriline
- konkreetse
- määratletud
- kiirus
- stabiilne
- Stage
- Käivitus
- algab
- riik
- Samm
- Sammud
- peatatud
- ladustamine
- stuudio
- teema
- edukas
- selline
- Kannatab
- piisav
- toetama
- Toetatud
- Toetab
- TAG
- Võtma
- võtab
- sihtmärk
- ülesanded
- meeskond
- tech
- tingimused
- testid
- .
- oma
- seetõttu
- Läbi
- aeg
- et
- täna
- kokku
- liiga
- Summa
- Rong
- koolitatud
- koolitus
- rongid
- üle
- reisib
- liigid
- ui
- ainulaadne
- Ülikool
- Värskendused
- ajakohastatud
- Uudised
- URI
- us
- kasutama
- kasutage juhtumit
- Kasutaja
- Kasutajaliides
- tavaliselt
- kommunaalteenused
- kasulikkus
- kasutab ära
- väärtuslik
- Väärtuslik teave
- väärtus
- Väärtused
- eri
- Video
- kuidas
- kaal
- kas
- mis
- kuigi
- valge
- will
- jooksul
- ilma
- sõnad
- Töö
- koos töötama
- töötas
- töö
- väärt
- saak
- Sinu
- ise
- sephyrnet
- null