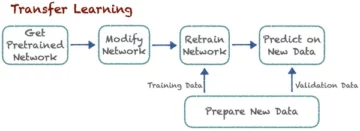
Sellest artiklist õpime, kuidas me saame käsitleda mitme kategooria muutujaid, kasutades funktsioonide projekteerimise tehnikat One Hot Encoding.
Kuid enne jätkamist arutleme lühidalt funktsioonide projekteerimise ja ühe kuuma kodeeringu üle.
Funktsioonitehnika
Seega on funktsioonide projekteerimine protsess, mille käigus eraldatakse toorandmetest funktsioonid, kasutades probleemi domeeniteadmisi. Neid funktsioone saab kasutada masinõppe algoritmide jõudluse parandamiseks ja kui jõudlus suureneb, annab see parima täpsuse. Võime ka öelda, et funktsioonide insener on sama mis rakenduslik masinõpe. Funktsioonide projekteerimine on masinõppe kõige olulisem kunst, mis loob suure erinevuse hea ja halva mudeli vahel. See on kolmas samm mis tahes andmeteaduse projekti elutsüklis.
Masinõppemudelite läbipaistvuse kontseptsioon on keeruline asi, kuna erinevad mudelid nõuavad sageli erinevat tüüpi andmete jaoks erinevat lähenemist. Nagu näiteks:-
- Pidevad andmed
- Kategoorilised omadused
- Puuduvad väärtused
- Normaliseerimine
- Kuupäevad ja kellaaeg
Kuid siin käsitleme ainult kategoorilisi tunnuseid. Kategoorilised tunnused on need funktsioonid, mille andmetüüp on objektitüüp. Andmepunkti väärtus üheski kategoorilises tunnuses ei ole numbrilisel kujul, pigem oli see objekti kujul.
Kategooriliste muutujate käsitlemiseks on palju tehnikaid, mõned neist on järgmised:
- Sildi kodeering või järjekorrakodeering
- Üks kuum kodeering
- Näiv kodeering
- Efektide kodeerimine
- Binaarne kodeerimine
- Baseli kodeering
- Räsikodeering
- Sihtkodeering
Niisiis käsitleme siin One Hot Encodingu kategoorilisi funktsioone, seega käsitleme kõigepealt One Hot Encodingut.
Üks kuum kodeering
Teame, et kategoorilised muutujad sisaldavad pigem sildi väärtusi kui arvväärtusi. Võimalike väärtuste arv on sageli piiratud kindla hulgaga. Kategoorilisi muutujaid nimetatakse sageli nominaalseteks. Paljud masinõppe algoritmid ei saa sildiandmetega otse töötada. Need nõuavad, et kõik sisend- ja väljundmuutujad oleksid numbrilised.
See tähendab, et kategoorilised andmed tuleb teisendada arvkujule. Kui kategooriline muutuja on väljundmuutuja, võite soovida ka mudeli prognoosid uuesti kategooriliseks vormiks teisendada, et neid esitada või mõnes rakenduses kasutada.
näiteks andmed soo kohta on kujul "mees" ja 'naine'.
Kui aga kasutame ühekordset kodeeringut, võib kodeerimine ja mudelil loomuliku kategooriatevahelise järjestuse lubamine põhjustada kehva jõudluse või ootamatuid tulemusi.
Täisarvude esitusviisile saab rakendada ühekordset kodeeringut. See on koht, kus täisarvuga kodeeritud muutuja eemaldatakse ja iga kordumatu täisarvu väärtuse jaoks lisatakse uus binaarne muutuja.
Näiteks kodeerime värvimuutujaid,
| Punane värv | Sinine_värv |
| 0 | 1 |
| 1 | 0 |
| 0 | 1 |
Nüüd alustame oma teekonda. Esimeses etapis koostame majahinna prognoosimise andmestiku.
Andmebaas
Siin kasutame andmestikku house_price, mida kasutatakse majahinna ennustamiseks vastavalt pindala suurusele.
Kui soovite alla laadida majahinna prognooside andmestiku, klõpsake nuppu siin.
Moodulite importimine
Nüüd peame pythonist importima olulised moodulid, mida kasutatakse ühekuuma kodeeringu jaoks
# pandade importimine pd-vormingus pandade importimine # numpy import numpy np-na # OneHotEncoderi importimine sklearn.preprocessing import OneHotEncoder()
Siin kasutame pandasid, mida kasutatakse andmeanalüüsiks, NumPyused n-mõõtmeliste massiivide jaoks ja sklearnist kasutame kategooriliseks kodeerimiseks ühte olulist klassi One Hot Encoderit.
Nüüd peame neid andmeid Pythoni abil lugema.
Andmestiku lugemine
Üldiselt on andmestik CSV-vormingus ja meie kasutatav andmestik on samuti CSV-vormingus. CSV-faili lugemiseks kasutame funktsiooni pandas read_csv(). vaata allpool:
# andmestiku lugemine df = pd.read_csv('house_price.csv') df.head()
väljund: -

Kuid me peame kasutama ainult ühe kuuma kodeerija jaoks kategoorilisi muutujaid ja lihtsamaks mõistmiseks proovime seletada ainult kategooriliste muutujatega.
Kategooriliste muutujate andmetest jaotamiseks peame kontrollima, kui paljudel funktsioonidel on kategoorilised väärtused.
Kategooriliste väärtuste kontrollimine
Väärtuste kontrollimiseks kasutame funktsiooni pandas select_dtypes, mida kasutatakse muutuja andmetüüpide valimiseks.
# funktsioonide kontrollimine cat = df.select_dtypes(include='O').keys() # kuva muutujad cat
väljund: -

Nüüd peame need numbrilised veerud andmestikust välja jätma ja kasutame seda kategoorilist muutujat. Me kasutame andmestikust ainult 3–4 kategoorilist veergu ühe kuumuse kodeeringu rakendamiseks.
Uue andmeraami loomine
Nüüd loome kategooriliste muutujate kasutamiseks uue andmeraami valitud kategooria veergudest.
# uue df-i loomine # seadete veerge kasutame new_df = pd.read_csv('house_price.csv',usecols=['Naabruskond','Exterior1st', 'Exterior2nd']) new_df.head()
väljund: -

Nüüd peame välja selgitama, kui palju unikaalseid kategooriaid on igas kategooria veerus.
Unikaalsete väärtuste leidmine
Unikaalsete väärtuste leidmiseks kasutame funktsiooni pandas unikaalne().
# kordumatud väärtused x igas veerus failis new_df.columns: #prinfting unikaalsed väärtused print(x ,':', len(new_df[x].unique()))
väljund: -
| Naabruskond: 25 |
| Välispind 1: 15 |
| Välimine 2.: 16 |
Nüüd käsitleme oma tehnikat, et rakendada mitme kategooria muutujatele ühekordset kodeeringut.
Mitme kategooria muutujate tehnika
Tehnika seisneb selles, et me piirame ühekuulise kodeerimise muutuja 10 kõige sagedasema sildiga. See tähendab, et teeme ühe binaarmuutuja ainult iga 10 kõige sagedasema sildi jaoks, mis võrdub kõigi teiste siltide grupeerimisega uude kategooriasse, mis sel juhul välja jäetakse. Seega näitavad 10 uut näivat muutujat, kas üks kümnest kõige sagedamini esinevast märgisest on olemas 1 või siis mitte 0 konkreetse vaatluse jaoks.
Kõige sagedasemad muutujad
Siin valime 20 kõige sagedamini esinevat muutujat.
Oletame, et võtame ühe kategoorilise muutuja Naabrus.
# 20 parima kategooria leidmine new_df.Neighborhood.value_counts().sort_values(ascending=False).head(20)
väljund:

Kui näete seda väljundpilti, märkate, et NIMED silt kordub naabruskonna veergudes 225 korda ja me läheme alla, see arv väheneb.
Nii et võtsime 10 parimat tulemust ülaosast ja teisendasime selle 10 parima tulemuse ühekordseks kodeeringuks ja vasakpoolsed sildid muutuvad nulliks.
väljund: -

Kõige sagedamini esinevate kategooriliste muutujate loend
# koosta loend 10 populaarseima muutujaga top_10 = [x jaoks x in new_df.Neighborhood.value_counts().sort_values(ascending=False).head(10).index] top_10
väljund: -
["NIMED",
"CollgCr",
'Vanalinn',
"Edwards",
"Somerst",
"Gilbert",
"NridgHt",
"Sawyer",
'NWAmes',
"SawyerW"]
Naabruskonna veerus on 10 parimat kategoorilist silti.
Tee binaarne
Nüüd peame tegema top_10 siltide 10 binaarset muutujat:
# tee siltidest binaarfail
sildi jaoks top_10:
uus_df = np.where(new_df['Neighborhood']==silt,1,0)
new_df[['Neighborhood']+top_10]
väljund: -
| NIMED | CollgCr | Vanalinn | Edwards | Somerst | Gilbert | NridgHt | Saemees | NWAmes | SawyerW | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | CollgCr | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | Veenker | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | CollgCr | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | Crawfor | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | NoRidge | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | Mitchel | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 6 | Somerst | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 7 | NWAmes | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 8 | Vanalinn | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 9 | BrkSide | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 10 | Saemees | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 11 | NridgHt | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
Näete, kuidas top_10 sildid nüüd binaarvormingusse teisendatakse.
Võtame näite, vaata tabelist, kus 1 indeks Veenker mis ei kuulunud meie top_10 kategooria sildile, nii et selle tulemuseks on 0 kõik veerud.
Nüüd teeme seda kõigi ülaltoodud kategooria muutujate puhul.
Kõik valitud muutujad rakenduses OneHotEncoding
# valisime kõigi kategooria muutujate jaoks def top_x(df2,muutuja,top_x_sildid): sildi jaoks top_x_labels: df2[muutuja+'_'+silt] = np.where(data[muutuja]==silt,1,0) # loe the data again data = pd.read_csv('D://xdatasets/train.csv',usecols = ['Neighborhood','Exterior1st','Exterior2nd']) #encode Neighborhood 10 sagedasemasse kategooriasse top_x(data, 'Neighborhood',top_10) # kuva andmed data.head()
Väljund:-

Nüüd rakendame siin kõikidele mitme kategooria muutujatele ühekordset kodeeringut.
Nüüd näeme One Hot Encodingi eeliseid ja puudusi mitme muutuja jaoks.
Eelised
- Lihtne rakendada
- Ei nõua muutuja uurimiseks palju aega
- Ei laienda funktsiooniruumi massiliselt.
Puudused
- Ei lisa teavet, mis võib muuta muutuja ennustavamaks
- Ärge hoidke ignoreeritud muutujate teavet.
Lõpeta märkused
Kokkuvõte on see, et me õpime, kuidas käsitleda mitme kategooria muutujaid. Kui selle probleemiga kokku puutute, on see väga keeruline ülesanne. Nii et tänan teid selle artikli lugemise eest.
Ühendage minuga Linkedinis: profiil
Lugege minu teisi artikleid: https://www.analyticsvidhya.com/blog/author/mayurbadole2407/
Aitäh 😎
Selles artiklis näidatud meediumid ei kuulu Analytics Vidhyale ja neid kasutatakse autori äranägemisel.
Seda artiklit saate lugeda ka meie mobiilirakenduses 

seotud artiklid
- '
- algoritme
- Materjal: BPA ja flataatide vaba plastik
- Lubades
- analüüs
- analytics
- app
- õun
- taotlus
- PIIRKOND
- kunst
- artikkel
- kaubad
- BEST
- kontroll
- Veerg
- loomine
- andmed
- andmete analüüs
- andmeteadus
- Drop
- langes
- Inseneriteadus
- sündmus
- Laiendama
- tunnusjoon
- FUNKTSIOONID
- esimene
- vorm
- formaat
- funktsioon
- SUGU
- hea
- Google Play
- Käsitsemine
- siin
- maja
- Kuidas
- Kuidas
- HTTPS
- tohutu
- pilt
- importivate
- Suurendama
- indeks
- info
- IT
- teadmised
- Labels
- Õppida
- õppimine
- piiratud
- nimekiri
- masinõpe
- Meedia
- mobiilne
- mobiilirakenduse
- mudel
- Muu
- jõudlus
- vaene
- ennustus
- Ennustused
- esitada
- hind
- Hinnaprognoos
- projekt
- Python
- Töötlemata
- algandmed
- Lugemine
- Tulemused
- teadus
- väljavalitud
- komplekt
- kehtestamine
- SUURUS
- So
- Ruum
- algus
- aeg
- ülemine
- läbipaistvus
- us
- väärtus
- X
- null