Ma ei jõudnud sel aastal Punta Canasse  aga mul on (kaugemalt) hea meel nende inimeste üle, kes suutsid vaatamata reisipiirangutele kohale jõuda! Premium sisu sees.
aga mul on (kaugemalt) hea meel nende inimeste üle, kes suutsid vaatamata reisipiirangutele kohale jõuda! Premium sisu sees.
Sügis sai väga töine ja tahaks proovida lühemat formaati: igal suurel teemal on üks “prožektori valgus”  põhiploki tööd, mis mulle eriti huvitavad, ja mitu asjakohast tööd, mille kirjeldus on veidi lühem.
põhiploki tööd, mis mulle eriti huvitavad, ja mitu asjakohast tööd, mille kirjeldus on veidi lühem.
Tänane plaan:
- KG-laiendatud keelemudelid: kategoriseerimine
- Vestluspõhine tehisintellekt: lõpetage hallutsineerimine, vend
- Üksuste linkimine: kolossaalsuse varjus (üksused)
- KG Ehitus
- KG küsimusele vastamine: lisage mõned
 SPARQL
SPARQL
Kui see põhjalik hariv sisu on teile kasulik, tellige meie AI-uuringute meililist hoiatada, kui avaldame uut materjali.
KG-laiendatud keelemudelid: kategoriseerimine
Relatsioonilise maailma teadmiste esitus kontekstuaalsetes keelemudelites: ülevaade Tara Safavi ja Danai Koutra
Kui olete selliste kokkuvõtete (või varasemate postituste) kogenud lugeja, siis teate üsna hästi, kui palju on igal konverentsil avaldatud ja iganädalaselt arxivisse üles laaditud KG-ga täiendatud LM-e. Kui tunnete end eksinud  — Võin kinnitada, et te pole ainuke.
— Võin kinnitada, et te pole ainuke.
Sel aastal on meil lõpuks a kindel raamistik ja erinevate KG+LM-lähenemiste taksonoomiat! Autorid määratlevad 3 suurt perekonda: 1⃣ KG järelevalve puudub, LM-i parameetritesse kodeeritud teadmiste uurimine cloze-stiilis viipadega; 2⃣ KG järelevalve üksuste ja ID-dega; 3⃣ KG järelevalve seosemallide ja pinnavormidega.
Igal perel on paar haru  Näiteks vaatame nelja olemiteadlikku mudelit, mis on illustreeritud allpool. Erinevalt "Vähem sümboolne" et "Rohkem sümboolne", mõned LM-id teostavad mainimisvahemiku maskeerimist või kontrastset õppimist või olemi manustamist tuntud sõnavarast. Autorid tegid suurepärast tööd kümnete olemasolevate arhitektuuride klassifitseerimisel raamistiku järgi ja see näeb nüüd palju paremini organiseeritud. Väga vajalik töö!
Näiteks vaatame nelja olemiteadlikku mudelit, mis on illustreeritud allpool. Erinevalt "Vähem sümboolne" et "Rohkem sümboolne", mõned LM-id teostavad mainimisvahemiku maskeerimist või kontrastset õppimist või olemi manustamist tuntud sõnavarast. Autorid tegid suurepärast tööd kümnete olemasolevate arhitektuuride klassifitseerimisel raamistiku järgi ja see näeb nüüd palju paremini organiseeritud. Väga vajalik töö! 

Mõned lühikesed artiklid keskenduvad LM-ide rikastamisele biomeditsiiniliste KG-dega, mis on pikaajaline jõupingutus õpetada LM-idele domeenispetsiifilist biomeditsiini. släng. Meng et al esitama Vaheseinte segu (MoP), LM, mis põhineb AdapterFusion tehnika, mis leevendab vajadust LM-e nullist eelkoolitada. MoP koolitati tavaliste biomeditsiiniliste sõnavarade ja ontoloogiatega UMLS ja SNOMED CT. Sung et al küsima "Kas keelemudelid võivad olla biomeditsiiniliste teadmiste baasid?" viidates kuulus EMNLP'19 artikkel Petroni jt poolt. Vastus on suures osas EI. Autorid kujundavad BioLAMA, UMLS-i, CTD-st ja Wikidatast koostatud biomeditsiiniliste teadmiste kontrollimise etalon. Nad leiavad, et kaasaegsed LM-id saavutavad nende sondide puhul <10% täpsuse, seega vajab kogukond kindlasti midagi usaldusväärsemat
Meng et al esitama Vaheseinte segu (MoP), LM, mis põhineb AdapterFusion tehnika, mis leevendab vajadust LM-e nullist eelkoolitada. MoP koolitati tavaliste biomeditsiiniliste sõnavarade ja ontoloogiatega UMLS ja SNOMED CT. Sung et al küsima "Kas keelemudelid võivad olla biomeditsiiniliste teadmiste baasid?" viidates kuulus EMNLP'19 artikkel Petroni jt poolt. Vastus on suures osas EI. Autorid kujundavad BioLAMA, UMLS-i, CTD-st ja Wikidatast koostatud biomeditsiiniliste teadmiste kontrollimise etalon. Nad leiavad, et kaasaegsed LM-id saavutavad nende sondide puhul <10% täpsuse, seega vajab kogukond kindlasti midagi usaldusväärsemat  .
.
Vestluspõhine tehisintellekt: lõpetage hallutsineerimine, vend
Neural Path Hunter: hallutsinatsioonide vähendamine dialoogisüsteemides tee maandamise kaudu autorid Nouha Dziri, Andrea Madotto, Osmar Zaiane, Avishek Joey Bose
Vastuste genereerimine KG taustaga ConvAI süsteemiga on keeruline. Paljude komponentidega torujuhtmesüsteemides kasutate rangelt pinnavorme (oleminimesid) ja kasutate enamasti malle ja mallid on igavad ja vaevalt hooldatav. Teisest küljest annavad e2e generatiivsed mudelid, nagu GPT-2 ja GPT-3, palju ainulaadsemaid vastuseid, kuid sageli hallutsineerivad, st sisestavad valesid oleminimesid, kui te seda ei oota.
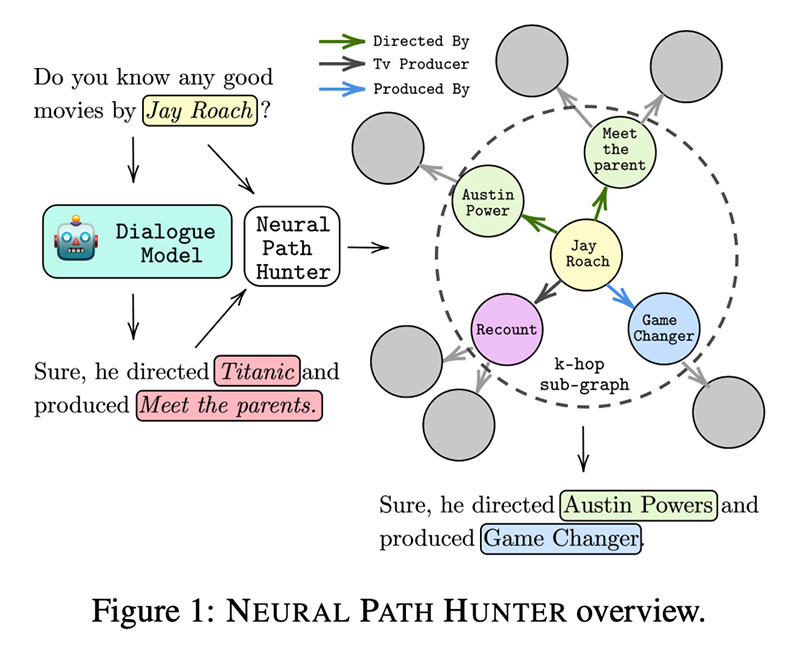
Selle töö autorid asusid a jaht  hallutsinatsioonide vähendamiseks KG järelevalve ettepanekuga Neural Path Hunter. Esiteks uurivad nad mitut teatud tüüpi halluatsioonid , kust need pärinevad (peamiselt top-k valimitest) ja kuidas seda kvantifitseerida.
hallutsinatsioonide vähendamiseks KG järelevalve ettepanekuga Neural Path Hunter. Esiteks uurivad nad mitut teatud tüüpi halluatsioonid , kust need pärinevad (peamiselt top-k valimitest) ja kuidas seda kvantifitseerida.
NPH ise koosneb kahest moodulist: 1⃣ kriitik (mitteautoregressiivne LM), mis teostab märkide alusel binaarset klassifikatsiooni; 2⃣ olemi retriiver olemi vigade parandamiseks: see on sisuliselt olemimälu, kus olemi manustused pärinevad GPT-st ja mida värskendatakse graafiku struktuuri kasutades CompGCN-iga. Kõige usutavamad kandidaadid pärinevad DistMulti punktifunktsiooni rakendamisest. Voila!
NPH-d saab siduda mis tahes eelkoolitatud LM-ga, katsed OpenDialKG etalon GPT2-KG-ga, GPT2-KEja AdapterBot näidata olulist vähenemist  hallutsinatsioonid ja suurenemine
hallutsinatsioonid ja suurenemine  ustavuses. Kasutajauuringud näitavad, et inimese poolt mõõdetud hallutsinatsioonid vähenevad NPH mudelites ~2 korda
ustavuses. Kasutajauuringud näitavad, et inimese poolt mõõdetud hallutsinatsioonid vähenevad NPH mudelites ~2 korda
Veel üks asjakohane töö selles kontekstis: Honovich et al uurida sama probleemi dialoogisüsteemides, kuid ilma tausta KGta ja pakkuda välja uus võrdlusalus Q² et mõõta küsimuste genereerimise ja küsimustele vastamise faktilist järjepidevust (kui küsite mõlemad Q-d).
Kui teile meeldivad ConvAI ja tavamõistuslikud KG-d – vaadake kindlasti CLUE-i (Conversational Multi-Hop Reasoner) Arabshahi, Lee jtmis hõlmab mõistet kui-(olek), siis-(tegevus), kuna-(eesmärk) mustrid loogilised reeglid ja sümboolne arutluskäik.
Üksuste sidumine: Kolossi varjus
Olemi täpsustuse usaldusväärsuse hindamine eelnevate proovide abil: olemi varjutamise juhtum by Vera Provatorova, Svitlana Vakulenko, Samarth Bhargav, Evangelos Kanoulas
Kui ühendate keeleülesannete jaoks reaalmaailma KG-d, puutute sellega paratamatult kokku erinevad üksused millel täpselt on sama nimi  . Kahjuks ei kasuta inimkond ainulaadseid räsisid kõigi maailma olemite jaoks, nii et olemite täpsustus jääb olemi linkimise oluliseks sammuks.
. Kahjuks ei kasuta inimkond ainulaadseid räsisid kõigi maailma olemite jaoks, nii et olemite täpsustus jääb olemi linkimise oluliseks sammuks.

Näiteks Wikidatas on vähemalt 18 üksust nimega "Michael Jordan". Sageli toetuvad EL-süsteemid põhistatistikale ja populaarsuse skooridele, nii et kõige populaarsem "korvpallur Michael Jordan" varjutaks vähem silmapaistvad (vähemalt popkultuuris) inimesed.
 Autorid tegelevad selle probleemiga ja tutvustavad uut andmekogumit, ShadowLink, et mõõta kaasaegsete EL-süsteemide segaduse astet. Selgus, et kõrgeim F1 skoor ulatub vaevu 0.35-ni (hiljutine generatiiv ŽANR annab 0.26) kõige raskemas osas. Kõik süsteemid küllastavad oma hinded pika sabaga haruldaste olemite puhul ja saavad hakkama ka tavalisemate üksustega. Peamine väljakutse on sõnastatud järgmiselt:ülesande teeb keeruliseks mitmetähenduslikkuse ja ebatavalisuse kombinatsioon”. Soovitan autoritel andmestik üles laadida HuggingFace'i andmestikud et suurendada nende laheda projekti nähtavust
Autorid tegelevad selle probleemiga ja tutvustavad uut andmekogumit, ShadowLink, et mõõta kaasaegsete EL-süsteemide segaduse astet. Selgus, et kõrgeim F1 skoor ulatub vaevu 0.35-ni (hiljutine generatiiv ŽANR annab 0.26) kõige raskemas osas. Kõik süsteemid küllastavad oma hinded pika sabaga haruldaste olemite puhul ja saavad hakkama ka tavalisemate üksustega. Peamine väljakutse on sõnastatud järgmiselt:ülesande teeb keeruliseks mitmetähenduslikkuse ja ebatavalisuse kombinatsioon”. Soovitan autoritel andmestik üles laadida HuggingFace'i andmestikud et suurendada nende laheda projekti nähtavust  .
.
Arora et al läheneda seostavale olemile teisest suunast. Põhiidee on see tõsi nimetatud üksuste dokumendis (töödeldakse ühiselt, mitte ükshaaval) sille madala auastmega alamruum  kõigi üksuste, sealhulgas kandidaatide ruumis (vaadake allolevat visuaalset näidet). The Eingenthemes lähenemine on järelevalveta, kui teil on eelkoolitatud olemi manustused – autorid kasutavad DeepWalki Wikidata ingliskeelse alamhulga kohal (alternatiivina proovivad nad sõna manustamist, kuid see ei tööta nii hästi).
kõigi üksuste, sealhulgas kandidaatide ruumis (vaadake allolevat visuaalset näidet). The Eingenthemes lähenemine on järelevalveta, kui teil on eelkoolitatud olemi manustused – autorid kasutavad DeepWalki Wikidata ingliskeelse alamhulga kohal (alternatiivina proovivad nad sõna manustamist, kuid see ei tööta nii hästi).

Kontseptuaalselt sarnane olemipõhiste konfliktide probleem uurib Longpre et al, nimelt teadmiste asendamine – kui muudate lõigus tõelise olemi juhuslikuks (või vastuoluliseks), kas mudel muudaks vastust? Teisisõnu, kas QA mudelid tugineksid konteksti lugemisele või meelde jäetud teadmistele? Selgub, et selliste asendustega QA mudelite treenimisel saate OOD üldistust tublisti suurendada!
Lõpuks vaadake küsitlust Tedeschi et al on "NER üksuste linkimiseks: mis töötab ja mis edasi". Autorid tuvastavad EL-i peamised väljakutsed ja püüavad käsitleda NER-i jaoks olulisi väljakutseid NER4EL mille eesmärk on vähendada jõudluslõhet suurte eelkoolitatud LM-de ja väiksemate mudelite vahel, mis on eriti oluline vähese ressursiga stsenaariumide puhul .

KG Ehitus
Mul ei õnnestunud siin meeldejäävat joont välja mõelda :/ Kui olete OpenIE ja KG Ehituse alal, võivad järgmised paberid olla asjakohased.
Dognin et al esitama ReGen, lähenemine LM-de peenhäälestamiseks nii Text2Graphi kui ka Graph2Text ülesannete täitmiseks (või spetsiaalsete mudelite peenhäälestamiseks). Peamine koostisosa  lisab standardsele ristentroopiale (CE) lisaks RL-i kadu (self-critical Sequence Training). Seda saab hõlpsasti lisada igale eelkoolitatud LM-ile - autorid proovivad seda T5-Large'i (770M parameetriga) ja T5-base'iga (220M parameetriga).
lisab standardsele ristentroopiale (CE) lisaks RL-i kadu (self-critical Sequence Training). Seda saab hõlpsasti lisada igale eelkoolitatud LM-ile - autorid proovivad seda T5-Large'i (770M parameetriga) ja T5-base'iga (220M parameetriga).  Eksperimentaalselt ReGen parandab oluliselt Text2Graph WebNLG baasjooni (3–10 abs. punkti olenevalt mõõdikust) ja töötab palju suurem TekGeni andmestik (6M treeningpaari).
Eksperimentaalselt ReGen parandab oluliselt Text2Graph WebNLG baasjooni (3–10 abs. punkti olenevalt mõõdikust) ja töötab palju suurem TekGeni andmestik (6M treeningpaari).
Dash et al uurida kanoniseerimine probleem OpenIE-s — kui erinevate pinnavormidega olemitele meeldib (NYC, New York City) viitavad samale prototüübile. Me tahame, et IE süsteemid koondaksid need mainimised automaatselt kokku järelevalveta. Meetod, TRUMM, kasutab klastrite tuvastamiseks variatsioonilisi automaatkoodereid (VAE) (olemite ja suhete parameetrid on Gausslased). Lisaks VAE standardile rekonstrueerimise kaotus, CUVA võtab tööle täiendavaid lingi ennustus kaotus põhineb HolE punktifunktsioonil.  Lisaks tutvustavad autorid romaani CanonicNELL andmestik!
Lisaks tutvustavad autorid romaani CanonicNELL andmestik!

KG küsimusele vastamine: lisage mõned SPARQL
SPARQLingi andmebaasipäringud vahepealsetest küsimuste lagunemistest by Irina Saparina ja Anton Osokin
Kahjuks pole *CL domeenis nii palju SPARQL-i rakendusi. Ma arvan, et see väärib NLP-s palju laiemat kasutuselevõttu. Kui seda toetab lahe rakendus – olen sees  .
.
Enamik struktureeritud kvaliteedikontrolli andmekogumeid või neid, mis kasutavad peamise väljundvorminguna semantilist parsimist siht-SQL-i. Kas väljaspool SQL-i torujuhtmeid on elu?
Saparina ja Osokin pakkuge sellele probleemile uus ilme, kasutades esmalt 1⃣, kasutades a Küsimuse lagunemise tähenduse esitus (QDMR) raamistik, mis tõlgib küsimuse süntaksist sõltumatusse loogilisse vormi; 2⃣ Seda vormi saab tõlkida mis tahes struktureeritud vormingusse ja siin kasutavad autorid SPARQL-i, mis näitab, et graafikuvormingus andmebaaside päringuid on palju lihtsam teha. See nõuab sisendtabeli muutmist RDF-iks, kuid andmekogumite jaoks Ämblik skaalal saab seda teha väga lihtsalt.
Koolitatavad moodulid hõlmavad RAT trafo LSTM-dekoodriga kodeerija, mis toodab QDMR-märke. QDMR -> SPARQL on sirge transpilatsioon, mis põhineb vähestel reeglitel. On-par-to-SOTA tulemused; kood on saadaval ; SPARQL töötab paremini kui SQL;
On-par-to-SOTA tulemused; kood on saadaval ; SPARQL töötab paremini kui SQL;
mida veel hea paberi jaoks vaja on?

Jälle üks põnev töö Das et al „Juhtumipõhine põhjendus loomuliku keele päringute jaoks teadmistebaaside üle ühendab SPARQL-iga juhtumipõhine arutluskäik (CBR). CBR-l on sügavad juured ekspertsüsteemides juba 80ndatel, kuid see taastati hiljuti esindusõppe võimega. TLDR-i selgitus CBR-i kohta 2021. aastal: see on kontseptuaalselt lähedane kompositsioonilisele üldistusele, st mõnede põhinäidete nägemisel saate koostada keerukama päringu seninägematute olemite kohta.
Vaadake allolevat näidet. Meil on sisestuspäring "Kes on Gimli isa õde-vend Hobitis?". Treeningandmetes ei pruugi meil Gimli või Hobbiti kohta midagi olla, kuid meil võib olla "suhteliselt sarnane" juhtudel seostest, mida võiksime oma päringu jaoks kasulikuks pidada, nt "Kes on Charlie Sheeni isa?" Freebase'i seosega people.person_parents ja "Kes on Rihanna õde-vend?" suhtega people.person.sibling_s . Koostades need meie küsimuse jaoks, koostame andmebaasi SPARQL-päringu.
Kavandatud CBR-KBQA lähenemine ühendab endas 1⃣ treenitavat DPR-stiilis neuraalset retriiverit (järelevalve põhineb kattuvatel suhetel), 2⃣ lineaarset trafot (nad kasutavad BigBirdi), kuna seotud küsimused ja päringud on üsna pikad, 3⃣ mitmed ümberjärjestusmehhanismid ennustused. Nad kasutavad valmis mooduleid NER ja Entity Linking ning kasutavad ümber järjestamiseks ka eelkoolitatud TransE seoste manuseid. CBR-KBQA demonstreerib muljetavaldavat jõudlust mitmes KBQA andmekogumis, sealhulgas CFQ. Väike märkus: ma olen veidi kahtlustav, et parim saadaolev SOTA mudel (67.3 MCD-Mean) on sellise marginaaliga 78.1-ni ületatud ja etalonile esitamata, kood pole ka veel saadaval.

Shi et al uurige mitme hüppega kvaliteedikontrolli ja tehke ettepanek integreerida nii olemi/relatsiooni ID-d (sildivorm) kui ka nende loomuliku keele kirjeldused (tekstivorm) oma sõnumite levitamise raamistikku TransferNet. Hindamine toimub standardsete MetaQA, WebQuestionsSP ja Complex Web Questions andmekogumitega.
Samas ülesandes (samad andmestikud, mis eelmises töös) Oliya et al märkasid, et enamik SOTA kvaliteedikontrolli mudeleid nõuavad tekstivahemikke, mis on juba KG-üksustega seotud, ja proovivad sellest nõudest mööda hiilida dünaamilise olemi ümberjärjestamisega, kasutades KG-olemite sõlmede naabruskonna funktsioone ja tekstivahemike funktsioone.
See on kõik
Andke mulle teada, kui teile meeldib see lühem "premum"  vorming parem kui pikad tekstiseinad nagu eelmistes arvustustes! Täname, et investeerisite siia oma aega, loodan, et võtsite koju kaasa midagi kasulikku
vorming parem kui pikad tekstiseinad nagu eelmistes arvustustes! Täname, et investeerisite siia oma aega, loodan, et võtsite koju kaasa midagi kasulikku

See artikkel oli algselt avaldatud Keskmine ja avaldati autori loal uuesti TOPBOTSis.
Kas teile meeldib see artikkel? Registreeruge, et saada rohkem AI värskendusi.
Anname teile teada, kui avaldame rohkem tehnilist haridust.
Postitus EMNLP 2021 teadmistegraafikud ilmus esmalt TOPBOOTID.
- '
- "
- 10
- 11
- 2021
- 67
- 7
- 9
- a
- MEIST
- küllus
- Vastavalt
- tegevus
- lisatud
- lisamine
- aadress
- haldamine
- Vastuvõtmine
- AI
- ai uuringud
- Eesmärk
- Materjal: BPA ja flataatide vaba plastik
- juba
- Mitmetähenduslikkus
- analytics
- Teine
- vastus
- taotlus
- rakendused
- rakendatud
- Rakendades
- lähenemine
- artikkel
- autorid
- automaatselt
- saadaval
- tagapõhi
- korvpall
- alla
- võrrelda
- BEST
- vahel
- Peale
- suurim
- Natuke
- Blokeerima
- äri
- helistama
- kandidaadid
- juhul
- juhtudel
- väljakutse
- väljakutseid
- raske
- muutma
- Linn
- klassifikatsioon
- kood
- kombinatsioon
- Tulema
- ühine
- kogukond
- keeruline
- komponendid
- Konverents
- segadus
- ehitus
- sisu
- võiks
- kultuur
- klient
- Klienditugi
- andmed
- andmebaas
- andmebaasid
- sügav
- näitama
- Olenevalt
- kirjeldama
- DID
- erinev
- Ei tee
- domeen
- dünaamiline
- iga
- kergesti
- Käsitöö
- haridus-
- jõupingutusi
- töötab
- Inglise
- üksuste
- üksus
- eriti
- põhiliselt
- hindamine
- sündmus
- näide
- näited
- põnev
- olemasolevate
- ootama
- ekspert
- peredele
- pere
- FUNKTSIOONID
- Lõpuks
- rahastama
- esimene
- Keskenduma
- Järel
- vorm
- formaat
- vormid
- Raamistik
- Alates
- funktsioon
- lõhe
- põlvkond
- generatiivne
- GitHub
- eesmärk
- hea
- suur
- õnnelik
- võttes
- kõrgus
- siin
- Avaleht
- lootus
- Kuidas
- Kuidas
- hr
- HTTPS
- Inimkond
- idee
- identifitseerima
- oluline
- muljetavaldav
- Teistes
- Kaasa arvatud
- Suurendama
- sisend
- Näiteks
- integreerima
- investeerimine
- IT
- ise
- töö
- Võti
- Teadma
- teadmised
- teatud
- silt
- keel
- suur
- õppimine
- Õigus
- joon
- sidumine
- London
- Pikk
- Vaata
- Enamus
- tegema
- TEEB
- juhtima
- juhitud
- viis
- Turundus
- materjal
- tähendus
- mõõtma
- keskmine
- Mälu
- mainib
- võib
- mudel
- mudelid
- rohkem
- kõige
- Populaarseim
- nimelt
- nimed
- Natural
- vajadustele
- New York
- New York City
- Mõiste
- NYC
- Ontario
- Operations
- Korraldatud
- Muu
- Paber
- osa
- eriti
- jõudlus
- inimene
- palun
- võrra
- populaarne
- populaarsus
- Postitusi
- võim
- Ennustused
- preemia
- ilus
- eelmine
- Probleem
- tootma
- Toode
- projekt
- silmapaistev
- esitama
- küsimus
- lugeja
- Lugemine
- hiljuti
- hiljuti
- soovitama
- vähendama
- Lühendatud
- vähendamine
- suhted
- vabastama
- asjakohane
- usaldusväärne
- jäänused
- Aruanded
- esindamine
- nõudma
- teadustöö
- Resort
- Tulemused
- eeskirjade
- müük
- sama
- Skaala
- Hinded
- mitu
- vari
- Lühike
- kirjutama
- märkimisväärne
- väike
- So
- mõned
- midagi
- Ruum
- spetsialiseeritud
- standard
- riik
- stats
- struktureeritud
- Uuring
- esitatud
- järelevalve
- toetama
- Toetatud
- Pind
- Uuring
- süsteem
- süsteemid
- sihtmärk
- ülesanded
- Tehniline
- malle
- .
- maailm
- aeg
- täna
- kokku
- märgid
- teema
- koolitus
- transformeerivate
- Reisimine
- Uk
- ainulaadne
- Uudised
- kasutama
- eri
- nähtavus
- W
- web
- iga nädal
- M
- WHO
- laiem
- sõnad
- Töö
- töötab
- maailm
- oleks
- aasta
- Sinu









