Sissejuhatus
Tere tulemast meie kõikehõlmavasse andmete analüüs blogi, mis süveneb sügavale Netflixi maailma. Maailma ühe juhtiva voogedastusplatvormina on Netflix muutnud meelelahutuse tarbimise. Oma tohutu filmide ja telesaadete raamatukoguga pakub see vaatajatele üle maailma palju valikuvõimalusi.
Netflixi globaalne haare
Netflix on kogenud märkimisväärset kasvu ja laiendanud oma kohalolekut, et saada voogedastustööstuses domineerivaks jõuks. Siin on mõned tähelepanuväärsed statistikad, mis näitavad selle ülemaailmset mõju:
- Kasutajate baas: 2022. aasta teise kvartali alguseks oli Netflix kogunud ligikaudu 222 miljonit rahvusvahelist tellijat, mis hõlmab üle 190 riigi (v.a Hiina, Krimm, Põhja-Korea, Venemaa ja Süüria). Need muljetavaldavad arvud rõhutavad platvormi laialdast heakskiitu ja populaarsust kogu maailmas.
- Rahvusvaheline laienemine: Kuna Netflix on saadaval enam kui 190 riigis, on see edukalt saavutanud ülemaailmse kohaloleku. Ettevõte on teinud märkimisväärseid jõupingutusi oma sisu lokaliseerimiseks, pakkudes subtiitreid ja dubleerimist erinevates keeltes, tagades juurdepääsetavuse mitmekesisele publikule.
Selles blogis asume põnevale teekonnale, et uurida Netflixi sisumaastikul peidetud intrigeerivaid mustreid, suundumusi ja teadmisi. Võimendades jõudu Python ja selle andmete analüüs raamatukogudes, sukeldume Netflixi pakkumiste tohutusse kogusse, et leida väärtuslikku teavet, mis heidab valgust sisu täiendustele, kestuse jaotustele, žanri seostele ja isegi pealkirjades ja kirjeldustes kõige sagedamini kasutatavatele sõnadele.
Läbi üksikasjalike koodijuppide ja visualiseeringuid, eemaldame Netflixi sisu ökosüsteemi kihid, et anda värske ülevaade platvormi arengust. Analüüsides väljalaskemustreid, hooajalisi trende ja vaatajaskonna eelistusi, püüame paremini mõista sisu dünaamikat Netflixi tohutus universumis.
See artikkel avaldati osana Andmeteaduse ajaveebi.
Sisukord
Andmete ettevalmistamine
Selles juhtumiuuringus kasutatud andmed pärinevad andmeteaduse ja masinõppe entusiastide populaarsest platvormist Kaggle. Andmekogum pealkirjaga "Netflixi filmid ja telesaated”, on Kaggle'is avalikult saadaval ja pakub väärtuslikku teavet Netflixi voogesituse platvormi filmide ja telesaadete kohta.
Andmekogum koosneb tabelivormingust, mis sisaldab erinevaid veerge, mis kirjeldavad iga filmi või telesaate erinevaid aspekte. Siin on tabel, mis võtab kokku veerud ja nende kirjeldused:
| Veeru nimi | Kirjeldus |
|---|---|
| näita_id | Iga filmi/telesaate kordumatu ID |
| tüüp | Identifikaator – film või telesaade |
| pealkiri | Filmi/telesaate pealkiri |
| juhataja | Filmi režissöör |
| koo | Filmis / saates osalevad näitlejad |
| riik | Riik, kus film/saade toodeti |
| kuupäev lisatud | Netflixi lisamise kuupäev |
| väljalaske_aasta | Filmi/saate tegelik väljalaskeaasta |
| hinnang | Filmi/saate telehinnang |
| kestus | Kogukestus – minutites või hooaegade arvus |
Selles jaotises teostame Netflixi andmestiku andmete ettevalmistamise ülesandeid, et tagada selle puhtus ja sobivus analüüsiks. Käsitleme puuduvaid väärtusi ja duplikaate ning teostame vajadusel andmetüüpide teisendusi. Sukeldume koodi ja uurime iga sammu.
Raamatukogude importimine
Alustuseks impordime andmete analüüsiks ja visualiseerimiseks vajalikud teegid. Need raamatukogud hõlmavad pandas, numpy ja matplotlib. pyplot ja seaborn. Need pakuvad olulisi funktsioone ja tööriistu andmete tõhusaks manipuleerimiseks ja visualiseerimiseks.
# Importing necessary libraries for data analysis and visualization
import pandas as pd # pandas for data manipulation and analysis
import numpy as np # numpy for numerical operations
import matplotlib.pyplot as plt # matplotlib for data visualization
import seaborn as sns # seaborn for enhanced data visualizationAndmestiku laadimine
Järgmisena laadime Netflixi andmestiku funktsiooni pd.read_csv() abil. Andmekogum salvestatakse faili „netflix.csv”. Vaatame andmestiku viit esimest kirjet, et mõista selle struktuuri.
# Loading the dataset from a CSV file
df = pd.read_csv('netflix.csv') # Displaying the first few rows of the dataset
df.head()Kirjeldav statistika
Väga oluline on mõista andmestiku üldisi omadusi kirjeldav statistika. Saame ülevaate numbrilistest atribuutidest, nagu arv, keskmine, standardhälve, miinimum, maksimum ja kvartiilid.
# Computing descriptive statistics for the dataset
df.describe()Lühike kokkuvõte
Andmestikust kokkuvõtliku kokkuvõtte saamiseks kasutame funktsiooni df.info(). See annab teavet mitte-nullväärtuste arvu ja iga veeru andmetüüpide kohta. See kokkuvõte aitab tuvastada puuduvad väärtused ja võimalikud andmetüüpidega seotud probleemid.
# Obtaining information about the dataset
df.info()Puuduvate väärtuste käsitlemine
Väärtuste puudumine võib takistada täpset analüüsi. See andmestik uurib df-i abil igas veerus puuduvaid väärtusi. isnull().sum(). Meie eesmärk on tuvastada puuduvate väärtustega veerud ja määrata igas veerus puuduvate andmete protsent.
# Checking for missing values in the dataset
df.isnull().sum()Puuduvate väärtuste käsitlemiseks kasutame erinevate veergude jaoks erinevaid strateegiaid. Vaatame läbi iga etapi:
Duplikaadid
Duplikaadid võivad analüüsitulemusi moonutada, mistõttu on oluline nendega tegeleda. Tuvastame ja eemaldame dubleerivad kirjed, kasutades df.duplicated().sum().
# Checking for duplicate rows in the dataset
df.duplicated().sum()Puuduvate väärtuste käsitlemine konkreetsetes veergudes
Veergude „direktor” ja „ülekandmine” puhul asendame puuduvad väärtused väärtusega „Andmeid puuduvad”, et säilitada andmete terviklikkus ja vältida analüüsi nihkeid.
# Replacing missing values in the 'director' column with 'No Data'
df['director'].replace(np.nan, 'No Data', inplace=True) # Replacing missing values in the 'cast' column with 'No Data'
df['cast'].replace(np.nan, 'No Data', inplace=True)Veerus „riik” täidame puuduvad väärtused režiimiga (kõige sagedamini esinev väärtus), et tagada järjepidevus ja minimeerida andmete kadu.
# Filling missing values in the 'country' column with the mode value
df['country'] = df['country'].fillna(df['country'].mode()[0])Veerus „hinnang“ sisestame puuduvad väärtused saate „tüübi“ alusel. Filmide ja telesaadete jaoks määrame reitingurežiimi eraldi.
# Finding the mode rating for movies and TV shows
movie_rating = df.loc[df['type'] == 'Movie', 'rating'].mode()[0]
tv_rating = df.loc[df['type'] == 'TV Show', 'rating'].mode()[0] # Filling missing rating values based on the type of content
df['rating'] = df.apply(lambda x: movie_rating if x['type'] == 'Movie' and pd.isna(x['rating']) else tv_rating if x['type'] == 'TV Show' and pd.isna(x['rating']) else x['rating'], axis=1)Veerus "Kestus" sisestame puuduvad väärtused saate "tüübi" alusel. Määrame filmide ja telesaadete jaoks eraldi kestuse režiimi.
# Finding the mode duration for movies and TV shows
movie_duration_mode = df.loc[df['type'] == 'Movie', 'duration'].mode()[0]
tv_duration_mode = df.loc[df['type'] == 'TV Show', 'duration'].mode()[0] # Filling missing duration values based on the type of content
df['duration'] = df.apply(lambda x: movie_duration_mode if x['type'] == 'Movie' and pd.isna(x['duration']) else tv_duration_mode if x['type'] == 'TV Show' and pd.isna(x['duration']) else x['duration'], axis=1)Ülejäänud puuduvate väärtuste eemaldamine
Pärast konkreetsetes veergudes puuduvate väärtuste käsitlemist eemaldame kõik ülejäänud puuduvate väärtustega read, et tagada analüüsi jaoks puhas andmestik.
# Dropping rows with missing values
df.dropna(inplace=True)Kuupäeva käsitlemine
Teisendame veeru „date_added” kuupäeva-aja vormingusse kasutades pd.to_datetime(), et võimaldada kuupäevaga seotud atribuutidel põhinevat edasist analüüsi.
# Converting the 'date_added' column to datetime format
df["date_added"] = pd.to_datetime(df['date_added'])Täiendavad andmete teisendused
Analüüsivõimaluste täiustamiseks eraldame veerust „lisamiskuupäev” täiendavaid atribuute. Nende ajaliste aspektide põhjal suundumuste analüüsimiseks eemaldame kuu ja aasta väärtused.
# Extracting month, month name, and year from the 'date_added' column
df['month_added'] = df['date_added'].dt.month
df['month_name_added'] = df['date_added'].dt.month_name()
df['year_added'] = df['date_added'].dt.yearAndmete teisendamine: näitlejad, riik, kantud ja režissöör
Kategooriliste atribuutide tõhusamaks analüüsimiseks muudame need eraldi andmeraamideks, mis võimaldab rahulikumalt uurida ja analüüsida.
Veergude „cast”, „country”, „listed_in” ja „director” jaoks jagasime väärtused komaeraldaja alusel ja lõime iga väärtuse jaoks eraldi read. See teisendus võimaldab meil andmeid detailsemalt analüüsida.
# Splitting and expanding the 'cast' column
df_cast = df['cast'].str.split(',', expand=True).stack()
df_cast = df_cast.reset_index(level=1, drop=True).to_frame('cast')
df_cast['show_id'] = df['show_id'] # Splitting and expanding the 'country' column
df_country = df['country'].str.split(',', expand=True).stack()
df_country = df_country.reset_index(level=1, drop=True).to_frame('country')
df_country['show_id'] = df['show_id'] # Splitting and expanding the 'listed_in' column
df_listed_in = df['listed_in'].str.split(',', expand=True).stack()
df_listed_in = df_listed_in.reset_index(level=1, drop=True).to_frame('listed_in')
df_listed_in['show_id'] = df['show_id'] # Splitting and expanding the 'director' column
df_director = df['director'].str.split(',', expand=True).stack()
df_director = df_director.reset_index(level=1, drop=True).to_frame('director')
df_director['show_id'] = df['show_id']Pärast nende andmete ettevalmistamise etappide lõpetamist on meil puhas ja muudetud andmestik, mis on valmis edasiseks analüüsiks. Need esialgsed andmetega manipulatsioonid loovad aluse Netflixi andmekogumi uurimiseks ja voogesitusplatvormi andmepõhistest strateegiatest ülevaate saamiseks.
Uurimisandmete analüüs
Sisutüüpide levitamine
Netflixi teegi sisu jaotuse määramiseks saame arvutada sisutüüpide (filmid ja telesaated) protsentuaalse jaotuse järgmise koodi abil:
# Calculate the percentage distribution of content types
x = df.groupby(['type'])['type'].count()
y = len(df)
r = ((x/y) * 100).round(2) # Create a DataFrame to store the percentage distribution
mf_ratio = pd.DataFrame(r)
mf_ratio.rename({'type': '%'}, axis=1, inplace=True) # Plot the 3D-effect pie chart
plt.figure(figsize=(12, 8))
colors = ['#b20710', '#221f1f']
explode = (0.1, 0)
plt.pie(mf_ratio['%'], labels=mf_ratio.index, autopct='%1.1f%%', colors=colors, explode=explode, shadow=True, startangle=90, textprops={'color': 'white'}) plt.legend(loc='upper right')
plt.title('Distribution of Content Types')
plt.show()
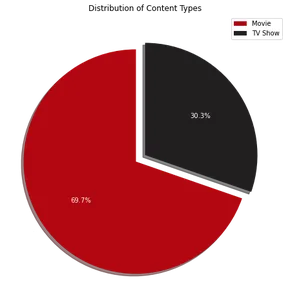
Sektordiagrammi visualiseerimine näitab, et ligikaudu 70% Netflixi sisust koosneb filmidest, ülejäänud 30% on telesaated. Järgmiseks saame kasutada järgmist koodi, et tuvastada 10 parimat riiki, kus Netflix on populaarne:
Top 10 riiki, kus Netflix on populaarne
Järgmiseks saame kasutada järgmist koodi, et tuvastada 10 parimat riiki, kus Netflix on populaarne:
# Remove white spaces from 'country' column
df_country['country'] = df_country['country'].str.rstrip() # Find value counts
country_counts = df_country['country'].value_counts() # Select the top 10 countries
top_10_countries = country_counts.head(10) # Plot the top 10 countries
plt.figure(figsize=(16, 10))
colors = ['#b20710'] + ['#221f1f'] * (len(top_10_countries) - 1)
bar_plot = sns.barplot(x=top_10_countries.index, y=top_10_countries.values, palette=colors) plt.xlabel('Country')
plt.ylabel('Number of Titles')
plt.title('Top 10 Countries Where Netflix is Popular') # Add count values on top of each bar
for index, value in enumerate(top_10_countries.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') plt.show()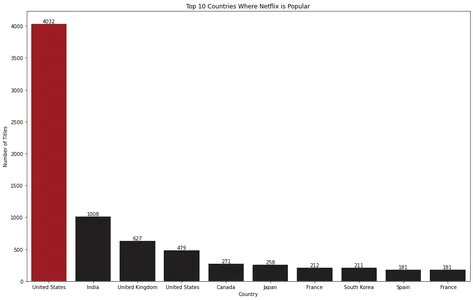
Lintdiagrammi visualiseerimine näitab, et Ameerika Ühendriigid on Netflixi populaarseim riik.
10 parimat näitlejat filmide/telesaadete arvu järgi
10 kõige rohkem filmides ja telesaadetes esinenud näitlejate tuvastamiseks võite kasutada järgmist koodi:
# Count the occurrences of each actor
cast_counts = df_cast['cast'].value_counts()[1:] # Select the top 10 actors
top_10_cast = cast_counts.head(10) plt.figure(figsize=(16, 8))
colors = ['#b20710'] + ['#221f1f'] * (len(top_10_cast) - 1)
bar_plot = sns.barplot(x=top_10_cast.index, y=top_10_cast.values, palette=colors) plt.xlabel('Actor')
plt.ylabel('Number of Appearances')
plt.title('Top 10 Actors by Movie/TV Show Count') # Add count values on top of each bar
for index, value in enumerate(top_10_cast.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') plt.show()
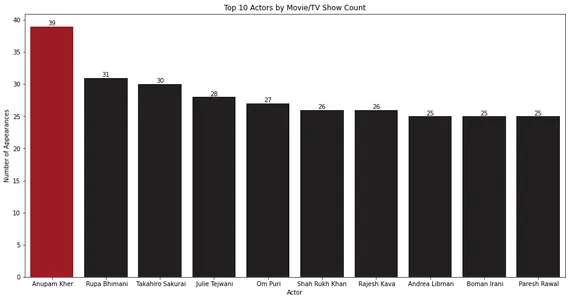
Lintdiagramm näitab, et Anupam Kheril on kõige rohkem esinemisi filmides ja telesaadetes.
10 parimat režissööri filmide/telesaadete arvu järgi
Kõige rohkem filme või telesaateid juhtinud 10 parima režissööri tuvastamiseks võite kasutada järgmist koodi:
# Count the occurrences of each actor
director_counts = df_director['director'].value_counts()[1:] # Select the top 10 actors
top_10_directors = director_counts.head(10) plt.figure(figsize=(16, 8))
colors = ['#b20710'] + ['#221f1f'] * (len(top_10_directors) - 1)
bar_plot = sns.barplot(x=top_10_directors.index, y=top_10_directors.values, palette=colors) plt.xlabel('Director')
plt.ylabel('Number of Movies/TV Shows')
plt.title('Top 10 Directors by Movie/TV Show Count') # Add count values on top of each bar
for index, value in enumerate(top_10_directors.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') plt.show()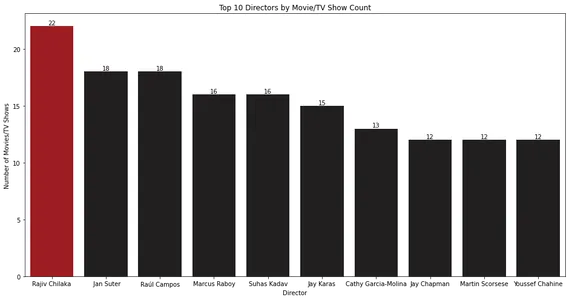
Lintdiagramm näitab 10 parimat režissööri, kellel on kõige rohkem filme või telesaateid. Näib, et Rajiv Chilaka on Netflixi raamatukogus kõige rohkem sisu juhtinud.
10 parimat kategooriat filmide/telesaadete arvu järgi
Sisu jaotuse analüüsimiseks erinevates kategooriates saate kasutada järgmist koodi:
df_listed_in['listed_in'] = df_listed_in['listed_in'].str.strip() # Count the occurrences of each actor
listed_in_counts = df_listed_in['listed_in'].value_counts() # Select the top 10 actors
top_10_listed_in = listed_in_counts.head(10) plt.figure(figsize=(12, 8))
bar_plot = sns.barplot(x=top_10_listed_in.index, y=top_10_listed_in.values, palette=colors) # Customize the plot
plt.xlabel('Category')
plt.ylabel('Number of Movies/TV Shows')
plt.title('Top 10 Categories by Movie/TV Show Count')
plt.xticks(rotation=45) # Add count values on top of each bar
for index, value in enumerate(top_10_listed_in.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') # Show the plot
plt.show()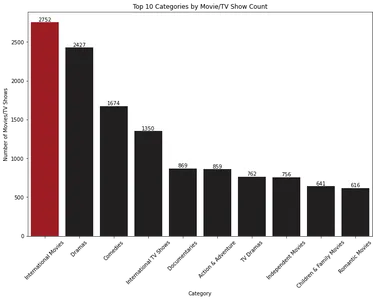
Lintdiagramm näitab 10 parimat filmide ja telesaadete kategooriat nende arvu põhjal. "Rahvusvahelised filmid" on kõige domineerivam kategooria, millele järgneb "Draamad".
Aja jooksul lisatud filmid ja telesaated
Filmide ja telesaadete lisamise analüüsimiseks aja jooksul saate kasutada järgmist koodi.
# Filter the DataFrame to include only Movies and TV Shows
df_movies = df[df['type'] == 'Movie']
df_tv_shows = df[df['type'] == 'TV Show'] # Group the data by year and count the number of Movies and TV Shows # added in each year
movies_count = df_movies['year_added'].value_counts().sort_index()
tv_shows_count = df_tv_shows['year_added'].value_counts().sort_index() # Create a line chart to visualize the trends over time
plt.figure(figsize=(16, 8))
plt.plot(movies_count.index, movies_count.values, color='#b20710', label='Movies', linewidth=2)
plt.plot(tv_shows_count.index, tv_shows_count.values, color='#221f1f', label='TV Shows', linewidth=2) # Fill the area under the line charts
plt.fill_between(movies_count.index, movies_count.values, color='#b20710')
plt.fill_between(tv_shows_count.index, tv_shows_count.values, color='#221f1f') # Customize the plot
plt.xlabel('Year')
plt.ylabel('Count')
plt.title('Movies & TV Shows Added Over Time')
plt.legend() # Show the plot
plt.show()
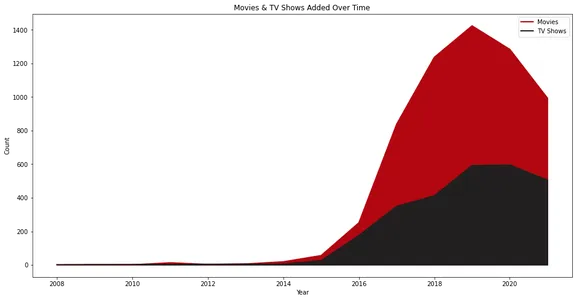
Joonediagramm illustreerib Netflixi aja jooksul lisatud filmide ja telesaadete arvu. See kujutab visuaalselt sisu lisamise kasvu ja suundumusi koos eraldi ridadega filmide ja telesaadete jaoks.
Netflix nägi oma tegelikku kasvu alates aastast 2015 ja näeme, et see on aastate jooksul lisanud rohkem filme kui telesaateid.
Huvitav on ka see, et 2020. aastal vähenes sisu lisamine. Selle põhjuseks võib olla pandeemia olukord.
Järgmisena uurime sisu täienduste jaotust erinevate kuude lõikes. See analüüs aitab meil tuvastada mustreid ja mõista, millal Netflix uut sisu tutvustab.
Sisu lisatud kuude kaupa
Selle uurimiseks eraldame veerust „lisamiskuupäev” kuu ja loendame iga kuu esinemised. Nende andmete tulpdiagrammina visualiseerimine võimaldab meil kiiresti tuvastada kõige suurema sisulisandiga kuud.
# Extract the month from the 'date_added' column
df['month_added'] = pd.to_datetime(df['date_added']).dt.month_name() # Define the order of the months
month_order = ['January', 'February', 'March', 'April', 'May', 'June', 'July', 'August', 'September', 'October', 'November', 'December'] # Count the number of shows added in each month
monthly_counts = df['month_added'].value_counts().loc[month_order] # Determine the maximum count
max_count = monthly_counts.max() # Set the color for the highest bar and the rest of the bars
colors = ['#b20710' if count == max_count else '#221f1f' for count in monthly_counts] # Create the bar chart
plt.figure(figsize=(16, 8))
bar_plot = sns.barplot(x=monthly_counts.index, y=monthly_counts.values, palette=colors) # Customize the plot
plt.xlabel('Month')
plt.ylabel('Count')
plt.title('Content Added by Month') # Add count values on top of each bar
for index, value in enumerate(monthly_counts.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') # Rotate x-axis labels for better readability
plt.xticks(rotation=45) # Show the plot
plt.show()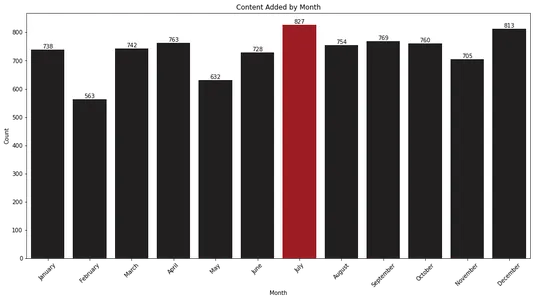
Lintdiagramm näitab, et juuli ja detsember on kuud, mil Netflix lisab oma teeki kõige rohkem sisu. See teave võib olla väärtuslik vaatajatele, kes soovivad nendel kuudel uusi väljalaseid oodata.
Teine Netflixi sisuanalüüsi oluline aspekt on reitingute jaotuse mõistmine. Uurides iga reitingukategooria arvu, saame kindlaks teha platvormil kõige levinumad sisutüübid.
Reitingute levitamine
Alustuseks arvutame iga reitingukategooria esinemissagedused ja visualiseerime need tulpdiagrammi abil. See visualiseerimine annab selge ülevaate hinnangute jaotusest.
# Count the occurrences of each rating
rating_counts = df['rating'].value_counts() # Create a bar chart to visualize the ratings
plt.figure(figsize=(16, 8))
colors = ['#b20710'] + ['#221f1f'] * (len(rating_counts) - 1)
sns.barplot(x=rating_counts.index, y=rating_counts.values, palette=colors) # Customize the plot
plt.xlabel('Rating')
plt.ylabel('Count')
plt.title('Distribution of Ratings') # Rotate x-axis labels for better readability
plt.xticks(rotation=45) # Show the plot
plt.show()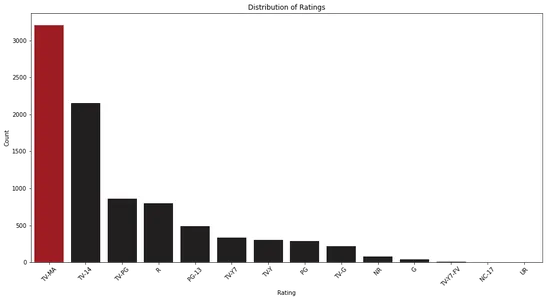
Lintdiagrammi analüüsimisel saame jälgida hinnangute jaotust Netflixis. See aitab meil tuvastada kõige levinumad reitingukategooriad ja nende suhteline sagedus.
Žanri korrelatsiooni soojuskaart
Žanrid mängivad Netflixi sisu kategoriseerimisel ja korraldamisel olulist rolli. Žanrite korrelatsiooni analüüsimine võib paljastada huvitavaid seoseid eri tüüpi sisu vahel.
Loome žanriandmete DataFrame'i, et uurida žanri korrelatsiooni ja täita see nullidega. Itereerides algse DataFrame'i iga rea, värskendame DataFrame'i žanriandmeid loetletud žanrite alusel. Seejärel loome nende žanriandmete abil korrelatsioonimaatriksi ja visualiseerime selle soojuskaardina.
# Extracting unique genres from the 'listed_in' column
genres = df['listed_in'].str.split(', ', expand=True).stack().unique() # Create a new DataFrame to store the genre data
genre_data = pd.DataFrame(index=genres, columns=genres, dtype=float) # Fill the genre data DataFrame with zeros
genre_data.fillna(0, inplace=True) # Iterate over each row in the original DataFrame and update the genre data DataFrame
for _, row in df.iterrows(): listed_in = row['listed_in'].split(', ') for genre1 in listed_in: for genre2 in listed_in: genre_data.at[genre1, genre2] += 1 # Create a correlation matrix using the genre data
correlation_matrix = genre_data.corr() # Create the heatmap
plt.figure(figsize=(20, 16))
sns.heatmap(correlation_matrix, annot=False, cmap='coolwarm') # Customize the plot
plt.title('Genre Correlation Heatmap')
plt.xticks(rotation=90)
plt.yticks(rotation=0) # Show the plot
plt.show()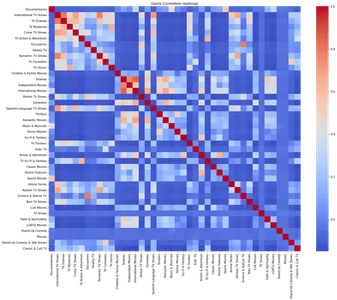
Kuumakaart näitab erinevate žanrite vahelist seost. Kuumakaarti analüüsides saame tuvastada tugevad positiivsed korrelatsioonid konkreetsete žanrite vahel, nagu teledraamad ja rahvusvahelised telesaated, romantilised telesaated ja rahvusvahelised telesaated.
Filmide pikkuste ja telesaadete osade arv
Filmide ja telesaadete kestuse mõistmine annab ülevaate sisu pikkusest ja aitab vaatajatel oma vaatamisaega planeerida. Filmide pikkuste ja telesaadete kestuste jaotust uurides saame paremini aru Netflixis saadaolevast sisust.
Selle saavutamiseks eraldame veerust „Kestus” filmide pikkused ja telesaadete osade arvud. Seejärel joonistame histogrammid ja kastigraafikud, et visualiseerida filmide pikkuste ja telesaadete kestuste jaotust.
# Extract the movie lengths and TV show episode counts
movie_lengths = df_movies['duration'].str.extract('(d+)', expand=False).astype(int)
tv_show_episodes = df_tv_shows['duration'].str.extract('(d+)', expand=False).astype(int) # Plot the histogram
plt.figure(figsize=(10, 6))
plt.hist(movie_lengths, bins=10, color='#b20710', label='Movies')
plt.hist(tv_show_episodes, bins=10, color='#221f1f', label='TV Shows') # Customize the plot
plt.xlabel('Duration/Episode Count')
plt.ylabel('Frequency')
plt.title('Distribution of Movie Lengths and TV Show Episode Counts')
plt.legend() # Show the plot
plt.show()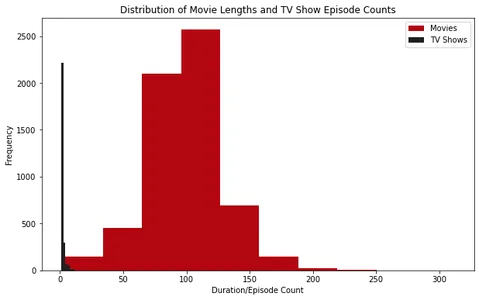
Histogramme analüüsides võime täheldada, et enamiku Netflixi filmide kestus on umbes 100 minutit. Teisest küljest on enamikul Netflixi telesaadetel ainult üks hooaeg.
Lisaks näeme kasti graafikuid uurides, et üle 2.5 tunni pikkuseid filme peetakse kõrvalekalleteks. Telesaadete puhul on haruldane leida neid, millel on rohkem kui neli hooaega.
Filmide/telesaadete pikkuste trend aastate jooksul
Saame joonistada joondiagramme, et mõista, kuidas filmide pikkused ja telesaadete osade arv on aastate jooksul muutunud. Sisu kestuse mustrite või muutuste tuvastamine neid suundumusi analüüsides.
Alustuseks eraldame veerust „Kestus” filmide pikkused ja telesaadete osade arvud. Seejärel loome joonised, et visualiseerida filmide pikkuste ja telesaadete episoodide muutusi aastate jooksul.
import seaborn as sns
import matplotlib.pyplot as plt # Extract the movie lengths and TV show episodes from the 'duration' column
movie_lengths = df_movies['duration'].str.extract('(d+)', expand=False).astype(int)
tv_show_episodes = df_tv_shows['duration'].str.extract('(d+)', expand=False).astype(int) # Create line plots for movie lengths and TV show episodes
plt.figure(figsize=(16, 8)) plt.subplot(2, 1, 1)
sns.lineplot(data=df_movies, x='release_year', y=movie_lengths, color=colors[0])
plt.xlabel('Release Year')
plt.ylabel('Movie Length')
plt.title('Trend of Movie Lengths Over the Years') plt.subplot(2, 1, 2)
sns.lineplot(data=df_tv_shows, x='release_year', y=tv_show_episodes,color=colors[1])
plt.xlabel('Release Year')
plt.ylabel('TV Show Episodes')
plt.title('Trend of TV Show Episodes Over the Years') # Adjust the layout and spacing
plt.tight_layout() # Show the plots
plt.show()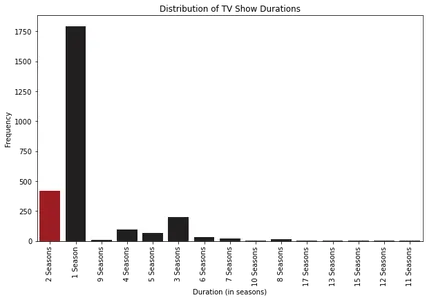
Joonekaarte analüüsides jälgime põnevaid mustreid. Näeme, et filmi pikkus kasvas algselt kuni umbes aastani 1963–1964 ja seejärel järk-järgult langes, stabiliseerudes keskmiselt 100 minuti ümber. See viitab vaatajaskonna eelistuste muutumisele aja jooksul.
Telesaadete episoodide osas oleme alates 2000. aastate algusest märganud püsivat trendi, kus enamikul Netflixi telesaadetel on üks kuni kolm hooaega. See näitab, et vaatajad eelistavad lühemaid seriaali või piiratud seeriaformaate.
Pealkirjades ja kirjeldustes levinumad sõnad
Pealkirjades ja kirjeldustes kõige levinumate sõnade analüüsimine võib anda ülevaate Netflixi teemadest ja sisust. Nende mustrite avastamiseks saame luua sõnapilvi Netflixi sisu pealkirjade ja kirjelduste põhjal.
from wordcloud import WordCloud # Concatenate all the titles into a single string
text = ' '.join(df['title']) wordcloud = WordCloud(width = 800, height = 800, background_color ='white', min_font_size = 10).generate(text) # plot the WordCloud image
plt.figure(figsize = (8, 8), facecolor = None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad = 0) plt.show() # Concatenate all the titles into a single string
text = ' '.join(df['description']) wordcloud = WordCloud(width = 800, height = 800, background_color ='white', min_font_size = 10).generate(text) # plot the WordCloud image
plt.figure(figsize = (8, 8), facecolor = None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad = 0) plt.show()
Uurides pealkirjade sõnapilve, näeme, et sageli kasutatakse selliseid termineid nagu "armastus", "tüdruk", "mees", "elu" ja "maailm", mis viitab romantilisele, täisealiseks saamisele ja draamale. žanrid Netflixi sisukogus.
Analüüsides kirjelduste jaoks sõnapilve, märkame domineerivaid sõnu, nagu "elu", "leida" ja "perekond", mis viitab Netflixi sisus levinud isiklike reiside, suhete ja perekonna dünaamika teemadele.
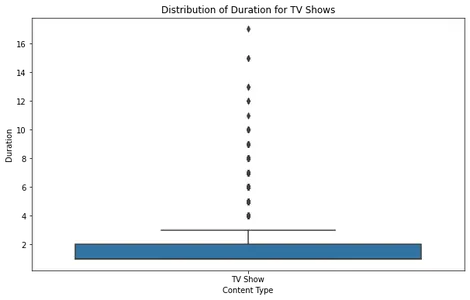
Filmide ja telesaadete kestus
Filmide ja telesaadete kestuse jaotuse analüüsimine võimaldab meil mõista Netflixis saadaoleva sisu tüüpilist pikkust. Nende jaotuste visualiseerimiseks ja kõrvalekallete või standardkestuse tuvastamiseks saame luua kastgraafikuid.
# Extracting and converting the duration for movies
df_movies['duration'] = df_movies['duration'].str.extract('(d+)', expand=False).astype(int) # Creating a boxplot for movie duration
plt.figure(figsize=(10, 6))
sns.boxplot(data=df_movies, x='type', y='duration')
plt.xlabel('Content Type')
plt.ylabel('Duration')
plt.title('Distribution of Duration for Movies')
plt.show() # Extracting and converting the duration for TV shows
df_tv_shows['duration'] = df_tv_shows['duration'].str.extract('(d+)', expand=False).astype(int) # Creating a boxplot for TV show duration
plt.figure(figsize=(10, 6))
sns.boxplot(data=df_tv_shows, x='type', y='duration')
plt.xlabel('Content Type')
plt.ylabel('Duration')
plt.title('Distribution of Duration for TV Shows')
plt.show()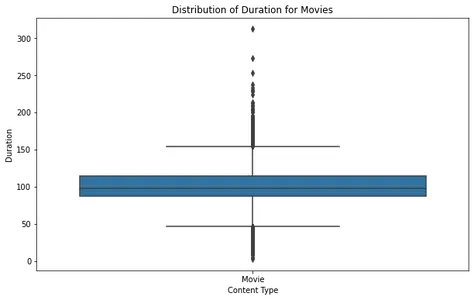
Filmi kasti süžeed analüüsides näeme, et enamik filme jääb mõistliku kestuse vahemikku, vähesed kõrvalekalded ületavad ligikaudu 2.5 tundi. See viitab sellele, et enamik Netflixi filme on loodud nii, et need mahuksid standardse vaatamisaja sisse.
Telesaadete puhul näitab kasti süžee, et enamikul saadetel on üks kuni neli hooaega ning väga vähestel kõrvalekalletel on pikem kestus. See ühtib varasemate suundumustega, mis näitab, et Netflix keskendub lühematele sarjavormingutele.
Järeldus
Selle artikli abil oleme saanud teada,
- Kogus: meie analüüs näitas, et Netflix oli lisanud rohkem filme kui telesaateid, mis on kooskõlas ootusega, et filmid domineerivad nende sisukogus.
- Sisu lisamine: Juuli tõusis kuuks, mil Netflix lisab kõige rohkem sisu, millele järgneb tihedalt detsember, mis näitab strateegilist lähenemist sisu avaldamisele.
- Žanri korrelatsioon: erinevate žanrite, nagu teledraamad ja rahvusvahelised telesaated, romantilised ja rahvusvahelised telesaated ning sõltumatud filmid ja draamad, vahel täheldati tugevaid positiivseid seoseid. Need korrelatsioonid annavad ülevaate vaatajate eelistustest ja sisu omavahelistest seostest.
- Filmi pikkused: filmide kestuste analüüs näitas haripunkti umbes 1960ndatel, millele järgnes umbes 100-minutiline stabiliseerumine, mis toob esile filmide pikkuste trendi ajas.
- Telesaadete jaod: enamikul Netflixi telesaadetel on üks hooaeg, mis viitab sellele, et vaatajad eelistavad lühemaid sarju.
- Levinud teemad: pealkirjades ja kirjeldustes leidus sageli selliseid sõnu nagu armastus, elu, perekond ja seiklus, jäädvustades Netflixi sisus korduvaid teemasid.
- Reitingute levitamine: hinnangute jaotus aastate jooksul annab ülevaate arenevast sisumaastikust ja vaatajaskonna vastuvõtust.
- Andmepõhised ülevaated: meie andmeanalüüsi teekond näitas andmete võimsust Netflixi sisumaastiku saladuste lahtiharutamisel, pakkudes vaatajatele ja sisuloojatele väärtuslikku teavet.
- Jätkuv asjakohasus: voogedastustööstuse arenedes muutub nende mustrite ja suundumuste mõistmine Netflixi ja selle tohutu raamatukogu dünaamilisel maastikul navigeerimiseks üha olulisemaks.
- Head voogesitust: loodame, et see ajaveeb on olnud valgustav ja meelelahutuslik teekond Netflixi maailma ning soovitame teil uurida põnevaid lugusid selle pidevalt muutuvas sisupakkumises. Laske andmetel oma voogesituse seiklusi juhtida!
Ametlik dokumentatsioon ja ressursid
Altpoolt leiate ametlikud lingid meie analüüsis kasutatud raamatukogudele. Nende teekide pakutavate meetodite ja funktsioonide kohta lisateabe saamiseks võite vaadata neid linke:
- Pandad: https://pandas.pydata.org/
- NumPy: https://numpy.org/
- matplotlib: https://matplotlib.org/
- SciPy: https://scipy.org/
- Seaborn: https://seaborn.pydata.org/
Selles artiklis näidatud meedia ei kuulu Analytics Vidhyale ja seda kasutatakse autori äranägemisel.
seotud
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- PlatoAiStream. Web3 andmete luure. Täiustatud teadmised. Juurdepääs siia.
- Tuleviku rahapaja Adryenn Ashley. Juurdepääs siia.
- Ostke ja müüge IPO-eelsete ettevõtete aktsiaid koos PREIPO®-ga. Juurdepääs siia.
- Allikas: https://www.analyticsvidhya.com/blog/2023/06/netflix-case-study-eda-unveiling-data-driven-strategies-for-streaming/
- :on
- :on
- :mitte
- : kus
- 1
- 10
- 100
- 12
- 20
- 2015
- 2020
- 2022
- 8
- 9
- a
- Võimalik
- MEIST
- küllus
- vastuvõtmine
- kättesaadavus
- täpne
- Saavutada
- üle
- osalejad
- lisama
- lisatud
- lisamine
- Täiendavad lisad
- täiendused
- aadress
- Lisab
- seiklus
- eesmärk
- Joondab
- Materjal: BPA ja flataatide vaba plastik
- Lubades
- võimaldab
- varitsenud
- vahel
- an
- analüüs
- analytics
- Analüütika Vidhya
- analüüsima
- analüüsides
- ja
- ennetada
- mistahes
- esinemised
- lähenemine
- umbes
- Aprill
- OLEME
- PIIRKOND
- ümber
- artikkel
- AS
- aspekt
- aspektid
- ühendused
- At
- atribuudid
- publik
- AUGUST
- kättesaadavus
- saadaval
- keskmine
- vältima
- tagasi
- baar
- baarid
- baas
- põhineb
- BE
- muutuma
- muutub
- olnud
- alustama
- Algus
- alla
- Parem
- vahel
- erapoolikus
- Blogi
- põhi
- Kast
- by
- arvutama
- arvutamisel
- CAN
- võimeid
- köitev
- Püüdmine
- juhul
- juhtumiuuring
- kategooriad
- kategoriseerimine
- Kategooria
- keskus
- Vaidluste lahendamine
- omadused
- Joonis
- Äritegevus
- kontroll
- Hiina
- valikuid
- selge
- lähedalt
- Cloud
- kood
- kogumine
- värv
- Veerg
- Veerud
- ühine
- tavaliselt
- ettevõte
- lõpetamist
- terviklik
- arvutustehnika
- kaaluda
- järjepidev
- koosneb
- tarbima
- sisu
- sisu loojad
- Sisutüübid
- konversioonid
- muutma
- konverteeriva
- Korrelatsioon
- korrelatsioonid
- võiks
- riikides
- riik
- looma
- loodud
- loomine
- loojad
- otsustav
- kohandada
- andmed
- andmete analüüs
- andmete kadu
- Andmete ettevalmistamine
- andmeteadus
- andmete visualiseerimine
- andmepõhistele
- Andmepõhine strateegia
- kuupäev Kellaaeg
- Detsember
- sügav
- näitab
- kirjeldama
- kirjeldus
- kavandatud
- üksikasjalik
- Määrama
- kõrvalekalle
- erinev
- suunatud
- Juhataja
- Direktorid
- äranägemisel
- väljapanek
- Näidikute
- jaotus
- Väljamaksed
- mitu
- Mitmekesine publik
- dokumentatsioon
- domineeriv
- domineerima
- Draama
- Drop
- langes
- Kukkumine
- kaks
- duplikaadid
- kestus
- ajal
- dünaamiline
- dünaamika
- iga
- Ajalugu
- Varajane
- ökosüsteemi
- tõhusalt
- jõupingutusi
- teine
- asuma
- tekkinud
- võimaldama
- võimaldab
- julgustama
- suurendama
- tõhustatud
- tagama
- tagades
- lõbus
- meelelahutus
- entusiastid
- episood
- Episodes
- oluline
- asutatud
- Eeter (ETH)
- Isegi
- pidevalt muutuv
- Iga
- arenenud
- areneb
- areneb
- Uurimine
- põnev
- välja arvatud
- laiendatud
- laiendades
- laiendamine
- ootus
- kogenud
- uurimine
- uurima
- uurib
- Avastades
- väljavõte
- Langema
- pere
- Veebruar
- vähe
- arvandmed
- fail
- täitma
- Film
- filmid
- filtreerida
- leidma
- leidmine
- esimene
- sobima
- Keskenduma
- keskendub
- Järgneb
- Järel
- eest
- Sundida
- formaat
- avastatud
- Sihtasutus
- neli
- Sagedus
- sageli
- värske
- Alates
- funktsioon
- funktsionaalsused
- funktsioonid
- edasi
- kasu
- tekitama
- saama
- Globaalne
- ülemaailmne kohalolek
- Ülemaailmselt
- Go
- järk-järgult
- Grupp
- Kasv
- suunata
- olnud
- käsi
- käepide
- Käsitsemine
- Olema
- võttes
- kõrgus
- aitama
- aitab
- siin
- varjatud
- kõrgeim
- esiletõstmine
- takistama
- lootus
- Lahtiolekuajad
- Kuidas
- HTTPS
- ID
- identifitseerima
- identifitseerimiseks
- if
- illustreerib
- pilt
- mõju
- import
- importivate
- muljetavaldav
- in
- sisaldama
- kasvanud
- üha rohkem
- sõltumatud
- indeks
- osutatud
- näitab
- tööstus
- info
- esialgne
- esialgu
- teadmisi
- terviklikkuse
- huvitav
- rahvusvaheliselt
- sisse
- intrigeeriv
- Tutvustab
- uurima
- seotud
- küsimustes
- IT
- ITS
- Jaanuar
- teekond
- Reisid
- Juuli
- juuni
- Korea
- Labels
- maastik
- Keeled
- kihid
- Layout
- juhtivate
- Õppida
- õppimine
- Pikkus
- Tase
- võimendav
- raamatukogud
- Raamatukogu
- elu
- valgus
- nagu
- piiratud
- joon
- liinid
- lingid
- Loetletud
- koormus
- laadimine
- enam
- Vaata
- kaotus
- armastus
- masin
- masinõpe
- tehtud
- säilitada
- Manipuleerimine
- Märts
- matplotlib
- maatriks
- maksimaalne
- mai..
- keskmine
- Meedia
- meetodid
- miljon
- minimeerima
- miinimum
- protokoll
- puuduvad
- viis
- kuu
- kuu
- rohkem
- kõige
- film
- Filmid
- nimi
- navigeerimine
- vajalik
- vaja
- Netflix
- Uus
- järgmine
- ei
- põhja-
- Põhja-Korea
- märkimisväärne
- Märka..
- November
- number
- tuim
- jälgima
- saamine
- esineb
- oktoober
- of
- maha
- pakkumine
- Pakkumised
- Pakkumised
- ametlik
- on
- ONE
- ainult
- Operations
- or
- et
- korraldamine
- originaal
- Muu
- meie
- üle
- üldine
- ülevaade
- omanikuks
- pad
- pandas
- pandeemia
- osa
- mustrid
- tipp
- protsent
- täitma
- isiklik
- perspektiiv
- kava
- inimesele
- Platvormid
- Platon
- Platoni andmete intelligentsus
- PlatoData
- mängima
- populaarne
- populaarsus
- positiivne
- potentsiaal
- võim
- eelistusi
- ettevalmistamine
- olemasolu
- levinud
- anda
- tingimusel
- annab
- pakkudes
- avalikult
- avaldatud
- Kvartal
- kiiresti
- valik
- hinnang
- hinnangust
- valmis
- reaalne
- mõistlik
- vastuvõtt
- andmed
- korduv
- Suhted
- suhteline
- vabastama
- Pressiteated
- asjakohasus
- ülejäänud
- tähelepanuväärne
- kõrvaldama
- asendama
- esindab
- REST
- Tulemused
- avalduma
- Revealed
- Ilmutab
- revolutsiooniliselt
- õige
- Roll
- ROW
- Venemaa
- teadus
- meres sündinud
- hooaeg
- hooajaline
- hooaega
- Teine
- teises kvartalis
- Osa
- vaata
- tundub
- eri
- eraldi
- September
- Seeria
- komplekt
- suunata
- Vahetused
- näitama
- presentatsioon
- tutvustatud
- näidatud
- Näitused
- märkimisväärne
- alates
- ühekordne
- olukord
- So
- mõned
- hangitud
- tühikud
- konkreetse
- jagada
- standard
- algus
- Käivitus
- Ühendriigid
- statistika
- Samm
- Sammud
- salvestada
- ladustatud
- Lood
- Strateegiline
- strateegiline lähenemine
- strateegiad
- Strateegia
- streaming
- nöör
- tugev
- struktuur
- Uuring
- subtiitrid
- Edukalt
- selline
- Soovitab
- sobivus
- KOKKUVÕTE
- Süüria
- tabel
- ülesanded
- tingimused
- kui
- et
- .
- Piirkond
- maailm
- oma
- Neile
- SIIS
- Need
- nad
- see
- need
- kolm
- Läbi
- aeg
- Kapslid
- pealkirjaga
- pealkirjad
- et
- töövahendid
- ülemine
- Top 10
- Muutma
- Transformation
- ümber
- Trend
- Trends
- tv
- telesaade
- tüüp
- liigid
- tüüpiline
- Aeg-ajalt
- paljastama
- all
- rõhutama
- mõistma
- mõistmine
- ainulaadne
- Ühendatud
- Ühendriigid
- Universum
- kuni
- avamine
- Värskendused
- us
- kasutama
- Kasutatud
- kasutamine
- väärtuslik
- Väärtuslik teave
- väärtus
- Väärtused
- eri
- suur
- väga
- Vaatajad
- vaatamine
- visualiseerimine
- visualiseeri
- tahan
- oli
- vaadates
- we
- webp
- olid
- millal
- kuigi
- valge
- WHO
- laialt levinud
- will
- koos
- jooksul
- sõna
- sõnad
- maailm
- ülemaailmne
- X
- aasta
- aastat
- sa
- Sinu
- sephyrnet