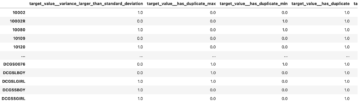
Arvutinägemises on semantiline segmenteerimine ülesanne klassifitseerida pildil kõik pikslid teadaolevate siltide komplekti kuuluvate klassidega, nii et sama sildiga pikslitel on teatud omadused. See loob sisendpiltide segmenteerimismaski. Näiteks järgmistel piltidel on näidatud segmendimask cat silt.
 |
 |
Novembris 2018 Amazon SageMaker teatas semantilise segmenteerimisalgoritmi SageMaker käivitamisest. Selle algoritmi abil saate koolitada oma mudeleid avaliku andmestiku või oma andmekogumiga. Populaarsed kujutiste segmenteerimise andmestikud hõlmavad andmekogumit Common Objects in Context (COCO) ja PASCALi visuaalseid objektide klasse (PASCAL VOC), kuid nende siltide klassid on piiratud ja võite soovida koolitada mudelit sihtobjektide jaoks, mis ei sisaldu avalikud andmestikud. Sel juhul võite kasutada Amazon SageMaker Ground Truth oma andmestiku märgistamiseks.
Selles postituses näitan järgmisi lahendusi:
- Ground Truthi kasutamine semantilise segmenteerimise andmestiku märgistamiseks
- Ground Truthi tulemuste teisendamine SageMakeri sisseehitatud semantilise segmenteerimisalgoritmi jaoks vajalikuks sisendvorminguks
- Semantilise segmenteerimisalgoritmi kasutamine mudeli treenimiseks ja järelduste tegemiseks
Semantilise segmenteerimise andmete märgistamine
Semantilise segmenteerimise masinõppemudeli koostamiseks peame andmestiku piksli tasemel märgistama. Ground Truth annab teile võimaluse kasutada inimeste annotaatoreid Amazon Mehaaniline Türk, kolmandatest osapooltest müüjad või teie isiklik tööjõud. Tööjõu kohta lisateabe saamiseks vaadake Looge ja hallake tööjõudu. Kui te ei soovi märgistamise tööjõudu ise hallata, Amazon SageMaker Ground Truth Plus on veel üks suurepärane võimalus uue käivitusvalmis andmesilditeenusena, mis võimaldab teil kiiresti luua kvaliteetseid treeningandmekogumeid ja vähendab kulusid kuni 40%. Selle postituse jaoks näitan teile, kuidas andmestikku käsitsi Ground Truthi automaatse segmenteerimise funktsiooniga ja ühisallika märgistamist mehaanilise türklaste tööjõuga.
Käsitsi märgistamine Ground Truthiga
2019. aasta detsembris lisas Ground Truth semantilise segmenteerimise sildistamise kasutajaliidesele automaatse segmenteerimise funktsiooni, et suurendada märgistamise läbilaskevõimet ja parandada täpsust. Lisateabe saamiseks vaadake Objektide automaatne segmentimine semantilise segmenteerimise sildistamise ajal rakendusega Amazon SageMaker Ground Truth. Selle uue funktsiooniga saate kiirendada segmenteerimistoimingute märgistamisprotsessi. Selle asemel, et joonistada tihedalt liibuvat hulknurka või kasutada objekti pildil jäädvustamiseks pintslitööriista, joonistate ainult neli punkti: objekti kõige ülemisse, alumisse, vasakpoolsesse ja parempoolseimasse punkti. Ground Truth võtab need neli punkti sisendiks ja kasutab Deep Extreme Cut (DEXTR) algoritmi, et luua objekti ümber tihedalt liibuv mask. Õpetust Ground Truthi kasutamise kohta kujutise semantilise segmenteerimise märgistamiseks vt Pildi semantiline segmenteerimine. Järgnev on näide sellest, kuidas automaatse segmenteerimise tööriist genereerib segmenteerimismaski automaatselt pärast seda, kui olete valinud objekti neli äärmist punkti.


Crowdsourcing märgistamine koos mehaanilise türklase tööjõuga
Kui teil on suur andmestik ja te ei soovi ise sadu või tuhandeid pilte käsitsi sildistada, saate kasutada Mechanical Turki, mis pakub nõudmisel skaleeritavat inimtööjõudu, et täita töid, mida inimesed saavad arvutist paremini teha. Mehhaaniline Turk tarkvara vormistab tööpakkumised tuhandetele töötajatele, kes soovivad teha neile sobival ajal tükitööd. Tarkvara otsib ka tehtud tööd ja koostab selle teile, tellijale, kes maksab töötajatele (ainult) rahuldava töö eest. Mehhaanilise Turki kasutamise alustamiseks vaadake Amazon Mechanical Turki tutvustus.
Looge märgistamistöö
Järgmine on näide merikilpkonnade andmestiku Mechanical Turk märgistamistööst. Merikilpkonnade andmestik pärineb võistlusest Kaggle Merikilpkonna näotuvastusja valisin demonstratsiooni eesmärgil andmekogumist 300 pilti. Merikilpkonn ei ole avalikes andmekogumites tavaline klass, nii et see võib kujutada endast olukorda, mis nõuab tohutu andmestiku märgistamist.
- Valige SageMakeri konsoolil Märgistustööd navigeerimispaanil.
- Vali Loo märgistustöö.
- Sisestage oma töö nimi.
- eest Sisendandmete seadistaminevalige Automatiseeritud andmete seadistamine.
See loob sisendandmete manifesti. - eest S3 asukoht sisendandmete kogumitele, sisestage andmestiku tee.

- eest Ülesande kategooria, vali pilt.
- eest Ülesande valikvalige Semantiline segmenteerimine.

- eest Töötajate tüübidvalige Amazon Mehaaniline Türk.
- Konfigureerige oma seaded ülesande ajalõpu, ülesande aegumisaja ja ülesande hinna jaoks.

- Lisa silt (selle postituse jaoks
sea turtle) ja esitage märgistamisjuhised. - Vali Looma.

Pärast märgistamistöö seadistamist saate SageMakeri konsoolis kontrollida märgistamise edenemist. Kui töö on märgitud lõpetatuks, saate tulemuste kontrollimiseks valida töö ja kasutada neid järgmisteks sammudeks.

Andmestiku teisendus
Pärast Ground Truthi väljundi saamist saate selle andmestiku mudeli koolitamiseks kasutada SageMakeri sisseehitatud algoritme. Esiteks peate valmistama märgistatud andmestiku SageMakeri semantilise segmenteerimisalgoritmi nõutud sisendliideseks.
Nõutud sisendandmekanalid
SageMakeri semantiline segmenteerimine eeldab, et teie treeninguandmed salvestatakse Amazoni lihtne salvestusteenus (Amazon S3). Eeldatakse, et Amazon S3 andmestik esitatakse kahes kanalis, millest üks train ja üks validation, kasutades nelja kataloogi, kaks piltide jaoks ja kaks annotatsioonide jaoks. Märkused peaksid olema tihendamata PNG-kujutised. Andmestikul võib olla ka sildikaart, mis kirjeldab, kuidas annotatsiooni vastendused luuakse. Kui ei, kasutab algoritm vaikeväärtust. Järelduste tegemiseks aktsepteerib lõpp-punkt kujutisi, millel on an image/jpeg sisu tüüp. Andmekanalite nõutav struktuur on järgmine:
Igal rongi- ja valideerimiskataloogi JPG-pildil on vastav PNG-sildi kujutis, millel on sama nimi train_annotation ja validation_annotation kataloogid. See nimetamisviis aitab algoritmil seostada sildi treeningu ajal vastava kujutisega. Rongi, train_annotation, valideerimine ja validation_annotation kanalid on kohustuslikud. Märkused on ühe kanaliga PNG-kujutised. Vorming töötab seni, kuni pildi metaandmed (režiimid) aitavad algoritmil lugeda annotatsioonipilte ühe kanaliga 8-bitiseks märgita täisarvuks.
Ground Truthi märgistamistöö väljund
Ground Truthi märgistustööst genereeritud väljunditel on järgmine kaustastruktuur:
Segmenteerimismaskid salvestatakse s3://turtle2022/labelturtles/annotations/consolidated-annotation/output. Iga annotatsioonipilt on .png-fail, mille nimi on lähtekujutise indeksi ja selle pildi sildistamise lõpetamise aja järgi. Näiteks on järgmised lähtekujutis (Image_1.jpg) ja selle segmenteerimismask, mille on loonud Mechanical Turk tööjõud (0_2022-02-10T17:41:04.724225.png). Pange tähele, et maski indeks erineb lähtekujutise nimes olevast numbrist.
 |
 |
Märgistustöö väljundmanifest asub failis /manifests/output/output.manifest faili. See on JSON-fail ja iga rida salvestab lähtepildi ja selle sildi ning muude metaandmete vahelise vastenduse. Järgmine JSON-rida salvestab kuvatava lähtepildi ja selle märkuse vahelise vastenduse:
Lähtekujutise nimi on Image_1.jpg ja märkuse nimi on 0_2022-02-10T17:41: 04.724225.png. Andmete ettevalmistamiseks semantilise segmenteerimise algoritmi SageMaker nõutavate andmekanalivormingutena peame muutma annotatsiooni nime nii, et sellel oleks sama nimi, mis lähte-JPG-piltidel. Ja me peame ka andmestiku jagama train ja validation lähtepiltide ja annotatsioonide kataloogid.
Teisendage Ground Truthi märgistustöö väljund soovitud sisendvormingusse
Väljundi teisendamiseks toimige järgmiselt.
- Laadige kõik sildistamistöö failid Amazon S3-st alla kohalikku kataloogi:
- Lugege manifesti faili ja muutke annotatsiooni nimed samadeks, mis lähtekujutistel:
- Jagage rong ja valideerimisandmed:
- Tehke semantilise segmenteerimise algoritmi andmekanalite jaoks vajalikus vormingus kataloog:
- Liigutage rongi- ja valideerimiskujutised ning nende annotatsioonid loodud kataloogidesse.
- Piltide jaoks kasutage järgmist koodi:
- Märkuste jaoks kasutage järgmist koodi:
- Laadige rongi- ja valideerimisandmed ning nende annotatsiooniandmed Amazon S3 üles:
SageMaker semantilise segmenteerimise mudeli koolitus
Selles jaotises käsitleme teie semantilise segmenteerimismudeli treenimise samme.
Järgige näidismärkmikku ja seadistage andmekanalid
Saate järgida juhiseid Semantilise segmenteerimise algoritm on nüüd saadaval Amazon SageMakeris semantilise segmenteerimise algoritmi juurutamiseks oma märgistatud andmekogumis. See proov märkmik näitab algoritmi tutvustavat otsast lõpuni näidet. Märkmikus saate teada, kuidas õpetada ja hostida semantilist segmenteerimismudelit, kasutades täielikult konvolutsioonivõrku (FCN) algoritmi kasutades Pascali VOC andmestik koolituse jaoks. Kuna ma ei kavatse Pascali lenduvate orgaaniliste ühendite andmestikust mudelit koolitada, jätsin selle märkmiku 3. sammu (andmete ettevalmistamine) vahele. Selle asemel lõin otse train_channel, train_annotation_channe, validation_channelja validation_annotation_channel kasutades S3 asukohti, kuhu ma oma pilte ja märkusi salvestasin:
Reguleerige SageMakeri hinnangus oma andmekogumi hüperparameetreid
Jälgisin märkmikku ja lõin SageMakeri hinnanguobjekti (ss_estimator), et treenida segmenteerimisalgoritmi. Üks asi, mida peame uue andmestiku jaoks kohandama, on sees ss_estimator.set_hyperparameters: me peame muutma num_classes=21 et num_classes=2 (turtle ja background) ja ka mina muutsin epochs=10 et epochs=30 sest 10 on ainult demo jaoks. Seejärel kasutasin p3.2xlarge eksemplari mudelitreeninguks seadistamise teel instance_type="ml.p3.2xlarge". Treening läbis 8 minutiga. Parim MIoU (keskmine ristmik liidu kohal) 0.846 saavutatakse 11. epohhil pix_acc (teie pildi pikslite protsent, mis on õigesti klassifitseeritud) 0.925, mis on selle väikese andmestiku kohta päris hea tulemus.
Mudeli järelduste tulemused
Hostisin mudelit odavas ml.c5.xlarge eksemplaris:
Lõpuks valmistasin ette 10 kilpkonna kujutise testikomplekti, et näha treenitud segmenteerimismudeli järeldustulemust:
Järgmised pildid näitavad tulemusi.

Merikilpkonnade segmenteerimismaskid näevad välja täpsed ja ma olen rahul selle tulemusega, mis on saadud Mechanical Turki töötajate märgistatud 300-pildilisest andmekogumist. Samuti saate uurida teisi saadaolevaid võrke, näiteks püramiid-stseeni sõelumisvõrk (PSP) or DeepLab-V3 oma andmestikuga näidismärkmikusse.
Koristage
Kustutage lõpp-punkt, kui olete sellega lõpetanud, et vältida jätkuvaid kulusid.
Järeldus
Selles postituses näitasin, kuidas kohandada semantilise segmenteerimise andmete märgistamist ja mudelikoolitust SageMakeri abil. Esiteks saate seadistada märgistamistöö automaatse segmenteerimise tööriistaga või kasutada mehaanilist Turki tööjõudu (nagu ka muid valikuid). Kui teil on üle 5,000 objekti, saate kasutada ka automaatset andmemärgistust. Seejärel teisendate oma Ground Truthi märgistustöö väljundid SageMakeri sisseehitatud semantilise segmenteerimise koolituse jaoks vajalikeks sisendvorminguteks. Pärast seda saate kasutada kiirendatud andmetöötluseksemplari (nt p2 või p3), et koolitada semantilise segmenteerimise mudelit järgmisega märkmik ja juurutage mudel kuluefektiivsemasse eksemplari (nt ml.c5.xlarge). Lõpuks saate mõne koodirea abil üle vaadata oma testiandmestiku järeldustulemused.
Alustage SageMakeri semantilise segmenteerimisega andmete märgistamine ja mudelkoolitus oma lemmikandmestikuga!
Teave Autor
 Kara Yang on AWS-i professionaalsete teenuste andmeteadlane. Ta on kirglik aidata klientidel AWS-i pilveteenustega nende ärieesmärke saavutada. Ta on aidanud organisatsioonidel luua ML-lahendusi mitmetes tööstusharudes, nagu tootmine, autotööstus, keskkonnasäästlikkus ja kosmosetööstus.
Kara Yang on AWS-i professionaalsete teenuste andmeteadlane. Ta on kirglik aidata klientidel AWS-i pilveteenustega nende ärieesmärke saavutada. Ta on aidanud organisatsioonidel luua ML-lahendusi mitmetes tööstusharudes, nagu tootmine, autotööstus, keskkonnasäästlikkus ja kosmosetööstus.
- Münditark. Euroopa parim Bitcoini ja krüptobörs.
- Platoblockchain. Web3 metaversiooni intelligentsus. Täiustatud teadmised. TASUTA PÄÄS.
- CryptoHawk. Altcoini radar. Tasuta prooviversioon.
- Allikas: https://aws.amazon.com/blogs/machine-learning/semantic-segmentation-data-labeling-and-model-training-using-amazon-sagemaker/
- '
- "
- 000
- 10
- 100
- 11
- 2019
- a
- MEIST
- kiirendama
- kiirendatud
- täpne
- Saavutada
- saavutada
- üle
- lisatud
- Aerospace
- algoritm
- algoritme
- Materjal: BPA ja flataatide vaba plastik
- Amazon
- teatas
- Teine
- ümber
- Partner
- Automatiseeritud
- automaatselt
- auto
- saadaval
- AWS
- tagapõhi
- sest
- BEST
- Parem
- vahel
- ehitama
- sisseehitatud
- äri
- lüüa
- juhul
- kindel
- muutma
- kanalid
- Vali
- klass
- klassid
- salastatud
- Cloud
- pilvteenustest
- kood
- ühine
- konkurents
- täitma
- arvuti
- arvutid
- arvutustehnika
- usaldus
- konsool
- sisu
- mugavus
- Vastav
- kuluefektiivne
- kulud
- looma
- loodud
- Kliendid
- kohandada
- andmed
- andmeteadlane
- sügav
- näitama
- juurutada
- erinev
- otse
- joonistus
- ajal
- iga
- võimaldab
- Lõpuks-lõpuni
- Lõpp-punkt
- sisene
- keskkonna-
- asutatud
- näide
- Välja arvatud
- oodatav
- ootab
- uurima
- äärmuslik
- nägu
- tunnusjoon
- esimene
- järgima
- Järel
- formaat
- Alates
- loodud
- Eesmärgid
- hea
- hall
- suur
- õnnelik
- aitas
- aidates
- aitab
- kvaliteetne
- võõrustas
- Kuidas
- Kuidas
- HTTPS
- inim-
- Inimestel
- sajad
- pilt
- pildid
- rakendada
- parandama
- sisaldama
- lisatud
- Suurendama
- indeks
- tööstusharudes
- info
- sisend
- Näiteks
- Interface
- ristmik
- sisse
- IT
- töö
- Tööturg
- teatud
- silt
- märgistamine
- Labels
- suur
- algatama
- Õppida
- õppimine
- Tase
- piiratud
- joon
- liinid
- nimekiri
- kohalik
- liising
- kohad
- Pikk
- Vaata
- masin
- masinõpe
- juhtima
- kohustuslik
- käsitsi
- tootmine
- kaart
- kaardistus
- mask
- Maskid
- suur
- mehaaniline
- võib
- ML
- mudel
- mudelid
- rohkem
- mitmekordne
- nimed
- nimetamine
- NAVIGATSIOON
- võrk
- võrgustikud
- järgmine
- märkmik
- number
- Pakkumised
- valik
- Valikud
- organisatsioonid
- Muu
- enda
- kirglik
- protsent
- esitades
- võrra
- hulknurk
- populaarne
- Valmistama
- ilus
- hind
- era-
- protsess
- tootma
- professionaalne
- anda
- annab
- avalik
- eesmärkidel
- kiiresti
- RE
- andmed
- esindama
- nõutav
- Vajab
- Tulemused
- läbi
- sama
- skaalautuvia
- teadlane
- SEA
- segmentatsioon
- väljavalitud
- teenus
- Teenused
- komplekt
- kehtestamine
- Jaga
- näitama
- näidatud
- lihtne
- olukord
- väike
- So
- tarkvara
- Lahendused
- jagada
- alustatud
- ladustamine
- Jätkusuutlikkus
- sihtmärk
- ülesanded
- meeskond
- test
- .
- Allikas
- asi
- kolmanda osapoole
- tuhandeid
- Läbi
- läbilaskevõime
- aeg
- tööriist
- Rong
- koolitus
- Muutma
- liit
- kasutama
- kinnitamine
- müüjad
- nägemus
- WHO
- Töö
- töötajate
- Tööjõud
- töötab
- Sinu