Apache Jäämägi on avatud tabelivorming väga suurte analüütiliste andmekogumite jaoks, mis salvestab metaandmete teabe andmekogumite oleku kohta, kui need aja jooksul arenevad ja muutuvad. See lisab tabeleid arvutusmootoritele, sealhulgas Spark, Trino, PrestoDB, Flink ja Hive, kasutades suure jõudlusega tabelivormingut, mis töötab täpselt nagu SQL-tabel. Iceberg on muutunud väga populaarseks tänu oma ACID-tehingute toetamisele andmejärvedes ja funktsioonide, nagu skeemide ja partitsioonide arendamine, ajarännak ja tagasipööramine, tõttu.
Apache Icebergi integreerimist toetavad AWS-i analüüsiteenused, sealhulgas Amazon EMR, Amazonase Athenaja AWS liim. Amazon EMR saab varustada klastreid Sparki, Hive'i, Trino ja Flinkiga, mis suudavad käitada Icebergi. Alates Amazon EMR versioonist 6.5.0 saate seda teha kasutage oma EMR-klastriga Icebergi ilma alglaadimistoimingut nõudmata. 2022. aasta alguses teatas AWS Apache Icebergi toiteallika Athena ACID tehingute üldisest kättesaadavusest. Hiljuti vabastatud Athena päringumootori versioon 3 pakub paremat integratsiooni Icebergi tabelivorminguga. AWS Glue 3.0 ja uuemad toetab Apache Icebergi raamistikku andmejärvede jaoks.
Selles postituses arutleme, mida kliendid kaasaegsetelt andmejärvedelt soovivad ja kuidas Apache Iceberg aitab klientide vajadusi rahuldada. Seejärel tutvume lahendusega, mille abil ehitada suure jõudlusega ja arenev Icebergi andmejärv Amazoni lihtne salvestusteenus (Amazon S3) ja töödelda lisaandmeid, käivitades SQL-lausete lisamise, värskendamise ja kustutamise. Lõpuks näitame teile, kuidas protsessi jõudlust reguleerida, et parandada lugemise ja kirjutamise jõudlust.
Kuidas Apache Iceberg tegeleb sellega, mida kliendid tänapäevastes andmejärvedes soovivad
Üha enam kliente loob struktureeritud ja struktureerimata andmetega andmejärvesid, et toetada paljusid kasutajaid, rakendusi ja analüüsitööriistu. Suurenenud on vajadus andmejärvede järele, et toetada selliseid andmebaase nagu ACID-tehingud, rekordtasemel värskendused ja kustutamised, ajarännakud ja tagasipööramine. Apache Iceberg on loodud toetama neid funktsioone Amazon S3 kuluefektiivsetes petabaitide skaala andmejärvedes.
Apache Iceberg tegeleb klientide vajadustega, püüdes üksikute andmefailide loomise ajal andmestiku kohta rikkalikku metaandmeid. Icebergi tabeli arhitektuuris on kolm kihti: Icebergi kataloog, metaandmete kiht ja andmekiht, nagu on kujutatud järgmisel joonisel (allikas).

Icebergi kataloog salvestab metaandmete osuti praegusele tabeli metaandmete failile. Kui valitud päring loeb Icebergi tabelit, läheb päringumootor esmalt Icebergi kataloogi, seejärel hangib praeguse metaandmete faili asukoha. Iga kord, kui Icebergi tabelit värskendatakse, luuakse tabelist uus hetktõmmis ja metaandmete osuti osutab praegusele tabeli metaandmete failile.
Järgmine on Icebergi kataloogi näide koos AWS-liimi rakendamisega. Näete andmebaasi nime, jäämäe tabeli asukohta (S3 tee) ja metaandmete asukohta.

Metaandmete kihil on kolme tüüpi faile: metaandmete fail, manifesti loend ja manifesti fail hierarhias. Hierarhia ülaosas on metaandmete fail, mis salvestab teavet tabeli skeemi, partitsiooniteabe ja hetktõmmiste kohta. Hetktõmmis osutab manifesti loendile. Manifestiloendis on teave iga hetktõmmise moodustava manifestifaili kohta, näiteks manifestifaili asukoht, partitsioonid, kuhu see kuulub, ning jälgitavate andmefailide partitsiooniveergude alumine ja ülemine piir. Manifestifail jälgib andmefaile ja iga faili kohta täiendavaid üksikasju, näiteks failivormingut. Kõik kolm faili töötavad hierarhias, et jälgida jäämäe tabelis olevaid hetktõmmiseid, skeemi, jaotust, atribuute ja andmefaile.
Andmekihil on Icebergi tabeli üksikud andmefailid. Iceberg toetab laias valikus failivorminguid, sealhulgas Parquet, ORC ja Avro. Kuna tabel Iceberg jälgib üksikuid andmefaile, selle asemel, et osutada andmefailidega ainult partitsiooni asukohale, isoleerib see kirjutamistoimingud lugemistoimingutest. Saate andmefaile igal ajal kirjutada, kuid muudatuse tuleb teha ainult selgesõnaliselt, mis loob hetktõmmise ja metaandmefailide uue versiooni.
Lahenduse ülevaade
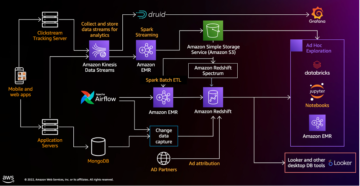
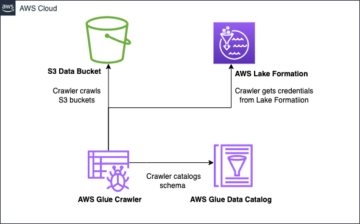
Selles postituses tutvustame teile lahendust suure jõudlusega Apache Icebergi andmejärve ehitamiseks Amazon S3-le; töödelda lisaandmeid SQL-lausete lisamise, värskendamise ja kustutamisega; ja häälestage Iceberg tabelit, et parandada lugemise ja kirjutamise jõudlust. Järgnev diagramm illustreerib lahenduse arhitektuuri.

Selle lahenduse demonstreerimiseks kasutame Amazoni klientide ülevaated andmestik S3 ämbris (s3://amazon-reviews-pds/parquet/). Reaalsel kasutamisel oleksid need teie S3 ämbrisse salvestatud töötlemata andmed. Saame kontrollida andmete suurust järgmise koodiga AWS-i käsurea liides (AWS CLI):
Objektide koguarv on 430 ja kogumaht 47.4 GiB.
Selle lahenduse seadistamiseks ja testimiseks teeme järgmised kõrgetasemelised sammud.
- Seadistage kureeritud tsoonis S3 ämber, et salvestada konverteeritud andmed Icebergi tabelivormingus.
- Käivitage Apache Icebergi jaoks sobivate konfiguratsioonidega EMR-klaster.
- Looge EMR Studios märkmik.
- Seadistage Sparki seanss Apache Icebergi jaoks.
- Teisendage andmed Icebergi tabelivormingusse ja teisaldage andmed kureeritud tsooni.
- Käivitage lisaandmete töötlemiseks Athenas sisestus-, värskendamis- ja kustutamispäringuid.
- Viige läbi jõudluse häälestamine.
Eeldused
Selle juhendi järgimiseks peab teil olema AWS-i konto koos AWS-i identiteedi- ja juurdepääsuhaldus (IAM) roll, millel on piisav juurdepääs vajalike ressursside varustamiseks.
Seadistage oma andmejärve kureeritud tsoonis Icebergi andmete jaoks S3-salv
Valige piirkond, kus soovite S3 ämbri luua, ja andke kordumatu nimi:
Käivitage EMR-klaster, et käitada Sparki kasutades Icebergi töid
Saate luua EMR-klastri AWS-i juhtimiskonsool, Amazon EMR CLI või AWS pilvearenduskomplekt (AWS CDK). Selle postituse jaoks tutvustame teile, kuidas luua konsoolist EMR-klastrit.
- Valige Amazon EMR-i konsoolil Loo klaster.
- Vali Lisavalikud.
- eest Tarkvara konfigureerimine, valige uusim Amazon EMR-i väljalase. 2023. aasta jaanuari seisuga on uusim versioon 6.9.0. Iceberg nõuab versiooni 6.5.0 ja uuemat versiooni.
- valima JupyterEnterpriseGateway ja Säde installitava tarkvarana.
- eest Muutke tarkvara sätteidvalige Sisestage konfiguratsioon ja sisestage
[{"classification":"iceberg-defaults","properties":{"iceberg.enabled":true}}]. - Jätke muud seaded vaikeseadeteks ja valige järgmine.

- eest riistvara, kasutage vaikeseadet.
- Vali järgmine.
- eest Klastri nimi, sisestage nimi. Me kasutame
iceberg-blog-cluster. - Jätke ülejäänud seaded muutmata ja valige järgmine.
- Vali Loo klaster.
Looge EMR Studios märkmik
Nüüd tutvustame teile, kuidas luua konsoolist EMR Studios märkmikku.
- IAM-konsoolis luua EMR Studio teenuseroll.
- Valige Amazon EMR-i konsoolil EMR stuudio.
- Vali Alustamine.
. Alustamine leht ilmub uuele vahelehele.
- Vali Looge stuudio uuel vahelehel.
- Sisestage nimi. Kasutame jäämägi-stuudiot.
- Valige sama VPC ja alamvõrk, mis EMR-klastri jaoks, ja vaiketurberühm.
- Vali AWS-i identiteedi ja juurdepääsu haldus (IAM) autentimiseks ja valige äsja loodud EMR Studio teenuseroll.
- Valige S3 tee Tööruumide varundamine.
- Vali Looge stuudio.
- Pärast stuudio loomist valige stuudio juurdepääsu URL.
- Valige EMR Studio armatuurlaual Looge tööruum.
- Sisestage oma tööruumi nimi. Me kasutame
iceberg-workspace. - Laiendama Täpsem konfiguratsioon Ja vali Ühendage tööruum EMR-klastriga.
- Valige varem loodud EMR-klaster.
- Vali Looge tööruum.
- Uue vahelehe avamiseks valige tööruumi nimi.
Navigeerimispaanil on märkmik, millel on sama nimi, mis tööruumil. Meie puhul on see jäämägi-tööruum.
- Avage märkmik.
- Kui teil palutakse valida kernel, valige Säde.
Seadistage Apache Icebergi jaoks Sparki seanss
Kasutage järgmist koodi, lisades oma S3 ämbri nime:
See määrab järgmised Sparki seansi konfiguratsioonid:
- spark.sql.catalog.demo – Registreerib Sparki kataloogi nimega demo, mis kasutab Iceberg Sparki kataloogi pistikprogrammi.
- spark.sql.catalog.demo.catalog-impl - Demo Spark kataloog kasutab Icebergi andmebaasi ja tabeliteabe salvestamiseks füüsilise kataloogina AWS Glue'i.
- spark.sql.catalog.demo.warehouse – Demo Sparki kataloog salvestab kõik Icebergi metaandmed ja andmefailid selle atribuudiga määratud juurteele:
s3://iceberg-curated-blog-data. - spark.sql.extensions – Lisab toe Iceberg Spark SQL laiendustele, mis võimaldab teil käitada Iceberg Sparki protseduure ja mõningaid ainult Icebergi SQL-käske (kasutate seda hilisemas etapis).
- spark.sql.catalog.demo.io-impl - Iceberg võimaldab kasutajatel S3FileIO kaudu andmeid Amazon S3-sse kirjutada. AWS-i liimiandmete kataloog kasutab vaikimisi seda FileIO-d ja teised kataloogid saavad seda FileIO-d laadida, kasutades kataloogi io-impl atribuuti.
Teisendage andmed Icebergi tabelivormingusse
Saate Icebergi tabeli laadimiseks kasutada kas Sparki Amazon EMR-is või Athena. Käivitage EMR Studio Workspace'i märkmiku Sparki seansil andmete laadimiseks järgmised käsud.
Pärast koodi käivitamist peaksite leidma kaks prefiksit, mis on loodud teie andmelao S3 teele (s3://iceberg-curated-blog-data/reviews.db/all_reviews): andmed ja metaandmed.
Töötlege lisaandmeid, kasutades Athena SQL-lausete lisamist, värskendamist ja kustutamist
Athena on serverita päringumootor, mida saate kasutada lugemis-, kirjutamis-, värskendamis- ja optimeerimistoimingute tegemiseks Icebergi tabelite alusel. Näitamaks, kuidas Apache Icebergi andmejärve vorming toetab järkjärgulist andmete sisestamist, käivitame andmejärves SQL-lausete lisamise, värskendamise ja kustutamise.
Liikuge Athena konsooli ja valige Päringu redaktor. Kui kasutate Athena päringuredaktorit esimest korda, peate seda tegema konfigureerida päringu tulemuse asukoht olema varem loodud S3 ämber. Peaksite nägema, et tabel reviews.all_reviews on päringute tegemiseks saadaval. Käivitage järgmine päring, et kontrollida, kas olete Icebergi tabeli edukalt laadinud:
Töötlege lisaandmeid, käivitades SQL-lausete lisamise, värskendamise ja kustutamise:
Jõudluse häälestamine
Selles jaotises käsitleme erinevaid viise, kuidas parandada Apache Icebergi lugemis- ja kirjutamisjõudlust.
Apache Icebergi tabeli atribuutide seadistamine
Apache Iceberg on tabelivorming ja see toetab tabeli atribuute, et konfigureerida tabeli käitumist, nagu lugemine, kirjutamine ja kataloog. Saate parandada Icebergi tabelite lugemis- ja kirjutamisjõudlust, kohandades tabeli atribuute.
Näiteks kui märkate, et kirjutate Icebergi tabeli jaoks liiga palju väikeseid faile, saate päringu jõudluse parandamiseks konfigureerida kirjutamisfaili suuruse nii, et see kirjutaks vähem, kuid suuremaid faile.
| vara | vaikimisi | Kirjeldus |
| write.target-file-size-bytes | 536870912 (512 MB) | Juhib umbes nii paljude baitide sihtimiseks loodud failide suurust |
Tabelivormingu muutmiseks kasutage järgmist koodi:
Jaotamine ja sorteerimine
Päringu kiireks käivitamiseks, mida vähem andmeid loetakse, seda parem. Iceberg kasutab ära rikkalikke metaandmeid, mida ta salvestab kirjutamise ajal ja hõlbustab selliseid tehnikaid nagu skannimise planeerimine, jaotamine, kärpimine ja veerutaseme statistika, nagu min/max väärtused, et jätta vahele andmefailid, millel pole vastekirjeid. Anname teile ülevaate, kuidas Icebergis toimib päringu kontrolli planeerimine ja jaotamine ning kuidas me neid päringu jõudluse parandamiseks kasutame.
Päringu skannimise planeerimine
Antud päringu puhul on päringumootori esimene samm skannimise planeerimine, mis on päringu jaoks vajalike failide leidmine tabelist. Icebergi tabelis planeerimine on väga tõhus, kuna Icebergi rikkalikke metaandmeid saab kasutada mittevajalike metaandmete failide kärpimiseks, lisaks sobivaid andmeid mitte sisaldavate andmefailide filtreerimiseks. Meie katsetes täheldasime, et Athena skaneeris enne Icebergi vormingusse teisendamist 50% või vähem andmeid Icebergi tabelis antud päringu jaoks võrreldes algandmetega.
Filtreerimist on kahte tüüpi:
- Metaandmete filtreerimine – Iceberg kasutab failide hetktõmmises jälgimiseks kahte metaandmete taset: manifesti loendit ja manifestifaile. Esmalt kasutab see manifesti loendit, mis toimib manifestifailide indeksina. Planeerimise ajal filtreerib Iceberg manifeste, kasutades manifestiloendis partitsiooniväärtuste vahemikku, ilma kõiki manifestifaile lugemata. Seejärel kasutab ta andmefailide hankimiseks valitud manifestifaile.
- Andmete filtreerimine – Pärast manifestifailide loendi valimist kasutab Iceberg andmefailide filtreerimiseks iga manifestifailidesse salvestatud andmefaili partitsiooniandmeid ja veerutaseme statistikat. Planeerimise ajal teisendatakse päringu predikaadid partitsiooniandmete predikaatideks ja rakendatakse esmalt andmefailide filtreerimiseks. Seejärel kasutatakse veerustatistikat, näiteks veerutaseme väärtuste loendeid, nullide loendeid, alumisi ja ülemisi piire, et filtreerida välja andmefailid, mis ei vasta päringu predikaadile. Kasutades andmefailide planeerimise ajal filtreerimiseks ülemist ja alumist piiri, parandab Iceberg oluliselt päringu jõudlust.
Jaotamine ja sorteerimine
Partitsioneerimine on viis samade võtmeveeru väärtustega kirjete kirjalikult rühmitamiseks. Jaotamise eeliseks on kiiremad päringud, mis pääsevad juurde ainult osale andmetest, nagu selgitati varem päringu kontrollimise planeerimises: andmete filtreerimine. Iceberg muudab jaotamise lihtsaks, toetades peidetud partitsiooni, nii, et Iceberg loob partitsiooni väärtused, võttes veeru väärtuse ja seda valikuliselt teisendades.
Meie kasutusjuhul käivitame esmalt järgmise päringu Icebergi tabelis, mis pole partitsioonitud. Seejärel jagame Icebergi tabeli arvustuste kategooria järgi, mida kasutatakse päringu WHERE tingimuses kirjete filtreerimiseks. Partitsioneerimisega saaks päring skannida palju vähem andmeid. Vaadake järgmist koodi:
Käivitage toimivuse erinevuse nägemiseks partitsioonimata tabelis all_reviews ja partitsiooniga tabelis järgmine valikulause:
Järgmine tabel näitab andmete jaotamise jõudluse paranemist, umbes 50% jõudluse paranemisega ja 70% vähem skannitud andmeid.
| Andmekogumi nimi | Partitsioneerimata andmekogum | Jaotatud andmekogum |
| Kestus (sekundites) | 8.20 | 4.25 |
| Andmed skannitud (MB) | 131.55 | 33.79 |
Pange tähele, et käitusaeg on keskmine käitusaeg, kus meie testis on mitu käitamist.
Pärast partitsioonide eraldamist nägime jõudluse head paranemist. Seda saab aga veelgi parandada, kasutades Icebergi manifestifailide veerutaseme statistikat. Veerutaseme statistika tõhusaks kasutamiseks soovite oma kirjeid päringumustrite alusel veelgi sorteerida. Kogu andmestiku sorteerimine päringutes sageli kasutatavate veergude abil korraldab andmed ümber nii, et iga andmefaili tulemuseks on konkreetsete veergude jaoks kordumatu väärtusvahemik. Kui neid veerge kasutatakse päringutingimuses, võimaldab see päringumootoritel andmefaile veelgi enam vahele jätta, võimaldades seeläbi veelgi kiiremaid päringuid.
Kopeerimine-kirjutamisel vs lugemine-liitmine
Andmejärves Icebergi tabelites värskendamise ja kustutamise juurutamisel on Icebergi tabeli atribuudid määratletud kahel viisil.
- Kopeeri kirjutamise peale – Selle lähenemisviisi korral dubleeritakse ja värskendatakse mõjutatud kirjetega seotud andmefaile, kui Icebergi tabelis tehakse muudatusi (värskendusi või kustutamisi). Kirjeid kas uuendatakse või kustutatakse dubleeritud andmefailidest. Jäämäe tabelist luuakse uus hetktõmmis, mis osutab andmefailide uuemale versioonile. See muudab üldise kirjutamise aeglasemaks. Võib esineda olukordi, kus konfliktidega on vaja samaaegset kirjutamist, mistõttu tuleb uuesti proovida, mis pikendab kirjutamisaega veelgi. Teisest küljest pole andmete lugemisel täiendavat protsessi vaja. Päring hangib andmed andmefailide uusimatest versioonidest.
- Ühendamine lugemisel – Kui Icebergi tabelis on uuendusi või kustutamisi, siis selle lähenemisviisi korral olemasolevaid andmefaile ümber ei kirjutata; selle asemel luuakse muudatuste jälgimiseks uued kustutamisfailid. Kustutuste jaoks luuakse kustutatud kirjetega uus kustutamisfail. Jäämäe tabeli lugemisel rakendatakse kustutatud andmetele kustutamisfaili, et kustutada kustutatud kirjed. Värskenduste jaoks luuakse uus kustutamisfail, mis märgib värskendatud kirjed kustutatuks. Seejärel luuakse nende kirjete jaoks uus, kuid värskendatud väärtustega fail. Icebergi tabeli lugemisel rakendatakse hangitud andmetele nii kustutatud kui ka uued failid, et kajastada viimaseid muudatusi ja anda õigeid tulemusi. Seega toimub kõigi järgnevate päringute puhul täiendav samm andmefailide ühendamiseks kustutatud ja uute failidega, mis tavaliselt pikendab päringu esitamise aega. Teisest küljest võib kirjutamine olla kiirem, kuna pole vaja olemasolevaid andmefaile ümber kirjutada.
Kahe lähenemisviisi mõju testimiseks saate Icebergi tabeli atribuutide määramiseks käivitada järgmise koodi.
Käivitage Athenas värskendus, kustutage ja valige SQL-laused, et näidata käitusaja erinevust kirjutamisel kopeerimise ja lugemisel ühendamise vahel:
Järgmine tabel võtab kokku päringu käitusajad.
| Query | Kopeerimine-kirjutamisel | Ühendamine lugemisel | ||||
| UPDATE | Kustuta | SELECT | UPDATE | Kustuta | SELECT | |
| Kestus (sekundites) | 66.251 | 116.174 | 97.75 | 10.788 | 54.941 | 113.44 |
| Andmed skannitud (MB) | 494.06 | 3.07 | 137.16 | 494.06 | 3.07 | 137.16 |
Pange tähele, et käitusaeg on keskmine käitusaeg, kus meie testis on mitu käitamist.
Nagu meie testitulemused näitavad, on nende kahe lähenemisviisi puhul alati kompromisse. Millist lähenemist kasutada, sõltub teie kasutusjuhtudest. Kokkuvõttes taanduvad kaalutlused lugemise ja kirjutamise latentsusele. Saate vaadata järgmist tabelit ja teha õige valiku.
| . | Kopeerimine-kirjutamisel | Ühendamine lugemisel |
| Plusse | Kiirem lugemine | Kiirem kirjutab |
| Miinused | Kallis kirjutab | Kõrgem latentsus lugemisel |
| Millal kasutada | Hea sagedaseks lugemiseks, harvaks värskendamiseks ja kustutamiseks või suurte pakettvärskenduste jaoks | Sobib sagedaste värskenduste ja kustutamistega tabelite jaoks |
Andmete tihendamine
Kui teie andmefaili suurus on väike, võib jäämäe tabelis olla tuhandeid või miljoneid faile. See suurendab järsult I/O-toimingut ja aeglustab päringuid. Lisaks jälgib Iceberg iga andmefaili andmekogumis. Rohkem andmefaile toovad kaasa rohkem metaandmeid. See omakorda suurendab metaandmefailide lugemise üldkulusid ja I/O-toiminguid. Päringu jõudluse parandamiseks on soovitatav tihendada väikesed andmefailid suuremateks andmefailideks.
Kirjete värskendamisel ja kustutamisel Icebergi tabelis, kui kasutatakse lugemise ja liitmise meetodit, võib tulemuseks olla palju väikeseid kustutamisi või uusi andmefaile. Tihendamise käivitamine ühendab kõik need failid ja loob andmefailist uuema versiooni. See välistab vajaduse neid lugemise ajal sobitada. Soovitatav on teha korrapäraseid tihendustöid, et lugemist võimalikult vähe mõjutada, säilitades samal ajal kiirema kirjutamiskiiruse.
Käivitage järgmine andmete tihendamise käsk, seejärel käivitage Athena valikupäring:
Järgmises tabelis võrreldakse käitusaega enne ja pärast andmete tihendamist. Näete umbes 40% jõudluse paranemist.
| Query | Enne andmete tihendamist | Pärast andmete tihendamist |
| Kestus (sekundites) | 97.75 | 32.676 sekundit |
| Andmed skannitud (MB) | 137.16 M | 189.19 M |
Pange tähele, et valikupäringud jooksid saidil all_reviews tabel pärast värskendamise ja kustutamise toiminguid, enne ja pärast andmete tihendamist. Käitusaeg on keskmine käitusaeg, kus meie testis on mitu käitamist.
Koristage
Pärast seda, kui olete kasutamisjuhtumite täitmiseks järginud lahenduse juhiseid, tehke ressursside puhastamiseks ja täiendavate kulude vältimiseks järgmised sammud.
- Eemaldage AWS Glue tabelid ja andmebaas Athenast või käivitage oma märkmikus järgmine kood:
- Valige EMR Studio konsoolil tööruumid navigeerimispaanil.
- Valige loodud tööruum ja valige kustutama.
- Liikuge EMR-konsoolil valikule Studios lehel.
- Valige loodud stuudio ja tehke valik kustutama.
- Valige EMR-konsoolil Klastrid navigeerimispaanil.
- Valige klaster ja valige Lõpetage.
- Kustutage S3-salv ja kõik muud ressursid, mille lõite selle postituse eeltingimuste osana.
Järeldus
Selles postituses tutvustasime Apache Icebergi raamistikku ja seda, kuidas see aitab lahendada mõningaid väljakutseid, mis meil tänapäevases andmejärves on. Seejärel tutvustasime teile lahendust täiendavate andmete töötlemiseks andmejärves, kasutades Apache Icebergi. Lõpuks sukeldusime põhjalikult jõudluse häälestamisesse, et parandada lugemis- ja kirjutamisjõudlust meie kasutusjuhtudel.
Loodame, et see postitus annab teile kasulikku teavet, et otsustada, kas soovite Apache Icebergi oma andmejärve lahenduses kasutusele võtta.
Autoritest
 Flora Wu on AWS Data Labi vanem arhitekt. Ta aitab ettevõtte klientidel luua andmeanalüüsi strateegiaid ja luua lahendusi, mis kiirendavad nende äritulemusi. Vabal ajal meeldib talle tennist mängida, salsat tantsida ja reisida.
Flora Wu on AWS Data Labi vanem arhitekt. Ta aitab ettevõtte klientidel luua andmeanalüüsi strateegiaid ja luua lahendusi, mis kiirendavad nende äritulemusi. Vabal ajal meeldib talle tennist mängida, salsat tantsida ja reisida.
 Daniel Li on Amazon Web Services'i lahenduste arhitekt. Ta keskendub klientide abistamisele pilveteenuste ja -strateegia väljatöötamisel, kasutuselevõtul ja juurutamisel. Kui ta ei tööta, meeldib talle perega õues aega veeta.
Daniel Li on Amazon Web Services'i lahenduste arhitekt. Ta keskendub klientide abistamisele pilveteenuste ja -strateegia väljatöötamisel, kasutuselevõtul ja juurutamisel. Kui ta ei tööta, meeldib talle perega õues aega veeta.
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- Platoblockchain. Web3 metaversiooni intelligentsus. Täiustatud teadmised. Juurdepääs siia.
- Allikas: https://aws.amazon.com/blogs/big-data/use-apache-iceberg-in-a-data-lake-to-support-incremental-data-processing/
- 10
- 100
- 11
- 2022
- 2023
- 7
- 9
- a
- Võimalik
- MEIST
- üle
- kiirendama
- juurdepääs
- juurdepääsu haldamine
- tegevus
- õigusaktid
- lisamine
- Täiendavad lisad
- aadress
- aadressid
- Lisab
- vastu võtma
- ADEelis
- pärast
- vastu
- Materjal: BPA ja flataatide vaba plastik
- võimaldab
- alati
- Amazon
- Amazon EMR
- Amazon Web Services
- Analüütiline
- analytics
- ja
- teatas
- Apache
- rakendused
- rakendatud
- lähenemine
- lähenemisviisid
- asjakohane
- arhitektuur
- seotud
- Autentimine
- kättesaadavus
- saadaval
- keskmine
- vältima
- AWS
- AWS liim
- põhineb
- sest
- muutuma
- enne
- kasu
- Parem
- vahel
- suurem
- Bootstrap
- ehitama
- Ehitus
- ettevõtted
- lööb
- Püüdmine
- juhul
- juhtudel
- kataloog
- kataloogid
- Kategooria
- väljakutseid
- muutma
- Vaidluste lahendamine
- kontrollima
- valik
- Vali
- klassifikatsioon
- Cloud
- pilvteenustest
- Cluster
- kood
- Veerg
- Veerud
- ühendama
- Tulema
- endale
- võrreldes
- täitma
- Arvutama
- konkurent
- seisund
- konfiguratsioonid
- kaalutlused
- konsool
- Konverteerimine
- ümber
- kuluefektiivne
- kulud
- võiks
- looma
- loodud
- loob
- kureeritud
- Praegune
- klient
- Kliendid
- Dancing
- armatuurlaud
- andmed
- Andmete analüüs
- andmejärv
- andmetöötlus
- andmekogus
- andmebaas
- andmekogumid
- sügav
- sügav sukeldumine
- vaikimisi
- määratletud
- Demo
- näitama
- sõltub
- kavandatud
- detailid
- arendama
- & Tarkvaraarendus
- erinevus
- erinev
- arutama
- Ära
- alla
- dramaatiliselt
- Drop
- ajal
- iga
- Ajalugu
- Varajane
- toimetaja
- tõhusalt
- tõhus
- kumbki
- kõrvaldab
- lubatud
- võimaldades
- lõppeb
- Mootor
- Mootorid
- sisene
- ettevõte
- ettevõtte kliendid
- Eeter (ETH)
- Isegi
- evolutsioon
- arenema
- areneb
- näide
- olemasolevate
- olemas
- selgitas
- laiendused
- lisatasu
- hõlbustab
- pere
- KIIRE
- kiiremini
- FUNKTSIOONID
- Joonis
- fail
- Faile
- filtreerida
- filtreerimine
- Filtrid
- Lõpuks
- leidma
- esimene
- Esimest korda
- keskendub
- järgima
- Järel
- formaat
- Raamistik
- sage
- Alates
- edasi
- Pealegi
- Üldine
- loodud
- saama
- antud
- Goes
- hea
- suuresti
- Grupp
- käsi
- juhtuda
- aitama
- aidates
- aitab
- varjatud
- hierarhia
- kõrgetasemeline
- suur jõudlus
- suure jõudlusega
- Mesilaspere
- lootus
- Kuidas
- Kuidas
- aga
- HTML
- HTTPS
- IAM
- Identity
- identiteedi ja juurdepääsu haldamine
- mõju
- mõjutatud
- rakendada
- täitmine
- rakendamisel
- parandama
- paranenud
- paranemine
- parandab
- in
- Kaasa arvatud
- Suurendama
- kasvanud
- Tõstab
- indeks
- eraldi
- info
- paigaldama
- selle asemel
- integratsioon
- sisse
- Isoleerib
- IT
- Jaanuar
- Tööturg
- Võti
- labor
- järv
- suur
- suurem
- Hilinemine
- hiljemalt
- viimane versioon
- kiht
- kihid
- viima
- taset
- LIMIT
- joon
- nimekiri
- vähe
- koormus
- liising
- tegema
- TEEB
- juhtimine
- palju
- märk
- turul
- Vastama
- sobitamine
- Merge
- Metaandmed
- võib
- miljonid
- Kaasaegne
- rohkem
- liikuma
- mitmekordne
- nimi
- Nimega
- Navigate
- NAVIGATSIOON
- Vajadus
- vaja
- vajadustele
- Uus
- märkmik
- objekt
- avatud
- töö
- Operations
- optimeerimine
- optimeerima
- et
- originaal
- Muu
- väljas
- üldine
- enda
- pane
- osa
- tee
- mustrid
- täitma
- jõudlus
- füüsiline
- planeerimine
- Platon
- Platoni andmete intelligentsus
- PlatoData
- mängimine
- plugin
- võrra
- populaarne
- võimalik
- post
- sisse
- eeldused
- menetlused
- protsess
- töötlemine
- tootma
- omadused
- kinnisvara
- anda
- annab
- pakkudes
- säte
- valik
- Töötlemata
- algandmed
- Lugenud
- Lugemine
- reaalne
- hiljuti
- soovitatav
- andmed
- kajastama
- piirkond
- registrite
- regulaarne
- vabastama
- vabastatud
- ülejäänud
- nõutav
- Vajab
- Vahendid
- kaasa
- Tulemused
- Arvustused
- Rikas
- Roll
- juur
- jooks
- jooksmine
- sama
- skaneerida
- sekundit
- Osa
- turvalisus
- väljavalitud
- valides
- Serverita
- teenus
- Teenused
- istung
- komplekt
- Komplektid
- kehtestamine
- seaded
- peaks
- näitama
- Näitused
- lihtne
- olukordades
- SUURUS
- aeglustub
- väike
- Snapshot
- So
- tarkvara
- lahendus
- Lahendused
- mõned
- Säde
- konkreetse
- kiirus
- Kulutused
- SQL
- Käivitus
- riik
- väljavõte
- avaldused
- stats
- Samm
- Sammud
- Veel
- ladustamine
- salvestada
- ladustatud
- kauplustes
- strateegiad
- Strateegia
- struktureeritud
- struktureeritud ja struktureerimata andmed
- stuudio
- alamvõrgu
- järgnev
- Edukalt
- selline
- piisav
- KOKKUVÕTE
- toetama
- Toetatud
- Toetamine
- Toetab
- tabel
- võtab
- võtmine
- sihtmärk
- ülesanded
- tehnikat
- tennis
- test
- Testimine
- testid
- .
- teave
- Riik
- oma
- sellega
- tuhandeid
- kolm
- Läbi
- aeg
- ajas rännata
- et
- kokku
- liiga
- töövahendid
- ülemine
- Summa
- jälgida
- Tehingud
- transformeerivate
- reisima
- Reisimine
- Pöörake
- liigid
- all
- ainulaadne
- Värskendused
- ajakohastatud
- Uudised
- ajakohastamine
- URL
- kasutama
- kasutage juhtumit
- Kasutajad
- tavaliselt
- VAL
- väärtus
- Väärtused
- kontrollima
- versioon
- kõndis
- läbikäiguks
- Ladu
- kellad
- kuidas
- web
- veebiteenused
- M
- kas
- mis
- kuigi
- lai
- Lai valik
- will
- ilma
- Töö
- töö
- töötab
- oleks
- kirjutama
- kirjutamine
- Sinu
- sephyrnet