تصویر توسط نویسنده
تجزیه و تحلیل داده های اکتشافی (یا EDA) به عنوان یک مرحله اصلی در فرآیند تجزیه و تحلیل داده ها می ایستد و بر بررسی کامل جزئیات و ویژگی های درونی یک مجموعه داده تأکید دارد.
هدف اصلی آن کشف الگوهای اساسی، درک ساختار مجموعه داده و شناسایی هرگونه ناهنجاری یا روابط احتمالی بین متغیرها است.
با انجام EDA، متخصصان داده کیفیت داده ها را بررسی می کنند. بنابراین، تضمین می کند که تجزیه و تحلیل بیشتر بر اساس اطلاعات دقیق و روشنگر است و در نتیجه احتمال خطا در مراحل بعدی کاهش می یابد.
بنابراین بیایید سعی کنیم با هم بفهمیم که مراحل اساسی برای انجام یک EDA خوب برای پروژه بعدی علم داده ما چیست.
من مطمئن هستم که قبلاً این عبارت را شنیده اید:
زباله داخل، زباله بیرون
کیفیت داده های ورودی همیشه مهمترین عامل برای هر پروژه داده موفق است.
متأسفانه، بیشتر داده ها در ابتدا کثیف هستند. از طریق فرآیند تجزیه و تحلیل داده های اکتشافی، مجموعه داده ای که تقریباً قابل استفاده است را می توان به مجموعه ای کاملاً قابل استفاده تبدیل کرد.
واضح است که این یک راه حل جادویی برای خالص سازی هر مجموعه داده ای نیست. با این وجود، راهبردهای متعدد EDA در رسیدگی به چندین مشکل معمولی که در مجموعه دادهها با آن مواجه میشوند، مؤثر هستند.
بنابراین… بیایید طبق گفته Ayodele Oluleye در کتاب Exploratory Data Analysis with Python Cookbook ابتدایی ترین مراحل را بیاموزیم.
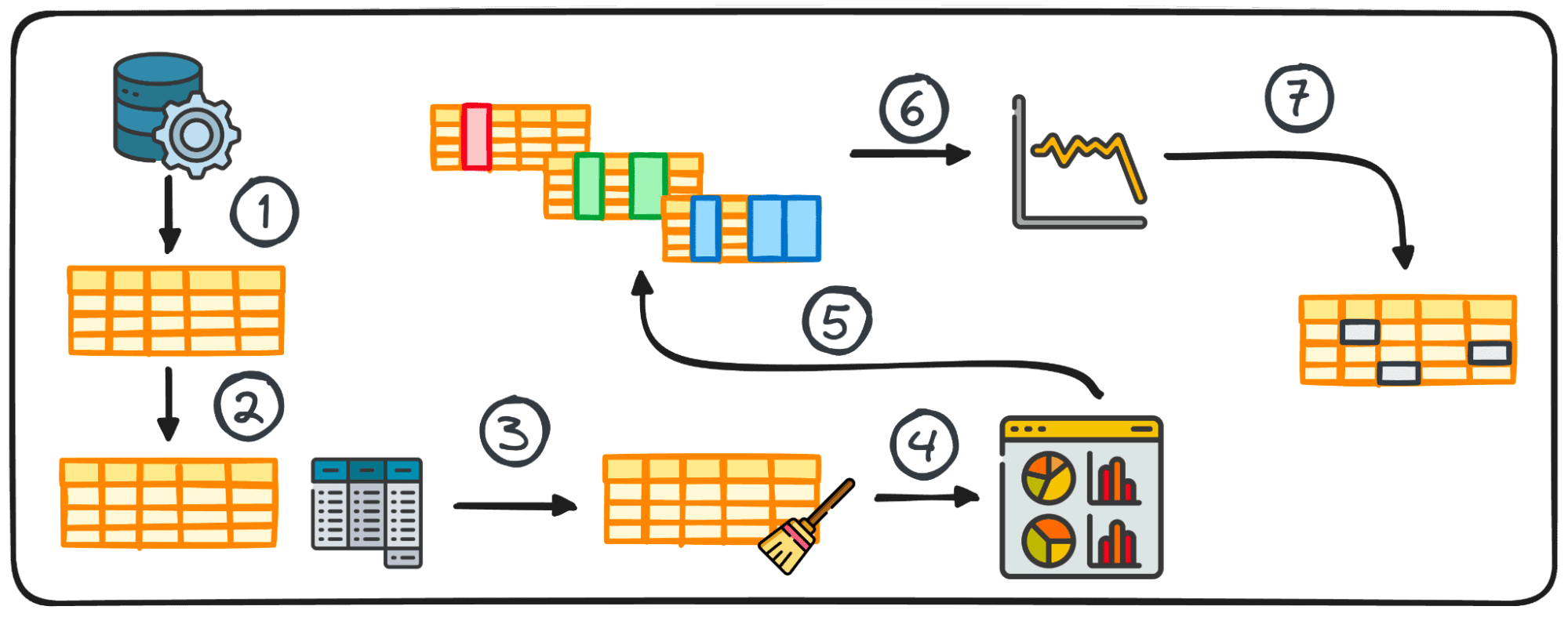
مرحله 1: جمع آوری داده ها
گام اولیه در هر پروژه داده، داشتن خود داده است. این مرحله اول جایی است که داده ها از منابع مختلف برای تجزیه و تحلیل بعدی جمع آوری می شوند.
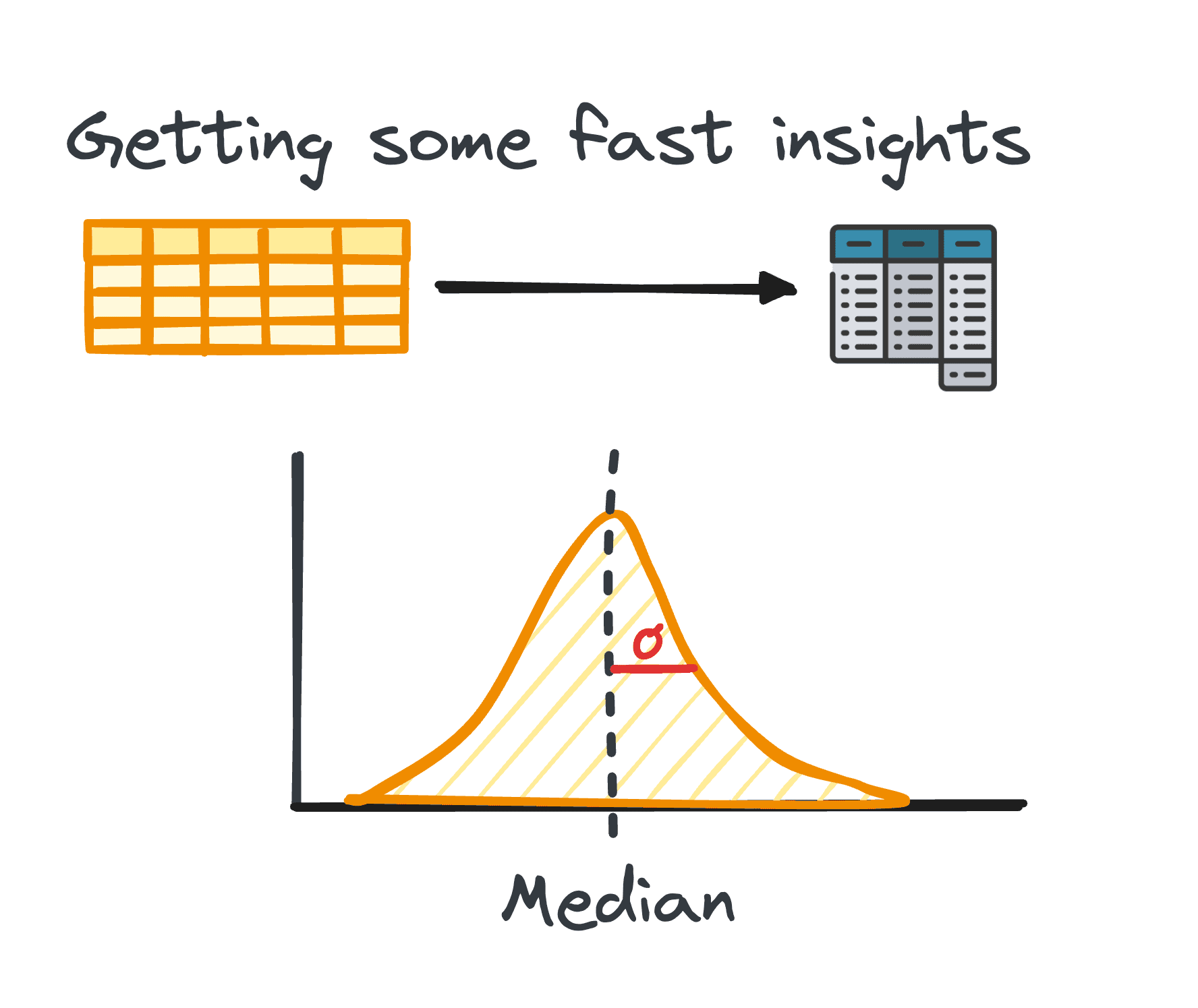
2. آمار خلاصه
در تجزیه و تحلیل داده ها، مدیریت داده های جدولی بسیار رایج است. در طول تجزیه و تحلیل چنین داده هایی، اغلب لازم است که بینش سریعی در مورد الگوها و توزیع داده ها به دست آوریم.
این بینش های اولیه به عنوان پایه ای برای کاوش بیشتر و تجزیه و تحلیل عمیق عمل می کنند و به عنوان آمار خلاصه شناخته می شوند.
آنها یک نمای کلی مختصر از توزیع و الگوهای مجموعه داده ارائه می دهند که از طریق معیارهایی مانند میانگین، میانه، حالت، واریانس، انحراف استاندارد، محدوده، صدک ها و ربع ها محصور شده است.
تصویر توسط نویسنده
3. آماده سازی داده ها برای EDA
قبل از شروع اکتشاف، معمولاً داده ها باید برای تجزیه و تحلیل بیشتر آماده شوند. آمادهسازی دادهها شامل تبدیل، جمعآوری یا تمیز کردن دادهها با استفاده از کتابخانه پانداهای پایتون برای مطابقت با نیازهای تحلیل شما است.
این مرحله بر اساس ساختار داده ها تنظیم شده است و می تواند شامل گروه بندی، الحاق، ادغام، مرتب سازی، طبقه بندی و برخورد با موارد تکراری باشد.
در پایتون، انجام این کار توسط کتابخانه پانداها از طریق ماژول های مختلف آن تسهیل می شود.
فرآیند آماده سازی برای داده های جدولی به یک روش جهانی پایبند نیست. در عوض، بر اساس ویژگیهای خاص دادههای ما، از جمله ردیفها، ستونها، انواع دادهها و مقادیری که در آن وجود دارد، شکل میگیرد.
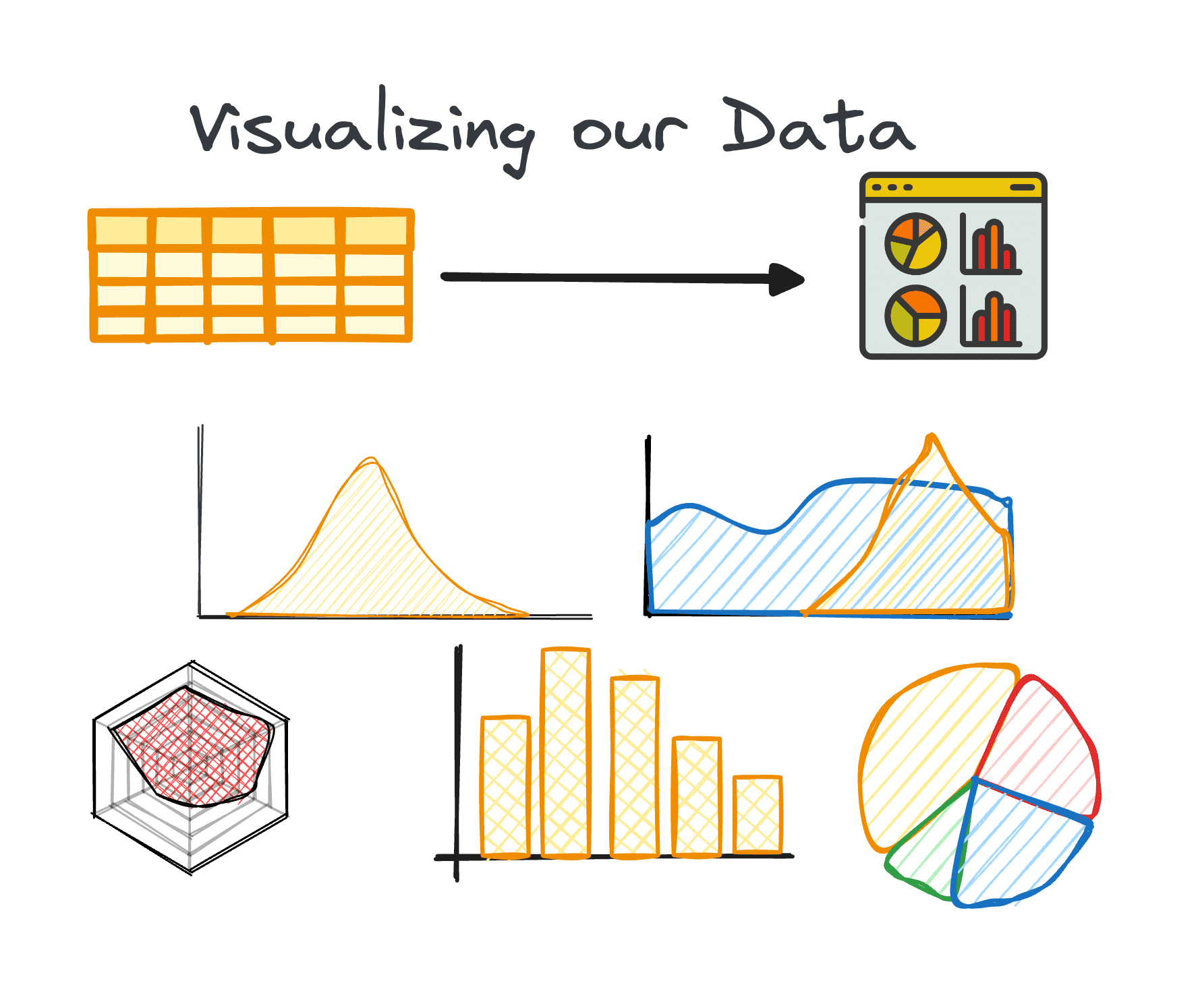
4. تجسم داده ها
تجسم جزء اصلی EDA است که روابط و روندهای پیچیده در مجموعه داده را به راحتی قابل درک می کند.
استفاده از نمودارهای مناسب می تواند به ما در شناسایی روندها در یک مجموعه داده بزرگ و یافتن الگوهای پنهان یا نقاط پرت کمک کند. پایتون کتابخانه های مختلفی را برای تجسم داده ها ارائه می دهد، از جمله Matplotlib یا Seaborn در میان دیگران.
تصویر توسط نویسنده
5. انجام تجزیه و تحلیل متغیرها:
تحلیل متغیر می تواند تک متغیره، دو متغیره یا چند متغیره باشد. هر یک از آنها بینشی در مورد توزیع و همبستگی بین متغیرهای مجموعه داده ارائه می دهد. تکنیک ها بسته به تعداد متغیرهای تحلیل شده متفاوت است:
تک متغیره
تمرکز اصلی در تحلیل تک متغیره بر بررسی هر متغیر در مجموعه داده ما به تنهایی است. در طول این تجزیه و تحلیل، ما می توانیم بینش هایی مانند میانه، حالت، حداکثر، محدوده و نقاط پرت را کشف کنیم.
این نوع تجزیه و تحلیل هم برای متغیرهای طبقه ای و هم برای متغیرهای عددی قابل استفاده است.
دوتایی
تجزیه و تحلیل دو متغیره با هدف آشکارسازی بینش بین دو متغیر انتخاب شده و بر درک توزیع و رابطه بین این دو متغیر تمرکز دارد.
همانطور که ما دو متغیر را به طور همزمان تجزیه و تحلیل می کنیم، این نوع تحلیل می تواند پیچیده تر باشد. این می تواند شامل سه جفت متغیر مختلف باشد: عددی-عددی، عددی-مقوله ای و طبقه بندی-ردهی.
چند متغیره
یک چالش مکرر با مجموعه داده های بزرگ، تجزیه و تحلیل همزمان چندین متغیر است. حتی اگر روش های تجزیه و تحلیل تک متغیره و دو متغیره بینش های ارزشمندی را ارائه می دهند، این معمولا برای تجزیه و تحلیل مجموعه داده های حاوی چندین متغیر (معمولا بیش از پنج متغیر) کافی نیست.
این موضوع مدیریت داده های با ابعاد بالا، که معمولاً به عنوان نفرین ابعادی از آن یاد می شود، به خوبی مستند شده است. داشتن تعداد زیادی متغیر می تواند سودمند باشد زیرا امکان استخراج بینش های بیشتری را فراهم می کند. در عین حال، به دلیل تعداد محدود تکنیک های موجود برای تجزیه و تحلیل یا تجسم چندین متغیر به طور همزمان، این مزیت می تواند علیه ما باشد.
6. تجزیه و تحلیل داده های سری زمانی
این مرحله بر بررسی نقاط داده جمع آوری شده در بازه های زمانی منظم متمرکز است. داده های سری زمانی برای داده هایی اعمال می شود که در طول زمان تغییر می کنند. این اساساً به این معنی است که مجموعه داده ما از گروهی از نقاط داده تشکیل شده است که در بازه های زمانی منظم ثبت می شوند.
وقتی دادههای سری زمانی را تجزیه و تحلیل میکنیم، معمولاً میتوانیم الگوها یا روندهایی را کشف کنیم که در طول زمان تکرار میشوند و فصلی زمانی را نشان میدهند. اجزای کلیدی دادههای سری زمانی شامل روندها، تغییرات فصلی، تغییرات چرخهای، و تغییرات نامنظم یا نویز است.
7. برخورد با موارد دور از دسترس و ارزش های گمشده
نقاط پرت و مقادیر از دست رفته می توانند نتایج تجزیه و تحلیل را منحرف کنند، اگر به درستی مورد توجه قرار نگیرند. به همین دلیل است که همیشه باید یک مرحله واحد را برای مقابله با آنها در نظر بگیریم.
شناسایی، حذف یا جایگزینی این نقاط داده برای حفظ یکپارچگی تجزیه و تحلیل مجموعه داده بسیار مهم است. بنابراین، بسیار مهم است که قبل از شروع به تجزیه و تحلیل داده های خود به آنها بپردازیم.
- نقاط پرت نقاط داده ای هستند که انحراف قابل توجهی از بقیه نشان می دهند. آنها معمولاً مقادیر غیرعادی بالا یا پایین را نشان می دهند.
- مقادیر از دست رفته عدم وجود نقاط داده مربوط به یک متغیر یا مشاهده خاص است.
یک گام اولیه حیاتی در برخورد با مقادیر از دست رفته و مقادیر پرت، درک دلیل وجود آنها در مجموعه داده است. این درک اغلب انتخاب مناسب ترین روش برای پرداختن به آنها را راهنمایی می کند. عوامل دیگری که باید در نظر گرفته شوند، ویژگی های داده ها و تجزیه و تحلیل خاصی است که انجام خواهد شد.
EDA نه تنها وضوح مجموعه داده ها را افزایش می دهد، بلکه متخصصان داده را قادر می سازد تا با ارائه استراتژی هایی برای مدیریت مجموعه داده ها با متغیرهای متعدد، در لعنت ابعاد بعدی حرکت کنند.
از طریق این مراحل دقیق، EDA با پایتون، تحلیلگران را با ابزارهای لازم برای استخراج بینش معنیدار از دادهها مجهز میکند و پایهای محکم برای تمام تلاشهای بعدی تجزیه و تحلیل دادهها ایجاد میکند.
جوزپ فرر یک مهندس تجزیه و تحلیل از بارسلونا است. او در رشته مهندسی فیزیک فارغ التحصیل شد و در حال حاضر در زمینه علم داده های کاربردی برای تحرک انسان کار می کند. او یک تولید کننده محتوای پاره وقت است که بر علم و فناوری داده تمرکز دارد. می توانید با او تماس بگیرید لینک, توییتر or متوسط.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://www.kdnuggets.com/7-steps-to-mastering-exploratory-data-analysis?utm_source=rss&utm_medium=rss&utm_campaign=7-steps-to-mastering-exploratory-data-analysis
- :است
- :نه
- :جایی که
- 1
- 7
- a
- انجام دادن
- مطابق
- دقیق
- اضافی
- نشانی
- خطاب
- خطاب به
- پایبند بودن
- مزیت - فایده - سود - منفعت
- با صرفه
- در برابر
- جمع کردن
- هدف
- اهداف
- معرفی
- اجازه می دهد تا
- قبلا
- همچنین
- همیشه
- am
- در میان
- an
- تحلیل
- تحلیلگران
- علم تجزیه و تحلیل
- تحلیل
- تجزیه و تحلیل
- تجزیه و تحلیل
- و
- هر
- مربوط
- اعمال می شود
- اعمال میشود
- هستند
- AS
- At
- در دسترس
- بارسلونا
- پایه
- مستقر
- اساسی
- اساسا
- BE
- قبل از
- میان
- بزرگ
- کتاب
- هر دو
- اما
- by
- CAN
- طبقه بندی
- به چالش
- تغییر دادن
- مشخصات
- نمودار
- بررسی
- برگزیده
- وضوح
- تمیز کاری
- جمع آوری
- ستون ها
- مشترک
- پیچیده
- جزء
- اجزاء
- مرکب
- مختصر
- انجام
- در نظر بگیرید
- تماس
- شامل
- محتوا
- هسته
- همبستگی
- متناظر
- خالق
- بحرانی
- بسیار سخت
- در حال حاضر
- لعنت
- چرخه ای
- داده ها
- تحلیل داده ها
- نقاط داده
- آماده سازی داده ها
- کیفیت داده
- علم اطلاعات
- تجسم داده ها
- مجموعه داده ها
- مقدار
- معامله
- بستگی دارد
- جزئیات
- انحراف
- مختلف
- خاک
- توزیع
- ندارد
- دو
- نسخه های تکراری
- در طی
- هر
- به آسانی
- موثر
- هر دو
- با تاکید بر
- را قادر می سازد
- بسته بندی شده
- شامل
- تلاش می کند
- مهندس
- مهندسی
- افزایش می یابد
- کافی
- تضمین می کند
- خطاهای
- حتی
- معاینه
- در حال بررسی
- اکتشاف
- تجزیه و تحلیل داده های اکتشافی
- عصاره
- استخراج
- تسهیل
- عامل
- عوامل
- رشته
- پیدا کردن
- نام خانوادگی
- پنج
- تمرکز
- متمرکز شده است
- تمرکز
- برای
- پایه
- مکرر
- از جانب
- کاملا
- بیشتر
- افزایش
- جمع آوری
- خوب
- فهم
- گروه
- راهنما
- اداره
- آیا
- داشتن
- he
- شنیده
- کمک
- پنهان
- زیاد
- خیلی
- او را
- خود را
- HTTPS
- انسان
- شناسایی
- if
- مهم
- in
- در عمق
- شامل
- از جمله
- اطلاعات
- اول
- داخلی
- بصیرت
- بینش
- در عوض
- تمامیت
- به
- تحقیق
- شامل
- موضوع
- مسائل
- IT
- ITS
- خود
- kdnuggets
- کلید
- شناخته شده
- بزرگ
- تخمگذار
- یاد گرفتن
- کتابخانه ها
- کتابخانه
- احتمال
- محدود شده
- لینک
- کم
- شعبده بازي
- اصلی
- نگهداری
- ساخت
- مدیریت
- تسلط
- ماتپلوتلب
- بیشترین
- متوسط
- معنی دار
- به معنی
- ادغام
- روش
- روش
- دقیق
- متریک
- گم
- تحرک
- حالت
- ماژول ها
- بیش
- اکثر
- چندگانه
- هدایت
- تقریبا
- لازم
- نیازهای
- بعد
- سر و صدا
- عدد
- عددی
- متعدد
- مشاهده
- of
- ارائه
- پیشنهادات
- غالبا
- on
- ONE
- فقط
- or
- دیگران
- ما
- روی
- مروری
- خود
- جفت
- پانداها
- الگوهای
- انجام دادن
- انجام
- فاز
- فیزیک
- افلاطون
- هوش داده افلاطون
- PlatoData
- نقطه
- پتانسیل
- تهیه
- آماده شده
- آماده
- در حال حاضر
- زیبا
- اصلی
- روند
- حرفه ای
- پروژه
- به درستی
- فراهم می کند
- ارائه
- پــایتــون
- کیفیت
- کاملا
- محدوده
- سریع
- ثبت
- کاهش
- اشاره
- منظم
- ارتباط
- روابط
- از بین بردن
- تکرار
- REST
- نتایج
- فاش کردن
- راست
- s
- همان
- علم
- علم و تکنولوژی
- متولد دریا
- فصلی
- انتخاب
- سلسله
- خدمت
- چند
- شکل
- باید
- قابل توجه
- همزمان
- تنها
- سرخ کردن
- جامد
- راه حل
- منابع
- خاص
- مراحل
- استاندارد
- می ایستد
- شروع
- راه افتادن
- ارقام
- گام
- مراحل
- استراتژی ها
- ساختار
- متعاقب
- موفق
- چنین
- کت و شلوار
- مناسب
- خلاصه
- مطمئن
- T
- طراحی شده
- کار
- تکنیک
- پیشرفته
- نسبت به
- که
- La
- آنها
- در نتیجه
- از این رو
- اینها
- آنها
- این
- کامل
- اگر چه؟
- سه
- از طریق
- زمان
- سری زمانی
- به
- با هم
- ابزار
- مبدل
- تبدیل شدن
- روند
- امتحان
- دو
- نوع
- انواع
- نوعی
- به طور معمول
- برملا کردن
- اساسی
- فهمیدن
- درک
- جهانی
- us
- قابل استفاده
- با استفاده از
- معمولا
- ارزشمند
- ارزشها
- متغیر
- متغیرها
- تغییرات
- مختلف
- متفاوت
- تجسم
- we
- چی
- چرا
- اراده
- با
- در داخل
- کارگر
- شما
- شما
- زفیرنت







