آخرین به روز رسانی: ژانویه 2021.
این وبلاگ یک مرور کلی از استفاده از OCR با هر ابزار RPA برای خودکار کردن گردش کار اسناد شما است. ما بررسی میکنیم که چگونه جدیدترین فناوریهای OCR مبتنی بر یادگیری ماشینی به قوانین یا تنظیم الگو نیاز ندارند.

RPA یا اتوماسیون فرآیند رباتیک ابزارهای نرم افزاری هستند که با هدف حذف وظایف تجاری تکراری انجام می شوند. تعداد بیشتری از CIOها برای کاهش هزینه ها و کمک به کارمندان برای تمرکز بر کارهای تجاری با ارزش بالاتر به سمت آنها روی می آورند. به عنوان مثال می توان به پاسخ به نظرات در وب سایت ها یا پردازش سفارش مشتری اشاره کرد. کارهای کمی پیچیده تر شامل رسیدگی به اسنادی مانند فرم های دست نویس و فاکتورها - اینها معمولاً باید از یک سیستم قدیمی به سیستم دیگر منتقل شوند - مشتری ایمیل خود را به سیستم SAP ERP خود بگویید که در آن باید داده ها را استخراج کنید. این قسمت مشکل ساز است.
اکثر ابزارهای OCR که داده ها را از این اسناد می گیرند مبتنی بر الگو هستند (مثلا ابی فلکسی کپچر) و در اسناد نیمه ساختاریافته به خوبی مقیاس نگیرید. راه حل های مبتنی بر یادگیری ماشینی نسل جدیدتری وجود دارد که معمولاً API را ارائه می دهند
ادغام هایی که می توانند جفت های کلید-مقدار را از اسناد دریافت کنند - سیستم های سازمانی معمولاً قدیمی هستند و برای ادغام با API های خارجی باز نیستند. از طرف دیگر، RPAها برای مدیریت این گردشهای کاری سیستم قدیمی مانند دریافت اسناد از پوشهها و وارد کردن نتایج به ERP یا CRM ساخته شدهاند.
از آنجایی که اتوماسیون فرآیند رباتیک (RPA) و ML در حال تکامل به سمت اتوماسیون فوقالعاده هستند، میتوانیم از رباتهای نرمافزاری در ارتباط با ML برای انجام کارهای پیچیده مانند طبقهبندی اسناد، استخراج و تشخیص کاراکترهای نوری استفاده کنیم. در یک مطالعه اخیر، گفته شد که با خودکارسازی تنها 29٪ از عملکردها برای یک کار با استفاده از RPA، بخش های مالی به تنهایی بیش از 25,000 ساعت کار مجدد ناشی از خطاهای انسانی را با هزینه 878,000 دلار در سال برای سازمانی با 40 کار کامل صرفه جویی می کنند. کارکنان حسابداری زمان [1]. در این وبلاگ، ما در مورد استفاده از OCR با RPA و بررسی عمیق جریان های کاری درک سند یاد خواهیم گرفت. در زیر فهرست مطالب آمده است.
تعاریف و بررسی اجمالی
به طور کلی، RPA یک فناوری است که به خودکارسازی وظایف اداری از طریق ربات های نرم افزاری-سخت افزاری کمک می کند. این ربات ها از رابط های کاربری بهره می برند. برای گرفتن داده ها و دستکاری برنامه ها مانند انسان ها. برای مثال، یک RPA میتواند به مجموعهای از وظایف انجامشده در یک رابط کاربری گرافیکی نگاه کند، مثلاً مکاننماهای متحرک، به APIها متصل شود، دادهها را کپی پیست کند، و همان توالی از اقدامات را در قالب RPA فرموله کند که به کد ترجمه میشود. علاوه بر این، این وظایف را می توان بدون دخالت انسان در آینده انجام داد. تشخیص کاراکتر نوری (OCR) یکی از ویژگیهای مهم هر راهحل اتوماسیون فرآیند روباتیک عملکردی (RPA) است. این فناوری برای خواندن و استخراج متن از منابع مختلف مانند تصاویر یا پی دی اف به یک فرمت دیجیتال بدون گرفتن دستی آن.
از سوی دیگر، درک سند اصطلاحی است که برای توصیف خودکار خواندن، تفسیر و عمل بر روی داده های سند استفاده می شود. مهمترین چیز در این فرآیند این است که ربات های نرم افزاری خود تمام وظایف را انجام می دهند. این ربات ها از قدرت هوش مصنوعی و یادگیری ماشین برای درک اسناد به عنوان دستیار دیجیتال استفاده می کنند. به این ترتیب، می توان گفت که درک سند در تقاطع پردازش اسناد، هوش مصنوعی و RPA ظاهر می شود.

چگونه روبات ها می توانند یاد بگیرند که اسناد را با OCR و ML درک کنند
قبل از اینکه ابتدا عمیقاً به درک سند بپردازیم، اجازه دهید در مورد نقش Robots for Document Understanding صحبت کنیم. این کمک های کاملاً نامرئی زندگی ما را بسیار راحت تر می کند. برخلاف فیلمها و سریالها، این رباتها دستگاههای فیزیکی یا برنامههای هوش مصنوعی نیستند که روی دسکتاپ بنشینند و دکمهها را برای انجام وظایف فشار دهند. ما میتوانیم اینها را دستیارهای دیجیتالی بدانیم که برای پردازش اسناد با خواندن و استفاده از برنامهها مانند ما آموزش دیدهاند. از جنبه عملکردی، ربات ها در بهبود عملکرد و کارایی یک فرآیند خوب هستند. با این حال، آنها به عنوان یک نرم افزار مستقل، نمی توانند فرآیند را ارزیابی کنند و تصمیمات شناختی بگیرند. با این حال، اگر یادگیری ماشین با موفقیت یکپارچه شود، رباتیک پویاتر و سازگارتر خواهد شد. به عنوان مثال، رباتهایی که برای پردازش اسناد، مدیریت دادهها و سایر عملکردها در دفتر جلو و میانی استفاده میشوند، اقدامات هوشمندانهتری مانند حذف ورودیهای تکراری یا حل استثناهای سیستم ناشناخته در این فرآیند را انجام میدهند. علاوه بر این، ربات ها برای خواندن، استخراج، تفسیر و عمل بر روی داده ها از اسناد با استفاده از هوش مصنوعی (AI) آموزش می بینند.
چگونه شرکت ها می توانند OCR هوشمند را با RPA برای بهبود گردش کار ادغام کنند
استخراج داده های سند یک جزء حیاتی برای درک سند است. در این بخش، نحوه ادغام OCR با RPA یا بالعکس را مورد بحث قرار خواهیم داد. اولاً، همه ما می دانستیم که اسناد مختلفی از نظر قالب، سبک، قالب بندی و گاهی اوقات زبان وجود دارد. از این رو نمیتوانیم برای استخراج دادهها از این اسناد به یک تکنیک OCR ساده تکیه کنیم. برای رسیدگی به این مشکل، از رویکردهای مبتنی بر قانون و رویکردهای مبتنی بر مدل در OCR برای مدیریت دادهها از ساختارهای اسناد مختلف استفاده میکنیم. اکنون خواهیم دید که چگونه شرکت هایی که OCR انجام می دهند می توانند RPA ها را بر اساس نوع اسناد در سیستم موجود خود ادغام کنند.
اسناد ساختاریافته: در این نوع اسناد، طرح ها و قالب ها معمولاً ثابت و تقریباً ثابت هستند. برای مثال، سازمانی را در نظر بگیرید که KYC را با شناسههای دولتی مانند گذرنامه یا گواهینامه رانندگی انجام میدهد. همه این مدارک یکسان خواهند بود و دارای فیلدهای مشابه با شماره شناسه، نام شخص، سن، و تعداد کمی دیگر در همان موقعیت ها هستند. اما فقط جزئیات متفاوت است. ممکن است محدودیتهای کمی مانند پر شدن جدول یا دادههای فایل نشده وجود داشته باشد.
معمولاً، رویکرد پیشنهادی از یک الگو یا موتور مبتنی بر قانون برای استخراج اطلاعات برای اسناد ساختاریافته استفاده میکند. اینها می تواند شامل عبارات منظم یا نگاشت موقعیت ساده و OCR باشد. از این رو برای ادغام رباتهای نرمافزاری برای استخراج خودکار اطلاعات، میتوانیم از الگوهای از قبل موجود استفاده کنیم یا قوانینی را برای دادههای ساختاریافته خود ایجاد کنیم. استفاده از رویکرد مبتنی بر قانون یک نقطه ضعف دارد، زیرا به قطعات ثابت متکی است، حتی تغییرات جزئی در ساختار فرم میتواند باعث شکست قوانین شود.
اسناد نیمه ساختاریافته: این اسناد دارای اطلاعات یکسانی هستند اما در موقعیت های مختلف تنظیم شده اند. برای مثال در نظر بگیرید فاکتورها حاوی 8-12 فیلد یکسان. کم فاکتورها، آدرس تاجر را می توان در بالا قرار داد و در موارد دیگر، آن را می توان در پایین یافت. معمولاً این رویکردهای مبتنی بر قاعده دقت بالایی ارائه نمی دهند. از این رو ما مدلهای یادگیری ماشین و یادگیری عمیق را برای استخراج اطلاعات با استفاده از OCR وارد تصویر میکنیم. متناوبا، در برخی موارد، میتوانیم از مدلهای ترکیبی استفاده کنیم که هم شامل قوانین و هم مدلهای ML میشوند. چند مدل از پیش آموزش دیده محبوب عبارتند از FastRCNN، Attention OCR، Graph Convolutions برای استخراج اطلاعات در اسناد. با این حال، دوباره این مدل ها دارای اشکالات کمی هستند. از این رو عملکرد الگوریتم را با استفاده از معیارهایی مانند دقت یا امتیاز اطمینان اندازه گیری می کنیم. از آنجایی که مدل به جای اجرای قوانین مشخص، الگوها را یاد میگیرد، ممکن است در ابتدا بلافاصله پس از اصلاحات اشتباه کند. با این حال، راه حل این اشکالات - هر چه مدل ML نمونه های بیشتری را پردازش کند، الگوهای بیشتری را برای اطمینان از دقت یاد می گیرد.
اسناد بدون ساختار: RPA، امروزه قادر به مدیریت مستقیم داده های بدون ساختار نیست، از این رو ابتدا به ربات ها نیاز دارد که داده های ساختاریافته را با استفاده از OCR استخراج و ایجاد کنند. برخلاف اسناد ساختاریافته و نیمه ساختاریافته، داده های بدون ساختار دارای چند جفت کلید-مقدار نیستند. مثلاً در چند مورد فاکتورها، ما یک آدرس تجاری را در جایی بدون هیچ نام کلیدی می بینیم. به همین ترتیب، برای سایر فیلدها مانند تاریخ، شناسه فاکتور نیز همین موضوع را رعایت می کنیم. برای اینکه مدلهای ML بتوانند این موارد را به دقت پردازش کنند، رباتها باید یاد بگیرند که چگونه متن نوشته شده را به دادههای کاربردی مانند ایمیل، شماره تلفن، آدرس و غیره ترجمه کنند. سپس مدل یاد میگیرد که الگوهای اعداد 7 یا 10 رقمی باید استخراج شوند. به عنوان شماره تلفن و متن بزرگ حاوی کدهای پنج رقمی و اسامی مختلف به عنوان متن. برای دقیقتر کردن این مدلها، میتوانیم از تکنیکهای پردازش زبان طبیعی (NLP) مانند شناسایی موجودیت نامگذاری شده و تعبیه کلمه استفاده کنیم.
به طور کلی برای درک سند، ابتدا درک داده ها و سپس پیاده سازی OCR با RPA ضروری است. در مرحله بعد، به جای ترسیم مرحله به مرحله یک فرآیند، میتوانیم با ادغام قوانین و الگوریتمهای یادگیری ماشین، به ربات آموزش دهیم که «همانطور که من انجام میدهم»، فرآیند را همانطور که با قابلیتهای قدرتمند OCR اتفاق میافتد، ثبت کند. ربات نرم افزاری کلیک ها و اقدامات شما را روی صفحه دنبال می کند و سپس آنها را به یک گردش کار قابل ویرایش تبدیل می کند. اگر به طور کامل در برنامه های محلی کار می کنید، به همان اندازه است که باید بدانید.
چالش های OCR که توسعه دهندگان RPA با آن روبرو هستند
ما دیدهایم که چگونه میتوانیم OCRR را با RPA برای اسناد مختلف ادغام کنیم، اما چند مورد از چالشها وجود دارد که رباتها باید به خوبی از پس آن برآیند. حالا بیایید در مورد آنها بحث کنیم!
- داده های ضعیف یا متناقض: داده ها نقش مهمی در درک سند دارند. در بیشتر موارد، اسناد با استفاده از دوربینها اسکن میشوند، جایی که احتمال از بین رفتن قالببندی سند در طول اسکن متن وجود دارد (یعنی پررنگ، مورب و زیرخط همیشه تشخیص داده نمیشوند). گاهی اوقات، OCR ممکن است متن را به روشی اشتباه استخراج کند که منجر به اشتباهات املایی، شکستن پاراگراف های نامنظم می شود، که عملکرد کلی روبات ها را کاهش می دهد. از این رو، مدیریت تمام مقادیر از دست رفته و گرفتن داده ها با دقت بالاتر برای دستیابی به دقت بالاتر برای OCR حیاتی است.
- جهت گیری نادرست صفحه در اسناد: جهت گیری و چولگی صفحه نیز یکی از مشکلات رایجی است که منجر به تصحیح متن نادرست OCR می شود. این معمولاً زمانی رخ می دهد که اسناد در مرحله جمع آوری داده ها به اشتباه اسکن شوند. برای غلبه بر این مشکل، ما باید چند عملکرد مانند تناسب خودکار در صفحه، فیلتر خودکار را به روباتها اعلام کنیم تا بتوانند کیفیت سند اسکن شده را افزایش دهند و دادههای صحیح را در خروجی دریافت کنند.
- مشکلات یکپارچه سازی: همه ابزارهای RPA در محیط های دسکتاپ راه دور عملکرد خوبی ندارند - آنها باعث خرابی و مشکلات اساسی در اتوماسیون می شوند. علاوه بر این، توسعه دهنده RPA باید بداند کدام راه حل OCR برای یک مورد خاص بهترین خواهد بود. همچنین، برای کار با ابزارهای اتوماسیون خاص، توسعهدهنده RPA باید تنها فناوری محدود OCR ایجاد شده توسط مایکروسافت، گوگل را انتخاب کند. از این رو ادغام الگوریتم ها و مدل های سفارشی ما گاهی اوقات چالش برانگیز است.
- تمام متن به صورت متن درهم است: برای موارد استفاده واقعی، متنی که توسط یک OCR عمومی گرفته میشود، همگی درهم است و هیچ اطلاعات معنیداری ندارد که رباتها بتوانند از آن برای انجام عملیات مهم استفاده کنند. توسعه دهندگان RPA به پشتیبانی قوی ML نیاز دارند تا بتوانند اپلیکیشن های مفیدی بسازند.
خط لوله برای گردش کار درک سند
در بخشهای قبلی، دیدیم که چگونه رباتها به انجام OCR برای انواع مختلف اسناد کمک میکنند. اما OCR فقط تکنیکی است که تصاویر یا فایل های دیگر را به متن تبدیل می کند. اکنون، در این بخش، از ابتدای جمعآوری اسناد، به بررسی گردش کار درک سند میپردازیم تا در نهایت اطلاعات معنیدار آنها را در قالب مورد نظر ذخیره کنیم.

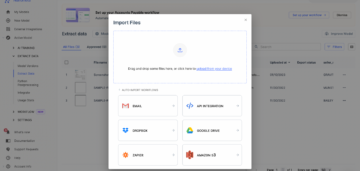
- با استفاده از ربات خود، سند را از یک پوشه وارد کنید: این اولین قدم از طریق دستیابی به درک سند از طریق ربات ها است. در اینجا، ما سندی را که در یک پلتفرم ابری (با استفاده از یک API) یا از یک ماشین محلی قرار دارد، واکشی خواهیم کرد. در موارد معدودی، اگر اسناد ما در صفحات وب باشد، میتوانیم اسکریپتها را از طریق رباتها بهطور خودکار خراش دهیم تا بتوانند اسناد را بهموقع واکشی کنند.
- نوع سند: پس از واکشی داده ها، درک نوع سند و فرمت ذخیره شده آنها در سیستم های ما ضروری است، زیرا گاهی اوقات، ما داده ها را از منابع مختلف در قالب های مختلف فایل دریافت می کنیم. PDF، PNG و JPG. نه فقط انواع فایلها، گاهی اوقات وقتی اسناد با دوربین گوشی اسکن میشوند، چند مشکل چالش برانگیز مانند چولگی تصویر، چرخش، روشنایی یا وضوح پایین نیز باید حل شود. بنابراین، ما باید مطمئن شویم که رباتها این اسناد را در دستههای ساختاریافته، نیمه ساختاریافته یا بدون ساختار طبقهبندی میکنند، بنابراین آنها را در قالبی عمومی ذخیره میکنند. وظیفه طبقه بندی با مقایسه اسناد با الگوها و تجزیه و تحلیل ویژگی هایی مانند فونت ها، زبان، وجود جفت های کلید-مقدار، جداول و غیره به دست می آید.
- استخراج داده ها با OCR: بسیار خوب، اکنون که ربات ها اسناد ما را در قالبی عمومی مرتب کردند و آنها را طبقه بندی کردند، زمان آن رسیده است که آنها را با استفاده از تکنیک OCR دیجیتالی کنیم. با این کار، متن، مکان آن را در مختصات از تصاویر خواهیم داشت. این به استانداردسازی اسناد و داده ها برای مراحل بعدی کمک می کند. همچنین زمانی که نرم افزار OCR نمی تواند به درستی بین کاراکترها تمایز قائل شود، مانند «t» در مقابل «i» یا «0» در مقابل «O» با چند مورد مواجه می شویم. هنگامی که فناوری OCR قادر به تجزیه و تحلیل نکات ظریف یک سند بر اساس کیفیت یا شکل اصلی آن نباشد، همان خطاهایی که میخواهید با استفاده از نرمافزار OCR از آنها طفره بروید، میتوانند به دردسر جدیدی تبدیل شوند. اینجاست که یادگیری ماشینی به تصویر میآید که در مرحله بعد به آن خواهیم پرداخت.
- استفاده از ML/DL برای OCR هوشمند با استفاده از ربات ها: پس از دیجیتالی شدن دادهها، نرمافزار OCR باید نوع سندی که با آن کار میکند و آنچه مرتبط است را درک کند. اما نرمافزار سنتی OCR میتواند تلاشهای طبقهبندی اسناد را مقیاسبندی کند. از این رو، رباتهای نرمافزاری باید با استفاده از تکنیکهای یادگیری ماشینی و یادگیری عمیق، با تواناییهای شناختی آموزش ببینند تا OCRها را باهوشتر کنند. راهحلهای OCR مبتنی بر ML میتوانند نوع سند را شناسایی کرده و آن را با نوع سند شناختهشدهای که توسط کسبوکار شما استفاده میشود مطابقت دهند. آنها همچنین می توانند بلوک های متن را در اسناد بدون ساختار تجزیه و درک کنند. هنگامی که راه حل بیشتر در مورد خود سند می داند، می تواند شروع به استخراج اطلاعات مرتبط بر اساس هدف و معنا کند.
- استخراج و طبقه بندی بهتر داده ها: استخراج داده ها هسته اصلی درک سند است. همانطور که در بخش قبلی در مورد ادغام RPA با OCR در این مرحله بحث شد، روش استخراج داده را بر اساس نوع سند انتخاب کنید. از طریق RPAها، ما به راحتی میتوانیم استخراجکننده را پیکربندی کنیم، چه تکنیک OCR مبتنی بر قانون یا مبتنی بر ML یا مدل ترکیبی. بر اساس معیارهای اطمینان و عملکردی که پس از استخراج اطلاعات برگردانده می شود، ربات های نرم افزاری آنها را برای تجزیه و تحلیل بیشتر در قالب مورد نظر ما ذخیره می کنند. در زیر تصویری از نحوه پیکربندی استخراج کننده ها و تنظیم سطح اطمینان در ابزار RPA توسط UIPath آمده است.

6. اعتبارسنجی و بینش های توانمند: مدل های OCR و Machine Learning از نظر استخراج اطلاعات صد در صد دقیق نیستند، از این رو افزودن لایه ای از دخالت انسان با کمک ربات ها می تواند مشکل را حل کند. روش کار این اعتبارسنجی به این صورت است که هرگاه روباتها با دقت کم و استثنا سروکار داشته باشند، فوراً یک اعلان به مرکز اقدام ارسال میکند که در آن کارمند میتواند درخواستی برای تأیید اعتبار دادهها یا رسیدگی به استثناها دریافت کند و میتواند هر گونه عدم قطعیت را در یک کلیک حل کند. علاوه بر این، میتوانیم پتانسیل هوش مصنوعی را برای مستندسازی دادهها در طول زمان برای پیشبینیها و شناسایی ناهنجاریهای بالقوه که ممکن است نشاندهنده تقلب، تکرار و سایر خطاها باشد، باز کنیم.
مزایای ادغام ربات ها با Document Understanding
- خودکار کردن فرآیند: دلیل اصلی ادغام ربات ها برای درک سند، خودکارسازی کل فرآیند از ابتدا تا انتها است. تنها کاری که ما باید انجام دهیم این است که یک گردش کار برای ربات ها ایجاد کنیم تا یاد بگیرند، بنشینند و استراحت کنند. در طول فرآیند اعتبار سنجی، ممکن است لازم باشد مسائلی را که توسط رباتها اطلاع داده میشود و در صورت شناسایی هرگونه خطا یا تقلب، مورد توجه قرار دهیم.
- ربات هایی با یادگیری ماشینی: در طول فرآیند اتوماسیون، میتوانیم رباتها را در برابر یادگیری ماشینی انعطافپذیر کنیم. به این معنی که روباتها همچنین میتوانند نحوه عملکرد مدلهای یادگیری ماشینی را بیاموزند و در نتیجه مدلها را برای دستیابی به دقت و عملکرد بالاتر برای استخراج متن و اطلاعات اسناد ارتقا دهند.
- طیف گسترده ای از پردازش اسناد را پردازش کنید: برای کارهای کلی مانند استخراج جدول و اطلاعات، ما باید خطوط لوله یادگیری عمیق متفاوتی را برای انواع مختلف اسناد ایجاد کنیم. این امر منجر به ساخت برنامه های متعدد و استقرار مدل های مختلف بر روی سرورهای مختلف می شود که به تلاش و زمان زیادی نیاز دارد. وقتی رباتها برای طیف وسیعی از اسناد در تصویر هستند، ما فقط میتوانیم یک خط لوله واحد داشته باشیم که در آن رباتها بتوانند آنها را طبقهبندی کنند و سپس از مدل مناسب برای کارهای مختلف استفاده کنند. ما همچنین میتوانیم سرویسهای مختلف را از طریق APIها ادغام کنیم و از نظر واکشی دادهها با سازمانهای دیگر ارتباط برقرار کنیم.
- استقرار آسان: برای درک سند پس از ایجاد خطوط لوله، فرآیند استقرار فقط یک دقیقه است. ما میتوانیم پس از آموزش، APIهایی داشته باشیم که توسط رباتها صادر میشوند، یا میتوانیم یک راهحل سفارشی RPA بسازیم که میتواند در سیستمهای محلی ما استفاده شود. این نوع استقرار همچنین می تواند بنگاه ها را بهینه کند و هزینه ها را با حداقل خطرات کاهش دهد.
Nanonets را وارد کنید
NanoNets یک پلتفرم یادگیری ماشینی است که به کاربران امکان می دهد داده ها را از آن ضبط کنند فاکتورها، رسیدها و سایر اسناد بدون تنظیم الگو. ما پیشرفتهترین الگوریتمهای یادگیری عمیق و بینایی رایانهای را داریم که در پشت اجرا میشوند که میتوانند هر نوع کار درک سند مانند OCR، استخراج جدول، استخراج جفت کلید-مقدار را انجام دهند. آنها معمولاً به عنوان API صادر می شوند یا می توانند بر اساس موارد استفاده مختلف در محل مستقر شوند. در اینجا چند نمونه هستند،
- مدل فاکتور: فیلدهای کلیدی را شناسایی کنید فاکتورها مانند نام خریداران، شناسه فاکتور، تاریخ، مبلغ و غیره.
- مدل رسیدها: فیلدهای کلیدی را از رسیدهایی مانند نام فروشنده، شماره، تاریخ، مبلغ و غیره شناسایی کنید.
- گواهینامه رانندگی (ایالات متحده آمریکا): فیلدهای کلیدی مانند شماره گواهینامه، DOB، تاریخ انقضا، تاریخ صدور و غیره را شناسایی کنید.
- رزومه ها: استخراج تجربه، تحصیلات، مجموعه مهارت ها، اطلاعات نامزد و غیره.
برای اینکه این گردشها سریعتر و قویتر شوند، از UiPath، یک ابزار RPA برای اتوماسیون یکپارچه اسناد شما بدون هیچ الگوی استفاده میکنیم. در بخش بعدی، نحوه استفاده از UiPath Connect با Nanonets را برای درک اسناد توضیح خواهیم داد. 3 بازیکن بزرگ در بازار RPA عبارتند از UiPath، Automation Anywhere و منشور آبی. این وبلاگ بر روی Uipath تمرکز دارد.
NanoNets با UiPath
ما در بخشهای قبلی یاد گرفتهایم که یک خط لوله درک سند ایجاد کنیم. این نیاز به دانش اولیه OCR، RPA و یادگیری ماشین دارد، زیرا رویکردها و الگوریتمهای مختلفی برای وظایف مختلف در نقاط مختلف وجود دارد. همچنین، ما باید تلاش زیادی را صرف ساختن شبکههای عصبی کنیم که الگوهای ما، آموزش و استقرار آنها را درک کنند. از این رو، ما در Nanonets برای راحت بودن و خودکار کردن همه چیز از بارگذاری اسناد، طبقه بندی آنها، ساخت OCR، ادغام مدل های ML، در حال کار بر روی Ui Path هستیم تا یک خط لوله بدون درز برای درک سند ایجاد کنیم. در زیر تصویری از نحوه کار این است.

حال اجازه دهید هر یک از این موارد را مرور کنیم و یاد بگیریم که چگونه میتوانیم نانو شبکهها را با UiPath ادغام کنیم.
مرحله 1: در UiPath ثبت نام کنید و UiPath Studio را دانلود کنید
برای ایجاد یک گردش کار، ابتدا باید یک حساب کاربری در UiPath ایجاد کنیم. اگر کاربر فعلی هستید، میتوانید مستقیماً وارد حساب خود شوید و داشبورد UiPath خود را تغییر مسیر دهید. در مرحله بعد، باید UiPath Studio (نسخه انجمن) را دانلود و نصب کنید که رایگان است.
مرحله 2: کامپوننت Nanonets را دانلود کنید
بعد، برای راه اندازی خود خط لوله پردازش فاکتور، باید کانکتور Nanonets را از لینک زیر دانلود کنید.
-> NanoNets OCR – RPA Component
در زیر یک اسکرین شات از بازار UiPath و مؤلفه Nanonets مشاهده می شود. همچنین، برای دانلود این، مطمئن شوید که از سیستم عامل ویندوز به UiPath وارد شده اید.

فایل های دانلود شده شما باید حاوی فایل های لیست شده در زیر باشد،
UiPath OCR Predict ├── Main.xaml
└── project.json
مرحله 3: فایل Main.xaml Nanonets Component را باز کنید
برای بررسی اینکه آیا Nanonets UiPath کار می کند یا خیر، می توانید فایل Main.xml خود را از مؤلفه Nanonets دانلود شده با استفاده از Ui Path Studio باز کنید. سپس می توانید خط لوله خود را که قبلاً برای پردازش اسناد برای شما ایجاد شده است، مشاهده کنید.

مرحله 4: شناسه مدل، کلید API و نقطه پایانی API خود را از برنامه Nanonets جمع آوری کنید
در مرحله بعد، می توانید از هر یک از مدل های OCR آموزش دیده از برنامه Nanonets استفاده کنید و شناسه مدل، کلید API و نقطه پایانی را جمع آوری کنید. در زیر جزئیات بیشتری وجود دارد تا بتوانید سریع آنها را پیدا کنید.
شناسه مدل: به حساب Nanonets خود وارد شوید و به "My Models" بروید. می توانید یک مدل جدید آموزش دهید یا شناسه برنامه یک مدل موجود را کپی کنید.

نقطه پایانی API: میتوانید هر مدل موجود را انتخاب کنید و روی Integrate کلیک کنید تا نقطه پایانی API خود را پیدا کنید. در زیر نمونه ای از نحوه ظاهر نقاط پایانی شما آورده شده است.
https://app.nanonets.com/api/v2/OCR/Model/XXXXXXX-4840-4c27-8940-d3add200779e/LabelUrls/

3. کلید API: به تب API Key بروید و می توانید هر کلید API موجود را کپی کنید یا یک کلید جدید ایجاد کنید.

مرحله 5: درخواست HTTP را اضافه کنید تا متد و متغیرهای خود را به مسیر UI دریافت کنید
اکنون برای ادغام مدل خود از Nanonets به مسیر UI، اولین کلیک روی درخواست HTTP و افزودن EndPoint را خواهید داشت که در ناوبری سمت چپ در بخش ورودی یافت می شود. در زیر یک اسکرین شات است.

بعداً، همه متغیرهای خود را اضافه کنید تا از استودیوی UiPath خود به API Nanonets ارتباط برقرار کنید. میتوانید این بخش را در قسمت پایین در «برگه متغیرها» پیدا کنید. در زیر اسکرین شات است، شما باید کلید API، نقطه پایان و شناسه مدل مدل خود را در اینجا به روز کنید/کپی کنید.

مرحله 6: مکان فایل را برای پیش بینی ها اضافه کنید
در نهایت، میتوانید همانطور که در تصویر زیر نشان داده شده است، مکان فایل خود را در زیر تب ویژگیها اضافه کنید و دکمه پخش را در ناوبری بالای خود فشار دهید تا خروجیهای خود را پیشبینی کنید.

وایلا! در اینجا خروجی های ما برای سندی است که در تصویر زیر درخواست کرده ایم. برای پردازش بیشتر، می توانید به سادگی مکان های فایل خود را اضافه کنید و دکمه اجرا را فشار دهید.

مرحله 7 - خروجی را به CSV / ERP فشار دهید
در نهایت، برای سفارشی کردن خروجی خود در قالب دلخواه شما، میتوانیم بلوکهای جدیدی را در فایل Main.XML به خط لوله شما اضافه کنیم. ما همچنین میتوانیم این را از طریق فایلهای آفلاین یا تماسهای API وارد سیستمهای ERP موجود کنیم.

برای هر گونه کمکی با ما در support@nanonets.com تماس بگیرید
کنفرانس آن لاین

برای یک وبینار سه شنبه آینده در OCR با RPA به ما بپیوندید، اینجا ثبت نام کنید.
منابع
[2] درک سند - پردازش اسناد هوش مصنوعی
[3] RPA OCR – بالا بردن اتوماسیون فرآیند | خوب
[4] نحوه استفاده از هوش مصنوعی برای بهینه سازی درک اسناد
[5] https://www.uipath.com/product/document-understanding
[6] استفاده از NanoNets در گردش کار UiPath برای OCR فاکتور
برای مطالعه بیشتر
ممکن است به آخرین پست های ما در این زمینه علاقه مند باشید:
به روز رسانی:
مطالب خواندنی بیشتری در مورد استفاده و تأثیر OCR، RPA در درک سند اضافه شده است.
منبع: https://nanonets.com/blog/ocr-with-rpa-and-document-understanding-uipath/
- '
- &
- 000
- 2021
- 7
- حساب
- حسابداری (Accounting)
- عمل
- مزیت - فایده - سود - منفعت
- AI
- الگوریتم
- الگوریتم
- معرفی
- تحلیل
- API
- رابط های برنامه کاربردی
- نرم افزار
- کاربرد
- برنامه های کاربردی
- هنر
- هوش مصنوعی
- هوش مصنوعی (AI)
- هوش مصنوعی و یادگیری ماشین
- اتوماسیون
- اتوماسیون در هر مکان
- بهترین
- بزرگترین
- بلاگ
- ربات
- رباتها
- ساختن
- بنا
- کسب و کار
- دوربین
- موارد
- علت
- ایجاد می شود
- شخصیت شناسی
- طبقه بندی
- ابر
- بستر ابری
- رمز
- شناختی
- جمع آوری
- نظرات
- مشترک
- انجمن
- شرکت
- جزء
- چشم انداز کامپیوتر
- اعتماد به نفس
- محتویات
- اصلاحات
- هزینه
- داشبورد
- داده ها
- مدیریت اطلاعات
- مقدار
- یادگیری عمیق
- توسعه دهنده
- توسعه دهندگان
- دستگاه ها
- دیجیتال
- اسناد و مدارک
- گول زدن
- رانندگی
- آموزش
- بهره وری
- پست الکترونیک
- کارکنان
- نقطه پایانی
- سرمایه گذاری
- و غیره
- داده ها را استخراج کنید
- استخراج
- ویژگی
- امکانات
- زمینه
- سرانجام
- سرمایه گذاری
- نام خانوادگی
- تمرکز
- فرم
- قالب
- تقلب
- رایگان
- آینده
- گارتنر
- سوالات عمومی
- GIF
- خوب
- گوگل
- راهنمایی
- اداره
- سردرد
- اینجا کلیک نمایید
- زیاد
- چگونه
- چگونه
- HTTPS
- بزرگ
- انسان
- ترکیبی
- شناسایی
- تصویر
- تأثیر
- افزایش
- اطلاعات
- اطلاعات
- استخراج اطلاعات
- اطلاعات
- قصد
- مسائل
- IT
- کلید
- دانش
- KYC
- زبان
- آخرین
- رهبری
- برجسته
- یاد گرفتن
- آموخته
- یادگیری
- سطح
- قدرت نفوذ
- مجوز
- محدود شده
- ارتباط دادن
- محلی
- محل
- فراگیری ماشین
- مدیریت
- بازار
- بازار
- مسابقه
- اندازه
- بازرگان
- متریک
- مایکروسافت
- ML
- مدل
- فیلم ها
- زبان طبیعی
- پردازش زبان طبیعی
- جهت یابی
- شبکه
- عصبی
- شبکه های عصبی
- nlp
- اخطار
- تعداد
- OCR
- باز کن
- عملیاتی
- سیستم عامل
- عملیات
- تشخیص شخصیت نوری
- سفارش
- دیگر
- دیگران
- گذرنامه
- کارایی
- تصویر
- سکو
- محبوب
- پست ها
- قدرت
- دقت
- پیش بینی
- خودکارسازی فرایند
- برنامه ها
- پروژه
- کیفیت
- افزایش
- محدوده
- RE
- مطالعه
- كاهش دادن
- نتایج
- این فایل نقد می نویسید:
- ربات
- اتوماسیون فرایند روباتیک
- رباتیک
- ربات ها
- آفریقای جنوبی
- قوانین
- دویدن
- در حال اجرا
- شیره
- صرفه جویی کردن
- مقیاس
- پویش
- خراش دادن
- پرده
- بدون درز
- فروشندگان
- سلسله
- خدمات
- تنظیم
- ساده
- So
- نرم افزار
- ربات های نرم افزاری
- مزایا
- حل
- خرج کردن
- شروع
- دولت
- مهاجرت تحصیلی
- پشتیبانی
- سیستم
- سیستم های
- استخراج جدول
- فن آوری
- پیشرفته
- آینده
- زمان
- بالا
- آموزش
- ui
- UiPath
- بروزرسانی
- us
- ایالات متحده
- موارد استفاده
- کاربران
- ارزش
- در مقابل
- دید
- وب
- وبینار
- وب سایت
- WHO
- پنجره
- در داخل
- مهاجرت کاری
- گردش کار
- با این نسخهها کار
- XML
- سال
- یوتیوب