معرفی
حداقل مربعات معمولی یک تکنیک بهینه سازی است. OLS همان تکنیکی است که توسط کلاس Sicit-learn LinearRegression و تابع numpy.polyfit() در پشت صحنه استفاده می شود. قبل از اینکه به جزئیات تکنیک OLS بپردازیم، بهتر است مقاله ای را که در مورد آن نوشته ام مرور کنیم نقش تکنیک های بهینه سازی در یادگیری ماشینی و یادگیری عمیق. در همین مقاله دلیل و زمینه وجود تکنیک OLS را به اختصار توضیح داده ام (بخش 6). این مقاله بسیار در ادامه همین مقاله است و انتظار می رود خوانندگان با همین مطلب آشنا شوند.

منبع: Pixbay
اهداف یادگیری:
در این مقاله، شما
- یاد بگیرید OLS چیست و معادله ریاضی آن را درک کنید
- یک نمای کلی از OLS به شکل مقیاس کننده و معایب آن دریافت کنید
- OLS را با استفاده از یک مثال بلادرنگ درک کنید
فهرست مندرجات
- مشکلات بهینه سازی چیست؟
- چرا به OLS نیاز داریم؟
- درک ریاضیات پشت الگوریتم OLS
- محلول OLS به شکل Scaler
- OLS در عمل با استفاده از یک مثال واقعی
- مشکلات با فرم Scaler راه حل OLS
- نتیجه
مشکلات بهینه سازی چیست؟
مسائل بهینه سازی مسائل ریاضی هستند که شامل یافتن بهترین راه حل از مجموعه ای از راه حل های ممکن است. این مسائل معمولاً به عنوان مسائل به حداکثر رساندن یا به حداقل رساندن فرموله می شوند، که در آن هدف، حداکثر یا حداقل کردن یک تابع هدف خاص است. تابع هدف یک عبارت ریاضی است که کمیتی را که باید بهینه شود را توصیف می کند و مجموعه ای از محدودیت ها مجموعه راه حل های ممکن را تعریف می کند.
مشکلات بهینه سازی در زمینه های مختلف از جمله مهندسی، مالی، اقتصاد و تحقیقات عملیاتی به وجود می آید. آنها برای مدلسازی و حل مسائلی مانند تخصیص منابع، زمانبندی و بهینهسازی پورتفولیو استفاده میشوند. بهینه سازی یک جزء حیاتی بسیاری از الگوریتم های یادگیری ماشین است. در یادگیری ماشینی، از بهینه سازی برای یافتن بهترین مجموعه پارامترها برای مدلی استفاده می شود که تفاوت بین پیش بینی های مدل و مقادیر واقعی را به حداقل می رساند. بهینه سازی یک حوزه تحقیقاتی فعال در یادگیری ماشین است، با الگوریتم های بهینه سازی جدیدی که برای بهبود سرعت و دقت آموزش مدل های یادگیری ماشینی توسعه یافته است.
برخی از نمونه هایی از مواردی که بهینه سازی در یادگیری ماشین استفاده می شود عبارتند از:
- در یادگیری تحت نظارت، از بهینه سازی برای یافتن پارامترهای یک مدل استفاده می شود که تفاوت بین پیش بینی های مدل و مقادیر واقعی را برای یک مجموعه داده آموزشی به حداقل می رساند. به عنوان مثال، رگرسیون خطی و رگرسیون لجستیک از بهینه سازی برای یافتن بهترین مقادیر ضرایب مدل استفاده می کنند. علاوه بر این، برخی از مدلها مانند درختهای تصمیم، جنگلهای تصادفی و مدلهای تقویت گرادیان با افزودن مکرر مدلهای جدید به مجموعه و بهینهسازی پارامترهای مدلهای جدید ساخته میشوند که خطا در دادههای آموزشی را به حداقل میرساند.
- در یادگیری بدون نظارت، بهینه سازی به یافتن بهترین پیکربندی خوشه ها یا نقشه برداری از داده ها کمک می کند که ساختار زیربنایی داده ها را به بهترین شکل نشان دهد. که در خوشه بندی، از بهینه سازی برای یافتن بهترین پیکربندی خوشه ها در داده ها استفاده می شود. به عنوان مثال، الگوریتم K-Means از یک تکنیک بهینهسازی به نام الگوریتم لوید استفاده میکند که به طور مکرر نقاط داده را به نزدیکترین مرکز خوشهای تخصیص میدهد و مرکز خوشهها را بر اساس نقاط جدید اختصاص داده شده به روز میکند. به طور مشابه، سایر الگوریتمهای خوشهبندی مانند خوشهبندی سلسله مراتبی، خوشهبندی مبتنی بر چگالی و مدلهای مخلوط گاوسی نیز از تکنیکهای بهینهسازی برای یافتن بهترین راهحل خوشهبندی استفاده میکنند. که در کاهش ابعاد، بهینه سازی بهترین نگاشت داده ها را از یک فضای با ابعاد بالا به یک فضای کمتر پیدا می کند. به عنوان مثال، تجزیه و تحلیل مؤلفه اصلی (PCA) از تجزیه ارزش واحد (SVD)، یک تکنیک بهینهسازی، برای یافتن بهترین ترکیب خطی از متغیرهای اصلی استفاده میکند که بیشترین واریانس را در دادهها توضیح میدهد. علاوه بر این، سایر تکنیکهای کاهش ابعاد مانند آنالیز تشخیص خطی (LDA) و تعبیه تصادفی همسایه t-distributed (t-SNE) نیز از تکنیکهای بهینهسازی برای یافتن بهترین نمایش دادهها در فضایی با ابعاد پایینتر استفاده میکنند.
- در یادگیری عمیق، از بهینه سازی برای یافتن بهترین مجموعه پارامترها برای شبکه های عصبی استفاده می شود که معمولاً با استفاده از الگوریتم های بهینه سازی مبتنی بر گرادیان مانند نزول گرادیان تصادفی (SGD) یا Adam/Adagrad/RMSProp و غیره انجام می شود.
چرا به OLS نیاز داریم؟
La حداقل مربعات معمولی الگوریتم (OLS) روشی برای تخمین پارامترهای یک مدل رگرسیون خطی است. هدف الگوریتم OLS یافتن مقادیر پارامترهای مدل رگرسیون خطی (یعنی ضرایب) است که مجموع مجذور باقیمانده را به حداقل می رساند. باقیمانده ها تفاوت بین مقادیر مشاهده شده متغیر وابسته و مقادیر پیش بینی شده متغیر وابسته با توجه به متغیرهای مستقل هستند. توجه به این نکته مهم است که الگوریتم OLS فرض میکند که خطاها معمولاً با میانگین صفر و واریانس ثابت توزیع میشوند و هیچ خطی (همبستگی بالا) بین متغیرهای مستقل وجود ندارد. در مواردی که این مفروضات برآورده نمی شوند، باید از روش های دیگری مانند حداقل مربعات تعمیم یافته یا حداقل مربعات وزن دار استفاده شود.
درک ریاضیات پشت الگوریتم OLS
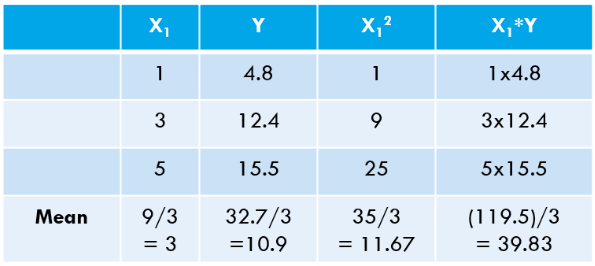
برای توضیح الگوریتم OLS، اجازه دهید ساده ترین مثال ممکن را بزنم. 3 نقطه داده زیر را در نظر بگیرید:
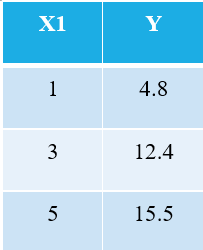
هر کسی که با یادگیری ماشینی آشناست بلافاصله متوجه می شود که ما به X1 به عنوان متغیر مستقل اشاره می کنیم (همچنین به نام "امکانات" یا "ویژگی های")، و Y متغیر وابسته است (همچنین به آن اشاره می شود "هدف" or "نتیجه"). از این رو، وظیفه کلی هر ماشینی یافتن رابطه بین X1 و Y است. این رابطه در واقع وجود دارد "یاد گرفت" توسط دستگاه از داده ها. از این رو اصطلاح یادگیری ماشین را می نامیم. ما انسان ها از تجربیات خود درس می گیریم. به طور مشابه، همان تجربه به عنوان داده به ماشین وارد می شود.
حال، فرض کنید میخواهیم بهترین خط را از طریق 3 نقطه داده بالا پیدا کنیم. نمودار زیر این 3 نقطه داده را در دایره های آبی نشان می دهد. همچنین خط قرمز (با مربع) نشان داده شده است که ما آن را به عنوان "بهترین خطاز طریق این 3 نقطه داده. همچنین، من یک خط "ضعیف" (خط زرد) را برای مقایسه نشان داده ام.
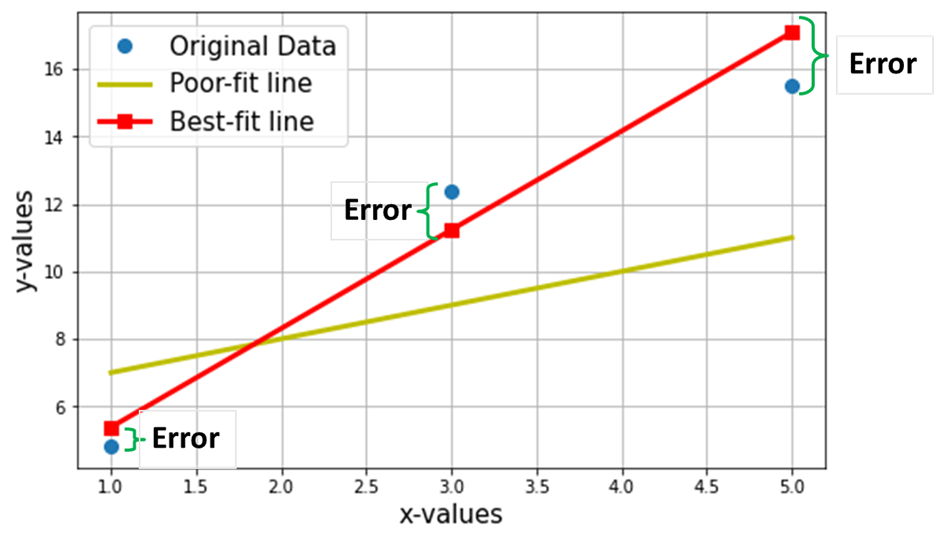
هدف خالص یافتن معادله است مناسب ترین خط مستقیم (از طریق این 3 نقطه داده ذکر شده در جدول بالا).

معادله بهترین خط (خط قرمز در نمودار بالا)، که در آن w1 = شیب خط. w0 = قطع خط
در یادگیری ماشینی، این بهترین تناسب، نامیده می شود خطی رگرسیون مدل (LR) و w0 و w1 نیز نامیده می شوند وزن مدل یا ضرایب مدل.
مربع های قرمز در نمودار بالا مقادیر پیش بینی شده از مدل رگرسیون خطی (Y^) را نشان می دهند. البته، مقادیر پیش بینی شده با مقادیر واقعی Y (دایره های آبی) یکسان نیستند. تفاوت عمودی نشان دهنده خطا در پیش بینی داده شده توسط (تصویر زیر) برای هر نقطه داده ith است.
![]()
اکنون من ادعا میکنم که این بهترین خط مناسب حداقل خطای پیشبینی را خواهد داشت (در میان تمام خطوط تصادفی نامتناهی ممکن با تناسب ضعیف). این خطای کل در تمام نقاط داده به صورت نشان داده می شود تابع میانگین مربعات خطا (MSE).، که خواهد بود حد اقل برای بهترین خط مناسب
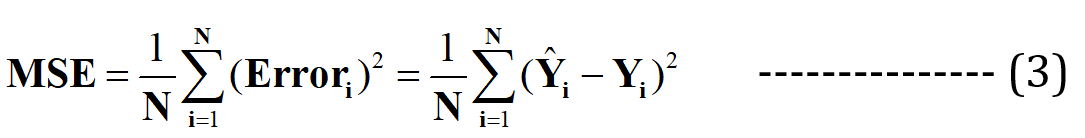
N = تعداد کل نقاط داده در مجموعه داده (در حالت فعلی، 3 است)
به حداقل رساندن یا به حداکثر رساندن هر کمیت از نظر ریاضی به عنوان یک اطلاق می شود مشکل بهینه سازی، و از این رو راه حل (نقطه ای که حداقل/حداکثر وجود دارد) به مقادیر بهینه متغیرها اشاره دارد.

رگرسیون خطی نمونه ای از بهینه سازی بدون محدودیت است، ارائه شده توسط:
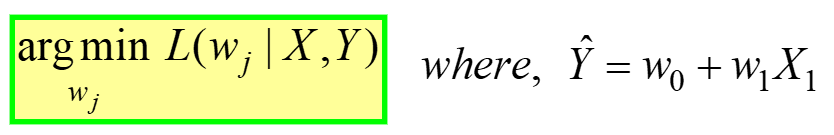 ---- (4)
---- (4)
این به عنوان "پیدا کردن وزن های بهینه (wj) که برای MSE تابع از دست دادن (در معادله 3 در بالا داده شده) دارد مقدار حداقل، برای داده های X، Y داده شده است" (به اولین جدول در ابتدای مقاله مراجعه کنید). L(wj) نشان دهنده ضرر MSE است، تابعی از وزن مدل، نه X یا Y. به یاد داشته باشید، X & Y داده شما است و قرار است ثابت باشد! زیرنویس "j" نشان دهنده ضریب/وزن مدل j است.
پس از جایگزینی برای Y^ = w0 +w1X1 در معادله 3 بالا، فینال تابع از دست دادن MSE (L) به نظر می رسد:
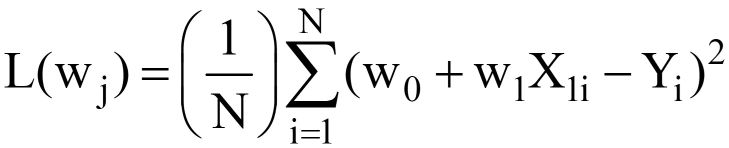 ---- (5)
---- (5)
واضح است که L تابعی از وزن مدل است (w0 & w1مقادیر بهینه آن را با کمینه کردن L باید پیدا کنیم. مقادیر بهینه با (*) در شکل زیر نشان داده شده است.
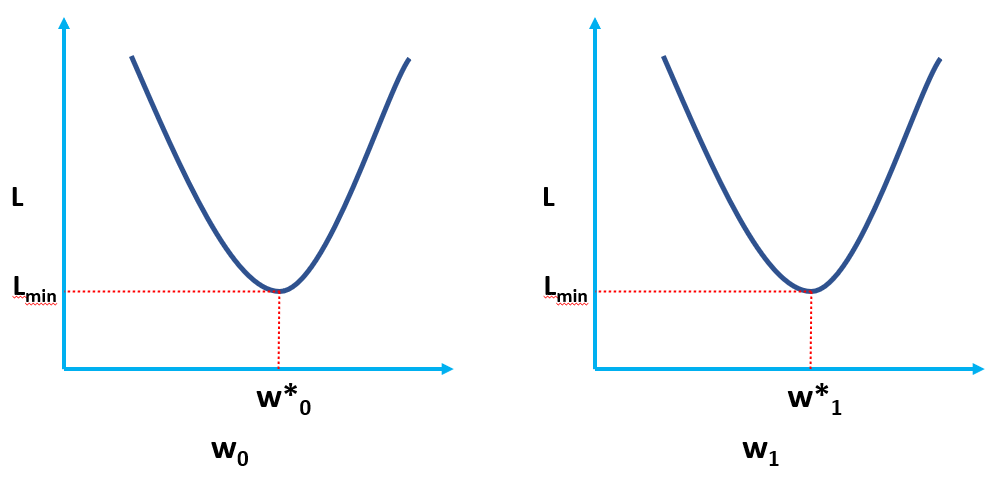
راه حل OLS به شکل مقیاس کننده
معادله 5 داده شده در بالا نشان دهنده تابع OLS Loss در شکل مقیاس کننده است (جایی که می توانیم آن را ببینیم جمع بندی خطاها برای هر نقطه داده الگوریتم OLS یک راه حل تحلیلی برای مسئله بهینه سازی است که در معادله ارائه شده است. 4. این راه حل تحلیلی شامل مراحل زیر است:
مرحله 1:

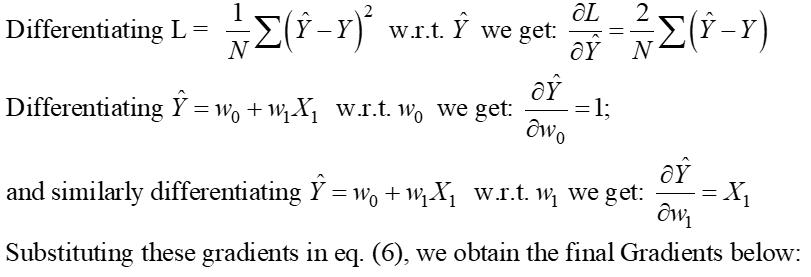

مرحله 2: این گرادیان ها را با صفر برابر کنید و مقادیر بهینه ضرایب مدل را حل کنیدj.
این اساساً به این معنی است که شیب مماس (تفسیر هندسی گرادیان ها) به تابع Loss در مقادیر بهینه (نقطه ای که L حداقل است) صفر خواهد بود، همانطور که در شکل های بالا نشان داده شده است.

از معادلات بالا، میتوانیم «2» را از LHS به RHS تغییر دهیم. RHS 0 باقی می ماند (زیرا 0/2 هنوز 0 است).


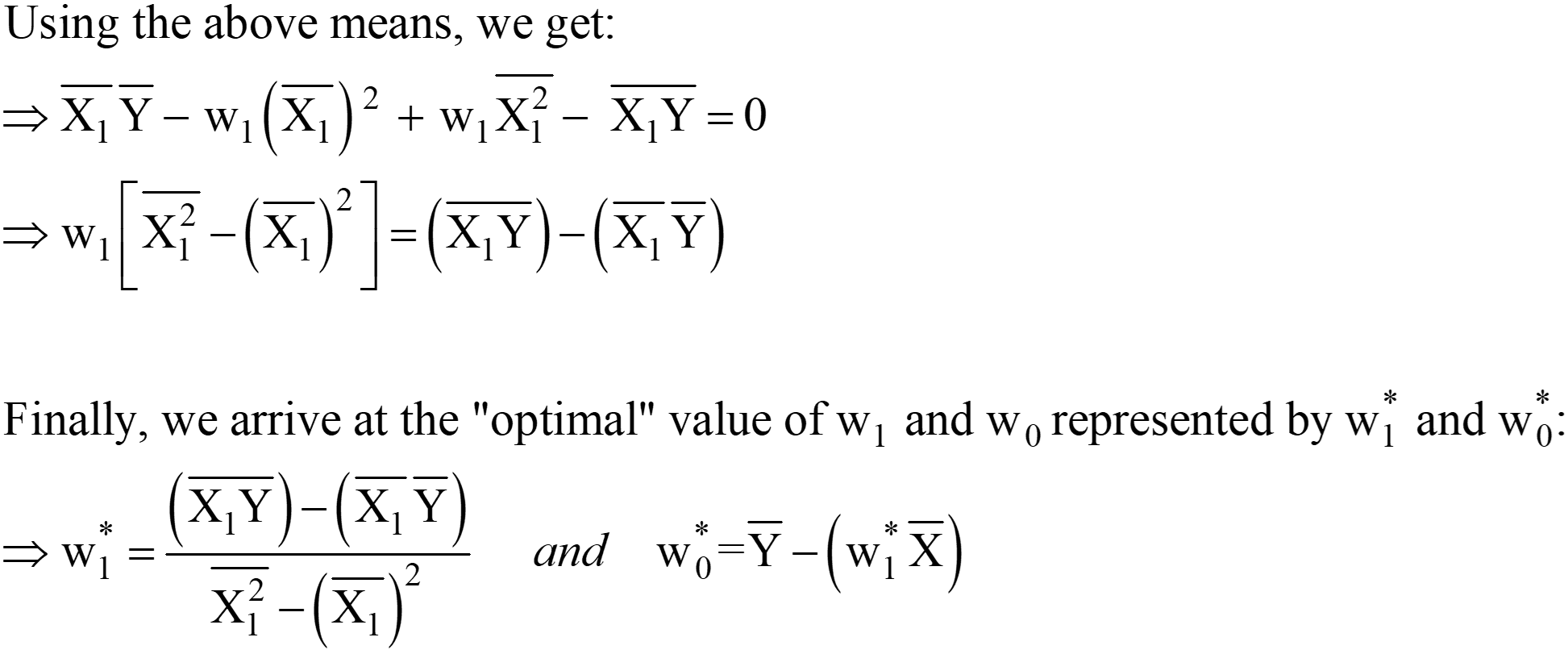
این عبارات برای w1* و w0* راه حل نهایی OLS Analytical در فرم Scaler هستند.
مرحله 3: میانگین های بالا را محاسبه کرده و در عبارت w1* و w0* را جایگزین کنید.
بیایید این مقادیر را برای مجموعه داده خود محاسبه کنیم:
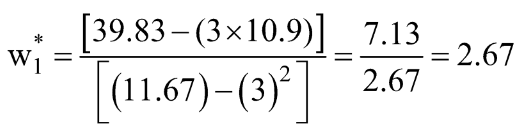
![]()
بیایید با استفاده از کد پایتون همین را محاسبه کنیم:
[خروجی]: این معادله خط "بهترین مناسب" است: 2.675 x + 2.875
میتوانید ببینید که مقادیر «محاسبهشده با دست» ما با مقادیر شیب و قطع بهدستآمده با استفاده از NumPy بسیار نزدیک است (تفاوت کوچک به دلیل خطاهای گرد کردن در محاسبات دستی ما است). همچنین میتوانیم تأیید کنیم که همان OLS در پشت صحنه کلاس LinearRegression در حال اجرا است. یادگیری بسته، همانطور که در کد زیر نشان داده شده است.
# وارد کردن کلاس LinearRegression از بسته scikit-learn از sklearn.linear_model import LinearRegression LR = LinearRegression() # یک نمونه از کلاس LinearRegression ایجاد کنید # X و Y خود را به عنوان آرایه های NumPy (بردارهای ستونی) تعریف کنید X = np.array([1,3,5 ,1,1]).reshape(-4.8,12.4,15.5) Y = np.array([1,1]).reshape(-0) LR.fit(X,Y) # محاسبه ضرایب مدل LR .intercept_ # تعصب یا عبارت رهگیری (wXNUMX*)
[خروجی]: آرایه ([2.875])
LR.coef_ # عبارت شیب (w1*) [خروجی]: آرایه ([[2.675]])
OLS در عمل با استفاده از یک مثال واقعی
در اینجا من از مجموعه داده قیمت گذاری خانه بوستون استفاده می کنم، یکی از متداول ترین مجموعه داده هایی که هنگام یادگیری علم داده با آن مواجه می شویم. هدف این است که یک مدل رگرسیون خطی برای پیش بینی ارزش میانه قیمت خانه بر اساس 13 ویژگی/ویژگی ذکر شده در زیر.
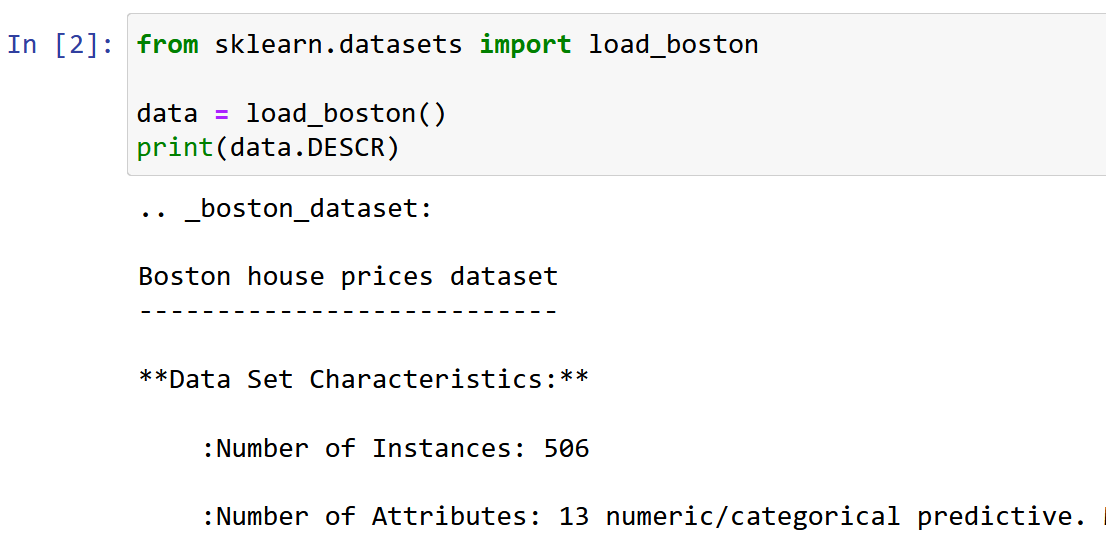
وارد کردن و کاوش مجموعه داده.
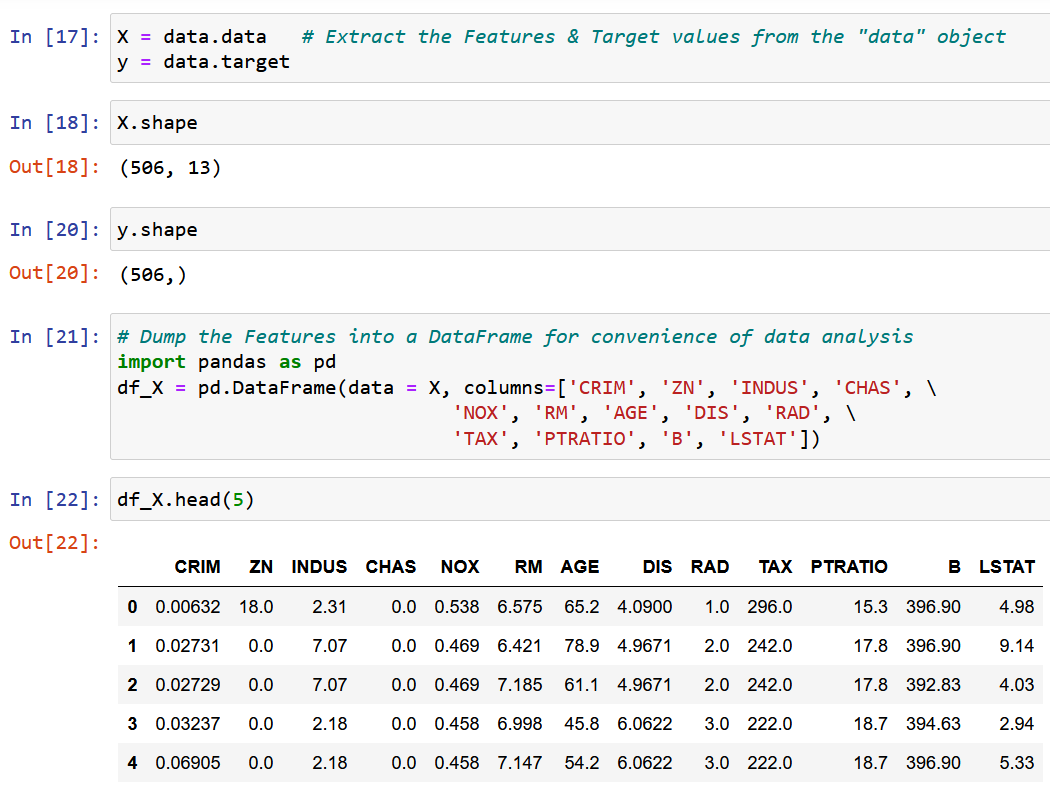
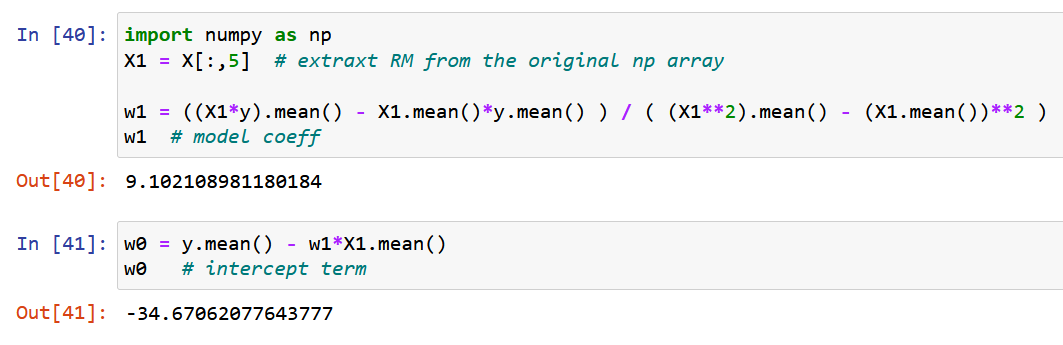
ما یک ویژگی واحد RM را استخراج می کنیم، اندازه متوسط اتاق در محل داده شده، و آن را با متغیر هدف y (مقدار متوسط قیمت خانه) متناسب می کنیم.
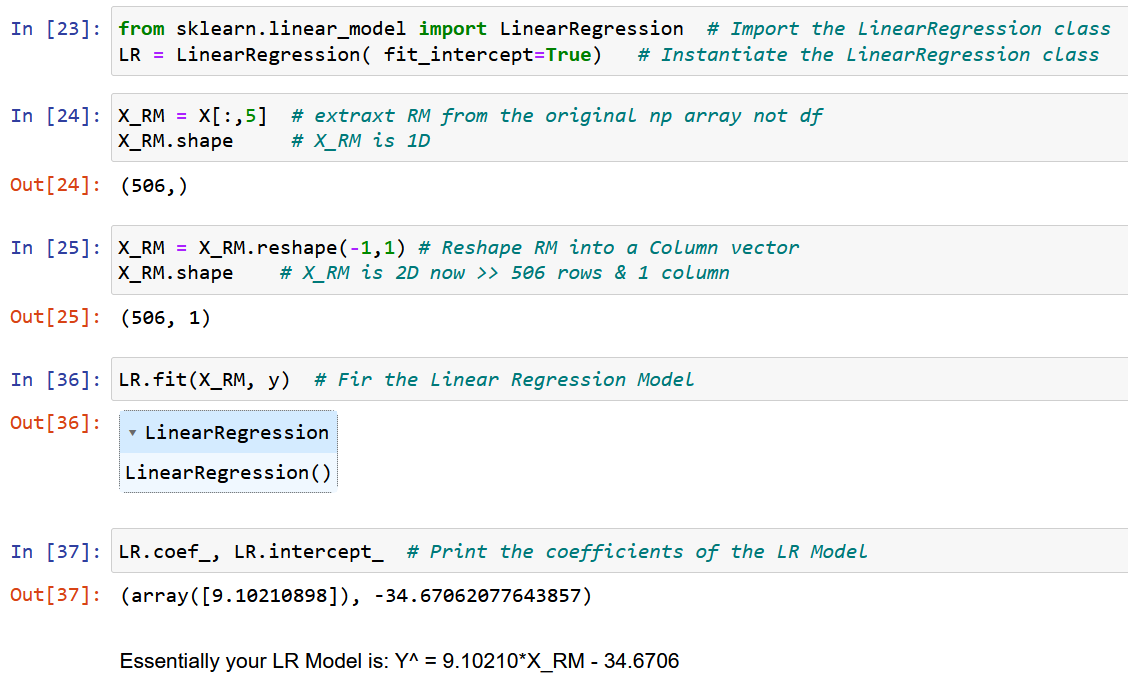
حال، بیایید از NumPy خالص استفاده کنیم و ضرایب مدل را با استفاده از عبارات به دست آمده برای مقادیر بهینه ضرایب مدل w0 و w1 در بالا (پایان مرحله 2) محاسبه کنیم.
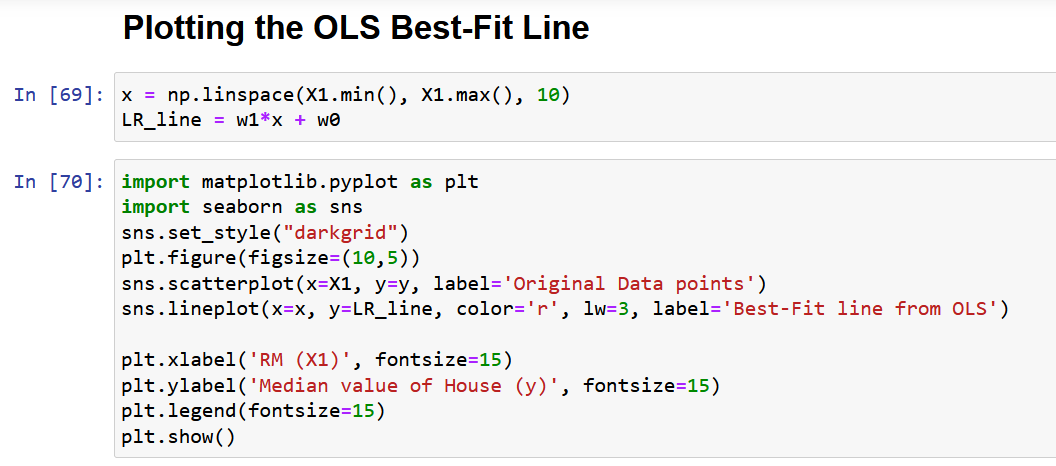
اجازه دهید در نهایت داده های اصلی را به همراه بهترین خط مطابق زیر رسم کنیم.

مشکلات مربوط به فرم مقیاس کننده راه حل OLS
در نهایت، اجازه دهید مشکل اصلی رویکرد بالا را همانطور که در بخش 4 توضیح داده شده است، مورد بحث قرار دهم. دلیل اصلی که من فقط یک ویژگی را برای نشان دادن روش OLS در بخش بالا انتخاب کردم این بود که با افزایش تعداد ویژگی ها، تعداد گرادیان ها نیز افزایش می یابد، بنابراین تعداد معادلاتی که باید همزمان حل شوند!
به طور دقیق، برای 13 ویژگی (مجموعه داده بوستون در بالا)، ما 13 ضریب مدل و یک جمله رهگیری خواهیم داشت که تعداد کل متغیرهای بهینه سازی شده را به 14 می رساند. بنابراین، ما 14 گرادیان (مشتق جزئی) را به دست خواهیم آورد. تابع ضرر با توجه به هر یک از این 14 متغیر). در نتیجه، ما باید 14 معادله را حل کنیم (پس از معادل سازی این 14 مشتق جزئی با صفر، همانطور که در مرحله 2 توضیح داده شد). شما قبلاً به پیچیدگی راه حل تحلیلی تنها با 2 متغیر پی برده اید. صادقانه بگویم، من سعی کردهام مفصلترین توضیح OLS را که در اینترنت موجود است به شما ارائه دهم، اما در عین حال، جذب ریاضیات آسان نیست.
از این رو، به زبان ساده، راه حل تحلیلی بالا مقیاس پذیر نیست!
راه حل این مشکل «فرم برداری راه حل OLS» است که در مقاله بعدی (بخش 2 این مقاله)، با بخش های 7 و 8 به تفصیل مورد بحث قرار خواهد گرفت.
نتیجه
در نتیجه، روش OLS ابزار قدرتمندی برای تخمین پارامترهای یک مدل رگرسیون خطی است. این بر اساس اصل به حداقل رساندن مجموع اختلاف مجذور بین مقادیر پیش بینی شده و واقعی است.
برخی از نکات کلیدی مقاله به شرح زیر است:
- راهحل OLS را میتوان به شکل مقیاسکننده نشان داد که پیادهسازی و تفسیر آن را آسان میکند.
- در این مقاله مفهوم مسائل بهینهسازی و نیاز به OLS در تحلیل رگرسیون مورد بحث قرار گرفت و یک فرمول ریاضی و نمونهای از OLS در عمل ارائه شد.
- این مقاله همچنین برخی از محدودیتهای فرم مقیاسکننده راهحل OLS، مانند مقیاسپذیری و مفروضات خطی بودن و واریانس ثابت را برجسته میکند. امیدوارم از این مقاله چیز جدیدی یاد گرفته باشید.
لطفاً اگر احساس میکنید هر نکته/معادلهای در این مقاله نیاز به توضیح دارد یا اگر میخواهید در مورد هر الگوریتم یادگیری ماشین دیگری با چنین جزئیاتی بنویسم، لطفاً نظر بدهید.
مربوط
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- پلاتوبلاک چین. Web3 Metaverse Intelligence. دانش تقویت شده دسترسی به اینجا.
- منبع: https://www.analyticsvidhya.com/blog/2023/01/a-comprehensive-guide-to-ols-regression-part-1/
- 1
- 10
- 214
- 7
- a
- درباره ما
- بالاتر
- مطلق
- دقت
- در میان
- عمل
- فعال
- واقعا
- اضافه
- علاوه بر این
- پس از
- اهداف
- الگوریتم
- الگوریتم
- معرفی
- تخصیص
- قبلا
- در میان
- تحلیل
- تحلیلی
- و
- روش
- محدوده
- مقاله
- اختصاص داده
- در دسترس
- میانگین
- مستقر
- اساسا
- قبل از
- پشت سر
- پشت صحنه
- بودن
- در زیر
- بهترین
- میان
- تعصب
- آبی
- تقویت
- بوستون
- بطور خلاصه
- به ارمغان می آورد
- ساخته
- صدا
- نام
- مورد
- موارد
- مرکز
- معین
- محافل
- ادعا
- کلاس
- نزدیک
- خوشه
- خوشه بندی
- رمز
- ستون
- ترکیب
- توضیح
- عموما
- مقایسه
- پیچیدگی
- جزء
- جامع
- محاسبه
- مفهوم
- نتیجه
- پیکر بندی
- در نتیجه
- در نظر بگیرید
- ثابت
- محدودیت ها
- زمینه
- ادامه
- ارتباط
- دوره
- ایجاد
- بسیار سخت
- جاری
- تاریک
- داده ها
- نقاط داده
- علم اطلاعات
- مجموعه داده ها
- تصمیم
- عمیق
- تعریف می کند
- نشان
- نشان دادن
- وابسته
- مشتقات
- نشات گرفته
- شرح داده شده
- جزئیات
- جزئیات
- توسعه
- تفاوت
- تفاوت
- بحث و تبادل نظر
- بحث کردیم
- توزیع شده
- قطره
- هر
- اقتصاد (Economics)
- هر دو
- دارای جزئیات - بسیط
- مهندسی
- معادلات
- خطا
- خطاهای
- و غیره
- اتر (ETH)
- مثال
- مثال ها
- وجود دارد
- انتظار می رود
- تجربه
- تجارب
- توضیح دهید
- توضیح داده شده
- توضیح می دهد
- توضیح
- اکتشاف
- بیان
- اصطلاحات
- عصاره
- آشنا
- ویژگی
- امکانات
- تغذیه
- زمینه
- شکل
- آمار و ارقام
- نهایی
- سرانجام
- سرمایه گذاری
- پیدا کردن
- پیدا کردن
- پیدا می کند
- نام خانوادگی
- مناسب
- پیروی
- به دنبال آن است
- فرم
- از جانب
- تابع
- دادن
- داده
- هدف
- رفتن
- شیب ها
- گروه
- راهنمایی
- کمک می کند
- زیاد
- های لایت
- امید
- خانه
- HTTPS
- انسان
- تصویر
- بلافاصله
- انجام
- واردات
- مهم
- بهبود
- in
- شامل
- از جمله
- افزایش
- مستقل
- نمونه
- اینترنت
- تفسیر
- شامل
- IT
- کلید
- یاد گرفتن
- یادگیری
- LG
- محدودیت
- لاین
- خطوط
- مطالب
- خاموش
- دستگاه
- فراگیری ماشین
- اصلی
- ساخت
- ساخت
- بسیاری
- نقشه برداری
- مسابقه
- ریاضی
- از نظر ریاضی
- ریاضیات
- حداکثر عرض
- بیشینه ساختن
- به معنی
- ذکر شده
- روش
- روش
- به حداقل رساندن
- به حداقل رساندن
- حد اقل
- مخلوط
- مدل
- مدل
- اکثر
- چندگانه
- نیاز
- نیازهای
- خالص
- شبکه
- عصبی
- شبکه های عصبی
- جدید
- به طور معمول
- عدد
- بی حس
- هدف
- اهداف
- به دست آمده
- ONE
- عملیات
- بهینه
- بهینه سازی
- بهینه سازی
- بهینه
- اصلی
- دیگر
- به طور کلی
- مروری
- بسته
- پارامترهای
- بخش
- افلاطون
- هوش داده افلاطون
- PlatoData
- نقطه
- نقطه
- مقام
- ممکن
- قوی
- پیش بینی
- پیش بینی
- پیش گویی
- پیش بینی
- ارائه شده
- قیمت
- قیمت
- قیمت گذاری
- اصلی
- اصل
- مشکل
- مشکلات
- ارائه
- پــایتــون
- مقدار
- تصادفی
- خواندن
- خوانندگان
- زمان واقعی
- متوجه
- دلیل
- شناختن
- قرمز
- اشاره
- اشاره دارد
- رگرسیون
- ارتباط
- بقایای
- به یاد داشته باشید
- نشان دادن
- نمایندگی
- نمایندگی
- نشان دهنده
- تحقیق
- منابع
- نقش
- اتاق
- همان
- مقیاس پذیری
- صحنه های
- علم
- یادگیری
- بخش
- بخش
- تنظیم
- SGD
- تغییر
- باید
- نشان داده شده
- نشان می دهد
- به طور مشابه
- ساده
- تنها
- مفرد
- اندازه
- شیب
- کوچک
- راه حل
- مزایا
- حل
- برخی از
- چیزی
- فضا
- سرعت
- مربع
- مربع
- شروع
- گام
- مراحل
- هنوز
- راست
- ساختار
- چنین
- مفروض
- جدول
- گرفتن
- Takeaways
- هدف
- کار
- تکنیک
- La
- از طریق
- به
- ابزار
- جمع
- آموزش
- درختان
- درست
- به طور معمول
- اساسی
- فهمیدن
- به روز رسانی
- us
- استفاده کنید
- ارزش
- ارزشها
- مختلف
- بررسی
- قابل رویت
- چی
- که
- در حین
- اراده
- کلمات
- ارزشمند
- خواهد بود
- نوشتن
- کتبی
- X
- شما
- زفیرنت
- صفر