سازمان ها تصمیم گرفته اند دریاچه های داده را در بالای آن بسازند سرویس ذخیره سازی ساده آمازون (Amazon S3) برای چندین سال. دریاچه داده محبوبترین انتخاب برای سازمانها برای ذخیره تمام دادههای سازمانی تولید شده توسط تیمهای مختلف، در دامنههای تجاری، از همه فرمتهای مختلف و حتی در طول تاریخ است. مطابق با یک مطالعه، یک شرکت متوسط شاهد رشد حجم داده های خود با نرخی بیش از 50٪ در سال است و معمولاً به طور متوسط 33 منبع داده منحصر به فرد را برای تجزیه و تحلیل مدیریت می کند.
تیم ها اغلب سعی می کنند هزاران شغل را از پایگاه داده های رابطه ای با الگوی استخراج، تبدیل و بارگذاری (ETL) یکسان تکرار کنند. تلاش زیادی برای حفظ وضعیت شغلی و برنامه ریزی این مشاغل فردی وجود دارد. این رویکرد به تیم ها کمک می کند تا جداول را با تغییرات اندک اضافه کنند و همچنین وضعیت شغلی را با حداقل تلاش حفظ کنند. این می تواند منجر به بهبود بزرگی در جدول زمانی توسعه و ردیابی مشاغل به راحتی شود.
در این پست، ما به شما نشان میدهیم که چگونه میتوانید با استفاده از Apache Iceberg و Apache Iceberg و با یک کار ETL، به راحتی تمام ذخیرههای دادههای رابطهای خود را به صورت خودکار در یک دریاچه داده تراکنشی تکرار کنید. چسب AWS.
معماری راه حل
دریاچه های داده هستند معمولا سازماندهی شده با استفاده از سطل های جداگانه S3 برای سه لایه داده: لایه خام حاوی داده ها به شکل اصلی خود، لایه مرحله حاوی داده های پردازش شده میانی بهینه شده برای مصرف، و لایه تجزیه و تحلیل حاوی داده های انباشته برای موارد استفاده خاص. در لایه خام، جداول معمولاً بر اساس منابع داده سازماندهی می شوند، در حالی که جداول در لایه مرحله بر اساس حوزه های تجاری که به آن تعلق دارند سازماندهی می شوند.
این پست ارائه می دهد AWS CloudFormation الگویی که یک کار چسب AWS را اجرا می کند که مسیر Amazon S3 را برای یک منبع داده از لایه خام دریاچه داده می خواند و داده ها را در جداول Apache Iceberg در لایه مرحله با استفاده از پشتیبانی از چسب AWS برای چارچوبهای دریاچه داده. این کار انتظار دارد که جداول در لایه خام به همین شکل ساختار یافته باشند سرویس مهاجرت پایگاه داده AWS (AWS DMS) آنها را جذب می کند: طرحواره، سپس جدول، سپس فایل های داده.
این راه حل استفاده می کند AWS Systems Manager Parameter Store برای پیکربندی جدول شما باید این پارامتر را تغییر دهید و جداولی را که میخواهید پردازش کنید و نحوه پردازش آن را مشخص کنید، از جمله اطلاعاتی مانند کلید اصلی، پارتیشنها و دامنه تجاری مرتبط. کار از این اطلاعات برای ایجاد خودکار یک پایگاه داده (اگر قبلاً وجود نداشته باشد) برای هر دامنه تجاری، ایجاد جداول Iceberg و انجام بارگیری داده ها استفاده می کند.
در نهایت می توانیم استفاده کنیم آمازون آتنا برای پرس و جو از داده ها در جداول Iceberg.
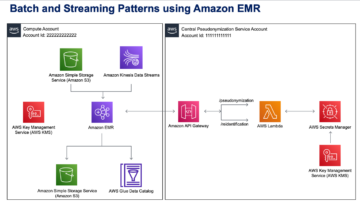
نمودار زیر این معماری را نشان می دهد.

این اجرا دارای ملاحظات زیر است:
- همه جداول از منبع داده باید یک کلید اصلی داشته باشند تا با استفاده از این راه حل تکرار شوند. کلید اصلی می تواند یک ستون یا یک کلید ترکیبی با بیش از یک ستون باشد.
- اگر دریاچه داده حاوی جداولی است که نیازی به upsert ندارند یا کلید اصلی ندارند، میتوانید آنها را از پیکربندی پارامتر حذف کنید و فرآیندهای سنتی ETL را برای وارد کردن آنها به دریاچه داده پیادهسازی کنید. این خارج از محدوده این پست است.
- اگر منابع داده دیگری وجود دارد که باید وارد شوند، میتوانید چندین پشته CloudFormation را مستقر کنید، یکی برای مدیریت هر منبع داده.
- کار چسب AWS برای پردازش داده ها در دو مرحله طراحی شده است: بار اولیه که پس از اتمام کار بارگذاری کامل توسط AWS DMS اجرا می شود و بار افزایشی که براساس برنامه زمانی اجرا می شود که فایل های ضبط داده تغییر (CDC) گرفته شده توسط AWS DMS را اعمال می کند. پردازش افزایشی با استفاده از یک انجام می شود نشانک کار چسب AWS.
۹ مرحله برای تکمیل این آموزش وجود دارد:
- یک نقطه پایانی منبع برای AWS DMS تنظیم کنید.
- راه حل را با استفاده از AWS CloudFormation مستقر کنید.
- وظیفه تکرار AWS DMS را مرور کنید.
- به صورت اختیاری، مجوزهای رمزگذاری و رمزگشایی را اضافه کنید یا سازند دریاچه AWS.
- پیکربندی جدول را در Parameter Store مرور کنید.
- بارگذاری داده های اولیه را انجام دهید.
- بارگذاری اطلاعات افزایشی را انجام دهید.
- نظارت بر مصرف جدول
- برای بارگیری دسته ای افزایشی داده ها برنامه ریزی کنید.
پیش نیازها
قبل از شروع این آموزش، باید قبلاً با Iceberg آشنا باشید. اگر اینطور نیست، میتوانید با تکرار یک جدول به دنبال دستورالعملهای موجود، شروع کنید پیاده سازی UPSERT مبتنی بر CDC در دریاچه داده با استفاده از Apache Iceberg و AWS Glue. علاوه بر این موارد زیر را تنظیم کنید:
یک نقطه پایانی منبع برای AWS DMS تنظیم کنید
قبل از ایجاد وظیفه AWS DMS خود، باید یک نقطه پایانی منبع را برای اتصال به پایگاه داده منبع تنظیم کنیم:
- در کنسول AWS DMS، را انتخاب کنید نقاط پایان در صفحه ناوبری
- را انتخاب کنید نقطه پایانی ایجاد کنید.
- اگر پایگاه داده شما روی Amazon RDS اجرا می شود، انتخاب کنید نمونه RDS DB را انتخاب کنید، سپس نمونه را از لیست انتخاب کنید. در غیر این صورت، موتور منبع را انتخاب کنید و اطلاعات اتصال را از طریق آن ارائه دهید مدیر اسرار AWS یا به صورت دستی
- برای شناسه نقطه پایانی، یک نام برای نقطه پایانی وارد کنید. به عنوان مثال، source-postgresql.
- را انتخاب کنید نقطه پایانی ایجاد کنید.
راه حل را با استفاده از AWS CloudFormation مستقر کنید
با استفاده از الگوی ارائه شده یک پشته CloudFormation ایجاد کنید. مراحل زیر را کامل کنید:
- را انتخاب کنید راه اندازی پشته:

- را انتخاب کنید بعدی.
- یک نام پشته، مانند
transactionaldl-postgresql. - پارامترهای مورد نیاز را وارد کنید:
- DMSS3EndpointIAMRoleARN - نقش IAM ARN برای AWS DMS برای نوشتن داده در آمازون S3.
- ReplicationInstanceArn – نمونه تکرار AWS DMS ARN.
- S3BucketStage – نام سطل موجود مورد استفاده برای لایه مرحله دریاچه داده.
- S3BucketGlue – نام سطل S3 موجود برای ذخیره اسکریپت های AWS Glue.
- S3BucketRaw – نام سطل موجود که برای لایه خام دریاچه داده استفاده می شود.
- SourceEndpointArn – نقطه پایانی AWS DMS ARN که قبلا ایجاد کردید.
- نام منبع - شناسه دلخواه منبع داده برای تکرار (به عنوان مثال،
postgres). این برای تعریف مسیر S3 دریاچه داده (لایه خام) که در آن داده ها ذخیره می شود استفاده می شود.
- پارامترهای زیر را تغییر ندهید:
- SourceS3BucketBlog – نام سطلی که اسکریپت AWS Glue ارائه شده در آن ذخیره می شود.
- SourceS3BucketPrefix - نام پیشوند سطل که اسکریپت AWS Glue ارائه شده در آن ذخیره می شود.
- را انتخاب کنید بعدی دو برابر.
- انتخاب کنید من تصدیق می کنم که AWS CloudFormation ممکن است منابع IAM را با نام های سفارشی ایجاد کند.
- را انتخاب کنید پشته ایجاد کنید.
پس از تقریباً 5 دقیقه، پشته CloudFormation مستقر می شود.
وظیفه تکرار AWS DMS را مرور کنید
استقرار AWS CloudFormation یک نقطه پایانی هدف AWS DMS برای شما ایجاد کرد. به دلیل دو تنظیمات خاص نقطه پایانی، داده ها همانطور که ما به آن نیاز داریم در Amazon S3 وارد می شوند.
- در کنسول AWS DMS، را انتخاب کنید نقاط پایان در صفحه ناوبری
- نقطه پایانی که با آن شروع می شود را جستجو و انتخاب کنید
dmsIcebergs3endpoint. - تنظیمات نقطه پایانی را مرور کنید:
DataFormatبه عنوان مشخص شده استparquet.TimestampColumnNameستون را اضافه خواهد کردlast_update_timeبا تاریخ ایجاد رکوردها در آمازون S3.

این استقرار همچنین یک وظیفه تکرار AWS DMS ایجاد می کند که با آن شروع می شود dmsicebergtask.
- را انتخاب کنید وظایف تکرار در پنجره ناوبری و جستجوی کار.
خواهید دید که نوع وظیفه به عنوان مشخص شده است بار کامل، تکرار مداوم. AWS DMS یک بار کامل اولیه از داده های موجود را انجام می دهد و سپس فایل های افزایشی را با تغییرات انجام شده در پایگاه داده منبع ایجاد می کند.
بر قوانین نقشه برداری تب، دو نوع قانون وجود دارد:
- یک قانون انتخاب با نام طرحواره منبع و جداول که از پایگاه داده منبع دریافت می شود. به طور پیش فرض، از پایگاه داده نمونه ارائه شده در پیش نیازها استفاده می کند.
dms_sample، و تمام جداول با کلمه کلیدی %. - دو قانون تبدیل که در فایل های هدف در آمازون S3 نام طرح و نام جدول را به عنوان ستون درج می کند. این کار توسط AWS Glue ما استفاده میشود تا بدانیم فایلهای موجود در دریاچه داده با کدام جداول مطابقت دارند.
برای کسب اطلاعات بیشتر در مورد نحوه سفارشی کردن این برای منابع داده خود، به مراجعه کنید قوانین و اقدامات انتخاب.

بیایید برخی از تنظیمات را تغییر دهیم تا آماده سازی کار خود را به پایان برسانیم.
- بر اعمال منو ، انتخاب کنید تغییر دادن.
- در تنظیمات وظیفه بخش، زیر پس از بارگذاری کامل، کار را متوقف کنید، انتخاب کنید پس از اعمال تغییرات حافظه پنهان متوقف شوید.
به این ترتیب، میتوانیم بارگذاری اولیه و تولید فایل افزایشی را در دو مرحله مختلف کنترل کنیم. ما از این رویکرد دو مرحله ای برای اجرای کار چسب AWS در هر مرحله یک بار استفاده می کنیم.
- تحت سیاهههای کار، انتخاب کنید گزارشهای CloudWatch را روشن کنید.
- را انتخاب کنید ذخیره.
- حدود 1 دقیقه صبر کنید تا وضعیت وظیفه انتقال پایگاه داده به عنوان نشان داده شود آماده تحویل.
مجوزهای رمزگذاری و رمزگشایی یا Lake Formation را اضافه کنید
به صورت اختیاری، می توانید مجوزهایی برای رمزگذاری و رمزگشایی یا Lake Formation اضافه کنید.
مجوزهای رمزگذاری و رمزگشایی را اضافه کنید
اگر سطل های S3 شما که برای لایه های خام و مرحله استفاده می شوند با استفاده از رمزگذاری شده اند سرویس مدیریت کلید AWS کلیدهای مدیریت شده توسط مشتری (AWS KMS)، باید مجوزهایی را اضافه کنید تا به کار چسب AWS اجازه دهید به داده ها دسترسی داشته باشد:
مجوزهای Lake Formation را اضافه کنید
اگر مجوزها را با استفاده از Lake Formation مدیریت می کنید، باید به کار AWS Glue خود اجازه دهید تا پایگاه داده ها و جداول دامنه شما را از طریق نقش IAM ایجاد کند. GlueJobRole.
- اعطای مجوز برای ایجاد پایگاه های داده (برای دستورالعمل ها، مراجعه کنید ایجاد پایگاه داده).
- اعطای مجوزهای SUPER به
defaultپایگاه داده. - مجوزهای مکان داده را اعطا کنید.
- اگر پایگاه داده را به صورت دستی ایجاد می کنید، به همه پایگاه های داده مجوز ایجاد جداول بدهید. رجوع شود به اعطای مجوزهای جدول با استفاده از کنسول Lake Formation و روش منبع نامگذاری شده or اعطای مجوزهای کاتالوگ داده با استفاده از روش LF-TBAC با توجه به مورد استفاده شما
پس از تکمیل مرحله بعدی بارگیری داده های اولیه، مطمئن شوید که مجوزهایی را نیز برای درخواست مصرف کنندگان از جداول اضافه کنید. نقش شغلی مالک تمام جداول ایجاد شده خواهد شد و مدیر دریاچه داده میتواند به کاربران دیگر کمک هزینه کند.
تنظیمات جدول را در Parameter Store مرور کنید
کار چسب AWS که انتقال داده ها را در جداول Iceberg انجام می دهد از مشخصات جدول ارائه شده در Parameter Store استفاده می کند. مراحل زیر را تکمیل کنید تا ذخیره پارامتر را که به طور خودکار برای شما پیکربندی شده است مرور کنید. در صورت نیاز، با توجه به نیاز خود اصلاح کنید.
- در کنسول Parameter Store، را انتخاب کنید پارامترهای من در صفحه ناوبری
پشته CloudFormation دو پارامتر ایجاد کرد:
iceberg-configبرای تنظیمات شغلیiceberg-tablesبرای پیکربندی جدول
- پارامتر را انتخاب کنید میزهای کوه یخ.
ساختار JSON حاوی اطلاعاتی است که AWS Glue برای خواندن داده ها و نوشتن جداول Iceberg در دامنه هدف استفاده می کند:
- یک شی در هر جدول - نام شی با استفاده از نام طرحواره، نقطه و نام جدول ایجاد می شود. مثلا،
schema.table. - کلید اصلی - این باید برای هر جدول منبع مشخص شود. شما می توانید یک ستون یا یک لیست ستون های جدا شده با کاما (بدون فاصله) ارائه دهید.
- partitionCols - این به صورت اختیاری ستون ها را برای جداول هدف تقسیم بندی می کند. اگر نمی خواهید جداول پارتیشن بندی شده ایجاد کنید، یک رشته خالی ارائه دهید. در غیر این صورت، یک ستون یا فهرستی از ستونهای جدا شده با کاما برای استفاده (بدون فاصله) ارائه دهید.
- اگر میخواهید از منبع داده خود استفاده کنید، از کد JSON زیر استفاده کنید و متن را به زبان CAPS از الگوی ارائه شده جایگزین کنید. اگر از منبع داده نمونه ارائه شده استفاده می کنید، تنظیمات پیش فرض را حفظ کنید:
{ "SCHEMA_NAME.TABLE_NAME_1": { "primaryKey": "ONLY_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "" }, "SCHEMA_NAME.TABLE_NAME_2": { "primaryKey": "FIRST_PRIMARY_KEY,SECOND_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "PARTITION_COLUMN_ONE,PARTITION_COLUMN_TWO" }
}- را انتخاب کنید ذخیره تغییرات.
بارگذاری داده های اولیه را انجام دهید
اکنون که پیکربندی مورد نیاز به پایان رسیده است، داده های اولیه را دریافت می کنیم. این مرحله شامل سه بخش است: وارد کردن دادهها از پایگاه داده رابطهای منبع به لایه خام دریاچه داده، ایجاد جداول کوه یخ در لایه مرحله دریاچه داده، و تأیید نتایج با استفاده از آتنا.
داده ها را به لایه خام دریاچه داده وارد کنید
برای دریافت دادهها از منبع داده رابطهای (اگر از نمونه ارائه شده PostgreSQL استفاده میکنید) به دریاچه داده تراکنشی ما با استفاده از Iceberg، مراحل زیر را کامل کنید:
- در کنسول AWS DMS، را انتخاب کنید وظایف مهاجرت پایگاه داده در صفحه ناوبری
- تکلیف تکراری که ایجاد کردید را انتخاب کنید و روی اعمال منو ، انتخاب کنید راه اندازی مجدد/از سرگیری.
- حدود 5 دقیقه صبر کنید تا کار تکرار کامل شود. شما می توانید جداول مصرف شده بر روی را نظارت کنید آمار برگه کار تکرار.

پس از چند دقیقه، کار با پیام به پایان می رسد بار کامل کامل شد.
- در کنسول آمازون S3، سطلی را که به عنوان لایه خام تعریف کرده اید انتخاب کنید.
تحت پیشوند S3 تعریف شده در AWS DMS (به عنوان مثال، postgres، باید سلسله مراتبی از پوشه ها را با ساختار زیر مشاهده کنید:
- طرح
- نام جدول
LOAD00000001.parquetLOAD0000000N.parquet
- نام جدول

اگر سطل S3 شما خالی است، بررسی کنید عیب یابی وظایف مهاجرت در سرویس مهاجرت پایگاه داده AWS قبل از اجرای کار چسب AWS.
ایجاد و وارد کردن داده ها در جداول Iceberg
قبل از اجرای کار، اجازه دهید اسکریپت کار چسب AWS ارائه شده به عنوان بخشی از پشته CloudFormation را برای درک رفتار آن مرور کنیم.
- در کنسول AWS Glue Studio، را انتخاب کنید شغل ها در صفحه ناوبری
- به دنبال شغلی باشید که با آن شروع می شود
IcebergJob-و پسوندی از نام پشته CloudFormation شما (به عنوان مثال،IcebergJob-transactionaldl-postgresql). - شغل را انتخاب کنید.

اسکریپت job پیکربندی مورد نیاز خود را از Parameter Store دریافت می کند. کارکرد getConfigFromSSM() پیکربندی های مرتبط با کار مانند سطل های منبع و هدف را از جایی که داده ها باید خوانده و نوشته شوند را برمی گرداند. متغیر ssmparam_table_values حاوی اطلاعات مربوط به جدول مانند دامنه داده، نام جدول، ستون های پارتیشن و کلید اصلی جداول است که باید وارد شوند. کد پایتون زیر را ببینید:
# Main application
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'stackName'])
SSM_PARAMETER_NAME = f"{args['stackName']}-iceberg-config"
SSM_TABLE_PARAMETER_NAME = f"{args['stackName']}-iceberg-tables" # Parameters for job
rawS3BucketName, rawBucketPrefix, stageS3BucketName, warehouse_path = getConfigFromSSM(SSM_PARAMETER_NAME)
ssm_param_table_values = json.loads(ssmClient.get_parameter(Name = SSM_TABLE_PARAMETER_NAME)['Parameter']['Value'])
dropColumnList = ['db','table_name', 'schema_name','Op', 'last_update_time', 'max_op_date']این اسکریپت از یک نام کاتالوگ دلخواه برای Iceberg استفاده می کند که به عنوان my_catalog تعریف می شود. این در کاتالوگ داده AWS Glue با استفاده از تنظیمات Spark پیاده سازی شده است، بنابراین یک عملیات SQL که به my_catalog اشاره می کند در کاتالوگ داده اعمال می شود. کد زیر را ببینید:
catalog_name = 'my_catalog'
errored_table_list = [] # Iceberg configuration
spark = SparkSession.builder .config('spark.sql.warehouse.dir', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') .config(f'spark.sql.catalog.{catalog_name}.warehouse', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}.catalog-impl', 'org.apache.iceberg.aws.glue.GlueCatalog') .config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.aws.s3.S3FileIO') .config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') .getOrCreate()
اسکریپت روی جداول تعریف شده در Parameter Store تکرار می شود و منطقی را برای تشخیص وجود جدول و اینکه داده های ورودی بار اولیه یا upsert هستند انجام می دهد:
# Iteration over tables stored on Parameter Store
for key in ssm_param_table_values: # Get table data isTableExists = False schemaName, tableName = key.split('.') logger.info(f'Processing table : {tableName}')La initialLoadRecordsSparkSQL() تابع زمانی که هیچ ستون عملیاتی در فایل های S3 وجود ندارد، داده های اولیه را بارگذاری می کند. AWS DMS این ستون را فقط به فایل های داده پارکت تولید شده توسط تکرار پیوسته (CDC) اضافه می کند. بارگذاری داده ها با استفاده از دستور INSERT INTO با SparkSQL انجام می شود. کد زیر را ببینید:
sqltemp = Template(""" INSERT INTO $catalog_name.$dbName.$tableName ($insertTableColumnList) SELECT $insertTableColumnList FROM insertTable $partitionStrSQL """)
SQLQUERY = sqltemp.substitute( catalog_name = catalog_name, dbName = dbName, tableName = tableName, insertTableColumnList = insertTableColumnList[ : -1], partitionStrSQL = partitionStrSQL) logger.info(f'****SQL QUERY IS : {SQLQUERY}')
spark.sql(SQLQUERY)
اکنون کار چسب AWS را اجرا می کنیم تا داده های اولیه را در جداول Iceberg وارد کنیم. پشته CloudFormation را اضافه می کند --datalake-formats پارامتر، اضافه کردن کتابخانه های مورد نیاز Iceberg به کار.
- را انتخاب کنید کار را اجرا کن.
- را انتخاب کنید کار اجرا می شود برای نظارت بر وضعیت صبر کنید تا وضعیت مشخص شود اجرا با موفقیت انجام شد.
داده های بارگذاری شده را تأیید کنید
برای تأیید اینکه کار داده ها را همانطور که انتظار می رود پردازش کرده است، مراحل زیر را انجام دهید:
- در کنسول آتنا، انتخاب کنید ویرایشگر پرس و جو در صفحه ناوبری
- تایید
AwsDataCatalogبه عنوان منبع داده انتخاب شده است. - تحت پایگاه داده، دامنه داده ای را که می خواهید کاوش کنید، بر اساس پیکربندی که در ذخیره پارامتر تعریف کرده اید، انتخاب کنید. در صورت استفاده از پایگاه داده نمونه ارائه شده، استفاده کنید
sports.
تحت جداول و نماها، می توانیم لیست جداول ایجاد شده توسط کار چسب AWS را مشاهده کنیم.
- منوی گزینه ها (سه نقطه) را در کنار نام جدول اول انتخاب کنید، سپس انتخاب کنید پیش نمایش داده ها.
می توانید داده های بارگذاری شده در جداول Iceberg را ببینید. 
بارگذاری اطلاعات افزایشی را انجام دهید
اکنون ما شروع به گرفتن تغییرات از پایگاه داده رابطه ای خود و اعمال آنها در دریاچه داده های تراکنش می کنیم. این مرحله نیز به سه بخش تقسیم میشود: ثبت تغییرات، اعمال آنها در جداول Iceberg و تأیید نتایج.
ثبت تغییرات از پایگاه داده رابطه ای
با توجه به پیکربندی که ما مشخص کردیم، پس از اجرای فاز بار کامل، کار تکرار متوقف شد. اکنون کار را مجدداً راه اندازی می کنیم تا فایل های افزایشی را با تغییرات به لایه خام دریاچه داده اضافه کنیم.
- در کنسول AWS DMS، وظیفهای را که قبلاً ایجاد و اجرا کردهایم انتخاب کنید.
- بر اعمال منو ، انتخاب کنید ادامه.
- را انتخاب کنید کار را شروع کنید برای شروع ثبت تغییرات
- برای راه اندازی ایجاد فایل جدید در دریاچه داده، درج، به روز رسانی یا حذف را بر روی جداول پایگاه داده منبع خود با استفاده از ابزار مدیریت پایگاه داده ترجیحی خود انجام دهید. اگر از پایگاه داده نمونه ارائه شده استفاده می کنید، می توانید دستورات SQL زیر را اجرا کنید:
UPDATE dms_sample.nfl_stadium_data_upd
SET seatin_capacity=93703
WHERE team = 'Los Angeles Rams' and sport_location_id = '31'; update dms_sample.mlb_data set bats = 'R'
where mlb_id=506560 and bats='L'; update dms_sample.sporting_event set start_date = current_date where id=11 and sold_out=0;
- در صفحه جزئیات کار AWS DMS، را انتخاب کنید آمار جدول برای مشاهده تغییرات ثبت شده، را انتخاب کنید.

- لایه خام دریاچه داده را باز کنید تا فایل جدیدی را پیدا کنید که تغییرات افزایشی را در پیشوند هر جدول، به عنوان مثال در زیر
sporting_eventپیشوند
رکورد با تغییرات برای sporting_event جدول مانند تصویر زیر است.

توجه کنید Op ستون در ابتدا با یک به روز رسانی مشخص شد (U). همچنین، دومین مقدار تاریخ/زمان، ستون کنترلی است که توسط AWS DMS با زمان ثبت تغییر اضافه شده است.

با استفاده از چسب AWS تغییرات را روی جداول Iceberg اعمال کنید
اکنون کار AWS Glue را دوباره اجرا می کنیم و از آنجایی که نشانک کار فعال است، به طور خودکار فقط فایل های افزایشی جدید را پردازش می کند. بیایید بررسی کنیم که چگونه کار می کند.
La dedupCDCRecords() تابع، دادهها را حذف میکند، زیرا تغییرات متعدد در یک شناسه رکورد واحد را میتوان در یک فایل داده در آمازون S3 ثبت کرد. Deduplication بر اساس انجام می شود last_update_time ستون اضافه شده توسط AWS DMS که نشان دهنده زمان ثبت تغییر است. کد پایتون زیر را ببینید:
def dedupCDCRecords(inputDf, keylist): IDWindowDF = Window.partitionBy(*keylist).orderBy(inputDf.last_update_time).rangeBetween(-sys.maxsize, sys.maxsize) inputDFWithTS = inputDf.withColumn('max_op_date', max(inputDf.last_update_time).over(IDWindowDF)) NewInsertsDF = inputDFWithTS.filter('last_update_time=max_op_date').filter("op='I'") UpdateDeleteDf = inputDFWithTS.filter('last_update_time=max_op_date').filter("op IN ('U','D')") finalInputDF = NewInsertsDF.unionAll(UpdateDeleteDf) return finalInputDFدر خط 99، upsertRecordsSparkSQL() تابع upsert را به روشی مشابه بار اولیه انجام می دهد، اما این بار با دستور SQL MERGE.
تغییرات اعمال شده را مرور کنید
کنسول Athena را باز کنید و یک کوئری اجرا کنید که رکوردهای تغییر یافته را در پایگاه داده منبع انتخاب می کند. اگر از پایگاه داده نمونه ارائه شده استفاده می کنید، از یکی از پرس و جوهای SQL زیر استفاده کنید:
SELECT * FROM "sports"."nfl_stadiu_data_upd"
WHERE team = 'Los Angeles Rams' and sport_location_id = 31
LIMIT 1;

نظارت بر مصرف جدول
اسکریپت کار چسب AWS با ساده کدگذاری شده است مدیریت استثناء پایتون برای گرفتن خطاها در طول پردازش یک جدول خاص. نشانک کار پس از اتمام موفقیتآمیز پردازش هر جدول ذخیره میشود تا در صورت تکرار کار برای جداول دارای خطا، از پردازش مجدد جداول جلوگیری شود.
La رابط خط فرمان AWS (AWS CLI) a get-job-bookmark دستور برای چسب AWS که بینشی از وضعیت نشانک برای هر جدول پردازش شده ارائه می دهد.
- در کنسول AWS Glue Studio، شغل ETL را انتخاب کنید.
- انتخاب کار اجرا می شود را برگه و شناسه اجرای کار را کپی کنید.
- دستور زیر را در ترمینال تأیید شده برای AWS CLI اجرا کنید و جایگزین کنید
<GLUE_JOB_RUN_ID>در خط 1 با مقداری که کپی کردید. اگر پشته CloudFormation شما نامی نداردtransactionaldl-postgresql، نام شغل خود را در خط 2 اسکریپت وارد کنید:
jobrun=<GLUE_JOB_RUN_ID>
jobname=IcebergJob-transactionaldl-postgresql
aws glue get-job-bookmark --job-name jobname --run-id $jobrunدر این راه حل، زمانی که پردازش جدول باعث استثنا می شود، کار AWS Glue بر اساس این منطق شکست نخواهد خورد. در عوض، جدول به آرایه ای اضافه می شود که پس از اتمام کار چاپ می شود. در چنین سناریویی، پس از تلاش برای پردازش بقیه جداول شناسایی شده در منبع داده خام، کار به عنوان ناموفق علامت گذاری می شود. به این ترتیب، جداول بدون خطا لازم نیست منتظر بمانند تا کاربر مشکل جداول متضاد را شناسایی و حل کند. کاربر می تواند با استفاده از وضعیت اجرای کار AWS Glue مشکلاتی را به سرعت تشخیص دهد و با استفاده از گزارش های CloudWatch برای اجرای کار، تشخیص دهد که کدام جداول خاص باعث ایجاد مشکل شده اند.
- اسکریپت job این ویژگی را با کد پایتون زیر پیاده سازی می کند:
# Performed for every table try: # Table processing logic except Exception as e: logger.info(f'There is an issue with table: {tableName}') logger.info(f'The exception is : {e}') errored_table_list.append(tableName) continue job.commit()
if (len(errored_table_list)): logger.info('Total number of errored tables are ',len(errored_table_list)) logger.info('Tables that failed during processing are ', *errored_table_list, sep=', ') raise Exception(f'***** Some tables failed to process.')تصویر زیر نشان میدهد که چگونه گزارشهای CloudWatch به دنبال جداولی هستند که باعث خطا در پردازش میشوند.

همراستا با لنز تجزیه و تحلیل داده چارچوب با معماری خوب AWS در روشهای مختلف، میتوانید مکانیسمهای کنترلی پیچیدهتری را برای شناسایی و اطلاع ذینفعان در صورت ظاهر شدن خطاها در خطوط انتقال داده، تطبیق دهید. به عنوان مثال، می توانید از یک استفاده کنید آمازون DynamoDB جدول کنترل برای ذخیره تمام جداول و کارهای اجرا شده با خطا یا استفاده از سرویس اطلاع رسانی ساده آمازون (Amazon SNS) به ارسال هشدار به اپراتورها زمانی که معیارهای خاصی برآورده شود.
برای بارگیری دسته ای افزایشی داده ها برنامه ریزی کنید
پشته CloudFormation یک پل رویداد آمازون قانون (به طور پیشفرض غیرفعال است) که میتواند کار AWS Glue را برای اجرا در یک زمانبندی فعال کند. برای ارائه برنامه زمانی خود و فعال کردن قانون، مراحل زیر را انجام دهید:
- در کنسول EventBridge، را انتخاب کنید قوانین در صفحه ناوبری
- قانون پیشوند با نام پشته CloudFormation خود را به دنبال آن جستجو کنید
JobTrigger(مثلا،transactionaldl-postgresql-JobTrigger-randomvalue). - قانون را انتخاب کنید.
- تحت برنامه رویداد، انتخاب کنید ویرایش.
برنامه پیشفرض به گونهای پیکربندی شده است که هر ساعت فعال شود.
- برنامه زمانی را که می خواهید کار را اجرا کنید ارائه دهید.
- علاوه بر این، می توانید از یک عبارت cron EventBridge با انتخاب یک برنامه ریزی دقیق.

- پس از اتمام تنظیم عبارت cron، را انتخاب کنید بعدی سه بار، و در نهایت انتخاب کنید به روز رسانی قانون برای ذخیره تغییرات
این قانون بهطور پیشفرض غیرفعال است تا به شما اجازه دهد ابتدا بارگذاری داده اولیه را اجرا کنید.
- قانون را با انتخاب فعال کنید فعال.
شما می توانید با استفاده از نظارت برای مشاهده فراخوانی قوانین، یا مستقیماً روی چسب AWS، برگه را بزنید Job Run جزئیات.
نتیجه
پس از استقرار این راه حل، شما جذب جداول خود را در یک منبع داده رابطه ای به طور خودکار انجام داده اید. سازمانهایی که از دریاچه داده بهعنوان پلتفرم داده مرکزی خود استفاده میکنند، معمولاً نیاز به مدیریت چندین و گاهی حتی دهها منبع داده دارند. همچنین موارد استفاده بیشتر و بیشتر سازمان ها را ملزم به پیاده سازی قابلیت های تراکنش در دریاچه داده می کند. میتوانید از این راهحل برای تسریع پذیرش چنین قابلیتهایی در تمام منابع دادههای رابطهای خود استفاده کنید تا موارد استفاده تجاری جدید را فعال کنید و فرآیند پیادهسازی را خودکار کنید تا ارزش بیشتری از دادههای شما به دست آورد.
درباره نویسنده
 لوئیس جراردو بائزا یک معمار کلان داده در آزمایشگاه داده خدمات وب آمازون (AWS) است. او 12 سال تجربه در کمک به سازمانها در بخشهای بهداشت، مالی و آموزشی برای اتخاذ برنامههای معماری سازمانی، رایانش ابری و قابلیتهای تجزیه و تحلیل داده دارد. لوئیس در حال حاضر به سازمانها در سرتاسر آمریکای لاتین کمک میکند تا ابتکارات دادههای استراتژیک را تسریع کنند.
لوئیس جراردو بائزا یک معمار کلان داده در آزمایشگاه داده خدمات وب آمازون (AWS) است. او 12 سال تجربه در کمک به سازمانها در بخشهای بهداشت، مالی و آموزشی برای اتخاذ برنامههای معماری سازمانی، رایانش ابری و قابلیتهای تجزیه و تحلیل داده دارد. لوئیس در حال حاضر به سازمانها در سرتاسر آمریکای لاتین کمک میکند تا ابتکارات دادههای استراتژیک را تسریع کنند.
 SaiKiran Reddy Aenugu یک معمار داده در آزمایشگاه داده خدمات وب آمازون (AWS) است. او دارای 10 سال تجربه در اجرای فرآیندهای بارگذاری، تبدیل و تجسم داده است. SaiKiran در حال حاضر به سازمانها در آمریکای شمالی کمک میکند تا معماریهای مدرن داده مانند دریاچههای داده و مش داده را اتخاذ کنند. او در بخش های خرده فروشی، خطوط هوایی و مالی تجربه دارد.
SaiKiran Reddy Aenugu یک معمار داده در آزمایشگاه داده خدمات وب آمازون (AWS) است. او دارای 10 سال تجربه در اجرای فرآیندهای بارگذاری، تبدیل و تجسم داده است. SaiKiran در حال حاضر به سازمانها در آمریکای شمالی کمک میکند تا معماریهای مدرن داده مانند دریاچههای داده و مش داده را اتخاذ کنند. او در بخش های خرده فروشی، خطوط هوایی و مالی تجربه دارد.
 نارندرا مرلا یک معمار داده در آزمایشگاه داده خدمات وب آمازون (AWS) است. او 12 سال تجربه در طراحی و تولید خطوط لوله داده بلادرنگ و دسته ای و ساخت دریاچه های داده در محیط های ابری و داخلی دارد. Narendra در حال حاضر به سازمانها در آمریکای شمالی کمک میکند تا معماریهای دادهای قوی بسازند و طراحی کنند و در بخشهای مخابراتی و مالی تجربه دارد.
نارندرا مرلا یک معمار داده در آزمایشگاه داده خدمات وب آمازون (AWS) است. او 12 سال تجربه در طراحی و تولید خطوط لوله داده بلادرنگ و دسته ای و ساخت دریاچه های داده در محیط های ابری و داخلی دارد. Narendra در حال حاضر به سازمانها در آمریکای شمالی کمک میکند تا معماریهای دادهای قوی بسازند و طراحی کنند و در بخشهای مخابراتی و مالی تجربه دارد.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- پلاتوبلاک چین. Web3 Metaverse Intelligence. دانش تقویت شده دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/big-data/automate-replication-of-relational-sources-into-a-transactional-data-lake-with-apache-iceberg-and-aws-glue/
- 1
- 10
- 100
- 102
- 107
- 7
- a
- درباره ما
- شتاب دادن
- دسترسی
- مطابق
- اذعان
- در میان
- وفق دادن
- اضافه
- اضافی
- علاوه بر این
- می افزاید:
- مدیر سایت
- حکومت
- اتخاذ
- اتخاذ
- پس از
- شرکت هواپیمایی
- معرفی
- قبلا
- آمازون
- آمازون آتنا
- آمازون RDS
- آمازون خدمات وب
- خدمات وب آمازون (AWS)
- امریکا
- تحلیل
- علم تجزیه و تحلیل
- و
- آنجلس
- آپاچی
- ظاهر شدن
- کاربرد
- اعمال می شود
- با استفاده از
- روش
- تقریبا
- معماری
- صف
- مرتبط است
- تأیید اعتبار
- خودکار بودن
- خودکار
- بطور خودکار
- اتوماسیون
- میانگین
- اجتناب از
- AWS
- AWS CloudFormation
- چسب AWS
- مستقر
- خفاش ها
- زیرا
- شدن
- قبل از
- شروع
- بزرگ
- بزرگ داده
- ساختن
- سازنده
- بنا
- کسب و کار
- می توانید دریافت کنید
- قابلیت های
- کلاه
- گرفتن
- ضبط
- مورد
- موارد
- کاتالوگ
- کشتی
- علت
- علل
- باعث می شود
- CDC
- مرکزی
- معین
- تغییر دادن
- تبادل
- انتخاب
- را انتخاب کنید
- انتخاب
- برگزیده
- ابر
- محاسبات ابری
- رمز
- ستون
- ستون ها
- شرکت
- کامل
- محاسبه
- پیکر بندی
- پیکربندی
- تکرار
- درگیری
- اتصال
- ارتباط
- ملاحظات
- کنسول
- مصرف کنندگان
- مصرف
- شامل
- ادامه دادن
- مداوم
- کنترل
- میتوانست
- ایجاد
- ایجاد شده
- ایجاد
- ایجاد
- ایجاد
- ضوابط
- در حال حاضر
- سفارشی
- مشتری
- سفارشی
- داده ها
- تجزیه و تحلیل داده ها
- دریاچه دریاچه
- بستر داده
- پایگاه داده
- پایگاه های داده
- تاریخ
- به طور پیش فرض
- مشخص
- گسترش
- مستقر
- استقرار
- گسترش
- مستقر می کند
- طرح
- طراحی
- طراحی
- جزئیات
- شناسایی شده
- پروژه
- مختلف
- مستقیما
- غیر فعال
- تقسیم شده
- نمی کند
- دامنه
- حوزه
- آیا
- در طی
- هر
- پیش از آن
- به آسانی
- آموزش
- تلاش
- هر دو
- قادر ساختن
- فعال
- رمزگذاری
- رمزگذاری
- نقطه پایانی
- موتور
- وارد
- سرمایه گذاری
- محیط
- خطاهای
- اتر (ETH)
- حتی
- هر
- مثال
- بیش از
- جز
- استثنا
- موجود
- وجود دارد
- انتظار می رود
- انتظار می رود
- تجربه
- اکتشاف
- ضمیمهها
- عصاره
- ناموفق
- آشنا
- روش
- ویژگی
- کمی از
- پرونده
- فایل ها
- سرانجام
- سرمایه گذاری
- مالی
- پیدا کردن
- پایان
- نام خانوادگی
- به دنبال
- پیروی
- برای مصرف کنندگان
- فرم
- تشکیل
- چارچوب
- از جانب
- کامل
- تابع
- تولید
- نسل
- دریافت کنید
- اعطا کردن
- کمک های مالی
- در حال رشد
- دسته
- بهداشت و درمان
- کمک
- کمک می کند
- سلسله مراتب
- تاریخ
- برگزاری
- چگونه
- چگونه
- HTML
- HTTPS
- بزرگ
- IAM
- شناسایی
- شناسه
- شناسایی می کند
- شناسایی
- انجام
- پیاده سازی
- اجرا
- اجرای
- پیاده سازی می کند
- بهبود
- in
- شامل
- شامل
- از جمله
- وارد شونده
- نشان می دهد
- فرد
- اطلاعات
- اول
- ابتکارات
- درج می کند
- بینش
- نمونه
- در عوض
- دستورالعمل
- حد واسط
- موضوع
- مسائل
- IT
- تکرار
- کار
- شغل ها
- json
- نگاه داشتن
- کلید
- کلید
- دانستن
- آزمایشگاه
- دریاچه
- لاتین
- لاتین امریکا
- لایه
- لایه
- رهبری
- یاد گرفتن
- کتابخانه ها
- محدود
- لاین
- فهرست
- بار
- بارگیری
- بارهای
- محل
- نگاه کنيد
- مطالب
- آنها
- لس آنجلس
- خیلی
- اصلی
- حفظ
- ساخت
- اداره می شود
- مدیریت
- مدیر
- مدیریت
- دستی
- بسیاری
- نقشه برداری
- علامت گذاری شده
- فهرست
- ادغام کردن
- پیام
- قدرت
- مهاجرت
- حد اقل
- دقیقه
- دقیقه
- مدرن
- تغییر
- مانیتور
- نظارت بر
- بیش
- اکثر
- محبوبترین
- چندگانه
- نام
- تحت عنوان
- نام
- هدایت
- جهت یابی
- نیاز
- ضروری
- نیازهای
- جدید
- بعد
- شمال
- شمال امریکا
- اخطار
- عدد
- هدف
- اشیاء
- ONE
- مداوم
- OP
- عمل
- بهینه
- گزینه
- سازمانی
- سازمان های
- سازمان یافته
- اصلی
- در غیر این صورت
- خارج از
- خود
- مالک
- قطعه
- پارامتر
- پارامترهای
- بخش
- بخش
- مسیر
- الگو
- انجام دادن
- انجام
- انجام می دهد
- دوره
- مجوز
- فاز
- سکو
- افلاطون
- هوش داده افلاطون
- PlatoData
- محبوب
- پست
- postgresql
- شیوه های
- مرجح
- پیش نیازها
- در حال حاضر
- اصلی
- مشکل
- روند
- فرآیندهای
- در حال پردازش
- ساخته
- برنامه ها
- ارائه
- ارائه
- فراهم می کند
- پــایتــون
- به سرعت
- بالا بردن
- نرخ
- خام
- داده های خام
- خواندن
- زمان واقعی
- رکورد
- سوابق
- جایگزین کردن
- تکرار شده
- تکرار
- نیاز
- ضروری
- منابع
- منابع
- REST
- نتایج
- خرده فروشی
- برگشت
- بازده
- این فایل نقد می نویسید:
- تنومند
- نقش
- قانون
- قوانین
- دویدن
- در حال اجرا
- همان
- ذخیره
- سناریو
- برنامه
- حوزه
- اسکریپت
- جستجو
- دوم
- بخش ها
- مشاهده
- انتخاب شد
- انتخاب
- انتخاب
- جداگانه
- خدمات
- تنظیم
- محیط
- تنظیمات
- باید
- نشان
- نشان می دهد
- مشابه
- ساده
- پس از
- تنها
- So
- راه حل
- حل می کند
- برخی از
- مصنوعی
- منبع
- منابع
- فضاها
- جرقه
- خاص
- مشخصات
- مشخص شده
- ورزش ها
- SQL
- پشته
- پشته
- صحنه
- سهامداران
- شروع
- آغاز شده
- راه افتادن
- شروع می شود
- ایالات
- ارقام
- وضعیت
- گام
- مراحل
- متوقف شد
- ذخیره سازی
- opbevare
- ذخیره شده
- پرده
- استراتژیک
- ساختار
- ساخت یافته
- استودیو
- موفقیت
- چنین
- فوق العاده
- پشتیبانی
- سیستم های
- جدول
- هدف
- کار
- وظایف
- تیم
- تیم ها
- مخابراتی
- قالب
- پایانه
- La
- منبع
- شان
- هزاران نفر
- سه
- از طریق
- زمان
- جدول زمانی
- بار
- برچسب زمان
- به
- ابزار
- بالا
- جمع
- پیگردی
- سنتی
- معامله ای
- دگرگون کردن
- دگرگونی
- ماشه
- آموزش
- انواع
- زیر
- فهمیدن
- منحصر به فرد
- بروزرسانی
- به روز رسانی
- استفاده کنید
- مورد استفاده
- کاربر
- کاربران
- معمولا
- ارزش
- تایید
- چشم انداز
- تجسم
- حجم
- صبر کنيد
- انبار کالا
- وب
- خدمات وب
- که
- اراده
- در داخل
- بدون
- با این نسخهها کار
- نوشتن
- کتبی
- یامل
- سال
- سال
- شما
- زفیرنت