دنیایی که ما در آن زندگی می کنیم دائما در حال تغییر است، و همچنین داده هایی که برای ساخت مدل ها جمع آوری می شود، تغییر می کند. یکی از مشکلاتی که اغلب در محیط های تولید دیده می شود این است که مدل مستقر شده مانند مرحله آموزش رفتار نمی کند. این مفهوم به طور کلی نامیده می شود رانش داده or تغییر مجموعه دادهو میتواند توسط عوامل زیادی ایجاد شود، مانند سوگیری در دادههای نمونهگیری که بر ویژگیها یا دادههای برچسب تأثیر میگذارد، ماهیت غیر ثابت دادههای سری زمانی، یا تغییرات در خط لوله دادهها. از آنجایی که مدلهای یادگیری ماشین (ML) قطعی نیستند، مهم است که با نظارت دورهای محیط استقرار برای جابجایی مدل و ارسال هشدارها و در صورت لزوم، شروع به آموزش مجدد مدلها با دادههای جدید، واریانس در محیط تولید را به حداقل برسانیم.
آمازون SageMaker یک سرویس کاملاً مدیریت شده است که توسعه دهندگان و دانشمندان داده را قادر می سازد تا به سرعت و به راحتی مدل های ML را در هر مقیاسی بسازند، آموزش دهند و به کار گیرند. پس از آموزش یک مدل ML، میتوانید آن را در نقاط پایانی SageMaker که به طور کامل مدیریت میشوند و میتوانند استنتاجها را در زمان واقعی با تأخیر کم ارائه کنند، مستقر کنید. پس از استقرار مدل خود، می توانید استفاده کنید مانیتور مدل آمازون SageMaker برای نظارت مداوم بر کیفیت مدل ML خود در زمان واقعی. همچنین میتوانید هشدارها را به گونهای پیکربندی کنید که در صورت مشاهده هرگونه تغییری در عملکرد مدل، اقداماتی را به شما اطلاع داده و راهاندازی کنند. تشخیص زودهنگام و پیشگیرانه این انحرافات شما را قادر می سازد تا اقدامات اصلاحی مانند جمع آوری داده های جدید آموزش حقیقت زمینی، مدل های بازآموزی و ممیزی سیستم های بالادستی را بدون نیاز به نظارت دستی مدل ها یا ساخت ابزار اضافی انجام دهید.
در این پست، ما چند تکنیک برای تشخیص دریفت متغیر (یکی از انواع رانش داده) ارائه میکنیم و نشان میدهیم که چگونه الگوریتمها و تجسمهای تشخیص رانش خود را با مدل مانیتور ترکیب کنید.
انواع رانش داده
رانش داده ها را می توان به سه دسته طبقه بندی کرد که بستگی به این دارد که تغییر توزیع در سمت ورودی یا خروجی اتفاق می افتد یا اینکه رابطه بین ورودی و خروجی تغییر کرده است.
تغییر متغیر
در یک تغییر متغیر، توزیع ورودی ها در طول زمان تغییر می کند، اما توزیع شرطی P(y|x) تغییر نمی کند این نوع رانش را تغییر متغیر می نامند زیرا مشکل به دلیل تغییر در توزیع متغیرهای کمکی (ویژگی ها) به وجود می آید. به عنوان مثال، مجموعه داده آموزشی برای یک الگوریتم تشخیص چهره ممکن است شامل چهرههای جوانتر باشد، در حالی که در دنیای واقعی ممکن است نسبت افراد مسنتر بیشتر باشد.
تغییر برچسب
در حالی که تغییر متغیر بر تغییرات در توزیع ویژگی تمرکز دارد، تغییر برچسب بر تغییرات توزیع متغیر کلاس تمرکز دارد. این نوع جابجایی اساساً معکوس تغییر متغیر است. یک راه بصری برای فکر کردن در مورد آن ممکن است در نظر گرفتن یک مجموعه داده نامتعادل باشد. به عنوان مثال، اگر نسبت هرزنامه به غیر هرزنامه ایمیل ها در مجموعه آموزشی ما 50٪ باشد، اما در واقع، 10٪ از ایمیل های ما غیر اسپم هستند، پس توزیع برچسب هدف تغییر کرده است.
تغییر مفهوم
تغییر مفهوم با متغیر کمکی و تغییر برچسب تفاوت دارد زیرا به توزیع داده یا توزیع کلاس مربوط نمی شود، بلکه به رابطه بین دو متغیر مربوط می شود. به عنوان مثال، در تجزیه و تحلیل سهام، رابطه بین داده های قبلی بازار سهام و قیمت سهام غیر ثابت است. رابطه بین داده های ورودی و متغیر هدف در طول زمان تغییر می کند و مدل باید اغلب به روز شود.
اکنون که انواع شیفت های توزیع را می دانیم، بیایید ببینیم که چگونه مانیتور مدل به ما در تشخیص جابجایی داده ها کمک می کند. در بخش بعدی، راهاندازی مانیتور مدل و ترکیب الگوریتمهای تشخیص دریفت سفارشی خود را طی میکنیم.
مانیتور مدل
مدل مانیتور چهار نوع مختلف قابلیت نظارت را برای شناسایی و کاهش انحراف مدل در زمان واقعی ارائه می دهد:
- کیفیت داده - به تشخیص تغییر در طرحواره های داده ها و ویژگی های آماری متغیرهای مستقل کمک می کند و هشدارهایی را در هنگام شناسایی دریفت می دهد.
- کیفیت مدل - برای نظارت بر ویژگیهای عملکرد مدل مانند دقت یا دقت در زمان واقعی، مدل مانیتور به شما امکان میدهد برچسبهای حقیقت زمینی جمعآوریشده از برنامههای خود را دریافت کنید. مدل مانیتور به طور خودکار اطلاعات حقیقت پایه را با داده های پیش بینی ادغام می کند تا معیارهای عملکرد مدل را محاسبه کند.
- تعصب مدل - مانیتور مدل یکپارچه شده است Amazon SageMaker Clarify برای بهبود دید به سوگیری بالقوه. اگرچه داده ها یا مدل اولیه شما ممکن است سوگیری نداشته باشد، تغییرات در جهان ممکن است باعث شود که سوگیری در طول زمان در مدلی که قبلا آموزش داده شده است ایجاد شود.
- قابلیت توضیح مدل – تشخیص دریفت زمانی که تغییری در اهمیت نسبی تخصیص ویژگیها رخ میدهد به شما هشدار میدهد.
Deequکه کیفیت داده ها را اندازه گیری می کند، برخی از مانیتورهای از پیش ساخته شده Model Monitor را نیرو می دهد. برای استفاده از این قابلیت های نظارت از پیش ساخته شده نیازی به کدنویسی ندارید. شما همچنین انعطاف پذیری برای نظارت بر مدل ها با کدگذاری برای ارائه تجزیه و تحلیل سفارشی دارید. تمام معیارهای منتشر شده توسط Model Monitor را می توان جمع آوری و مشاهده کرد Amazon SageMaker Studio، بنابراین می توانید عملکرد مدل خود را بدون نوشتن کد اضافی به صورت بصری تجزیه و تحلیل کنید.
در سناریوهای خاصی، مانیتورهای از پیش ساخته شده ممکن است برای تولید معیارهای پیچیده برای تشخیص انحراف کافی نباشند و ممکن است نیاز به آوردن معیارهای خود را داشته باشند. در بخشهای بعدی، تنظیماتی را شرح میدهیم که معیارهای شما را با ساختن یک ظرف سفارشی وارد کنید.
تنظیم محیط
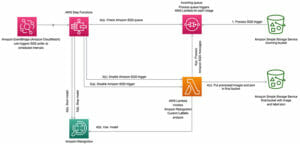
برای این پست، ما از یک نوت بوک SageMaker برای راه اندازی Model Monitor و همچنین تجسم دریفت ها استفاده می کنیم. ما با تنظیم نقش های مورد نیاز و سرویس ذخیره سازی ساده آمازون سطل های (Amazon S3) برای ذخیره داده های ما:
مجموعه داده قطار، مجموعه داده آزمایشی و فایل مدل را در آمازون S3 بارگذاری کنید
در مرحله بعد، مجموعه داده های آموزشی و آزمایشی خود و همچنین مدل آموزشی را که برای استنتاج استفاده می کنیم، آپلود می کنیم. برای این پست از مجموعه داده های درآمد سرشماری از مخزن یادگیری ماشین UCI. مجموعه داده شامل درآمد افراد و چندین ویژگی است که جمعیت شناسی جمعیت را توصیف می کند. وظیفه این است که پیش بینی کنید که آیا یک فرد درآمدی بالاتر یا کمتر از 50,000 دلار دارد. این مجموعه داده شامل هر دو ویژگی طبقه بندی و انتگرال است و دارای چندین مقدار گم شده است. این آن را به مثال خوبی برای نشان دادن رانش و تشخیص مدل تبدیل می کند.
ما از الگوریتم XGBoost برای آموزش آفلاین مدل با استفاده از SageMaker استفاده می کنیم. ما فایل مدل را برای استقرار ارائه می دهیم. مجموعه داده آموزشی برای مقایسه با دادههای استنتاج برای تولید امتیازات رانش استفاده میشود، در حالی که مجموعه داده آزمایشی برای محاسبه میزان کاهش دقت مدل به دلیل رانش استفاده میشود. ما شهود بیشتری در مورد این الگوریتم ها در مراحل بعدی ارائه می دهیم.
کد زیر مجموعه داده ها و مدل ما را در آمازون S3 آپلود می کند:
یک ظرف Docker راه اندازی کنید
Model Monitor از آوردن ظروف مانیتور مدل سفارشی شما پشتیبانی می کند. هنگامی که یک را ایجاد می کنید MonitoringSchedule، مدل مانیتور پردازش کارها را برای ارزیابی داده های استنتاج دریافتی آغاز می کند. در حین فراخوانی کانتینرها، مدل مانیتور متغیرهای محیطی اضافی را برای شما تنظیم میکند تا کانتینر شما زمینه کافی برای پردازش دادهها را برای اجرای خاص نظارت برنامهریزیشده داشته باشد. برای متغیرهای کد ظرف، نگاه کنید ورودی های قرارداد کانتینری. از متغیرهای محیطی ورودی موجود، ما به آن علاقه داریم dataset_source, output_pathو end_time:
La dataset_source متغیر مکان جمع آوری داده ها را در ظرف مشخص می کند و end_time به زمان ضبط آخرین رویداد اشاره دارد. الگوریتم دریفت سفارشی در src فهرست راهنما. برای جزئیات بیشتر در مورد الگوریتم ها، به ادامه مطلب مراجعه کنید GitHub repo.
حالا کانتینر Docker را می سازیم و آن را فشار می دهیم آمازون ECR. Dockerfile زیر را ببینید:
ما آن را با کد زیر به Amazon ECR میسازیم و میفرستیم:
یک نقطه پایانی تنظیم کنید و ضبط داده را فعال کنید
همانطور که قبلا ذکر کردیم، مدل ما با استفاده از XGBoost آموزش داده شده است، بنابراین ما از آن استفاده می کنیم XGBoostModel از SageMaker SDK برای استقرار مدل. از آنجایی که ما یک تجزیه کننده ورودی سفارشی داریم که شامل imputation و یک رمزگذاری یکباره است، نقطه ورودی استنتاج را به همراه فهرست منبع ارائه می دهیم که شامل Scikit است. ColumnTransfomer مدل. کد زیر تابع استنتاج مشتری است:
ما همچنین پیکربندی برای جمعآوری داده، تعیین مقصد S3 و درصد نمونهبرداری با استقرار نقطه پایانی را شامل میشویم (کد زیر را ببینید). در حالت ایدهآل، ما میخواهیم 100 درصد از دادههای ورودی را برای تشخیص رانش ضبط کنیم، اما برای یک نقطه پایانی ترافیک بالا، پیشنهاد میکنیم درصد نمونهبرداری را کاهش دهیم تا در دسترس بودن نقطه پایانی تحت تأثیر قرار نگیرد. علاوه بر این، مدل مانیتور ممکن است به طور خودکار درصد نمونه برداری را کاهش دهد اگر احساس کند در دسترس بودن نقطه پایانی تحت تأثیر قرار گرفته است.
پس از استقرار مدل، می توانیم یک برنامه مانیتور تنظیم کنیم.
یک برنامه مانیتور ایجاد کنید
به طور معمول، ما یک کار پردازشی برای تولید معیارهای پایه مجموعه آموزشی خود ایجاد می کنیم. سپس یک برنامه نظارتی برای شروع کارهای دوره ای ایجاد می کنیم تا درخواست های استنتاج دریافتی را تجزیه و تحلیل کنیم و معیارهایی مشابه معیارهای پایه ایجاد کنیم. معیارهای استنتاج با معیارهای پایه مقایسه میشوند و گزارش مفصلی در مورد نقض محدودیتها و رانش در کیفیت دادهها ایجاد میشود. استفاده از SageMaker SDK ایجاد معیارهای پایه و مانیتور مدل زمانبندی را ساده میکند.
برای الگوریتمهایی که در این پست استفاده میکنیم (مانند فاصله Wasserstein و آزمون Kolmogorov–Smirnov)، ظرفی که میسازیم نیاز به دسترسی به مجموعه دادههای آموزشی و دادههای استنتاج برای معیارهای محاسباتی دارد. این راهاندازی غیرمعمول نیاز به تنظیم سطح پایین برنامه مانیتور دارد. کد زیر درخواست Boto3 برای تنظیم برنامه مانیتور است. فیلدهای کلیدی مربوط به URL تصویر کانتینر و آرگومان های کانتینر هستند. کانتینرهای ساختمانی را در قسمت بعدی پوشش می دهیم. در حال حاضر، توجه داشته باشید که ما URL S3 را برای آموزش مجموعه داده ارسال می کنیم:
درخواست برای نقطه پایانی ایجاد کنید
پس از استقرار مدل، ترافیک را با نرخ ثابتی به نقاط پایانی ارسال می کنیم. کد زیر یک رشته را راه اندازی می کند تا درخواست ها را برای حدود 10 ساعت ایجاد کند. اگر میخواهید ترافیک را متوقف کنید، حتماً هسته را متوقف کنید. ما اجازه می دهیم که مولد ترافیک برای چند ساعت کار کند تا نمونه های کافی برای تجسم دریفت جمع آوری شود. هر زمان که داده های جدیدی وجود دارد، نمودارها به طور خودکار به روز می شوند.
رانش داده را تجسم کنید
ما از کل مجموعه داده برای آموزش استفاده می کنیم و به طور مصنوعی یک مجموعه داده جدید را برای استنتاج با اصلاح ویژگی های آماری برخی از ویژگی ها از مجموعه داده اصلی همانطور که در ما توضیح داده شده است ایجاد می کنیم. GitHub repo.
نمره دریفت عادی شده در هر ویژگی
یک امتیاز دریفت نرمال شده (در درصد) برای هر ویژگی با محاسبه نسبت همپوشانی توزیع داده های استنتاج ورودی با داده های اصلی به داده های اصلی محاسبه می شود. برای داده های طبقه بندی شده، این با جمع کردن مطلق تفاوت در امتیازات احتمال (آموزش و استنتاج) در هر برچسب محاسبه می شود. برای داده های عددی، داده های آموزشی به 10 bin (دهک) تقسیم می شوند و مطلق تفاوت در امتیازات احتمال بیش از bin برای محاسبه امتیاز رانش جمع می شود.
نمودار زیر امتیازات دریفت را در بازه های زمانی نشان می دهد. برخی از ویژگیها دارای دریفتهای کم یا بدون دریفت هستند، در حالی که برخی از ویژگیها دارای رانشهایی هستند که با گذشت زمان در حال افزایش هستند و در نهایت hours-per-week از همان ابتدا یک دریفت بزرگ دارد.

رانش پیش بینی شده در دقت مدل
این متریک به دلیل انحراف در دادههای استنتاج از دادههای آزمایش، پراکسی از دقت یک مدل ارائه میکند. ایده پشت این رویکرد این است که تعیین کنیم چه درصدی از داده های استنتاج شبیه به بخشی از داده های آزمایشی است، جایی که مدل به خوبی پیش بینی می کند. برای این معیار، ما از جنگلهای جداسازی برای آموزش طبقهبندیکننده تککلاسی استفاده میکنیم و برای بخشی از دادههای آزمایشی که مدل به خوبی پیشبینی کردهاند، و برای دادههای استنتاج امتیاز ایجاد میکنیم. تفاوت نسبی در میانگین این نمرات رانش پیش بینی شده در دقت است.
نمودار زیر کاهش مربوطه را در دقت مدل به دلیل رانش در داده های ورودی نشان می دهد. این نشان می دهد که تغییر متغیر می تواند دقت یک مدل را کاهش دهد. چند جهش در متریک را می توان به ماهیت آماری نحوه تولید داده ها نسبت داد. این فقط یک پروکسی برای دقت مدل است، و نه دقت واقعی، که فقط از روی حقیقت پایه برچسب ها قابل تشخیص است.

مقادیر P فرضیه آزمون صفر
یک فرضیه آزمون صفر آزمایش می کند که آیا دو نمونه (برای این پست، مجموعه داده های آموزشی و استنتاج) از یک جامعه عمومی مشتق شده اند یا خیر. p-value احتمال به دست آوردن نتایج آزمون را حداقل به اندازه مشاهدات با این فرض که فرضیه صفر درست است، می دهد. یک آستانه p-value 5% برای تصمیم گیری در مورد اینکه آیا نمونه مشاهده شده از داده های آموزشی منحرف شده است یا خیر استفاده می شود.
نمودار زیر مقادیر p ویژگی های مختلف را نشان می دهد که حداقل یک بار از آستانه عبور کرده اند. محور y log معکوس مقادیر p را برای تشخیص مقادیر p بسیار کوچک نشان می دهد. مقادیر P برای ویژگیهای عددی از آزمون کولموگروف-اسمیرنوف و برای ویژگیهای طبقهبندی از آزمون Chi-square بهدست میآیند.

نتیجه
مانیتور مدل آمازون SageMaker یک ابزار قدرتمند برای تشخیص انحراف داده ها است. در این پست، ما نشان دادیم که چگونه به راحتی الگوریتمهای تشخیص انحراف دادههای سفارشی خود را در مدل مانیتور ادغام کنید، در حالی که از مزایای سنگینی که Model Monitor از نظر جمعآوری دادهها و زمانبندی اجرای مانیتور ارائه میکند، بهره مند شوید. این دفتر یادداشت یک دستورالعمل گام به گام مفصل در مورد نحوه ساخت یک کانتینر سفارشی و پیوست آن به برنامه های مانیتور مدل ارائه می دهد. مدل مانیتور را امتحان کنید و نظرات خود را در نظرات بنویسید.
درباره نویسنده
 وینای هانومایا یک معمار ارشد یادگیری عمیق در آمازون ML Solutions Lab است، جایی که به مشتریان کمک می کند راه حل های هوش مصنوعی و ML بسازند تا چالش های تجاری خود را تسریع بخشند. قبل از این، او در راه اندازی AWS DeepLens و Amazon Personalize مشارکت داشت. او در اوقات فراغت خود از اوقات فراغت با خانواده خود لذت می برد و یک صخره نورد مشتاق است.
وینای هانومایا یک معمار ارشد یادگیری عمیق در آمازون ML Solutions Lab است، جایی که به مشتریان کمک می کند راه حل های هوش مصنوعی و ML بسازند تا چالش های تجاری خود را تسریع بخشند. قبل از این، او در راه اندازی AWS DeepLens و Amazon Personalize مشارکت داشت. او در اوقات فراغت خود از اوقات فراغت با خانواده خود لذت می برد و یک صخره نورد مشتاق است.
- '
- "
- 000
- 11
- مطلق
- دسترسی
- اضافی
- AI
- الگوریتم
- الگوریتم
- معرفی
- آمازون
- آمازون شخصی سازی کنید
- آمازون SageMaker
- تحلیل
- برنامه های کاربردی
- استدلال
- دسترس پذیری
- AWS
- خط مقدم
- بدن
- ساختن
- بنا
- کسب و کار
- علت
- ایجاد می شود
- تغییر دادن
- رمز
- برنامه نویسی
- جمع آوری
- نظرات
- محاسبه
- محاسبه
- ظرف
- ظروف
- محتوا
- قرارداد
- کمک
- مشتریان
- داده ها
- کیفیت داده
- یادگیری عمیق
- جمعیت
- کشف
- توسعه
- توسعه دهندگان
- DID
- فاصله
- کارگر بارانداز
- کانتینر داکر
- در اوایل
- نقطه پایانی
- محیط
- محیطی
- واقعه
- چهره
- تشخیص چهره
- چهره ها
- خانواده
- ویژگی
- امکانات
- زمینه
- انعطاف پذیری
- تابع
- سوالات عمومی
- خوب
- زیاد
- چگونه
- چگونه
- HTTPS
- ICS
- اندیشه
- تصویر
- درآمد
- اطلاعات
- انتگرال
- شهود
- انزوا
- IT
- کار
- شغل ها
- کلید
- برچسب ها
- بزرگ
- راه اندازی
- راه اندازی
- یادگیری
- محل
- فراگیری ماشین
- بازار
- متریک
- ML
- مدل
- نظارت بر
- پیشنهادات
- مردم
- کارایی
- جمعیت
- دقت
- پیش گویی
- در حال حاضر
- قیمت
- تولید
- پروژه
- پروکسی
- پــایتــون
- کیفیت
- بالا بردن
- واقعیت
- سوابق
- كاهش دادن
- گزارش
- پاسخ
- نتایج
- بازآموزی
- معکوس
- دویدن
- حکیم ساز
- مقیاس
- دانشمندان
- sdk
- سلسله
- تنظیم
- محیط
- تغییر
- ساده
- خواب
- کوچک
- So
- مزایا
- اسپم
- انشعاب
- شروع
- موجودی
- بازار سهام
- ذخیره سازی
- opbevare
- پشتیبانی
- پشتیبانی از
- سیستم های
- هدف
- آزمون
- تست
- زمان
- ترافیک
- آموزش
- us
- دید
- صبر کنيد
- جهان
- نوشته
- X