در چند سال گذشته، شرکت ها حجم عظیمی از داده ها را جمع آوری کرده اند. حجم داده ها با سرعت بی سابقه ای افزایش یافته و از ترابایت به پتابایت و گاهی اگزابایت داده افزایش یافته است. به طور فزاینده ای، بسیاری از شرکت ها در حال ساخت دریاچه های داده بسیار مقیاس پذیر، در دسترس، ایمن و انعطاف پذیر بر روی AWS هستند که می توانند مجموعه داده های بسیار بزرگی را مدیریت کنند. پس از تولید دریاچههای داده، برای اندازهگیری کارایی دریاچه داده و انتقال شکافها یا دستاوردها به گروههای تجاری، تیمهای داده سازمانی به ابزارهایی برای استخراج بینش عملیاتی از دریاچه داده نیاز دارند. این بینش ها به پاسخ به سوالات کلیدی مانند:
- آخرین باری که یک جدول به روز شد
- تعداد کل جدول در هر پایگاه داده
- رشد پیش بینی شده یک جدول داده شده
- جدول پر پرس و جو در مقابل جداول کم پرس و جو
در این پست، راه حلی را برای ایجاد یک داشبورد معیارهای عملیاتی (مانند تصویر زیر) برای شرکت شما راهنمایی می کنم. چسب AWS کاتالوگ داده در AWS.

بررسی اجمالی راه حل
این پست به شما نشان میدهد که چگونه میتوانید اطلاعات فراداده را از منابع AWS Glue Data Catalog (پایگاههای داده و جداول) داده خود جمعآوری کنید و یک داشبورد عملیاتی روی این دادهها بسازید.
نمودار زیر معماری کلی راه حل و مراحل را نشان می دهد.

مراحل زیر است:
- یک برنامه پایتون جمعآوریکننده داده بر اساس یک زمانبندی اجرا میشود و جزئیات فرادادهها را درباره پایگاههای داده و جداول از فهرست دادههای سازمانی جمعآوری میکند.
- ویژگی های داده کلیدی زیر برای هر جدول و پایگاه داده در کاتالوگ داده چسب AWS شما جمع آوری می شود.
| داده های جدول | داده های پایگاه داده |
| نام جدول | نام پایگاه داده |
| نام پایگاه داده | CreateTime |
| مالک | SharedResource |
| CreateTime | SharedResourceOwner |
| UpdateTime | SharedResourceDatabaseName |
| LastAccessTime | موقعیت مکانی: |
| TableType | توضیحات: |
| نگهداری | |
| خلق شده توسط | |
| IsRegisteredWithLakeFormation | |
| موقعیت مکانی: | |
| SizeInMBOnS3 | |
| TotalFilesonS3 |
- این برنامه مکان فایل هر جدول را می خواند و تعداد فایل های موجود را محاسبه می کند سرویس ذخیره سازی ساده آمازون (Amazon S3) و حجم آن به مگابایت است.
- تمام داده های جداول و پایگاه های داده در یک سطل S3 برای تجزیه و تحلیل پایین دست ذخیره می شود. این برنامه هر روز اجرا می شود و فایل های جدیدی را به تفکیک سال، ماه و روز در آمازون S3 ایجاد می کند.
- ما داده های ایجاد شده در مرحله 4 را با استفاده از یک خزنده چسب AWS می خزیم.
- خزنده یک پایگاه داده و جداول خارجی برای مجموعه داده های تولید شده ما برای تجزیه و تحلیل پایین دست ایجاد می کند.
- می توانیم داده های استخراج شده را با پرس و جو کنیم آمازون آتنا.
- استفاده می کنیم آمازون QuickSight برای ساخت داشبورد معیارهای عملیاتی و به دست آوردن بینش در مورد محتوای دریاچه داده و استفاده از آن.
برای سادگی، این برنامه فقط برای منطقه us-east-1 داده ها را از کاتالوگ داده جمع آوری می کند.
مرور کلی
راهنما شامل مراحل زیر است:
- مجموعه داده خود را پیکربندی کنید
- منابع راه حل اصلی را با یک AWS CloudFormation قالب، و کار چسب AWS را تنظیم و راه اندازی کنید.
- مجموعه داده ابرداده را خزیده و جداول خارجی را در کاتالوگ داده ایجاد کنید.
- یک نما بسازید و داده ها را از طریق آتنا جستجو کنید.
- برای ایجاد داشبورد معیارهای عملیاتی برای کاتالوگ داده، داده ها را به QuickSight راه اندازی و وارد کنید.
مجموعه داده خود را پیکربندی کنید
ما از دریاچه داده AWS COVID-19 برای تجزیه و تحلیل استفاده می کنیم. این دریاچه داده از داده های یک تشکیل شده است سطل S3 قابل خواندن برای عموم.
برای در دسترس قرار دادن دادههای دریاچه داده AWS COVID-19 در حساب AWS خود، با استفاده از موارد زیر یک پشته CloudFormation ایجاد کنید. قالب. اگر به حساب AWS خود وارد شده اید، موارد زیر را انجام دهید پیوند بیشتر فرم ایجاد پشته را برای شما پر می کند. حتما منطقه را به تغییر دهید us-east-1. برای دستورالعمل های ایجاد یک پشته CloudFormation، رجوع کنید به شروع به کار.
این الگو یک پایگاه داده COVID-19 در کاتالوگ داده و جداول شما ایجاد می کند که به دریاچه داده عمومی AWS COVID-19 اشاره می کند. شما نیازی به میزبانی دادهها در حساب خود ندارید و میتوانید برای بهروزرسانی دادهها به AWS تکیه کنید زیرا مجموعه دادهها از طریق بهروزرسانی میشوند. تبادل داده AWS.
برای اطلاعات بیشتر درباره مجموعه داده COVID-19، رجوع کنید یک دریاچه داده عمومی برای تجزیه و تحلیل داده های COVID-19.
ممکن است محیط شما قبلاً دارای مجموعه دادههای موجود در کاتالوگ داده باشد. این برنامه ویژگی های فوق الذکر را برای آن مجموعه داده ها نیز جمع آوری می کند که می تواند برای تجزیه و تحلیل استفاده شود.
منابع خود را مستقر کنید
برای سهولت در شروع، ما یک الگوی CloudFormation ایجاد کردیم که به طور خودکار چند جزء کلیدی راه حل را تنظیم می کند:
- یک کار چسب AWS (برنامه پایتون) که بر اساس یک زمانبندی راهاندازی میشود
- La هویت AWS و مدیریت دسترسی نقش (IAM) مورد نیاز کار AWS Glue تا کار بتواند جزئیات مربوط به پایگاههای داده و جداول را در فهرست داده جمعآوری و ذخیره کند.
- یک سطل جدید S3 برای کار چسب AWS برای ذخیره فایل های داده
- یک پایگاه داده جدید در کاتالوگ داده برای ذخیره جداول داده های معیارهای ما
کد منبع برای کار چسب AWS و الگوی CloudFormation در دسترس هستند GitHub repo.
ابتدا باید کد AWS Glue Python را از اینجا دانلود کنید GitHub و آن را در یک سطل S3 موجود آپلود کنید. هنگام اجرای پشته CloudFormation باید مسیر این فایل ارائه شود.
- پشته را راه اندازی کنید:

- همانطور که در تصویر زیر نشان داده شده است، مقادیری را برای پارامترهای خود ارائه دهید.

پس از استقرار موفقیت آمیز پشته، می توانید منابع ایجاد شده در پشته را بررسی کنید منابع تب.

میتوانید تنظیم و راهاندازی کار چسب AWS را تأیید و بررسی کنید، که طبق زمان تعیینشده شما برنامهریزی میشود.
اکنون که تأیید کردیم که پشته با موفقیت راه اندازی شده است، می توانیم کار چسب AWS خود را به صورت دستی اجرا کنیم و ویژگی های کلیدی را برای تجزیه و تحلیل خود جمع آوری کنیم.
- در کنسول AWS Glue، AWS Glue Studio را در قسمت ناوبری انتخاب کنید.

- در کنسول AWS Glue Studio، روی Jobs کلیک کرده و آن را انتخاب کنید
DataCollectorjob و Run the job.
کار چسب AWS داده ها را جمع آوری کرده و در سطل S3 که از طریق AWS CloudFormation برای ما ایجاد شده است ذخیره می کند. این کار پوشه های جداگانه ای را برای داده های پایگاه داده و جدول ایجاد می کند، همانطور که در تصویر زیر نشان داده شده است.

خزیدن و تنظیم جداول خارجی برای داده های معیارها
این مراحل را برای ایجاد جداول در پایگاه داده با استفاده از چسب AWS دنبال کنید خزنده بر روی داده های ذخیره شده در آمازون S3. توجه داشته باشید که پایگاه داده با استفاده از پشته CloudFormation برای ما ایجاد شده است.
- در کنسول AWS Glue، زیر پایگاه داده ها در قسمت ناوبری، را انتخاب کنید جداول.
- را انتخاب کنید جداول را اضافه کنید.
- را انتخاب کنید با استفاده از خزنده جداول را اضافه کنید.
- یک نام برای خزنده وارد کنید و انتخاب کنید بعدی.
- برای خزنده را اضافه کنید، انتخاب کنید ایجاد نوع منبع.
- با انتخاب نوع منبع خزنده را مشخص کنید ذخیره سازی داده ها و انتخاب کنید بعدی.
- در یک فروشگاه داده اضافه کنید بخش، برای یک فروشگاه داده را انتخاب کنید، انتخاب کنید S3.
- برای خزیدن داده در، انتخاب کنید مسیر مشخص شده.
- برای شامل مسیر، وارد مسیر به
tablesپوشه تولید شده توسط AWS Glue job:s3://<data bucket created using CFN>/datalake/tables/.
- وقتی از شما پرسیده شد که آیا میخواهید ذخیره داده دیگری ایجاد کنید، انتخاب کنید نه و سپس انتخاب کنید بعدی.
- بر یک نقش IAM را انتخاب کنید صفحه، را انتخاب کنید یک نقش IAM موجود را انتخاب کنید.
- برای نقش IAM، نقش IAM ایجاد شده از طریق پشته CloudFormation را انتخاب کنید.
- را انتخاب کنید بعدی.
- بر تولید صفحه، برای پایگاه داده، پایگاه داده AWS Glue را که قبلا ایجاد کرده اید انتخاب کنید.
- را انتخاب کنید بعدی.
- انتخاب های خود را مرور کنید و انتخاب کنید پایان.
- خزنده ای را که ایجاد کرده اید انتخاب کرده و انتخاب کنید خزنده را اجرا کنید.
خزنده باید فقط چند دقیقه طول بکشد تا کامل شود. در حین اجرای آن، پیامهای وضعیت ممکن است ظاهر شوند که به شما اطلاع میدهند که سیستم در تلاش است خزنده را اجرا کند و سپس در واقع خزنده را اجرا میکند. برای بررسی وضعیت فعلی خزنده میتوانید نماد تازهسازی را انتخاب کنید.
- در صفحه پیمایش، را انتخاب کنید جداول.
میز زنگ زد tables، که توسط خزنده ایجاد شده است، باید لیست شود.

پرس و جو داده ها با آتنا
این بخش نحوه پرس و جو کردن این جداول را با استفاده از Athena نشان می دهد. Athena یک سرویس پرس و جو بدون سرور و تعاملی است که تجزیه و تحلیل داده ها را در دریاچه داده AWS COVID-19 آسان می کند. آتنا از SQL پشتیبانی می کند، زبان رایجی که تحلیلگران داده برای تجزیه و تحلیل داده های ساخت یافته استفاده می کنند. برای استعلام داده ها، مراحل زیر را انجام دهید:
- وارد کنسول آتنا شوید.
- اگر اولین بار است که از آتنا استفاده می کنید، باید مکان نتیجه پرس و جو را مشخص کنید در آمازون S3.
- در منوی کشویی، را انتخاب کنید
datalake360dbپایگاه داده. - سوالات خود را وارد کنید و مجموعه داده ها را کاوش کنید.
داده ها را به QuickSight راه اندازی و وارد کنید و یک داشبورد معیارهای عملیاتی ایجاد کنید
QuickSight را تنظیم کنید قبل از وارد کردن مجموعه داده، و مطمئن شوید که حداقل 512 مگابایت ظرفیت SPICE دارید. برای اطلاعات بیشتر ببین مدیریت ظرفیت SPICE.
قبل از ادامه، مطمئن شوید که حساب QuickSight شما دارای مجوزهای IAM برای دسترسی به Athena است (نگاه کنید به مجوز اتصال به آمازون آتنا) و آمازون S3.
بیایید ابتدا مجموعه داده های خود را ایجاد کنیم.
- در کنسول QuickSight، را انتخاب کنید مجموعه داده ها در صفحه ناوبری
- را انتخاب کنید مجموعه داده جدید.
- آتنا را از لیست منابع داده انتخاب کنید.
- برای نام منبع داده، یک نام وارد کنید.

- برای پایگاه داده، پایگاه داده ای را که در مرحله قبل تنظیم کردید انتخاب کنید (
datalake360db). - برای جداول، انتخاب کنید پایگاه های داده.

- ایجاد مجموعه داده خود را تمام کنید..
- همین مراحل را برای ایجاد a تکرار کنید
tablesمجموعه داده
اکنون مجموعه داده پایگاه داده را ویرایش می کنید.
- از لیست مجموعه داده ها، را انتخاب کنید
databasesمجموعه داده - را انتخاب کنید ویرایش مجموعه داده.

- تغییر دادن
createtimeنوع فیلد از رشته تا تاریخ
- قالب تاریخ را به عنوان وارد کنید
yy/MM/dd HH:mm:ss. - را انتخاب کنید بروزرسانی.

- به طور مشابه، فیلدهای داده جداول را تغییر دهید
createtime,updatetimeوlastaccessedtimeبه نوع تاریخ - را انتخاب کنید ذخیره و انتشار برای ذخیره تغییرات در مجموعه داده.
بعد، فیلدهای محاسبه شده را برای تعداد اضافه می کنیم databases و tables.
- برای
tablesمجموعه داده، انتخاب کنید محاسبه را اضافه کنید.
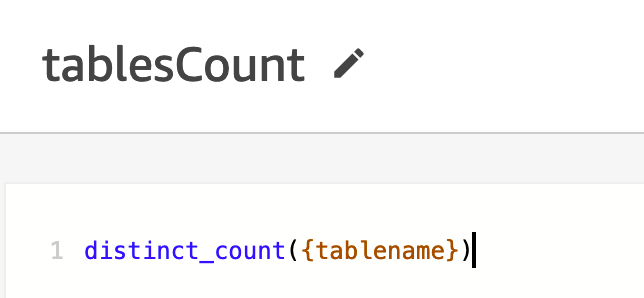
- فیلد محاسبه شده را اضافه کنید
tablesCountasdistinct_count({tablename}.
- به طور مشابه، یک فیلد محاسبه شده جدید اضافه کنید
databasesCountasdistinct_count({databasename}.
حالا بیایید یک تحلیل جدید ایجاد کنیم.
- در صفحه پیمایش، را انتخاب کنید تحلیل و بررسی.
- انتخاب
tablesمجموعه داده - را انتخاب کنید تحلیل ایجاد کنید.

بیایید اولین تصویر خود را برای تعداد پایگاههای داده و جداول در فهرست دادههای دریاچه دادهمان ایجاد کنیم.
- یک تصویر جدید ایجاد کنید و اضافه کنید
databasesCountاز لیست فیلدها
این به ما تعدادی پایگاه داده را در کاتالوگ داده ما ارائه می دهد.
- به طور مشابه، یک تصویر بصری برای نمایش تعداد کل جداول با استفاده از
tablesCountرشته.
بیایید تصویر دوم را برای تعداد کل فایلها در Amazon S3 و حجم کل فضای ذخیرهسازی در Amazon S3 ایجاد کنیم.
- مشابه مرحله قبل، یک تصویر جدید اضافه می کنیم و گزینه را انتخاب می کنیم
totalfilesons3وsizeinmbons3فیلدهایی برای نمایش جزئیات ذخیره سازی مربوط به آمازون S3.
بیایید تصویر دیگری ایجاد کنیم تا بررسی کنیم که کدام مجموعه داده کمتر استفاده شده است.
- اضافه کردن تصویری با استفاده از
LastAccessTimeعنصر داده
در نهایت، بیایید یک تصویر دیگر ایجاد کنیم تا بررسی کنیم که آیا پایگاه داده وجود دارد یا خیر منابع مشترک از حساب های مختلف
- را انتخاب کنید
databasesمجموعه داده - یک نوع تصویری جدول ایجاد می کنیم و اضافه می کنیم
databasename,sharedresourceوdescriptionزمینه ها.
اکنون ایده ای دارید که با استفاده از این داده ها چه نوع تصاویری امکان پذیر است. تصویر زیر نمونه ای از یک داشبورد تمام شده است.

پاک کردن
برای جلوگیری از هزینههای مداوم، پشتههای CloudFormation و فایلهای خروجی را در Amazon S3 که در حین استقرار ایجاد کردهاید حذف کنید. قبل از اینکه بتوانید سطل ها را حذف کنید، باید داده های موجود در سطل های S3 را حذف کنید.
نتیجه
در این پست نشان دادیم که چگونه می توانید یک داشبورد معیارهای عملیاتی برای کاتالوگ داده خود راه اندازی کنید. ما برنامه خود را برای جمع آوری عناصر کلیدی داده در مورد جداول و پایگاه های داده خود از کاتالوگ داده چسب AWS تنظیم کردیم. سپس از این مجموعه داده برای ساخت داشبورد معیارهای عملیاتی خود استفاده کردیم و بینشی در مورد دریاچه داده خود به دست آوردیم.
درباره نویسنده
 ساچین تاکار یک معمار ارشد راه حل در خدمات وب آمازون است که با یکپارچه ساز سیستم جهانی (GSI) پیشرو کار می کند. او بیش از 22 سال تجربه به عنوان یک معمار فناوری اطلاعات و به عنوان مشاور فناوری برای موسسات بزرگ دارد. حوزه تمرکز او بر روی داده ها و تجزیه و تحلیل است. ساچین راهنمایی های معماری ارائه می دهد و از شریک GSI در ساخت راه حل های استراتژیک صنعت در AWS پشتیبانی می کند.
ساچین تاکار یک معمار ارشد راه حل در خدمات وب آمازون است که با یکپارچه ساز سیستم جهانی (GSI) پیشرو کار می کند. او بیش از 22 سال تجربه به عنوان یک معمار فناوری اطلاعات و به عنوان مشاور فناوری برای موسسات بزرگ دارد. حوزه تمرکز او بر روی داده ها و تجزیه و تحلیل است. ساچین راهنمایی های معماری ارائه می دهد و از شریک GSI در ساخت راه حل های استراتژیک صنعت در AWS پشتیبانی می کند.
- '
- &
- 100
- 107
- 9
- دسترسی
- حساب
- آمازون
- آمازون خدمات وب
- تحلیل
- علم تجزیه و تحلیل
- معماری
- محدوده
- AWS
- ساختن
- بنا
- کسب و کار
- ظرفیت
- تغییر دادن
- بار
- رمز
- مشترک
- اتصالات
- مشاور
- محتوا
- Covid-19
- ایجاد
- جاری
- داشبورد
- داده ها
- دریاچه دریاچه
- پایگاه داده
- پایگاه های داده
- روز
- سرمایه گذاری
- محیط
- تجربه
- زمینه
- نام خانوادگی
- بار اول
- تمرکز
- فرم
- قالب
- جهانی
- رشد
- چگونه
- چگونه
- HTTPS
- IAM
- ICON
- اندیشه
- هویت
- صنعت
- اطلاعات
- بینش
- موسسات
- تعاملی
- IT
- کار
- شغل ها
- کلید
- زبان
- بزرگ
- برجسته
- فهرست
- محل
- اندازه
- متریک
- جهت یابی
- شریک
- برنامه
- عمومی
- پــایتــون
- منابع
- دویدن
- در حال اجرا
- مقیاس
- بدون سرور
- خدمات
- تنظیم
- ساده
- اندازه
- So
- مزایا
- SQL
- آغاز شده
- وضعیت
- ذخیره سازی
- opbevare
- پرده
- استراتژیک
- پشتیبانی از
- سیستم
- پیشرفته
- زمان
- us
- چشم انداز
- وب
- خدمات وب
- سال
- سال