معرفی
در این پروژه، ما روی دادههای هند تمرکز خواهیم کرد. و هدف ما ایجاد یک مدل پیشبینیکننده است تا وقتی ویژگیهای یک نامزد را میدهیم، مدل بتواند پیشبینی کند که آیا آنها استخدام خواهند شد یا خیر.
La مجموعه داده حول فصل قرار دادن یک مدرسه کسب و کار در هند می چرخد. مجموعه داده دارای فاکتورهای مختلفی بر روی داوطلبان است، مانند تجربه کاری، درصد امتحان و غیره. در نهایت، شامل وضعیت استخدام و جزئیات حقوق و دستمزد است.
استخدام در پردیس یک استراتژی برای تامین منابع، جذب و استخدام استعدادهای جوان برای کارآموزی و موقعیت های ابتدایی است. اغلب شامل کار با مراکز خدمات شغلی دانشگاه و شرکت در نمایشگاه های شغلی برای ملاقات حضوری با دانشجویان و فارغ التحصیلان اخیر می شود.

در این مقاله، آن مجموعه داده را وارد میکنیم، آن را پاک میکنیم و سپس آن را برای ساختن یک مدل رگرسیون لجستیک آماده میکنیم.
این مقاله به عنوان بخشی از بلاگاتون علم داده.
فهرست مندرجات
هدف از ساخت مدل رگرسیون لجستیک
اهداف ما در اینجا موارد زیر است:
ابتدا، میخواهیم مجموعه دادههای خود را برای طبقهبندی باینری آماده کنیم. حالا، منظورم چیست؟ وقتی سعی میکنیم یک ارزش مستمر مانند قیمت یک آپارتمان را پیشبینی کنیم، ممکن است هر عددی بین صفر تا میلیونها دلار باشد. ما آن را یک مشکل رگرسیون می نامیم.
اما در این پروژه، چیزها کمی متفاوت است. بهجای پیشبینی یک مقدار پیوسته، گروهها یا کلاسهای مجزایی داریم که سعی میکنیم بین آنها پیشبینی کنیم. بنابراین به این مسئله یک مشکل طبقه بندی گفته می شود ، و به دلیل اینکه در پروژه ما فقط دو گروه خواهیم داشت که سعی می کنیم بین آنها انتخاب کنیم ، این امر آن را به یک طبقه بندی باینری تبدیل می کند.
هدف دوم ایجاد یک مدل رگرسیون لجستیک برای پیشبینی استخدام است. و هدف سوم ما این است که پیشبینیهای مدل خود را با استفاده از نسبت شانس توضیح دهیم.
اکنون از نظر گردش کار یادگیری ماشینی، مراحلی که دنبال خواهیم کرد، و برخی از چیزهای جدید، در طول مسیر یاد خواهیم گرفت. بنابراین، در مرحله واردات، دادههای خود را برای کار با یک هدف باینری آماده میکنیم. در مرحله اکتشاف، تراز کلاس را بررسی خواهیم کرد. بنابراین، اساساً، چه نسبتی از کاندیداها نفر سوم بودند و چه نسبتهایی نبودند؟ و در مرحله رمزگذاری ویژگیها، ویژگیهای دستهبندی خود را رمزگذاری میکنیم. در بخش تقسیم ، تقسیم آزمایش قطار تصادفی را انجام خواهیم داد.
برای مدل:
مرحله ساخت، اولا، ما خط پایه خود را تعیین می کنیم، و چون از امتیازات دقت استفاده خواهیم کرد، بیشتر در مورد اینکه امتیاز دقت چیست و چگونه یک خط مبنا ایجاد کنیم، صحبت خواهیم کرد، در مرحله دوم، ما رگرسیون لجستیک انجام دهید. و در آخر، مرحله ارزیابی را خواهیم داشت. ما دوباره بر روی امتیاز دقت تمرکز خواهیم کرد. در نهایت، برای ارتباط نتایج، به نسبت شانس نگاه می کنیم.
در نهایت، قبل از فرو رفتن در کار، بیایید خودمان را با کتابخانههایی که در پروژه استفاده خواهیم کرد، معرفی کنیم. ابتدا داده های خود را به نوت بوک Google Colabe در کتابخانه io وارد می کنیم. سپس، همانطور که از یک مدل رگرسیون لجستیک استفاده می کنیم، آن را از scikit-learn وارد می کنیم. پس از آن، همچنین از scikit-learn، معیارهای عملکرد، امتیاز دقت، و train-test-split را وارد خواهیم کرد.
ما استفاده خواهیم کرد matplotlib و Seaborn برای تجسم مان، و NumPy فقط برای ریاضیات اندک خواهد بود. نیاز داریم پانداها برای دستکاری دادههای ما، LabelEncoder برای رمزگذاری متغیرهای دستهای ما و StandardScaler برای عادی کردن دادهها. اینها کتابخانههایی خواهند بود که به آنها نیاز داریم. بیایید به آماده سازی داده ها بپردازیم.
#import libraries
import io
import warnings import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.preprocessing import LabelEncoder
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler warnings.simplefilter(action="ignore", category=FutureWarning)داده ها را برای مدل رگرسیون لجستیک آماده کنید
وارد كردن
برای شروع آماده سازی داده ها، بیایید کار مهم خود را انجام دهیم. ابتدا فایل داده خود را بارگذاری می کنیم و سپس باید آنها را در یک DataFrame 'df' قرار دهیم.
کد پایتون:
ما میتوانیم DataFrame زیبای خود را ببینیم و 215 رکورد و 15 ستون داریم که شامل ویژگی «وضعیت»، هدف ما است. این توضیحات برای همه ویژگی ها است.

کاوش
اکنون همه این ویژگی ها را داریم که می خواهیم بررسی کنیم. بنابراین بیایید تجزیه و تحلیل داده های اکتشافی خود را شروع کنیم. ابتدا، بیایید نگاهی به اطلاعات این دیتافریم بیندازیم و ببینیم که آیا ممکن است نیاز به نگه داشتن هر یک از آنها داشته باشیم یا ممکن است لازم باشد آن ها را حذف کنیم.
# Inspect DataFrame
df.info() <class 'pandas.core.frame.DataFrame'>
RangeIndex: 215 entries, 0 to 214
Data columns (total 15 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 sl_no 215 non-null int64 1 gender 215 non-null object 2 ssc_p 215 non-null float64 3 ssc_b 215 non-null object 4 hsc_p 215 non-null float64 5 hsc_b 215 non-null object 6 hsc_s 215 non-null object 7 degree_p 215 non-null float64 8 degree_t 215 non-null object 9 workex 215 non-null object 10 etest_p 215 non-null float64 11 specialisation 215 non-null object 12 mba_p 215 non-null float64 13 status 215 non-null object 14 salary 148 non-null float64
dtypes: float64(6), int64(1), object(8)
memory usage: 25.3+ KBاکنون وقتی به اطلاعات `df` نگاه می کنیم، چند چیز وجود دارد که به دنبال آن هستیم، ما 215 ردیف در فریم داده خود داریم، و سؤالی که می خواهیم از خود بپرسیم این است که آیا داده ای از دست رفته است؟ و اگر به اینجا نگاه کنیم، به نظر می رسد که به دلیل نامزدهایی که استخدام نشده اند، به جز ستون حقوق، همانطور که انتظار می رود، داده های گم نشده ای نداریم.
یکی دیگر از نگرانیهای ما در اینجا این است که آیا ویژگیهای نشتی وجود دارد که اطلاعاتی را به مدل ما بدهد که در صورت استقرار در دنیای واقعی از آن برخوردار نبود؟ به یاد داشته باشید که ما میخواهیم مدل ما پیشبینی کند که آیا یک نامزد شرکت میکند یا نه، و میخواهیم مدل ما این پیشبینیها را قبل از استخدام انجام دهد. بنابراین ما نمی خواهیم بعد از استخدام هیچ اطلاعاتی در مورد این نامزدها بدهیم.
بنابراین، کاملاً واضح است که این ویژگی «حقوق» اطلاعاتی درباره حقوق ارائه شده توسط شرکت ارائه میکند. و چون این حقوق برای افرادی است که پذیرفته شدهاند، این ویژگی در اینجا به منزله نشتی است، و ما باید آن را حذف کنیم.
df.drop(columns="salary", inplace=True)دومین مورد که می خواهم به آن نگاه کنم انواع داده های این ویژگی های مختلف است. بنابراین، با نگاهی به این نوع داده ها، ما هشت ویژگی طبقه بندی شده با هدف خود و هفت ویژگی عددی داریم و همه چیز درست است. بنابراین، اکنون که این ایده ها را داریم، اجازه دهید کمی زمان بگذاریم تا آنها را عمیق تر بررسی کنیم.
می دانیم که هدف ما دو کلاس دارد. ما کاندیدا گذاشته ایم و کاندیدا نگذاشته ایم. سوال این است که نسبت نسبی آن دو طبقه چقدر است؟ آیا آنها در مورد یک تعادل هستند؟ یا یکی خیلی بیشتر از دیگری است؟ این چیزی است که هنگام انجام مشکلات طبقه بندی باید به آن نگاهی بیندازید. بنابراین این یک گام مهم در ما است و از.
# Plot class balance
df["status"].value_counts(normalize=True).plot( kind="bar", xlabel="Class", ylabel="Relative Frequency", title="Class Balance"
);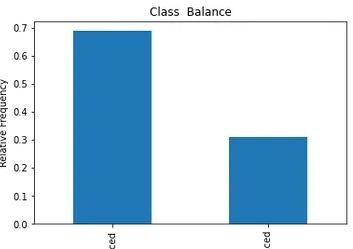
کلاس مثبت ما "قرار داده شده" بیش از 65٪ از مشاهدات ما را تشکیل می دهد و کلاس منفی ما "جای داده نشده" حدود 30٪ است. حالا اگر اینها فوق العاده نامتعادل بودند، مثلاً اگر بیشتر از 80 یا حتی بیشتر از آن بود، می گفتم اینها هستند کلاس های نامتعادل. و ما باید کمی کار کنیم تا مطمئن شویم که مدل ما به درستی عمل می کند. اما این یک تعادل خوب است.
یکی دیگه بسازیم تجسم برای توجه به ارتباط بین ویژگی های ما و هدف. بیایید با ویژگی های عددی شروع کنیم.
ابتدا توزیع فردی ویژگی ها را با استفاده از نمودار توزیع و همچنین رابطه بین ویژگی های عددی و هدف خود را با استفاده از نمودار جعبه مشاهده خواهیم کرد.
fig,ax=plt.subplots(5,2,figsize=(15,35))
for index,i in enumerate(df.select_dtypes("number").drop(columns="sl_no")): plt.suptitle("Visualizing Distribution of Numerical Columns Indivualy and by Class",size=20) sns.histplot(data=df, x=i, kde=True, ax=ax[index,0]) sns.boxplot(data=df, x='status', y=i, ax=ax[index,1]);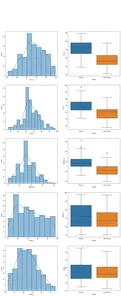
در ستون اول از طرح ما، می بینیم که همه توزیع ها از توزیع نرمال پیروی می کنند و اکثر عملکردهای آموزشی داوطلب بین 60-80٪ است.
در ستون دوم، یک نمودار باکس دوتایی داریم که کلاس «Placed» در سمت راست و سپس کلاس «Not Placed» در سمت چپ قرار دارد. برای ویژگیهای «etest_p» و «mba_p»، تفاوت زیادی در این دو توزیع از منظر ساخت مدل وجود ندارد. همپوشانی قابل توجهی در توزیع بر روی کلاس ها وجود دارد، بنابراین این ویژگی ها پیش بینی خوبی برای هدف ما نیستند. در مورد بقیه ویژگی ها، به اندازه کافی متمایز هستند که آنها را به عنوان پیش بینی کننده های خوب بالقوه هدف خود در نظر بگیریم. بیایید به ویژگی های طبقه بندی برویم. و برای کشف آنها از نمودار شمارش استفاده می کنیم.
fig,ax=plt.subplots(7,2,figsize=(15,35))
for index,i in enumerate(df.select_dtypes("object").drop(columns="status")): plt.suptitle("Visualizing Count of Categorical Columns",size=20) sns.countplot(data=df,x=i,ax=ax[index,0]) sns.countplot(data=df,x=i,ax=ax[index,1],hue="status")
با نگاهی به طرح، می بینیم که تعداد نامزدهای مرد بیشتر از زنان است. و اکثر کاندیداهای ما هیچ تجربه کاری ندارند، اما این نامزدها بیشتر از آنهایی که داشتند استخدام شدند. ما داوطلبانی داریم که تجارت را به عنوان دوره "hsc" خود انجام دادهاند، و همچنین داوطلبانی که دارای پیشینه علمی هستند، در هر دو مورد رتبه دوم را دارند.
یک نکته کوچک در مورد مدلهای رگرسیون لجستیک، اگرچه برای طبقهبندی هستند، اما در گروه مدلهای خطی دیگر مانند رگرسیون خطی قرار میگیرند و به همین دلیل، زیرا هر دو مدل خطی هستند. همچنین باید نگران موضوع چند خطی بودن باشیم. بنابراین ما باید یک ماتریس همبستگی ایجاد کنیم و سپس باید آن را در یک نقشه حرارتی ترسیم کنیم.
ما نمیخواهیم همه ویژگیها را در اینجا بررسی کنیم، میخواهیم فقط به ویژگیهای عددی نگاه کنیم، و نمیخواهیم هدفمان را لحاظ کنیم. از آنجایی که اگر هدف ما با برخی از ویژگی های ما مرتبط باشد، بسیار خوب است.
corr = df.select_dtypes("number").corr()
# Plot heatmap of `correlation`
plt.title('Correlation Matrix')
sns.heatmap(corr, vmax=1, square=True, annot=True, cmap='GnBu');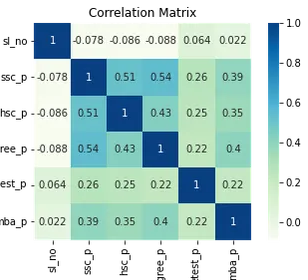
در اینجا آبی روشن، که به معنای کم تا بدون همبستگی ، و آبی تیره با که ما همبستگی بالاتری داریم هستند. بنابراین، ما میخواهیم مراقب آبیهای تیره باشیم. ما میتوانیم یک خط آبی تیره ، یک خط مورب که از وسط این نقشه پایین میرود، ببینیم. اینها ویژگیهایی هستند که با خودشان مرتبط هستند. و سپس، تعدادی مربع تاریک را میبینیم. این بدان معناست که ما تعداد زیادی همبستگی بین ویژگیها داریم.
در مرحله آخر EDA خود، باید کاردینالیته بالا و پایین را در ویژگی های دسته بندی بررسی کنیم. Cardinality به تعداد مقادیر منحصر به فرد در یک متغیر طبقه بندی اشاره دارد. کاردینالیته بالا به این معنی است که ویژگی های طبقه بندی تعداد زیادی ارزش منحصر به فرد دارند. تعداد دقیقی از مقادیر منحصر به فرد وجود ندارد که یک ویژگی را با کاردینالیته بالا میسازد. اما اگر مقدار مشخصه طبقه بندی تقریباً برای همه مشاهدات منحصر به فرد باشد، معمولاً می توان آن را حذف کرد.
# Check for high- and low-cardinality categorical features
df.select_dtypes("object").nunique() gender 2
ssc_b 2
hsc_b 2
hsc_s 3
degree_t 3
workex 2
specialisation 2
status 2
dtype: int64هیچ ستونی را نمیبینم که در آن تعداد مقادیر منحصربهفرد یک یا هر چیزی فوقالعاده زیاد باشد. اما من فکر میکنم یک ستون دستهبندی نوع وجود دارد که ما اینجا آن را از دست میدهیم. و دلیل آن این است که به عنوان یک شیء رمزگذاری نمیشود، بلکه بهعنوان یک عدد صحیح کدگذاری میشود.
ستون `sl_no` به معنایی که میدانیم یک عدد صحیح نیست. این نامزدها به ترتیبی رتبهبندی میشوند. فقط یک برچسب نام منحصر به فرد و نام آن مانند یک دسته است، درست است؟ بنابراین این یک متغیر قطعی است. و هیچ اطلاعاتی ندارد، بنابراین باید آن را رها کنیم.
df.drop(columns="sl_no", inplace=True)ویژگی های رمزگذاری
ما تجزیه و تحلیل خود را به پایان رساندیم، و کاری که باید انجام دهیم این است که ویژگیهای طبقهبندی خود را رمزگذاری کنیم، من از «LabelEncoder» استفاده خواهم کرد. Label Encoding یک تکنیک رمزگذاری محبوب برای کارکرد متغیرهای دستهای است. با استفاده از این تکنیک، به هر برچسب یک عدد صحیح منحصر به فرد بر اساس ترتیب حروف الفبا اختصاص داده می شود.
lb = LabelEncoder () cat_data = ['gender', 'ssc_b', 'hsc_b', 'hsc_s', 'degree_t', 'workex', 'specialisation', 'status']
for i in cat_data: df[i] = lb.fit_transform(df[i]) df.head()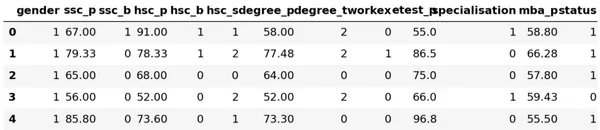
شکاف
ما داده های خود را وارد و پاک کردیم. ما کمی انجام داده ایم تجزیه و تحلیل داده های اکتشافی، و اکنون باید داده های خود را تقسیم کنیم. ما دو نوع تقسیم داریم: تقسیم عمودی یا ویژگی ها-هدف و تقسیم افقی یا مجموعه های تست قطار.
بیایید با عمودی شروع کنیم. ما ماتریس ویژگی "X" و بردار هدف "y" را ایجاد خواهیم کرد. هدف ما "وضعیت" است. ویژگی های ما باید تمام ستون هایی باشد که در `df` باقی می مانند.
#vertical split
target = "status"
X = df.drop(columns = target)
y = df[target]مدلها معمولاً وقتی دادههای نرمالسازی شده برای آموزش داشته باشند بهتر عمل میکنند، بنابراین نرمالسازی چیست؟ عادی سازی، تبدیل مقادیر چندین متغیر به یک محدوده مشابه است. هدف ما عادی سازی متغیرهایمان است. بنابراین محدوده مقادیر آنها از 0 تا 1 خواهد بود. بیایید این کار را انجام دهیم، و من از «StandardScaler» استفاده خواهم کرد.
scaler = StandardScaler()
X = scaler.fit_transform(X)اکنون بیایید مجموعههای آزمایشی تقسیم افقی یا آموزش را انجام دهیم. ما باید دادههای خود (X و y) را با استفاده از یک تقسیم تصادفی آزمون قطار به مجموعههای آموزشی و آزمایشی تقسیم کنیم. مجموعه تست ما باید 20٪ از کل داده های ما باشد. و فراموش نمی کنیم که یک حالت_تصادفی برای تکرارپذیری تنظیم کنیم.
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size = 0.2, random_state = 42 ) print("X_train shape:", X_train.shape)
print("y_train shape:", y_train.shape)
print("X_test shape:", X_test.shape)
print("y_test shape:", y_test.shape) X_train shape: (172, 12)
y_train shape: (172,)
X_test shape: (43, 12)
y_test shape: (43,)یک مدل رگرسیون لجستیک بسازید
خط مقدم
بنابراین اکنون باید ساخت مدل رگرسیون لجستیک خود را شروع کنیم، و باید شروع به سفارشدهی برای تنظیم خط پایه خود کنیم. به یاد داشته باشید که نوع مشکلی که ما با آن سر و کار داریم یک مشکل طبقه بندی است و معیارهای مختلفی برای ارزیابی مدل های طبقه بندی وجود دارد. چیزی که می خواهم روی آن تمرکز کنم امتیاز دقت است.
حالا نمره دقت چنده؟ امتیاز دقت در یادگیری ماشینی یک معیار ارزیابی است که تعداد پیشبینیهای صحیح انجامشده توسط یک مدل را به تعداد کل پیشبینیهای انجامشده اندازهگیری میکند. ما آن را با تقسیم تعداد پیش بینی های صحیح بر تعداد کل پیش بینی ها محاسبه می کنیم. بنابراین منظور این است که نمره دقت بین 0 و 1 می رود. صفر خوب نیست. اینجا جایی است که شما نمی خواهید باشید، و یکی کامل است.
بنابراین بیایید این را در نظر داشته باشیم و به یاد داشته باشیم که یک پیشبینی را بارها و بارها ارائه میکند، صرف نظر از چه ، فقط یک حدس برای ما است.
در مورد ما، ما دو کلاس داریم، قرار داده شده یا نه. بنابراین اگر بتوانیم فقط یک پیش بینی انجام دهیم، حدس ما چه خواهد بود؟ اگر گفتید طبقه اکثریت. فکر می کنم منطقی است، درست است؟ اگر بتوانیم فقط یک پیشبینی داشته باشیم، احتمالاً باید یکی را انتخاب کنیم که بالاترین مشاهدات را در مجموعه دادههای ما داشته باشد.
بنابراین، خط پایه ما از درصدی استفاده می کند که کلاس اکثریت در داده های آموزشی نشان می دهد. اگر مدل این خط پایه را شکست ندهد، ویژگی ها اطلاعات ارزشمندی برای طبقه بندی مشاهدات ما اضافه نمی کنند.
ما میتوانیم از متد «value_counts» با آرگومان «normalize = True» برای محاسبه دقت پایه استفاده کنیم:
acc_baseline = y_train.value_counts(normalize=True).max()
print("Baseline Accuracy:", round(acc_baseline, 2)) Baseline Accuracy: 0.68میتوانیم ببینیم که دقت خط پایه ما 68٪ یا 0.68 به عنوان یک نسبت است. بنابراین، برای ارزش افزودن برای استفاده، میخواهیم از آن عدد بالاتر باشیم و به یک نزدیکتر شویم. این هدف ماست و اکنون بیایید ساختن مدل خود را شروع کنیم.
تکرار کنید
اکنون زمان آن است که مدل خود را بسازیم. ما از رگرسیون لجستیک استفاده خواهیم کرد، اما قبل از این کار، اجازه دهید کمی در مورد اینکه رگرسیون لجستیک چیست و چگونه کار می کند صحبت کنیم و سپس می توانیم موارد کدگذاری را انجام دهیم. و برای آن، در اینجا ما یک شبکه کوچک داریم.
در امتداد محور x، فرض کنید من p_degrees نامزدها را در مجموعه دادههایمان دارم. و همانطور که از راست به چپ حرکت می کنم، درجه ها بالاتر و بالاتر می روند، و سپس در امتداد محور Y، کلاس های ممکن را برای قرار دادن دارم: صفر و یک.
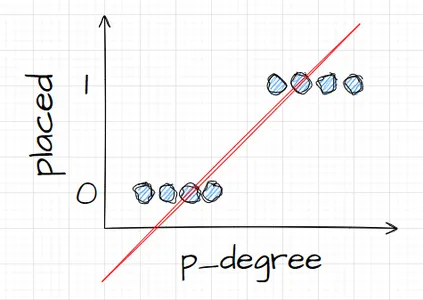
بنابراین اگر بخواهیم نقاط داده خود را ترسیم کنیم، چه شکلی خواهد بود؟ ما از تجزیه و تحلیل خود می دانیم که یک کاندیدای "p_degree" بالا احتمال بیشتری دارد که استخدام شود. بنابراین، احتمالاً چیزی شبیه به این خواهد بود، که در آن نامزد با 'p_degree' کوچک در صفر خواهد بود. و کاندیدای با "p_degree" بالا در یک خواهد بود.

حالا فرض کنید میخواستیم رگرسیون خطی را با این کار انجام دهیم. فرض کنید میخواستیم خطی را ترسیم کنیم. اکنون، اگر این کار را انجام میدادیم، اتفاقی که میافتاد این است که خط به گونهای ترسیم میشد که سعی میکرد تا حد ممکن به همه نقاط نزدیک باشد. و بنابراین، احتمالاً به خطی میرسیم که چیزی شبیه به این است. آیا این مدل مدل خوبی خواهد بود؟
نه واقعا. چه اتفاقی میافتد این است که صرف نظر از درجه p کاندید، ما همیشه یک نوع ارزش را دریافت میکنیم. و این به ما کمکی نمیکند، زیرا اعداد در این زمینه، معنایی ندارند. این مشکل طبقهبندی باید یا صفر باشد یا یک. بنابراین، به این صورت کار نمیکند.
از طرف دیگر، چون این یک خط است، اگر کاندیدایی با مدرک p_خیلی پایین داشته باشیم، چطور؟ خب، ناگهان، تخمین ما یک عدد منفی است. و باز هم، این معنی ندارد. هیچ عدد منفی وجود ندارد، یا باید صفر یا یک باشد. و به همین ترتیب، اگر کاندیدایی با مدرک p_بسیار بالا داشته باشیم، ممکن است من یک نمره مثبت داشته باشم، چیزی بالاتر از یک. و باز هم، این معنایی ندارد. ما باید یک یا صفر داشته باشیم یا یک.
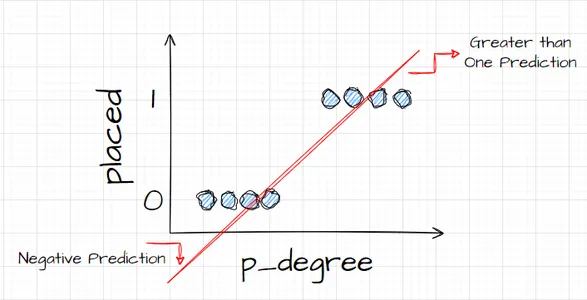
بنابراین، آنچه در اینجا میبینیم، محدودیتهای جدی برای استفاده از رگرسیون خطی برای طبقهبندی است. بنابراین، چه کاری باید انجام دهیم؟ ما باید مدلی بسازیم که شماره یک باشد: زیر صفر یا بالاتر از یک نمی رود، بنابراین باید بین صفر و یک محدود شود. و عدد دو، هرچه از شاید نباید آن را بهعنوان پیشبینی فی نفسه بلکه بهعنوان گامی به سوی پیشبینی نهایی در نظر بگیریم.
اکنون، اجازه دهید آنچه گفتم را باز کنم و به خود یادآوری کنیم که وقتی مدلهای رگرسیون خطی خود را انجام میدهیم، به این معادله خطی به پایان میرسیم، که سادهترین شکل است. و این همان معادله یا تابعی است که آن خط مستقیم را به ما می دهد.

راهی برای پیوند دادن آن خط بین 0 و 1 وجود دارد. و کاری که میتوانیم انجام دهیم این است که این تابع را که بهتازگی ایجاد کردهایم استفاده کنیم و آن را در یک تابع دیگر قرار دهیم، که به آن یک تابع میگویند. تابع سیگموئید.

بنابراین، من میخواهم معادله خطی را که قبلاً داشتیم، بگیرم و آن را در تابع سیگموید کوچک کنم و آن را به عنوان نمایی قرار دهم.
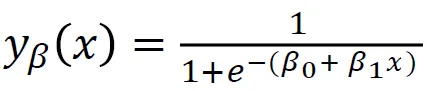
اتفاقی که میافتد این است که بهجای اینکه یک خط مستقیم بگیریم، خطی به این شکل میگیریم. در یک گیر کرده است. داخل میشود و پایین میآید. سپس روی صفر گیر کرده است.
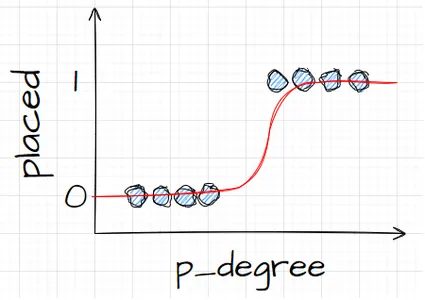
بسیار خوب، این خط به نظر می رسد، و ما می توانیم ببینیم که اولین مشکل خود را حل کرده ایم. هر چیزی که از این تابع خارج میشویم، بین 0 تا 1 خواهد بود. در مرحله دوم، هر چیزی که از این معادله به دست میآید به عنوان پیشبینی نهایی تلقی نمیکنیم. در عوض، آن را بهعنوان یک احتمال در نظر میگیریم.
منظورم چیست؟ این بدان معناست که وقتی پیشبینی میکنم، مقداری از ارزش ممیز شناور بین 0 تا 1 را دریافت میکنم. و کاری که انجام خواهم داد این است که آن را بهعنوان احتمال تعلق پیشبینی من به موارد مثبت در نظر بگیرم.
بنابراین من با 0.9999 مقدار بالا میبرم. من میگویم احتمال این که این نامزد به کلاس مثبت، قرارداده ما تعلق دارد ۹۹٪ است. بنابراین تقریباً مطمئن هستم که به کلاس مثبت تعلق دارد. برعکس، اگر در نقطه 99 یا هر چیز دیگری پایین باشد، میگویم این عدد پایین است. احتمال اینکه این مشاهده خاص متعلق به کلاس مثبت باشد، تقریباً صفر است. و بنابراین، من میخواهم بگویم که به کلاس صفر تعلق دارد.
بنابراین، برای اعدادی که نزدیک به یک یا نزدیک به صفر هستند، منطقی است. اما ممکن است از خود بپرسید، با سایر ارزشها چه کار میکنم؟ روش کار این است که ما یک خط برش را درست روی 0.5 قرار میدهیم، بنابراین هر مقداری که زیر آن خط قرار میگیرد، آن را روی صفر میگذارم، بنابراین پیشبینی من خیر است، و اگر بالاتر از یک خط باشد پنج، من این را در کلاس مثبت قرار میدهم، پیشبینی من یک است.
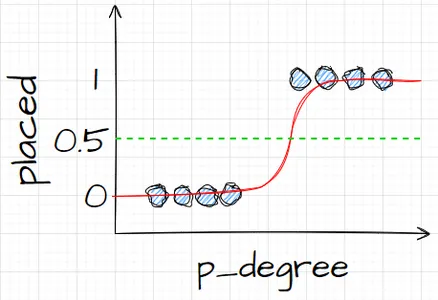
بنابراین، اکنون من تابعی دارم که به من پیشبینی بین صفر و یک میدهد، و آن را بهعنوان یک احتمال در نظر میگیرم. و اگر این احتمال بالای 0.5 یا 50 درصد باشد، میگویم، خوب، کلاس یک مثبت است. و اگر زیر ۵۰٪ باشد من میگویم، این کلاس منفی است، صفر. بنابراین رگرسیون لجستیک به این صورت است. و اکنون ما آن را میفهمیم، بیایید آن را کدگذاری کنیم و برازش کنیم. فراپارامتر «max_iter» را روی 50 تنظیم میکنم. این پارامتر به حداکثر تعداد دفعات تکرار برای حلکنندهها اشاره دارد.
# Build model
model = LogisticRegression(max_iter=1000) # Fit model to training data
model.fit(X_train, y_train) LogisticRegression(max_iter=1000)ارزیابی
اکنون وقت آن است که ببینیم مدل ما چگونه عمل میکند. زمان ارزیابی فرا رسیده است. بنابراین، بیایید به یاد داشته باشیم که این بار، معیار عملکرد مورد علاقه ما، امتیاز دقت است، و ما یک امتیاز دقیق میخواهیم. و ما میخواهیم از 0.68 به پایه بررسی کنیم. دقت مدل را میتوان با استفاده از تابع accuracy_score محاسبه کرد. این تابع به دو آرگومان نیاز دارد، برچسب های واقعی و برچسب های پیش بینی شده.
acc_train = accuracy_score(y_train, model.predict(X_train))
acc_test = model.score(X_test, y_test) print("Training Accuracy:", round(acc_train, 2))
print("Test Accuracy:", round(acc_test, 2)) Training Accuracy: 0.9
Test Accuracy: 0.88میتوانیم دقت آموزش خود را در ۹۰ درصد ببینیم. در حال شکست دادن خط پایه است. دقت آزمایش ما کمی پایینتر از ۸۸ درصد بود. همچنین خط پایه را شکست داد و به دقت تمرین ما بسیار نزدیک بود. بنابراین این خبر خوب است زیرا به این معناست که مدل ما بیش از حد یا هرچیز مناسب نیست. و این احتمالاً بهخوبی تعمیم مییابد، پس این خبر خوب است.
نتایج
به یاد داشته باشید که با رگرسیون لجستیک، به این پیشبینیهای نهایی صفر یا یک میرسیم. اما در زیر این پیشبینی، احتمال وجود یک عدد ممیز شناور بین صفر یا یک وجود دارد، و گاهی اوقات دیدن این که تخمینهای احتمالی چقدر هستند، میتواند مفید باشد. بیایید به پیشبینیهای آموزشی خود نگاه کنیم، و به پنج مورد اول نگاه کنیم. روش «پیشبینی» هدف یک مشاهده بدون برچسب را پیشبینی میکند.
model.predict(X_train)[:5] array([0, 1, 1, 1, 1])بنابراین اینها پیش بینی های نهایی بودند، اما احتمالات پشت آنها چیست؟ برای دریافت آن ها، باید یک کد کمی متفاوت انجام دهیم. به جای استفاده از روش «پیشبینی» با مدل خود، از «پیشبینی_پروبا» با دادههای آموزشی خود استفاده میکنم.
y_train_pred_proba = model.predict_proba(X_train)
print(y_train_pred_proba[:5]) [[0.92003219 0.07996781] [0.03202019 0.96797981] [0.00678421 0.99321579] [0.03889446 0.96110554] [0.00245525 0.99754475]]ما می توانیم نوعی لیست تو در تو را با دو ستون مختلف در آن ببینیم. ستون سمت چپ نشان دهنده احتمال قرار نگرفتن یک نامزد یا کلاس منفی ما 'Not Placed' است. ستون دیگر نشان دهنده کلاس مثبت 'Placed' یا احتمال قرار گرفتن یک نامزد است.
روی ستون دوم تمرکز خواهم کرد. اگر به اولین تخمین احتمال درست نگاه کنیم، میتوانیم ببینیم که این 0.07 است. بنابراین از آنجایی که زیر 50٪ است مدل ما میگوید پیشبینی من صفر است. و برای پیشبینیهای زیر، میتوانیم ببینیم که همه آنها بالاتر از 0.5 هستند، و به همین دلیل است که مدل ما در نهایت یک مورد را پیشبینی کرد.
حال می خواهیم نام و اهمیت ویژگی ها را استخراج کرده و در یک سری قرار دهیم. و از آنجایی که ما باید اهمیت ویژگی را به عنوان نسبت شانس نمایش دهیم، باید با در نظر گرفتن نمایی اهمیت خود، یک تغییر ریاضی کوچک انجام دهیم.
# Features names
features = ['gender', 'ssc_p', 'ssc_b', 'hsc_p', 'hsc_b', 'hsc_s', 'degree_p' ,'degree_t', 'workex', 'etest_p', 'specialisation', 'mba_p']
# Get importances
importances = model.coef_[0]
# Put importances into a Series
odds_ratios = pd.Series(np.exp(importances), index= features).sort_values()
# Review odds_ratios.head() mba_p 0.406590
degree_t 0.706021
specialisation 0.850301
hsc_b 0.876864
etest_p 0.877831
dtype: float64قبل از بحث در مورد نسبتهای شانس و چیستی آنها، اجازه دهید آنها را در نمودار میلهای افقی قرار دهیم. بیایید از پانداها برای ساختن طرح استفاده کنیم و به یاد داشته باشیم که به دنبال پنج ضریب بزرگ خواهیم بود. و ما نمی خواهیم از همه نسبت های شانس استفاده کنیم. بنابراین می خواهیم از دم استفاده کنیم.
# Horizontal bar chart, five largest coefficients
odds_ratios.tail().plot(kind="barh")
plt.xlabel("Odds Ratio")
plt.ylabel("Feature")
plt.title("High Importance Features");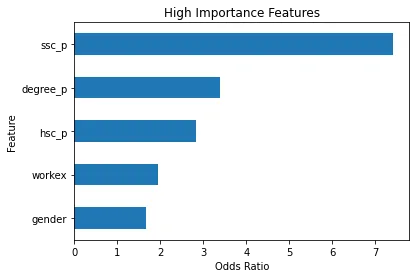
اکنون می خواهم یک خط عمودی را درست در 5 تصور کنید و می خواهم با نگاه کردن به آن شروع کنم. بیایید در مورد هر یک از اینها به صورت جداگانه یا فقط زوج اول صحبت کنیم. بنابراین بیایید از اینجا با «ssc_p» شروع کنیم، که به «درصد آموزش متوسطه - پایه دهم» اشاره دارد. و ما می توانیم ببینیم که نسبت شانس 10 است. حال، این به چه معناست؟ این بدان معناست که اگر یک نامزد دارای 'ssc_p' بالایی باشد، شانس قرار گرفتن آنها شش برابر بیشتر از سایر کاندیداها است، همه چیز برابر است. بنابراین راه دیگری برای فکر کردن به آن این است که زمانی که نامزد 'ssc_p' داشته باشد، شانس استخدام نامزد شش برابر افزایش می یابد.
بنابراین هر نسبت شانس بیش از پنج، شانس قرار گرفتن نامزدها را افزایش می دهد. و به همین دلیل است که ما آن خط عمودی را در پنج داریم. و این پنج نوع ویژگی ویژگی هایی هستند که بیشتر با افزایش استخدام مرتبط هستند. بنابراین، نسبت شانس ما همین است. اکنون، ما به ویژگی هایی که بیشترین ارتباط را با افزایش استخدام دارند، بررسی کرده ایم. بیایید به ویژگی های مرتبط با آن، کاهش استخدام نگاه کنیم. بنابراین اکنون وقت آن است که به کوچکترین آنها نگاه کنیم. بنابراین به جای نگاه کردن به دم، به آن نگاه خواهیم کرد.
odds_ratios.head().plot(kind="barh")
plt.xlabel("Odds Ratio")
plt.xlabel("Odds Ratio")
plt.ylabel("Feature")
plt.title("Low Importance Features");
اولین چیزی که در اینجا باید ببینیم این است که توجه داشته باشید در محور x همه چیز یک یا زیر است. حالا معنی اون چیه؟ بنابراین بیایید نگاهی به کوچکترین نسبت شانس خود بیندازیم. این mba_p است که به درصد MBA اشاره دارد. می بینیم که در حدود 0.45 آماده است. حالا معنی اون چیه؟ خوب، تفاوت بین 0.45 و 1 0.55 است. خیلی خوب؟ و این عدد به چه معناست؟ 55% احتمال کمتری دارد که داوطلبان دارای MBA استخدام شوند. خیلی خوب؟ بنابراین شانس استخدام را با ضریب 0.55 یا 55 درصد کاهش داد. و این برای همه چیز در اینجا صادق است.
نتیجه
خب، ما چی یاد گرفتیم؟ ابتدا، در مرحله داده های آماده شده، یاد گرفتیم که در حال کار با طبقه بندی، به طور خاص طبقه بندی باینری هستیم. از نظر کاوش در دادهها، ما کارهای زیادی انجام دادیم، اما از نظر نکات برجسته، به تعادل طبقاتی نگاه کردیم، درست است؟ نسبت طبقات مثبت و منفی ما. سپس داده های خود را برای مدل رگرسیون لجستیک تقسیم می کنیم.
از آنجایی که این یک مدل طبقه بندی است، ما در مورد یک معیار عملکرد جدید، امتیاز دقت، یاد گرفتیم. حالا نمره دقت بین 0 تا 1 می شود. صفر بد است و یک خوب است. وقتی در حال تکرار بودیم، در مورد رگرسیون لجستیک یاد گرفتیم. این یک راه جادویی است، که در آن شما می توانید یک معادله خطی، یک خط مستقیم را بردارید و آن را در یک تابع دیگر، یک تابع سیگموئید و یک تابع فعال سازی قرار دهید و یک تخمین احتمال از آن بگیرید و آن تخمین احتمال را به یک پیش بینی تبدیل کنید.
سپس با ارزیابی، دیدیم که دقت ما از خط مبنا پیشی گرفته است. بنابراین این یک یک خبر خوب بود. در نهایت، وقتی درباره نسبت شانس و روشی که میتوانیم ضرایب را در مدل رگرسیون لجستیک خود تفسیر کنیم، یاد گرفتیم تا ببینیم آیا یک ویژگی دادهشده، شانسی را که میتوانیم آن را افزایش دهیم، افزایش میدهد یا نه.
کد منبع پروژه: https://github.com/SawsanYusuf/Campus-Recruitment.git
رسانه نشان داده شده در این مقاله متعلق به Analytics Vidhya نیست و به صلاحدید نویسنده استفاده می شود.
مربوط
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- پلاتوبلاک چین. Web3 Metaverse Intelligence. دانش تقویت شده دسترسی به اینجا.
- منبع: https://www.analyticsvidhya.com/blog/2023/03/campus-recruitment-classification-with-logistic-regression/
- 1
- 10
- 11
- 214
- 7
- 9
- a
- درباره ما
- پذیرفته
- دقت
- فعال سازی
- پس از
- معرفی
- هر چند
- تحلیل
- علم تجزیه و تحلیل
- تجزیه و تحلیل Vidhya
- و
- دیگر
- اپارتمان
- استدلال
- استدلال
- دور و بر
- مقاله
- مرتبط است
- شرکت کننده
- محور
- زمینه
- بد
- برج میزان
- بار
- خط مقدم
- اساسا
- خوشگل
- زیرا
- قبل از
- پشت سر
- بودن
- در زیر
- بهتر
- میان
- بیت
- آبی
- جعبه
- ساختن
- بنا
- محاسبه
- محاسبه
- دانشگاه
- نامزد
- نامزد
- کاریابی
- مورد
- موارد
- دسته بندی
- مراکز
- شانس
- مشخصات
- چارت سازمانی
- بررسی
- را انتخاب کنید
- کلاس
- کلاس ها
- طبقه بندی
- طبقه بندی کنید
- رمز
- برنامه نویسی
- کالج
- ستون
- ستون ها
- تجارت
- ارتباط
- نگرانی
- نتیجه
- ارتباط
- زمینه
- همگرا
- هسته
- شرکت
- ارتباط
- میتوانست
- زن و شوهر
- دوره
- ایجاد
- داده ها
- تحلیل داده ها
- نقاط داده
- مجموعه داده ها
- معامله
- کاهش
- مستقر
- شرح
- جزئیات
- DID
- تفاوت
- مختلف
- اختیار
- بحث در مورد
- نمایش دادن
- متمایز
- توزیع
- توزیع
- عمل
- دلار
- آیا
- دو برابر
- پایین
- قطره
- کاهش یافته است
- هر
- آموزش
- آموزش
- جذاب
- کافی
- ورود به سطح
- تخمین زدن
- و غیره
- اتر (ETH)
- ارزیابی
- ارزیابی
- حتی
- همه چیز
- جز
- انتظار می رود
- تجربه
- تجزیه و تحلیل داده های اکتشافی
- اکتشاف
- بررسی
- نمایی
- عصاره
- ویژگی
- امکانات
- زن
- پرونده
- نهایی
- سرانجام
- نام خانوادگی
- مناسب
- تمرکز
- به دنبال
- پیروی
- فرم
- فرمول
- FRAME
- فرکانس
- از جانب
- تابع
- جنس
- عموما
- دریافت کنید
- رفتن
- دادن
- هدف
- می رود
- رفتن
- خوب
- گوگل
- بیشتر
- توری
- گروه
- دست
- اتفاق می افتد
- اینجا کلیک نمایید
- زیاد
- بالاتر
- بالاترین
- های لایت
- استخدام
- افقی
- چگونه
- چگونه
- HTTPS
- ایده ها
- واردات
- اهمیت
- مهم
- in
- شامل
- افزایش
- افزایش
- افزایش
- شاخص
- هندوستان
- فرد
- به طور جداگانه
- اطلاعات
- اطلاعات
- در عوض
- علاقه مند
- معرفی
- معرفی
- شامل
- موضوع
- IT
- نگاه داشتن
- نوع
- دانستن
- برچسب ها
- بزرگ
- بزرگترین
- نام
- یاد گرفتن
- آموخته
- یادگیری
- کتابخانه ها
- کتابخانه
- احتمالا
- لاین
- فهرست
- کوچک
- بار
- نگاه کنيد
- شبیه
- نگاه
- به دنبال
- خیلی
- کم
- دستگاه
- فراگیری ماشین
- ساخته
- اکثریت
- ساخت
- باعث می شود
- ریاضی
- ریاضی
- ماتپلوتلب
- ماتریس
- MBA
- به معنی
- معیارهای
- رسانه ها
- دیدار
- حافظه
- روش
- متری
- متریک
- گم
- مدل
- مدل
- بیش
- اکثر
- حرکت
- نام
- نوا
- نیاز
- منفی
- جدید
- اخبار
- طبیعی
- دفتر یادداشت
- عدد
- تعداد
- بی حس
- هدف
- هدف
- شانس
- خوب
- ONE
- سفارش
- دیگر
- متعلق به
- پانداها
- بخش
- درصد
- کامل
- انجام دادن
- کارایی
- اجرای
- شخص
- چشم انداز
- فاز
- محل
- افلاطون
- هوش داده افلاطون
- PlatoData
- نقطه
- موقعیت
- مثبت
- ممکن
- پتانسیل
- پیش بینی
- پیش بینی
- پیش گویی
- پیش بینی
- پیشگو
- پیش بینی می کند
- آماده شده
- آماده
- احتمال
- شاید
- مشکل
- مشکلات
- پروژه
- منتشر شده
- قرار دادن
- سوال
- تصادفی
- محدوده
- نسبت
- اماده
- واقعی
- دنیای واقعی
- دلیل
- اخیر
- سوابق
- استخدام
- اشاره دارد
- رگرسیون
- ارتباط
- ماندن
- به یاد داشته باشید
- نشان دهنده
- نیاز
- REST
- نتایج
- این فایل نقد می نویسید:
- سعید
- حقوق
- همان
- می گوید:
- علم
- یادگیری
- متولد دریا
- دوم
- به نظر می رسد
- حس
- سلسله
- خدمات
- تنظیم
- مجموعه
- هفت
- چند
- شکل
- باید
- نشان داده شده
- نشان می دهد
- قابل توجه
- مشابه
- پس از
- شش
- کمی متفاوت
- کوچک
- کوچکترین
- So
- برخی از
- چیزی
- منبع
- کد منبع
- سپارش
- به طور خاص
- انشعاب
- مربع
- شروع
- وضعیت
- گام
- راست
- استراتژی
- دانشجویان
- ناگهانی
- فوق العاده
- جدول
- گرفتن
- مصرف
- استعداد
- صحبت
- هدف
- قوانین و مقررات
- آزمون
- La
- شان
- خودشان
- چیز
- اشیاء
- فکر کردن
- زمان
- بار
- به
- تن
- جمع
- قطار
- آموزش
- دگرگونی
- تبدیل شدن
- درست
- دور زدن
- انواع
- منحصر به فرد
- دانشگاه
- us
- استفاده
- استفاده کنید
- معمولا
- ارزشمند
- اطلاعات ارزشمند
- ارزش
- ارزشها
- متغیرها
- تجسم
- چی
- چه شده است
- چه
- که
- WHO
- اراده
- مهاجرت کاری
- گردش کار
- کارگر
- با این نسخهها کار
- جهان
- خواهد بود
- می داد
- X
- جوان
- خودت
- زفیرنت
- صفر






![راهنمای مدیریت فایل در پایتون [توضیح داده شده با مثال]](https://platoaistream.net/wp-content/uploads/2024/01/guide-to-file-handling-in-python-explained-with-examples-360x202.jpg)