استقرار مدلهای یادگیری ماشینی آموزشدیده (ML) با کیفیت بالا برای انجام استنتاج دستهای یا زمان واقعی، بخش مهمی برای ارزشبخشی به مشتریان است. با این حال، فرآیند آزمایش ML می تواند خسته کننده باشد - رویکردهای زیادی وجود دارد که به زمان قابل توجهی برای پیاده سازی نیاز دارند. به همین دلیل است که مدل های ML از قبل آموزش دیده مانند مدل های ارائه شده در باغ وحش مدل PyTorch بسیار مفید هستند آمازون SageMaker یک رابط یکپارچه برای آزمایش با مدلهای مختلف ML ارائه میکند، و PyTorch Model Zoo به ما این امکان را میدهد تا مدلهای خود را بهصورت استاندارد شده به راحتی تعویض کنیم.
این پست وبلاگ نحوه انجام استنتاج ML را با استفاده از یک مدل تشخیص شی از باغ وحش PyTorch Model در SageMaker نشان می دهد. مدل های ML از پیش آموزش دیده باغ وحش مدل PyTorch آماده هستند و به راحتی می توانند به عنوان بخشی از برنامه های ML استفاده شوند. راه اندازی این مدل های ML به عنوان نقطه پایانی SageMaker یا SageMaker Batch Transform کار برای استنتاج آنلاین یا آفلاین با مراحل ذکر شده در این پست وبلاگ آسان است. از a استفاده خواهیم کرد R-CNN سریعتر مدل تشخیص شی برای پیشبینی جعبههای مرزی برای کلاسهای شی از پیش تعریفشده.
ما از طریق یک مثال سرتاسر، از بارگیری وزنهای مدل تشخیص شی سریعتر R-CNN تا ذخیره آنها در سرویس ذخیره سازی ساده آمازون (Amazon S3) سطل، و برای نوشتن یک فایل ورودی و درک پارامترهای کلیدی در PyTorchModel API. در نهایت، مدل ML را مستقر میکنیم، با استفاده از SageMaker Batch Transform استنتاج را روی آن انجام میدهیم و خروجی مدل ML را بررسی میکنیم و نحوه تفسیر نتایج را یاد میگیریم. این راه حل را می توان برای هر مدل از پیش آموزش دیده دیگری در باغ وحش مدل PyTorch اعمال کرد. برای لیستی از مدل های موجود، به ادامه مطلب مراجعه کنید مستندات باغ وحش مدل PyTorch.
بررسی اجمالی راه حل
این پست وبلاگ مراحل زیر را طی خواهد کرد. برای نسخه کامل کار همه مراحل، نگاه کنید create_pytorch_model_sagemaker.ipynb
- مرحله 1: راه اندازی
- مرحله 2: بارگیری یک مدل ML از PyTorch Model Zoo
- مرحله 3 مصنوعات مدل ML را در آمازون S3 ذخیره و آپلود کنید
- مرحله 4: ساخت اسکریپت های استنتاج مدل ML
- مرحله 5: راه اندازی یک کار تبدیل دسته ای SageMaker
- مرحله 6: تجسم نتایج
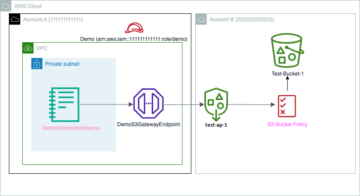
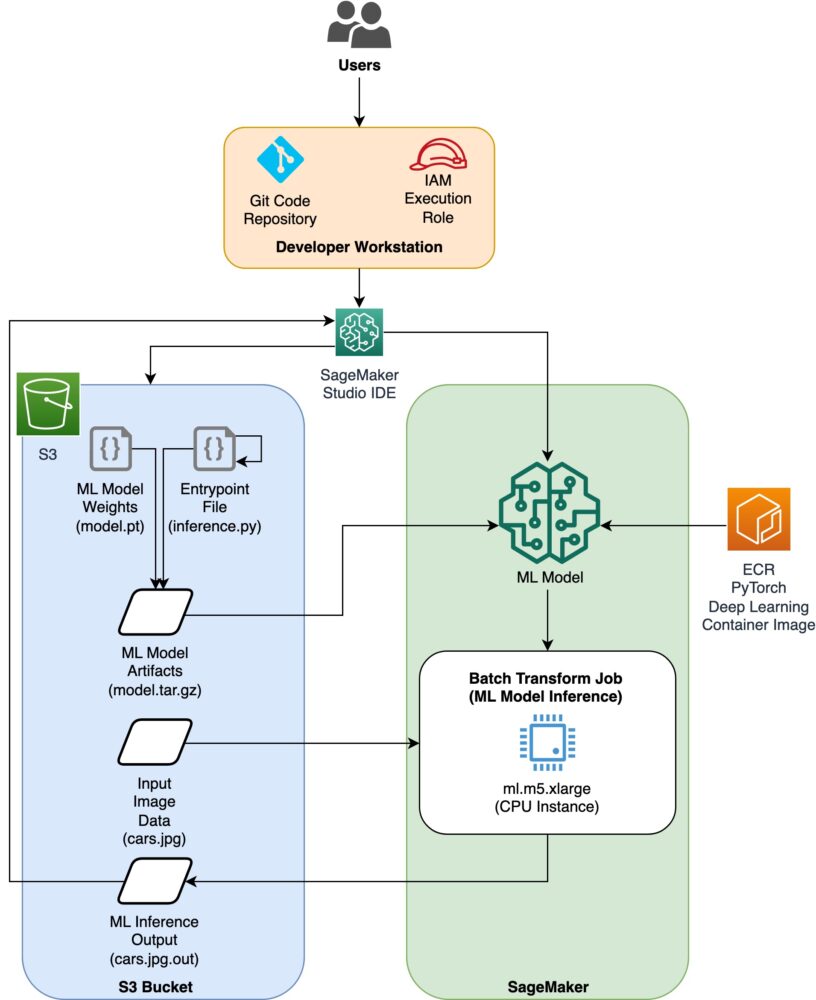
نمودار معماری

ساختار دایرکتوری
کد این وبلاگ را می توانید در این مطلب پیدا کنید مخزن GitHub. پایگاه کد شامل همه چیزهایی است که برای ساخت مصنوعات مدل ML، راه اندازی کار تبدیل و تجسم نتایج به آن نیاز داریم.
این جریان کاری است که ما استفاده می کنیم. تمام مراحل زیر به ماژول های این ساختار اشاره دارد.
La sagemaker_torch_model_zoo پوشه باید حاوی inference.py به عنوان یک فایل ورودی، و create_pytorch_model_sagemaker.ipynb را برای بارگیری و ذخیره وزن های مدل، ایجاد یک شی مدل SageMaker، و در نهایت آن را به یک کار تبدیل دسته ای SageMaker ارسال کنید. برای اینکه مدل های ML خود را بیاورید، مسیرها را در قسمت Step 1: setup notebook تغییر دهید و یک مدل جدید را در مرحله 2: Loading an ML Model از بخش PyTorch Model Zoo بارگذاری کنید. بقیه مراحل زیر در ادامه به همین صورت باقی می مانند.
مرحله 1: راه اندازی
نقش های IAM
SageMaker عملیاتی را روی زیرساختی انجام می دهد که توسط SageMaker مدیریت می شود. SageMaker فقط میتواند اقداماتی را که در نقش اجرای IAM همراه نوتبوک برای SageMaker تعریف شده است، انجام دهد. برای مستندات دقیق تر در مورد ایجاد نقش های IAM و مدیریت مجوزهای IAM، به بخش مراجعه کنید اسناد نقش های AWS SageMaker. میتوانیم نقش جدیدی خلق کنیم، یا میتوانیم آن را دریافت کنیم نوت بوک SageMaker (Studio).نقش اجرای پیشفرض با اجرای خطوط کد زیر:
کد بالا نقش اجرای SageMaker را برای نمونه نوت بوک دریافت می کند. این نقش IAM است که ما برای نمونه نوت بوک SageMaker یا SageMaker Studio خود ایجاد کردیم.
پارامترهای قابل تنظیم توسط کاربر
در اینجا تمام پارامترهای قابل تنظیم مورد نیاز برای ایجاد و راه اندازی کار تبدیل دسته ای SageMaker ما آمده است:
مرحله 2: بارگیری یک مدل ML از باغ وحش مدل PyTorch
در مرحله بعد، یک مدل تشخیص شی از باغ وحش PyTorch Model مشخص می کنیم و وزن مدل ML آن را ذخیره می کنیم. به طور معمول، ما یک مدل PyTorch را با استفاده از پسوندهای فایل .pt یا pth ذخیره می کنیم. قطعه کد زیر یک مدل سریعتر R-CNN ResNet50 ML از پیش آموزش دیده را از باغ وحش مدل PyTorch دانلود می کند:
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
تبدیل دستهای SageMaker به وزنهای مدل به عنوان ورودی نیاز دارد، بنابراین مدل ML از پیش آموزشدیدهشده را بهعنوان model.pt ذخیره میکنیم. اگر میخواهیم یک مدل سفارشی بارگذاری کنیم، میتوانیم وزنهای مدل را از یک مدل PyTorch دیگر بهعنوان model.pt ذخیره کنیم.
مرحله 3: مصنوعات مدل ML را در Amazon S3 ذخیره و آپلود کنید
از آنجایی که ما از SageMaker برای استنتاج ML استفاده خواهیم کرد، باید وزن های مدل را در یک سطل S3 آپلود کنیم. ما می توانیم این کار را با استفاده از دستورات زیر یا با دانلود و به سادگی کشیدن و رها کردن فایل به طور مستقیم در S3 انجام دهیم. دستورات زیر ابتدا گروه فایل های داخل را فشرده می کند model.pt به یک تاربول و وزن های مدل را از دستگاه محلی ما در سطل S3 کپی کنید.
توجه داشته باشید: برای اجرای دستورات زیر باید داشته باشید رابط خط فرمان AWS (AWS CLI) نصب شده است.
بعد، تصویر ورودی خود را در S3 کپی می کنیم. در زیر مسیر کامل S3 برای تصویر آمده است.
ما می توانیم این تصویر را با دستور دیگری aws s3 cp روی S3 کپی کنیم.
مرحله 4: ساخت اسکریپت های استنتاج مدل ML
اکنون به فایل ورودی خود می پردازیم، inference.py مدول. ما می توانیم یک مدل PyTorch را که در خارج از SageMaker آموزش داده شده است، با استفاده از کلاس PyTorchModel مستقر کنیم. ابتدا شی PyTorchModelZoo را نمونه سازی می کنیم. سپس یک فایل ورودی inference.py برای انجام استنتاج ML با استفاده از تبدیل دسته ای SageMaker بر روی داده های نمونه میزبانی شده در آمازون S3 می سازیم.
درک شی PyTorchModel
La PyTorchModel کلاس در SageMaker Python API به ما اجازه می دهد تا استنتاج ML را با استفاده از آرتیفکت مدل دانلود شده خود انجام دهیم.
برای شروع کلاس PyTorchModel، باید پارامترهای ورودی زیر را درک کنیم:
name: نام مدل؛ توصیه می کنیم از نام مدل + تاریخ زمان یا یک رشته تصادفی + زمان تاریخ برای منحصر به فرد بودن استفاده کنید.model_data: S3 URI آرتیفکت مدل بسته بندی شده ML.entry_point: یک فایل پایتون تعریف شده توسط کاربر که توسط تصویر داکر استنتاج برای تعریف کنترلکنندهها برای درخواستهای ورودی استفاده میشود. کد بارگذاری مدل، پیش پردازش ورودی، منطق پیش بینی و پس پردازش خروجی را تعریف می کند.framework_version: برای فعال کردن بسته بندی خودکار مدل PyTorch باید روی نسخه 1.2 یا بالاتر تنظیم شود.source_dir: دایرکتوری فایل enter_point.role: نقش IAM برای درخواست خدمات AWS.image_uri: از این تصویر کانتینر Amazon ECR Docker به عنوان پایه ای برای محیط محاسباتی مدل ML استفاده کنید.sagemaker_session: جلسه SageMaker.py_version: نسخه پایتون مورد استفاده
قطعه کد زیر کلاس PyTorchModel را برای انجام استنتاج با استفاده از مدل PyTorch از پیش آموزش دیده نمونه می کند:
درک فایل ورودی (inference.py)
پارامتر enter_point به یک فایل پایتون با نام اشاره می کند inference.py. این نقطه ورودی بارگذاری مدل، پیش پردازش ورودی، منطق پیش بینی و پس پردازش خروجی را تعریف می کند. این کد سرویس دهنده مدل ML را در PyTorch از پیش ساخته شده تکمیل می کند ظرف یادگیری عمیق SageMaker تصویر
Inference.py شامل توابع زیر خواهد بود. در مثال ما، ما را اجرا می کنیم model_fn, input_fn, predict_fn و output_fn توابع برای نادیده گرفتن کنترل کننده استنتاج پیش فرض PyTorch.
model_fn: یک دایرکتوری حاوی نقاط بازرسی مدل ایستا در تصویر استنتاج می گیرد. مدل را از یک مسیر مشخص باز می کند و بارگذاری می کند و یک مدل PyTorch را برمی گرداند.input_fn: بار درخواست ورودی (request_body) و نوع محتوای درخواست ورودی (request_content_type) را به عنوان ورودی دریافت می کند. رمزگشایی داده ها را کنترل می کند. این تابع باید برای ورودی مورد انتظار مدل تنظیم شود.predict_fn: یک مدل را بر روی داده های deserialized در input_fn فراخوانی می کند. با مدل ML بارگذاری شده، روی شی deserialized پیش بینی می کند.output_fn: نتیجه پیش بینی را به نوع محتوای پاسخ دلخواه سریال می کند. پیش بینی های به دست آمده از تابع predict_fn را به فرمت های JSON، CSV یا NPY تبدیل می کند.
مرحله 5: راه اندازی یک کار تبدیل دسته ای SageMaker
برای این مثال، ما نتایج استنتاج ML را از طریق یک کار تبدیل دسته ای SageMaker به دست خواهیم آورد. کارهای تبدیل دسته ای زمانی بسیار مفید هستند که بخواهیم یک بار استنتاج از مجموعه داده ها را بدون نیاز به نقطه پایانی پایدار بدست آوریم. الف را نمونه می کنیم حکیم ساز.ترانسفورماتور.ترانسفورماتور شی برای ایجاد و تعامل با کارهای تبدیل دسته ای SageMaker.
مستندات ایجاد یک کار تبدیل دسته ای را در اینجا ببینید CreateTransformJob.
مرحله 6: تجسم نتایج
هنگامی که کار تبدیل دسته ای SageMaker به پایان رسید، می توانیم خروجی های استنتاج ML را از Amazon S3 بارگذاری کنیم. برای این کار به مسیر بروید کنسول مدیریت AWS و Amazon SageMaker را جستجو کنید. در پانل سمت چپ، زیر استنباط، نگاه کنید به مشاغل تبدیل دسته ای.

بعد از انتخاب تبدیل دسته ای، صفحه وب را ببینید که تمام کارهای تبدیل دسته ای SageMaker را فهرست می کند. ما می توانیم پیشرفت آخرین اجرای کار خود را مشاهده کنیم.

ابتدا، کار وضعیت «در حال پیشرفت» را خواهد داشت. پس از اتمام، تغییر وضعیت به تکمیل شده را مشاهده کنید.

هنگامی که وضعیت به عنوان تکمیل شده علامت گذاری شد، می توانیم روی کار کلیک کنیم تا نتایج را مشاهده کنیم. این صفحه وب شامل خلاصه کار، از جمله تنظیمات کاری است که به تازگی اجرا کردیم.

تحت پیکربندی داده های خروجی، یک مسیر خروجی S3 را مشاهده خواهیم کرد. اینجاست که خروجی استنتاج ML خود را پیدا می کنیم.

مسیر خروجی S3 را انتخاب کنید و یک فایل [image_name].[file_type].out را با داده های خروجی ما ببینید. فایل خروجی ما حاوی لیستی از نگاشت ها خواهد بود. خروجی نمونه:
در مرحله بعد، این فایل خروجی را پردازش می کنیم و پیش بینی های خود را تجسم می کنیم. در زیر آستانه اطمینان خود را مشخص می کنیم. ما لیست کلاس ها را از نقشه برداری شیء مجموعه داده COCO. در طول استنتاج، مدل فقط به تانسورهای ورودی نیاز دارد و پیشبینیهای پس از پردازش را بهعنوان فهرست [Dict[Tensor]]، یکی برای هر تصویر ورودی، برمیگرداند. فیلدهای Dict به شرح زیر است، که در آن N تعداد شناسایی است:
- جعبه ها (FloatTensor[N, 4]): جعبه های پیش بینی شده در
[x1, y1, x2, y2]قالب ، با0 <= x1 < x2 <= W and 0 <= y1 < y2 <= H، که در آنWعرض تصویر است وHارتفاع تصویر است - برچسب ها (
Int64Tensor[N]): برچسب های پیش بینی شده برای هر تشخیص - امتیازات (
Tensor[N]): امتیازهای پیش بینی برای هر تشخیص
برای جزئیات بیشتر در مورد خروجی، مراجعه کنید اسناد PyTorch سریعتر R-CNN FPN.
خروجی مدل شامل جعبه های محدود کننده با امتیازهای اطمینان مربوطه است. ما میتوانیم با حذف کادرهای محدودکنندهای که مدل برای آنها مطمئن نیست، نمایش مثبت کاذب را بهینه کنیم. قطعه کد زیر پیشبینیهای موجود در فایل خروجی را پردازش میکند و جعبههای مرزی را روی پیشبینیهایی ترسیم میکند که امتیاز بالاتر از آستانه اطمینان ما است. ما آستانه احتمال را تعیین می کنیم، CONF_THRESHبرای این مثال تا 75.
در نهایت، ما این نگاشت ها را برای درک خروجی خود مجسم می کنیم.

توجه داشته باشید: اگر تصویر در نوت بوک شما نمایش داده نمی شود، لطفاً آن را در درخت دایرکتوری در سمت چپ JupyterLab پیدا کرده و از آنجا باز کنید.
اجرای کد نمونه
برای یک مثال کار کامل، کد موجود در آن را شبیه سازی کنید amazon-sagemaker-examples GitHub و سلول های موجود در create_pytorch_model_sagemaker.ipynb نوت بوک.
نتیجه
در این پست وبلاگ، ما یک مثال سرتاسری از انجام استنتاج ML با استفاده از یک مدل تشخیص شی از باغ وحش مدل PyTorch با استفاده از تبدیل دستهای SageMaker به نمایش گذاشتیم. ما بارگذاری وزنهای مدل تشخیص شی سریعتر R-CNN، ذخیره آنها در یک سطل S3، نوشتن یک فایل ورودی، و درک پارامترهای کلیدی در PyTorchModel API را پوشش دادیم. در نهایت، مدل را مستقر کردیم و استنتاج مدل ML را انجام دادیم، خروجی مدل را تجسم کردیم و یاد گرفتیم که چگونه نتایج را تفسیر کنیم.
درباره نویسنده
 دیپیکا خولار مهندس ML در آزمایشگاه راه حل های آمازون ام ال. او به مشتریان کمک می کند تا راه حل های ML را برای حل مشکلات تجاری خود ادغام کنند. اخیراً، او خطوط لوله آموزشی و استنباط را برای مشتریان رسانه ای و مدل های پیش بینی کننده برای بازاریابی ایجاد کرده است.
دیپیکا خولار مهندس ML در آزمایشگاه راه حل های آمازون ام ال. او به مشتریان کمک می کند تا راه حل های ML را برای حل مشکلات تجاری خود ادغام کنند. اخیراً، او خطوط لوله آموزشی و استنباط را برای مشتریان رسانه ای و مدل های پیش بینی کننده برای بازاریابی ایجاد کرده است.
 مارسلو آبرله مهندس ML در سازمان AWS AI است. او رهبری تلاشهای MLOps را بر عهده دارد آزمایشگاه راه حل های آمازون ام ال، به مشتریان در طراحی و پیاده سازی سیستم های مقیاس پذیر ML کمک می کند. ماموریت او هدایت مشتریان در سفر ML سازمانی و تسریع در مسیر ML آنها به سمت تولید است.
مارسلو آبرله مهندس ML در سازمان AWS AI است. او رهبری تلاشهای MLOps را بر عهده دارد آزمایشگاه راه حل های آمازون ام ال، به مشتریان در طراحی و پیاده سازی سیستم های مقیاس پذیر ML کمک می کند. ماموریت او هدایت مشتریان در سفر ML سازمانی و تسریع در مسیر ML آنها به سمت تولید است.
 نیناد کولکارنی دانشمند کاربردی در آزمایشگاه راه حل های آمازون ام ال. او با ایجاد راه حل هایی برای رفع مشکلات تجاری به مشتریان کمک می کند تا ML و AI را اتخاذ کنند. اخیراً، او مدلهای پیشبینیکننده برای مشتریان ورزشی، خودرویی و رسانهای ساخته است.
نیناد کولکارنی دانشمند کاربردی در آزمایشگاه راه حل های آمازون ام ال. او با ایجاد راه حل هایی برای رفع مشکلات تجاری به مشتریان کمک می کند تا ML و AI را اتخاذ کنند. اخیراً، او مدلهای پیشبینیکننده برای مشتریان ورزشی، خودرویی و رسانهای ساخته است.
 یاش شاه مدیر علوم در آزمایشگاه راه حل های آمازون ام ال. او و تیمش از دانشمندان کاربردی و مهندسان ML روی طیف وسیعی از موارد استفاده از ML از مراقبتهای بهداشتی، ورزشی، خودروسازی و تولید کار میکنند.
یاش شاه مدیر علوم در آزمایشگاه راه حل های آمازون ام ال. او و تیمش از دانشمندان کاربردی و مهندسان ML روی طیف وسیعی از موارد استفاده از ML از مراقبتهای بهداشتی، ورزشی، خودروسازی و تولید کار میکنند.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- پلاتوبلاک چین. Web3 Metaverse Intelligence. دانش تقویت شده دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/create-amazon-sagemaker-models-using-the-pytorch-model-zoo/
- 1
- 100
- 214
- 28
- 7
- 9
- a
- بالاتر
- شتاب دادن
- اقدامات
- نشانی
- تنظیم شده
- اتخاذ
- AI
- معرفی
- اجازه می دهد تا
- آمازون
- آمازون SageMaker
- مقدار
- و
- دیگر
- API
- برنامه های کاربردی
- اعمال می شود
- رویکردها
- اتوماتیک
- خودرو
- در دسترس
- AWS
- پایه
- در زیر
- بلاگ
- بدن
- جعبه
- جعبه
- به ارمغان بیاورد
- آوردن
- ساختن
- بنا
- ساخته
- کسب و کار
- تماس ها
- ماشین
- اتومبیل
- موارد
- سلول ها
- تغییر دادن
- کلاس
- کلاس ها
- رمز
- پایه کد
- رنگ
- تکمیل شده
- محاسبه
- کامپیوتر
- اعتماد به نفس
- مطمئن
- ساختن
- ظرف
- شامل
- محتوا
- میتوانست
- پوشش داده شده
- ایجاد
- ایجاد شده
- ایجاد
- بحرانی
- سفارشی
- مشتریان
- داده ها
- مجموعه داده ها
- تاریخ
- رمز گشایی
- عمیق
- یادگیری عمیق
- به طور پیش فرض
- تعریف می کند
- گسترش
- مستقر
- طرح
- دقیق
- جزئیات
- کشف
- DICT
- مختلف
- مستقیما
- نمایش دادن
- کارگر بارانداز
- مستندات
- نمی کند
- دانلود
- رها کردن
- هر
- به آسانی
- تلاش
- هر دو
- قادر ساختن
- پشت سر هم
- نقطه پایانی
- مهندس
- مورد تأیید
- سرمایه گذاری
- ورود
- محیط
- اتر (ETH)
- همه چیز
- مثال
- اعدام
- تجربه
- ضمیمهها
- سریعتر
- زمینه
- پرونده
- فایل ها
- پر کردن
- سرانجام
- پیدا کردن
- نام خانوادگی
- پیروی
- به دنبال آن است
- قالب
- یافت
- از جانب
- کامل
- تابع
- توابع
- دریافت کنید
- Go
- گروه
- راهنمایی
- دستگیره
- بهداشت و درمان
- ارتفاع
- مفید
- کمک
- کمک می کند
- با کیفیت بالا
- بالاتر
- میزبانی
- چگونه
- چگونه
- اما
- HTML
- HTTPS
- تصویر
- تصاویر
- انجام
- in
- از جمله
- وارد شونده
- شاخص
- شالوده
- وارد کردن
- ورودی
- نمونه
- در عوض
- ادغام
- تعامل
- رابط
- IT
- JIT
- کار
- شغل ها
- سفر
- json
- کلید
- آزمایشگاه
- برچسب
- برچسب ها
- راه اندازی
- راه اندازی
- برجسته
- یاد گرفتن
- آموخته
- یادگیری
- لاین
- خطوط
- فهرست
- فهرست
- بار
- بارگیری
- بارهای
- محلی
- خیلی
- دستگاه
- فراگیری ماشین
- ساخت
- اداره می شود
- مدیریت
- مدیر
- مدیریت
- روش
- تولید
- نقشه برداری
- بازار یابی (Marketing)
- رسانه ها
- ماموریت
- ML
- MLO ها
- مدل
- مدل
- ماژول ها
- بیش
- اکثر
- نام
- تحت عنوان
- هدایت
- نیاز
- نیازهای
- جدید
- دفتر یادداشت
- عدد
- هدف
- تشخیص شی
- به دست آمده
- آنلاین نیست.
- ONE
- آنلاین
- باز کن
- باز می شود
- عملیات
- بهینه سازی
- سفارش
- کدام سازمان ها
- OS
- دیگر
- مشخص شده
- خارج از
- خود
- تابلو
- پارامتر
- پارامترهای
- بخش
- مسیر
- انجام دادن
- انجام
- انجام می دهد
- قطعه
- افلاطون
- هوش داده افلاطون
- PlatoData
- لطفا
- نقطه
- نقطه
- پست
- پیش بینی
- پیش بینی
- پیش گویی
- پیش بینی
- مشکلات
- روند
- تولید
- پیشرفت
- ارائه
- فراهم می کند
- پــایتــون
- مارماهی
- محدوده
- خواندن
- زمان واقعی
- اخیر
- تازه
- توصیه
- منطقه
- ماندن
- از بین بردن
- درخواست
- درخواست
- نیاز
- قابل احترام
- پاسخ
- REST
- نتیجه
- نتایج
- برگشت
- بازده
- نقش
- نقش
- ریشه
- دویدن
- در حال اجرا
- حکیم ساز
- همان
- ذخیره
- صرفه جویی کردن
- مقیاس پذیر
- علم
- دانشمند
- دانشمندان
- جستجو
- بخش
- انتخاب
- سرویس
- خدمت
- جلسه
- تنظیم
- محیط
- باید
- قابل توجه
- ساده
- به سادگی
- So
- راه حل
- مزایا
- حل
- برخی از
- مشخص شده
- ورزش ها
- ورزش ها
- وضعیت
- گام
- مراحل
- ذخیره سازی
- ساختار
- استودیو
- خلاصه
- سیستم های
- طول می کشد
- تیم
- La
- شان
- آستانه
- از طریق
- زمان
- به
- مشعل
- چشم انداز مشعل
- آموزش دیده
- آموزش
- دگرگون کردن
- به طور معمول
- زیر
- فهمیدن
- درک
- us
- استفاده کنید
- ارزش
- نسخه
- چشم انداز
- W
- چی
- که
- اراده
- در داخل
- بدون
- مهاجرت کاری
- کارگر
- خواهد بود
- نوشته
- شما
- زفیرنت
- ZOO