هر روز، دستگاههای آمازون میلیاردها تراکنش را از تیمهای حمل و نقل جهانی، موجودی، ظرفیت، عرضه، فروش، بازاریابی، تولیدکنندگان و خدمات مشتری پردازش و تجزیه و تحلیل میکنند. این داده ها در تهیه موجودی دستگاه ها برای برآورده کردن خواسته های مشتریان آمازون استفاده می شود. با توجه به اینکه حجم دادهها نرخ رشد سالانه دو رقمی را نشان میدهند و همهگیری کووید، لجستیک جهانی را در سال 2021 مختل میکند، مقیاسسازی و تولید دادههای تقریباً در زمان واقعی حیاتیتر شد.
این پست به شما نشان می دهد که چگونه به یک دریاچه داده بدون سرور ساخته شده بر روی AWS که داده ها را به طور خودکار از منابع مختلف و فرمت های مختلف مصرف می کند، مهاجرت کردیم. علاوه بر این، فرصت های بیشتری را برای دانشمندان و مهندسان داده ما ایجاد کرد تا از خدمات هوش مصنوعی و یادگیری ماشین (ML) برای تغذیه و تجزیه و تحلیل مداوم داده ها استفاده کنند.
چالش ها و دغدغه های طراحی
معماری میراث ما در درجه اول استفاده می شود ابر محاسبه الاستیک آمازون (Amazon EC2) برای استخراج داده ها از منابع داده ناهمگن داخلی مختلف و API های REST با ترکیبی از سرویس ذخیره سازی ساده آمازون (Amazon S3) برای بارگذاری داده ها و آمازون Redshift برای تجزیه و تحلیل بیشتر و ایجاد سفارشات خرید.
ما متوجه شدیم که این رویکرد منجر به چند نقص می شود و بنابراین باعث بهبود در زمینه های زیر شده است:
- سرعت توسعه دهنده - به دلیل عدم یکپارچگی و کشف طرحواره، که دلایل اصلی خرابی در زمان اجرا هستند، توسعه دهندگان اغلب وقت خود را صرف رسیدگی به مسائل عملیاتی و نگهداری می کنند.
- مقیاس پذیری - بیشتر این مجموعه داده ها در سراسر جهان به اشتراک گذاشته می شوند. بنابراین، هنگام جستجوی داده ها باید محدودیت های مقیاس بندی را رعایت کنیم.
- حداقل نگهداری زیرساخت - فرآیند فعلی بسته به منبع داده، چندین محاسبات را در بر می گیرد. بنابراین، کاهش تعمیر و نگهداری زیرساخت حیاتی است.
- پاسخگویی به تغییرات منبع داده - سیستم فعلی ما داده ها را از فروشگاه ها و سرویس های مختلف داده های ناهمگن دریافت می کند. هر بهروزرسانی برای این سرویسها ماهها چرخه توسعهدهنده طول میکشد. زمان پاسخ برای این منابع داده برای ذینفعان کلیدی ما حیاتی است. بنابراین، ما باید یک رویکرد داده محور برای انتخاب یک معماری با کارایی بالا داشته باشیم.
- ذخیره سازی و افزونگی - با توجه به مدلها و فروشگاههای داده ناهمگون، ذخیره مجموعه دادههای مختلف از تیمهای مختلف ذینفعان تجاری چالش برانگیز بود. بنابراین، داشتن نسخهسازی همراه با دادههای افزایشی و دیفرانسیل برای مقایسه، توانایی قابل توجهی را برای تولید طرحهای بهینهتر فراهم میکند.
- فراری و دسترسی - به دلیل ماهیت بی ثبات لجستیک، چند تیم ذینفع کسب و کار نیاز به تجزیه و تحلیل داده ها بر اساس تقاضا و ایجاد برنامه بهینه تقریباً واقعی برای سفارشات خرید دارند. این نیاز به نظرسنجی و فشار دادن به داده ها برای دسترسی و تجزیه و تحلیل در زمان واقعی را نشان می دهد.
استراتژی پیاده سازی
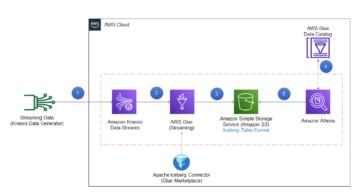
بر اساس این الزامات، استراتژی ها را تغییر دادیم و شروع به تجزیه و تحلیل هر موضوع برای شناسایی راه حل کردیم. از نظر معماری، ما یک مدل بدون سرور را انتخاب کردیم و خط اقدام معماری دریاچه داده به تمام شکافهای معماری و ویژگیهای چالشبرانگیز که تشخیص دادیم بخشی از پیشرفتها هستند، اشاره دارد. از نقطه نظر عملیاتی، ما یک مدل مسئولیت مشترک جدید برای استفاده از دادهها طراحی کردیم چسب AWS به جای سرویس های داخلی (REST API) طراحی شده در Amazon EC2 برای استخراج داده ها. ما هم استفاده کردیم AWS لامبدا برای پردازش داده ها سپس ما انتخاب کردیم آمازون آتنا به عنوان خدمات پرس و جو ما. برای بهینه سازی بیشتر و بهبود سرعت توسعه دهنده برای مصرف کنندگان داده، ما اضافه کردیم آمازون DynamoDB به عنوان یک ذخیره ابرداده برای منابع داده های مختلف که در دریاچه داده فرود می آیند. این دو تصمیم، هر تصمیم طراحی و اجرای ما را هدایت میکرد.
نمودار زیر معماری را نشان می دهد

در بخشهای بعدی، در حین حرکت در جریان فرآیند، به هر جزء در معماری با جزئیات بیشتری نگاه میکنیم.
چسب AWS برای ETL
برای پاسخگویی به تقاضای مشتری و در عین حال پشتیبانی از مقیاس منابع دادهای کسبوکارهای جدید، داشتن درجه بالایی از چابکی، مقیاسپذیری و پاسخگویی در جستوجوی منابع داده مختلف برای ما حیاتی بود.
AWS Glue یک سرویس یکپارچهسازی دادههای بدون سرور است که کشف، آمادهسازی، انتقال و ادغام دادهها از چندین منبع را برای کاربران تجزیه و تحلیل آسان میکند. می توانید از آن برای تجزیه و تحلیل، ML و توسعه برنامه استفاده کنید. همچنین شامل بهرهوری بیشتر و ابزار DataOps برای نوشتن، اجرای مشاغل و پیادهسازی گردشهای کاری تجاری است.
با چسب AWS، می توانید بیش از 70 منبع داده متنوع را کشف کرده و به آن متصل شوید و داده های خود را در یک کاتالوگ داده متمرکز مدیریت کنید. شما می توانید به صورت بصری خطوط لوله استخراج، تبدیل، و بارگذاری (ETL) را ایجاد، اجرا و نظارت کنید تا داده ها را در دریاچه های داده خود بارگیری کنید. همچنین، میتوانید بلافاصله دادههای فهرستبندی شده را با استفاده از Athena جستجو و پرس و جو کنید. آمازون EMRو آمازون Redshift Spectrum.
چسب AWS اتصال به دادهها را در فروشگاههای داده مختلف، ویرایش و تمیز کردن دادهها در صورت نیاز و بارگذاری دادهها در یک فروشگاه ارائهشده توسط AWS برای نمای یکپارچه برای ما آسان کرد. کارهای چسب AWS را می توان برای استخراج داده ها از منبع مشتری و از دریاچه داده، برنامه ریزی کرد یا بر اساس تقاضا فراخوانی کرد.
برخی از مسئولیت های این مشاغل به شرح زیر است:
- استخراج و تبدیل یک موجودیت منبع به موجودیت داده
- برای فهرستنویسی بهتر، دادهها را به گونهای غنی کنید که شامل سال، ماه و روز باشد و برای پرس و جوی بهتر، یک شناسه عکس فوری اضافه کنید.
- اعتبار سنجی ورودی و تولید مسیر را برای Amazon S3 انجام دهید
- ابرداده های معتبر را بر اساس سیستم منبع مرتبط کنید
جستجوی API های REST از سرویس های داخلی یکی از چالش های اصلی ما است و با توجه به حداقل زیرساخت ها، ما می خواستیم از آنها در این پروژه استفاده کنیم. اتصالات چسب AWS به ما در پایبندی به نیاز و هدف کمک کردند. برای جستجوی داده ها از API های REST و سایر منابع داده، ما از ماژول های PySpark و JDBC استفاده کردیم.
چسب AWS از انواع مختلفی از اتصالات پشتیبانی می کند. برای جزئیات بیشتر مراجعه کنید انواع اتصال و گزینه های ETL در چسب AWS.
سطل S3 به عنوان منطقه فرود
ما از یک سطل S3 به عنوان منطقه فرود فوری داده های استخراج شده استفاده کردیم که بیشتر پردازش و بهینه سازی می شود.
Lambda به عنوان AWS Glue ETL Trigger
ما اعلانهای رویداد S3 را در سطل S3 فعال کردیم تا Lambda را فعال کند، که دادههای ما را بیشتر پارتیشن بندی میکند. داده ها بر اساس InputDataSetName، Year، Month و Date تقسیم بندی می شوند. هر پردازشگر پرس و جو که در بالای این داده ها اجرا شود، تنها زیر مجموعه ای از داده ها را برای بهینه سازی هزینه و عملکرد بهتر اسکن می کند. داده های ما را می توان در قالب های مختلفی مانند CSV، JSON و پارکت ذخیره کرد.
دادههای خام برای اکثر موارد استفاده ما برای ایجاد طرح بهینه ایدهآل نیست زیرا اغلب دارای انواع دادههای تکراری یا نادرست است. مهمتر از همه، داده ها در قالب های متعدد هستند، اما ما به سرعت داده ها را تغییر دادیم و نتایج قابل توجهی از عملکرد پرس و جو از استفاده از قالب پارکت مشاهده کردیم. در اینجا، ما از یکی از نکات عملکرد استفاده کردیم 10 نکته برتر تنظیم عملکرد برای آمازون آتنا.
کارهای چسب AWS برای ETL
ما میخواستیم تفکیک دادهها و دسترسی بهتری داشته باشیم، بنابراین ترجیح دادیم یک سطل S3 متفاوت برای بهبود عملکرد بیشتر داشته باشیم. ما از همان کارهای چسب AWS برای تبدیل و بارگذاری بیشتر داده ها در سطل S3 مورد نیاز و بخشی از ابرداده استخراج شده در DynamoDB استفاده کردیم.
DynamoDB به عنوان فروشگاه ابرداده
اکنون که داده ها را در اختیار داریم، سهامداران مختلف کسب و کار بیشتر آن را مصرف می کنند. این برای ما دو سوال ایجاد می کند: کدام منبع داده در دریاچه داده قرار دارد و چه نسخه. ما DynamoDB را به عنوان فروشگاه ابرداده خود انتخاب کردیم، که آخرین جزئیات را در اختیار مصرف کنندگان قرار می دهد تا داده ها را به طور مؤثر جستجو کنند. هر مجموعه داده در سیستم ما به طور منحصربهفرد با شناسه عکس فوری شناسایی میشود، که میتوانیم آن را از فروشگاه ابرداده خود جستجو کنیم. مشتریان با یک API به این فروشگاه داده دسترسی دارند.
آمازون S3 به عنوان دریاچه داده
برای کیفیت بهتر دادهها، دادههای غنیشده را با همان کار چسب AWS در یک سطل S3 دیگر استخراج کردیم.
خزنده چسب AWS
خزنده ها "سس مخفی" هستند که ما را قادر می سازند تا به تغییرات طرح واره پاسخگو باشیم. در طول فرآیند، ما تصمیم گرفتیم که هر مرحله را تا حد امکان طرحوارهای کنیم، که اجازه میدهد هر گونه تغییر طرحواره تا زمانی که به چسب AWS برسد، جریان داشته باشد. با یک خزنده، میتوانیم تغییرات آگنوستیکی را که در طرحواره اتفاق میافتد، حفظ کنیم. این به ما کمک کرد تا به طور خودکار داده ها را از Amazon S3 بخزیم و طرح و جداول را تولید کنیم.
کاتالوگ داده چسب AWS
کاتالوگ داده به ما کمک کرد تا کاتالوگ را به عنوان شاخصی برای مکان، طرح و معیارهای زمان اجرا در آمازون S3 نگهداری کنیم. اطلاعات در کاتالوگ داده به صورت جداول فراداده ذخیره می شود، جایی که هر جدول یک ذخیره داده واحد را مشخص می کند.
آتنا برای پرس و جوهای SQL
Athena یک سرویس پرس و جو تعاملی است که تجزیه و تحلیل داده ها را در Amazon S3 با استفاده از SQL استاندارد آسان می کند. آتنا بدون سرور است، بنابراین هیچ زیرساختی برای مدیریت وجود ندارد و شما فقط برای کوئری هایی که اجرا می کنید هزینه پرداخت می کنید. ما ثبات عملیاتی و افزایش سرعت توسعه دهنده را به عنوان عوامل کلیدی بهبود خود در نظر گرفتیم.
ما فرآیند پرس و جوی Athena را بیشتر بهینه کردیم تا کاربران بتوانند مقادیر و پرس و جوها را برای دریافت داده از Athena با ایجاد موارد زیر وصل کنند:
- An کیت توسعه ابری AWS (AWS CDK) قالب برای ایجاد زیرساخت آتنا و هویت AWS و مدیریت دسترسی (IAM) برای دسترسی به سطلهای دریاچه داده S3 و کاتالوگ داده از هر حسابی نقش دارد
- کتابخانه ای که مشتری بتواند نقش IAM، پرس و جو، فرمت داده و مکان خروجی را برای شروع پرس و جوی Athena و دریافت وضعیت و نتیجه پرس و جو در سطل مورد نظر خود ارائه دهد.
پرس و جو از آتنا یک فرآیند دو مرحله ای است:
- StartQueryExecution – با این کار اجرای query شروع می شود و شناسه اجرا را دریافت می کند. کاربران می توانند محل خروجی را که در آن خروجی پرس و جو ذخیره می شود، ارائه دهند.
- GetQueryExecution - این وضعیت query را دریافت می کند زیرا اجرا ناهمزمان است. هنگامی که موفقیت آمیز بود، می توانید خروجی را در یک فایل S3 یا از طریق پرس و جو کنید API.
روش کمکی برای شروع اجرای کوئری و دریافت نتیجه در کتابخانه خواهد بود.
سرویس ابرداده دریاچه داده
این سرویس به صورت سفارشی توسعه یافته است و با DynamoDB تعامل دارد تا متادیتا (نام مجموعه داده، شناسه عکس فوری، رشته پارتیشن، مهر زمان و پیوند S3 داده ها) را در قالب یک REST API دریافت کند. هنگامی که طرحواره کشف می شود، مشتریان از Athena به عنوان پردازشگر پرس و جو برای جستجوی داده ها استفاده می کنند.
از آنجایی که همه مجموعههای داده دارای شناسه عکس فوری پارتیشن بندی شدهاند، پرس و جوی پیوستن منجر به اسکن کامل جدول نمیشود، بلکه فقط به اسکن پارتیشن در Amazon S3 منجر میشود. ما از Athena بهعنوان پردازشگر پرس و جو خود استفاده کردیم، زیرا به راحتی زیرساخت پرس و جو را مدیریت نمیکند. بعداً، اگر احساس کردیم به چیزی بیشتر نیاز داریم، میتوانیم از Redshift Spectrum یا Amazon EMR استفاده کنیم.
نتیجه
تیمهای دستگاههای آمازون با حرکت به معماری دریاچه داده با استفاده از چسب AWS، ارزش قابل توجهی را کشف کردند، که چندین سهامدار تجارت جهانی را قادر میسازد تا دادهها را به روشهای سازندهتری دریافت کنند. این تیم ها را قادر می سازد تا با تجزیه و تحلیل مجموعه داده های مختلف در زمان واقعی با منطق تجاری مناسب برای حل مشکلات زنجیره تامین، تقاضا و پیش بینی، برنامه بهینه برای سفارش خرید دستگاه ها را ایجاد کنند.
از منظر عملیاتی، سرمایه گذاری در حال حاضر شروع به پرداخت کرده است:
- این مکانیسمهای بلع، ذخیرهسازی و بازیابی ما را استاندارد کرد و در زمان ورود صرفهجویی کرد. قبل از پیاده سازی این سیستم، نصب یک مجموعه داده 1 ماه طول کشید. با توجه به معماری جدیدمان، ما توانستیم 15 مجموعه داده جدید را در کمتر از 2 ماه وارد کنیم که چابکی ما را 70 درصد بهبود بخشید.
- این گلوگاه های پوسته پوسته شدن را حذف کرد و یک سیستم همگن ایجاد کرد که می تواند به سرعت به هزاران اجرا برسد.
- این راه حل، طرحواره و اعتبارسنجی کیفیت داده را قبل از پذیرش هرگونه ورودی و رد کردن آنها در صورت کشف نقض کیفیت داده، اضافه کرد.
- بازیابی مجموعه دادهها را آسان میکند، در حالی که از شبیهسازیهای آینده و موارد استفاده از آزمایشکننده برگشتی که نیاز به ورودیهای نسخهسازی شده دارند، پشتیبانی میکند. این کار راه اندازی و آزمایش مدل ها را ساده تر می کند.
- این راه حل یک زیرساخت مشترک ایجاد کرد که می تواند به راحتی به سایر تیم ها در سراسر DIAL که مشکلات مشابهی در مورد مصرف داده، ذخیره سازی و موارد استفاده بازیابی دارند گسترش دهد.
- هزینه های عملیاتی ما تقریبا 90 درصد کاهش یافته است.
- این دریاچه داده می تواند توسط دانشمندان و مهندسان داده ما برای انجام سایر تجزیه و تحلیل ها و یک رویکرد پیش بینی به عنوان فرصتی در آینده برای ایجاد برنامه های دقیق برای سفارشات خرید به طور مؤثر قابل دسترسی باشد.
مراحل این پست می تواند به شما کمک کند تا با استفاده از سرویس های مدیریت شده AWS برای دریافت داده ها از منابع مختلف، ایجاد خودکار کاتالوگ های ابرداده، اشتراک گذاری یکپارچه داده ها بین دریاچه داده و انبار داده، و ایجاد هشدار در رویداد، یک استراتژی داده مدرن مشابه ایجاد کنید. شکست گردش کار داده هماهنگ شده
درباره نویسندگان
 آویناش کلوری یک معمار ارشد راه حل در AWS است. او در سراسر آمازون الکسا و دستگاه ها برای معمار و طراحی راه حل های توزیع شده مدرن کار می کند. اشتیاق او ایجاد راه حل های مقرون به صرفه و بسیار مقیاس پذیر در AWS است. او در اوقات فراغت خود از پختن دستور العمل های فیوژن و سفر لذت می برد.
آویناش کلوری یک معمار ارشد راه حل در AWS است. او در سراسر آمازون الکسا و دستگاه ها برای معمار و طراحی راه حل های توزیع شده مدرن کار می کند. اشتیاق او ایجاد راه حل های مقرون به صرفه و بسیار مقیاس پذیر در AWS است. او در اوقات فراغت خود از پختن دستور العمل های فیوژن و سفر لذت می برد.
 ویپول ورما یک مهندس نرم افزار Sr. در Amazon.com است. او از سال 2015 با آمازون بوده و چالش های دنیای واقعی را از طریق فناوری حل می کند که مستقیماً بر زندگی مشتریان آمازون تأثیر می گذارد و آن را بهبود می بخشد. در اوقات فراغت خود از پیاده روی لذت می برد.
ویپول ورما یک مهندس نرم افزار Sr. در Amazon.com است. او از سال 2015 با آمازون بوده و چالش های دنیای واقعی را از طریق فناوری حل می کند که مستقیماً بر زندگی مشتریان آمازون تأثیر می گذارد و آن را بهبود می بخشد. در اوقات فراغت خود از پیاده روی لذت می برد.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- پلاتوبلاک چین. Web3 Metaverse Intelligence. دانش تقویت شده دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/big-data/how-amazon-devices-scaled-and-optimized-real-time-demand-and-supply-forecasts-using-serverless-analytics/
- 1
- 10
- 100
- 2021
- 70
- a
- توانایی
- قادر
- دسترسی
- قابل دسترسی است
- دسترسی
- معتبر
- دقیق
- در میان
- عمل
- اضافه
- اضافی
- AI
- چک
- معرفی
- اجازه می دهد تا
- قبلا
- آمازون
- آمازون الکسا
- آمازون EC2
- آمازون EMR
- Amazon.com
- تحلیل
- علم تجزیه و تحلیل
- تحلیل
- تجزیه و تحلیل
- و
- دیگر
- API
- رابط های برنامه کاربردی
- کاربرد
- برنامه توسعه
- روش
- مناسب
- معماری
- معماری
- مناطق
- تالیف
- بطور خودکار
- AWS
- چسب AWS
- به عقب
- مستقر
- زیرا
- قبل از
- بهتر
- میان
- میلیاردها
- ساختن
- ساخته
- کسب و کار
- نام
- ظرفیت
- موارد
- کاتالوگ
- کاتالوگ
- متمرکز
- زنجیر
- چالش ها
- به چالش کشیدن
- تبادل
- انتخاب
- را انتخاب
- مشتری
- مشتریان
- ابر
- COM
- ترکیب
- مشترک
- مقايسه كردن
- جزء
- محاسبه
- اتصال
- ارتباط
- در نظر گرفته
- با توجه به
- مصرف
- مصرف کنندگان
- به طور مداوم
- پخت و پز
- هسته
- هزینه
- مقرون به صرفه
- هزینه
- میتوانست
- کاوید
- خزنده
- ایجاد
- ایجاد شده
- ایجاد
- بحرانی
- جاری
- سفارشی
- مشتری
- خدمات مشتری
- مشتریان
- چرخه
- داده ها
- یکپارچه سازی داده ها
- دریاچه دریاچه
- پردازش داده ها
- کیفیت داده
- استراتژی داده
- انبار داده
- داده محور
- مجموعه داده ها
- تاریخ
- روز
- معامله
- تصمیم
- تصمیم گیری
- درجه
- تقاضا
- خواسته
- بستگی دارد
- طرح
- طراحی
- جزئیات
- جزئیات
- مشخص
- توسعه
- توسعه دهنده
- توسعه دهندگان
- پروژه
- دستگاه ها
- مختلف
- مستقیما
- كشف كردن
- کشف
- کشف
- توزیع شده
- مختلف
- نمی کند
- نسخه های تکراری
- هر
- به آسانی
- به طور موثر
- موثر
- هر دو
- فعال
- را قادر می سازد
- مهندس
- مورد تأیید
- غنی شده
- موجودیت
- اتر (ETH)
- واقعه
- هر
- عصاره
- داده ها را استخراج کنید
- عوامل
- شکست
- افتادن
- امکانات
- کمی از
- پرونده
- جریان
- پیروی
- به دنبال آن است
- پیش بینی
- فرم
- قالب
- یافت
- از جانب
- کامل
- بیشتر
- بعلاوه
- ادغام
- آینده
- عایدات
- تولید می کنند
- مولد
- نسل
- دریافت کنید
- گرفتن
- جهانی
- تجارت جهانی
- زمین
- هدف
- رشد
- داشتن
- کمک
- کمک کرد
- اینجا کلیک نمایید
- زیاد
- عملکرد بالا
- خیلی
- پیاده روی
- چگونه
- HTML
- HTTPS
- IAM
- دلخواه
- شناسایی
- شناسایی
- هویت
- فوری
- بلافاصله
- تأثیر
- پیاده سازی
- اجرای
- بهبود
- بهبود یافته
- بهبود
- ارتقاء
- in
- شامل
- شامل
- افزایش
- شاخص
- اطلاعات
- شالوده
- ورودی
- در عوض
- ادغام
- ادغام
- تعاملی
- در ارتباط بودن
- داخلی
- معرفی می کند
- فهرست
- سرمایه گذاری
- موضوع
- مسائل
- IT
- کار
- شغل ها
- پیوستن
- json
- کلید
- عدم
- دریاچه
- فرود
- آخرین
- راه اندازی
- یادگیری
- میراث
- کتابخانه
- زندگی
- محدودیت
- لاین
- ارتباط دادن
- بار
- محل
- تدارکات
- نگاه کنيد
- دستگاه
- فراگیری ماشین
- ساخته
- حفظ
- نگهداری
- ساخت
- باعث می شود
- مدیریت
- مدیریت
- بازار یابی (Marketing)
- دیدار
- متاداده
- روش
- متریک
- حداقل
- ML
- مدل
- مدل
- مدرن
- اصلاح شده
- ماژول ها
- مانیتور
- ماه
- ماه
- بیش
- اکثر
- حرکت
- متحرک
- چندگانه
- نام
- طبیعت
- نیاز
- ضروری
- جدید
- اطلاعیه ها
- پردازنده
- شبانه روزی
- ONE
- عملیاتی
- قابل استفاده
- فرصت ها
- فرصت
- بهینه
- بهینه سازی
- بهینه سازی
- بهینه
- گزینه
- سفارشات
- دیگر
- بیماری همه گیر
- بخش
- شور
- مسیر
- پرداخت
- درصد
- انجام دادن
- کارایی
- چشم انداز
- محل
- برنامه
- برنامه
- افلاطون
- هوش داده افلاطون
- PlatoData
- ممکن
- پست
- آماده
- در درجه اول
- اصلی
- مشکلات
- روند
- در حال پردازش
- پردازنده
- تولید
- تولیدی
- بهره وری
- پروژه
- ارائه
- فراهم می کند
- خرید
- هل دادن
- کیفیت
- سوالات
- به سرعت
- نرخ
- خام
- داده های خام
- رسیدن به
- دنیای واقعی
- زمان واقعی
- دلایل
- دستور پخت
- کاهش
- اشاره دارد
- قابل توجه
- حذف شده
- ضروری
- نیاز
- مورد نیاز
- منابع
- پاسخ
- مسئولیت
- مسئوليت
- پاسخگو
- REST
- نتیجه
- نقش
- نقش
- دویدن
- در حال اجرا
- حراجی
- همان
- صرفه جویی کردن
- مقیاس پذیری
- مقیاس پذیر
- مقیاس
- مقیاس گذاری
- اسکن
- برنامه ریزی
- دانشمندان
- یکپارچه
- جستجو
- بخش
- ارشد
- بدون سرور
- سرویس
- خدمات
- اشتراک گذاری
- به اشتراک گذاشته شده
- حمل
- نشان می دهد
- قابل توجه
- مشابه
- ساده
- پس از
- تنها
- عکس فوری
- So
- نرم افزار
- مهندس نرمافزار
- راه حل
- مزایا
- حل
- حل کردن
- چیزی
- منبع
- منابع
- دهانه ها
- طیف
- صرف
- SQL
- ثبات
- ذینفع
- سهامداران
- استاندارد
- شروع
- آغاز شده
- راه افتادن
- شروع می شود
- وضعیت
- گام
- مراحل
- ذخیره سازی
- opbevare
- ذخیره شده
- پرده
- استراتژی ها
- استراتژی
- موفق
- چنین
- عرضه
- زنجیره تامین
- حمایت از
- پشتیبانی از
- سیستم
- جدول
- گرفتن
- طول می کشد
- تیم ها
- پیشرفته
- قالب
- تست
- La
- منبع
- شان
- از این رو
- هزاران نفر
- از طریق
- سراسر
- زمان
- بار
- برچسب زمان
- نکات
- به
- بالا
- معاملات
- دگرگون کردن
- سفر
- ماشه
- انواع
- یکپارچه
- به روز رسانی
- us
- استفاده کنید
- کاربران
- اعتبار سنجی
- ارزش
- ارزشها
- تنوع
- مختلف
- VeloCity
- نسخه
- از طريق
- چشم انداز
- نقض
- فرار
- جلد
- خواسته
- انبار کالا
- راه
- چی
- که
- در حین
- وسیع
- اراده
- گردش کار
- گردش کار
- با این نسخهها کار
- خواهد بود
- سال
- شما
- زفیرنت