این پست توسط آنیش مورجانی، مهندس داده در SafetyCulture نوشته شده است.
SafetyCulture یک شرکت فناوری جهانی است که قدرت بهبود مستمر را در دستان همه قرار می دهد. پلت فرم عملیات آن قدرت مشاهده در مقیاس را باز می کند و به رهبران دیده می شود و به کارگران صدایی در کیفیت رانندگی، کارایی و بهبود ایمنی می دهد.
آمازون Redshift یک سرویس انبار داده کاملاً مدیریت شده است که ده ها هزار مشتری از آن برای مدیریت تجزیه و تحلیل در مقیاس استفاده می کنند. با هم قیمت-عملکردAmazon Redshift شما را قادر می سازد تا از داده های خود برای به دست آوردن بینش های جدید برای کسب و کار و مشتریان خود استفاده کنید و در عین حال هزینه ها را پایین نگه دارید.
در این پست، راه حل SafetyCulture مورد استفاده برای مقیاسبندی حجمهای کاری غیرقابل پیشبینی dbt Cloud را با روشی مقرونبهصرفه با Amazon Redshift به اشتراک میگذاریم.
مورد استفاده
SafetyCulture یک خوشه تدارکاتی Amazon Redshift را برای پشتیبانی از بارهای کاری غیرقابل پیش بینی و قابل پیش بینی اجرا می کند. منبع بارهای کاری غیرقابل پیش بینی است dbt ابر، که SafetyCulture از آن برای مدیریت تبدیل داده ها در قالب استفاده می کند مدل. هر زمان که مدل ها ایجاد یا اصلاح می شوند، الف کار dbt Cloud CI برای تست مدل ها توسط مادی شدن مدل های آمازون Redshift. برای متعادل کردن نیازهای بارهای کاری غیرقابل پیش بینی و قابل پیش بینی، SafetyCulture استفاده کرد مدیریت بار کاری آمازون Redshift (WLM) برای مدیریت انعطاف پذیر اولویت های حجم کار.
SafetyCulture با برنامه ریزی برای رشد بیشتر در حجم کاری dbt Cloud به راه حلی نیاز داشت که موارد زیر را انجام دهد:
- بارهای کاری غیرقابل پیش بینی را به شیوه ای مقرون به صرفه تامین می کند
- بارهای کاری غیرقابل پیش بینی را از بارهای کاری قابل پیش بینی جدا می کند تا منابع محاسباتی را به طور مستقل مقیاس بندی کند
- همچنان اجازه می دهد مدل ها بر اساس داده های تولید ایجاد و اصلاح شوند
بررسی اجمالی راه حل
راه حل استفاده شده از SafetyCulture شامل Amazon Redshift Serverless و Amazon Redshift Data Sharing به همراه خوشه ارائه شده Amazon Redshift موجود است.
آمازون Redshift بدون سرور بارهای کاری غیرقابل پیش بینی را به شیوه ای مقرون به صرفه برآورده می کند، زیرا هزینه محاسبه زمانی که حجم کاری وجود ندارد متحمل نمی شود. شما فقط برای آنچه استفاده می کنید پرداخت می کنید. علاوه بر این، انتقال بارهای کاری غیرقابل پیش بینی به یک انبار داده جداگانه Amazon Redshift به هر انبار داده Amazon Redshift اجازه می دهد تا منابع را به طور مستقل مقیاس کند.
آمازون Redshift به اشتراک گذاری داده دسترسی به داده ها را در انبارهای داده Amazon Redshift بدون نیاز به کپی یا انتقال داده ها امکان پذیر می کند. بنابراین، زمانی که یک حجم کاری از یک انبار داده Amazon Redshift به انبار دیگر Amazon Redshift منتقل می شود، حجم کار می تواند به داده ها در انبار داده اولیه Amazon Redshift دسترسی پیدا کند.
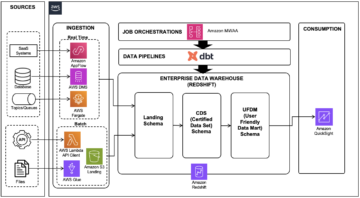
شکل زیر مراحل حل و گردش کار را نشان می دهد:
- ما یک نمونه بدون سرور ایجاد می کنیم تا بارهای کاری غیرقابل پیش بینی را برآورده کنیم. رجوع شود به مدیریت Amazon Redshift Serverless با استفاده از کنسول برای مراحل راه اندازی
- ما یک datashare به نام ایجاد می کنیم
prod_datashareبرای اجازه دسترسی نمونه بدون سرور به داده ها در کلاستر ارائه شده. رجوع شود به شروع به اشتراک گذاری داده با استفاده از کنسول برای مراحل راه اندازی نام پایگاه داده برای اجازه دادن به پرس و جوها با نماد مسیر کامل یکسان استdatabase_name.schema_name.object_nameبرای اجرای یکپارچه در هر دو انبار داده. - dbt Cloud به نمونه بدون سرور متصل میشود و مدلهای ایجاد شده یا اصلاح شده، با قرار گرفتن در پایگاه داده پیشفرض آزمایش میشوند.
dev، در طرحواره شخصی هر کاربر یا طرح مربوط به درخواست کشش. بجایdev، می توانید از پایگاه داده دیگری که برای آزمایش تعیین شده است استفاده کنید. رجوع شود به dbt Cloud را به Redshift وصل کنید برای مراحل راه اندازی - برای تأیید تغییرات میتوانید مدلهای تحققیافته را در نمونه بدون سرور با مدلهای تحققیافته در خوشه ارائهشده پرس و جو کنید. پس از تایید تغییرات، می توانید مدل ها را در نمونه بدون سرور در خوشه ارائه شده پیاده سازی کنید.
نتیجه
SafetyCulture مراحل ایجاد نمونه بدون سرور و اشتراک داده را با ادغام با dbt Cloud به راحتی انجام داد. SafetyCulture همچنین پروژه dbt خود را با تمامی seeds، مدلها و عکسهای فوری که از طریق دستورات اجرا از وظایف dbt Cloud IDE و dbt Cloud CI در نمونههای بدون سرور اجرا میشوند، با موفقیت اجرا کرد.
با توجه به عملکرد، SafetyCulture مشاهده کرد که بارهای کاری dbt Cloud به طور متوسط 60٪ سریعتر در نمونه بدون سرور تکمیل می شود. عملکرد بهتر را می توان به دو حوزه نسبت داد:
- Amazon Redshift Serverless ظرفیت محاسباتی را با استفاده از اندازه گیری می کند واحدهای پردازش Redshift (RPU). از آنجایی که هزینه اجرای 64 RPU در 10 دقیقه و 128 RPU در 5 دقیقه یکسان است، داشتن تعداد RPU بیشتر برای تکمیل بار کاری زودتر ترجیح داده می شود.
- با بارهای کاری dbt Cloud ایزوله شده در نمونه بدون سرور، dbt Cloud با موارد بیشتری پیکربندی شد. موضوعات تا امکان تحقق مدلهای بیشتر در یک زمان فراهم شود.
برای تعیین هزینه، می توانید یک تخمین را انجام دهید. 128 RPU تقریباً همان مقدار حافظه ای را فراهم می کند که یک خوشه 3.4 گره ای بزرگ ra21x فراهم می کند. در شرق ایالات متحده (N. ویرجینیا)، هزینه اجرای یک نمونه بدون سرور با 128 RPU ساعتی 48 دلار است (0.375 دلار در هر ساعت RPU * 128 RPU). در همان منطقه، هزینه اجرای یک خوشه 3.4 گره ای ra21xlarge در صورت تقاضا 68.46 دلار در ساعت است (3.26 دلار در هر ساعت گره * 21 گره). بنابراین، یک ساعت انباشته از بارهای کاری غیرقابل پیشبینی در یک نمونه بدون سرور، 29 درصد مقرون به صرفهتر از یک کلاستر ارائهشده بر اساس تقاضا است. محاسبات در این مثال باید هنگام انجام تخمین هزینه های آتی مجدداً محاسبه شوند زیرا قیمت ممکن است در طول زمان تغییر کند.
یادگیری ها
SafetyCulture دو آموزش کلیدی برای ادغام بهتر dbt با Amazon Redshift داشت که می تواند برای پیاده سازی های مشابه مفید باشد.
ابتدا، هنگام ادغام dbt با دیتاشیر Amazon Redshift، پیکربندی کنید INCLUDENEW=True برای سهولت مدیریت اشیاء پایگاه داده در یک طرحواره:
به عنوان مثال، مدل را فرض کنید customers.sql توسط dbt به عنوان دیدگاه تحقق می یابد customers. بعد، customers به اشتراک گذاری داده اضافه می شود. چه زمانی customers.sql توسط dbt اصلاح شده و مجدداً تبدیل می شود، dbt نمای جدیدی با نام موقت ایجاد می کند، رها می کند customers، و نام نمای جدید را به customers. اگرچه نمای جدید همان نام را دارد، اما یک شی پایگاه داده جدید است که به اشتراک داده اضافه نشده است. از این رو، customers دیگر در datashare یافت نمی شود.
پیکربندی INCLUDENEW=True اجازه می دهد تا اشیاء پایگاه داده جدید به طور خودکار به اشتراک داده اضافه شوند. جایگزینی برای پیکربندی INCLUDENEW=True و ارائه کنترل دانه ای بیشتر استفاده از dbt post hook.
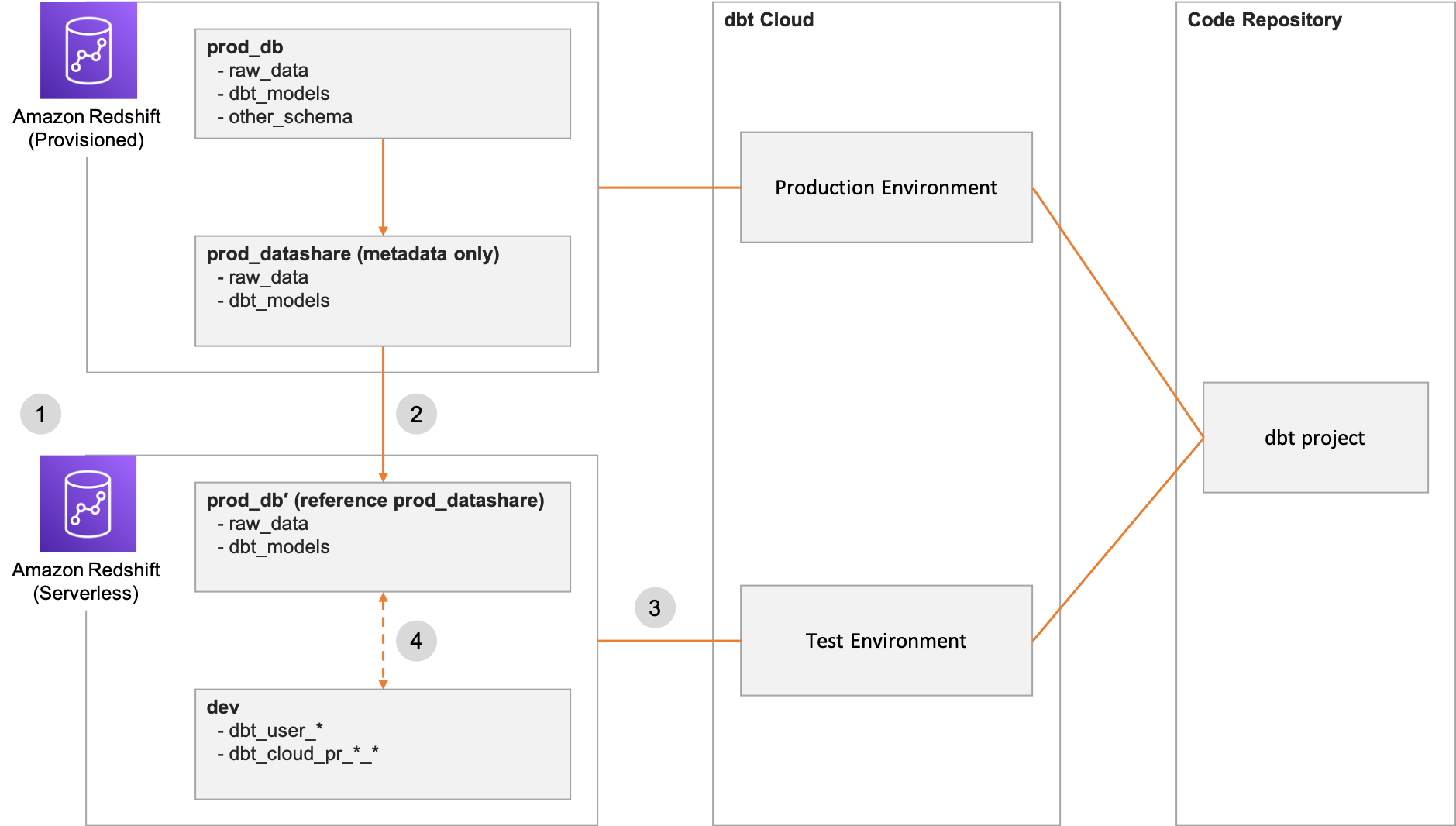
دوم، هنگام ادغام dbt با بیش از یک انبار داده Amazon Redshift، تعریف کنید منابع با پایگاه داده برای کمک به dbt در ارزیابی پایگاه داده مناسب.
به عنوان مثال، فرض کنید یک پروژه dbt در دو محیط dbt Cloud برای جداسازی تولید و آزمایش بارهای کاری استفاده شده است. محیط dbt Cloud برای بارهای کاری تولید با پایگاه داده پیش فرض پیکربندی شده است prod_db و به یک خوشه تدارکاتی متصل می شود. محیط dbt Cloud برای بارهای کاری آزمایشی با پایگاه داده پیش فرض پیکربندی شده است dev و به یک نمونه بدون سرور متصل می شود. علاوه بر این، خوشه ارائه شده حاوی جدول است prod_db.raw_data.sales، که از طریق datashare as در اختیار نمونه بدون سرور قرار می گیرد prod_db′.raw_data.sales.
وقتی dbt مدلی حاوی منبع را کامپایل می کند {{ source('raw_data', 'sales') }}، منبع به عنوان ارزیابی می شود database.raw_data.sales. اگر پایگاه داده برای منابع تعریف نشده باشد، dbt پایگاه داده را روی پایگاه داده پیش فرض محیط پیکربندی شده تنظیم می کند. بنابراین، محیط dbt Cloud که به خوشه ارائه شده متصل می شود، منبع را به عنوان ارزیابی می کند prod_db.raw_data.sales، در حالی که محیط dbt Cloud متصل به نمونه بدون سرور منبع را به عنوان ارزیابی می کند dev.raw_data.sales، که نادرست است.
تعریف پایگاه داده برای منابع به dbt اجازه می دهد تا به طور مداوم پایگاه داده مناسب را در محیط های مختلف dbt Cloud ارزیابی کند، زیرا ابهام را برطرف می کند.
نتیجه
پس از تست Amazon Redshift Serverless و Data Sharing، SafetyCulture از نتیجه راضی است و شروع به تولید راه حل کرده است.
تیاگو بالدیم، سرپرست تیم مهندس داده در SafetyCulture می گوید: «PoC پتانسیل گسترده Redshift Serverless را در زیرساخت ما نشان داد. ما میتوانیم خطوط لوله خود را برای پشتیبانی از Redshift Serverless با تغییرات ساده در استانداردهایی که در dbt خود استفاده میکردیم، منتقل کنیم. نتیجه، تصویر واضحی از پیادهسازیهای بالقوهای که میتوانستیم انجام دهیم، ارائه داد، که حجم کار را بهطور کامل توسط تیمها و کاربران جدا کرد و سطح مناسبی از قدرت محاسباتی را ارائه کرد که سریع و قابل اعتماد است.»
اگرچه این پست به طور خاص بارهای کاری غیرقابل پیش بینی از dbt Cloud را هدف قرار می دهد، اما این راه حل برای بارهای کاری غیرقابل پیش بینی دیگر، از جمله پرس و جوهای موقت از داشبوردها نیز مرتبط است. کاوش در Amazon Redshift Serverless را برای بارهای کاری غیرقابل پیش بینی خود از امروز شروع کنید.
درباره نویسندگان
 انیش مورجانی یک مهندس داده در تیم داده و تجزیه و تحلیل در SafetyCulture است. او به مقیاس زیرساخت تحلیلی SafetyCulture با افزایش تصاعدی در حجم و تنوع داده ها کمک می کند.
انیش مورجانی یک مهندس داده در تیم داده و تجزیه و تحلیل در SafetyCulture است. او به مقیاس زیرساخت تحلیلی SafetyCulture با افزایش تصاعدی در حجم و تنوع داده ها کمک می کند.
 رندی چنگ یک معمار راه حل های تجزیه و تحلیل در خدمات وب آمازون است. او با مشتریان کار می کند تا حل مشکلات کلیدی کسب و کار آنها را تسریع بخشد.
رندی چنگ یک معمار راه حل های تجزیه و تحلیل در خدمات وب آمازون است. او با مشتریان کار می کند تا حل مشکلات کلیدی کسب و کار آنها را تسریع بخشد.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- پلاتوبلاک چین. Web3 Metaverse Intelligence. دانش تقویت شده دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/big-data/how-safetyculture-scales-unpredictable-dbt-cloud-workloads-in-a-cost-effective-manner-with-amazon-redshift/
- :است
- $3
- 10
- 100
- 7
- a
- شتاب دادن
- دسترسی
- دسترسی به داده ها
- جمع آوری شده
- به دست آوردن
- در میان
- Ad
- اضافه
- اضافه
- پس از
- کمک
- معرفی
- اجازه می دهد تا
- جایگزین
- هر چند
- آمازون
- آمازون خدمات وب
- ابهام
- مقدار
- علم تجزیه و تحلیل
- و
- دیگر
- تقریبا
- هستند
- مناطق
- AS
- At
- بطور خودکار
- در دسترس
- میانگین
- AWS
- برج میزان
- مستقر
- BE
- زیرا
- بودن
- بهتر
- کسب و کار
- by
- نام
- CAN
- ظرفیت
- تغییر دادن
- تبادل
- واضح
- ابر
- خوشه
- شرکت
- کامل
- تکمیل
- شامل
- محاسبه
- محاسبه
- اتصال
- متصل
- شامل
- ادامه دادن
- مداوم
- کنترل
- هزینه
- مقرون به صرفه
- هزینه
- میتوانست
- ایجاد
- ایجاد شده
- ایجاد
- مشتریان
- داده ها
- دسترسی به داده ها
- مهندس داده
- به اشتراک گذاری داده ها
- انبار داده
- انبارهای داده
- پایگاه داده
- به طور پیش فرض
- مشخص
- تقاضا
- تعیین شده
- مشخص کردن
- مختلف
- رانندگی
- قطره
- هر
- شرق
- بهره وری
- هر دو
- را قادر می سازد
- مهندس
- به طور کامل
- محیط
- محیط
- اتر (ETH)
- ارزیابی
- ارزیابی
- ارزیابی
- هر کس
- مثال
- موجود
- بررسی
- نمایی
- FAST
- سریعتر
- شکل
- پیروی
- برای
- فرم
- یافت
- از جانب
- کامل
- کاملا
- بیشتر
- آینده
- دادن
- جهانی
- رشد
- دست ها
- داشتن
- مفید
- کمک می کند
- بالاتر
- چگونه
- HTML
- HTTPS
- یکسان
- انجام
- بهبود
- ارتقاء
- in
- از جمله
- افزایش
- به طور مستقل
- شالوده
- اول
- بینش
- نمونه
- در عوض
- ادغام
- ادغام
- ادغام
- جدا شده
- IT
- ITS
- شغل ها
- نگهداری
- کلید
- رهبری
- رهبران
- سطح
- دیگر
- کم
- ساخته
- مدیریت
- اداره می شود
- مدیریت
- روش
- معیارهای
- حافظه
- مهاجرت
- دقیقه
- مدل
- مدل
- اصلاح شده
- بیش
- حرکت
- متحرک
- نام
- نام
- ضروری
- نیازهای
- جدید
- بعد
- گره
- گره
- عدد
- هدف
- اشیاء
- of
- on
- بر روی تقاضا
- ONE
- عملیات
- دیگر
- نتیجه
- مسیر
- پرداخت
- انجام دادن
- کارایی
- انجام
- شخصی
- تصویر
- برنامه
- سکو
- افلاطون
- هوش داده افلاطون
- PlatoData
- پوک
- پست
- پتانسیل
- قدرت
- قابل پیش بینی
- مرجح
- مشکلات
- در حال پردازش
- تولید
- پروژه
- ارائه
- فراهم می کند
- ارائه
- قرار می دهد
- کیفیت
- منطقه
- مربوط
- مربوط
- قابل اعتماد
- درخواست
- منابع
- نتیجه
- دویدن
- در حال اجرا
- ایمنی
- حراجی
- همان
- راضی
- راضی با
- می گوید:
- مقیاس
- مقیاس ها
- یکپارچه
- دانه
- جداگانه
- بدون سرور
- سرویس
- خدمات
- تنظیم
- مجموعه
- برپایی
- اشتراک گذاری
- اشتراک
- باید
- نشان می دهد
- مشابه
- ساده
- راه حل
- مزایا
- منبع
- منابع
- به طور خاص
- استانداردهای
- شروع
- آغاز شده
- مراحل
- موفقیت
- پشتیبانی
- جدول
- اهداف
- تیم
- تیم ها
- پیشرفته
- موقت
- آزمون
- تست
- که
- La
- منبع
- شان
- از این رو
- هزاران نفر
- زمان
- به
- امروز
- با هم
- تحولات
- باعث شد
- درست
- واحد
- باز کردن
- غیرقابل پیش بینی
- us
- استفاده کنید
- کاربران
- تصدیق
- تنوع
- وسیع
- از طريق
- چشم انداز
- ویرجینیا
- دید
- صدا
- حجم
- انبار کالا
- وب
- خدمات وب
- چی
- که
- در حین
- با
- بدون
- کارگران
- گردش کار
- با این نسخهها کار
- شما
- زفیرنت