این پست با مهیما آگاروال، مهندس یادگیری ماشین، و دیپاک متم، مدیر ارشد مهندسی، در VMware Carbon Black نوشته شده است.
VMware کربن بلک یک راه حل امنیتی مشهور است که محافظت در برابر طیف کامل حملات سایبری مدرن را ارائه می دهد. با ترابایت داده تولید شده توسط این محصول، تیم تجزیه و تحلیل امنیتی بر ساخت راه حل های یادگیری ماشینی (ML) برای سطح حملات حیاتی و توجه به تهدیدهای نوظهور تمرکز می کند.
برای تیم VMware Carbon Black بسیار مهم است که یک خط لوله MLOps سرتاسر سفارشی را طراحی و بسازد که گردش کار را در چرخه حیات ML هماهنگ و خودکار می کند و آموزش مدل، ارزیابی و استقرار را امکان پذیر می کند.
دو هدف اصلی برای ساخت این خط لوله وجود دارد: پشتیبانی از دانشمندان داده برای توسعه مدل در مرحله آخر، و پیشبینی مدل سطح در محصول با ارائه مدلها در حجم بالا و ترافیک تولید بلادرنگ. بنابراین، VMware Carbon Black و AWS تصمیم گرفتند با استفاده از خط لوله MLOps سفارشی بسازند آمازون SageMaker به دلیل سهولت استفاده، تطبیق پذیری و زیرساخت کاملاً مدیریت شده. ما با استفاده از خطوط لوله آموزش و استقرار ML خود را هماهنگ می کنیم آمازون گردش های کاری را برای Apache Airflow مدیریت کرد (Amazon MWAA)، که ما را قادر می سازد تا بدون نگرانی در مورد مقیاس خودکار یا تعمیر و نگهداری زیرساخت، بر روی نوشتن برنامه ای گردش کار و خطوط لوله تمرکز بیشتری داشته باشیم.
با این خط لوله، آنچه زمانی تحقیقات ML مبتنی بر نوتبوک Jupyter بود، اکنون یک فرآیند خودکار است که مدلها را با مداخله دستی کمی از دانشمندان داده به تولید میرساند. پیش از این، فرآیند آموزش، ارزیابی و استقرار یک مدل ممکن بود یک روز طول بکشد. با این پیاده سازی، همه چیز فقط یک ماشه دور است و زمان کلی را به چند دقیقه کاهش داده است.
در این پست، معماران VMware Carbon Black و AWS درباره نحوه ساخت و مدیریت گردش کار سفارشی ML با استفاده از گیتلب، آمازون MWAA و SageMaker. ما در مورد آنچه تاکنون به دست آوردهایم، پیشرفتهای بیشتر در خط لوله و درسهایی که در این مسیر آموختهایم بحث میکنیم.
بررسی اجمالی راه حل
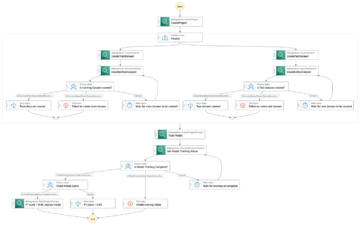
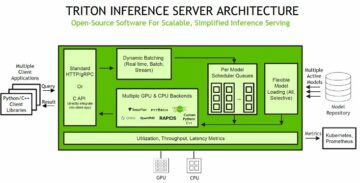
نمودار زیر معماری پلتفرم ML را نشان می دهد.

طراحی راه حل سطح بالا
این پلتفرم ML برای استفاده توسط مدل های مختلف در مخازن کدهای مختلف پیش بینی و طراحی شده است. تیم ما از GitLab به عنوان یک ابزار مدیریت کد منبع برای نگهداری تمام مخازن کد استفاده می کند. هر گونه تغییر در کد منبع مخزن مدل به طور مداوم با استفاده از کد یکپارچه می شود Gitlab CI، که جریان های کاری بعدی را در خط لوله فراخوانی می کند (آموزش مدل، ارزیابی و استقرار).
نمودار معماری زیر جریان کار سرتاسر و اجزای درگیر در خط لوله MLOps ما را نشان می دهد.

گردش کار End-to-End
خطوط لوله آموزش، ارزیابی و استقرار مدل ML با استفاده از آمازون MWAA تنظیم شده است که به عنوان یک نمودار Acyclic کارگردانی شده است (DAG). DAG مجموعه ای از وظایف است که با وابستگی ها و روابط سازماندهی شده اند تا نحوه اجرای آنها را بیان کنند.
در سطح بالا، معماری راه حل شامل سه جزء اصلی است:
- مخزن کد خط لوله ML
- خط لوله آموزش و ارزیابی مدل ML
- خط لوله استقرار مدل ML
بیایید در مورد چگونگی مدیریت این اجزای مختلف و نحوه تعامل آنها با یکدیگر بحث کنیم.
مخزن کد خط لوله ML
پس از اینکه مخزن مدل، مخزن MLOps را به عنوان خط لوله پایین دست خود ادغام کرد، و یک دانشمند داده کد را در مخزن مدل خود ادغام کرد، یک رانر GitLab اعتبارسنجی کد استاندارد و آزمایش تعریف شده در آن مخزن را انجام میدهد و خط لوله MLOps را بر اساس تغییرات کد راهاندازی میکند. ما از خط لوله چند پروژه ای Gitlab برای فعال کردن این ماشه در مخازن مختلف استفاده می کنیم.
خط لوله MLOps GitLab مجموعه ای از مراحل را اجرا می کند. اعتبار سنجی کد اولیه را با استفاده از پیلینت انجام می دهد، کد آموزش و استنتاج مدل را در تصویر داکر بسته بندی می کند و تصویر ظرف را منتشر می کند. رجیستری ظروف الاستیک آمازون (Amazon ECR). Amazon ECR یک رجیستری کانتینر کاملاً مدیریت شده است که میزبانی با کارایی بالا را ارائه می دهد، بنابراین می توانید تصاویر و مصنوعات برنامه را به طور قابل اعتماد در هر کجا مستقر کنید.
خط لوله آموزش و ارزیابی مدل ML
پس از انتشار تصویر، آموزش و ارزیابی را آغاز می کند جریان هوای آپاچی خط لوله از طریق AWS لامبدا تابع. Lambda یک سرویس محاسباتی بدون سرور و رویداد محور است که به شما امکان میدهد کد تقریباً برای هر نوع برنامه کاربردی یا سرویس پشتیبان را بدون تهیه یا مدیریت سرورها اجرا کنید.
پس از اینکه خط لوله با موفقیت راه اندازی شد، Training and Evaluation DAG را اجرا می کند که به نوبه خود آموزش مدل را در SageMaker شروع می کند. در پایان این خط لوله آموزشی، گروه کاربری شناسایی شده یک اعلان با نتایج آموزش و ارزیابی مدل از طریق ایمیل از طریق ایمیل دریافت می کند. سرویس اطلاع رسانی ساده آمازون (Amazon SNS) و Slack. Amazon SNS یک سرویس میخانه/فرعی کاملاً مدیریت شده برای پیام رسانی A2A و A2P است.
پس از تجزیه و تحلیل دقیق نتایج ارزیابی، دانشمند داده یا مهندس ML می توانند مدل جدید را در صورتی که عملکرد مدل تازه آموزش دیده در مقایسه با نسخه قبلی بهتر باشد، به کار گیرند. عملکرد مدل ها بر اساس معیارهای خاص مدل (مانند امتیاز F1، MSE یا ماتریس سردرگمی) ارزیابی می شود.
خط لوله استقرار مدل ML
برای شروع استقرار، کاربر کار GitLab را شروع می کند که Deployment DAG را از طریق همان تابع Lambda فعال می کند. پس از اجرای موفقیت آمیز خط لوله، نقطه پایانی SageMaker را با مدل جدید ایجاد یا به روز می کند. این همچنین با استفاده از Amazon SNS و Slack، یک اعلان با جزئیات نقطه پایانی از طریق ایمیل ارسال می کند.
در صورت خرابی در هر یک از خطوط لوله، کاربران از طریق همان کانال های ارتباطی مطلع می شوند.
SageMaker استنتاج بلادرنگی را ارائه میکند که برای بارهای کاری استنتاج با تاخیر کم و نیازهای توان عملیاتی بالا ایدهآل است. این نقاط پایانی به طور کامل مدیریت میشوند، با بار متعادل میشوند و به صورت خودکار مقیاسبندی میشوند و میتوانند در چندین منطقه در دسترس برای دسترسی بالا مستقر شوند. خط لوله ما چنین نقطه پایانی را برای یک مدل پس از اجرای موفقیت آمیز ایجاد می کند.
در بخش های بعدی، اجزای مختلف را گسترش داده و به جزئیات می پردازیم.
GitLab: مدلهای بسته و خطوط لوله ماشه
ما از GitLab به عنوان مخزن کد خود و برای خط لوله استفاده می کنیم تا کد مدل را بسته بندی کنیم و DAG های جریان هوای پایین دست را راه اندازی کنیم.
خط لوله چند پروژه
ویژگی خط لوله چند پروژه ای GitLab در جایی استفاده می شود که خط لوله اصلی (بالادست) یک مخزن مدل باشد و خط لوله فرزند (پایین دست) مخزن MLOps است. هر مخزن دارای یک .gitlab-ci.yml است و بلوک کد زیر فعال شده در خط لوله بالادست، خط لوله MLOps پایین دستی را راه اندازی می کند.
خط لوله بالادست کد مدل را به خط لوله پایین دستی می فرستد، جایی که کار بسته بندی و انتشار CI آغاز می شود. کد برای کانتینر کردن کد مدل و انتشار آن در Amazon ECR توسط خط لوله MLOps نگهداری و مدیریت می شود. متغیرهایی مانند ACCESS_TOKEN را می فرستد (می توان در زیر ایجاد کرد تنظیمات, دسترسیمتغیرهای JOB_ID (برای دسترسی به مصنوعات بالادست) و $CI_PROJECT_ID (شناسه پروژه مدل مخزن)، به طوری که خط لوله MLOps بتواند به فایلهای کد مدل دسترسی داشته باشد. با مصنوعات شغلی از ویژگی های Gitlab، مخزن پایین دستی با استفاده از دستور زیر به آرتیفکت های راه دور دسترسی پیدا می کند:
مخزن مدل میتواند خطوط لوله پاییندستی را برای چندین مدل از یک مخزن با گسترش مرحلهای که باعث ایجاد آن با استفاده از گسترش می یابد کلمه کلیدی از GitLab، که به شما امکان می دهد از پیکربندی مشابه در مراحل مختلف استفاده مجدد کنید.
پس از انتشار تصویر مدل در Amazon ECR، خط لوله MLOps خط لوله آموزشی آمازون MWAA را با استفاده از Lambda راه اندازی می کند. پس از تایید کاربر، استقرار مدل خط لوله آمازون MWAA را نیز با استفاده از همان عملکرد لامبدا راه اندازی می کند.
نسخهسازی معنایی و انتقال نسخههای پایین دست
ما کد سفارشی را برای نسخه تصاویر ECR و مدل های SageMaker ایجاد کردیم. خط لوله MLOps منطق نسخهسازی معنایی تصاویر و مدلها را بهعنوان بخشی از مرحلهای که کد مدل ظرفی میشود، مدیریت میکند و نسخهها را به عنوان مصنوع به مراحل بعدی منتقل میکند.
آموزش مجدد
از آنجا که بازآموزی یک جنبه حیاتی از چرخه حیات ML است، ما قابلیت های بازآموزی را به عنوان بخشی از خط لوله خود پیاده سازی کرده ایم. ما از SageMaker list-models API استفاده میکنیم تا تشخیص دهیم که آیا بر اساس شماره نسخه بازآموزی مدل و مهر زمانی در حال آموزش مجدد است یا خیر.
ما برنامه روزانه خط لوله بازآموزی را با استفاده از مدیریت می کنیم خطوط لوله برنامه GitLab.
Terraform: راه اندازی زیرساخت
علاوه بر خوشه آمازون MWAA، مخازن ECR، توابع Lambda و موضوع SNS، این راه حل همچنین از هویت AWS و مدیریت دسترسی (IAM) نقش ها، کاربران و خط مشی ها؛ سرویس ذخیره سازی ساده آمازون (Amazon S3) سطل، و یک CloudWatch آمازون ارسال کننده گزارش
برای سادهسازی راهاندازی و نگهداری زیرساختها برای خدمات درگیر در سراسر خط لوله، ما از آن استفاده میکنیم Terraform برای پیاده سازی زیرساخت به عنوان کد. هر زمان که بهروزرسانیهای زیرساختی مورد نیاز باشد، تغییرات کد یک خط لوله GitLab CI را راهاندازی میکند که ما راهاندازی کردهایم، که تغییرات را تأیید و در محیطهای مختلف مستقر میکند (به عنوان مثال، اضافه کردن مجوز به یک خطمشی IAM در حسابهای توسعهدهنده، مرحله و پرود).
Amazon ECR، Amazon S3، و Lambda: تسهیل خط لوله
ما از خدمات کلیدی زیر برای تسهیل خط لوله خود استفاده می کنیم:
- آمازون ECR - برای حفظ و امکان بازیابی راحت تصاویر ظرف مدل، آنها را با نسخه های معنایی برچسب گذاری می کنیم و آنها را در مخازن ECR که در هر زمان تنظیم شده اند بارگذاری می کنیم.
${project_name}/${model_name}از طریق Terraform این یک لایه جداسازی خوب بین مدلهای مختلف را امکانپذیر میکند و به ما امکان میدهد از الگوریتمهای سفارشی استفاده کنیم و درخواستهای استنتاج و پاسخها را طوری قالببندی کنیم که اطلاعات مانیفست مدل مورد نظر (نام مدل، نسخه، مسیر دادههای آموزشی و غیره) را شامل شود. - آمازون S3 - ما از سطل های S3 برای تداوم داده های آموزشی مدل، مصنوعات مدل آموزش دیده در هر مدل، DAG های جریان هوا و سایر اطلاعات اضافی مورد نیاز خطوط لوله استفاده می کنیم.
- یازدهمین حرف الفبای یونانی - از آنجایی که خوشه جریان هوای ما در یک VPC جداگانه برای ملاحظات امنیتی مستقر شده است، DAG ها مستقیما قابل دسترسی نیستند. بنابراین، ما از یک تابع Lambda استفاده میکنیم که با Terraform نیز حفظ میشود تا هر DAG مشخص شده با نام DAG را فعال کنیم. با راه اندازی مناسب IAM، کار GitLab CI تابع Lambda را فعال می کند، که از طریق تنظیمات به DAG های آموزشی یا استقرار درخواست شده منتقل می شود.
آمازون MWAA: خطوط لوله آموزش و استقرار
همانطور که قبلا ذکر شد، ما از آمازون MWAA برای هماهنگی خطوط لوله آموزشی و استقرار استفاده می کنیم. ما از عملگرهای SageMaker موجود در بسته ارائه دهنده آمازون برای Airflow برای ادغام با SageMaker (برای جلوگیری از الگوسازی jinja).
ما از عملگرهای زیر در این خط لوله آموزشی استفاده می کنیم (نشان داده شده در نمودار گردش کار زیر):

خط لوله آموزشی MWAA
ما از عملگرهای زیر در خط لوله استقرار استفاده می کنیم (در نمودار گردش کار زیر نشان داده شده است):

خط لوله استقرار مدل
ما از Slack و Amazon SNS برای انتشار پیامهای خطا/موفقیت و نتایج ارزیابی در هر دو خط لوله استفاده میکنیم. Slack طیف گسترده ای از گزینه ها را برای سفارشی کردن پیام ها فراهم می کند، از جمله موارد زیر:
- SnsPublishOperator - ما استفاده می کنیم SnsPublishOperator برای ارسال اعلان های موفقیت/شکست به ایمیل های کاربر
- Slack API - ما ایجاد کردیم آدرس وب هوک ورودی برای دریافت اعلان های خط لوله به کانال مورد نظر
CloudWatch و VMware Wavefront: نظارت و ثبت گزارش
ما از داشبورد CloudWatch برای پیکربندی نظارت و گزارش گیری نقطه پایانی استفاده می کنیم. این به تجسم و پیگیری معیارهای مختلف عملکرد عملیاتی و مدل خاص برای هر پروژه کمک می کند. علاوه بر خطمشیهای مقیاسبندی خودکار تنظیمشده برای ردیابی برخی از آنها، ما به طور مداوم تغییرات در استفاده از CPU و حافظه، درخواستها در ثانیه، تأخیر پاسخها و معیارهای مدل را نظارت میکنیم.
CloudWatch حتی با داشبورد VMware Tanzu Wavefront ادغام شده است تا بتواند معیارها را برای نقاط پایانی مدل و همچنین سایر خدمات در سطح پروژه تجسم کند.
مزایای کسب و کار و آینده
خطوط لوله ML برای خدمات و ویژگی های ML بسیار مهم هستند. در این پست، یک مورد استفاده از ML را با استفاده از قابلیتهای AWS مورد بحث قرار دادیم. ما یک خط لوله سفارشی با استفاده از SageMaker و Amazon MWAA ساختیم، که میتوانیم از آن در پروژهها و مدلها استفاده مجدد کنیم، و چرخه حیات ML را خودکار کردیم، که زمان را از آموزش مدل تا استقرار تولید به 10 دقیقه کاهش داد.
با انتقال بار چرخه عمر ML به SageMaker، زیرساخت های بهینه و مقیاس پذیر برای آموزش و استقرار مدل فراهم کرد. ارائه مدل با SageMaker به ما کمک کرد تا پیشبینیهای بیدرنگ با تأخیرهای میلیثانیهای و قابلیتهای نظارت داشته باشیم. ما از Terraform برای سهولت راه اندازی و مدیریت زیرساخت استفاده کردیم.
گامهای بعدی برای این خط لوله، تقویت خط لوله آموزشی مدل با قابلیتهای بازآموزی است، چه برنامهریزی شده باشد یا براساس تشخیص رانش مدل، پشتیبانی از استقرار سایه یا آزمایش A/B برای استقرار مدل سریعتر و واجد شرایط، و ردیابی نسل ML. همچنین در نظر داریم ارزیابی کنیم خطوط لوله آمازون SageMaker زیرا ادغام GitLab اکنون پشتیبانی می شود.
درس های آموخته شده
به عنوان بخشی از ساخت این راه حل، ما یاد گرفتیم که باید زودتر تعمیم دهید، اما بیش از حد تعمیم ندهید. هنگامی که ما برای اولین بار طراحی معماری را به پایان رساندیم، سعی کردیم الگوی کد را برای کد مدل به عنوان بهترین عمل ایجاد و اجرا کنیم. با این حال، آنقدر در مراحل اولیه توسعه بود که الگوها یا بیش از حد تعمیم یافته بودند یا بسیار جزئی بودند که برای مدلهای آینده قابل استفاده مجدد نبودند.
پس از تحویل اولین مدل از طریق خط لوله، الگوها به طور طبیعی بر اساس بینش کار قبلی ما ظاهر شدند. یک خط لوله نمی تواند همه کارها را از روز اول انجام دهد.
آزمایش و تولید مدل اغلب الزامات بسیار متفاوت (یا حتی گاهی متناقض) دارند. بسیار مهم است که این الزامات را از ابتدا به عنوان یک تیم متعادل کنیم و بر اساس آن اولویت بندی کنیم.
علاوه بر این، ممکن است به همه ویژگی های یک سرویس نیاز نداشته باشید. استفاده از ویژگیهای ضروری یک سرویس و داشتن طراحی مدولار شده، کلید توسعه کارآمدتر و خط لوله انعطافپذیر است.
نتیجه
در این پست، ما نشان دادیم که چگونه با استفاده از SageMaker و Amazon MWAA یک راه حل MLOps ساختیم که فرآیند استقرار مدلها را برای تولید، با مداخله دستی کمی از دانشمندان داده، خودکار کرد. ما شما را تشویق می کنیم تا خدمات مختلف AWS مانند SageMaker، Amazon MWAA، Amazon S3 و Amazon ECR را برای ایجاد یک راه حل کامل MLOps ارزیابی کنید.
*Apache، Apache Airflow و Airflow علائم تجاری یا علائم تجاری ثبت شده این شرکت هستند Apache Software Foundation در ایالات متحده و / یا کشورهای دیگر.
درباره نویسنده
 دیپاک متم یک مدیر ارشد مهندسی در VMware، Carbon Black Unit است. او و تیمش روی ساخت برنامهها و سرویسهای مبتنی بر جریان کار میکنند که بسیار در دسترس، مقیاسپذیر و انعطافپذیر هستند تا راهحلهای مبتنی بر یادگیری ماشین را در زمان واقعی به مشتریان ارائه دهند. او و تیمش همچنین مسئول ایجاد ابزارهای لازم برای دانشمندان داده برای ساخت، آموزش، استقرار و اعتبارسنجی مدلهای ML خود در تولید هستند.
دیپاک متم یک مدیر ارشد مهندسی در VMware، Carbon Black Unit است. او و تیمش روی ساخت برنامهها و سرویسهای مبتنی بر جریان کار میکنند که بسیار در دسترس، مقیاسپذیر و انعطافپذیر هستند تا راهحلهای مبتنی بر یادگیری ماشین را در زمان واقعی به مشتریان ارائه دهند. او و تیمش همچنین مسئول ایجاد ابزارهای لازم برای دانشمندان داده برای ساخت، آموزش، استقرار و اعتبارسنجی مدلهای ML خود در تولید هستند.
 مهیما آگاروال یک مهندس یادگیری ماشین در VMware، Carbon Black Unit است.
مهیما آگاروال یک مهندس یادگیری ماشین در VMware، Carbon Black Unit است.
او روی طراحی، ساخت و توسعه اجزای اصلی و معماری پلت فرم یادگیری ماشین برای VMware CB SBU کار می کند.
 وامشی کریشنا انابوتالا یک معمار متخصص هوش مصنوعی کاربردی در AWS است. او با مشتریانی از بخشهای مختلف کار میکند تا دادهها، تحلیلها و ابتکارات یادگیری ماشینی را تسریع بخشد. او علاقه زیادی به سیستم های توصیه، NLP و حوزه های بینایی کامپیوتر در هوش مصنوعی و ML دارد. خارج از محل کار، وامشی یک علاقهمند به RC است و تجهیزات RC (هواپیما، ماشین و هواپیماهای بدون سرنشین) میسازد و همچنین از باغبانی لذت میبرد.
وامشی کریشنا انابوتالا یک معمار متخصص هوش مصنوعی کاربردی در AWS است. او با مشتریانی از بخشهای مختلف کار میکند تا دادهها، تحلیلها و ابتکارات یادگیری ماشینی را تسریع بخشد. او علاقه زیادی به سیستم های توصیه، NLP و حوزه های بینایی کامپیوتر در هوش مصنوعی و ML دارد. خارج از محل کار، وامشی یک علاقهمند به RC است و تجهیزات RC (هواپیما، ماشین و هواپیماهای بدون سرنشین) میسازد و همچنین از باغبانی لذت میبرد.
 ساحل تاپر یک معمار راه حل های سازمانی است. او با مشتریان همکاری می کند تا به آنها کمک کند تا برنامه های بسیار در دسترس، مقیاس پذیر و انعطاف پذیر را در AWS Cloud بسازند. او در حال حاضر بر روی کانتینرها و راه حل های یادگیری ماشین متمرکز است.
ساحل تاپر یک معمار راه حل های سازمانی است. او با مشتریان همکاری می کند تا به آنها کمک کند تا برنامه های بسیار در دسترس، مقیاس پذیر و انعطاف پذیر را در AWS Cloud بسازند. او در حال حاضر بر روی کانتینرها و راه حل های یادگیری ماشین متمرکز است.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- پلاتوبلاک چین. Web3 Metaverse Intelligence. دانش تقویت شده دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/how-vmware-built-an-mlops-pipeline-from-scratch-using-gitlab-amazon-mwaa-and-amazon-sagemaker/
- :است
- $UP
- 1
- 10
- 100
- 7
- 8
- a
- درباره ما
- شتاب دادن
- دسترسی
- قابل دسترسی است
- بر این اساس
- حساب ها
- دست
- در میان
- حلقوی
- اضافه
- اضافی
- اطلاعات اضافی
- پس از
- در برابر
- AI
- الگوریتم
- معرفی
- اجازه می دهد تا
- آمازون
- آمازون SageMaker
- تحلیل
- علم تجزیه و تحلیل
- و
- هر جا
- آپاچی
- API
- کاربرد
- برنامه های کاربردی
- اعمال می شود
- هوش مصنوعی کاربردی
- تصویب
- معماری
- هستند
- مناطق
- AS
- ظاهر
- At
- حمله
- تالیف
- خودکار
- خودکار
- خودکار می کند
- دسترس پذیری
- در دسترس
- اجتناب از
- AWS
- بخش مدیریت
- برج میزان
- مستقر
- اساسی
- BE
- زیرا
- شروع
- مزایای
- بهترین
- بهتر
- میان
- سیاه پوست
- مسدود کردن
- شاخه
- به ارمغان بیاورد
- ساختن
- بنا
- ساخته
- بار
- by
- CAN
- نمی توان
- قابلیت های
- کربن
- اتومبیل
- مورد
- CB
- معین
- تبادل
- کانال
- کودک
- را انتخاب
- ابر
- خوشه
- رمز
- مجموعه
- ارتباط
- مقایسه
- کامل
- اجزاء
- محاسبه
- کامپیوتر
- چشم انداز کامپیوتر
- هدایت می کند
- پیکر بندی
- پیکربندی
- درگیری
- گیجی
- ملاحظات
- مصرف
- مصرف
- ظرف
- ظروف
- به طور مداوم
- مناسب
- هسته
- میتوانست
- کشور
- پردازنده
- ایجاد
- ایجاد شده
- ایجاد
- ایجاد
- بحرانی
- بسیار سخت
- در حال حاضر
- سفارشی
- مشتریان
- سفارشی
- حملات سایبری
- DAG
- روزانه
- داشبورد
- داده ها
- دانشمند داده
- روز
- مشخص
- تحویل
- گسترش
- مستقر
- استقرار
- گسترش
- اعزام ها
- مستقر می کند
- طرح
- طراحی
- طراحی
- دقیق
- جزئیات
- کشف
- برنامه نویس
- توسعه
- در حال توسعه
- پروژه
- مختلف
- مستقیما
- بحث و تبادل نظر
- بحث کردیم
- کارگر بارانداز
- آیا
- پایین
- هواپیماهای بدون سرنشین
- هر
- پیش از آن
- در اوایل
- راحتی در استفاده
- موثر
- هر دو
- پست الکترونیک
- سنگ سنباده
- قادر ساختن
- فعال
- را قادر می سازد
- تشویق
- پشت سر هم
- نقطه پایانی
- مهندس
- مهندسی
- سرمایه گذاری
- راه حل های سازمانی
- علاقهمند
- محیط
- تجهیزات
- ضروری است
- اتر (ETH)
- ارزیابی
- ارزیابی
- ارزیابی
- ارزیابی
- ارزیابی
- حتی
- واقعه
- هر
- همه چیز
- مثال
- گسترش
- گسترش
- f1
- تسهیل کردن
- شکست
- بسیار
- سریعتر
- ویژگی
- امکانات
- کمی از
- فایل ها
- نام خانوادگی
- قابل انعطاف
- تمرکز
- متمرکز شده است
- تمرکز
- پیروی
- برای
- قالب
- از جانب
- کامل
- طیف کامل
- کاملا
- تابع
- توابع
- بیشتر
- آینده
- تولید
- دریافت کنید
- خوب
- گروه
- آیا
- داشتن
- کمک
- کمک کرد
- کمک می کند
- زیاد
- عملکرد بالا
- خیلی
- میزبانی وب
- چگونه
- اما
- HTML
- HTTP
- HTTPS
- IAM
- ID
- دلخواه
- شناسایی
- شناسایی
- هویت
- تصویر
- تصاویر
- انجام
- پیاده سازی
- اجرا
- in
- شامل
- شامل
- از جمله
- اطلاعات
- شالوده
- ابتکارات
- بینش
- ادغام
- یکپارچه
- ادغام
- ادغام
- تعامل
- مداخله
- فراخوانی میکند
- گرفتار
- انزوا
- IT
- ITS
- کار
- شغل ها
- JPG
- نگاه داشتن
- کلید
- کلید
- تاخیر
- لایه
- آموخته
- یادگیری
- درس
- درس های آموخته شده
- اجازه می دهد تا
- سطح
- wifecycwe
- پسندیدن
- کوچک
- بار
- کم
- دستگاه
- فراگیری ماشین
- اصلی
- حفظ
- حفظ
- نگهداری
- ساخت
- مدیریت
- اداره می شود
- مدیریت
- مدیر
- مدیریت می کند
- مدیریت
- کتابچه راهنمای
- ماتریس
- حافظه
- ذکر شده
- پیام
- پیام
- متریک
- قدرت
- میلی ثانیه
- دقیقه
- ML
- MLO ها
- مدل
- مدل
- مدرن
- مانیتور
- نظارت بر
- بیش
- کارآمدتر
- چندگانه
- نام
- به طور طبیعی
- لازم
- نیاز
- جدید
- بعد
- nlp
- سر و صدا
- اخطار
- اطلاعیه ها
- عدد
- of
- ارائه
- پیشنهادات
- on
- ONE
- قابل استفاده
- اپراتور
- بهینه
- گزینه
- هماهنگ شده
- سازمان یافته
- دیگر
- خارج از
- به طور کلی
- بسته
- بسته
- بسته بندی
- بخش
- عبور می کند
- عبور
- احساساتی
- مسیر
- کارایی
- اجازه
- خط لوله
- برنامه
- هواپیما
- سکو
- افلاطون
- هوش داده افلاطون
- PlatoData
- سیاست
- سیاست
- پست
- تمرین
- پیش بینی
- قبلی
- اولویت بندی
- روند
- محصول
- تولید
- پروژه
- پروژه ها
- مناسب
- حفاظت
- ارائه
- ارائه دهنده
- فراهم می کند
- منتشر کردن
- منتشر شده
- منتشر می کند
- انتشار
- اهداف
- واجد شرایط
- محدوده
- زمان واقعی
- توصیه
- کاهش
- اشاره
- ثبت نام
- رجیستری
- روابط
- دور
- مشهور
- مخزن
- خواسته
- درخواست
- ضروری
- مورد نیاز
- تحقیق
- انعطاف پذیر
- پاسخ
- مسئوليت
- نتایج
- بازآموزی
- قابل استفاده مجدد
- نقش
- دویدن
- دونده
- حکیم ساز
- همان
- مقیاس پذیر
- مقیاس گذاری
- برنامه
- برنامه ریزی
- دانشمند
- دانشمندان
- دوم
- بخش
- بخش ها
- تیم امنیت لاتاری
- ارشد
- جداگانه
- بدون سرور
- سرور
- سرویس
- خدمات
- خدمت
- تنظیم
- برپایی
- سایه
- انتقال
- باید
- نشان داده شده
- ساده
- شل
- So
- تا حالا
- نرم افزار
- راه حل
- مزایا
- برخی از
- منبع
- کد منبع
- متخصص
- خاص
- مشخص شده
- طیف
- نور افکن
- صحنه
- مراحل
- استاندارد
- شروع
- شروع می شود
- ایالات
- مراحل
- ذخیره سازی
- استراتژی
- جریان
- ساده کردن
- متعاقب
- موفقیت
- چنین
- پشتیبانی
- پشتیبانی
- سطح
- سیستم های
- TAG
- گرفتن
- وظایف
- تیم
- قالب
- Terraform
- تست
- که
- La
- شان
- آنها
- از این رو
- اینها
- تهدید
- سه
- از طریق
- سراسر
- توان
- زمان
- برچسب زمان
- به
- با هم
- هم
- ابزار
- ابزار
- بالا
- موضوع
- مسیر
- پیگردی
- علائم تجاری
- ترافیک
- قطار
- آموزش دیده
- آموزش
- ماشه
- باعث شد
- دور زدن
- زیر
- واحد
- متحد
- ایالات متحده
- به روز رسانی
- us
- استفاده
- استفاده کنید
- مورد استفاده
- کاربر
- کاربران
- تصدیق
- اعتبار سنجی
- متغیرها
- مختلف
- نسخه
- عملا
- دید
- تجسم
- آموزش VMware
- حجم
- مسیر..
- خوب
- چی
- چه
- که
- وسیع
- دامنه گسترده
- با
- در داخل
- بدون
- مهاجرت کاری
- گردش کار
- گردش کار
- با این نسخهها کار
- خواهد بود
- زفیرنت
- زیپ
- مناطق