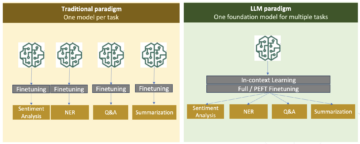
مدلهای ترانسفورماتور مبتنی بر توجه بزرگ دستاوردهای عظیمی در پردازش زبان طبیعی (NLP) به دست آوردهاند. با این حال، آموزش این شبکه های غول پیکر از ابتدا به حجم عظیمی از داده ها و محاسبات نیاز دارد. برای مجموعه داده های NLP کوچکتر، یک استراتژی ساده و در عین حال موثر استفاده از یک ترانسفورماتور از پیش آموزش دیده است که معمولاً به شیوه ای بدون نظارت بر روی مجموعه داده های بسیار بزرگ آموزش داده می شود و آن را بر روی مجموعه داده مورد نظر تنظیم می کند. در آغوش کشیدن صورت یک باغ وحش مدل بزرگ از این ترانسفورماتورهای از پیش آموزش دیده نگهداری می کند و حتی برای کاربران مبتدی به راحتی قابل دسترسی است.
با این حال، تنظیم دقیق این مدل ها همچنان به دانش تخصصی نیاز دارد، زیرا آنها به فراپارامترهای خود، مانند نرخ یادگیری یا اندازه دسته، کاملاً حساس هستند. در این پست، نحوه بهینه سازی این هایپرپارامترها را با چارچوب متن باز نشان می دهیم Syne Tune برای بهینه سازی فراپارامتر توزیع شده (HPO). Syne Tune به ما امکان می دهد پیکربندی هایپرپارامتر بهتری را پیدا کنیم که در مقایسه با هایپرپارامترهای پیش فرض در محبوب، به بهبود نسبی بین 1-4٪ دست یابد. GLUE مجموعه داده های معیار انتخاب خود مدل از پیش آموزش دیده نیز می تواند یک فراپارامتر در نظر گرفته شود و بنابراین به طور خودکار توسط Syne Tune انتخاب شود. در یک مشکل طبقه بندی متن، این منجر به افزایش بیشتر دقت در مقایسه با مدل پیش فرض تقریباً 5٪ می شود. با این حال، ما میتوانیم تصمیمات بیشتری را که کاربر باید بگیرد، خودکار کنیم. ما این را با نشان دادن نوع نمونه به عنوان یک فراپارامتر که بعداً برای استقرار مدل استفاده میکنیم، نشان میدهیم. با انتخاب نوع نمونه مناسب، میتوانیم پیکربندیهایی را پیدا کنیم که به طور بهینه هزینه و تأخیر را کاهش میدهند.
برای آشنایی با Syne Tune لطفا مراجعه کنید کارهای تنظیم هایپرپارامتر و معماری عصبی توزیع شده را با Syne Tune اجرا کنید.
بهینه سازی هایپرپارامتر با Syne Tune
ما با استفاده از GLUE مجموعه معیار، که از XNUMX مجموعه داده برای وظایف درک زبان طبیعی، مانند تشخیص دلالت متنی یا تجزیه و تحلیل احساسات تشکیل شده است. برای آن، ما Hugging Face را تطبیق می دهیم run_glue.py اسکریپت آموزشی مجموعه داده های GLUE با یک مجموعه آموزشی و ارزیابی از پیش تعریف شده با برچسب ها و همچنین یک مجموعه تست نگهدارنده بدون برچسب ارائه می شوند. بنابراین، مجموعه آموزشی را به مجموعههای آموزشی و اعتبار سنجی (70%/30% تقسیم) تقسیم میکنیم و از مجموعه ارزیابی به عنوان مجموعه دادههای آزمون نگهدارنده خود استفاده میکنیم. علاوه بر این، یک تابع تماس دیگر را به Hugging Face's Trainer API اضافه می کنیم که عملکرد اعتبارسنجی را پس از هر دوره به Syne Tune گزارش می دهد. کد زیر را ببینید:
ما با بهینهسازی فراپارامترهای آموزشی معمولی شروع میکنیم: نرخ یادگیری، نسبت گرم کردن برای افزایش نرخ یادگیری، و اندازه دستهای برای تنظیم دقیق BERT از پیش آموزش دیده (برت پایه موردی) مدل، که مدل پیش فرض در مثال Hugging Face است. کد زیر را ببینید:
ما به عنوان روش HPO خود استفاده می کنیم آسا، که پیکربندی هایپرپارامتر را به طور یکنواخت به صورت تصادفی نمونه برداری می کند و به طور مکرر ارزیابی پیکربندی های ضعیف را متوقف می کند. اگرچه روشهای پیچیدهتر از یک مدل احتمالی تابع هدف استفاده میکنند، مانند BO یا MoBster، ما از ASHA برای این پست استفاده میکنیم زیرا بدون هیچ فرضی در فضای جستجو ارائه میشود.
در شکل زیر، بهبود نسبی خطای تست را نسبت به پیکربندی پیشفرض هایپرپارامتر Hugging Faces مقایسه میکنیم.
![]()
برای سادگی، ما مقایسه را به MRPC، COLA و STSB محدود می کنیم، اما همچنین پیشرفت های مشابهی را برای سایر مجموعه داده های GLUE مشاهده می کنیم. برای هر مجموعه داده، ASHA را روی یک ml.g4dn.xlarge اجرا می کنیم آمازون SageMaker به عنوان مثال با بودجه زمان اجرا 1,800 ثانیه، که به ترتیب با 13، 7، و 9 ارزیابی عملکرد کامل در این مجموعه داده ها مطابقت دارد. برای در نظر گرفتن تصادفی بودن فرآیند آموزش، به عنوان مثال ناشی از نمونه برداری دسته ای کوچک، هم ASHA و هم پیکربندی پیش فرض را برای پنج تکرار با یک دانه مستقل برای تولید کننده اعداد تصادفی اجرا می کنیم و میانگین و انحراف استاندارد را گزارش می کنیم. بهبود نسبی در طول تکرارها ما میتوانیم ببینیم که در تمام مجموعههای داده، ما در واقع میتوانیم عملکرد پیشبینی را 1-3 درصد نسبت به عملکرد پیکربندی پیشفرض با دقت انتخابشده بهبود دهیم.
انتخاب مدل از پیش آموزش دیده را خودکار کنید
ما می توانیم از HPO نه تنها برای یافتن هایپرپارامترها استفاده کنیم، بلکه به طور خودکار مدل از پیش آموزش دیده مناسب را نیز انتخاب کنیم. چرا می خواهیم این کار را انجام دهیم؟ از آنجایی که هیچ مدل واحدی در تمام مجموعه داده ها بهتر عمل نمی کند، باید مدل مناسب را برای یک مجموعه داده خاص انتخاب کنیم. برای نشان دادن این موضوع، ما طیف وسیعی از مدلهای ترانسفورماتور محبوب را از Hugging Face ارزیابی میکنیم. برای هر مجموعه داده، هر مدل را بر اساس عملکرد آزمایشی آن رتبه بندی می کنیم. رتبه بندی در میان مجموعه داده ها (شکل زیر را ببینید) تغییر می کند و نه یک مدل واحد که بالاترین امتیاز را در هر مجموعه داده کسب کند. به عنوان مرجع، ما همچنین عملکرد تست مطلق هر مدل و مجموعه داده را در شکل زیر نشان می دهیم.
برای انتخاب خودکار مدل مناسب، میتوانیم انتخاب مدل را به عنوان پارامترهای طبقهبندی کنیم و آن را به فضای جستجوی فراپارامتر خود اضافه کنیم:
اگرچه فضای جستجو اکنون بزرگتر شده است، اما این لزوماً به این معنی نیست که بهینه سازی آن دشوارتر است. شکل زیر خطای تست بهترین پیکربندی مشاهده شده (بر اساس خطای اعتبارسنجی) را در مجموعه داده های MRPC ASHA در طول زمان نشان می دهد، زمانی که ما در فضای اصلی (خط آبی) جستجو می کنیم (با یک مدل از پیش آموزش دیده با کیس پایه BERT). ) یا در فضای جستجوی جدید افزوده شده (خط نارنجی). با توجه به همین بودجه، ASHA قادر است پیکربندی هایپرپارامتر با عملکرد بسیار بهتری را در فضای جستجوی گسترده نسبت به فضای کوچکتر پیدا کند.
![]()
انتخاب نوع نمونه را خودکار کنید
در عمل، ممکن است ما فقط به بهینه سازی عملکرد پیش بینی اهمیت ندهیم. همچنین ممکن است به اهداف دیگری مانند زمان آموزش، هزینه (دلار)، تأخیر یا معیارهای عادلانه اهمیت دهیم. ما همچنین باید انتخاب های دیگری فراتر از فراپارامترهای مدل داشته باشیم، به عنوان مثال انتخاب نوع نمونه.
اگرچه نوع نمونه بر عملکرد پیشبینی تأثیر نمیگذارد، اما به شدت بر هزینه (دلار)، زمان اجرای آموزش و تأخیر تأثیر میگذارد. زمانی که مدل به کار گرفته می شود مورد دوم اهمیت ویژه ای پیدا می کند. میتوانیم HPO را یک مسئله بهینهسازی چند هدفه بیان کنیم، جایی که هدف ما بهینهسازی چندین هدف به طور همزمان است. با این حال، هیچ راه حل واحدی همه معیارها را به طور همزمان بهینه نمی کند. در عوض، هدف ما یافتن مجموعهای از پیکربندیها است که به طور بهینه یک هدف را در مقابل هدف دیگر قرار میدهد. به این می گویند مجموعه پارتو.
برای تجزیه و تحلیل بیشتر این تنظیمات، انتخاب نوع نمونه را به عنوان یک فراپارامتر دستهبندی اضافی به فضای جستجوی خود اضافه میکنیم:
استفاده می کنیم MO-ASHA، که ASHA را با استفاده از مرتبسازی غیرمسلط با سناریوی چند هدفه سازگار میکند. در هر تکرار، MO-ASHA همچنین برای هر پیکربندی، نوع نمونهای را که میخواهیم آن را ارزیابی کنیم، انتخاب میکند. برای اجرای HPO روی مجموعهای از نمونههای ناهمگن، Syne Tune باطن SageMaker را ارائه میکند. با این بکاند، هر آزمایشی به عنوان یک کار آموزشی مستقل SageMaker در نمونه خودش ارزیابی میشود. تعداد کارگران تعیین می کند که چند شغل SageMaker را در یک زمان معین به طور موازی اجرا می کنیم. خود بهینه ساز، MO-ASHA در مورد ما، یا بر روی ماشین محلی، یک نوت بوک Sagemaker یا در یک کار آموزشی جداگانه SageMaker اجرا می شود. کد زیر را ببینید:
شکلهای زیر خطای تاخیر در مقابل آزمون در سمت چپ و تاخیر در مقابل هزینه در سمت راست را برای پیکربندیهای تصادفی نمونهبرداری شده توسط MO-ASHA (ما محور را برای دید محدود میکنیم) در مجموعه داده MRPC پس از اجرای آن به مدت 10,800 ثانیه روی چهار کارگر نشان میدهد. رنگ نشان دهنده نوع نمونه است. خط مشکی چین نشان دهنده مجموعه پارتو است، به معنای مجموعه نقاطی که بر تمام نقاط دیگر حداقل در یک هدف تسلط دارند.
ما میتوانیم بین تاخیر و خطای تست یک مبادله مشاهده کنیم، به این معنی که بهترین پیکربندی با کمترین خطای تست، کمترین تاخیر را به دست نمیآورد. بر اساس اولویت خود، می توانید یک پیکربندی هایپرپارامتری را انتخاب کنید که عملکرد تست را قربانی می کند اما با تاخیر کمتری همراه است. ما همچنین شاهد مبادله بین تاخیر و هزینه هستیم. برای مثال، با استفاده از یک نمونه ml.g4dn.xlarge کوچکتر، ما فقط تأخیر را به طور جزئی افزایش می دهیم، اما یک چهارم هزینه یک نمونه ml.g4dn.8xlarge را پرداخت می کنیم.
نتیجه
در این پست، ما در مورد بهینه سازی هایپرپارامتر برای تنظیم دقیق مدل های ترانسفورماتور از پیش آموزش دیده از Hugging Face بر اساس Syne Tune بحث کردیم. دیدیم که با بهینهسازی فراپارامترهایی مانند نرخ یادگیری، اندازه دسته و نسبت گرم کردن، میتوانیم پیکربندی پیشفرض با دقت انتخاب شده را بهبود ببخشیم. ما همچنین میتوانیم این را با انتخاب خودکار مدل از پیش آموزشدیده از طریق بهینهسازی هایپرپارامتر گسترش دهیم.
با کمک باطن SageMaker Syne Tune، میتوانیم نوع نمونه را به عنوان یک فراپارامتر در نظر بگیریم. اگرچه نوع نمونه بر عملکرد تأثیر نمی گذارد، اما تأثیر قابل توجهی بر تأخیر و هزینه دارد. بنابراین، با در نظر گرفتن HPO به عنوان یک مسئله بهینهسازی چند هدفه، میتوانیم مجموعهای از پیکربندیها را پیدا کنیم که به طور بهینه یک هدف را در مقابل هدف دیگر قرار دهند. اگر می خواهید خودتان این را امتحان کنید، ما را بررسی کنید نمونه دفترچه یادداشت.
درباره نویسنده
![]() آرون کلین دانشمند کاربردی در AWS است.
آرون کلین دانشمند کاربردی در AWS است.
![]() ماتیاس سیگر یک دانشمند کاربردی اصلی در AWS است.
ماتیاس سیگر یک دانشمند کاربردی اصلی در AWS است.
![]() دیوید سالیناس دانشمند کاربردی Sr در AWS است.
دیوید سالیناس دانشمند کاربردی Sr در AWS است.
![]() امیلی وبر درست پس از راه اندازی SageMaker به AWS ملحق شد و از آن زمان تلاش کرده است تا در مورد آن به جهان بگوید! غیر از ایجاد تجربیات جدید ML برای مشتریان، امیلی از مراقبه و مطالعه بودیسم تبتی لذت می برد.
امیلی وبر درست پس از راه اندازی SageMaker به AWS ملحق شد و از آن زمان تلاش کرده است تا در مورد آن به جهان بگوید! غیر از ایجاد تجربیات جدید ML برای مشتریان، امیلی از مراقبه و مطالعه بودیسم تبتی لذت می برد.
![]() سدریک آرچامبو دانشمند کاربردی اصلی در AWS و عضو آزمایشگاه اروپایی برای یادگیری و سیستم های هوشمند است.
سدریک آرچامبو دانشمند کاربردی اصلی در AWS و عضو آزمایشگاه اروپایی برای یادگیری و سیستم های هوشمند است.
- Coinsmart. بهترین صرافی بیت کوین و کریپتو اروپا.
- پلاتوبلاک چین. Web3 Metaverse Intelligence. دانش تقویت شده دسترسی رایگان.
- CryptoHawk. رادار آلت کوین امتحان رایگان.
- منبع: https://aws.amazon.com/blogs/machine-learning/hyperparameter-optimization-for-fine-tuning-pre-trained-transformer-models-from-hugging-face/
- "
- 10
- 100
- 7
- 9
- a
- درباره ما
- مطلق
- در دسترس
- حساب
- رسیدن
- در میان
- اضافی
- اثر
- معرفی
- اجازه می دهد تا
- هر چند
- آمازون
- مقدار
- تحلیل
- تحلیل
- دیگر
- API
- اعمال می شود
- تقریبا
- معماری
- افزوده شده
- خودکار بودن
- بطور خودکار
- میانگین
- AWS
- محور
- زیرا
- محک
- بهترین
- بهتر
- میان
- خارج از
- سیاه پوست
- جسور
- بالا بردن
- بودجه
- بنا
- اهميت دادن
- مورد
- ایجاد می شود
- انتخاب
- انتخاب
- برگزیده
- کلاس
- طبقه بندی
- رمز
- بیا
- مقایسه
- محاسبه
- پیکر بندی
- کنترل
- مشتریان
- داده ها
- تصمیم گیری
- نشان دادن
- گسترش
- مستقر
- توزیع شده
- نمی کند
- دلار
- هر
- به آسانی
- موثر
- اروپایی
- ارزیابی
- ارزیابی
- مثال
- تجارب
- کارشناس
- گسترش
- چهره
- روش
- شکل
- پیروی
- چارچوب
- از جانب
- کامل
- تابع
- بیشتر
- بعلاوه
- ژنراتور
- کمک
- اینجا کلیک نمایید
- چگونه
- چگونه
- اما
- HTTPS
- تأثیر
- مهم
- بهبود
- بهبود
- افزایش
- مستقل
- نفوذ
- نمونه
- هوشمند
- علاقه
- IT
- خود
- کار
- شغل ها
- پیوست
- دانش
- آزمایشگاه
- برچسب ها
- زبان
- بزرگ
- بزرگتر
- راه اندازی
- منجر می شود
- یادگیری
- محدود
- لاین
- محلی
- دستگاه
- ساخت
- باعث می شود
- عظیم
- معنی
- روش
- متریک
- قدرت
- ML
- مدل
- مدل
- بیش
- چندگانه
- طبیعی
- لزوما
- نیازهای
- شبکه
- دفتر یادداشت
- عدد
- اهداف
- به دست آمده
- بهینه سازی
- بهینه سازی
- بهینه سازی
- اصلی
- دیگر
- خود
- ویژه
- پرداخت
- کارایی
- انجام
- لطفا
- نقطه
- محبوب
- تمرین
- اصلی
- مشکل
- روند
- در حال پردازش
- فراهم می کند
- محدوده
- رتبه بندی
- گزارش
- خبرنگار
- گزارش ها
- نشان دهنده
- نیاز
- نتایج
- دویدن
- در حال اجرا
- همان
- دانشمند
- جستجو
- ثانیه
- دانه
- انتخاب شد
- احساس
- تنظیم
- محیط
- نشان
- قابل توجه
- مشابه
- ساده
- تنها
- اندازه
- راه حل
- مصنوعی
- فضا
- خاص
- انشعاب
- استاندارد
- شروع
- دولت
- هنوز
- استراتژی
- سیستم های
- وظایف
- آزمون
- La
- جهان
- از این رو
- زمان
- تجارت
- آموزش
- درمان
- عظیم
- محاکمه
- درک
- us
- استفاده کنید
- کاربران
- معمولا
- استفاده کنید
- اعتبار سنجی
- دید
- ویکیپدیا
- بدون
- کارگران
- جهان
- شما