ما اخیرا اعلام کرد پشتیبانی سازند دریاچه AWS سیاست های کنترل دسترسی دقیق در آمازون آتنا پرس و جو برای داده های ذخیره شده در هر فرمت فایل پشتیبانی شده با استفاده از فرمت های جدول مانند Apache Iceberg، Apache Hudi و Apache Hive. AWS Lake Formation به شما این امکان را میدهد تا سیاستهای دسترسی به پایگاه داده، جدول و ستونها را برای استعلام جداول Iceberg ذخیره شده در Amazon S3 تعریف و اجرا کنید. Lake Formation یک لایه مجوز و حاکمیت بر روی داده های ذخیره شده در Amazon S3 ارائه می دهد. این قابلیت مستلزم آن است که شما آن را ارتقا دهید موتور آتنا نسخه 3.
سازمانهای بزرگ اغلب دارای خطوط کسبوکار (LoBs) هستند که در مدیریت دادههای تجاری خود با استقلال عمل میکنند. این باعث می شود به اشتراک گذاری داده ها در LoB ها غیر ضروری باشد. این سازمان ها یک مدل فدرال را اتخاذ کرده اند که هر LoB دارای استقلال تصمیم گیری در مورد داده های خود است. آنها از مدل ناشر/مصرف کننده با یک لایه حاکمیت متمرکز استفاده می کنند که برای اعمال کنترل های دسترسی استفاده می شود. اگر علاقه مند به کسب اطلاعات بیشتر در مورد معماری دیتا مش هستید، مراجعه کنید یک معماری مش داده با استفاده از AWS Lake Formation و AWS Glue طراحی کنید. با موتور Athena نسخه 3، مشتریان می توانند از همان کنترل های دقیق برای چارچوب های داده باز مانند Apache Iceberg، Apache Hudi و Apache Hive استفاده کنند.
در این پست، ما عمیقاً به یک مورد استفاده میپردازیم که در آن شما یک مدل تولیدکننده/مصرفکننده با اشتراکگذاری دادهها را فعال کردهاید تا دسترسی محدودی به جدول Apache Iceberg که مصرفکننده میتواند پرس و جو کند، فراهم میکند. در مورد فیلتر کردن ستون برای محدود کردن ردیفهای خاص، فیلتر کردن برای محدود کردن دسترسی در سطح ستون، تکامل طرحواره و سفر در زمان بحث خواهیم کرد.
بررسی اجمالی راه حل
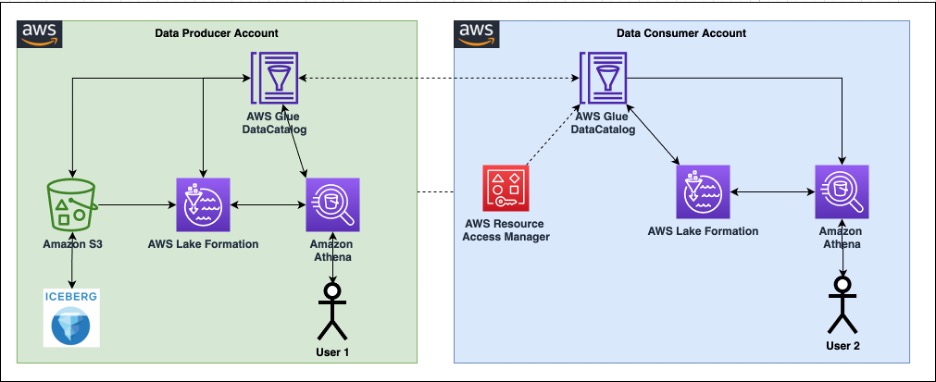
برای نشان دادن کارکرد مجوزهای ریز دانه برای جداول Apache Iceberg با Athena و Lake Formation، اجزای زیر را تنظیم کردیم:
- در حساب تولید کننده:
- An چسب AWS کاتالوگ داده برای ثبت طرح و نقشه جدول در قالب Apache Iceberg
- Lake Formation برای ارائه دسترسی دقیق به حساب مصرف کننده
- آتنا برای تأیید اطلاعات از حساب تولید کننده
- در حساب مصرف کننده:
- مدیریت دسترسی به منابع AWS (RAM AWS) برای ایجاد یک دست دادن بین کاتالوگ داده تولید کننده و مصرف کننده
- Lake Formation برای ارائه دسترسی دقیق به حساب مصرف کننده
- آتنا برای تأیید اطلاعات از حساب تولید کننده
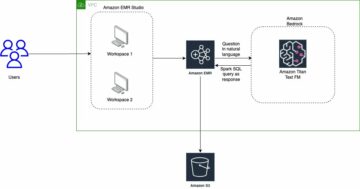
نمودار زیر معماری را نشان می دهد.
پیش نیازها
قبل از شروع، مطمئن شوید که موارد زیر را دارید:
راه اندازی تولید کننده داده
در این قسمت مراحل راه اندازی تولید کننده داده را ارائه می دهیم.
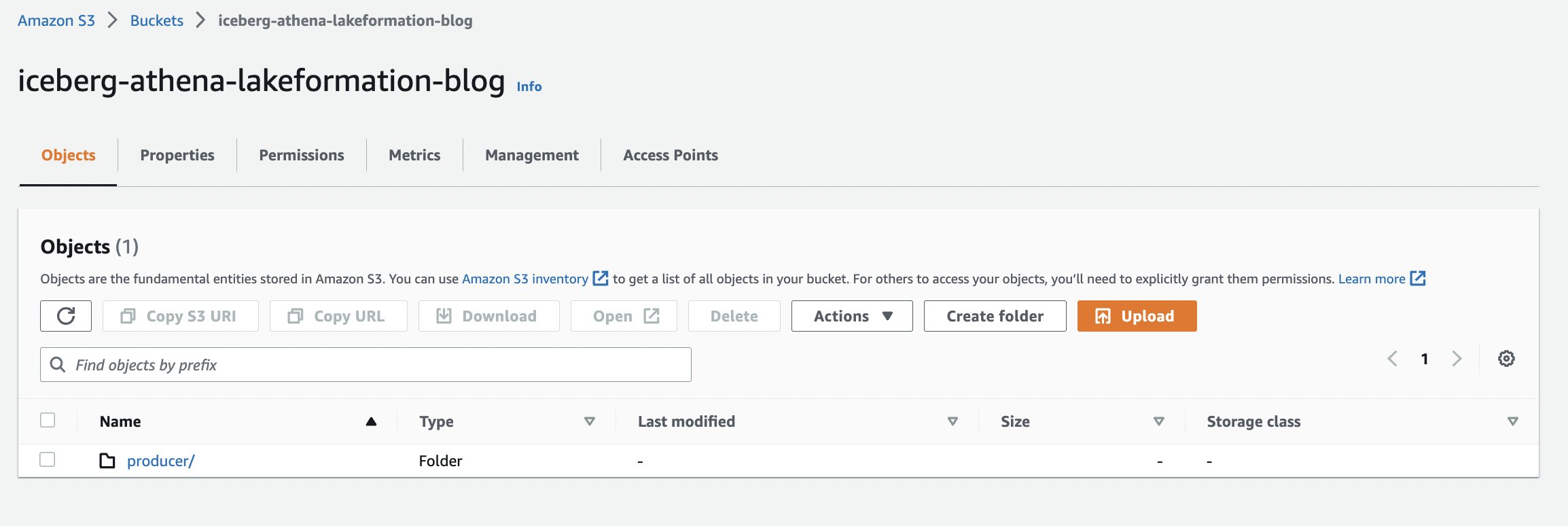
یک سطل S3 برای ذخیره داده های جدول ایجاد کنید
ما یک سطل S3 جدید برای ذخیره داده های جدول ایجاد می کنیم:
- در کنسول آمازون S3، یک سطل S3 ایجاد کنید با نام منحصر به فرد (برای این پست، ما استفاده می کنیم
iceberg-athena-lakeformation-blog). - پوشه تولید کننده را در داخل سطل ایجاد کنید تا برای جدول استفاده کنید.
مسیر S3 ذخیره جدول را با استفاده از Lake Formation ثبت کنید
ما مسیر کامل S3 را در سازند دریاچه ثبت می کنیم:
- به کنسول Lake Formation بروید.
- اگر برای اولین بار است که وارد سیستم می شوید، از شما خواسته می شود که یک کاربر مدیریت ایجاد کنید.
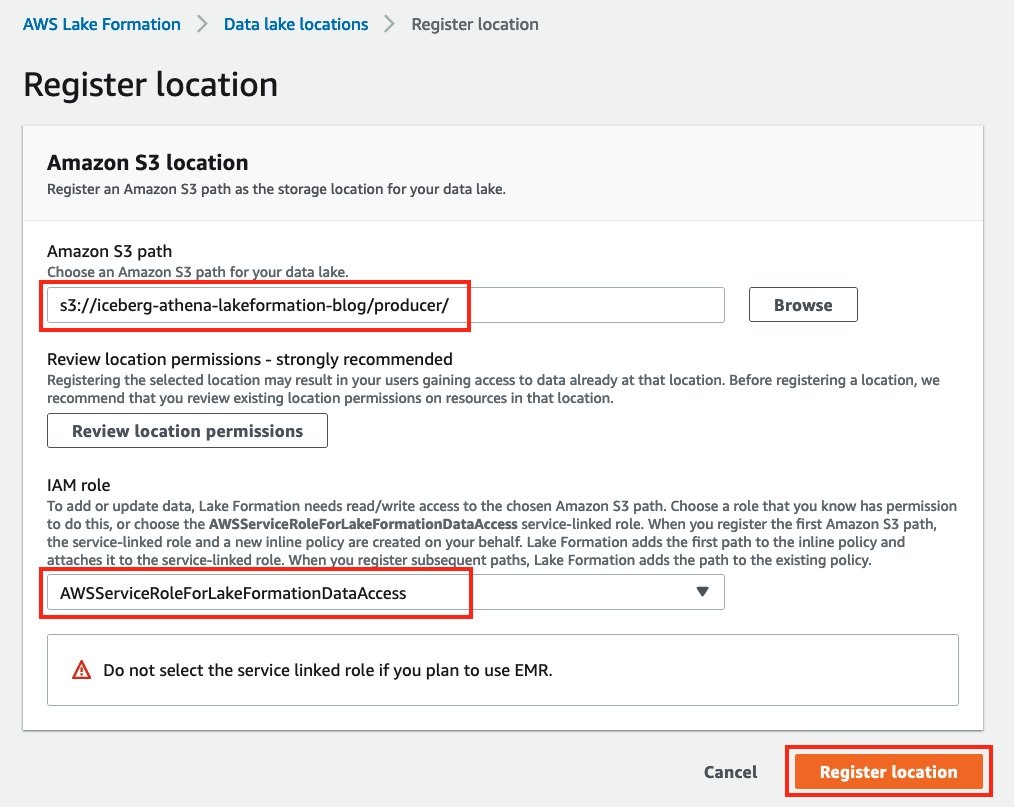
- در قسمت ناوبری، در زیر ثبت نام کنید و مصرف کنید، انتخاب کنید مکان های دریاچه داده.
- را انتخاب کنید ثبت مکانو مسیر سطل S3 را که قبلا ایجاد کرده بودید ارائه دهید.
- را انتخاب کنید
AWSServiceRoleForLakeFormationDataAccessبرای نقش IAM.
برای اطلاعات بیشتر در مورد نقش ها، مراجعه کنید الزامات نقش های مورد استفاده برای ثبت مکان ها.
اگر رمزگذاری سطل S3 خود را فعال کرده اید، باید مجوزهایی را برای Lake Formation برای انجام عملیات رمزگذاری و رمزگشایی فراهم کنید. رجوع شود به ثبت مکان رمزگذاری شده آمازون S3 برای راهنمایی
- را انتخاب کنید ثبت مکان.
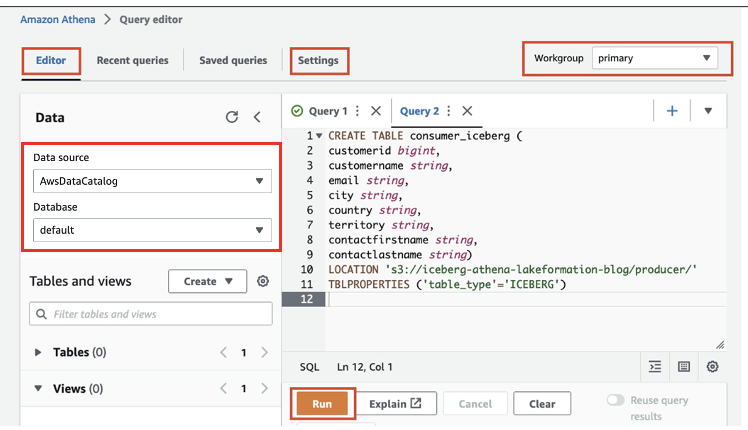
با استفاده از آتنا یک جدول کوه یخ بسازید
حالا بیایید جدول را با استفاده از Athena با فرمت Apache Iceberg ایجاد کنیم:
- در کنسول آتنا، انتخاب کنید Query-Editor در صفحه ناوبری
- اگر برای اولین بار از آتنا استفاده می کنید، زیر تنظیمات، انتخاب کنید مدیریت و محل سطل S3 را که قبلا ایجاد کرده اید وارد کنید (
iceberg-athena-lakeformation-blog/producer). - را انتخاب کنید ذخیره.
- در ویرایشگر پرس و جو، عبارت زیر را وارد کنید (مکانی را با سطل S3 که با Lake Formation ثبت کرده اید جایگزین کنید). توجه داشته باشید که ما از پایگاه داده پیش فرض استفاده می کنیم، اما شما می توانید از هر پایگاه داده دیگری استفاده کنید.
- را انتخاب کنید دویدن.
جدول را با حساب مصرف کننده به اشتراک بگذارید
برای نشان دادن عملکرد، سناریوهای زیر را اجرا می کنیم:
- دسترسی به ستون های انتخابی را فراهم کنید
- دسترسی به ردیف های انتخابی را بر اساس فیلتر فراهم کنید
مراحل زیر را انجام دهید:
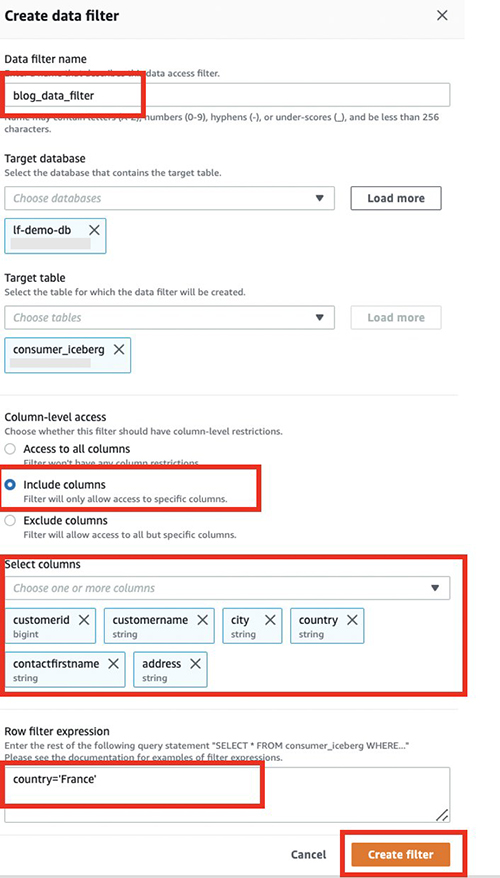
- در کنسول Lake Formation، در قسمت ناوبری زیر کاتالوگ داده، انتخاب کنید فیلترهای داده.
- را انتخاب کنید فیلتر جدید ایجاد کنید.
- برای نام فیلتر داده، وارد
blog_data_filter. - برای پایگاه داده هدف، وارد
lf-demo-db. - برای جدول هدف، وارد
consumer_iceberg. - برای دسترسی در سطح ستون، انتخاب کنید شامل ستون ها.
- ستون هایی را برای اشتراک گذاری با مصرف کننده انتخاب کنید:
country, address, contactfirstname, city, customerid,وcustomername. - برای عبارت فیلتر ردیفی، وارد فیلتر شوید
country='France'. - را انتخاب کنید فیلتر ایجاد کنید.
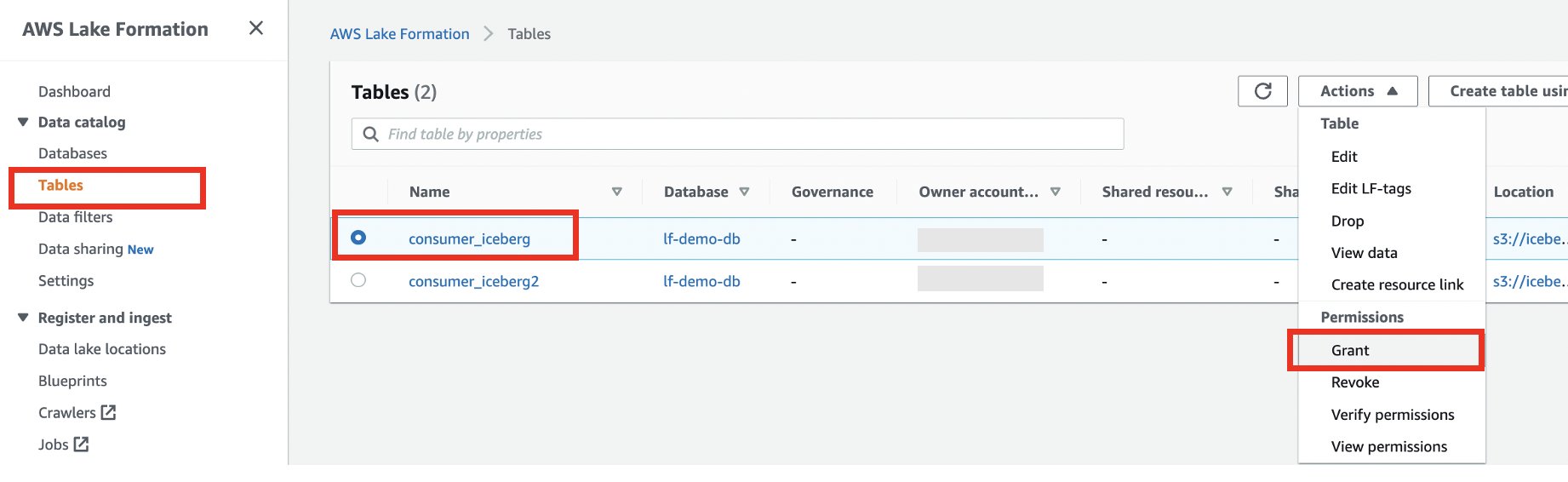
اکنون اجازه دهید دسترسی به حساب مصرف کننده در consumer_iceberg جدول.
- در صفحه پیمایش، را انتخاب کنید جداول.
- جدول customers_iceberg را انتخاب کرده و انتخاب کنید گرانت در اعمال منو.
- انتخاب کنید حساب های خارجی.
- شناسه حساب خارجی را وارد کنید.
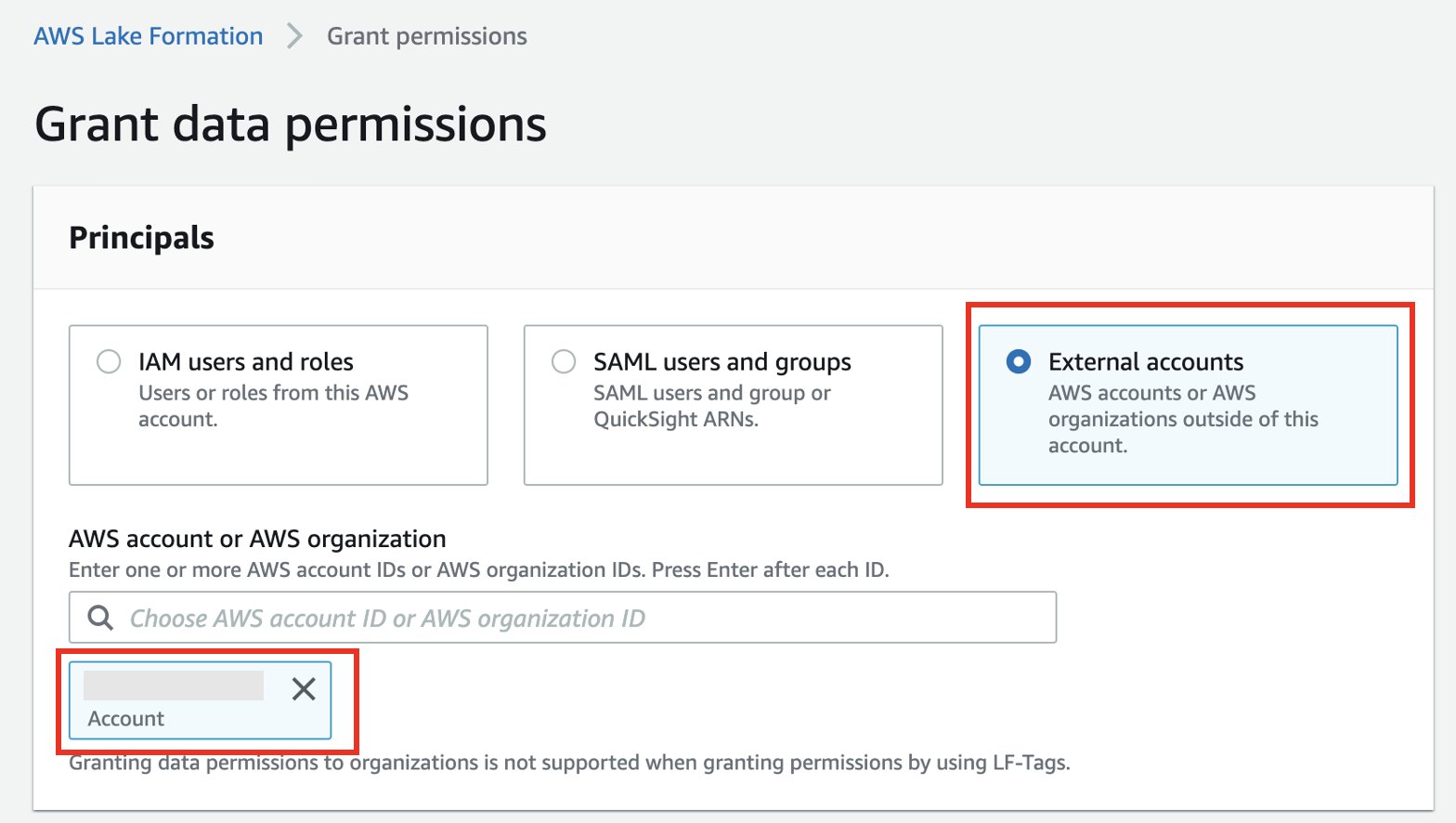
- انتخاب کنید منابع کاتالوگ داده نامگذاری شده.
- پایگاه داده و جدول خود را انتخاب کنید.
- برای فیلترهای داده، فیلتر داده ای را که ایجاد کرده اید انتخاب کنید.
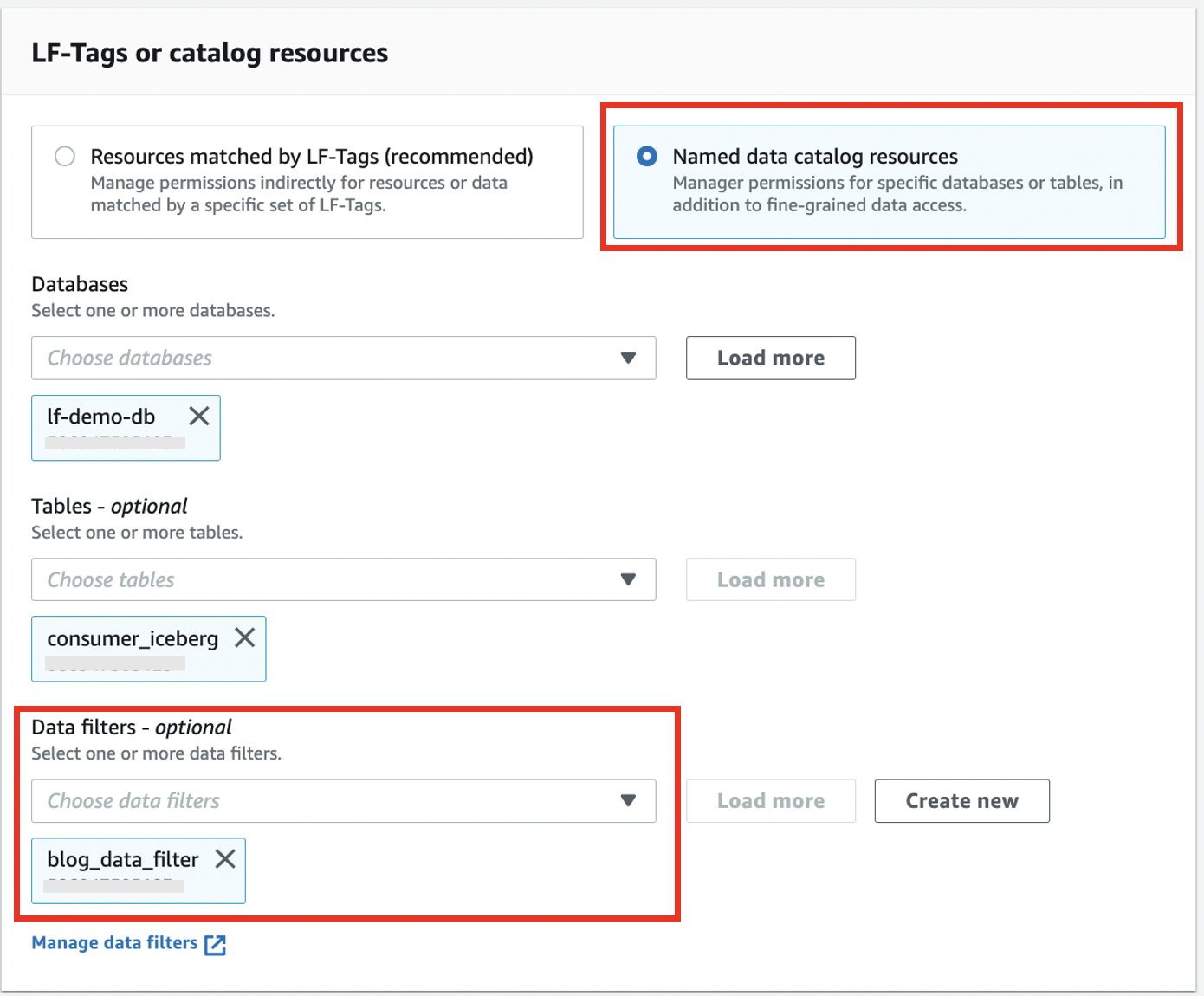
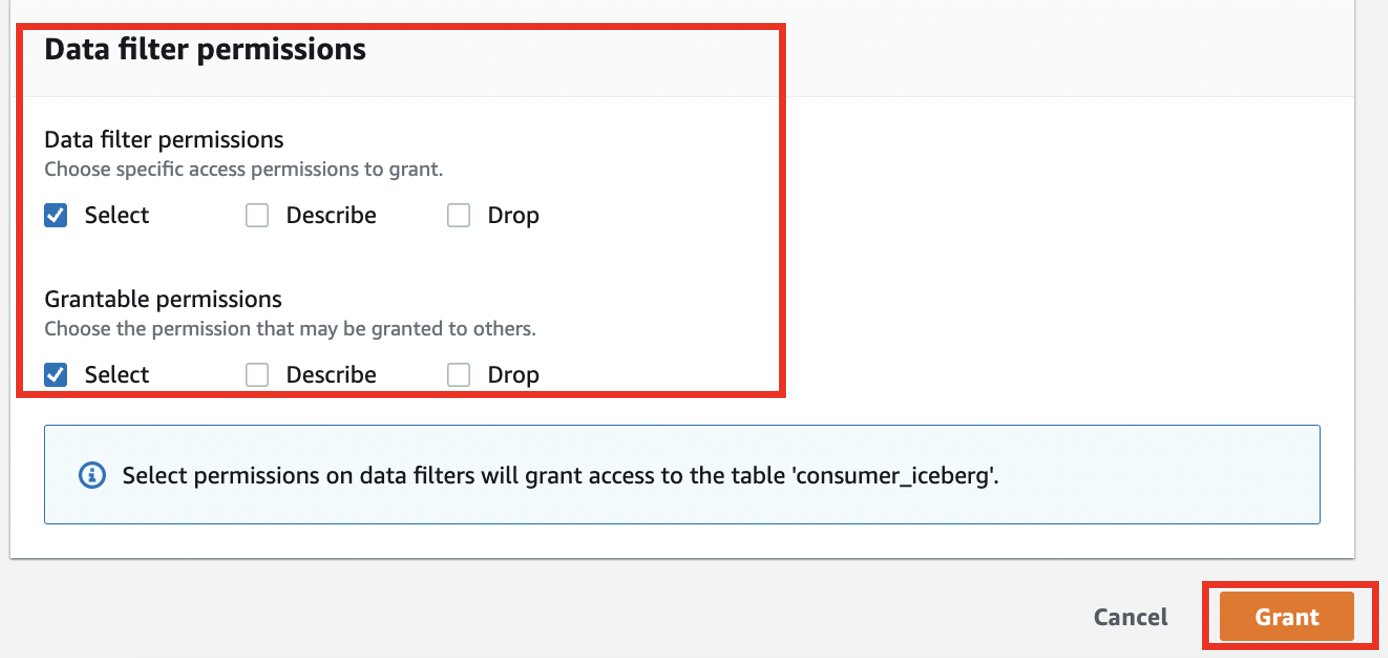
- برای مجوزهای فیلتر داده و مجوزهای قابل اعطا، انتخاب کنید انتخاب کنید.
- را انتخاب کنید گرانت.
تنظیم مصرف کننده داده
برای راهاندازی مصرفکننده داده، سهم منابع را میپذیریم و جدولی را با استفاده از RAM AWS و Lake Formation ایجاد میکنیم. مراحل زیر را کامل کنید:
- به حساب مصرف کننده وارد شوید و به کنسول AWS RAM بروید.
- تحت به اشتراک گذاشته شده با من در قسمت ناوبری، را انتخاب کنید سهام منابع.
- سهم منابع خود را انتخاب کنید
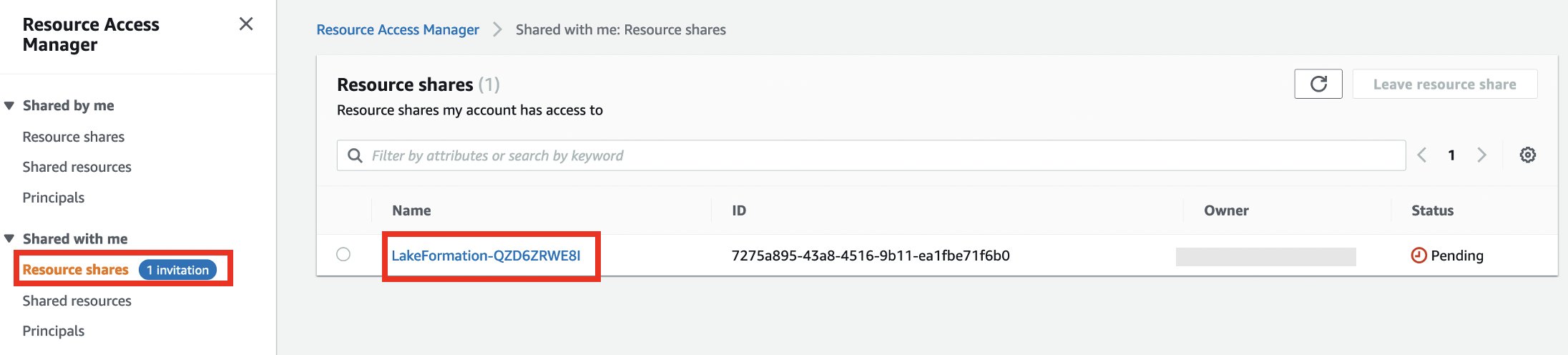
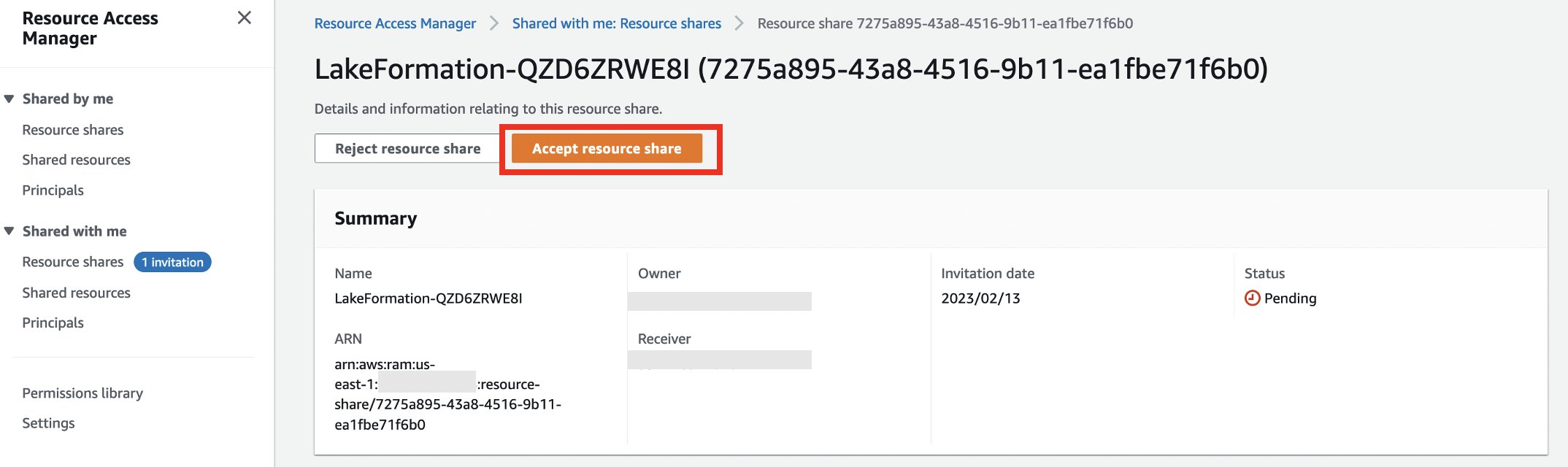
- را انتخاب کنید اشتراک منابع را بپذیرید.
- به نام اشتراک منبع برای استفاده در مراحل بعدی توجه کنید.
- به کنسول Lake Formation بروید.
- اگر برای اولین بار است که وارد سیستم می شوید، از شما خواسته می شود که یک کاربر مدیریت ایجاد کنید.
- را انتخاب کنید پایگاه داده ها در قسمت ناوبری، سپس پایگاه داده خود را انتخاب کنید.
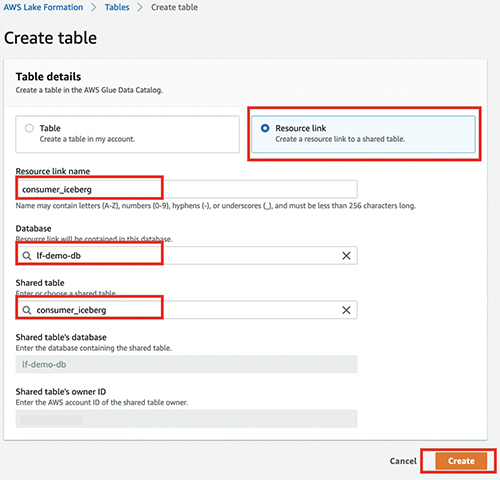
- بر اعمال منو ، انتخاب کنید ایجاد لینک منبع.

- برای نام لینک منبع، نام پیوند منبع خود را وارد کنید (به عنوان مثال،
consumer_iceberg). - پایگاه داده و جدول مشترک خود را انتخاب کنید.
- را انتخاب کنید ساختن.
راه حل را تأیید کنید
اکنون میتوانیم عملیاتهای مختلفی را روی جداول اجرا کنیم تا کنترلهای دسترسی دقیق را تأیید کنیم.
عملیات درج
بیایید داده ها را وارد کنید consumer_iceberg جدول را در حساب تولید کننده قرار دهید و عملکرد فیلتر داده را همانطور که در حساب مصرف کننده انتظار می رود تأیید کنید.
- وارد حساب تولید کننده شوید.
- در کنسول آتنا، انتخاب کنید Query-Editor در صفحه ناوبری
- برای نوشتن و درج داده ها در جدول Iceberg از SQL زیر استفاده کنید. از ویرایشگر Query برای اجرای یک پرس و جو در یک زمان استفاده کنید. میتوانید هر بار یک عبارت را برجسته/انتخاب کنید و روی «Run»/«Run again» کلیک کنید:

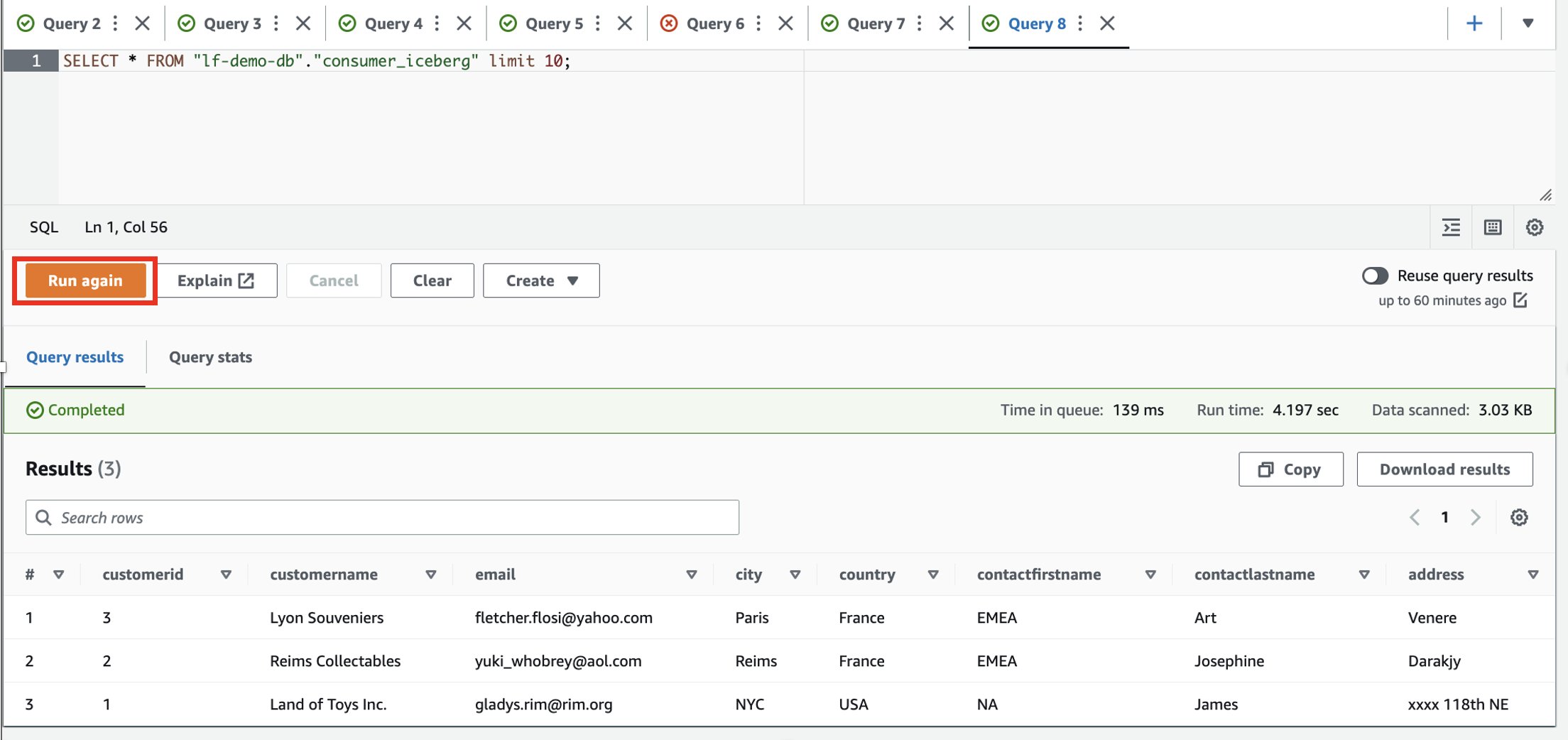
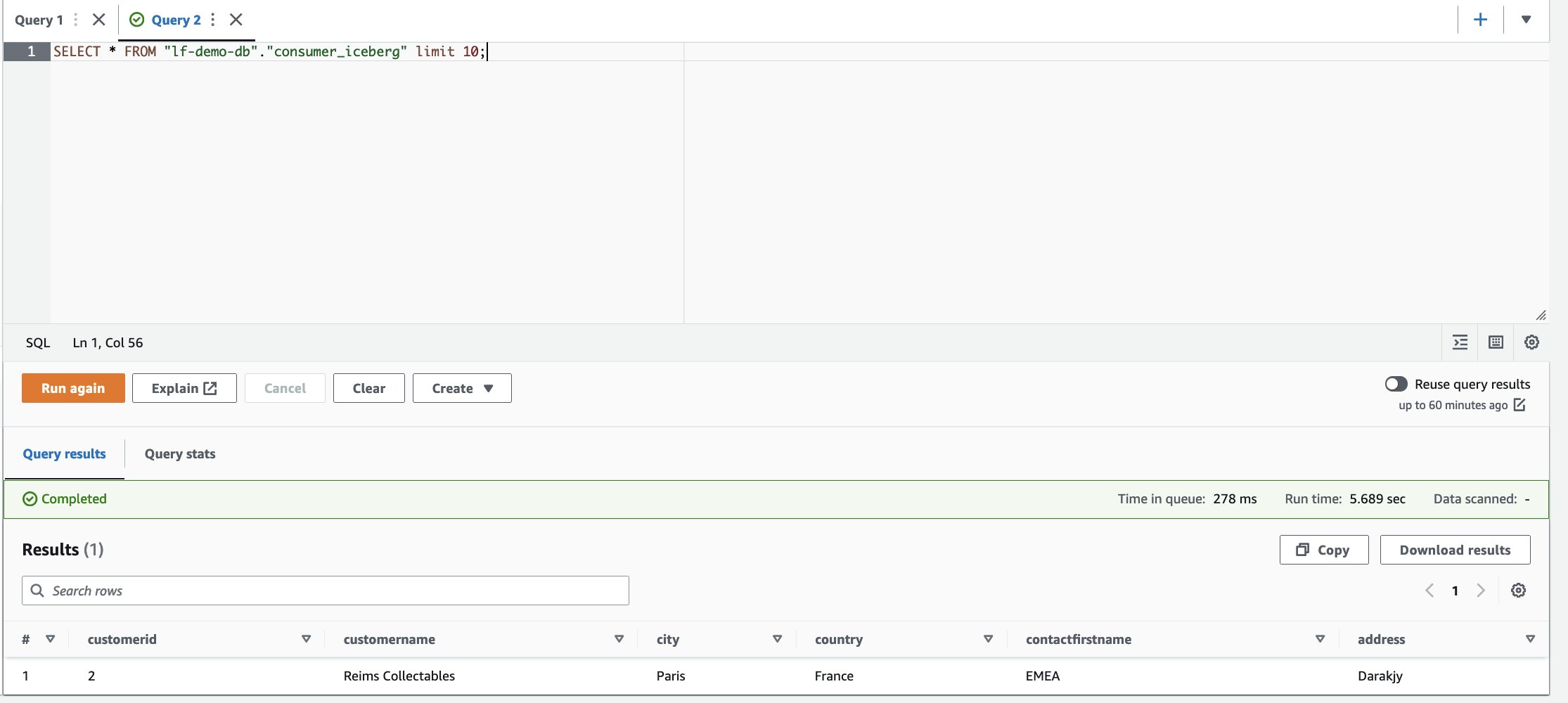
- برای خواندن و انتخاب داده ها در جدول Iceberg از SQL زیر استفاده کنید:
- وارد حساب کاربری مصرف کننده شوید.
- در ویرایشگر پرس و جو Athena، کوئری SELECT زیر را در جدول مشترک اجرا کنید:
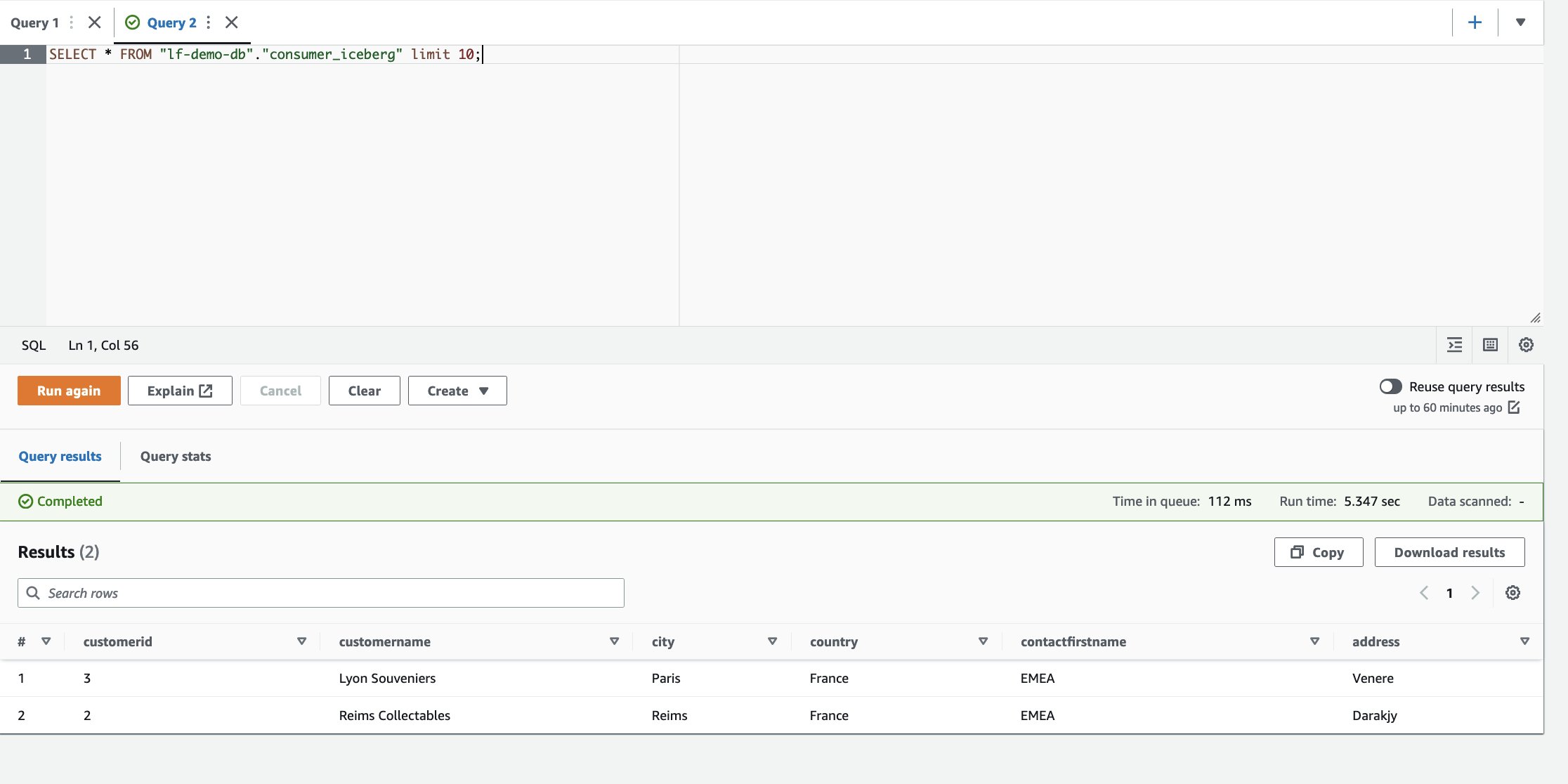
بر اساس فیلترها، مصرفکننده به زیرمجموعهای از ستونها و ردیفهایی که کشور فرانسه است، قابل مشاهده است.
عملیات به روز رسانی/حذف
حالا بیایید یکی از ردیف ها را به روز کنیم و یکی از مجموعه داده های به اشتراک گذاشته شده با مصرف کننده را حذف کنیم.
- وارد حساب تولید کننده شوید.
- بروزرسانی
city='Paris' WHERE city='Reims'و ردیف را حذف کنیدcustomerid = 3;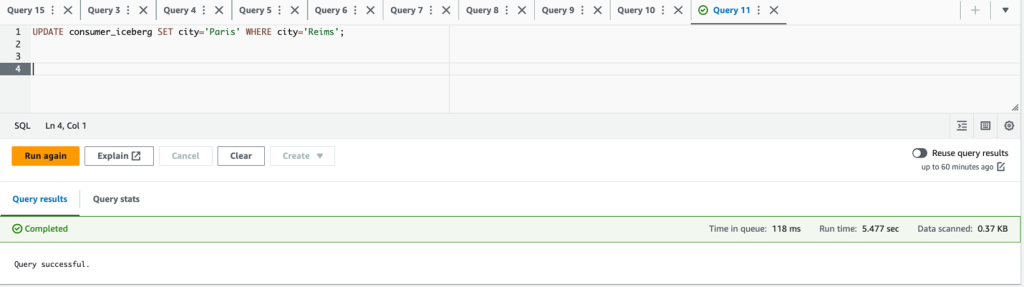

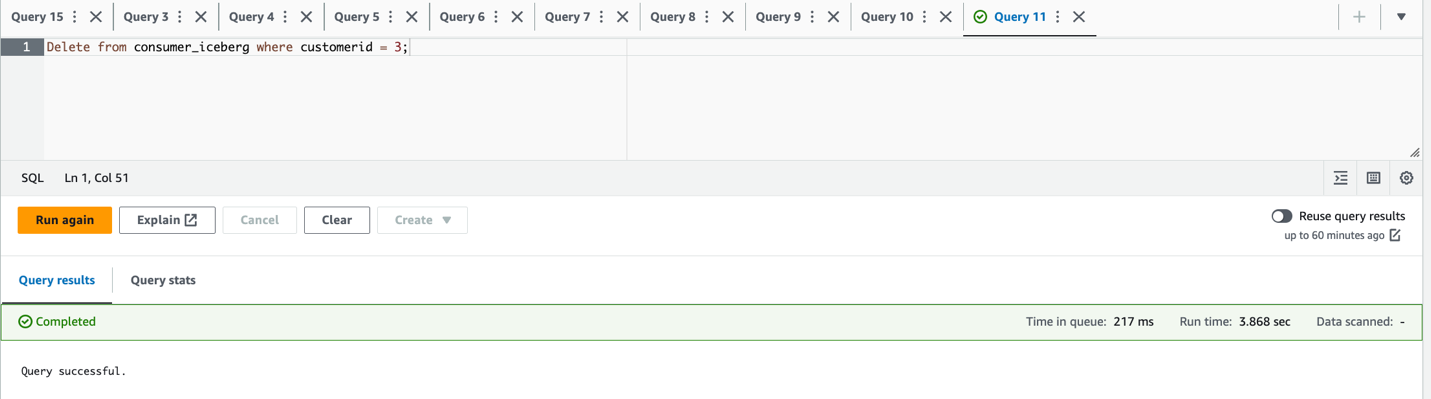
- مجموعه داده های به روز شده و حذف شده را تأیید کنید:
- وارد حساب کاربری مصرف کننده شوید.
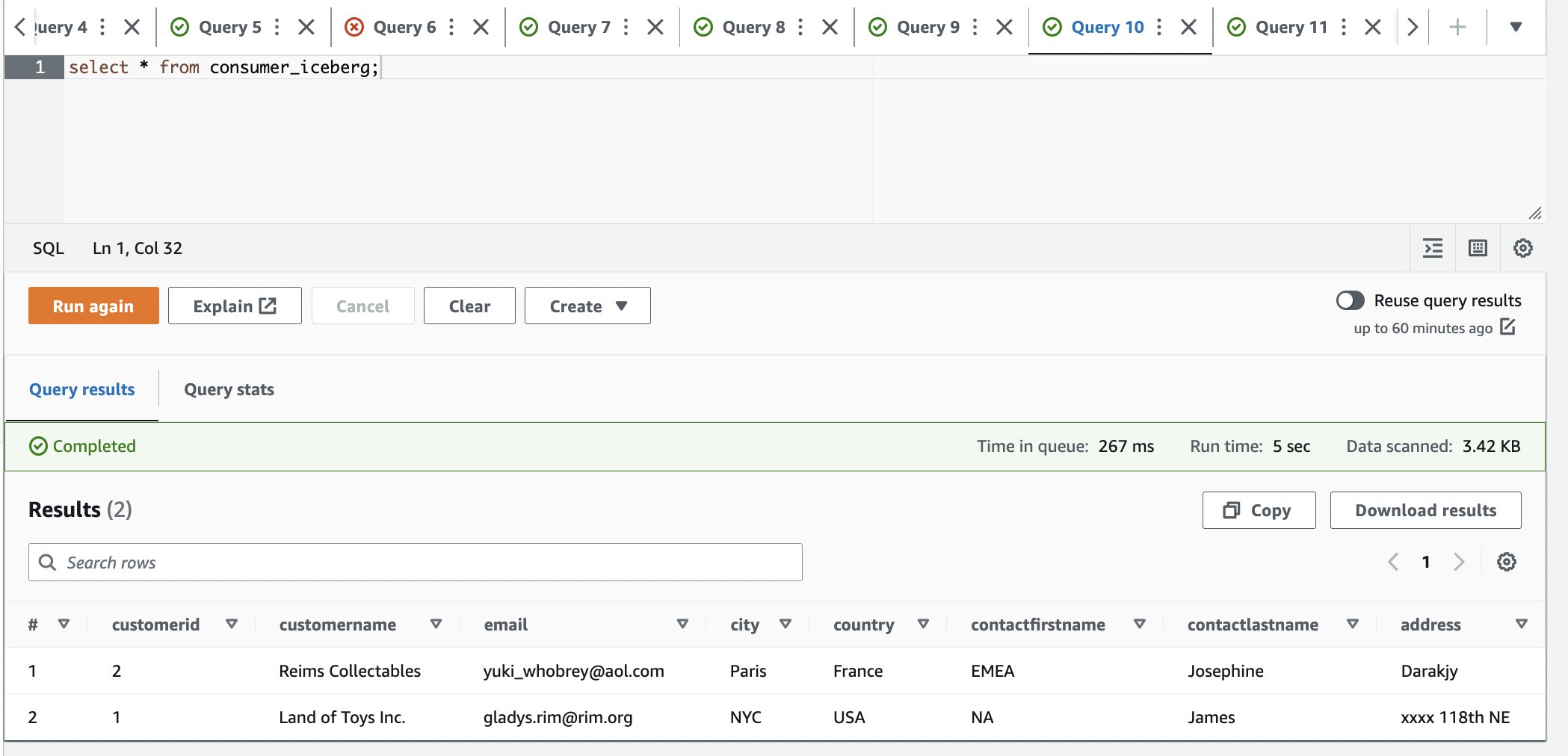
- در ویرایشگر پرس و جو Athena، کوئری SELECT زیر را در جدول مشترک اجرا کنید:
می توانیم مشاهده کنیم که فقط یک ردیف موجود است و شهر به پاریس به روز شده است.
تکامل طرحواره: یک ستون جدید اضافه کنید
بیایید یکی از ردیف ها را به روز کنیم و یکی را از مجموعه داده به اشتراک گذاشته شده با مصرف کننده حذف کنیم.
- وارد حساب تولید کننده شوید.
- یک ستون جدید به نام اضافه کنید
geo_locدر جدول کوه یخ از ویرایشگر Query برای اجرای یک پرس و جو در یک زمان استفاده کنید. میتوانید هر بار یک عبارت را برجسته/انتخاب کنید و روی «Run»/«Run again» کلیک کنید:
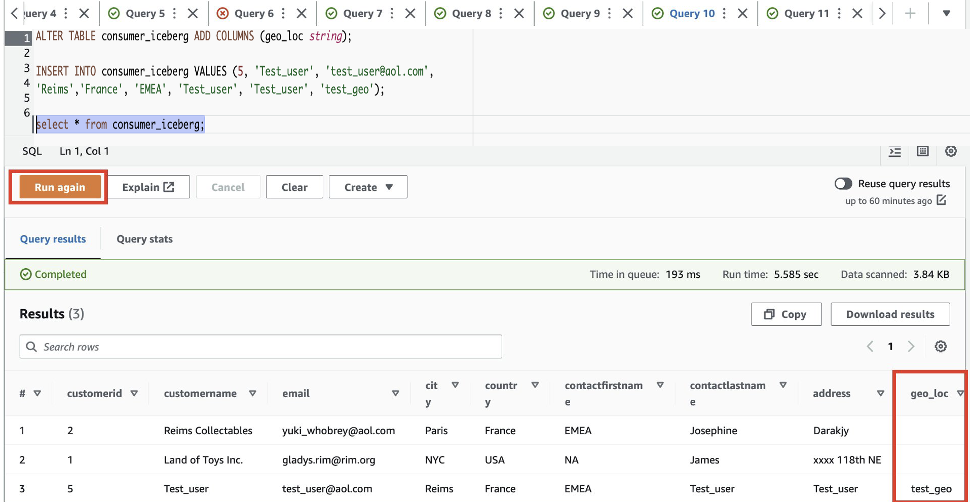
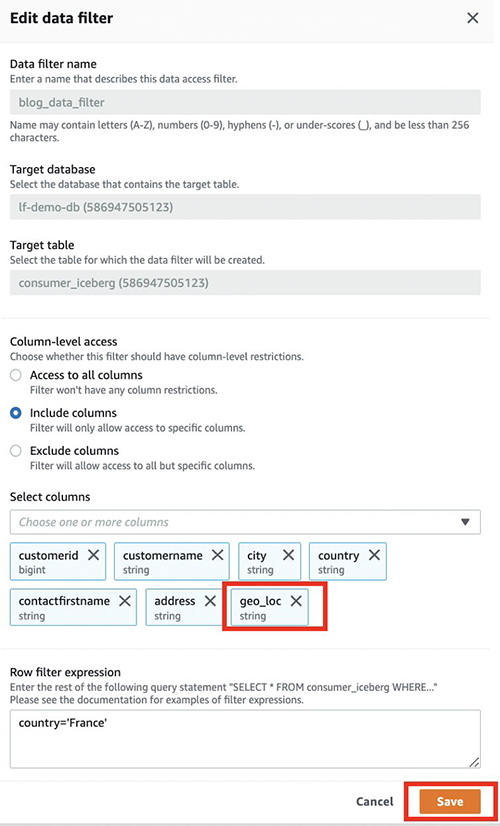
برای ارائه دید به موارد جدید اضافه شده geo_loc ستون، ما باید فیلتر داده Lake Formation را به روز کنیم.
- در کنسول Lake Formation، را انتخاب کنید فیلترهای داده در صفحه ناوبری
- فیلتر داده خود را انتخاب کنید و انتخاب کنید ویرایش.

- تحت دسترسی در سطح ستون، ستون جدید را اضافه کنید (
geo_loc). - را انتخاب کنید ذخیره.
- وارد حساب کاربری مصرف کننده شوید.
- در ویرایشگر پرس و جو Athena، موارد زیر را اجرا کنید
SELECTپرس و جو در جدول مشترک:
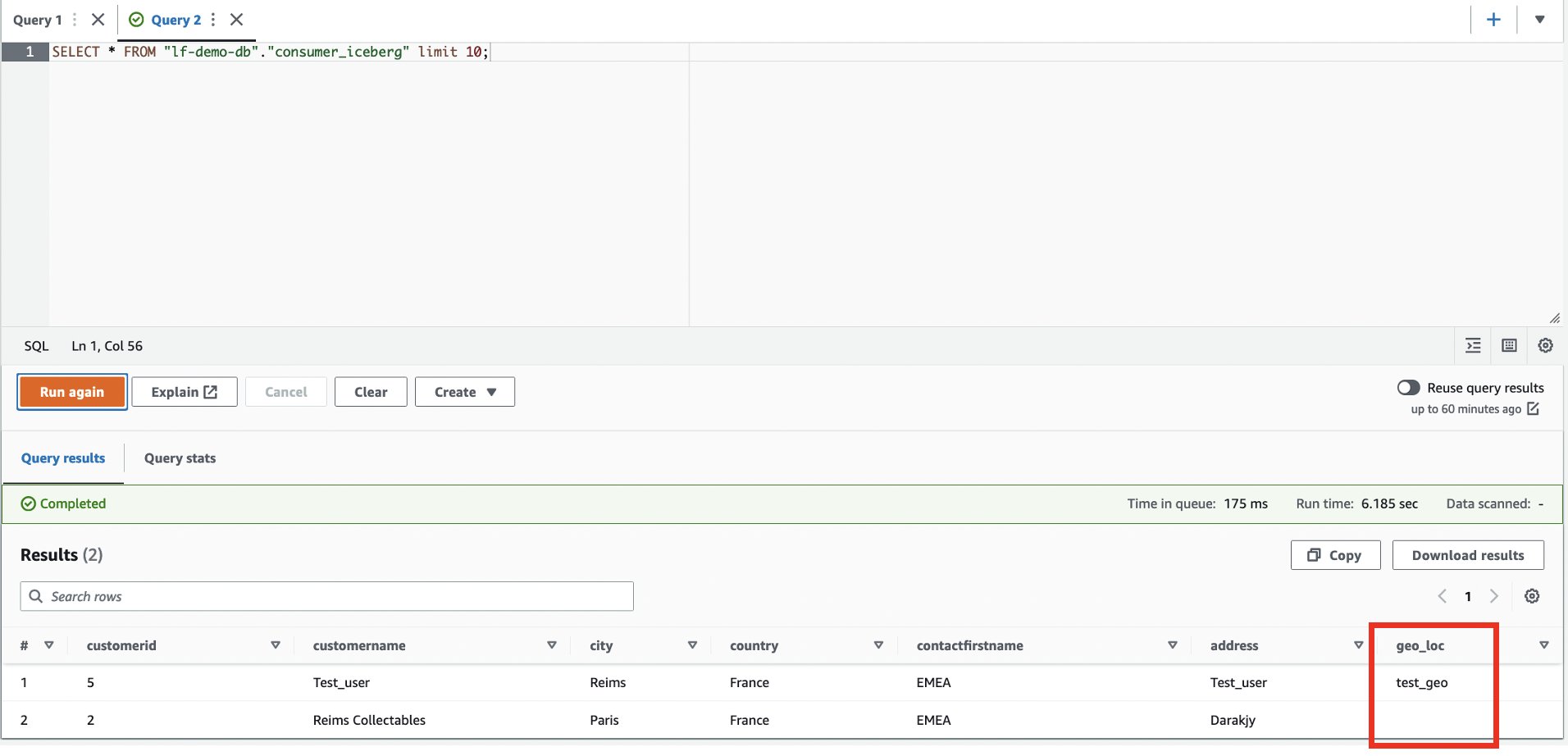
ستون جدید geo_loc قابل مشاهده است و یک ردیف اضافی.
تکامل طرحواره: حذف ستون
بیایید یکی از ردیف ها را به روز کنیم و یکی را از مجموعه داده به اشتراک گذاشته شده با مصرف کننده حذف کنیم.
- وارد حساب تولید کننده شوید.
- جدول را تغییر دهید تا ستون آدرس از جدول Iceberg حذف شود. از ویرایشگر Query برای اجرای یک پرس و جو در یک زمان استفاده کنید. میتوانید هر بار یک عبارت را برجسته/انتخاب کنید و روی «Run»/«Run again» کلیک کنید:

مشاهده می کنیم که آدرس ستون در جدول وجود ندارد.
- وارد حساب کاربری مصرف کننده شوید.
- در ویرایشگر پرس و جو Athena، کوئری SELECT زیر را در جدول مشترک اجرا کنید:
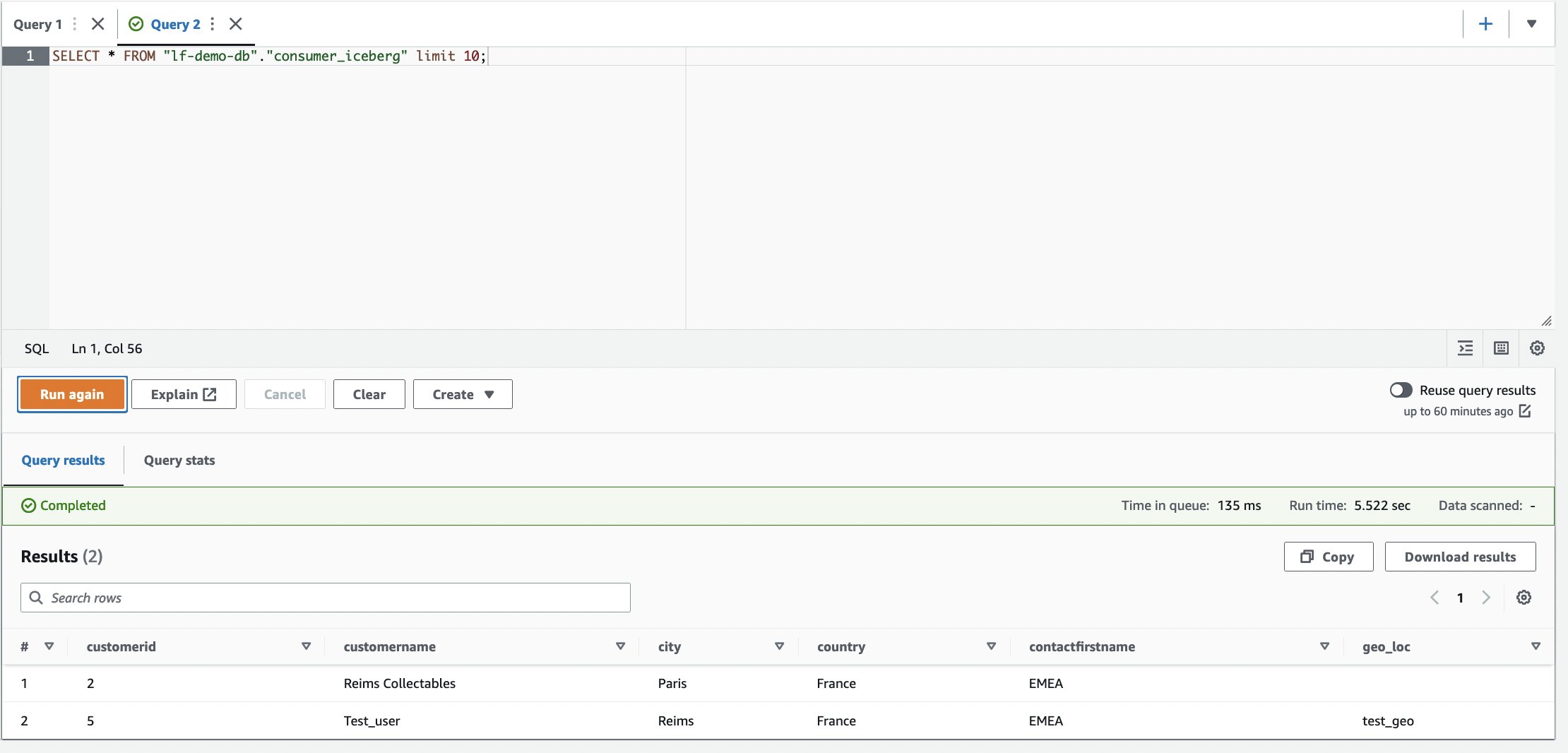
آدرس ستون در جدول وجود ندارد.
سفر زماني
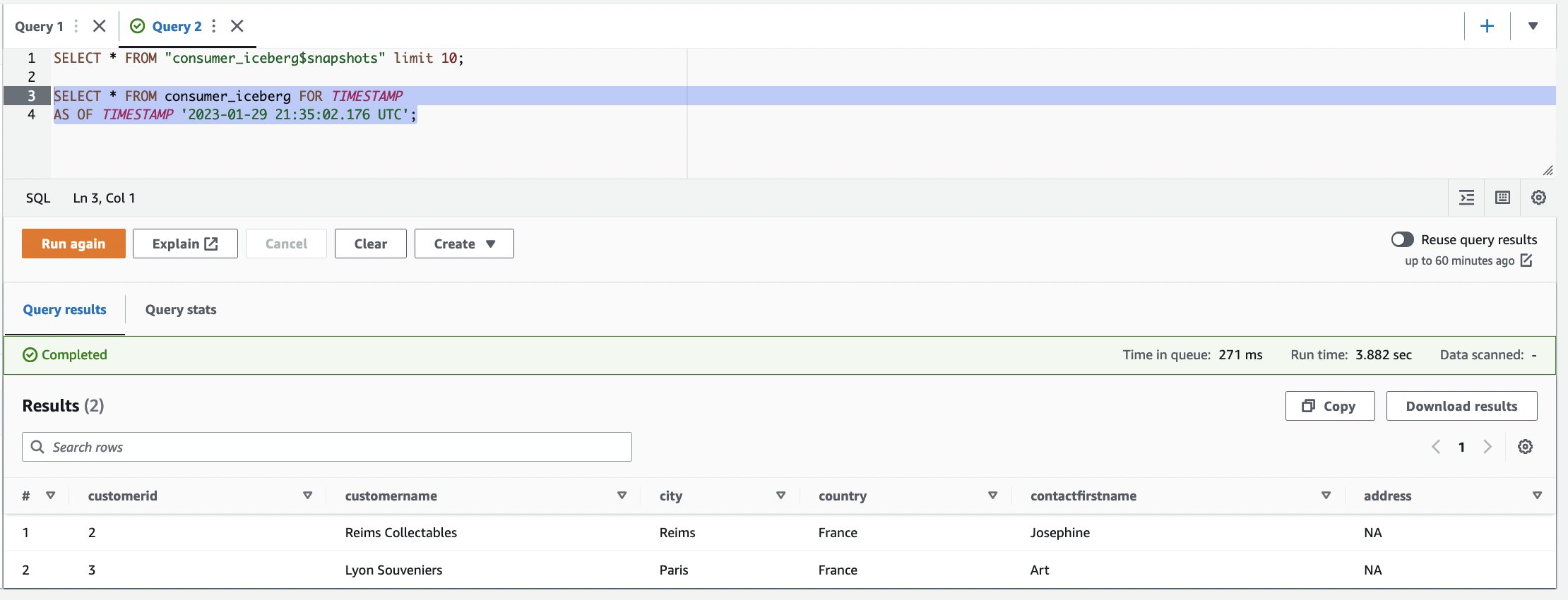
ما اکنون میز کوه یخ را چندین بار تغییر داده ایم. میز کوه یخ عکس های فوری را پیگیری می کند. مراحل زیر را برای بررسی عملکرد سفر در زمان کامل کنید:
- وارد حساب تولید کننده شوید.
- پرس و جو از جدول سیستم:
ما می توانیم مشاهده کنیم که چندین عکس فوری ایجاد کرده ایم.
- یکی از موارد را یادداشت کنید
committed_atمقادیر مورد استفاده در مراحل بعدی (برای مثال،2023-01-29 21:35:02.176 UTC).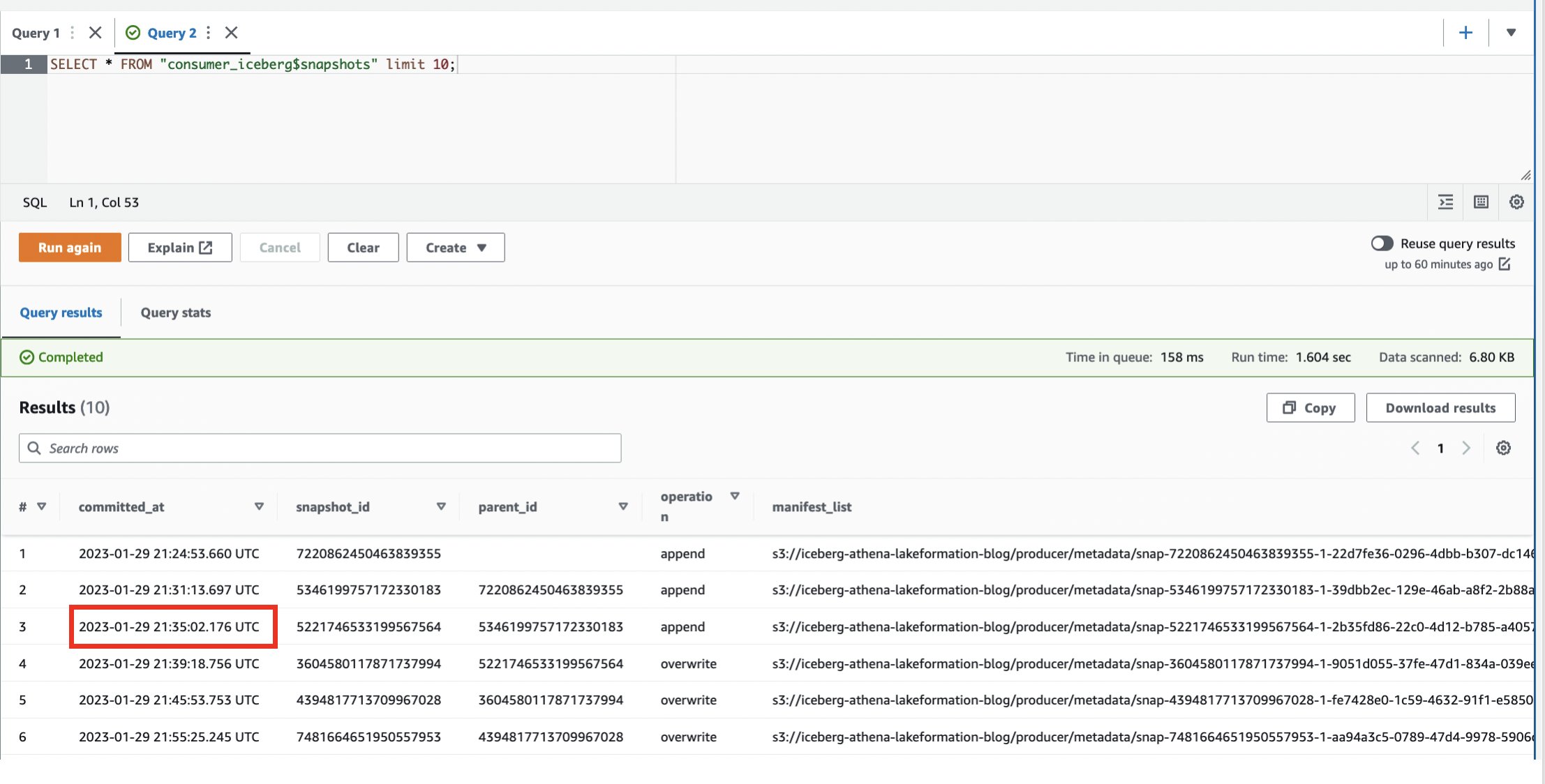
- از سفر در زمان برای یافتن عکس فوری جدول استفاده کنید. از ویرایشگر Query برای اجرای یک پرس و جو در یک زمان استفاده کنید. میتوانید هر بار یک عبارت را برجسته/انتخاب کنید و روی «Run»/«Run again» کلیک کنید:
پاک کردن
برای جلوگیری از تحمیل هزینه در آینده مراحل زیر را انجام دهید:
- در کنسول آمازون S3، سطل ذخیره سازی جدول را حذف کنید (برای این پست، iceberg-athena-lakeformation-blog).
- در حساب تولید کننده در کنسول آتنا، دستورات زیر را برای حذف جداولی که ایجاد کرده اید اجرا کنید:
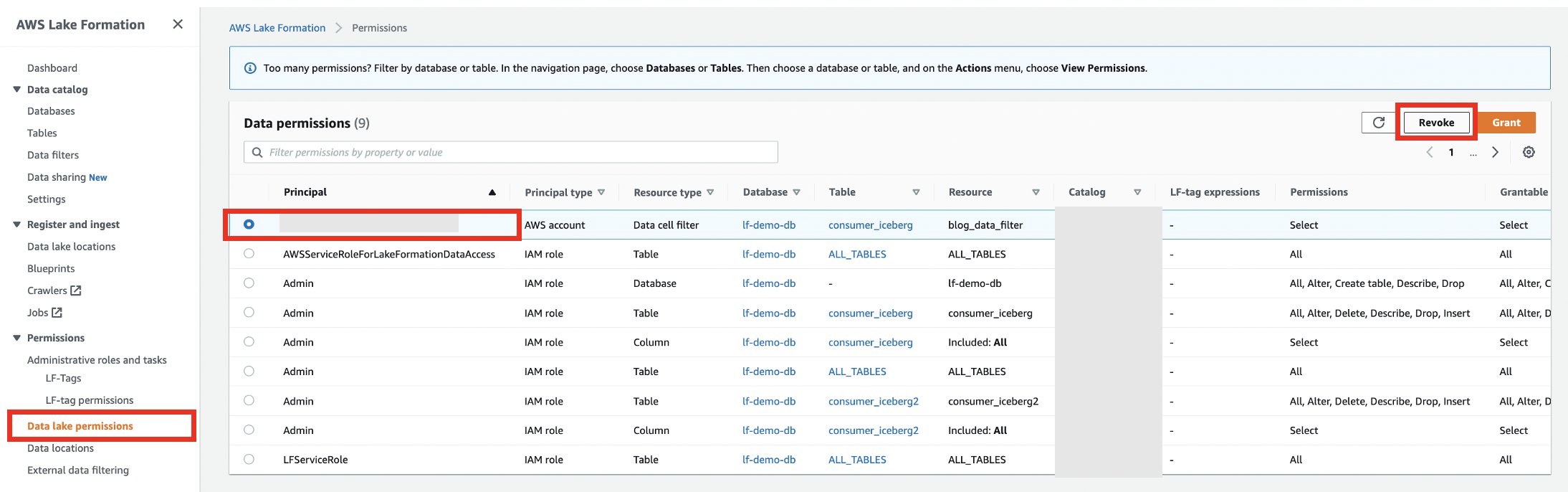
- در حساب تولیدکننده در کنسول Lake Formation، مجوزهای حساب مصرف کننده را لغو کنید.
- سطل S3 مورد استفاده برای مکان نتیجه جستجوی Athena را از حساب مصرف کننده حذف کنید.
نتیجه
با پشتیبانی از خطمشیهای کنترل دسترسی دقیق و متقاطع برای فرمتهایی مانند Iceberg، انعطافپذیری لازم برای کار با هر قالبی که توسط Athena پشتیبانی میشود را دارید. توانایی انجام عملیات CRUD در برابر دادههای موجود در دریاچه داده S3 شما همراه با کنترلهای دسترسی ریزدانه Lake Formation برای همه جداول و فرمتهای پشتیبانی شده توسط Athena فرصتهایی را برای نوآوری و سادهسازی استراتژی داده شما فراهم میکند. ما دوست داریم نظرات شما را بشنویم!
درباره نویسندگان
 کیشور داموداران یک معمار ارشد راه حل در AWS است. کیشور به مشتریان استراتژیک در استراتژی سازمانی ابری و سفر مهاجرت کمک می کند و از سال ها تجربه صنعت و ابر خود استفاده می کند.
کیشور داموداران یک معمار ارشد راه حل در AWS است. کیشور به مشتریان استراتژیک در استراتژی سازمانی ابری و سفر مهاجرت کمک می کند و از سال ها تجربه صنعت و ابر خود استفاده می کند.
 جک یه مهندس نرم افزار تیم دریاچه داده و ذخیره سازی Athena در AWS است. او یکی از اعضای Apache Iceberg Committer و عضو PMC است.
جک یه مهندس نرم افزار تیم دریاچه داده و ذخیره سازی Athena در AWS است. او یکی از اعضای Apache Iceberg Committer و عضو PMC است.
 کریس اولسون مهندس توسعه نرم افزار در AWS است.
کریس اولسون مهندس توسعه نرم افزار در AWS است.
 Xiaoxuan Li مهندس توسعه نرم افزار در AWS است.
Xiaoxuan Li مهندس توسعه نرم افزار در AWS است.
 راهول سوناوان یک معمار اصلی راه حل های تجزیه و تحلیل در AWS با AI/ML و Analytics به عنوان حوزه تخصصی او است.
راهول سوناوان یک معمار اصلی راه حل های تجزیه و تحلیل در AWS با AI/ML و Analytics به عنوان حوزه تخصصی او است.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- پلاتوبلاک چین. Web3 Metaverse Intelligence. دانش تقویت شده دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/big-data/interact-with-apache-iceberg-tables-using-amazon-athena-and-cross-account-fine-grained-permissions-using-aws-lake-formation/
- :است
- $UP
- 1
- 10
- 100
- 7
- a
- توانایی
- درباره ما
- پذیرفتن
- دسترسی
- حساب
- در میان
- اضافه
- اضافی
- اطلاعات اضافی
- نشانی
- مدیر سایت
- به تصویب رسید
- در برابر
- AI / ML
- معرفی
- اجازه می دهد تا
- آمازون
- آمازون آتنا
- علم تجزیه و تحلیل
- و
- آپاچی
- معماری
- هستند
- محدوده
- هنر
- AS
- At
- مجوز
- در دسترس
- اجتناب از
- AWS
- سازند دریاچه AWS
- حمایت کرد
- مستقر
- میان
- کسب و کار
- کسب و کار
- by
- نام
- CAN
- کاتالوگ
- متمرکز
- معین
- تغییر دادن
- بار
- را انتخاب کنید
- شهر:
- کلیک
- ابر
- ستون
- ستون ها
- COM
- ترکیب شده
- کامل
- اجزاء
- کنسول
- مصرف کننده
- کنترل
- گروه شاهد
- کشور
- ایجاد
- ایجاد شده
- ایجاد
- ایجاد
- صلیب
- مشتریان
- داده ها
- دریاچه دریاچه
- به اشتراک گذاری داده ها
- استراتژی داده
- پایگاه داده
- تصمیم گیری
- عمیق
- شیرجه عمیق
- به طور پیش فرض
- پروژه
- مختلف
- بحث و تبادل نظر
- پایین
- قطره
- هر
- پیش از آن
- سردبیر
- پست الکترونیک
- EMEA
- فعال
- رمزگذاری
- رمزگذاری
- موتور
- مهندس
- وارد
- سرمایه گذاری
- اتر (ETH)
- تکامل
- مثال
- انتظار می رود
- تجربه
- اکتشاف
- خارجی
- پرونده
- فیلتر
- فیلتر
- فیلترها برای تصفیه آب
- پیدا کردن
- نام خانوادگی
- بار اول
- انعطاف پذیری
- پیروی
- برای
- قالب
- تشکیل
- چارچوب
- فرانسه
- از جانب
- کامل
- قابلیت
- آینده
- تولید
- دریافت کنید
- دادن
- حکومت
- اعطا کردن
- راهنمایی
- آیا
- داشتن
- شنیدن
- کمک می کند
- کندو
- HTML
- HTTP
- HTTPS
- ID
- انجام
- in
- شرکت
- صنعت
- اطلاعات
- نوآوری
- تعامل
- علاقه مند
- IT
- سفر
- JPG
- دریاچه
- زمین
- لایه
- یادگیری
- سطح
- بهره برداری
- محدود
- خطوط
- ارتباط دادن
- محل
- عشق
- لیون
- ساخت
- باعث می شود
- مدیریت
- عضو
- فهرست
- مهاجرت
- مدل
- بیش
- چندگانه
- نام
- هدایت
- جهت یابی
- نیاز
- جدید
- بعد
- نیویورک
- مشاهده کردن
- of
- on
- ONE
- باز کن
- داده های باز
- کار
- عملیات
- فرصت ها
- سازمان های
- دیگر
- قطعه
- پاریس
- مسیر
- انجام دادن
- مجوز
- افلاطون
- هوش داده افلاطون
- PlatoData
- سیاست
- پست
- در حال حاضر
- اصلی
- تهيه كننده
- ارائه
- فراهم می کند
- رم
- خواندن
- تازه
- منعکس شده
- ثبت نام
- ثبت نام
- جایگزین کردن
- نیاز
- منابع
- محدود کردن
- منحصر
- نتیجه
- نقش
- نقش
- ROW
- دویدن
- همان
- ذخیره
- سناریوها
- بخش
- انتخاب شد
- ارشد
- تنظیم
- اشتراک گذاری
- به اشتراک گذاشته شده
- اشتراک
- ساده کردن
- عکس فوری
- نرم افزار
- توسعه نرم افزار
- مهندس نرمافزار
- مزایا
- تخصص
- SQL
- آغاز شده
- مراحل
- ذخیره سازی
- opbevare
- ذخیره شده
- استراتژیک
- استراتژی
- رشته
- چنین
- پشتیبانی
- پشتیبانی
- سیستم
- جدول
- تیم
- که
- La
- شان
- اینها
- زمان
- سفر در زمان
- بار
- برچسب زمان
- به
- مسیر
- سفر
- زیر
- منحصر به فرد
- بروزرسانی
- به روز شده
- ارتقاء
- ایالات متحده
- استفاده کنید
- کاربر
- ساعت محلی UTC تنظیم شده اند
- تصدیق
- ارزشها
- بررسی
- نسخه
- دید
- قابل رویت
- بازدید
- با
- مهاجرت کاری
- با این نسخهها کار
- نوشتن
- سال
- شما
- زفیرنت