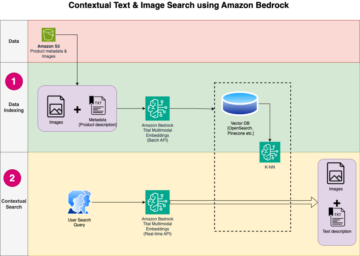
آمازون SageMaker مجموعه ای از الگوریتم های داخلی, مدل های از پیش آموزش دیدهو الگوهای راه حل از پیش ساخته شده برای کمک به دانشمندان داده و متخصصان یادگیری ماشین (ML) برای شروع آموزش و استقرار سریع مدلهای ML. شما می توانید از این الگوریتم ها و مدل ها برای یادگیری تحت نظارت و بدون نظارت استفاده کنید. آنها می توانند انواع مختلفی از داده های ورودی از جمله جدولی، تصویری و متنی را پردازش کنند.
از امروز، SageMaker چهار الگوریتم داخلی جدید مدلسازی دادههای جدولی را ارائه میکند: LightGBM، CatBoost، AutoGluon-Tabular، و TabTransformer. شما می توانید از این الگوریتم های محبوب و پیشرفته برای طبقه بندی جدولی و وظایف رگرسیون استفاده کنید. آنها از طریق در دسترس هستند الگوریتم های داخلی در کنسول SageMaker و همچنین از طریق Amazon SageMaker JumpStart UI داخل Amazon SageMaker Studio.
در زیر لیستی از چهار الگوریتم داخلی جدید به همراه پیوندهایی به مستندات، دفترچههای نمونه و منبع آنها آمده است.
| مستندات | نمونه دفترچه یادداشت | منبع |
| الگوریتم LightGBM | رگرسیون, طبقه بندی | LightGBM |
| الگوریتم CatBoost | رگرسیون, طبقه بندی | CatBoost |
| الگوریتم AutoGluon-Tabular | رگرسیون, طبقه بندی | AutoGluon-Tabular |
| الگوریتم TabTransformer | رگرسیون, طبقه بندی | تب ترانسفورماتور |
در بخشهای بعدی، توضیح فنی مختصری از هر الگوریتم و نمونههایی از نحوه آموزش یک مدل از طریق SageMaker SDK یا SageMaker Jumpstart ارائه میکنیم.
LightGBM
LightGBM یک پیادهسازی منبع باز محبوب و کارآمد از الگوریتم درخت تصمیم تقویت گرادیان (GBDT) است. GBDT یک الگوریتم یادگیری نظارت شده است که سعی می کند با ترکیب مجموعه ای از تخمین ها از مجموعه ای از مدل های ساده تر و ضعیف تر، یک متغیر هدف را به طور دقیق پیش بینی کند. LightGBM از تکنیک های اضافی برای بهبود قابل توجه کارایی و مقیاس پذیری GBDT معمولی استفاده می کند.
CatBoost
CatBoost یک پیاده سازی منبع باز محبوب و با کارایی بالا از الگوریتم GBDT است. دو پیشرفت الگوریتمی حیاتی در CatBoost معرفی شدهاند: اجرای تقویت سفارشی، جایگزینی مبتنی بر جایگشت برای الگوریتم کلاسیک، و یک الگوریتم نوآورانه برای پردازش ویژگیهای طبقهبندی. هر دو تکنیک برای مبارزه با یک تغییر پیشبینی ناشی از نوع خاصی از نشت هدف موجود در همه پیادهسازیهای فعلی الگوریتمهای تقویت گرادیان ایجاد شدند.
AutoGluon-Tabular
AutoGluon-Tabular یک پروژه AutoML منبع باز است که توسط آمازون توسعه و نگهداری می شود که پردازش داده های پیشرفته، یادگیری عمیق و مجموعه چند لایه پشته را انجام می دهد. به طور خودکار نوع داده را در هر ستون برای پیش پردازش قوی داده، از جمله مدیریت ویژه فیلدهای متنی، تشخیص می دهد. AutoGluon با مدلهای مختلف از درختان تقویتشده خارج از قفسه گرفته تا مدلهای شبکه عصبی سفارشیشده مطابقت دارد. این مدلها به شیوهای بدیع ترکیب میشوند: مدلها در چندین لایه روی هم چیده میشوند و به روشی لایهای آموزش داده میشوند که تضمین میکند دادههای خام را میتوان به پیشبینیهای با کیفیت بالا در یک محدودیت زمانی معین ترجمه کرد. تناسب بیش از حد در طول این فرآیند با تقسیم دادهها به روشهای مختلف با ردیابی دقیق نمونههای خارج از چین کاهش مییابد. AutoGluon برای عملکرد بهینه شده است، و استفاده خارج از جعبه آن چندین مقام برتر را در مسابقات علم داده به دست آورده است.
تب ترانسفورماتور
تب ترانسفورماتور یک معماری جدید مدلسازی دادههای جدولی عمیق برای یادگیری تحت نظارت است. TabTransformer بر اساس ترانسفورماتورهای مبتنی بر توجه خود ساخته شده است. لایههای ترانسفورماتور جاسازیهای ویژگیهای طبقهبندی را به جاسازیهای متنی قوی برای دستیابی به دقت پیشبینی بالاتر تبدیل میکنند. علاوه بر این، تعبیههای متنی آموختهشده از TabTransformer در برابر ویژگیهای دادههای مفقود و نویز بسیار قوی هستند و قابلیت تفسیر بهتری را ارائه میدهند. این مدل محصول اخیر است علم آمازون پژوهش (مقاله و رسمی پست های وبلاگ اینجا) و به طور گسترده توسط جامعه ML، با پیاده سازی های شخص ثالث مختلف (کراس, AutoGluon،) و ویژگی های رسانه های اجتماعی مانند توییت, به سمت علم داده، متوسط و کجگل.
مزایای الگوریتم های داخلی SageMaker
هنگام انتخاب یک الگوریتم برای نوع خاص مشکل و داده خود، استفاده از الگوریتم داخلی SageMaker ساده ترین گزینه است، زیرا انجام این کار مزایای عمده زیر را به همراه دارد:
- الگوریتمهای داخلی برای شروع آزمایشها نیازی به کدنویسی ندارند. تنها ورودی هایی که باید ارائه کنید داده ها، فراپارامترها و منابع محاسباتی است. این به شما امکان میدهد آزمایشها را سریعتر اجرا کنید، با هزینه کمتری برای ردیابی نتایج و تغییرات کد.
- الگوریتمهای داخلی همراه با موازیسازی در چندین نمونه محاسباتی و پشتیبانی از GPU برای همه الگوریتمهای قابل اجرا هستند (برخی از الگوریتمها ممکن است به دلیل محدودیتهای ذاتی گنجانده نشوند). اگر دادههای زیادی برای آموزش مدل خود دارید، اکثر الگوریتمهای داخلی میتوانند به راحتی برای پاسخگویی به تقاضا مقیاس شوند. حتی اگر از قبل یک مدل از پیش آموزش دیده داشته باشید، باز هم ممکن است استفاده از نتیجه آن در SageMaker و وارد کردن هایپرپارامترهایی که از قبل می شناسید آسان تر باشد تا اینکه آن را بر روی آن پورت کنید و خودتان یک اسکریپت آموزشی بنویسید.
- شما مالک مصنوعات مدل به دست آمده هستید. میتوانید آن مدل را بگیرید و آن را در SageMaker برای چندین الگوی استنتاج مختلف اجرا کنید (همه را بررسی کنید انواع استقرار موجود) و مقیاسبندی و مدیریت نقطه پایانی آسان، یا میتوانید آن را در هر کجا که به آن نیاز دارید مستقر کنید.
حال بیایید ببینیم که چگونه یکی از این الگوریتم های داخلی را آموزش دهیم.
با استفاده از SageMaker SDK یک الگوریتم داخلی را آموزش دهید
برای آموزش یک مدل انتخاب شده، باید URI آن مدل و همچنین اسکریپت آموزشی و تصویر ظرف مورد استفاده برای آموزش را دریافت کنیم. خوشبختانه، این سه ورودی صرفاً به نام مدل، نسخه بستگی دارد (برای لیستی از مدل های موجود، نگاه کنید به جدول مدل در دسترس JumpStart) و نوع نمونه ای که می خواهید روی آن آموزش دهید. این در قطعه کد زیر نشان داده شده است:
La train_model_id تغییرات lightgbm-regression-model اگر با مشکل رگرسیون روبرو هستیم. شناسه تمامی مدل های معرفی شده در این پست در جدول زیر آمده است.
| مدل | نوع مشکل | شناسه مدل |
| LightGBM | طبقه بندی | lightgbm-classification-model |
| . | رگرسیون | lightgbm-regression-model |
| CatBoost | طبقه بندی | catboost-classification-model |
| . | رگرسیون | catboost-regression-model |
| AutoGluon-Tabular | طبقه بندی | autogluon-classification-ensemble |
| . | رگرسیون | autogluon-regression-ensemble |
| تب ترانسفورماتور | طبقه بندی | pytorch-tabtransformerclassification-model |
| . | رگرسیون | pytorch-tabtransformerregression-model |
سپس مشخص می کنیم که ورودی ما در کجا قرار دارد سرویس ذخیره سازی ساده آمازون (Amazon S3). ما از یک مجموعه داده نمونه عمومی برای این مثال استفاده می کنیم. ما همچنین تعیین می کنیم که خروجی ما به کجا برسد، و لیست پیش فرض هایپرپارامترهای مورد نیاز برای آموزش مدل انتخاب شده را بازیابی می کنیم. شما می توانید ارزش آنها را به دلخواه تغییر دهید.
در نهایت، ما یک SageMaker را نمونهسازی میکنیم Estimator با تمام ورودی های بازیابی شده و کار آموزشی را با .fit، URI مجموعه داده آموزشی ما را ارسال می کنیم. در entry_point اسکریپت ارائه شده نامگذاری شده است transfer_learning.py (همانطور برای سایر وظایف و الگوریتم ها)، و کانال داده ورودی به آن منتقل می شود .fit باید نام برد training.
توجه داشته باشید که می توانید الگوریتم های داخلی را با آن آموزش دهید تنظیم خودکار مدل SageMaker برای انتخاب فراپارامترهای بهینه و بهبود بیشتر عملکرد مدل.
با استفاده از SageMaker JumpStart یک الگوریتم داخلی را آموزش دهید
همچنین میتوانید این الگوریتمهای داخلی را با چند کلیک از طریق SageMaker JumpStart UI آموزش دهید. JumpStart یک ویژگی SageMaker است که به شما امکان می دهد الگوریتم های داخلی و مدل های از پیش آموزش دیده را از چارچوب های مختلف ML و هاب مدل از طریق یک رابط گرافیکی آموزش و استقرار دهید. همچنین به شما امکان میدهد راهحلهای کاملاً پیشرفته ML را که مدلهای ML و سرویسهای مختلف AWS دیگر را برای حل یک مورد استفاده هدفمند با هم ترکیب میکنند، به کار بگیرید.
برای اطلاعات بیشتر به مراجعه کنید اجرای طبقه بندی متن با Amazon SageMaker JumpStart با استفاده از مدل های TensorFlow Hub و Hugging Face.
نتیجه
در این پست، ما از راه اندازی چهار الگوریتم داخلی قدرتمند جدید برای ML در مجموعه داده های جدولی خبر دادیم که اکنون در SageMaker موجود است. ما یک توضیح فنی از چیستی این الگوریتمها و همچنین یک نمونه کار آموزشی برای LightGBM با استفاده از SageMaker SDK ارائه کردیم.
مجموعه دادههای خود را بیاورید و این الگوریتمهای جدید را در SageMaker امتحان کنید، و برای استفاده از الگوریتمهای داخلی موجود، نمونههای نوتبوک را بررسی کنید. GitHub.
درباره نویسنده
![]() دکتر شین هوانگ یک دانشمند کاربردی برای آمازون SageMaker JumpStart و آمازون SageMaker الگوریتم های داخلی است. او بر روی توسعه الگوریتم های یادگیری ماشینی مقیاس پذیر تمرکز می کند. علایق تحقیقاتی او در زمینه پردازش زبان طبیعی، یادگیری عمیق قابل توضیح بر روی داده های جدولی و تجزیه و تحلیل قوی خوشه بندی ناپارامتریک فضا-زمان است. او مقالات زیادی را در کنفرانسهای ACL، ICDM، KDD و مجله Royal Statistical Society: Series A منتشر کرده است.
دکتر شین هوانگ یک دانشمند کاربردی برای آمازون SageMaker JumpStart و آمازون SageMaker الگوریتم های داخلی است. او بر روی توسعه الگوریتم های یادگیری ماشینی مقیاس پذیر تمرکز می کند. علایق تحقیقاتی او در زمینه پردازش زبان طبیعی، یادگیری عمیق قابل توضیح بر روی داده های جدولی و تجزیه و تحلیل قوی خوشه بندی ناپارامتریک فضا-زمان است. او مقالات زیادی را در کنفرانسهای ACL، ICDM، KDD و مجله Royal Statistical Society: Series A منتشر کرده است.
![]() دکتر آشیش ختان یک دانشمند کاربردی ارشد با آمازون SageMaker JumpStart و آمازون SageMaker الگوریتم های داخلی است و به توسعه الگوریتم های یادگیری ماشین کمک می کند. او یک محقق فعال در یادگیری ماشین و استنتاج آماری است و مقالات زیادی در کنفرانس های NeurIPS، ICML، ICLR، JMLR، ACL و EMNLP منتشر کرده است.
دکتر آشیش ختان یک دانشمند کاربردی ارشد با آمازون SageMaker JumpStart و آمازون SageMaker الگوریتم های داخلی است و به توسعه الگوریتم های یادگیری ماشین کمک می کند. او یک محقق فعال در یادگیری ماشین و استنتاج آماری است و مقالات زیادی در کنفرانس های NeurIPS، ICML، ICLR، JMLR، ACL و EMNLP منتشر کرده است.
 ژائو مورا یک معمار راه حل های تخصصی AI/ML در خدمات وب آمازون است. او بیشتر روی موارد استفاده NLP و کمک به مشتریان در بهینه سازی آموزش و استقرار مدل یادگیری عمیق متمرکز است. او همچنین یکی از حامیان فعال راه حل های ML با کد پایین و سخت افزار تخصصی ML است.
ژائو مورا یک معمار راه حل های تخصصی AI/ML در خدمات وب آمازون است. او بیشتر روی موارد استفاده NLP و کمک به مشتریان در بهینه سازی آموزش و استقرار مدل یادگیری عمیق متمرکز است. او همچنین یکی از حامیان فعال راه حل های ML با کد پایین و سخت افزار تخصصی ML است.
- Coinsmart. بهترین صرافی بیت کوین و کریپتو اروپا.
- پلاتوبلاک چین. Web3 Metaverse Intelligence. دانش تقویت شده دسترسی رایگان.
- CryptoHawk. رادار آلت کوین امتحان رایگان.
- منبع: https://aws.amazon.com/blogs/machine-learning/new-built-in-amazon-sagemaker-algorithms-for-tabular-data-modeling-lightgbm-catboost-autogluon-tabular-and-tabtransformer/
- "
- 100
- a
- رسیدن
- دست
- در میان
- فعال
- اضافی
- پیشرفته
- پیشرفت
- در برابر
- الگوریتم
- الگوریتمی
- الگوریتم
- معرفی
- اجازه می دهد تا
- قبلا
- جایگزین
- آمازون
- آمازون خدمات وب
- تحلیل
- اعلام کرد
- مربوط
- اعمال می شود
- معماری
- محدوده
- اتوماتیک
- بطور خودکار
- در دسترس
- AWS
- زیرا
- مزایای
- بهتر
- تقویت شده
- تقویت
- جعبه
- ساخته شده در
- دقیق
- مورد
- ایجاد می شود
- تغییر دادن
- کلاسیک
- طبقه بندی
- رمز
- برنامه نویسی
- ستون
- بیا
- انجمن
- مسابقات
- محاسبه
- همایش ها
- کنسول
- ظرف
- ایجاد
- ایجاد شده
- بحرانی
- در حال حاضر
- سفارشی
- مشتریان
- داده ها
- پردازش داده ها
- علم اطلاعات
- معامله
- تصمیم
- عمیق
- تقاضا
- نشان
- گسترش
- استقرار
- گسترش
- شرح
- توسعه
- توسعه
- در حال توسعه
- مختلف
- کارگر بارانداز
- هر
- به آسانی
- بهره وری
- موثر
- نقطه پایانی
- تخمین می زند
- مثال
- مثال ها
- موجود
- چهره
- ویژگی
- امکانات
- زمینه
- متمرکز شده است
- تمرکز
- پیروی
- چارچوب
- از جانب
- بیشتر
- بعلاوه
- GPU
- اداره
- سخت افزار
- ارتفاع
- کمک
- کمک
- کمک می کند
- اینجا کلیک نمایید
- با کیفیت بالا
- بالاتر
- خیلی
- چگونه
- چگونه
- HTTPS
- قطب
- تصویر
- پیاده سازی
- بهبود
- مشمول
- از جمله
- اطلاعات
- ذاتی
- ابتکاری
- ورودی
- نمونه
- منافع
- رابط
- IT
- کار
- روزنامه
- دانستن
- زبان
- راه اندازی
- آموخته
- یادگیری
- لینک ها
- فهرست
- ذکر شده
- دستگاه
- فراگیری ماشین
- عمده
- مدیریت
- روش
- رسانه ها
- متوسط
- ML
- مدل
- مدل
- بیش
- اکثر
- چندگانه
- طبیعی
- شبکه
- بهینه سازی
- بهینه
- گزینه
- دیگر
- خود
- مالک
- ویژه
- عبور
- کارایی
- محبوب
- قوی
- پیش بینی
- پیش گویی
- پیش بینی
- در حال حاضر
- مشکل
- روند
- در حال پردازش
- محصول
- پروژه
- ارائه
- ارائه
- فراهم می کند
- عمومی
- منتشر شده
- به سرعت
- اعم
- خام
- به رسمیت می شناسد
- منطقه
- نیاز
- تحقیق
- منابع
- نتیجه
- نتایج
- دویدن
- در حال اجرا
- همان
- مقیاس پذیری
- مقیاس پذیر
- مقیاس
- مقیاس گذاری
- علم
- دانشمند
- دانشمندان
- sdk
- انتخاب شد
- سلسله
- سری A
- خدمات
- تنظیم
- چند
- تغییر
- ساده
- So
- آگاهی
- رسانه های اجتماعی
- جامعه
- راه حل
- مزایا
- حل
- برخی از
- ویژه
- متخصص
- پشته
- شروع
- آغاز شده
- وضعیت هنر
- آماری
- هنوز
- ذخیره سازی
- پشتیبانی
- هدف
- هدف قرار
- وظایف
- فنی
- تکنیک
- La
- شخص ثالث
- سه
- از طریق
- سراسر
- زمان
- امروز
- با هم
- پیگردی
- قطار
- آموزش
- دگرگون کردن
- انواع
- ui
- منحصر به فرد
- استفاده کنید
- موارد استفاده
- ارزش
- مختلف
- نسخه
- راه
- وب
- خدمات وب
- چی
- در داخل
- شما