این مجموعه سه قسمتی نحوه استفاده از شبکه های عصبی گراف (GNN) و نپتون آمازون برای تولید توصیه های فیلم با استفاده از IMDb و Box Office Mojo Movies/TV/OTT بسته داده های قابل مجوز، که طیف گسترده ای از فراداده های سرگرمی، از جمله بیش از 1 میلیارد رتبه بندی کاربر را ارائه می دهد. اعتبار برای بیش از 11 میلیون بازیگر و خدمه؛ 9 میلیون عنوان فیلم، تلویزیون و سرگرمی؛ و داده های گزارش باکس آفیس جهانی از بیش از 60 کشور. بسیاری از مشتریان رسانه و سرگرمی AWS به داده های IMDb مجوز می دهند تبادل داده AWS برای بهبود کشف محتوا و افزایش تعامل و حفظ مشتری.
In قسمت 1، ما در مورد کاربردهای GNN و نحوه تبدیل و آماده سازی داده های IMDb خود برای پرس و جو بحث کردیم. در این پست، ما در مورد فرآیند استفاده از نپتون برای ایجاد جاسازیهایی که برای انجام جستجوی خارج از کاتالوگ در قسمت 3 استفاده میشوند، بحث میکنیم. ما هم می رویم آمازون نپتون ام ال، ویژگی یادگیری ماشین (ML) نپتون و کدی که در فرآیند توسعه خود استفاده می کنیم. در قسمت 3، نحوه اعمال جاسازیهای نمودار دانش خود را در مورد استفاده جستجوی خارج از فهرست توضیح میدهیم.
بررسی اجمالی راه حل
مجموعه دادههای متصل بزرگ اغلب حاوی اطلاعات ارزشمندی هستند که استخراج آنها با استفاده از جستارهای مبتنی بر شهود انسانی به تنهایی دشوار است. تکنیکهای ML میتوانند به یافتن همبستگیهای پنهان در نمودارها با میلیاردها رابطه کمک کنند. این همبستگی ها می تواند برای توصیه محصولات، پیش بینی ارزش اعتبار، شناسایی تقلب و بسیاری موارد استفاده دیگر مفید باشد.
Neptune ML امکان ساخت و آموزش مدل های مفید ML را بر روی نمودارهای بزرگ در چند ساعت به جای هفته ها فراهم می کند. برای انجام این کار، Neptune ML از فناوری GNN استفاده می کند آمازون SageMaker و کتابخانه نمودار عمیق (DGL) (که است منبع باز). GNN ها یک زمینه نوظهور در هوش مصنوعی هستند (به عنوان مثال، نگاه کنید به بررسی جامع شبکه های عصبی نموداری). برای یک آموزش عملی در مورد استفاده از GNN با DGL، نگاه کنید آموزش شبکه های عصبی گراف با Deep Graph Library.
در این پست، نحوه استفاده از نپتون در خط لوله خود را برای ایجاد جاسازی نشان می دهیم.
نمودار زیر جریان کلی داده های IMDb را از بارگیری تا تولید جاسازی نشان می دهد.
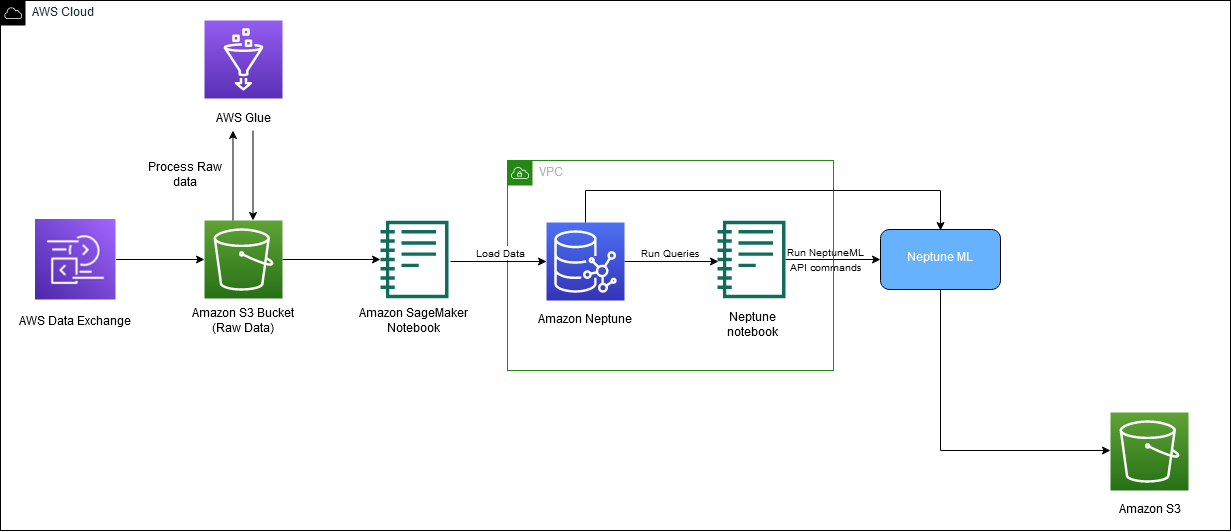
ما از خدمات AWS زیر برای پیاده سازی راه حل استفاده می کنیم:
در این پست شما را در مراحل سطح بالا راهنمایی می کنیم:
- تنظیم متغیرهای محیطی
- ایجاد شغل صادراتی
- یک کار پردازش داده ایجاد کنید.
- یک شغل آموزشی ارسال کنید.
- جاسازی ها را دانلود کنید.
کد دستورات Neptune ML
ما از دستورات زیر به عنوان بخشی از اجرای این راه حل استفاده می کنیم:
استفاده می کنیم neptune_ml export برای بررسی وضعیت یا شروع فرآیند صادرات Neptune ML، و neptune_ml training برای شروع و بررسی وضعیت کار آموزش مدل Neptune ML.
برای اطلاعات بیشتر در مورد این دستورات و سایر دستورات به ادامه مطلب مراجعه کنید از جادوهای میز کار نپتون در نوت بوک های خود استفاده کنید.
پیش نیازها
برای دنبال کردن این پست، باید موارد زیر را داشته باشید:
- An حساب AWS
- آشنایی با SageMaker، Amazon S3 و AWS CloudFormation
- داده های نمودار بارگذاری شده در خوشه نپتون (نگاه کنید به قسمت 1 برای اطلاعات بیشتر)
تنظیم متغیرهای محیطی
قبل از شروع، باید محیط خود را با تنظیم متغیرهای زیر تنظیم کنید: s3_bucket_uri و processed_folder. s3_bucket_uri نام سطل مورد استفاده در قسمت 1 و processed_folder محل آمازون S3 برای خروجی از کار صادرات است.
ایجاد شغل صادراتی
در قسمت 1، ما یک نوت بوک SageMaker و سرویس صادرات ایجاد کردیم تا داده های خود را از خوشه DB Neptune به Amazon S3 در قالب مورد نیاز صادر کنیم.
اکنون که داده های ما بارگیری شده و سرویس صادرات ایجاد شده است، باید یک کار صادراتی ایجاد کنیم و آن را شروع کنیم. برای این کار استفاده می کنیم NeptuneExportApiUri و ایجاد پارامترهایی برای کار صادرات. در کد زیر از متغیرها استفاده می کنیم expo و export_params. تنظیم expo خود را به NeptuneExportApiUri ارزش، که می توانید در آن پیدا کنید خروجی برگه پشته CloudFormation شما. برای export_params، ما از نقطه پایانی خوشه نپتون شما استفاده می کنیم و مقدار آن را ارائه می دهیم outputS3path، که محل آمازون S3 برای خروجی از کار صادرات است.
برای ارسال کار صادراتی از دستور زیر استفاده کنید:
برای بررسی وضعیت صادرات کار از دستور زیر استفاده کنید:
پس از اتمام کارتان، آن را تنظیم کنید processed_folder متغیر برای ارائه مکان آمازون S3 نتایج پردازش شده:
یک کار پردازش داده ایجاد کنید
اکنون که صادرات انجام شده است، یک کار پردازش داده ایجاد می کنیم تا داده ها را برای فرآیند آموزش Neptune ML آماده کنیم. این را می توان به چند روش مختلف انجام داد. برای این مرحله می توانید تغییر دهید job_name و modelType متغیرها، اما تمام پارامترهای دیگر باید ثابت بمانند. بخش اصلی این کد عبارت است از modelType پارامتر، که می تواند مدل های گراف ناهمگن باشد (heterogeneous) یا نمودارهای دانش (kge).
کار صادرات نیز شامل می شود training-data-configuration.json. از این فایل برای اضافه کردن یا حذف هر گونه گره یا لبه ای که نمی خواهید برای آموزش ارائه دهید استفاده کنید (به عنوان مثال، اگر می خواهید پیوند بین دو گره را پیش بینی کنید، می توانید آن پیوند را در این فایل پیکربندی حذف کنید). برای این پست وبلاگ ما از فایل پیکربندی اصلی استفاده می کنیم. برای اطلاعات بیشتر، نگاه کنید ویرایش فایل پیکربندی آموزشی.
کار پردازش داده خود را با کد زیر ایجاد کنید:
برای بررسی وضعیت صادرات کار از دستور زیر استفاده کنید:
یک شغل آموزشی ارسال کنید
پس از تکمیل کار پردازش، میتوانیم کار آموزشی خود را شروع کنیم، جایی که جاسازیهای خود را ایجاد میکنیم. ما یک نوع نمونه از ml.m5.24xlarge را توصیه می کنیم، اما می توانید آن را مطابق با نیازهای محاسباتی خود تغییر دهید. کد زیر را ببینید:
متغیر training_results را چاپ می کنیم تا شناسه کار آموزشی را بدست آوریم. برای بررسی وضعیت شغل خود از دستور زیر استفاده کنید:
%neptune_ml training status --job-id {training_results['id']} --store-to training_status_results
جاسازی ها را دانلود کنید
پس از اتمام کار آموزشی، آخرین مرحله این است که تعبیههای خام خود را دانلود کنید. مراحل زیر به شما نشان می دهد که چگونه جاسازی های ایجاد شده با استفاده از KGE را بارگیری کنید (می توانید از همان فرآیند برای RGCN استفاده کنید).
در کد زیر استفاده می کنیم neptune_ml.get_mapping() و get_embeddings() برای دانلود فایل نقشه برداری (mapping.info) و فایل embeddings خام (entity.npy). سپس باید جاسازی های مناسب را به شناسه های مربوطه آنها نگاشت کنیم.
برای دانلود RGCN ها، با پردازش داده ها با پارامتر modelType که روی آن تنظیم شده است، همین روند را با نام شغل آموزشی جدید دنبال کنید. heterogeneous، سپس مدل خود را با پارامتر modelName آموزش دهید rgcn دیدن اینجا کلیک نمایید برای جزئیات بیشتر پس از اتمام آن، با شماره تماس بگیرید get_mapping و get_embeddings توابع برای دانلود جدید خود mapping.info و entity.npy فایل ها. پس از در اختیار داشتن فایل های موجودیت و نقشه برداری، فرآیند ایجاد فایل CSV یکسان است.
در نهایت، جاسازی های خود را در مکان مورد نظر آمازون S3 خود آپلود کنید:
مطمئن شوید که این مکان S3 را به خاطر دارید، باید از آن در قسمت 3 استفاده کنید.
پاک کردن
وقتی استفاده از محلول را تمام کردید، مطمئن شوید که همه منابع را تمیز کنید تا از هزینه های مداوم جلوگیری کنید.
نتیجه
در این پست، نحوه استفاده از Neptune ML برای آموزش تعبیههای GNN از دادههای IMDb را مورد بحث قرار دادیم.
برخی از کاربردهای مرتبط تعبیه گراف دانش مفاهیمی مانند جستجوی خارج از فهرست، توصیههای محتوا، تبلیغات هدفمند، پیشبینی لینکهای گمشده، جستجوی کلی و تحلیل گروهی هستند. جستجوی خارج از کاتالوگ فرآیند جستجوی محتوایی است که متعلق به شما نیست، و یافتن یا توصیه محتوایی که در کاتالوگ شما وجود دارد که تا حد امکان به آنچه کاربر جستجو کرده است نزدیک باشد. ما در قسمت 3 به جستجوی خارج از کاتالوگ عمیق تر می پردازیم.
درباره نویسنده
 متیو رودز یک دانشمند داده است که در آزمایشگاه راه حل های آمازون ام ال کار می کنم. او در ساخت خطوط لوله یادگیری ماشین که شامل مفاهیمی مانند پردازش زبان طبیعی و بینایی کامپیوتری است، تخصص دارد.
متیو رودز یک دانشمند داده است که در آزمایشگاه راه حل های آمازون ام ال کار می کنم. او در ساخت خطوط لوله یادگیری ماشین که شامل مفاهیمی مانند پردازش زبان طبیعی و بینایی کامپیوتری است، تخصص دارد.
 دیویا بهرگاوی دانشمند داده و رهبر عمودی رسانه و سرگرمی در آزمایشگاه راه حل های آمازون ML است، جایی که او با استفاده از یادگیری ماشینی مشکلات تجاری با ارزش را برای مشتریان AWS حل می کند. او روی درک تصویر/ویدیو، سیستمهای توصیه گراف دانش، موارد استفاده از تبلیغات پیشبینیکننده کار میکند.
دیویا بهرگاوی دانشمند داده و رهبر عمودی رسانه و سرگرمی در آزمایشگاه راه حل های آمازون ML است، جایی که او با استفاده از یادگیری ماشینی مشکلات تجاری با ارزش را برای مشتریان AWS حل می کند. او روی درک تصویر/ویدیو، سیستمهای توصیه گراف دانش، موارد استفاده از تبلیغات پیشبینیکننده کار میکند.
 گاوراو رله یک دانشمند داده در آزمایشگاه راه حل آمازون ML است، جایی که با مشتریان AWS در سطوح مختلف کار می کند تا استفاده آنها از یادگیری ماشین و خدمات AWS Cloud را برای حل چالش های تجاری آنها تسریع بخشد.
گاوراو رله یک دانشمند داده در آزمایشگاه راه حل آمازون ML است، جایی که با مشتریان AWS در سطوح مختلف کار می کند تا استفاده آنها از یادگیری ماشین و خدمات AWS Cloud را برای حل چالش های تجاری آنها تسریع بخشد.
 کاران سیندوانی دانشمند داده در آزمایشگاه راه حل های آمازون ML است، جایی که مدل های یادگیری عمیق را می سازد و به کار می برد. او در زمینه بینایی کامپیوتر تخصص دارد. در اوقات فراغت خود از پیاده روی لذت می برد.
کاران سیندوانی دانشمند داده در آزمایشگاه راه حل های آمازون ML است، جایی که مدل های یادگیری عمیق را می سازد و به کار می برد. او در زمینه بینایی کامپیوتر تخصص دارد. در اوقات فراغت خود از پیاده روی لذت می برد.
 سوجی آدیشینا یک دانشمند کاربردی در AWS است که در آن مدلهای مبتنی بر شبکه عصبی گراف را برای یادگیری ماشین در وظایف نمودارها با برنامههای کاربردی برای تقلب و سوء استفاده، نمودارهای دانش، سیستمهای توصیهکننده و علوم زیستی توسعه میدهد. در اوقات فراغت از مطالعه و آشپزی لذت می برد.
سوجی آدیشینا یک دانشمند کاربردی در AWS است که در آن مدلهای مبتنی بر شبکه عصبی گراف را برای یادگیری ماشین در وظایف نمودارها با برنامههای کاربردی برای تقلب و سوء استفاده، نمودارهای دانش، سیستمهای توصیهکننده و علوم زیستی توسعه میدهد. در اوقات فراغت از مطالعه و آشپزی لذت می برد.
 ویدیا ساگار راویپاتی مدیر آزمایشگاه راه حلهای آمازون ML است، جایی که از تجربه گسترده خود در سیستمهای توزیعشده در مقیاس بزرگ و اشتیاق خود به یادگیری ماشینی استفاده میکند تا به مشتریان AWS در بخشهای مختلف صنعت کمک کند تا پذیرش هوش مصنوعی و ابر خود را تسریع کنند.
ویدیا ساگار راویپاتی مدیر آزمایشگاه راه حلهای آمازون ML است، جایی که از تجربه گسترده خود در سیستمهای توزیعشده در مقیاس بزرگ و اشتیاق خود به یادگیری ماشینی استفاده میکند تا به مشتریان AWS در بخشهای مختلف صنعت کمک کند تا پذیرش هوش مصنوعی و ابر خود را تسریع کنند.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- پلاتوبلاک چین. Web3 Metaverse Intelligence. دانش تقویت شده دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/part-2-power-recommendations-and-search-using-an-imdb-knowledge-graph/
- 1
- 10
- 100
- 11
- 116
- 7
- 9
- a
- درباره ما
- سو استفاده کردن
- شتاب دادن
- در میان
- اضافی
- اطلاعات اضافی
- اتخاذ
- تبلیغات
- پس از
- AI
- معرفی
- تنها
- آمازون
- آزمایشگاه راه حل های آمازون ام ال
- تحلیل
- و
- برنامه های کاربردی
- اعمال می شود
- درخواست
- مناسب
- محدوده
- مصنوعی
- هوش مصنوعی
- AWS
- مستقر
- میان
- بیلیون
- میلیاردها
- بلاگ
- جعبه
- دفتر جعبه
- ساختن
- بنا
- می سازد
- کسب و کار
- صدا
- مورد
- موارد
- کاتالوگ
- چالش ها
- تغییر دادن
- بار
- بررسی
- نزدیک
- ابر
- پذیرش ابر
- خدمات ابر
- خوشه
- رمز
- کوهورت
- کامل
- جامع
- کامپیوتر
- چشم انداز کامپیوتر
- محاسبه
- مفاهیم
- رفتار
- پیکر بندی
- متصل
- محتوا
- متناظر
- کشور
- ایجاد
- ایجاد شده
- اعتبار
- اعتبار
- مشتری
- نامزدی مشتری
- مشتریان
- داده ها
- پردازش داده ها
- دانشمند داده
- مجموعه داده ها
- عمیق
- یادگیری عمیق
- عمیق تر
- مستقر می کند
- جزئیات
- پروژه
- توسعه
- dgl
- مختلف
- کشف
- بحث و تبادل نظر
- بحث کردیم
- توزیع شده
- سیستم های توزیع شده
- آیا
- دانلود
- هر دو
- سنگ سنباده
- نقطه پایانی
- نامزدی
- سرگرمی
- موجودیت
- محیط
- اتر (ETH)
- مثال
- تجربه
- صادرات
- عصاره
- ویژگی
- کمی از
- رشته
- پرونده
- فایل ها
- پیدا کردن
- پیدا کردن
- جریان
- به دنبال
- پیروی
- قالب
- تقلب
- از جانب
- کامل
- توابع
- سوالات عمومی
- تولید می کنند
- نسل
- دریافت کنید
- جهانی
- Go
- گراف
- نمودار ها
- دست
- سخت
- کمک
- مفید
- پنهان
- در سطح بالا
- ساعت ها
- چگونه
- چگونه
- HTML
- HTTPS
- انسان
- یکسان
- شناسایی
- انجام
- اجرای
- بهبود
- in
- شامل
- از جمله
- افزایش
- شاخص
- صنعت
- اطلاعات
- اطلاعات
- نمونه
- در عوض
- اطلاعات
- شامل
- IT
- کار
- json
- کلید
- دانش
- آزمایشگاه
- زبان
- بزرگ
- در مقیاس بزرگ
- نام
- رهبری
- یادگیری
- اهرم ها
- کتابخانه
- مجوز
- زندگی
- علوم زندگی
- ارتباط دادن
- لینک ها
- محل
- دستگاه
- فراگیری ماشین
- اصلی
- باعث می شود
- مدیر
- بسیاری
- نقشه
- نقشه برداری
- رسانه ها
- متوسط
- اعضا
- متاداده
- میلیون
- گم
- ML
- مدل
- مدل
- بیش
- سینما
- نام
- طبیعی
- پردازش زبان طبیعی
- نیاز
- نیازهای
- نپتون
- مبتنی بر شبکه
- شبکه
- شبکه های عصبی
- جدید
- گره
- دفتر یادداشت
- دفتر
- مداوم
- اصلی
- دیگر
- به طور کلی
- خود
- بسته
- پارامتر
- پارامترهای
- بخش
- شور
- خط لوله
- افلاطون
- هوش داده افلاطون
- PlatoData
- ممکن
- پست
- قدرت
- صفحه اصلی
- پیش بینی
- پیش بینی
- آماده
- چاپ
- مشکلات
- روند
- در حال پردازش
- محصولات
- مشخصات
- ارائه
- فراهم می کند
- محدوده
- رتبه بندی
- خام
- مطالعه
- توصیه
- توصیه
- توصیه
- توصیه
- مربوط
- روابط
- ماندن
- به یاد داشته باشید
- برداشتن
- گزارش
- ضروری
- منابع
- نتایج
- نگهداری
- حکیم ساز
- همان
- علوم
- دانشمند
- جستجو
- جستجو
- سلسله
- سرویس
- خدمات
- تنظیم
- محیط
- باید
- نشان
- راه حل
- مزایا
- حل
- حل می کند
- تخصص دارد
- پشته
- شروع
- وضعیت
- گام
- مراحل
- opbevare
- ارسال
- چنین
- کت و شلوار
- بررسی
- سیستم های
- هدف قرار
- وظایف
- تکنیک
- پیشرفته
- La
- محوطه
- شان
- از طریق
- زمان
- عناوین
- به
- قطار
- آموزش
- دگرگون کردن
- درست
- آموزش
- tv
- درک
- استفاده کنید
- مورد استفاده
- کاربر
- ارزشمند
- ارزش
- وسیع
- نسخه
- عمودی
- دید
- راه
- هفته
- چی
- که
- وسیع
- دامنه گسترده
- اراده
- کارگر
- با این نسخهها کار
- شما
- زفیرنت