داده های سری زمانی به طور گسترده ای در زندگی ما وجود دارد. قیمت سهام، قیمت خانه، اطلاعات آب و هوا، و داده های فروش که در طول زمان به دست آمده اند، تنها چند نمونه هستند. از آنجایی که کسبوکارها به طور فزایندهای به دنبال راههای جدید برای به دست آوردن بینش معنادار از دادههای سری زمانی هستند، توانایی تجسم دادهها و اعمال تغییرات مورد نظر مراحل اساسی هستند. با این حال، دادههای سری زمانی در مقایسه با انواع دیگر دادههای جدولی دارای ویژگیها و تفاوتهای منحصربهفردی هستند و نیازمند ملاحظات خاصی هستند. به عنوان مثال، داده های استاندارد جدولی یا مقطعی در یک مقطع زمانی خاص جمع آوری می شوند. در مقابل، دادههای سری زمانی به طور مکرر در طول زمان ضبط میشوند و هر نقطه داده متوالی به مقادیر گذشته آن وابسته است.
از آنجایی که بیشتر تحلیلهای سریهای زمانی بر اطلاعات جمعآوریشده در مجموعهای از مشاهدات متکی هستند، دادههای از دست رفته و پراکندگی ذاتی میتواند دقت پیشبینیها را کاهش دهد و سوگیری ایجاد کند. علاوه بر این، بیشتر رویکردهای تحلیل سری زمانی بر فاصله مساوی بین نقاط داده، به عبارت دیگر، تناوب تکیه دارند. بنابراین، توانایی رفع بی نظمی های فاصله گذاری داده ها یک پیش نیاز حیاتی است. در نهایت، تجزیه و تحلیل سری های زمانی اغلب نیاز به ایجاد ویژگی های اضافی دارد که می تواند به توضیح رابطه ذاتی بین داده های ورودی و پیش بینی های آینده کمک کند. همه این عوامل پروژه های سری زمانی را از سناریوهای یادگیری ماشین سنتی (ML) متمایز می کند و رویکردی متمایز برای تحلیل آن را می طلبد.
در این پست نحوه استفاده توضیح داده شده است Amazon SageMaker Data Rangler برای اعمال تبدیل سری های زمانی و آماده سازی مجموعه داده های خود برای موارد استفاده سری های زمانی.
از موارد برای Data Wrangler استفاده کنید
Data Wrangler یک راه حل بدون کد/کد کم برای تجزیه و تحلیل سری های زمانی با ویژگی هایی برای تمیز کردن، تبدیل و آماده سازی سریعتر داده ها ارائه می دهد. همچنین دانشمندان داده را قادر می سازد تا داده های سری زمانی را مطابق با الزامات قالب ورودی مدل پیش بینی خود تهیه کنند. در زیر چند راه برای استفاده از این قابلیت ها آورده شده است:
- تحلیل توصیفی– معمولاً مرحله اول هر پروژه علم داده، درک داده ها است. وقتی دادههای سری زمانی را رسم میکنیم، یک نمای کلی در سطح بالایی از الگوهای آن، مانند روند، فصلی، چرخهها و تغییرات تصادفی به دست میآوریم. این به ما کمک می کند تا روش پیش بینی صحیح را برای نمایش دقیق این الگوها تصمیم بگیریم. طرحریزی همچنین میتواند به شناسایی موارد پرت کمک کند و از پیشبینیهای غیرواقعی و نادرست جلوگیری کند. Data Wrangler همراه با a تجسم تجزیه روند فصلی برای نمایش اجزای یک سری زمانی و an تجسم تشخیص بیرونی برای شناسایی موارد پرت
- تحلیل توضیحی- برای سری های زمانی چند متغیره، توانایی کاوش، شناسایی و مدل سازی رابطه بین دو یا چند سری زمانی برای به دست آوردن پیش بینی های معنادار ضروری است. این دسته بندی بر اساس transform in Data Wrangler با گروه بندی داده ها برای سلول های مشخص، چندین سری زمانی ایجاد می کند. بهعلاوه، تبدیلهای سریهای زمانی Data Wrangler، در صورت لزوم، اجازه میدهد تا ستونهای ID اضافی را بهصورت گروهبندی کنند و تجزیه و تحلیل سریهای زمانی پیچیده را ممکن میسازد.
- آماده سازی داده ها و مهندسی ویژگی- داده های سری زمانی به ندرت در قالب مورد انتظار مدل های سری زمانی هستند. برای تبدیل دادههای خام به ویژگیهای سری زمانی، اغلب نیاز به آمادهسازی دادهها دارد. ممکن است بخواهید اعتبارسنجی کنید که داده های سری زمانی قبل از تجزیه و تحلیل به طور منظم یا مساوی فاصله دارند. برای پیشبینی موارد استفاده، ممکن است بخواهید ویژگیهای سری زمانی اضافی، مانند همبستگی خودکار و ویژگیهای آماری را نیز وارد کنید. با Data Wrangler، میتوانید به سرعت ویژگیهای سری زمانی مانند ستونهای تاخیر برای دورههای تاخیر متعدد، نمونهبرداری مجدد دادهها به دانهبندیهای زمانی متعدد، و استخراج خودکار ویژگیهای آماری یک سری زمانی، برای نام بردن چند قابلیت ایجاد کنید.
بررسی اجمالی راه حل
این پست توضیح می دهد که چگونه دانشمندان و تحلیلگران داده می توانند از Data Wrangler برای تجسم و تهیه داده های سری زمانی استفاده کنند. ما از مجموعه داده های ارز دیجیتال بیت کوین استفاده می کنیم cryptodata دانلود با جزئیات معاملات بیت کوین برای به نمایش گذاشتن این قابلیت ها. ما مجموعه داده خام را با ویژگی های سری زمانی تمیز، اعتبارسنجی و تبدیل می کنیم و همچنین با استفاده از مجموعه داده تبدیل شده به عنوان ورودی، پیش بینی های قیمت حجم بیت کوین را تولید می کنیم.
نمونه داده های معاملات بیت کوین از 1 ژانویه تا 19 نوامبر 2021 با 464,116 نقطه داده است. ویژگی های مجموعه داده شامل یک مهر زمانی از رکورد قیمت، افتتاحیه یا اولین قیمتی است که سکه در یک روز خاص مبادله شده است، بالاترین قیمتی که سکه در آن روز مبادله شده است، آخرین قیمتی که سکه در آن مبادله شده است. در روز، حجم مبادله شده به ارزش ارز دیجیتال در روز به BTC و ارز مربوط به USD.
پیش نیازها
دانلود Bitstamp_BTCUSD_2021_minute.csv پرونده از cryptodata دانلود و آن را آپلود کنید سرویس ذخیره سازی ساده آمازون (Amazon S3).
مجموعه داده بیت کوین را در Data Wrangler وارد کنید
برای شروع فرآیند انتقال به Data Wrangler، مراحل زیر را انجام دهید:
- بر SageMaker Studio کنسول، بر روی پرونده منو ، انتخاب کنید جدید، پس از آن را انتخاب کنید جریان متخاصم داده.
- نام جریان را به دلخواه تغییر دهید.
- برای وارد کردن داده، انتخاب کنید آمازون S3.
- بارگذاری کنید
Bitstamp_BTCUSD_2021_minute.csvفایل از سطل S3 شما.
اکنون می توانید پیش نمایش مجموعه داده های خود را مشاهده کنید.
- در جزئیات پنجره، انتخاب کنید پیکربندی پیشرفته و انتخاب را لغو کنید نمونه برداری را فعال کنید.
این یک مجموعه داده نسبتاً کوچک است، بنابراین ما نیازی به نمونه برداری نداریم.
- را انتخاب کنید وارد كردن.
شما با موفقیت نمودار جریان را ایجاد کرده اید و آماده اضافه کردن مراحل تبدیل هستید.

تبدیل ها را اضافه کنید
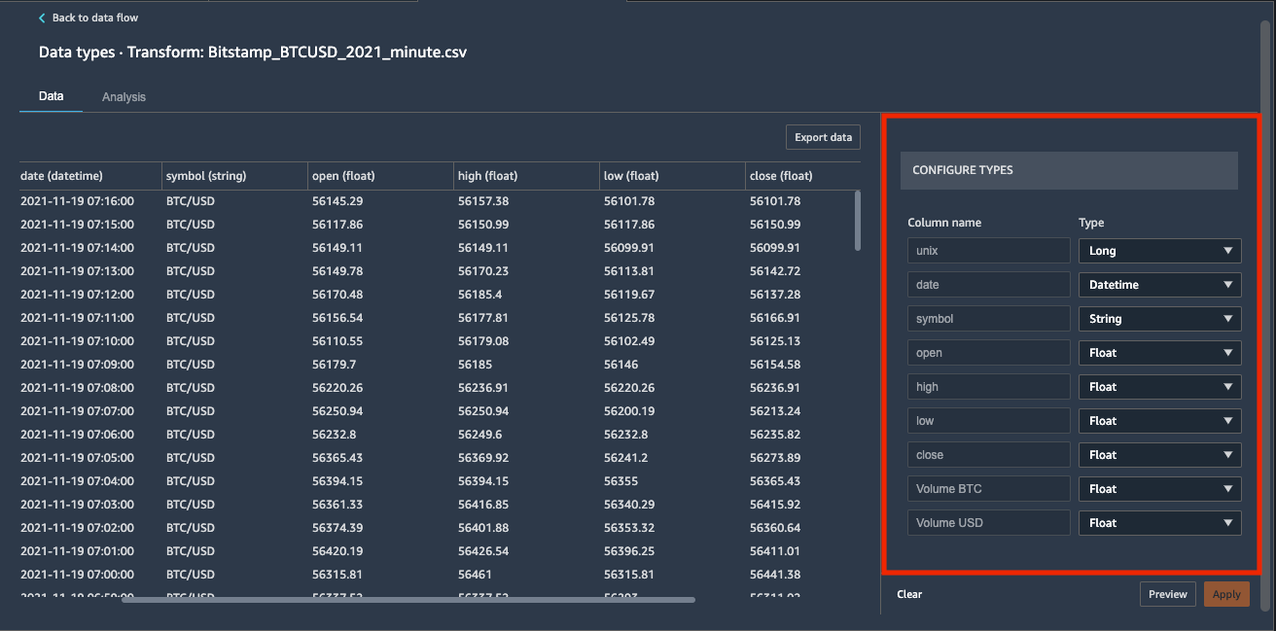
برای افزودن تبدیل داده ها، علامت مثبت در کنار آن را انتخاب کنید انواع داده ها و انتخاب کنید انواع داده ها را ویرایش کنید.

اطمینان حاصل کنید که Data Wrangler به طور خودکار انواع داده های صحیح را برای ستون های داده استنباط کرده است.
در مورد ما، انواع داده های استنباط شده صحیح هستند. با این حال، فرض کنید یک نوع داده نادرست بود. همانطور که در تصویر زیر نشان داده شده است، می توانید به راحتی آنها را از طریق UI تغییر دهید.
بیایید تجزیه و تحلیل را شروع کنیم و شروع به اضافه کردن تبدیل کنیم.
تمیز کردن داده ها
ابتدا چندین تبدیل پاکسازی داده را انجام می دهیم.
رها کردن ستون
بیایید با حذف کردن شروع کنیم unix ستون، زیرا ما از date ستون به عنوان شاخص
- را انتخاب کنید بازگشت به جریان داده.
- علامت مثبت کناری را انتخاب کنید انواع داده ها و انتخاب کنید تبدیل را اضافه کنید.
- را انتخاب کنید + افزودن مرحله در تبدیل می شود پنجره
- را انتخاب کنید ستون ها را مدیریت کنید.
- برای دگرگون کردن، انتخاب کنید رها کردن ستون.
- برای ستون برای انداختن، انتخاب کنید یونیکس.
- را انتخاب کنید پیش نمایش.
- را انتخاب کنید اضافه کردن برای نجات مرحله.
دسته گم شده است
داده های از دست رفته یک مشکل شناخته شده در مجموعه داده های دنیای واقعی است. بنابراین، این بهترین روش برای بررسی وجود هر گونه مقادیر از دست رفته یا تهی و مدیریت مناسب آنها است. مجموعه داده ما حاوی مقادیر گمشده نیست. اما اگر وجود داشت، از آن استفاده می کردیم دسته گم شده است تبدیل سری های زمانی برای رفع آنها. استراتژیهای رایج برای مدیریت دادههای از دست رفته شامل حذف ردیفهایی با مقادیر گمشده یا پر کردن مقادیر گمشده با برآوردهای معقول است. از آنجایی که داده های سری زمانی به دنباله ای از نقاط داده در طول زمان متکی هستند، پر کردن مقادیر از دست رفته رویکرد ترجیحی است. فرآیند پر کردن مقادیر از دست رفته به عنوان نامیده می شود انتساب. دسته گم شده است تبدیل سری زمانی به شما این امکان را می دهد که از بین چندین استراتژی انتساب انتخاب کنید.
- را انتخاب کنید + افزودن مرحله در تبدیل می شود پنجره
- انتخاب سری زمانی تبدیل.
- برای دگرگون کردن، انتخاب کنید دسته گم شده است.
- برای نوع ورودی سری زمانی، انتخاب کنید در امتداد ستون.
- برای روش برای محاسبه مقادیر، انتخاب کنید پر کردن به جلو.
La پر کردن به جلو روش مقادیر از دست رفته را با مقادیر غیر از دست رفته قبل از مقادیر از دست رفته جایگزین می کند.
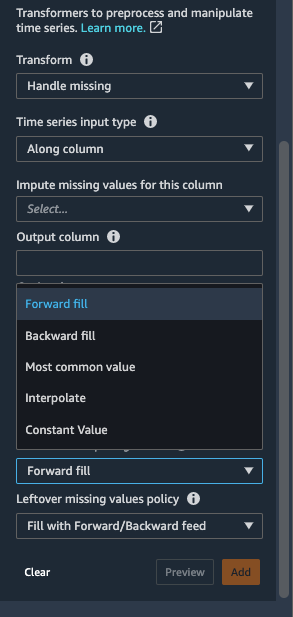
پر کردن عقب, مقدار ثابت, رایج ترین ارزش و تفسیر کنید دیگر استراتژیهای انتساب موجود در Data Wrangler هستند. تکنیک های درون یابی برای پر کردن مقادیر از دست رفته بر مقادیر همسایه تکیه می کنند. دادههای سری زمانی اغلب همبستگی بین مقادیر همسایه را نشان میدهند و درون یابی را به یک استراتژی پر کردن مؤثر تبدیل میکنند. برای جزئیات بیشتر در مورد توابعی که می توانید برای اعمال درون یابی استفاده کنید، مراجعه کنید pandas.DataFrame.interpolate.
اعتبارسنجی مهر زمانی
در تجزیه و تحلیل سری های زمانی، ستون مهر زمانی به عنوان ستون شاخص عمل می کند که تجزیه و تحلیل حول آن می چرخد. بنابراین، ضروری است که مطمئن شوید ستون مهر زمانی حاوی مقادیر مهر زمانی نامعتبر یا فرمتبندی نادرست است. چون ما از date ستون به عنوان ستون مهر زمان و شاخص، اجازه دهید تأیید کنیم که مقادیر آن به درستی قالب بندی شده است.
- را انتخاب کنید + افزودن مرحله در تبدیل می شود پنجره
- انتخاب سری زمانی تبدیل.
- برای تبدیل، را انتخاب کنید اعتبارسنجی مهرهای زمانی.
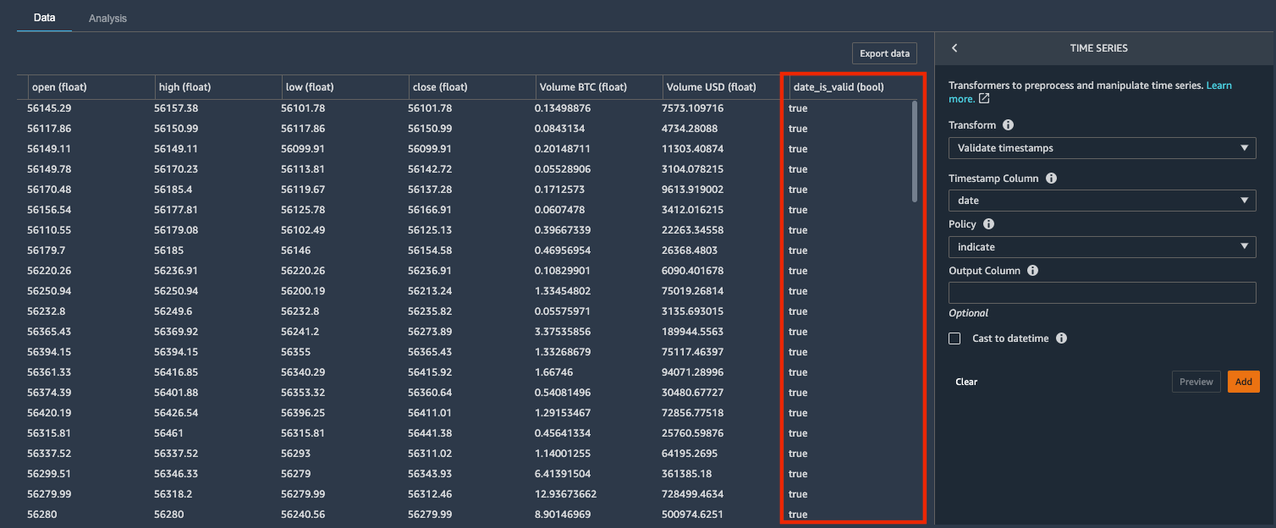
La اعتبارسنجی مهرهای زمانی transform به شما امکان می دهد بررسی کنید که ستون مهر زمانی در مجموعه داده شما دارای مقادیری با مُهر زمانی نادرست یا مقادیر گمشده باشد.
- برای ستون مهر زمان، انتخاب کنید تاریخ.
- برای سیاست کشویی، انتخاب کنید نشان دهید.
La نشان دهید گزینه Policy یک ستون بولی ایجاد می کند که نشان می دهد آیا مقدار در ستون مهر زمان یک قالب تاریخ/زمان معتبر است یا خیر. گزینه های دیگر برای سیاست عبارتند از:
- خطا - اگر ستون مهر زمان مفقود یا نامعتبر باشد، خطا می دهد
- قطره - اگر ستون مهر زمان مفقود یا نامعتبر باشد، ردیف را حذف می کند
- را انتخاب کنید پیش نمایش.
یک ستون بولی جدید به نام date_is_valid ایجاد شد، با true مقادیری که فرمت صحیح و ورودی های غیر پوچ را نشان می دهد. مجموعه داده ما حاوی مقادیر مُهر زمانی نامعتبر در date ستون اما اگر این کار را کرد، میتوانید از ستون Boolean جدید برای شناسایی و رفع آن مقادیر استفاده کنید.
- را انتخاب کنید اضافه کردن برای ذخیره این مرحله
تجسم سری زمانی
پس از پاکسازی و اعتبارسنجی مجموعه داده، میتوانیم دادهها را بهتر تجسم کنیم تا اجزای مختلف آن را درک کنیم.
نمونه گیری مجدد
از آنجایی که ما به پیش بینی های روزانه علاقه مندیم، بیایید فرکانس داده ها را به روزانه تبدیل کنیم.
La نمونه گیری مجدد تبدیل فرکانس مشاهدات سری زمانی را به یک دانه بندی مشخص تغییر می دهد و با هر دو گزینه نمونه برداری و نمونه برداری پایین ارائه می شود. استفاده از نمونهبرداری مجدد، فراوانی مشاهدات را افزایش میدهد (مثلاً از روزانه به ساعتی)، در حالی که نمونهبرداری پایین تعداد مشاهدات را کاهش میدهد (مثلاً از ساعتی به روزانه).
از آنجایی که مجموعه داده ما در جزئیات دقیق است، بیایید از گزینه downsampling استفاده کنیم.
- را انتخاب کنید + افزودن مرحله.
- انتخاب سری زمانی تبدیل.
- برای دگرگون کردن، انتخاب کنید نمونه گیری مجدد.
- برای TIMESTAMP، انتخاب کنید تاریخ.
- برای واحد فرکانس، انتخاب کنید روز تقویم.
- برای کمیت فرکانس، 1 را وارد کنید.
- برای روش تجمیع مقادیر عددی، انتخاب کنید متوسط.
- را انتخاب کنید پیش نمایش.
فرکانس مجموعه داده ما از هر دقیقه به روزانه تغییر کرده است.

- را انتخاب کنید اضافه کردن برای ذخیره این مرحله
فصلی-روند تجزیه
پس از نمونهبرداری مجدد، میتوانیم سری تبدیلشده و اجزای STL مرتبط با آن (تجزیه فصلی و روند با استفاده از LOESS) را با استفاده از فصلی-روند-تجزیه تجسم. این سری های زمانی اصلی را به اجزای روند متمایز، فصلی و باقیمانده تقسیم می کند و به ما درک خوبی از نحوه رفتار هر الگو می دهد. ما همچنین می توانیم از اطلاعات در هنگام مدل سازی مشکلات پیش بینی استفاده کنیم.
Data Wrangler از LOESS، یک روش آماری قوی و همه کاره برای مدلسازی روند و اجزای فصلی استفاده میکند. پیاده سازی زیربنایی آن از رگرسیون چند جمله ای برای تخمین روابط غیرخطی موجود در مؤلفه های سری زمانی (فصلی، روند، و باقیمانده) استفاده می کند.
- را انتخاب کنید بازگشت به جریان داده.
- علامت مثبت کنار علامت را انتخاب کنید مراحل on گردش داده ها.
- را انتخاب کنید تجزیه و تحلیل را اضافه کنید.
- در تحلیل ایجاد کنید پنجره، برای نوع آنالیز، را انتخاب کنید سری زمانی.
- برای تجسم، انتخاب کنید فصلی-روند تجزیه.
- برای نام تحلیل، یک نام وارد کنید.
- برای ستون مهر زمان، انتخاب کنید تاریخ.
- برای ستون ارزش، انتخاب کنید حجم USD.
- را انتخاب کنید پیش نمایش.
تجزیه و تحلیل به ما امکان می دهد سری های زمانی ورودی و فصلی، روند و باقیمانده تجزیه شده را تجسم کنیم.

- را انتخاب کنید ذخیره برای ذخیره تجزیه و تحلیل
با تجسم تجزیه روند فصلی، همانطور که در تصویر قبلی نشان داده شده است، می توانیم چهار الگو ایجاد کنیم:
- اصلی - سری زمانی اصلی مجدداً به صورت دانه بندی روزانه نمونه برداری شد.
- روند - روند چند جمله ای با الگوی روند کلی منفی برای سال 2021 که نشان دهنده کاهش
Volume USDارزش. - فصل - فصلی ضربی که با الگوهای مختلف نوسان نشان داده می شود. ما شاهد کاهش تغییرات فصلی هستیم که با کاهش دامنه نوسانات مشخص می شود.
- باقیمانده - نویز باقیمانده یا تصادفی. سری باقیمانده مجموعه ای است که پس از حذف روند و اجزای فصلی حاصل می شود. با نگاهی دقیق، ما بین ژانویه و مارس، و بین آوریل و ژوئن، افزایشهایی را مشاهده میکنیم که فضایی را برای مدلسازی چنین رویدادهای خاص با استفاده از دادههای تاریخی نشان میدهد.
این تجسم ها به دانشمندان و تحلیلگران داده سرنخ های ارزشمندی را در الگوهای موجود ارائه می دهند و می توانند به شما در انتخاب استراتژی مدل سازی کمک کنند. با این حال، اعتبارسنجی خروجی تجزیه STL با اطلاعات جمعآوریشده از طریق تحلیل توصیفی و تخصص دامنه، همیشه یک روش خوب است.
به طور خلاصه، ما یک روند نزولی مطابق با تجسم سری اصلی مشاهده می کنیم که اعتماد ما را در ترکیب اطلاعات منتقل شده توسط تجسم روند در تصمیم گیری پایین دستی افزایش می دهد. در مقابل، تجسم فصلی به اطلاع از حضور فصلی و نیاز به حذف آن با استفاده از تکنیکهایی مانند تفاوت کمک میکند، سطح مطلوبی از بینش دقیق در مورد الگوهای فصلی مختلف موجود را ارائه نمیکند، در نتیجه نیاز به تحلیل عمیقتری دارد.
مهندسی ویژگی
پس از درک الگوهای موجود در مجموعه داده خود، میتوانیم ویژگیهای جدیدی را با هدف افزایش دقت مدلهای پیشبینی شروع کنیم.
زمان تاریخ را مشخص کنید
بیایید فرآیند مهندسی ویژگی را با ویژگیهای تاریخ/زمان سادهتر شروع کنیم. ویژگیهای تاریخ/زمان از timestamp ستون و یک راه بهینه برای دانشمندان داده برای شروع فرآیند مهندسی ویژگی فراهم می کند. ما با زمان تاریخ را مشخص کنید تبدیل سری زمانی برای افزودن ویژگی های ماه، روز ماه، روز سال، هفته سال و ویژگی های سه ماهه به مجموعه داده ما. از آنجایی که ما مؤلفههای تاریخ/زمان را بهعنوان ویژگیهای جداگانه ارائه میکنیم، الگوریتمهای ML را برای شناسایی سیگنالها و الگوها برای بهبود دقت پیشبینی فعال میکنیم.
- را انتخاب کنید + افزودن مرحله.
- انتخاب سری زمانی تبدیل.
- برای تبدیل، را انتخاب کنید زمان تاریخ را مشخص کنید.
- برای ستون ورودی، انتخاب کنید تاریخ.
- برای ستون خروجی، وارد
date(این مرحله اختیاری است). - برای حالت خروجی، انتخاب کنید معمولی.
- برای فرمت خروجی، انتخاب کنید ستون ها.
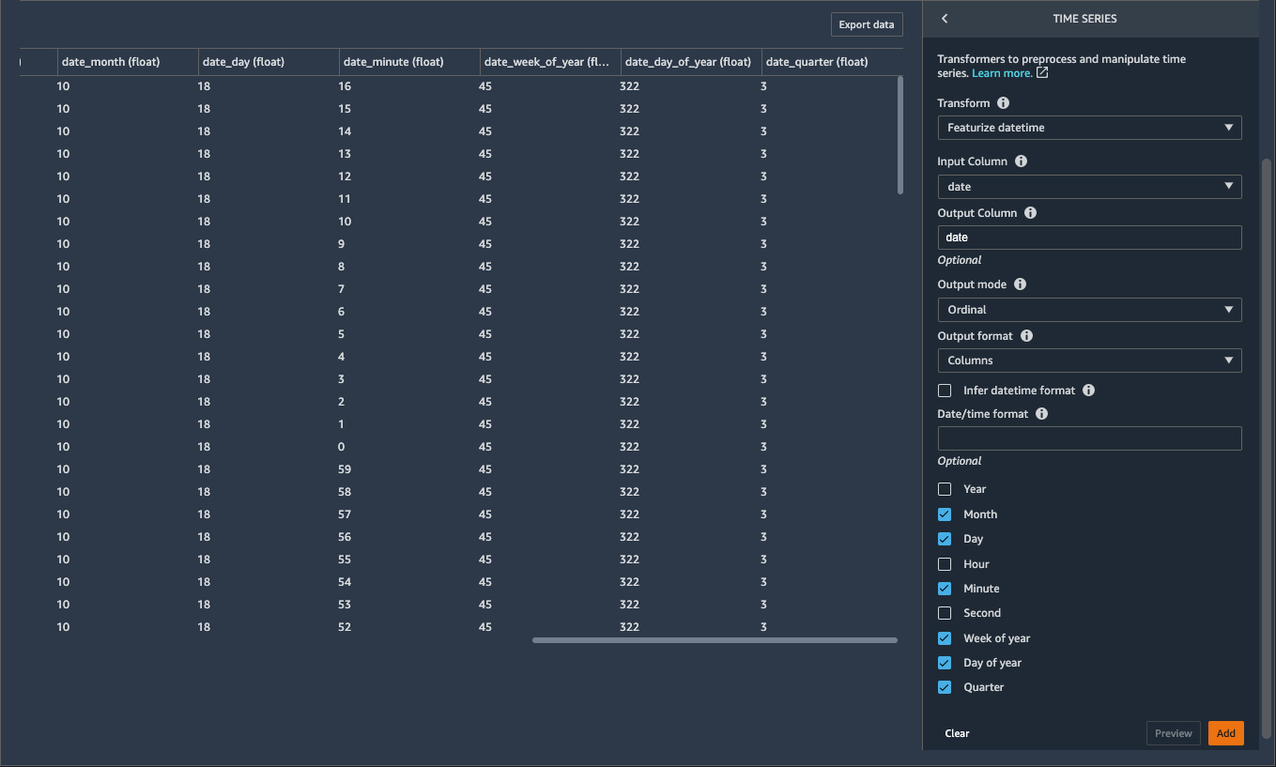
- برای استخراج ویژگیهای تاریخ/زمان، را انتخاب کنید ماه, روز, هفته از سال, روز سالو یک چهارم.
- را انتخاب کنید پیش نمایش.
اکنون مجموعه داده شامل ستونهای جدیدی با نام است date_month, date_day, date_week_of_year, date_day_of_yearو date_quarter. اطلاعات بازیابی شده از این ویژگی های جدید می تواند به دانشمندان داده کمک کند تا بینش بیشتری از داده ها و رابطه بین ویژگی های ورودی و ویژگی های خروجی بدست آورند.
- را انتخاب کنید اضافه کردن برای ذخیره این مرحله
کدگذاری طبقه بندی شده
ویژگیهای تاریخ/زمان به مقادیر صحیح محدود نمیشوند. همچنین میتوانید برخی از ویژگیهای تاریخ/زمان استخراجشده را بهعنوان متغیرهای طبقهبندی در نظر بگیرید و آنها را بهعنوان ویژگیهای رمزگذاریشده یکطرفه نشان دهید، که هر ستون حاوی مقادیر باینری است. تازه ایجاد شده date_quarter ستون حاوی مقادیری بین 0-3 است و میتواند با استفاده از چهار ستون باینری یکبار کدگذاری شود. بیایید چهار ویژگی باینری جدید ایجاد کنیم که هر کدام نشان دهنده فصل مربوطه سال است.
- را انتخاب کنید + افزودن مرحله.
- انتخاب کدگذاری طبقه بندی شده تبدیل.
- برای دگرگون کردن، انتخاب کنید یک کدگذاری داغ.
- برای ستون ورودی، انتخاب کنید تاریخ_چهارم.
- برای سبک خروجی، انتخاب کنید ستون ها.
- را انتخاب کنید پیش نمایش.
- را انتخاب کنید اضافه کردن برای اضافه کردن مرحله

ویژگی تاخیر
بعد، بیایید ویژگیهای تاخیر را برای ستون هدف ایجاد کنیم Volume USD. ویژگیهای تاخیر در تحلیل سریهای زمانی، مقادیری در مُهرهای زمانی قبلی هستند که برای استنباط مقادیر آینده مفید تلقی میشوند. آنها همچنین به شناسایی خود همبستگی کمک می کنند (همچنین به نام همبستگی سریال) الگوهای سری باقیمانده با کمی کردن رابطه مشاهده با مشاهدات در مراحل زمانی قبلی. خودهمبستگی شبیه همبستگی معمولی است اما بین مقادیر یک سری و مقادیر گذشته آن است. این مبنای مدلهای پیشبینی خودرگرسیون در سری ARIMA را تشکیل میدهد.
با Data Wrangler ویژگی تاخیر تبدیل، شما به راحتی می توانید ویژگی های تاخیر n دوره از هم ایجاد کنید. علاوه بر این، ما اغلب میخواهیم چندین ویژگی تاخیر را در تاخیرهای مختلف ایجاد کنیم و به مدل اجازه دهیم که معنیدارترین ویژگیها را تعیین کند. برای چنین سناریویی، ویژگی های تاخیر transform به ایجاد ستونهای تاخیری متعدد در یک اندازه پنجره مشخص کمک میکند.
- را انتخاب کنید بازگشت به جریان داده.
- علامت مثبت کنار علامت را انتخاب کنید مراحل on گردش داده ها.
- را انتخاب کنید + افزودن مرحله.
- را انتخاب کنید سری زمانی تبدیل.
- برای دگرگون کردن، انتخاب کنید ویژگی های تاخیر.
- برای ویژگی های تاخیر را برای این ستون ایجاد کنید، انتخاب کنید حجم USD.
- برای ستون مهر زمان، انتخاب کنید تاریخ.
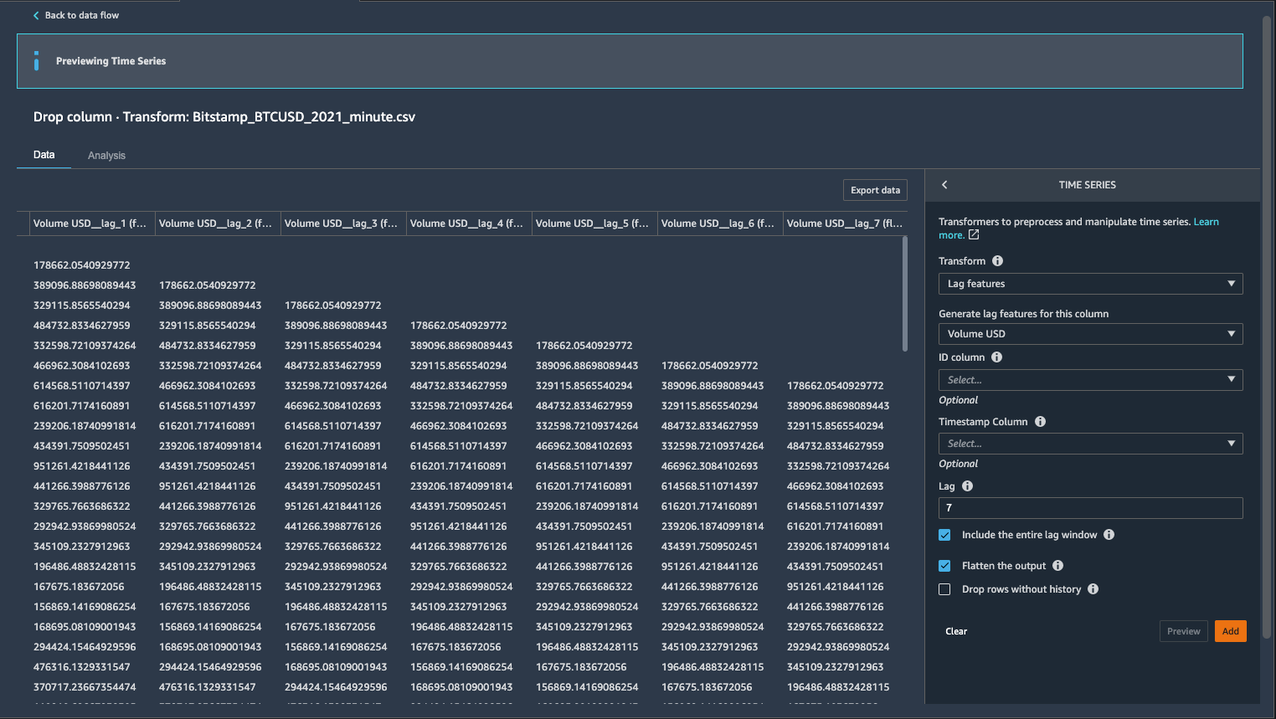
- برای عقب ماندن، وارد
7. - از آنجایی که ما علاقه مندیم تا هفت مقدار تاخیر قبلی را مشاهده کنیم، بیایید انتخاب کنیم کل پنجره تاخیر را شامل شود.
- برای ایجاد یک ستون جدید برای هر مقدار تاخیر، را انتخاب کنید خروجی را صاف کنید.
- را انتخاب کنید پیش نمایش.
هفت ستون جدید اضافه شده است که با پسوند lag_number کلمه کلیدی برای ستون هدف Volume USD.
- را انتخاب کنید اضافه کردن برای نجات مرحله.
ویژگی های پنجره غلتشی
همچنین میتوانیم خلاصههای آماری معنیداری را در محدودهای از مقادیر محاسبه کرده و آنها را به عنوان ویژگیهای ورودی بگنجانیم. بیایید ویژگی های رایج سری زمانی آماری را استخراج کنیم.
Data Wrangler قابلیت های استخراج ویژگی های سری زمانی خودکار را با استفاده از منبع باز پیاده سازی می کند تسفرش بسته بندی با تبدیلهای استخراج ویژگی سری زمانی، میتوانید فرآیند استخراج ویژگی را خودکار کنید. این امر زمان و تلاشی را که صرف اجرای دستی کتابخانه های پردازش سیگنال می شود حذف می کند. برای این پست، ما ویژگی ها را با استفاده از ویژگی های پنجره غلتشی تبدیل. این روش ویژگی های آماری را در مجموعه ای از مشاهدات تعریف شده توسط اندازه پنجره محاسبه می کند.
- را انتخاب کنید + افزودن مرحله.
- انتخاب سری زمانی تبدیل.
- برای دگرگون کردن، انتخاب کنید ویژگی های پنجره غلتشی.
- برای ویژگی های پنجره نورد را برای این ستون ایجاد کنید، انتخاب کنید حجم USD.
- برای ستون مهر زمان، انتخاب کنید تاریخ.
- برای اندازه پنجره، وارد
7.
تعیین اندازه پنجره از 7 ویژگی ها را با ترکیب مقدار در مهر زمانی فعلی و مقادیر هفت مهر زمانی قبلی محاسبه می کند.
- انتخاب کنید صاف برای ایجاد یک ستون جدید برای هر ویژگی محاسبه شده.
- استراتژی خود را به عنوان انتخاب کنید زیر مجموعه حداقل.
این استراتژی هشت ویژگی را استخراج می کند که در تحلیل های پایین دستی مفید هستند. استراتژی های دیگر عبارتند از زیر مجموعه کارآمد, زیر مجموعه سفارشیو همه ویژگی ها. برای لیست کامل ویژگی های موجود برای استخراج، مراجعه کنید مروری بر ویژگی های استخراج شده.
- را انتخاب کنید پیش نمایش.
ما می توانیم هشت ستون جدید با اندازه پنجره مشخص شده را ببینیم 7 به نام آنها، به مجموعه داده ما اضافه شده است.
- را انتخاب کنید اضافه کردن برای نجات مرحله.

مجموعه داده را صادر کنید
ما مجموعه داده سری زمانی را تغییر داده ایم و آماده استفاده از مجموعه داده تبدیل شده به عنوان ورودی برای یک الگوریتم پیش بینی هستیم. آخرین مرحله، صادر کردن مجموعه داده های تبدیل شده به آمازون S3 است. در Data Wrangler می توانید انتخاب کنید مرحله صادرات برای تولید خودکار یک نوت بوک Jupyter با کد پردازش Amazon SageMaker برای پردازش و صادرات مجموعه داده تبدیل شده به یک سطل S3. با این حال، از آنجایی که مجموعه داده ما حاوی بیش از 300 رکورد است، بیایید از مزایای آن استفاده کنیم صادر کردن داده گزینه در Transform را اضافه کنید مشاهده برای صادرات مجموعه داده تبدیل شده به طور مستقیم به Amazon S3 از Data Wrangler.
- را انتخاب کنید صادر کردن داده.
- برای مکان S3، انتخاب کنید مرورگر و سطل S3 خود را انتخاب کنید.
- را انتخاب کنید صادر کردن داده.

اکنون که مجموعه داده بیت کوین را با موفقیت تغییر داده ایم، می توانیم از آن استفاده کنیم پیش بینی آمازون برای تولید پیش بینی بیت کوین
پاک کردن
اگر کارتان با این مورد تمام شده است، منابعی را که ایجاد کردهاید پاک کنید تا از تحمیل هزینههای اضافی جلوگیری کنید. برای Data Wrangler میتوانید پس از اتمام، نمونه اصلی را خاموش کنید. رجوع شود به Data Wrangler را خاموش کنید اسناد برای جزئیات از طرف دیگر، می توانید ادامه دهید قسمت 2 از این سری برای استفاده از این مجموعه داده برای پیش بینی.
خلاصه
این پست نشان داد که چگونه می توان از Data Wrangler برای ساده سازی و تسریع تجزیه و تحلیل سری های زمانی با استفاده از قابلیت های سری زمانی داخلی آن استفاده کرد. ما بررسی کردیم که چگونه دانشمندان داده می توانند به راحتی و به طور تعاملی داده های سری زمانی را برای تجزیه و تحلیل معنادار پاکسازی، قالب بندی، اعتبارسنجی و تبدیل به قالب مورد نظر کنند. ما همچنین بررسی کردیم که چگونه می توانید تجزیه و تحلیل سری زمانی خود را با افزودن مجموعه ای جامع از ویژگی های آماری با استفاده از Data Wrangler غنی کنید. برای کسب اطلاعات بیشتر در مورد تبدیل سری های زمانی در Data Wrangler، مراجعه کنید تبدیل داده ها.
درباره نویسنده
 روپ باین یک معمار راه حل در AWS است که بر AI/ML تمرکز دارد. او مشتاق کمک به مشتریان برای نوآوری و دستیابی به اهداف تجاری خود با استفاده از هوش مصنوعی و یادگیری ماشین است. روپ در اوقات فراغت خود از مطالعه و پیاده روی لذت می برد.
روپ باین یک معمار راه حل در AWS است که بر AI/ML تمرکز دارد. او مشتاق کمک به مشتریان برای نوآوری و دستیابی به اهداف تجاری خود با استفاده از هوش مصنوعی و یادگیری ماشین است. روپ در اوقات فراغت خود از مطالعه و پیاده روی لذت می برد.
 نیکیتا ایوکین یک دانشمند کاربردی، Amazon SageMaker Data Wrangler است.
نیکیتا ایوکین یک دانشمند کاربردی، Amazon SageMaker Data Wrangler است.
- "
- 100
- 116
- 2021
- 7
- 9
- درباره ما
- شتاب دادن
- در میان
- اضافی
- مزیت - فایده - سود - منفعت
- الگوریتم
- الگوریتم
- معرفی
- آمازون
- تحلیل
- مربوط
- با استفاده از
- روش
- آوریل
- دور و بر
- مصنوعی
- هوش مصنوعی
- هوش مصنوعی و یادگیری ماشین
- در دسترس
- AWS
- اساس
- بهترین
- بیت کوین
- تجارت بیت کوین
- مرز
- BTC
- ساخته شده در
- کسب و کار
- کسب و کار
- قابلیت های
- موارد
- بار
- تمیز کاری
- رمز
- سکه
- ستون
- مشترک
- مقایسه
- پیچیده
- جزء
- اعتماد به نفس
- کنسول
- شامل
- ادامه دادن
- میتوانست
- کریپتو کارنسی (رمز ارزها )
- واحد پول
- جاری
- مشتریان
- داده ها
- علم اطلاعات
- مجموعه داده ها
- روز
- عمیق تر
- تقاضا
- کشف
- DID
- مختلف
- نمی کند
- دامنه
- پایین
- به آسانی
- موثر
- را قادر می سازد
- مهندس
- مهندسی
- ضروری است
- تخمین می زند
- حوادث
- مثال
- انتظار می رود
- تخصص
- عصاره ها
- عوامل
- سریعتر
- ویژگی
- امکانات
- سرانجام
- نام خانوادگی
- رفع
- جریان
- پیروی
- قالب
- اشکال
- کامل
- آینده
- تولید می کنند
- دادن
- خوب
- گروه
- اداره
- کمک
- مفید
- کمک می کند
- خانه
- چگونه
- چگونه
- HTTPS
- شناسایی
- در دیگر
- شامل
- افزایش
- شاخص
- اطلاعات
- بینش
- اطلاعات
- IT
- ژانویه
- شناخته شده
- یاد گرفتن
- یادگیری
- سطح
- محدود شده
- فهرست
- به دنبال
- دستگاه
- فراگیری ماشین
- ساخت
- مارس
- ML
- مدل
- مدل
- اکثر
- ویژگی های جدید
- سر و صدا
- دفتر یادداشت
- باز کن
- منبع باز
- افتتاح
- گزینه
- گزینه
- دیگر
- در غیر این صورت
- الگو
- دوره ها
- سیاست
- پیش گویی
- پیش بینی
- در حال حاضر
- جلوگیری
- پیش نمایش
- قیمت
- مشکل
- روند
- پروژه
- پروژه ها
- ارائه
- فراهم می کند
- یک چهارم
- به سرعت
- محدوده
- خام
- مطالعه
- معقول
- رکورد
- سوابق
- كاهش دادن
- منظم
- ارتباط
- روابط
- نیاز
- مورد نیاز
- منابع
- این فایل نقد می نویسید:
- حراجی
- علم
- دانشمند
- دانشمندان
- سلسله
- سرویس
- تنظیم
- تعطیل
- مشابه
- ساده
- اندازه
- کوچک
- So
- مزایا
- مشخصات
- شروع
- آماری
- موجودی
- ذخیره سازی
- استراتژی ها
- استراتژی
- موفقیت
- هدف
- تکنیک
- از طریق
- زمان
- تجارت
- سنتی
- دگرگون کردن
- دگرگونی
- ui
- فهمیدن
- منحصر به فرد
- us
- دلار آمریکا
- استفاده کنید
- معمولا
- استفاده کنید
- ارزش
- چشم انداز
- تجسم
- حجم
- هفته
- کلمات
- سال