پیش آموزش مدل مدرن اغلب مستلزم استقرار خوشه های بزرگتر برای کاهش زمان و هزینه است. در سطح سرور، چنین بارهای آموزشی نیازمند محاسبه سریعتر و افزایش تخصیص حافظه هستند. همانطور که مدل ها به صدها میلیارد پارامتر رشد می کنند، به یک مکانیسم آموزشی توزیع شده نیاز دارند که چندین گره (نمونه) را در بر می گیرد.
در اکتبر 2022 راه اندازی کردیم موارد آمازون EC2 Trn1، طراحی شده توسط AWS Trainium، که نسل دوم شتاب دهنده یادگیری ماشینی است که توسط AWS طراحی شده است. نمونههای Trn1 برای آموزش مدلهای یادگیری عمیق با کارایی بالا ساخته شدهاند، در حالی که تا 50% صرفهجویی در هزینه آموزش نسبت به نمونههای مشابه مبتنی بر GPU ارائه میدهند. به منظور کاهش زمان آموزش از هفتهها به روزها، یا روزها به ساعتها، و توزیع کار آموزشی یک مدل بزرگ، میتوانیم از یک UltraCluster EC2 Trn1 استفاده کنیم که متشکل از رکهای متراکم قرار گرفته از نمونههای محاسباتی Trn1 است که همگی به هم مرتبط هستند. شبکه های مقیاس پتابایت غیر مسدود کننده این بزرگترین UltraCluster ما تا به امروز است که 6 اگزافلاپس توان محاسباتی را با حداکثر 30,000 تراشه Trainium ارائه میکند.
در این پست، ما از حجم کار پیش تمرین مدل BeRT-Large Hugging Face به عنوان یک مثال ساده برای توضیح نحوه استفاده از Trn1 UltraClusters استفاده می کنیم.
Trn1 UltraClusters
Trn1 UltraCluster یک گروه قرار دادن نمونه های Trn1 در یک مرکز داده است. به عنوان بخشی از اجرای یک کلاستر، می توانید یک خوشه از نمونه های Trn1 را با شتاب دهنده های Trainium بچرخانید. نمودار زیر یک مثال را نشان می دهد.
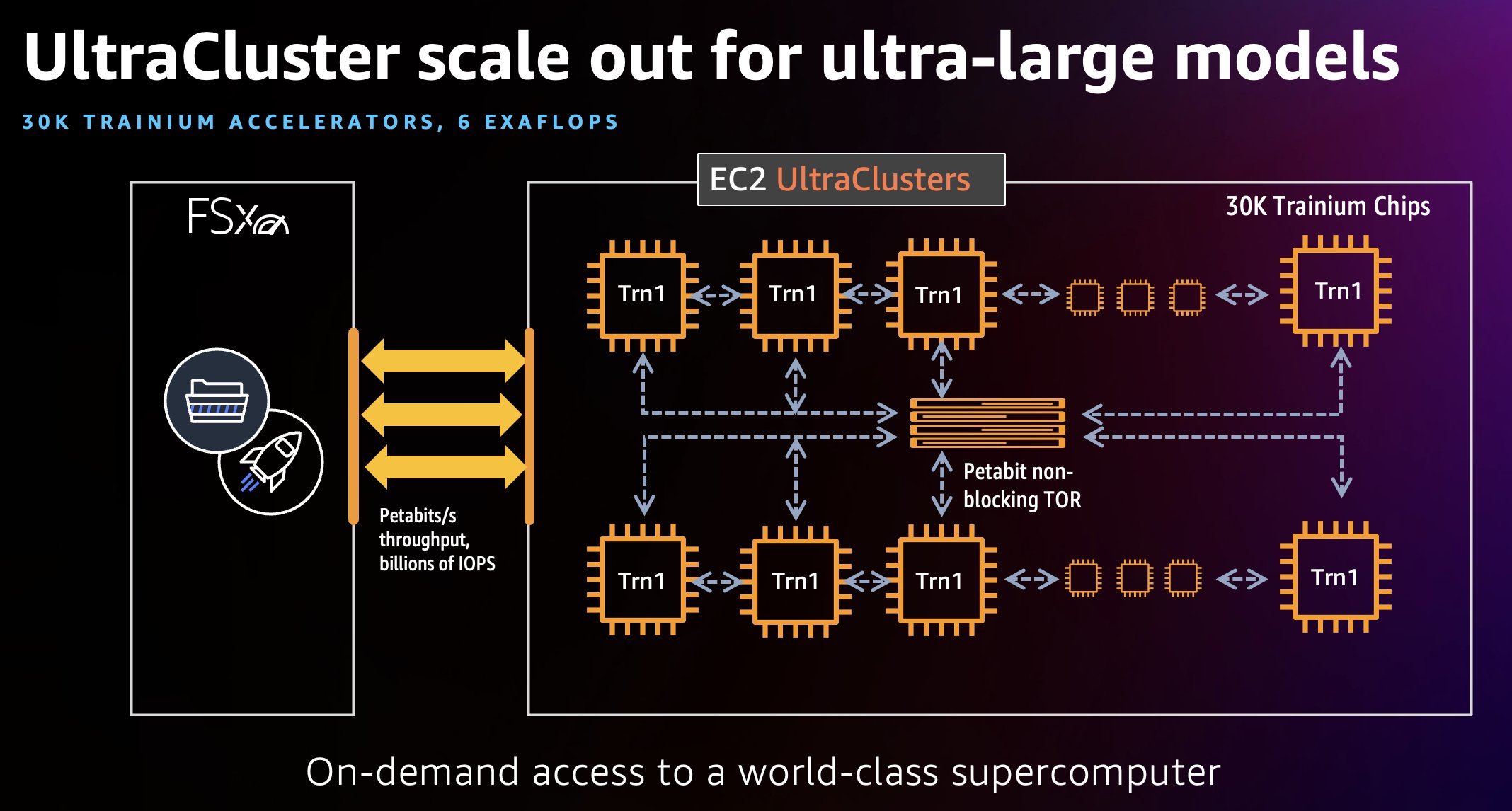
UltraCluster از نمونه های Trn1 در یک مرکز داده قرار گرفته اند و با استفاده از آن به هم متصل می شوند. آداپتور پارچه ای الاستیک (EFA)، که یک رابط شبکه غیر مسدود کننده در مقیاس پتابایت است، با پهنای باند شبکه تا 800 گیگابیت در ثانیه، که دو برابر پهنای باند پشتیبانی شده توسط نمونه های AWS P4d است (1.6 ترابایت در ثانیه، چهار برابر بیشتر با نمونه های آینده Trn1n). این رابطهای EFA به اجرای بارهای آموزشی مدل کمک میکنند که از کتابخانههای ارتباط جمعی نورون در مقیاس استفاده میکنند. Trn1 UltraClusterها همچنین شامل سرویسهای ذخیرهسازی متصل به شبکه میشوند آمازون FSx برای Luster برای فعال کردن دسترسی با توان بالا به مجموعه داده های بزرگ، اطمینان از عملکرد کارآمد خوشه ها. Trn1 UltraClusters می تواند تا 30,000 دستگاه Trainium را میزبانی کند و حداکثر 6 اگزافلاپس محاسبات را در یک خوشه ارائه دهد. EC2 Trn1 UltraClusters حداکثر 6 اگزافلاپس محاسباتی را ارائه میکند، که به معنای واقعی کلمه یک ابرکامپیوتر درخواستی است، با یک مدل استفاده بدون پرداخت. در این پست، ما از برخی ابزارهای HPC مانند Slurm برای افزایش یک UltraCluster و مدیریت بارهای کاری استفاده می کنیم.
بررسی اجمالی راه حل
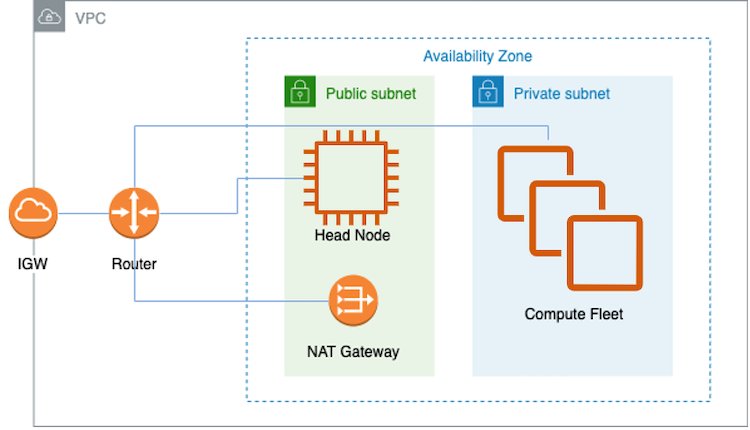
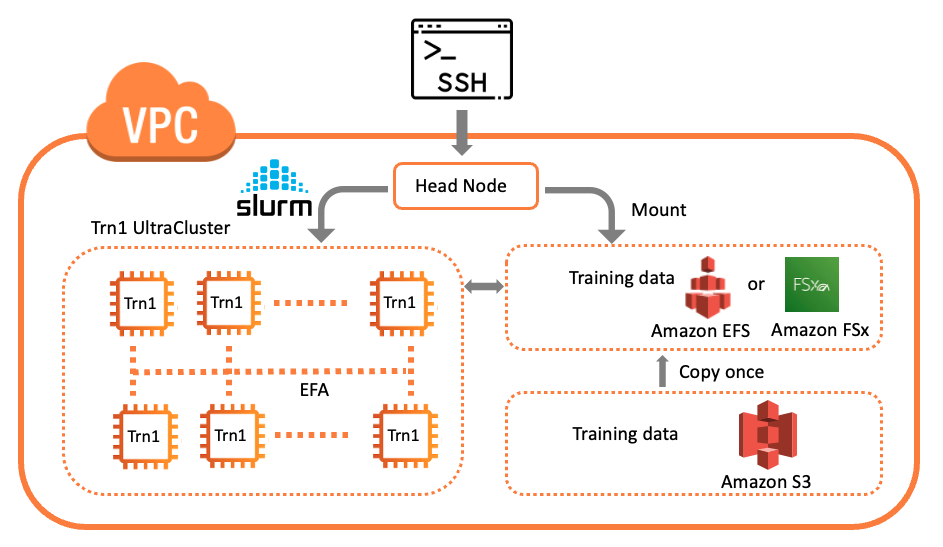
AWS طیف گسترده ای از خدمات را برای آموزش مدل های توزیع شده یا استنتاج بارهای کاری در مقیاس ارائه می دهد، از جمله دسته AWS, سرویس الاستیک کوبرنتز آمازون (Amazon EKS)، و UltraClusters. این پست بر روی آموزش مدل در UltraCluster تمرکز دارد. راه حل ما با استفاده از AWS ParallelCluster ابزار مدیریتی برای ایجاد زیرساخت و محیط لازم برای چرخش یک Trn1 UltraCluster. زیرساخت از یک گره سر و چندین گره محاسباتی Trn1 در یک ابر خصوصی مجازی (VPC) تشکیل شده است. ما از Slurm به عنوان مدیریت خوشه و سیستم برنامه ریزی شغلی استفاده می کنیم. نمودار زیر معماری راه حل ما را نشان می دهد.
برای جزئیات بیشتر و نحوه استقرار این راه حل، نگاه کنید یک مدل را در AWS Trn1 ParallelCluster آموزش دهید.
بیایید به چند مرحله مهم این راه حل نگاه کنیم:
- یک VPC و زیرشبکه ایجاد کنید.
- ناوگان محاسباتی را پیکربندی کنید.
- خوشه را ایجاد کنید.
- خوشه را بررسی کنید.
- کار آموزشی خود را راه اندازی کنید.
پیش نیازها
برای دنبال کردن این پست، آشنایی گسترده با خدمات اصلی AWS مانند ابر محاسبه الاستیک آمازون (Amazon EC2) ضمنی است و آشنایی اولیه با یادگیری عمیق و PyTorch مفید خواهد بود.
VPC و زیر شبکه ایجاد کنید
یک راه آسان برای ایجاد VPC و زیرشبکه ها از طریق این است ابر خصوصی مجازی آمازون کنسول (Amazon VPC). دستورالعمل های کامل را می توان در پیدا کرد GitHub. پس از نصب VPC و زیرشبکه ها، باید نمونه ها را در ناوگان محاسباتی پیکربندی کنید. به طور خلاصه، این امر توسط یک اسکریپت نصب مشخص شده توسط CustomActions در فایل YAML که برای ایجاد ParallelCluster استفاده می شود امکان پذیر است (نگاه کنید به ParallelCluster را ایجاد کنید). یک ParallelCluster به یک VPC نیاز دارد که دارای دو زیرشبکه و یک دروازه ترجمه آدرس شبکه (NAT) باشد، همانطور که در نمودار معماری قبلی نشان داده شده است. این VPC باید در مناطق در دسترس که در آن موارد Trn1 در دسترس است، قرار گیرد. همچنین، در این VPC، شما باید یک زیرشبکه عمومی و یک زیرشبکه خصوصی داشته باشید تا به ترتیب گره های اصلی و گره های محاسبه Trn1 را نگه دارند. شما همچنین به یک دروازه NAT دسترسی به اینترنت نیاز دارید، به طوری که گره های محاسباتی Trn1 بتوانند دانلود کنند نورون AWS بسته ها به طور کلی، گرههای محاسباتی بهروزرسانیهایی را برای بستههای OS، درایور نورون و زمان اجرا و درایور EFA برای آموزش چند نمونه دریافت میکنند.
در مورد گره سر، علاوه بر اجزای ذکر شده برای گره های محاسباتی، کامپایلر PyTorch-NeuronX و NeuronX را نیز دریافت می کند که فرآیند کامپایل مدل را در دستگاه های XLA مانند Trainium امکان پذیر می کند.
ناوگان محاسباتی را پیکربندی کنید
در فایل YAML برای ایجاد Trn1 UltraCluster، InstanceType به عنوان trn1.32xlarge مشخص شده است. MaxCount و MinCount برای نشان دادن محدوده اندازه ناوگان محاسباتی شما استفاده می شود. شما ممکن است استفاده کنید MinCount برخی یا همه موارد Trn1 را همیشه در دسترس نگه دارید. MinCount ممکن است روی صفر تنظیم شود تا اگر کار در حال اجرا وجود نداشته باشد، نمونه های Trn1 از این خوشه آزاد شوند.
Trn1 همچنین ممکن است در یک UltraCluster با صف های متعدد مستقر شود. در مثال زیر، تنها یک صف برای ارسال شغل Slurm تنظیم شده است:
اگر به بیش از یک صف نیاز دارید، می توانید چندین صف را مشخص کنید InstanceType، هر کدام مخصوص به خود MaxCount, MinCountو Name:
در اینجا، دو صف تنظیم شده است، به طوری که کاربر انعطاف پذیری برای انتخاب منابع برای کار Slurm خود را داشته باشد.
خوشه را ایجاد کنید
برای راه اندازی Trn1 UltraCluster، از موارد زیر استفاده کنید pcluster فرمان از جایی که شما ابزار ParallelCluster نصب شد:
ما در این دستور از گزینه های زیر استفاده می کنیم:
--cluster-configuration– این گزینه یک فایل YAML را انتظار دارد که پیکربندی کلاستر را توصیف کند-n(و یا--cluster-name) – نام این خوشه
این دستور یک کلاستر Trn1 را در حساب AWS شما ایجاد می کند. شما می توانید پیشرفت ایجاد خوشه را در آن بررسی کنید AWS CloudFormation کنسول. برای اطلاعات بیشتر مراجعه کنید با استفاده از کنسول AWS CloudFormation.
همچنین می توانید از دستور زیر برای مشاهده وضعیت درخواست خود استفاده کنید:
و دستور وضعیت را نشان می دهد، به عنوان مثال:
موارد زیر پارامترهای مورد علاقه از خروجی هستند:
- شناسه نمونه - این شناسه نمونه سر گره است که در کنسول آمازون EC2 فهرست می شود
- computeFleetStatus – این ویژگی نشان دهنده آمادگی گره های محاسباتی است
- گزينه ها – این ویژگی نشان دهنده نسخه است
pclusterابزار مورد استفاده برای ایجاد این خوشه
خوشه را بررسی کنید
می توانید از موارد ذکر شده استفاده کنید pcluster describe-cluster دستور برای بررسی خوشه. پس از ایجاد خوشه، موارد زیر را در خروجی مشاهده خواهید کرد:
در این مرحله، میتوانید SSH را وارد گره اصلی کنید (که با شناسه نمونه در کنسول آمازون EC2 مشخص میشود). شکل زیر یک نمودار منطقی از خوشه است.
بعد از اینکه SSH را وارد گره سر کردید، می توانید ناوگان محاسباتی و وضعیت آنها را با یک دستور Slurm تأیید کنید. sinfo برای مشاهده اطلاعات گره برای سیستم. نمونه زیر خروجی است:
این نشان می دهد که یک صف همانطور که توسط یک پارتیشن نشان داده شده است وجود دارد. 16 گره موجود است و منابع تخصیص داده شده است. از سر گره، می توانید SSH را به هر گره محاسباتی داده شده وارد کنید:
استفاده کنید exit برای بازگشت به گره سر
به همین ترتیب، می توانید SSH را به یک گره محاسباتی از یک گره محاسباتی دیگر تبدیل کنید. هر گره محاسباتی دارای ابزارهای نورون نصب شده است، مانند neuron-top. می توانید استناد کنید neuron-top در طول اسکریپت آموزشی برای بازرسی استفاده از NeuronCore در هر گره اجرا می شود.
کار آموزشی خود را راه اندازی کنید
ما با استفاده از آموزش پیش تمرینی BeRT-Large Hagging Face به عنوان مثالی برای اجرا در این خوشه. پس از دانلود داده ها و اسکریپت های آموزشی در خوشه، از کنترلر Slurm برای مدیریت و هماهنگ کردن حجم کاری خود استفاده می کنیم. ما کار آموزشی را با sbatch فرمان اسکریپت پوسته اسکریپت پایتون را از طریق neuron_parallel_compile API برای کامپایل مدل در نمودارها بدون اجرای کامل آموزشی. کد زیر را ببینید:
ما در این دستور از گزینه های زیر استفاده می کنیم:
--exclusive– این کار از تمام گره ها استفاده می کند و هنگام اجرای کار فعلی، گره ها را با کارهای دیگر به اشتراک نمی گذارد.--nodes– تعداد گره ها برای این کار.--wrap– این یک رشته فرمان را تعریف می کند که توسط کنترلر Slurm اجرا می شود. در این حالت، به سادگی مدل را با استفاده از تمام گره ها به صورت موازی کامپایل می کند.
پس از اینکه مدل با موفقیت کامپایل شد، می توانید کار آموزش کامل را با دستور زیر شروع کنید:
این دستور کار آموزش مدل Hugging Face BERT-Large را راه اندازی می کند. با 16 گره Trn1.32xlarge، می توانید انتظار داشته باشید که در کمتر از 8 ساعت کامل شود.
در این مرحله می توانید از دستور Slurm مانند squeue برای بازرسی شغل ارسالی یک نمونه خروجی به شرح زیر است:
این خروجی نشان می دهد که کار در حال اجرا است (R) در 16 گره محاسباتی.
همانطور که کار در حال اجرا است، خروجی ها گرفته شده و در یک فایل گزارش Slurm اضافه می شوند. از ترمینال سر گره، می توانید آن را در زمان واقعی بررسی کنید.
همچنین در همان دایرکتوری فایل log Slurm، دایرکتوری مربوط به این کار وجود دارد. این فهرست شامل موارد زیر است (به عنوان مثال):
این دایرکتوری برای تمام گره های محاسباتی قابل دسترسی است. results.json فرادادههای این کار خاص، مانند پیکربندی مدل، اندازه دستهای، کل مراحل، مراحل انباشتگی گرادیان، و نام مجموعه آموزشی را به تصویر میکشد. نقطه بازرسی مدل و گزارش خروجی هر گره محاسباتی نیز در این فهرست ثبت میشوند.
مقیاس پذیری خوشه را در نظر بگیرید
در یک Trn1 UltraCluster، چند نمونه Trn1 به هم پیوسته، حجم کار آموزشی مدل بزرگی را به صورت موازی اجرا میکنند و زمان یا زمان محاسبه کل را برای همگرایی کاهش میدهند. دو معیار برای مقیاس پذیری یک خوشه وجود دارد: پوسته پوسته شدن قوی و پوسته پوسته شدن ضعیف. به طور معمول، برای آموزش مدل، نیاز به سرعت بخشیدن به اجرای آموزش است، زیرا هزینه استفاده با توان نمونه برای دورهای به روز رسانی گرادیان تعیین می شود. مقیاس بندی قوی به سناریویی اطلاق می شود که در آن اندازه کل مشکل با افزایش تعداد پردازنده ها ثابت می ماند، مقیاس بندی قوی معیار مهمی برای مقیاس پذیری برای آموزش مدل است. در ارزیابی مقیاس بندی قوی، (یعنی تاثیر موازی سازی)، می خواهیم اندازه دسته جهانی را ثابت نگه داریم و ببینیم چقدر زمان برای همگرایی نیاز است. در چنین سناریویی، ما باید ریز مرحله انباشت گرادیان را با توجه به تعداد گره های محاسباتی تنظیم کنیم. این با موارد زیر در اسکریپت پوسته آموزشی به دست می آید run_dp_bert_large_hf_pretrain_bf16_s128.sh:
از سوی دیگر، اگر میخواهید با اضافه کردن گرههای بیشتر، ارزیابی کنید که چه تعداد بار کار بیشتری را میتوان در یک زمان ثابت اجرا کرد، از مقیاس ضعیف برای اندازهگیری مقیاسپذیری استفاده کنید. در مقیاس بندی ضعیف، اندازه مشکل با همان سرعتی که تعداد NeuronCoress افزایش می یابد، در نتیجه میزان کار در هر NeuronCores یکسان باقی می ماند. برای ارزیابی مقیاس بندی ضعیف، یا اثر افزودن گره های بیشتر بر افزایش حجم کار، به سادگی خط بالا را از اسکریپت آموزشی حذف کنید و تعداد مراحل انباشت گرادیان را با مقدار پیش فرض (32) ارائه شده در اسکریپت آموزشی ثابت نگه دارید.
نتایج خود را ارزیابی کنید
ما برخی از نتایج معیار را در صفحه عملکرد نورون برای نشان دادن اثر پوسته پوسته شدن دادهها مزایای استفاده از نمونههای متعدد برای موازی کردن کار آموزشی برای بسیاری از مدلهای بزرگ مختلف برای آموزش در مقیاس را نشان میدهد.
زیرساخت های خود را تمیز کنید
برای حذف تمام زیرساخت های این UltraCluster، از pcluster دستور حذف خوشه و منابع آن:
نتیجه
در این پست، ما بحث کردیم که چگونه مقیاسبندی کار آموزشی شما در یک Trn1-UltraCluster، که توسط شتابدهندههای Trainium در AWS ارائه میشود، زمان آموزش یک مدل را کاهش میدهد. ما همچنین یک لینک به مخزن نمونه های نورون، که حاوی دستورالعمل هایی در مورد نحوه استقرار یک کار آموزشی توزیع شده برای یک مدل BERT-Large است. Trn1-UltraCluster بارهای آموزشی توزیع شده را برای آموزش مدل های یادگیری عمیق فوق العاده بزرگ در مقیاس اجرا می کند. یک تنظیم آموزشی توزیع شده در مقایسه با آموزش روی یک نمونه Trn1 منجر به همگرایی مدل بسیار سریعتر می شود.
برای کسب اطلاعات بیشتر در مورد نحوه شروع کار با نمونههای Trn1 مجهز به Trainium، به سایت مراجعه کنید مستندات نورون.
درباره نویسنده
 کی سی تونگ یک معمار ارشد راه حل در آزمایشگاه AWS Annapurna است. او در آموزش مدل های یادگیری عمیق بزرگ و استقرار در مقیاس در فضای ابری تخصص دارد. او دکتری دارد. در بیوفیزیک مولکولی از مرکز پزشکی جنوب غربی دانشگاه تگزاس در دالاس. او در AWS Summits و AWS Reinvent سخنرانی کرده است. امروز او به مشتریان کمک می کند تا مدل های بزرگ PyTorch و TensorFlow را در ابر AWS آموزش و استقرار دهند. وی نویسنده دو کتاب است: TensorFlow Enterprise را یاد بگیرید و مرجع جیبی تنسورفلو 2.
کی سی تونگ یک معمار ارشد راه حل در آزمایشگاه AWS Annapurna است. او در آموزش مدل های یادگیری عمیق بزرگ و استقرار در مقیاس در فضای ابری تخصص دارد. او دکتری دارد. در بیوفیزیک مولکولی از مرکز پزشکی جنوب غربی دانشگاه تگزاس در دالاس. او در AWS Summits و AWS Reinvent سخنرانی کرده است. امروز او به مشتریان کمک می کند تا مدل های بزرگ PyTorch و TensorFlow را در ابر AWS آموزش و استقرار دهند. وی نویسنده دو کتاب است: TensorFlow Enterprise را یاد بگیرید و مرجع جیبی تنسورفلو 2.
 جفری هوین مهندس اصلی در AWS Annapurna Labs است. او مشتاق کمک به مشتریان برای اجرای بارهای آموزشی و استنتاج خود در دستگاههای شتابدهنده Trainium و Inferentia است. AWS Neuron SDK. او فارغ التحصیل دانشگاه کلتک/استنفورد با مدرک فیزیک و EE است. او از دویدن، تنیس، آشپزی و مطالعه در مورد علم و فناوری لذت می برد.
جفری هوین مهندس اصلی در AWS Annapurna Labs است. او مشتاق کمک به مشتریان برای اجرای بارهای آموزشی و استنتاج خود در دستگاههای شتابدهنده Trainium و Inferentia است. AWS Neuron SDK. او فارغ التحصیل دانشگاه کلتک/استنفورد با مدرک فیزیک و EE است. او از دویدن، تنیس، آشپزی و مطالعه در مورد علم و فناوری لذت می برد.
 شروتی کپرکار مدیر ارشد بازاریابی محصول در AWS است. او به مشتریان کمک میکند تا زیرساختهای محاسباتی تسریعشده EC2 را برای نیازهای یادگیری ماشین خود کاوش، ارزیابی و اتخاذ کنند.
شروتی کپرکار مدیر ارشد بازاریابی محصول در AWS است. او به مشتریان کمک میکند تا زیرساختهای محاسباتی تسریعشده EC2 را برای نیازهای یادگیری ماشین خود کاوش، ارزیابی و اتخاذ کنند.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- پلاتوبلاک چین. Web3 Metaverse Intelligence. دانش تقویت شده دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/scaling-large-language-model-llm-training-with-amazon-ec2-trn1-ultraclusters/
- 000
- 1
- 10
- 100
- 102
- 2022
- 7
- 9
- a
- درباره ما
- بالاتر
- تسریع شد
- شتاب دهنده
- شتاب دهنده ها
- دسترسی
- در دسترس
- مطابق
- حساب
- تجمع
- دست
- در میان
- اضافه
- نشانی
- اتخاذ
- پس از
- معرفی
- اختصاص داده شده است
- تخصیص
- آمازون
- آمازون EC2
- مقدار
- و
- دیگر
- API
- معماری
- متصل شده
- نویسنده
- دسترس پذیری
- در دسترس
- AWS
- AWS CloudFormation
- به عقب
- پهنای باند
- اساسی
- زیرا
- بودن
- محک
- سود
- میلیاردها
- بیوفیزیک
- کتاب
- بطور خلاصه
- به ارمغان بیاورد
- پهن
- ساخته
- تماس ها
- جلب
- مورد
- مرکز
- بررسی
- چیپس
- را انتخاب کنید
- ابر
- خوشه
- رمز
- Collective - Dubai Hills Estate
- ارتباط
- قابل مقایسه
- مقایسه
- کامل
- اجزاء
- محاسبه
- محاسبه
- محاسبه
- پیکر بندی
- کنسول
- ثابت
- شامل
- کنترل کننده
- همگرایی
- پخت و پز
- هسته
- متناظر
- هزینه
- ایجاد
- ایجاد شده
- ایجاد
- ایجاد
- ایجاد
- جاری
- مشتریان
- دالاس
- داده ها
- مرکز داده
- مجموعه داده ها
- تاریخ
- روز
- عمیق
- یادگیری عمیق
- به طور پیش فرض
- تعریف می کند
- ارائه
- تقاضا
- نشان دادن
- نشان می دهد
- گسترش
- مستقر
- گسترش
- طراحی
- جزئیات
- مشخص
- دستگاه ها
- مختلف
- بحث کردیم
- توزیع کردن
- توزیع شده
- آموزش توزیع شده
- پایین
- دانلود
- راننده
- در طی
- هر
- اثر
- موثر
- قادر ساختن
- را قادر می سازد
- مهندس
- حصول اطمینان از
- محیط
- اتر (ETH)
- ارزیابی
- ارزیابی
- مثال
- انتظار
- انتظار می رود
- توضیح دهید
- اکتشاف
- پارچه
- چهره
- آشنایی
- سریعتر
- پرونده
- ثابت
- ناوگان
- انعطاف پذیری
- تمرکز
- به دنبال
- پیروی
- به دنبال آن است
- یافت
- از جانب
- کامل
- دروازه
- سوالات عمومی
- نسل
- دریافت کنید
- رفتن
- داده
- جهانی
- نمودار ها
- بیشتر
- گروه
- شدن
- دست
- سر
- کمک
- مفید
- کمک
- کمک می کند
- زیاد
- عملکرد بالا
- نگه داشتن
- میزبان
- ساعت ها
- چگونه
- چگونه
- hpc
- HTML
- HTTPS
- صدها نفر
- شناسایی
- تأثیر
- ضمنی
- مهم
- in
- شامل
- شامل
- از جمله
- افزایش
- افزایش
- نشان دادن
- نشان می دهد
- اطلاعات
- شالوده
- نصب شده
- نمونه
- دستورالعمل
- به هم پیوسته
- علاقه
- رابط
- رابط
- اینترنت
- دسترسی به اینترنت
- فراخوانی میکند
- IT
- ژان
- کار
- شغل ها
- json
- نگاه داشتن
- نگهداری
- کلید
- کوبرنیتس
- آزمایشگاه
- زبان
- بزرگ
- بزرگتر
- بزرگترین
- راه اندازی
- راه اندازی
- یاد گرفتن
- یادگیری
- سطح
- کتابخانه ها
- لاین
- ارتباط دادن
- ذکر شده
- منطقی
- نگاه کنيد
- دستگاه
- فراگیری ماشین
- ساخته
- مدیریت
- مدیریت
- مدیر
- بسیاری
- بازار یابی (Marketing)
- اندازه
- معیارهای
- مکانیزم
- پزشکی
- حافظه
- متاداده
- مدل
- مدل
- مولکولی
- بیش
- چندگانه
- نام
- لازم
- نیاز
- نیازهای
- شبکه
- شبکه
- گره
- گره
- عدد
- مشاهده کردن
- اکتبر
- ارائه
- پیشنهادات
- ONE
- کار
- گزینه
- گزینه
- سفارش
- OS
- دیگر
- خود
- بسته
- بسته بندی شده
- موازی
- پارامترهای
- بخش
- ویژه
- احساساتی
- کارایی
- پتابایت
- فیزیک
- افلاطون
- هوش داده افلاطون
- PlatoData
- نقطه
- ممکن
- پست
- قدرت
- صفحه اصلی
- اصلی
- خصوصی
- مشکل
- روند
- پردازنده ها
- محصول
- پیشرفت
- ارائه
- ارائه
- عمومی
- هدف
- پــایتــون
- مارماهی
- رمپ
- محدوده
- نرخ
- آمادگی
- مطالعه
- واقعی
- زمان واقعی
- دلیل
- گرفتن
- دریافت
- كاهش دادن
- را کاهش می دهد
- اشاره دارد
- منطقه
- منتشر شد
- برداشتن
- درخواست
- نیاز
- نیاز
- منابع
- نتایج
- دور
- دویدن
- در حال اجرا
- همان
- پس انداز
- مقیاس پذیری
- مقیاس
- مقیاس گذاری
- سناریو
- علم
- علم و تکنولوژی
- اسکریپت
- دوم
- نسل دوم
- ارشد
- خدمات
- تنظیم
- برپایی
- اشتراک گذاری
- صدف
- نشان داده شده
- نشان می دهد
- ساده
- به سادگی
- تنها
- اندازه
- So
- راه حل
- برخی از
- دهانه ها
- تخصص دارد
- مشخص شده
- سرعت
- چرخش
- شروع
- آغاز شده
- دولت
- وضعیت
- مراحل
- ذخیره سازی
- قوی
- ارسال
- ارسال
- ارسال
- زیر شبکه
- زیرشبکه ها
- موفقیت
- چنین
- اجلاس
- ابر کامپیوتر
- پشتیبانی
- سیستم
- طول می کشد
- پیشرفته
- تنیس
- جریان تنسور
- پایانه
- وابسته به تکزاس
- La
- شان
- در نتیجه
- از طریق
- توان
- زمان
- بار
- به
- امروز
- ابزار
- ابزار
- جمع
- قطار
- آموزش
- ترجمه
- به طور معمول
- اوبونتو
- دانشگاه
- نزدیک
- به روز رسانی
- URL
- استفاده
- استفاده کنید
- کاربر
- ارزش
- تنوع
- بررسی
- نسخه
- از طريق
- چشم انداز
- مجازی
- هفته
- که
- در حین
- وسیع
- اراده
- در داخل
- بدون
- مهاجرت کاری
- خواهد بود
- بسته بندی کردن
- یامل
- شما
- زفیرنت
- صفر
- مناطق