چه زمانی OpenAI نسل سوم مدل یادگیری ماشینی (ML) خود را که در تولید متن تخصص دارد در جولای 2020 منتشر کردند، می دانستم که چیزی متفاوت است. این مدل اعصابی را که هیچ کس قبل از آن نیامده بود به هم زد. ناگهان شنیدم دوستان و همکارانی که ممکن است به فناوری علاقه مند باشند اما معمولاً به آخرین پیشرفت ها در فضای AI/ML اهمیت نمی دهند، در مورد آن صحبت کردند. حتی گاردین هم نوشت یک مقاله در مورد آن یا به طور دقیق، مدل مقاله را نوشت و گاردین آن را ویرایش و منتشر کرد. قابل انکار نبود - GPT-3 یک تغییر دهنده بازی بود
پس از انتشار این مدل، مردم بلافاصله شروع به ارائه برنامه های کاربردی بالقوه برای آن کردند. در عرض چند هفته، بسیاری از دموهای چشمگیر ایجاد شد که میتوان آنها را در آن یافت وب سایت GPT-3. یک برنامه خاص که توجه من را جلب کرد این بود خلاصه سازی متن – توانایی کامپیوتر برای خواندن یک متن داده شده و خلاصه کردن محتوای آن. این یکی از سخت ترین کارها برای رایانه است زیرا دو زمینه را در زمینه پردازش زبان طبیعی (NLP) ترکیب می کند: درک مطلب و تولید متن. به همین دلیل است که من تحت تأثیر دموهای GPT-3 برای خلاصه سازی متن قرار گرفتم.
می توانید آنها را امتحان کنید وب سایت Hugging Face Spaces. مورد علاقه من در حال حاضر یک است استفاده که خلاصه ای از مقالات خبری را فقط با URL مقاله به عنوان ورودی تولید می کند.
در این مجموعه دو قسمتی، من یک راهنمای عملی برای سازمان ها پیشنهاد می کنم تا بتوانید کیفیت مدل های خلاصه سازی متن را برای دامنه خود ارزیابی کنید.
نمای کلی آموزش
بسیاری از سازمانهایی که با آنها کار میکنم (موسسات خیریه، شرکتها، سازمانهای غیردولتی) تعداد زیادی متون دارند که باید آنها را بخوانند و خلاصه کنند - گزارشهای مالی یا مقالات خبری، مقالات علمی تحقیقاتی، درخواستهای ثبت اختراع، قراردادهای قانونی و موارد دیگر. طبیعتاً این سازمان ها علاقه مند هستند که این وظایف را با فناوری NLP خودکار کنند. برای نشان دادن هنر ممکن، اغلب از دموهای خلاصهسازی متن استفاده میکنم که تقریباً هرگز تحت تأثیر قرار نمیگیرند.
اما حالا چه؟
چالشی که برای این سازمانها وجود دارد این است که میخواهند مدلهای خلاصهسازی متن را بر اساس خلاصههای بسیاری از اسناد ارزیابی کنند - نه یکبار. آنها نمی خواهند کارآموزی را استخدام کنند که تنها کارش باز کردن برنامه، چسباندن یک سند، ضربه زدن به خلاصه کردن را فشار دهید، منتظر خروجی باشید، بررسی کنید که آیا خلاصه خوب است یا خیر، و این کار را دوباره برای هزاران سند انجام دهید.
من این آموزش را با در نظر گرفتن خود گذشتهام از چهار هفته پیش نوشتم - این آموزشی است که آرزو میکردم در آن زمان وقتی این سفر را شروع کردم، داشتم. از این نظر، مخاطب هدف این آموزش، فردی است که با AI/ML آشنایی دارد و قبلاً از مدلهای Transformer استفاده کرده است، اما در ابتدای سفر خلاصهسازی متن خود است و میخواهد عمیقتر در آن غواصی کند. از آنجا که توسط یک "مبتدی" و برای مبتدیان نوشته شده است، می خواهم بر این واقعیت تأکید کنم که این آموزش a راهنمای عملی - نه la راهنمای عملی لطفا با آن طوری رفتار کنید که انگار جرج EP باکس گفته بود:
![]()
از نظر میزان دانش فنی مورد نیاز در این آموزش: این آموزش شامل مقداری کدنویسی در پایتون است، اما بیشتر اوقات ما فقط از کد برای فراخوانی APIها استفاده میکنیم، بنابراین به دانش کدنویسی عمیق نیز نیاز نیست. آشنایی با مفاهیم خاصی از ML، مانند معنای آن، مفید است قطار و گسترش یک مدل، مفاهیم پرورش, اعتبار سنجیو مجموعه داده های آزمایشی، و غیره. همچنین داشتن با کتابخانه ترانسفورماتورها قبل ممکن است مفید باشد، زیرا ما از این کتابخانه به طور گسترده در طول این آموزش استفاده می کنیم. من همچنین پیوندهای مفیدی را برای مطالعه بیشتر برای این مفاهیم گنجانده ام.
از آنجایی که این آموزش توسط یک مبتدی نوشته شده است، من انتظار ندارم که متخصصان NLP و متخصصان آموزش عمیق پیشرفته، بخش زیادی از این آموزش را دریافت کنند. حداقل از منظر فنی نه - ممکن است هنوز از خواندن لذت ببرید، بنابراین لطفاً هنوز آن را ترک نکنید! اما با توجه به سادهسازیهای من باید صبور باشید - من سعی کردم با مفهوم ساده کردن همه چیز در این آموزش تا حد امکان، اما نه سادهتر زندگی کنم.
ساختار این آموزش
این مجموعه شامل چهار بخش است که به دو پست تقسیم می شود، که در آن مراحل مختلف یک پروژه خلاصه سازی متن را طی می کنیم. در اولین پست (بخش 1)، با معرفی یک معیار برای وظایف خلاصهسازی متن شروع میکنیم - معیاری از عملکرد که به ما امکان میدهد خوب یا بد بودن خلاصه را ارزیابی کنیم. ما همچنین مجموعه دادهای را که میخواهیم خلاصه کنیم معرفی میکنیم و با استفاده از یک مدل بدون ML یک خط پایه ایجاد میکنیم - از یک اکتشافی ساده برای تولید خلاصهای از یک متن داده شده استفاده میکنیم. ایجاد این خط پایه یک گام بسیار مهم در هر پروژه ML است، زیرا ما را قادر میسازد تا میزان پیشرفت خود را با استفاده از هوش مصنوعی در آینده تعیین کنیم. این به ما اجازه می دهد به این سوال پاسخ دهیم که "آیا واقعا ارزش سرمایه گذاری در فناوری هوش مصنوعی را دارد؟"
در پست دوم، از مدلی استفاده میکنیم که قبلاً برای تولید خلاصهها آموزش داده شده است (بخش 2). این امر با یک رویکرد مدرن در ML به نام امکان پذیر است انتقال یادگیری. این یک گام مفید دیگر است زیرا ما اساساً یک مدل خارج از قفسه را انتخاب می کنیم و آن را روی مجموعه داده خود آزمایش می کنیم. این به ما امکان میدهد خط پایه دیگری ایجاد کنیم، که به ما کمک میکند ببینیم وقتی واقعاً مدل را روی مجموعه داده خود آموزش میدهیم، چه اتفاقی میافتد. رویکرد نامیده می شود خلاصه سازی صفر شات، زیرا این مدل با مجموعه داده ما در معرض صفر قرار گرفته است.
پس از آن، زمان استفاده از یک مدل از پیش آموزش دیده و آموزش آن بر روی مجموعه داده های خودمان است (بخش 3). این نیز نامیده می شود تنظیم دقیق. این مدل را قادر میسازد تا از الگوها و ویژگیهای خاص دادههای ما بیاموزد و به آرامی با آن سازگار شود. پس از آموزش مدل، از آن برای ایجاد خلاصه استفاده می کنیم (بخش 4).
به طور خلاصه:
- 1 بخش:
- بخش 1: از یک مدل بدون ML برای ایجاد یک خط مبنا استفاده کنید
- قسمت 2:
- بخش 2: ایجاد خلاصه با یک مدل صفر شات
- بخش 3: یک مدل خلاصه سازی را آموزش دهید
- بخش 4: مدل آموزش دیده را ارزیابی کنید
کد کامل این آموزش در ادامه مطلب موجود است GitHub repo.
در پایان این آموزش چه چیزی به دست خواهیم آورد؟
در پایان این آموزش، ما نه دارای یک مدل خلاصه سازی متن است که می تواند در تولید استفاده شود. ما حتی یک نخواهیم داشت خوب مدل خلاصه سازی (اموجی جیغ را اینجا قرار دهید)!
آنچه در عوض خواهیم داشت، نقطه شروعی برای فاز بعدی پروژه است که مرحله آزمایش است. اینجاست که «علم» در علم داده مطرح میشود، زیرا اکنون همه چیز در مورد آزمایش مدلهای مختلف و تنظیمات مختلف است تا بفهمیم آیا میتوان یک مدل خلاصهسازی کافی را با دادههای آموزشی موجود آموزش داد.
و برای شفافیت کامل، احتمال زیادی وجود دارد که نتیجه گیری این باشد که فناوری هنوز به بلوغ نرسیده است و پروژه اجرا نخواهد شد. و شما باید سهامداران کسب و کار خود را برای این امکان آماده کنید. اما این موضوع برای پست دیگری است.
بخش 1: از یک مدل بدون ML برای ایجاد یک خط مبنا استفاده کنید
این اولین بخش از آموزش ما در مورد راه اندازی یک پروژه خلاصه سازی متن است. در این بخش، با استفاده از یک مدل بسیار ساده، بدون استفاده از ML، یک خط مبنا ایجاد می کنیم. این یک گام بسیار مهم در هر پروژه ML است، زیرا به ما این امکان را می دهد تا بفهمیم که ML در طول زمان پروژه چقدر ارزش اضافه می کند و آیا ارزش سرمایه گذاری روی آن را دارد یا خیر.
کد آموزش را می توانید در ادامه مطلب مشاهده کنید GitHub repo.
داده ، داده ، داده
هر پروژه ML با داده شروع می شود! در صورت امکان، همیشه باید از داده های مربوط به آنچه می خواهیم با پروژه خلاصه سازی متن به دست آوریم استفاده کنیم. به عنوان مثال، اگر هدف ما خلاصه کردن درخواست های ثبت اختراع است، باید از برنامه های ثبت اختراع نیز برای آموزش مدل استفاده کنیم. یک هشدار بزرگ برای پروژه ML این است که داده های آموزشی معمولاً باید برچسب گذاری شوند. در زمینه خلاصه سازی متن، به این معنی است که باید متنی را که باید خلاصه شود و همچنین خلاصه (برچسب) ارائه کنیم. تنها با ارائه هر دو مدل می تواند یاد بگیرد که یک خلاصه خوب چگونه به نظر می رسد.
در این آموزش، ما از یک مجموعه داده در دسترس عموم استفاده می کنیم، اما اگر از یک مجموعه داده سفارشی یا خصوصی استفاده کنیم، مراحل و کد دقیقاً یکسان باقی می مانند. و دوباره، اگر هدفی برای مدل خلاصهسازی متن خود در نظر دارید و دادههای مربوطه را دارید، لطفاً به جای آن از دادههای خود استفاده کنید تا بیشترین بهره را از آن ببرید.
داده ای که ما استفاده می کنیم همان است مجموعه داده arXiv، که شامل چکیده مقالات arXiv و همچنین عناوین آنها می باشد. برای هدف خود، از چکیده به عنوان متنی که می خواهیم خلاصه کنیم و عنوان را به عنوان خلاصه مرجع استفاده می کنیم. تمامی مراحل دانلود و پیش پردازش داده ها در ادامه مطلب موجود است دفتر یادداشت. ما نیاز داریم هویت AWS و مدیریت دسترسی نقش (IAM) که اجازه بارگیری داده ها را به و از آن می دهد سرویس ذخیره سازی ساده آمازون (Amazon S3) به منظور اجرای موفقیت آمیز این نوت بوک. مجموعه داده به عنوان بخشی از مقاله توسعه داده شد در مورد استفاده از ArXiv به عنوان مجموعه داده و دارای مجوز تحت Creative Commons CC0 1.0 اختصاص دامنه عمومی جهانی.
داده ها به سه مجموعه داده تقسیم می شوند: آموزش، اعتبار سنجی و داده های آزمایشی. اگر می خواهید از داده های خود استفاده کنید، مطمئن شوید که این مورد نیز وجود دارد. نمودار زیر نحوه استفاده از مجموعه داده های مختلف را نشان می دهد.
![]()
به طور طبیعی، یک سوال رایج در این مرحله این است: به چه مقدار داده نیاز داریم؟ همانطور که احتمالاً می توانید حدس بزنید، پاسخ این است: بستگی دارد. بستگی به این دارد که دامنه چقدر تخصصی باشد (خلاصه کردن درخواست های ثبت اختراع با خلاصه کردن مقالات خبری کاملاً متفاوت است)، چقدر مدل باید دقیق باشد تا مفید باشد، هزینه آموزش مدل چقدر باید باشد و غیره. زمانی که واقعاً مدل را آموزش میدهیم، به این سؤال باز میگردیم، اما کوتاهتر از آن این است که وقتی در مرحله آزمایشی پروژه هستیم، باید اندازههای دادههای مختلف را امتحان کنیم.
یک مدل خوب چیست؟
در بسیاری از پروژه های ML، اندازه گیری عملکرد یک مدل نسبتاً ساده است. دلیلش این است که معمولاً ابهام کمی در مورد درست بودن نتیجه مدل وجود دارد. برچسبهای مجموعه داده اغلب باینری (درست/نادرست، بله/خیر) یا دستهبندی هستند. در هر صورت، در این سناریو به راحتی می توان خروجی مدل را با برچسب مقایسه کرد و آن را به عنوان صحیح یا نادرست علامت گذاری کرد.
هنگام تولید متن، این کار چالش برانگیزتر می شود. خلاصهها (برچسبهایی) که در مجموعه دادههای خود ارائه میکنیم، تنها یک راه برای خلاصه کردن متن هستند. اما امکانات زیادی برای خلاصه کردن یک متن داده شده وجود دارد. بنابراین، حتی اگر مدل با برچسب ما مطابقت نداشته باشد 1:1، ممکن است خروجی همچنان یک خلاصه معتبر و مفید باشد. پس چگونه خلاصه مدل را با آنچه ارائه می کنیم مقایسه کنیم؟ معیاری که اغلب در خلاصه سازی متن برای اندازه گیری کیفیت یک مدل استفاده می شود امتیاز ROUGE. برای درک مکانیک این متریک به معیار عملکرد نهایی در NLP. به طور خلاصه، امتیاز ROUGE همپوشانی را اندازه گیری می کند n-گرم (توالی به هم پیوسته از n موارد) بین خلاصه مدل (خلاصه نامزد) و خلاصه مرجع (برچسبی که در مجموعه داده خود ارائه می کنیم). اما، البته، این یک معیار کامل نیست. برای درک محدودیت های آن، بررسی کنید به ROUGE یا نه به ROUGE؟
بنابراین، چگونه امتیاز ROUGE را محاسبه کنیم؟ تعداد زیادی بسته پایتون برای محاسبه این متریک وجود دارد. برای اطمینان از سازگاری، باید از همان روش در سراسر پروژه خود استفاده کنیم. از آنجایی که ما در مرحله بعدی این آموزش از یک اسکریپت آموزشی از کتابخانه Transformers به جای نوشتن اسکریپت خود استفاده خواهیم کرد، میتوانیم فقط به این اسکریپت نگاه کنیم. کد منبع از اسکریپت و کدی که امتیاز ROUGE را محاسبه می کند کپی کنید:
با استفاده از این روش برای محاسبه امتیاز، اطمینان حاصل می کنیم که همیشه سیب ها را با سیب در طول پروژه مقایسه می کنیم.
این تابع چندین امتیاز ROUGE را محاسبه می کند: rouge1, rouge2, rougeLو rougeLsum. "جمع" در rougeLsum به این واقعیت اشاره دارد که این متریک بر روی یک خلاصه کامل محاسبه می شود، در حالی که rougeL به عنوان میانگین بر روی جملات فردی محاسبه می شود. بنابراین، از کدام نمره ROUGE باید برای پروژه خود استفاده کنیم؟ باز هم باید رویکردهای مختلفی را در مرحله آزمایش امتحان کنیم. برای آنچه ارزش دارد، کاغذ ROUGE اصلی بیان میکند که «ROUGE-2 و ROUGE-L در وظایف خلاصهسازی سند به خوبی کار میکنند» در حالی که «ROUGE-1 و ROUGE-L در ارزیابی خلاصههای کوتاه عالی عمل میکنند».
خط پایه را ایجاد کنید
در مرحله بعد می خواهیم با استفاده از یک مدل ساده و بدون ML خط پایه را ایجاد کنیم. معنی آن چیست؟ در زمینه خلاصه سازی متن، بسیاری از مطالعات از یک رویکرد بسیار ساده استفاده می کنند: آنها اولین را انتخاب می کنند n جملات متن را به عنوان خلاصه نامزد اعلام کنید. سپس خلاصه نامزد را با خلاصه مرجع مقایسه می کنند و امتیاز ROUGE را محاسبه می کنند. این یک رویکرد ساده و در عین حال قدرتمند است که میتوانیم آن را در چند خط کد پیادهسازی کنیم (کل کد این بخش در زیر آمده است. دفتر یادداشت):
ما از مجموعه داده تست برای این ارزیابی استفاده می کنیم. این منطقی است زیرا پس از آموزش مدل، از همان مجموعه داده آزمایشی برای ارزیابی نهایی نیز استفاده میکنیم. ما همچنین اعداد مختلف را امتحان می کنیم n: فقط با اولین جمله به عنوان خلاصه نامزد شروع می کنیم، سپس دو جمله اول و در نهایت سه جمله اول.
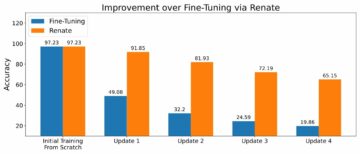
تصویر زیر نتایج را برای اولین مدل ما نشان می دهد.
![]()
نمرات ROUGE بالاترین امتیاز را دارند و تنها جمله اول به عنوان خلاصه نامزد است. این به این معنی است که گرفتن بیش از یک جمله خلاصه را بیش از حد پرمخاطب می کند و منجر به نمره کمتر می شود. بنابراین این بدان معناست که ما از نمرات خلاصه های یک جمله ای به عنوان خط پایه خود استفاده خواهیم کرد.
توجه به این نکته مهم است که برای چنین رویکرد ساده ای، این اعداد در واقع بسیار خوب هستند، به خصوص برای rouge1 نمره. برای قرار دادن این اعداد در متن می توان به مدل های پگاسوس، که امتیازهای یک مدل پیشرفته را برای مجموعه داده های مختلف نشان می دهد.
نتیجه گیری و آنچه در ادامه می آید
در قسمت 1 مجموعه خود، مجموعه داده ای را که در طول پروژه خلاصه سازی استفاده می کنیم و همچنین معیاری برای ارزیابی خلاصه ها معرفی کردیم. سپس خط پایه زیر را با یک مدل ساده و بدون ML ایجاد کردیم.
![]()
در پست بعدی، ما از یک مدل شات صفر استفاده می کنیم - به طور خاص، مدلی که به طور خاص برای خلاصه سازی متن در مقالات خبری عمومی آموزش داده شده است. با این حال، این مدل به هیچ وجه در مجموعه داده های ما آموزش داده نمی شود (از این رو نام "صفر شات").
من آن را به عنوان تکلیف به شما واگذار می کنم تا حدس بزنید که این مدل شات صفر در مقایسه با خط پایه بسیار ساده ما چگونه عمل می کند. از یک طرف، این مدل بسیار پیچیدهتر خواهد بود (در واقع یک شبکه عصبی است). از سوی دیگر، فقط برای خلاصه کردن مقالات خبری استفاده می شود، بنابراین ممکن است با الگوهای ذاتی مجموعه داده arXiv مشکل داشته باشد.
درباره نویسنده
![]() هایکو هاتز یک معمار ارشد راه حل برای AI و یادگیری ماشین است و جامعه پردازش زبان طبیعی (NLP) را در AWS رهبری می کند. قبل از این سمت، او رئیس بخش علوم داده برای خدمات مشتریان اتحادیه اروپا آمازون بود. Heiko به مشتریان ما کمک میکند تا در سفر هوش مصنوعی/ML خود در AWS موفق باشند و با سازمانهایی در بسیاری از صنایع، از جمله بیمه، خدمات مالی، رسانه و سرگرمی، مراقبتهای بهداشتی، خدمات شهری و تولید کار کرده است. هایکو در اوقات فراغت خود تا آنجا که ممکن است سفر می کند.
هایکو هاتز یک معمار ارشد راه حل برای AI و یادگیری ماشین است و جامعه پردازش زبان طبیعی (NLP) را در AWS رهبری می کند. قبل از این سمت، او رئیس بخش علوم داده برای خدمات مشتریان اتحادیه اروپا آمازون بود. Heiko به مشتریان ما کمک میکند تا در سفر هوش مصنوعی/ML خود در AWS موفق باشند و با سازمانهایی در بسیاری از صنایع، از جمله بیمه، خدمات مالی، رسانه و سرگرمی، مراقبتهای بهداشتی، خدمات شهری و تولید کار کرده است. هایکو در اوقات فراغت خود تا آنجا که ممکن است سفر می کند.
- '
- "
- &
- 100
- 2020
- درباره ما
- چکیده
- دسترسی
- دقیق
- دست
- پیشرفته
- پیشرفت
- AI
- معرفی
- قبلا
- آمازون
- ابهام
- مقدار
- دیگر
- رابط های برنامه کاربردی
- کاربرد
- برنامه های کاربردی
- روش
- دور و بر
- هنر
- مقاله
- مقالات
- حضار
- در دسترس
- میانگین
- AWS
- خط مقدم
- اساسا
- شروع
- بودن
- کسب و کار
- صدا
- اهميت دادن
- گرفتار
- به چالش
- رمز
- برنامه نویسی
- مشترک
- انجمن
- شرکت
- مقایسه
- به طور کامل
- محاسبه
- مفهوم
- شامل
- محتوا
- قرارداد
- ایجاد
- سفارشی
- خدمات مشتری
- مشتریان
- داده ها
- علم اطلاعات
- عمیق تر
- توسعه
- مختلف
- اسناد و مدارک
- نمی کند
- دامنه
- سرگرمی
- به خصوص
- ایجاد
- EU
- همه چیز
- مثال
- انتظار
- کارشناسان
- چشم
- چهره
- زمینه
- سرانجام
- مالی
- خدمات مالی
- نام خانوادگی
- پیروی
- به جلو
- یافت
- تابع
- بیشتر
- بازی
- تولید می کنند
- نسل
- هدف
- رفتن
- خوب
- بزرگ
- نگهبان
- راهنمایی
- داشتن
- سر
- بهداشت و درمان
- مفید
- کمک می کند
- اینجا کلیک نمایید
- استخدام
- چگونه
- HTTPS
- بزرگ
- هویت
- انجام
- اجرا
- مهم
- شامل
- از جمله
- فرد
- لوازم
- بیمه
- معرفی
- سرمایه گذاری
- IT
- کار
- جولای
- کلید
- دانش
- برچسب ها
- زبان
- آخرین
- منجر می شود
- یاد گرفتن
- یادگیری
- ترک کردن
- قانونی
- کتابخانه
- مجاز
- لینک ها
- کوچک
- دستگاه
- فراگیری ماشین
- باعث می شود
- ساخت
- تولید
- علامت
- مسابقه
- اندازه
- رسانه ها
- ذهن
- ML
- مدل
- مدل
- بیش
- اکثر
- طبیعی
- شبکه
- اخبار
- دفتر یادداشت
- تعداد
- باز کن
- سفارش
- سازمان های
- دیگر
- مقاله
- حق ثبت اختراع
- مردم
- کارایی
- چشم انداز
- فاز
- نقطه
- فرصت
- امکان
- ممکن
- پست ها
- پتانسیل
- قوی
- خصوصی
- تولید
- پروژه
- پروژه ها
- پیشنهادات
- ارائه
- ارائه
- عمومی
- هدف
- کیفیت
- سوال
- محدوده
- RE
- مطالعه
- گزارش ها
- نیاز
- ضروری
- تحقیق
- نتایج
- دویدن
- سعید
- علم
- حس
- سلسله
- سرویس
- خدمات
- تنظیم
- محیط
- کوتاه
- ساده
- So
- مزایا
- کسی
- چیزی
- مصنوعی
- فضا
- فضاها
- تخصصی
- تخصص دارد
- به طور خاص
- انشعاب
- شروع
- آغاز شده
- شروع می شود
- وضعیت هنر
- ایالات
- ذخیره سازی
- فشار
- مطالعات
- موفق
- موفقیت
- صحبت
- هدف
- وظایف
- فنی
- پیشرفته
- آزمون
- هزاران نفر
- از طریق
- سراسر
- زمان
- عنوان
- آموزش
- شفاف
- درمان
- نهایی
- فهمیدن
- جهانی
- us
- استفاده کنید
- معمولا
- ارزش
- صبر کنيد
- چی
- چه
- WHO
- ویکیپدیا
- در داخل
- بدون
- مهاجرت کاری
- مشغول به کار
- با ارزش
- نوشته
- X
- صفر