تنظیم مدل فرآیند آزمایشی یافتن پارامترها و تنظیمات بهینه برای یک مدل یادگیری ماشینی (ML) است که به بهترین نتیجه ممکن با مجموعه داده اعتبار سنجی منجر میشود. بهینه سازی تک هدف با معیار عملکرد رایج ترین رویکرد برای تنظیم مدل های ML است. با این حال، علاوه بر عملکرد پیشبینیکننده، ممکن است اهداف متعددی وجود داشته باشد که باید برای کاربردهای خاصی در نظر گرفته شوند. مثلا،
- انصاف - هدف در اینجا تشویق مدل ها برای کاهش تعصب در نتایج مدل بین گروه های فرعی خاص در داده ها است، به ویژه زمانی که انسان ها در معرض تصمیمات الگوریتمی هستند. به عنوان مثال، درخواست وام اعتباری نه تنها باید دقیق باشد، بلکه باید برای زیرگروه های مختلف جمعیت نیز بی طرف باشد.
- زمان استنتاج - هدف در اینجا کاهش زمان استنتاج در طول فراخوانی مدل است. به عنوان مثال، یک سیستم تشخیص گفتار نه تنها باید لهجه های مختلف یک زبان را به طور دقیق درک کند، بلکه باید در یک محدودیت زمانی مشخص که توسط فرآیند تجاری قابل قبول است عمل کند.
- بهره وری انرژی - هدف در اینجا آموزش مدل های کوچکتر کم مصرف است. به عنوان مثال، مدلهای شبکه عصبی برای استفاده در دستگاههای تلفن همراه فشرده میشوند و بنابراین به طور طبیعی مصرف انرژی آنها را با کاهش تعداد FLOPS مورد نیاز برای عبور از شبکه کاهش میدهند.
روشهای بهینهسازی چند هدفه، مبادلات متفاوتی را بین معیارهای مورد نظر نشان میدهند. این می تواند شامل یافتن یک حداقل کلی از یک تابع هدف باشد که در آن مجموعه ای از محدودیت ها در معیارهای مختلف به طور همزمان برآورده شوند.
تنظیم خودکار مدل Amazon SageMaker (AMT) با اجرای بسیاری از کارهای آموزشی SageMaker روی مجموعه داده شما با استفاده از الگوریتم و محدوده هایپرپارامترها، بهترین نسخه یک مدل را پیدا می کند. سپس مقادیر فراپارامتر را انتخاب میکند که منجر به مدلی میشود که بهترین عملکرد را دارد، همانطور که توسط متریک (مثلاً دقت، auc، یادآوری) که شما تعریف میکنید اندازهگیری میشود. با تنظیم خودکار مدل Amazon SageMaker، میتوانید بهترین نسخه مدل خود را با اجرای کارهای آموزشی در مجموعه داده خود با چندین استراتژی جستجو، مانند Bayesian، Random Search، Grid Search و Hyperband.
Amazon SageMaker Clarify می تواند سوگیری احتمالی را در طول آماده سازی داده ها، پس از آموزش مدل، و در مدل مستقر شما تشخیص دهد. در حال حاضر، 21 معیار مختلف را برای انتخاب ارائه می دهد. این معیارها نیز به صورت آشکار در دسترس هستند شفاف کردن بسته پایتون و مخزن github اینجا کلیک نمایید. میتوانید از Amazon SageMaker Clarify درباره اندازهگیری سوگیری با معیارها اطلاعات بیشتری کسب کنید بیاموزید که چگونه Amazon SageMaker Clarify به تشخیص سوگیری کمک می کند.
در این وبلاگ به شما نشان می دهیم که چگونه با ایجاد یک معیار ترکیبی واحد، یک مدل ML را با Amazon SageMaker AMT برای اهداف دقت و انصاف تنظیم کنید. ما یک مورد استفاده از خدمات مالی از پیشبینی ریسک اعتباری را با معیار دقت نشان میدهیم ناحیه زیر منحنی (AUC) برای اندازه گیری عملکرد و یک متریک سوگیری از تفاوت در نسبت های مثبت در برچسب های پیش بینی شده (DPPL) از SageMaker Clarify برای اندازهگیری عدم تعادل در پیشبینیهای مدل برای گروههای جمعیتی مختلف. کد این مثال در دسترس است GitHub.
انصاف در پیش بینی ریسک اعتباری
صنعت وامدهی اعتباری برای پردازش درخواستهای وام به شدت به امتیازات اعتباری متکی است. به طور کلی، امتیازات اعتباری منعکس کننده سابقه وام گرفتن و بازپرداخت پول متقاضی است و وام دهندگان هنگام تعیین اعتبار یک فرد به آنها اشاره می کنند. شرکتهای پرداخت و بانکها علاقهمند به ایجاد سیستمهایی هستند که میتواند به شناسایی ریسک مرتبط با یک برنامه خاص کمک کند و محصولات اعتباری رقابتی را ارائه دهد. مدلهای یادگیری ماشینی (ML) را میتوان برای ساخت چنین سیستمی استفاده کرد که دادههای متقاضی تاریخی را پردازش کرده و نمایه ریسک اعتباری را پیشبینی میکند. داده ها می تواند شامل تاریخچه مالی و شغلی متقاضی، جمعیت شناسی آنها و زمینه اعتبار / وام جدید باشد. همیشه برخی از عدم قطعیت های آماری با هر مدلی که پیش بینی می کند آیا یک متقاضی خاص در آینده نکول می کند وجود دارد. سیستمها باید بین رد برنامههایی که ممکن است به مرور زمان پیشفرض میشوند و پذیرش برنامههایی که در نهایت اعتبار دارند، تعادل ایجاد کنند.
صاحبان مشاغل چنین سیستمی باید از اعتبار و کیفیت مدل ها مطابق با الزامات انطباق مقرراتی موجود و آتی اطمینان حاصل کنند. آنها موظف به رفتار منصفانه با مشتریان و ایجاد شفافیت در تصمیم گیری آنها هستند. آنها ممکن است بخواهند اطمینان حاصل کنند که پیشبینیهای مدل مثبت در بین گروههای مختلف (مثلاً جنسیت، نژاد، قومیت، وضعیت مهاجرت و دیگران) نامتعادل نباشد. هنگامی که دادههای مورد نیاز جمعآوری شد، آموزش مدل ML معمولاً برای عملکرد پیشبینی بهعنوان هدف اصلی با معیارهایی مانند دقت طبقهبندی یا امتیاز AUC بهینه میشود. از طرف دیگر، یک مدل با یک هدف عملکرد معین را می توان با یک معیار انصاف محدود کرد تا اطمینان حاصل شود که الزامات خاصی حفظ می شوند. یکی از این تکنیکها برای محدود کردن مدل، تنظیم فراپارامتر آگاه از انصاف است. با استفاده از این استراتژیها، بهترین مدل کاندید میتواند سوگیری کمتری نسبت به مدل بدون محدودیت داشته باشد و در عین حال عملکرد پیشبینی بالایی را حفظ کند.

در سناریویی که در این شماتیک نشان داده شده است،
- مدل ML با داده های پروفایل اعتباری مشتری تاریخی ساخته شده است. آموزش مدل و فرآیند تنظیم فراپارامتر برای اهداف متعدد از جمله دقت طبقه بندی و انصاف به حداکثر می رسد. این مدل در یک فرآیند تجاری موجود در یک سیستم تولید مستقر شده است.
- یک پروفایل اعتباری جدید مشتری برای ریسک اعتباری ارزیابی می شود. اگر خطر کم باشد، می تواند از طریق یک فرآیند خودکار انجام شود. برنامه های پرخطر می تواند شامل بررسی انسانی قبل از تصمیم نهایی پذیرش یا رد باشد.
تصمیمات و معیارهای جمع آوری شده در طول طراحی و توسعه، استقرار و عملیات را می توان با آنها مستند کرد کارت های مدل SageMaker و با ذینفعان به اشتراک گذاشته شود.
این مورد استفاده نشان میدهد که چگونه میتوان تعصب مدل را در برابر یک گروه خاص با تنظیم دقیق فراپارامترها برای یک متریک هدف ترکیبی از دقت و انصاف با تنظیم خودکار مدل SageMaker کاهش داد. ما از مجموعه داده اعتبار آلمان جنوبی (مجموعه داده های اعتباری آلمان جنوبی).
داده های متقاضی را می توان به دسته های زیر تقسیم کرد:
- جمعیت شناسی
- اطلاعات مالی
- تاریخچه استخدام
- هدف وام
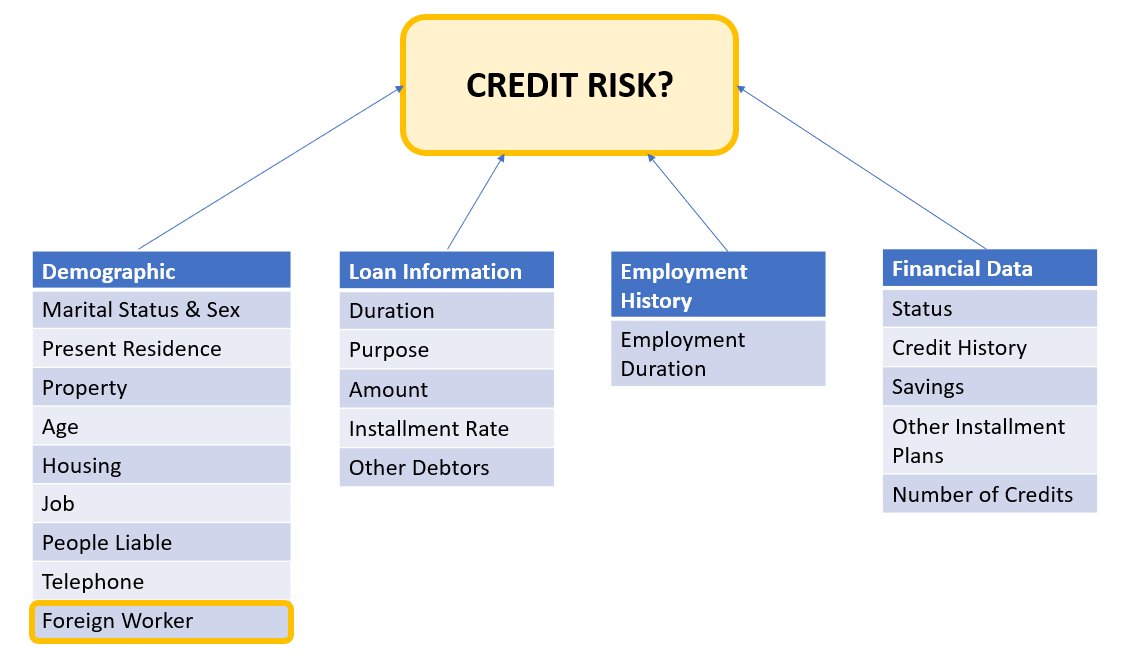
در این مثال، ما به طور خاص به جمعیت شناسی «کارگر خارجی» نگاه می کنیم و مدلی را تنظیم می کنیم که تصمیمات درخواست اعتبار را با دقت بالا و سوگیری کم در برابر آن زیر گروه خاص پیش بینی می کند.
مختلف وجود دارد معیارهای تعصب که می تواند برای ارزیابی عادلانه بودن سیستم با توجه به زیر گروه های خاص در داده ها استفاده شود. در اینجا، ما از مقدار مطلق تفاوت در نسبت های مثبت در برچسب های پیش بینی شده استفاده می کنیم (DPPL) از SageMaker Clarify. به عبارت ساده، DPPL تفاوت در تکالیف کلاس مثبت (اعتبار خوب) بین کارگران غیر خارجی و کارگران خارجی را اندازه گیری می کند.
به عنوان مثال، اگر 4.5٪ از همه کارگران خارجی توسط مدل برچسب مثبت و 13.7٪ از همه کارگران غیر خارجی برچسب مثبت را دریافت کنند، آنگاه DPPL = 0.137 – 0.045 = 0.092.
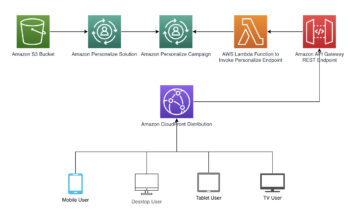
معماری راه حل
شکل زیر نمای کلی سطح بالایی از معماری یک کار تنظیم خودکار مدل با XGBoost در Amazon SageMaker را نشان می دهد.
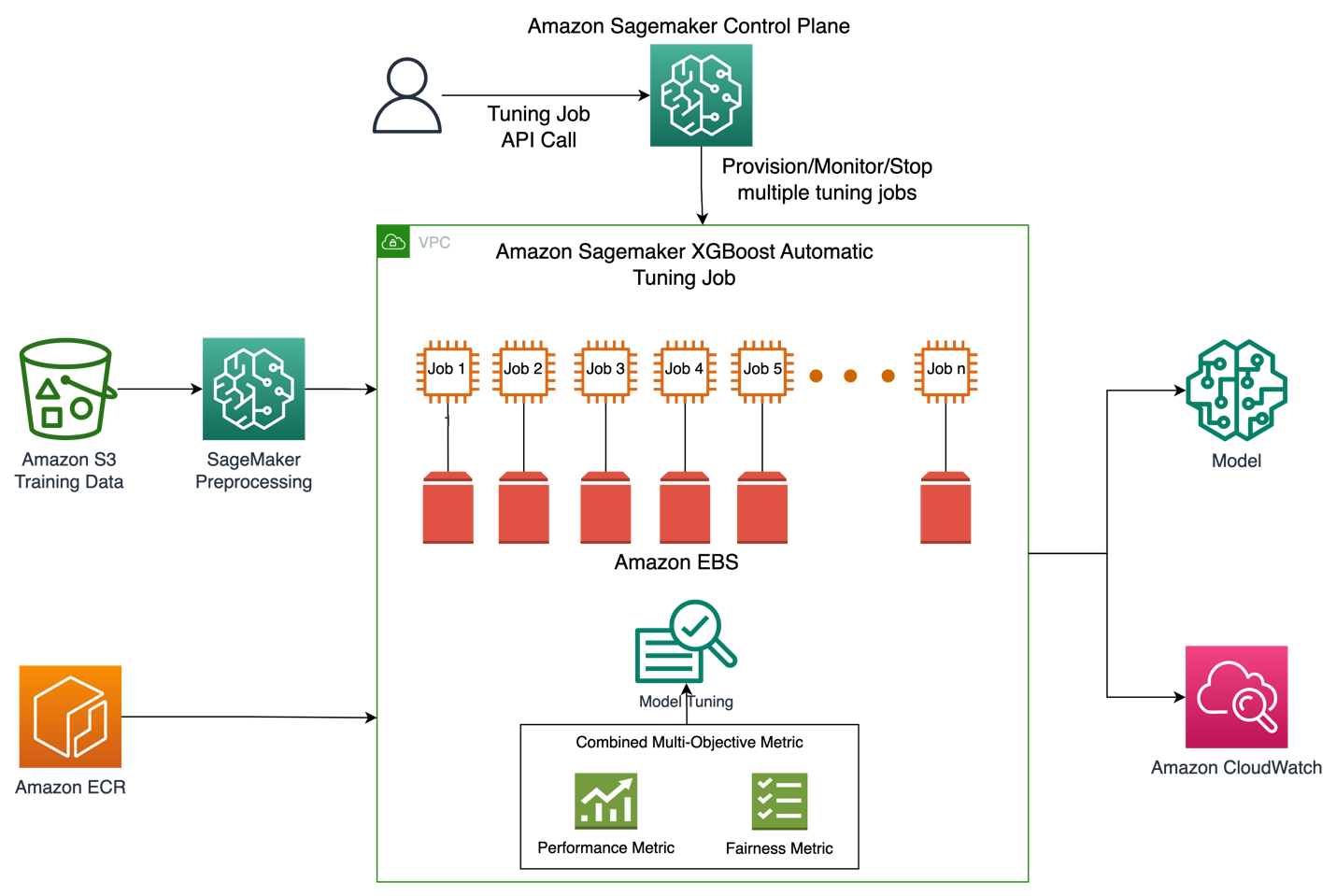
در راه حل، SageMaker Processing مجموعه داده های آموزشی را از Amazon S3 پیش پردازش می کند. آمازون SageMaker Automatic Tuning چندین کار آموزشی SageMaker را با نمونههای EC2 و حجمهای EBS مرتبط با آنها نشان میدهد. ظرف الگوریتم (XGBoost) از Amazon ECR در هر کار بارگیری می شود. SageMaker AMT بهترین نسخه یک مدل را با اجرای بسیاری از کارهای آموزشی بر روی مجموعه داده از پیش پردازش شده با استفاده از اسکریپت الگوریتم مشخص شده و محدوده فراپارامترها پیدا می کند. معیارهای خروجی برای نظارت در آمازون CloudWatch ثبت شده است.
هایپرپارامترهایی که در این مورد استفاده می کنیم به شرح زیر است:
- اتا - کوچک شدن اندازه پله در به روز رسانی ها برای جلوگیری از برازش بیش از حد استفاده می شود.
- حداقل_وزن_کودک - حداقل مقدار وزن مورد نیاز کودک.
- گاما - حداقل کاهش تلفات مورد نیاز برای ایجاد پارتیشن بیشتر روی یک گره برگ درخت.
- بیشترین عمق - حداکثر عمق یک درخت
تعریف این هایپرپارامترها و سایر پارامترهای موجود با SageMaker AMT را می توان یافت اینجا کلیک نمایید.
ابتدا، ما یک سناریوی پایه از یک معیار هدف عملکرد واحد برای تنظیم فراپارامترها با تنظیم خودکار مدل نشان میدهیم. سپس، سناریوی بهینه شده یک متریک چند هدفه را که به عنوان ترکیبی از معیار عملکرد و معیار انصاف مشخص شده است، نشان میدهیم.
تنظیم فراپارامتر تک متریک (پایه)
برای ارزیابی تک تک مشاغل آموزشی، چندین معیار برای یک کار تنظیم وجود دارد. مطابق قطعه کد زیر، متریک تک هدف را به عنوان مشخص می کنیم objective_metric_name. کار تنظیم فراپارامتر، کار آموزشی را برمیگرداند که بهترین مقدار را برای متریک هدف انتخابی داده است.
در این سناریوی پایه، همانطور که در زیر مشاهده میکنید، در حال تنظیم منطقه زیر منحنی (AUC) هستیم. توجه به این نکته مهم است که ما فقط AUC را بهینه میکنیم و برای معیارهای دیگر مانند عدالت بهینه نمیکنیم.
from sagemaker.tuner import IntegerParameter, CategoricalParameter, ContinuousParameter, HyperparameterTuner hyperparameter_ranges = {'eta': ContinuousParameter(0, 1), 'min_child_weight': IntegerParameter(1, 10), 'gamma': IntegerParameter(1, 5), 'max_depth': IntegerParameter(1, 10)} objective_metric_name = 'validation:auc' tuner = HyperparameterTuner(estimator,
objective_metric_name,
hyperparameter_ranges,
max_jobs=100,
max_parallel_jobs=10,
) tuning_job_name = "xgb-tuner-{}".format(strftime("%d-%H-%M-%S", gmtime()))
inputs = {'train': train_data_path, 'validation': val_data_path}
tuner.fit(inputs, job_name=tuning_job_name)
tuner.wait()
tuner_metrics = sagemaker.HyperparameterTuningJobAnalytics(tuning_job_name)در این زمینه max jobs به ما امکان می دهد مشخص کنیم که یک کار آموزشی چند بار تنظیم شود و بهترین شغل آموزشی را از آنجا پیدا کنیم.
تنظیم فراپارامتر چند هدفه (بهینه سازی منصفانه)
ما می خواهیم معیارهای هدف چندگانه را با تنظیم هایپرپارامتر همانطور که در این توضیح داده شده است بهینه کنیم مقاله. با این حال، SageMaker AMT هنوز تنها یک متریک را به عنوان ورودی می پذیرد.
برای مقابله با این چالش، چندین معیار را به عنوان یک تابع متریک بیان می کنیم و این متریک را بهینه می کنیم:
- maxM(y1,y2,θ)
- y1، y2 معیارهای مختلفی هستند. به عنوان مثال امتیاز AUC و DPPL.
- M(⋅،⋅،θ) یک تابع مقیاس بندی است و با یک پارامتر ثابت پارامتر می شود.
وزن بیشتر به نفع آن هدف خاص در تنظیم مدل است. وزن ها ممکن است از موردی به مورد دیگر محتاط باشند و ممکن است لازم باشد وزن های مختلفی را برای مورد استفاده خود امتحان کنید. در این مثال، وزن برای AUC و DPPL به صورت اکتشافی تنظیم شده است. بیایید از طریق کد چگونه به نظر می رسد. میتوانید کار آموزشی را ببینید که یک معیار واحد را بر اساس تابع ترکیبی از امتیاز AUC برای عملکرد و DPPL برای انصاف برمیگرداند. محدوده بهینه سازی هایپرپارامتر برای اهداف چندگانه با هدف واحد یکسان است. ما معیار اعتبار سنجی را به عنوان "auc" منتقل می کنیم، اما در پشت صحنه نتایج تابع متریک ترکیبی را همانطور که در لیست توابع زیر توضیح داده شد، برمی گردانیم:
در اینجا تابع بهینه سازی چند هدفه است:
objective_metric_name = 'validation:auc'
tuner = HyperparameterTuner(estimator,
objective_metric_name,
hyperparameter_ranges,
max_jobs=100,
max_parallel_jobs=10
)در اینجا تابع محاسبه امتیاز AUC است:
def eval_auc_score(predt, dtrain):
fY = [1 if p > 0.5 else 0 for p in predt]
y = dtrain.get_label()
auc_score = roc_auc_score(y, fY)
return auc_scoreدر اینجا تابع محاسبه امتیاز DPPL است:
def eval_dppl(predt, dtrain):
dtrain_np = dmatrix_to_numpy(dtrain)
# groups: an np array containing 1 or 2
groups = dtrain_np[:, -1]
# sensitive_facet_index: boolean column indicating sensitive group
sensitive_facet_index = pd.Series(groups - 1, dtype=bool)
# positive_predicted_label_index: boolean column indicating positive predicted labels
positive_label_index = pd.Series(predt > 0.5)
return abs(DPPL(predt, sensitive_facet_index, positive_label_index))در اینجا تابع متریک ترکیبی است:
def eval_combined_metric(predt, dtrain):
auc_score = eval_auc_score(predt, dtrain)
DPPL = eval_dppl(predt, dtrain)
# Assign weight of 3 to AUC and 1 to DPPL
# Maximize (1-DPPL) for the purpose of minimizing DPPL combined_metric = ((3*auc_score)+(1-DPPL))/4 print("DPPL, AUC Score, Combined Metric: ", DPPL, auc_score, combined_metric)
return "auc", combined_metricآزمایشات و نتایج
تولید داده مصنوعی برای مجموعه داده سوگیری
مجموعه داده اصلی اعتبار آلمان جنوبی شامل 1000 رکورد بود و ما 100 رکورد دیگر را به صورت مصنوعی ایجاد کردیم تا یک مجموعه داده ایجاد کنیم که در آن سوگیری در پیشبینیهای مدل باعث نارضایتی کارگران خارجی شود. این کار برای شبیه سازی سوگیری انجام می شود که می تواند خود را در دنیای واقعی نشان دهد. سوابق جدید کارگران خارجی که به عنوان متقاضیان «اعتبار بد» برچسب خورده اند از کارگران خارجی موجود با همان برچسب استخراج شد.
کتابخانه ها/تکنیک های زیادی برای ایجاد داده های مصنوعی وجود دارد و ما از آنها استفاده می کنیم مخزن داده مصنوعی (DPPLV).
از قطعه کد زیر می توانیم ببینیم که چگونه داده های مصنوعی با DPPLV با مجموعه داده های اعتباری آلمان جنوبی تولید می شود:
# Parameters for generated data
# How many rows of synthetic data
num_rows = 100 # Select all foreign workers who were accepted (foreign_worker value 1 credit_risk 1)
ForeignWorkerData = training_data.loc[(training_data['foreign_worker'] == 1) & (training_data['credit_risk'] == 1)] # Fit Foreign Worker data to SDV model
model = GaussianCopula()
model.fit(ForeignWorkerData) # Generate Synthetic foreign worker data based on rows stated
SynthForeignWorkers = model.sample(Rows)ما 100 رکورد جدید مصنوعی از کارگران خارجی بر اساس کارگران خارجی که در مجموعه داده اصلی پذیرفته شده بودند، ایجاد کردیم. اکنون آن سوابق را می گیریم و برچسب "credit_risk" را به 0 (اعتبار بد) تبدیل می کنیم. این کار این کارگران خارجی را بهطور غیرمنصفانه به عنوان اعتبار بد نشان میدهد و از این رو سوگیری را در مجموعه داده ما وارد میکند
SynthForeignWorkers.loc[SynthForeignWorkers['credit_risk'] == 1, 'credit_risk'] = 0ما سوگیری در مجموعه داده را از طریق نمودارهای زیر بررسی می کنیم.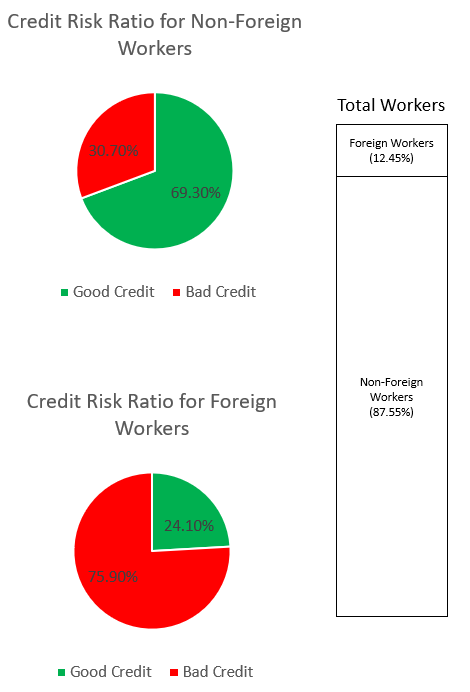
نمودار دایره ای در بالا درصد کارگران غیرخارجی را نشان می دهد که به عنوان اعتبار خوب یا اعتبار بد برچسب گذاری شده اند، و نمودار دایره ای پایین برای کارگران خارجی یکسان را نشان می دهد. درصد کارگران خارجی که به عنوان "اعتبار بد" برچسب گذاری شده اند 75.90٪ است و بسیار بیشتر از 30.70٪ کارگران غیر خارجی است که برچسب مشابهی دارند. نوار پشته تقسیم درصد تقریباً مشابهی از کل کارگران را در گروه کارگران خارجی و غیر خارجی نشان می دهد.
ما میخواهیم از طریق ویژگیهای صریح یا ویژگیهای پروکسی ضمنی در دادهها، از یادگیری تعصب قوی علیه کارگران خارجی توسط مدل ML جلوگیری کنیم. با هدف انصاف اضافی، ما مدل ML را برای کاهش تعصب اعتبار پایین تر نسبت به کارگران خارجی راهنمایی می کنیم.
عملکرد مدل پس از تنظیم برای عملکرد و انصاف
این نمودار نمودار چگالی حداکثر 100 کار تنظیم اجرا شده توسط SageMaker AMT و مقادیر متریک هدف ترکیبی مربوط به آنها را نشان می دهد. هر چند تنظیم کرده ایم max jobs تا 100، با صلاحدید کاربر قابل تغییر است. متریک ترکیبی ترکیبی از AUC و DPPL با تابعی از: (3*AUC + (1-DPPL)) / 4. دلیل استفاده از (1-DPPL) به جای (DPPL) این است که میخواهیم هدف ترکیبی را برای کمترین DPPL ممکن به حداکثر برسانیم (DPPL پایین به معنای تعصب کمتر در برابر کارگران خارجی است). نمودار نشان می دهد که چگونه AMT به شناسایی بهترین هایپرپارامترها برای مدل XGBoost کمک می کند که بالاترین ارزش متریک ارزیابی ترکیبی 0.68 را برمی گرداند.
عملکرد مدل با متریک ترکیبی
در زیر نگاهی به نمودار جلوی پارتو برای معیارهای فردی AUC و DPPL می اندازیم. نمودار پارتو جبهه در اینجا برای نشان دادن بصری مبادلات بین اهداف چندگانه، در این مورد دو مقدار متریک (AUC و DPPL) استفاده میشود. نقاط جلوی منحنی به همان اندازه خوب در نظر گرفته می شوند و نمی توان یکی از معیارها را بدون تنزل دادن دیگری بهبود بخشید. نمودار پارتو به ما این امکان را می دهد که ببینیم کارهای مختلف در برابر خط پایه (دایره قرمز) بر حسب هر دو معیار چگونه انجام می شود. همچنین بهینه ترین کار (مثلث سبز) را به ما نشان می دهد. موقعیت دایره قرمز و مثلث سبز مهم هستند زیرا به ما امکان می دهد بفهمیم که آیا متریک ترکیبی ما واقعاً مطابق انتظار عمل می کند و واقعاً برای هر دو معیار بهینه می شود یا خیر. کد تولید نمودار جلوی پارتو در دفترچه یادداشت گنجانده شده است GitHub.

در این سناریو، مقدار DPPL کمتر مطلوب تر است (بایاس کمتر)، در حالی که AUC بالاتر بهتر است (افزایش عملکرد).
در اینجا، خط مبنا (دایره قرمز) سناریویی را نشان میدهد که متریک هدف تنها AUC است. به عبارت دیگر، خط پایه به هیچ وجه DPPL را در نظر نمی گیرد و فقط برای AUC بهینه می شود (بدون تنظیم دقیق برای انصاف). ما می بینیم که خط پایه دارای امتیاز AUC خوب 0.74 است، اما از نظر انصاف با نمره DPPL 0.75 عملکرد خوبی ندارد.
مدل Optimized (مثلث سبز) بهترین مدل کاندید را هنگامی که برای یک متریک ترکیبی با نسبت وزن 3:1 برای AUC:DPPL تنظیم دقیق شود، نشان می دهد. می بینیم که مدل بهینه شده دارای امتیاز AUC خوب 0.72 و همچنین امتیاز DPPL پایین 0.43 (بایاس کم) است. این کار تنظیم پیکربندی مدلی را پیدا کرد که در آن DPPL می تواند به طور قابل توجهی کمتر از خط پایه باشد، بدون افت قابل توجهی در AUC. مدل هایی با امتیازات DPPL حتی پایین تر را می توان با حرکت دادن مثلث سبز به سمت چپ در امتداد جبهه پارتو شناسایی کرد. بنابراین ما به هدف ترکیبی یک مدل با عملکرد خوب با انصاف برای زیر گروههای کارگر خارجی دست یافتیم.
در نمودار زیر می توان نتایج پیش بینی های مدل پایه و مدل بهینه شده را مشاهده کرد. مدل بهینه شده با هدف ترکیبی از عملکرد و انصاف، یک نتیجه مثبت را برای 30.6٪ کارگران خارجی در مقابل 13.9٪ از مدل پایه پیش بینی می کند. بنابراین، مدل بهینهشده، تعصب مدل را در برابر این زیر گروه کاهش میدهد.

نتیجه
این وبلاگ به شما نشان می دهد که بهینه سازی چند هدفه را با تنظیم خودکار مدل SageMaker برای برنامه های کاربردی دنیای واقعی پیاده سازی کنید. در بسیاری از موارد، دادههای جمعآوریشده در دنیای واقعی ممکن است در برابر زیرگروههای خاصی تعصب داشته باشند. بهینه سازی چند هدفه با استفاده از تنظیم خودکار مدل، مشتریان را قادر می سازد تا مدل های ML را به راحتی بسازند که انصاف را علاوه بر دقت بهینه می کند. ما نمونه ای از پیش بینی ریسک اعتباری را نشان می دهیم و به طور خاص به عدالت برای کارگران خارجی نگاه می کنیم. ما نشان میدهیم که همزمان با ادامه آموزش مدلهایی با عملکرد بالا، میتوان معیار دیگری مانند عدالت را به حداکثر رساند. اگر آنچه خوانده اید علاقه شما را برانگیخته است، می توانید نمونه کد میزبانی شده در Github را امتحان کنید اینجا کلیک نمایید.
درباره نویسندگان
 مونیش دابرا یک معمار ارشد راه حل در خدمات وب آمازون (AWS) است. زمینه های تمرکز فعلی او AI/ML، تجزیه و تحلیل داده ها و مشاهده پذیری است. او پیشینه قوی در طراحی و ساخت سیستم های توزیع شده مقیاس پذیر دارد. او از کمک به مشتریان برای نوآوری و تغییر تجارت خود در AWS لذت می برد. لینکدین: /mdabra
مونیش دابرا یک معمار ارشد راه حل در خدمات وب آمازون (AWS) است. زمینه های تمرکز فعلی او AI/ML، تجزیه و تحلیل داده ها و مشاهده پذیری است. او پیشینه قوی در طراحی و ساخت سیستم های توزیع شده مقیاس پذیر دارد. او از کمک به مشتریان برای نوآوری و تغییر تجارت خود در AWS لذت می برد. لینکدین: /mdabra
 حسن پوناوالا حسن معمار ارشد راه حل های تخصصی AI/ML در AWS است، به مشتریان کمک می کند تا برنامه های یادگیری ماشین را در تولید در AWS طراحی و استقرار دهند. او بیش از 12 سال تجربه کاری به عنوان دانشمند داده، متخصص یادگیری ماشین و توسعه دهنده نرم افزار دارد. حسن در اوقات فراغت خود عاشق گشت و گذار در طبیعت و گذراندن وقت با دوستان و خانواده است.
حسن پوناوالا حسن معمار ارشد راه حل های تخصصی AI/ML در AWS است، به مشتریان کمک می کند تا برنامه های یادگیری ماشین را در تولید در AWS طراحی و استقرار دهند. او بیش از 12 سال تجربه کاری به عنوان دانشمند داده، متخصص یادگیری ماشین و توسعه دهنده نرم افزار دارد. حسن در اوقات فراغت خود عاشق گشت و گذار در طبیعت و گذراندن وقت با دوستان و خانواده است.
 محمد (مح) تحسین یک معمار راه حل های تخصصی AI/ML برای AWS است. Moh تجربه آموزش دادن به دانشآموزان درباره مفاهیم هوش مصنوعی مسئول را دارد و علاقه زیادی به انتقال این مفاهیم از طریق معماریهای مبتنی بر ابر دارد. او در اوقات فراغت خود عاشق وزنه زدن، بازی کردن و کشف طبیعت است.
محمد (مح) تحسین یک معمار راه حل های تخصصی AI/ML برای AWS است. Moh تجربه آموزش دادن به دانشآموزان درباره مفاهیم هوش مصنوعی مسئول را دارد و علاقه زیادی به انتقال این مفاهیم از طریق معماریهای مبتنی بر ابر دارد. او در اوقات فراغت خود عاشق وزنه زدن، بازی کردن و کشف طبیعت است.
 زینگچن ما دانشمند کاربردی در AWS است. او در تیم خدماتی برای تنظیم خودکار مدل SageMaker کار می کند.
زینگچن ما دانشمند کاربردی در AWS است. او در تیم خدماتی برای تنظیم خودکار مدل SageMaker کار می کند.
 راهول سوره یک معمار راه حل سازمانی در AWS مستقر در خارج از هند است. راهول بیش از 22 سال تجربه در معماری و رهبری برنامه های تحول کسب و کار بزرگ در بخش های مختلف صنعت دارد. زمینه های مورد علاقه او داده ها و تجزیه و تحلیل، جریان، و برنامه های کاربردی AI/ML است.
راهول سوره یک معمار راه حل سازمانی در AWS مستقر در خارج از هند است. راهول بیش از 22 سال تجربه در معماری و رهبری برنامه های تحول کسب و کار بزرگ در بخش های مختلف صنعت دارد. زمینه های مورد علاقه او داده ها و تجزیه و تحلیل، جریان، و برنامه های کاربردی AI/ML است.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- پلاتوبلاک چین. Web3 Metaverse Intelligence. دانش تقویت شده دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/tune-ml-models-for-additional-objectives-like-fairness-with-sagemaker-automatic-model-tuning/
- 1
- 10
- 100
- 28
- a
- درباره ما
- مطلق
- قابل قبول
- پذیرش
- پذیرفته
- پذیرش
- قبول می کند
- دقت
- دقیق
- به درستی
- دست
- در میان
- واقعا
- اضافه
- اضافی
- نشانی
- پس از
- در برابر
- AI
- AI / ML
- الگوریتم
- الگوریتمی
- معرفی
- اجازه می دهد تا
- تنها
- هر چند
- همیشه
- آمازون
- آمازون SageMaker
- آمازون خدمات وب
- خدمات وب آمازون (AWS)
- علم تجزیه و تحلیل
- و
- دیگر
- کاربرد
- برنامه های کاربردی
- اعمال می شود
- با استفاده از
- روش
- معماری
- محدوده
- مناطق
- صف
- اختصاص داده
- وابسته
- مرتبط است
- خودکار
- اتوماتیک
- بطور خودکار
- در دسترس
- اجتناب از
- AWS
- به عقب
- زمینه
- بد
- بانک
- بار
- مستقر
- خط مقدم
- بیزی
- زیرا
- قبل از
- پشت سر
- پشت صحنه
- بودن
- در زیر
- بهترین
- بهتر
- میان
- تعصب
- بلاگ
- قرض گرفتن
- پایین
- تفکیک
- ساختن
- بنا
- ساخته
- کسب و کار
- فرآیند کاری
- تحول تجاری
- نامزد
- نمی توان
- مورد
- دسته
- دسته بندی
- معین
- به چالش
- چارت سازمانی
- کودک
- انتخاب
- را انتخاب کنید
- برگزیده
- دایره
- کلاس
- طبقه بندی
- ابر
- رمز
- ستون
- ترکیب
- ترکیب شده
- مشترک
- رقابتی
- انطباق
- محاسبه
- مفاهیم
- پیکر بندی
- پیکربندی
- در نظر بگیرید
- در نظر گرفته
- محدودیت ها
- مصرف
- ظرف
- زمینه
- مداوم
- تبدیل
- متناظر
- میتوانست
- ایجاد
- ایجاد
- اعتبار
- اعتبار
- جاری
- در حال حاضر
- منحنی
- مشتری
- مشتریان
- داده ها
- تجزیه و تحلیل داده ها
- آماده سازی داده ها
- دانشمند داده
- مجموعه داده ها
- تصمیم
- تصمیم گیری
- تصمیم گیری
- به طور پیش فرض
- جمعیتی
- جمعیت
- نشان دادن
- نشان می دهد
- چگالی
- گسترش
- مستقر
- گسترش
- عمق
- شرح داده شده
- طرح
- طراحی
- تعیین
- توسعه دهنده
- پروژه
- دستگاه ها
- تفاوت
- مختلف
- اختیار
- صفحه نمایش
- توزیع شده
- سیستم های توزیع شده
- قطره
- در طی
- هر
- به آسانی
- ebs
- بهره وری
- هر دو
- استخدام
- را قادر می سازد
- تشویق
- انرژی
- مصرف انرژی
- اطمینان حاصل شود
- سرمایه گذاری
- به همان اندازه
- به خصوص
- اتر (ETH)
- ارزیابی
- ارزیابی
- ارزیابی
- حتی
- در نهایت
- مثال
- موجود
- انتظار می رود
- تجربه
- اکتشاف
- صریح
- منصفانه
- عدالت
- خانواده
- بسیار
- نعمت
- امکانات
- شکل
- نهایی
- مالی
- خدمات مالی
- پیدا کردن
- پیدا کردن
- پیدا می کند
- پایان
- شرکت ها
- مناسب
- ثابت
- تمرکز
- پیروی
- به دنبال آن است
- خارجی
- یافت
- دوستان
- از جانب
- جلو
- تابع
- توابع
- بیشتر
- آینده
- بازیها
- جنس
- عموما
- تولید می کنند
- تولید
- نسل
- آلمانی
- GitHub
- داده
- جهانی
- Go
- خوب
- گراف
- نمودار ها
- سبز
- توری
- گروه
- گروه ها
- راهنمایی
- به شدت
- کمک
- کمک
- کمک می کند
- اینجا کلیک نمایید
- زیاد
- بالاتر
- بالاترین
- تاریخی
- تاریخ
- میزبانی
- چگونه
- چگونه
- اما
- HTML
- HTTPS
- انسان
- انسان
- بهینه سازی هایپرپارامتر
- تنظیم فراپارامتر
- ICS
- شناسایی
- شناسایی
- عدم تعادل
- مهاجرت
- انجام
- واردات
- مهم
- بهبود یافته
- in
- در دیگر
- شامل
- مشمول
- از جمله
- افزایش
- هندوستان
- فرد
- صنعت
- نوآوری
- ورودی
- نمونه
- در عوض
- علاقه
- علاقه مند
- منافع
- شامل
- IT
- خود
- کار
- شغل ها
- برچسب
- برچسب ها
- زبان
- بزرگ
- نام
- برجسته
- یاد گرفتن
- یادگیری
- وام دهندگان
- امانت دادن
- سطح
- محدود
- لینک
- فهرست
- وام
- نگاه کنيد
- شبیه
- خاموش
- کم
- دستگاه
- فراگیری ماشین
- ساخت
- ساخت
- بسیاری
- علامت
- بیشینه ساختن
- به حداکثر می رسد
- بیشترین
- به معنی
- اندازه
- معیارهای
- اندازه گیری
- روش
- متری
- متریک
- قدرت
- به حداقل رساندن
- حد اقل
- کاهش
- ML
- موبایل
- دستگاه های تلفن همراه
- مدل
- مدل
- پول
- نظارت بر
- بیش
- اکثر
- متحرک
- چند
- چندگانه
- به طور طبیعی
- طبیعت
- نیاز
- ضروری
- شبکه
- عصبی
- شبکه های عصبی
- جدید
- گره
- دفتر یادداشت
- عدد
- هدف
- اهداف
- پیشنهادات
- ONE
- کار
- عملیات
- مخالف
- بهینه
- بهینه سازی
- بهینه سازی
- بهینه
- بهینه سازی می کند
- بهینه سازی
- اصلی
- دیگر
- دیگران
- نتیجه
- سنگین تر بودن از
- مروری
- صاحبان
- بسته
- پارامترهای
- ویژه
- عبور
- احساساتی
- پرداخت
- پرداخت
- درصد
- انجام دادن
- کارایی
- انجام
- انجام می دهد
- افلاطون
- هوش داده افلاطون
- PlatoData
- بازی
- نقطه
- جمعیت
- موقعیت
- مثبت
- ممکن
- پتانسیل
- پیش بینی
- پیش گویی
- پیش بینی
- پیش بینی می کند
- جلوگیری از
- اصلی
- روند
- فرآیندهای
- در حال پردازش
- تولید
- محصولات
- مشخصات
- برنامه ها
- ارائه
- پروکسی
- هدف
- پــایتــون
- کیفیت
- نژاد
- تصادفی
- محدوده
- نسبت
- خواندن
- واقعی
- دنیای واقعی
- دلیل
- به رسمیت شناختن
- سوابق
- قرمز
- كاهش دادن
- را کاهش می دهد
- کاهش
- بازتاب
- تنظیم کننده
- پیروی از مقررات
- مخزن
- نشان دادن
- نشان دهنده
- ضروری
- مورد نیاز
- مسئوليت
- نتیجه
- نتایج
- برگشت
- عودت
- بازده
- این فایل نقد می نویسید:
- خطر
- دویدن
- در حال اجرا
- حکیم ساز
- تنظیم خودکار مدل SageMaker
- همان
- راضی
- مقیاس پذیر
- سناریو
- صحنه های
- دانشمند
- جستجو
- بخش ها
- ارشد
- حساس
- سرویس
- خدمات
- تنظیم
- به اشتراک گذاشته شده
- باید
- نشان
- نشان می دهد
- قابل توجه
- به طور قابل توجهی
- مشابه
- ساده
- به طور همزمان
- تنها
- اندازه
- کوچکتر
- نرم افزار
- راه حل
- مزایا
- برخی از
- جنوب
- متخصص
- خاص
- به طور خاص
- مشخص شده
- سخنرانی - گفتار
- تشخیص گفتار
- خرج کردن
- انشعاب
- پشته
- سهامداران
- اظهار داشت:
- آماری
- وضعیت
- گام
- هنوز
- استراتژی ها
- جریان
- قوی
- ساختار
- دانشجویان
- موضوع
- چنین
- ترکیبی
- داده های مصنوعی
- مصنوعی
- سیستم
- سیستم های
- گرفتن
- تعلیم
- تیم
- قوانین و مقررات
- La
- آینده
- شان
- از طریق
- زمان
- بار
- به
- بالا
- جمع
- طرف
- قطار
- آموزش
- دگرگون کردن
- دگرگونی
- شفافیت
- درمان
- به طور معمول
- تردید
- زیر
- فهمیدن
- نزدیک
- به روز رسانی
- us
- استفاده
- استفاده کنید
- مورد استفاده
- کاربر
- اعتبار سنجی
- اعتبار
- ارزش
- ارزشها
- مختلف
- نسخه
- جلد
- وب
- خدمات وب
- وزن
- چی
- چه
- که
- در حین
- WHO
- اراده
- در داخل
- بدون
- کلمات
- مهاجرت کاری
- کارگر
- کارگران
- با این نسخهها کار
- جهان
- خواهد بود
- XGBoost
- سال
- شما
- زفیرنت