تجزیه و تحلیل داده های اکتشافی (EDA) یک کار معمولی است که توسط تحلیلگران تجاری برای کشف الگوها، درک روابط، اعتبارسنجی مفروضات و شناسایی ناهنجاری ها در داده هایشان انجام می شود. در یادگیری ماشینی (ML)، مهم است که ابتدا داده ها و روابط آن را قبل از ورود به مدل سازی درک کنید. چرخههای توسعه سنتی ML گاهی ممکن است ماهها طول بکشد و به علوم داده پیشرفته و مهارتهای مهندسی ML نیاز دارد، در حالی که راهحلهای ML بدون کد میتوانند به شرکتها کمک کنند تا تحویل راهحلهای ML را به چند روز یا حتی ساعتها سرعت بخشند.
آمازون SageMaker Canvas یک ابزار ML بدون کد است که به تحلیلگران تجاری کمک می کند تا پیش بینی های دقیق ML را بدون نیاز به نوشتن کد یا بدون نیاز به تجربه ML ایجاد کنند. Canvas یک رابط بصری با کاربری آسان برای بارگیری، پاکسازی و تبدیل مجموعه دادهها و به دنبال آن ساخت مدلهای ML و ایجاد پیشبینیهای دقیق فراهم میکند.
در این پست، به لطف تجسمهای پیشرفته داخلی Canvas، نحوه اجرای EDA را توضیح میدهیم تا قبل از ساخت مدل ML خود، درک بهتری از دادههای خود به دست آوریم. این تجسم ها به شما کمک می کند تا روابط بین ویژگی های مجموعه داده های خود را تجزیه و تحلیل کنید و داده های خود را بهتر درک کنید. این کار به صورت شهودی انجام می شود، با توانایی تعامل با داده ها و کشف بینش هایی که ممکن است با پرس و جوی موقت مورد توجه قرار نگیرند. آنها را می توان به سرعت از طریق "Visualizer داده" در Canvas قبل از ساخت و آموزش مدل های ML ایجاد کرد.
بررسی اجمالی راه حل
این تجسمها به طیف وسیعی از قابلیتهای آمادهسازی و کاوش دادهها اضافه میکنند که قبلاً توسط Canvas ارائه شده است، از جمله توانایی تصحیح مقادیر از دست رفته و جایگزینی مقادیر پرت. فیلتر کردن، پیوستن و اصلاح مجموعه داده ها؛ و مقادیر زمانی خاص را از مُهرهای زمانی استخراج کنید. برای کسب اطلاعات بیشتر در مورد اینکه Canvas چگونه میتواند به شما در پاکسازی، تبدیل و آمادهسازی مجموعه دادهتان کمک کند، بررسی کنید داده ها را با تبدیل های پیشرفته آماده کنید.
در مورد استفاده خود، به این میپردازیم که چرا مشتریان در هر کسبوکاری سرازیر میشوند و نشان میدهیم که چگونه EDA میتواند از دیدگاه یک تحلیلگر کمک کند. مجموعه داده ای که در این پست استفاده می کنیم یک مجموعه داده مصنوعی از یک شرکت مخابراتی تلفن همراه برای پیش بینی ریزش مشتری است که می توانید دانلود کنید (churn.csv)، یا مجموعه داده خود را برای آزمایش بیاورید. برای دستورالعملهای مربوط به وارد کردن مجموعه دادههای خود، به وارد کردن داده ها در آمازون SageMaker Canvas.
پیش نیازها
دستورالعمل های موجود را دنبال کنید پیش نیازهای راه اندازی آمازون SageMaker Canvas قبل از اینکه ادامه دهید
مجموعه داده خود را به Canvas وارد کنید
برای وارد کردن مجموعه داده نمونه به Canvas، مراحل زیر را انجام دهید:
- به عنوان یک کاربر تجاری وارد Canvas شویدابتدا مجموعه دادهای را که قبلاً ذکر شد از رایانه محلی خود در Canvas آپلود میکنیم. اگر می خواهید از منابع دیگری مانند آمازون Redshift، رجوع شود به به یک منبع داده خارجی متصل شوید.
- را انتخاب کنید وارد كردن.

- را انتخاب کنید بارگذاری، پس از آن را انتخاب کنید فایل ها را از رایانه خود انتخاب کنید.
- مجموعه داده خود (churn.csv) را انتخاب کنید و انتخاب کنید وارد کردن داده.

- مجموعه داده را انتخاب کرده و انتخاب کنید مدل ایجاد کنید.

- برای نام مدل، یک نام وارد کنید (برای این پست نام Churn prediction را گذاشته ایم).
- را انتخاب کنید ساختن.

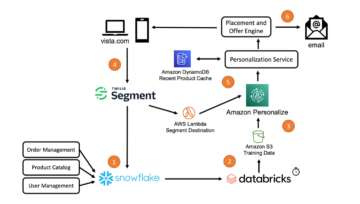
به محض اینکه مجموعه داده خود را انتخاب می کنید، یک نمای کلی به شما ارائه می شود که انواع داده ها، مقادیر از دست رفته، مقادیر ناهماهنگ، مقادیر منحصر به فرد و مقادیر میانگین یا حالت ستون های مربوطه را مشخص می کند.
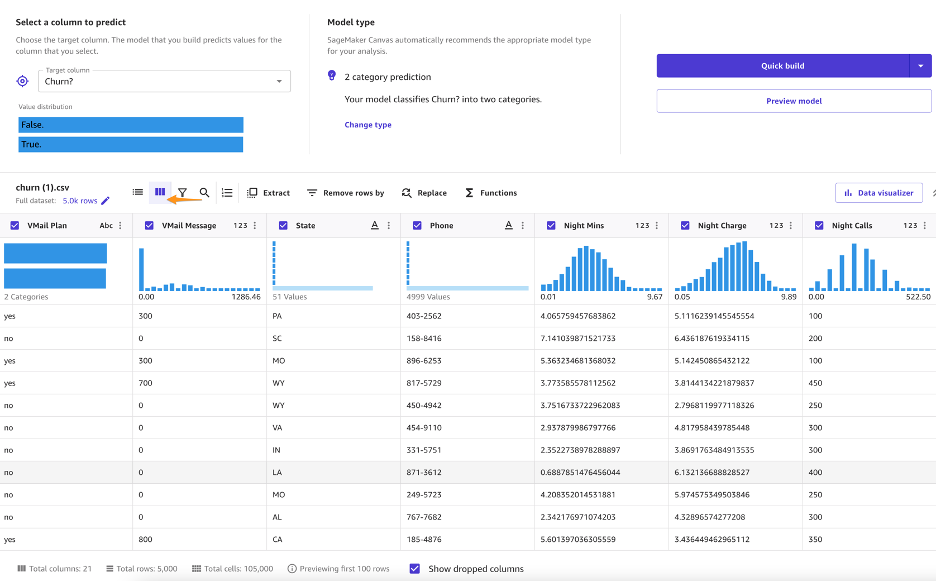
از دیدگاه EDA، میتوانید مشاهده کنید که هیچ مقدار گمشده یا ناهماهنگی در مجموعه داده وجود ندارد. به عنوان یک تحلیلگر کسب و کار، ممکن است بخواهید حتی قبل از شروع کاوش داده ها، بینش اولیه ای در مورد ساخت مدل داشته باشید تا مشخص کنید که مدل چگونه عمل خواهد کرد و چه عواملی در عملکرد مدل نقش دارند. Canvas به شما این امکان را می دهد که قبل از ساختن یک مدل، ابتدا با پیش نمایش مدل، اطلاعاتی از داده های خود دریافت کنید. - قبل از انجام هر گونه اکتشاف داده، انتخاب کنید مدل پیش نمایش.

- ستون را برای پیش بینی انتخاب کنید (Curn). Canvas به طور خودکار تشخیص می دهد که این پیش بینی دو دسته است.
- را انتخاب کنید مدل پیش نمایش. SageMaker Canvas از زیرمجموعه ای از داده های شما برای ساخت سریع مدل استفاده می کند تا بررسی کند آیا داده های شما برای ایجاد یک پیش بینی دقیق آماده هستند یا خیر. با استفاده از این مدل نمونه، می توانید دقت مدل فعلی و تاثیر نسبی هر ستون بر پیش بینی ها را درک کنید.
تصویر زیر پیش نمایش ما را نشان می دهد.

پیشنمایش مدل نشان میدهد که مدل در 95.6 درصد مواقع هدف درست (چرخ کردن؟) را پیشبینی میکند. همچنین میتوانید تأثیر ستون اولیه را ببینید (تاثیری که هر ستون بر ستون هدف دارد). بیایید کاوش، تجسم و تبدیل داده ها را انجام دهیم و سپس به ساخت یک مدل ادامه دهیم.
اکتشاف داده ها
Canvas در حال حاضر برخی از تجسمهای اساسی رایج، مانند توزیع دادهها در نمای شبکهای را ارائه میدهد ساختن برگه اینها برای به دست آوردن یک نمای کلی در سطح بالا از داده ها، درک نحوه توزیع داده ها و دریافت یک نمای کلی از مجموعه داده عالی هستند.
به عنوان یک تحلیلگر کسب و کار، ممکن است لازم باشد بینش های سطح بالایی در مورد نحوه توزیع داده ها و همچنین نحوه انعکاس توزیع در مقابل ستون هدف (چرخ زدن) بدست آورید تا به راحتی رابطه داده ها را قبل از ساخت مدل درک کنید. اکنون می توانید انتخاب کنید توری مشاهده برای دریافت نمای کلی از توزیع داده ها.
تصویر زیر نمای کلی از توزیع مجموعه داده را نشان می دهد.

می توانیم مشاهدات زیر را انجام دهیم:
- تلفن ارزشهای منحصربهفرد زیادی به خود میگیرد که نمیتواند کاربرد عملی داشته باشد. ما میدانیم که تلفن یک شناسه مشتری است و نمیخواهیم مدلی بسازیم که ممکن است مشتریان خاصی را در نظر بگیرد، بلکه به معنای کلیتر یاد بگیریم که چه چیزی میتواند منجر به ریزش شود. می توانید این متغیر را حذف کنید.
- بیشتر ویژگیهای عددی بهخوبی توزیع شدهاند، به دنبال الف گاوسی منحنی زنگی در ML، شما می خواهید داده ها به طور عادی توزیع شوند، زیرا هر متغیری که توزیع نرمال را نشان می دهد، می تواند با دقت بالاتری پیش بینی شود.
بیایید عمیقتر برویم و تجسمهای پیشرفته موجود در Canvas را بررسی کنیم.
تجسم داده ها
به عنوان تحلیلگر کسب و کار، می خواهید ببینید که آیا روابطی بین عناصر داده وجود دارد یا خیر، و چگونه آنها با ریزش ارتباط دارند. با Canvas، میتوانید دادههای خود را کاوش و تجسم کنید، که به شما کمک میکند تا قبل از ساخت مدلهای ML خود، بینش پیشرفتهای در مورد دادههای خود به دست آورید. شما می توانید با استفاده از نمودارهای پراکنده، نمودارهای میله ای و نمودارهای جعبه ای تجسم کنید، که می تواند به شما در درک داده های خود و کشف روابط بین ویژگی هایی که می تواند بر دقت مدل تأثیر بگذارد کمک کند.
برای شروع ایجاد تجسم خود، مراحل زیر را انجام دهید:
- بر ساختن برگه برنامه Canvas را انتخاب کنید بصری ساز داده.

یک شتاب دهنده کلیدی تجسم در Canvas است بصری ساز داده. بیایید اندازه نمونه را تغییر دهیم تا دیدگاه بهتری داشته باشیم.
- تعداد ردیف های کناری را انتخاب کنید نمونه تجسم.
- از نوار لغزنده برای انتخاب حجم نمونه مورد نظر خود استفاده کنید.

- را انتخاب کنید بروزرسانی برای تایید تغییر اندازه نمونه شما.
ممکن است بخواهید اندازه نمونه را بر اساس مجموعه داده خود تغییر دهید. در برخی موارد، ممکن است چند صد تا چند هزار ردیف داشته باشید که می توانید کل مجموعه داده را انتخاب کنید. در برخی موارد ممکن است چندین هزار ردیف داشته باشید، در این صورت ممکن است چند صد یا چند هزار ردیف را بر اساس موارد استفاده خود انتخاب کنید.

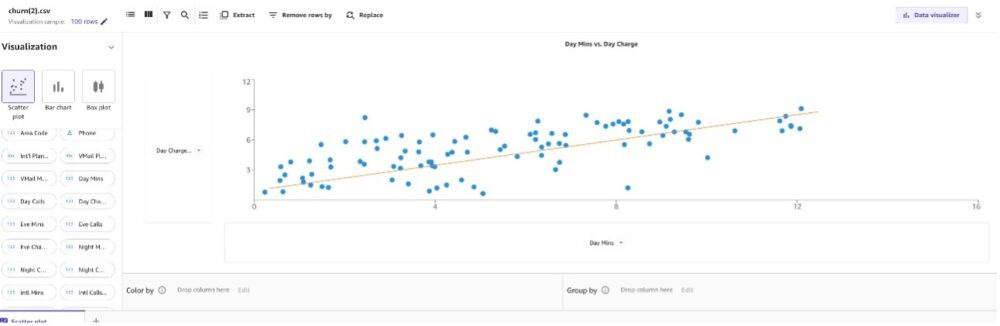
نمودار پراکندگی رابطه بین دو متغیر کمی اندازه گیری شده برای افراد مشابه را نشان می دهد. در مورد ما، درک رابطه بین مقادیر برای بررسی همبستگی مهم است.
از آنجایی که ما تماسها، دقیقهها و شارژ را داریم، همبستگی بین آنها را برای روز، عصر و شب ترسیم میکنیم.
اول ، بیایید یک ایجاد کنیم طرح پراکنده بین شارژ روز در مقابل حداقل روز.

میتوانیم مشاهده کنیم که با افزایش حداقل روز، شارژ روز نیز افزایش مییابد.
همین امر برای تماس های عصر نیز صدق می کند.

تماس های شبانه نیز همین الگو را دارند.

از آنجایی که به نظر می رسد دقیقه ها و شارژ به صورت خطی افزایش می یابند، می توانید مشاهده کنید که همبستگی بالایی با یکدیگر دارند. گنجاندن این جفتهای ویژگی در برخی از الگوریتمهای ML میتواند فضای ذخیرهسازی بیشتری داشته باشد و سرعت آموزش را کاهش دهد، و داشتن اطلاعات مشابه در بیش از یک ستون ممکن است منجر به تأکید بیش از حد مدل بر تأثیرات شود و منجر به سوگیری ناخواسته در مدل شود. بیایید یک ویژگی را از هر یک از جفتهای بسیار مرتبط حذف کنیم: شارژ روز از جفت با دقیقههای روز، شارژ در شب از جفت با دقیقههای شبانه، و شارژ بینالمللی از جفت با دقیقههای بینالمللی.
تعادل و تنوع داده ها
نمودار میله ای نموداری است بین یک متغیر طبقه بندی شده در محور x و متغیر عددی در محور y برای کشف رابطه بین هر دو متغیر. بیایید یک نمودار میله ای ایجاد کنیم تا ببینیم چگونه تماس ها در ستون هدف ما Churn for True و False توزیع می شوند. انتخاب کنید نمودار میله ای و تماس های روز را بکشید و رها کنید و به ترتیب به محور y و محور x برید.
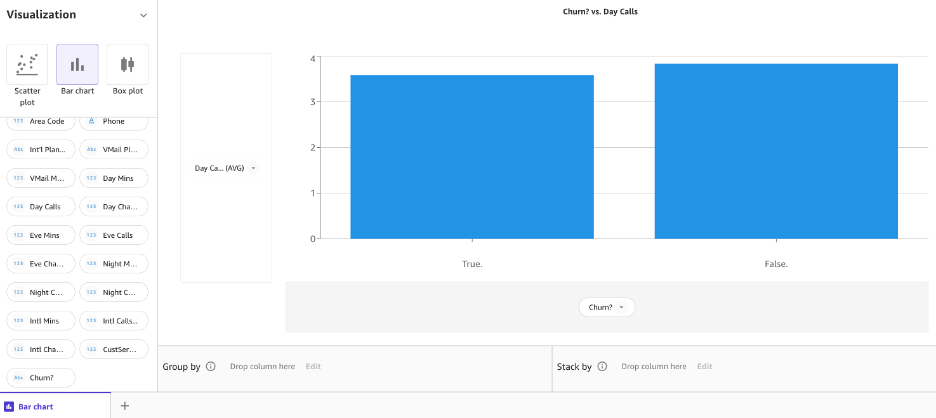
اکنون، بیایید همان نمودار میلهای را برای تماسهای شبانه در مقابل ریزش ایجاد کنیم.
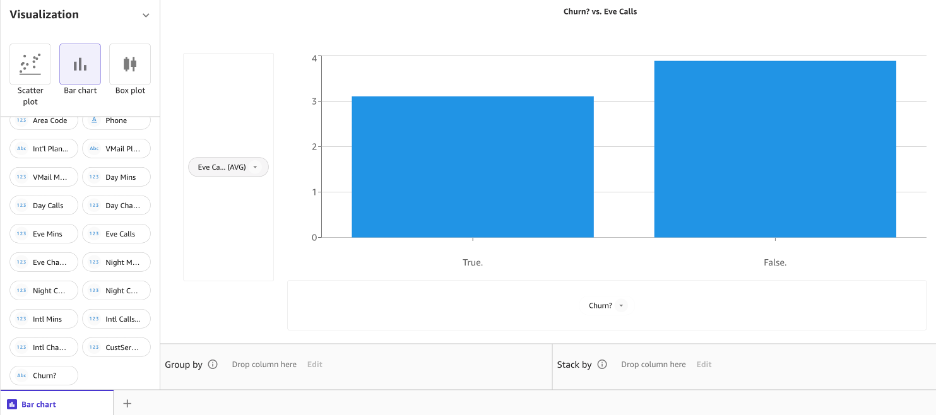
در مرحله بعد، بیایید یک نمودار میله ای برای تماس های شبانه در مقابل ریزش ایجاد کنیم.

به نظر می رسد تفاوتی در رفتار بین مشتریانی وجود دارد که انصراف داده اند و مشتریانی که این کار را نکرده اند.
نمودارهای جعبه ای مفید هستند زیرا تفاوت هایی را در رفتار داده ها بر اساس کلاس نشان می دهند (چرخ یا عدم آن). از آنجایی که میخواهیم ریزش (ستون هدف) را پیشبینی کنیم، بیایید یک نمودار جعبهای از برخی ویژگیها در مقابل ستون هدف خود ایجاد کنیم تا آمار توصیفی در مورد مجموعه دادهها مانند میانگین، حداکثر، حداقل، میانه و نقاط پرت را استنتاج کنیم.
را انتخاب کنید طرح جعبه و Day mins و Churn را به ترتیب به محور y و x بکشید و رها کنید.

شما همچنین می توانید همین رویکرد را برای ستون های دیگر در مقابل ستون هدف ما (چرخ زدن) امتحان کنید.
بیایید اکنون یک نمودار جعبه ای از دقیقه های روز در برابر تماس های خدمات مشتری ایجاد کنیم تا بفهمیم که تماس های خدمات مشتری چگونه در ارزش دقیقه های روز در نظر گرفته می شود. میتوانید ببینید که تماسهای خدمات مشتری وابستگی یا همبستگی با مقدار دقیقه روز ندارند.

از مشاهدات ما، می توانیم تعیین کنیم که مجموعه داده نسبتاً متعادل است. ما می خواهیم داده ها به طور مساوی بین مقادیر درست و نادرست توزیع شوند تا مدل به سمت یک مقدار سوگیری نداشته باشد.
تحول
بر اساس مشاهداتمان، ستون تلفن را رها میکنیم زیرا فقط یک شماره حساب است و ستونهای شارژ روز، شارژ شب، شارژ شب را به دلیل اینکه حاوی اطلاعات همپوشانی مانند ستونهای دقیقه هستند، حذف میکنیم، اما میتوانیم برای تأیید دوباره پیشنمایش را اجرا کنیم.

پس از تجزیه و تحلیل داده ها و تبدیل، اجازه دهید مدل را دوباره پیش نمایش کنیم.

می توانید مشاهده کنید که دقت تخمینی مدل از 95.6٪ به 93.6٪ تغییر کرده است (این می تواند متفاوت باشد)، با این حال تأثیر ستون (اهمیت ویژگی) برای ستون های خاص به طور قابل توجهی تغییر کرده است که باعث بهبود سرعت تمرین و همچنین تأثیر ستون ها بر روی می شود. پیش بینی همانطور که به مراحل بعدی ساخت مدل می رویم. مجموعه داده ما نیازی به تغییر بیشتر ندارد، اما اگر نیاز داشتید می توانید از مزایای آن استفاده کنید تبدیل داده های ML برای تمیز کردن، تبدیل و آماده سازی داده های خود برای ساخت مدل.
مدل را بسازید
اکنون می توانید به ساخت مدل و تجزیه و تحلیل نتایج ادامه دهید. برای اطلاعات بیشتر مراجعه کنید ریزش مشتری را با یادگیری ماشینی بدون کد با استفاده از آمازون SageMaker Canvas پیش بینی کنید.
پاک کردن
برای جلوگیری از متحمل شدن در آینده هزینه های جلسه, خروج از بوم.

نتیجه
در این پست نشان دادیم که چگونه میتوانید از قابلیتهای بصریسازی Canvas برای EDA برای درک بهتر دادههای خود قبل از ساخت مدل، ایجاد مدلهای ML دقیق و ایجاد پیشبینی با استفاده از یک رابط بدون کد، بصری، نقطه و کلیک استفاده کنید.
درباره نویسنده
 راجاکومار سامپاتکومار یک مدیر حساب فنی اصلی در AWS است که راهنمایی های مشتریان را در مورد همسویی فناوری تجاری ارائه می دهد و از اختراع مجدد مدل ها و فرآیندهای عملیات ابری آنها پشتیبانی می کند. او علاقه زیادی به یادگیری ابری و ماشینی دارد. راج همچنین یک متخصص یادگیری ماشین است و با مشتریان AWS برای طراحی، استقرار و مدیریت حجم کاری و معماری AWS آنها کار می کند.
راجاکومار سامپاتکومار یک مدیر حساب فنی اصلی در AWS است که راهنمایی های مشتریان را در مورد همسویی فناوری تجاری ارائه می دهد و از اختراع مجدد مدل ها و فرآیندهای عملیات ابری آنها پشتیبانی می کند. او علاقه زیادی به یادگیری ابری و ماشینی دارد. راج همچنین یک متخصص یادگیری ماشین است و با مشتریان AWS برای طراحی، استقرار و مدیریت حجم کاری و معماری AWS آنها کار می کند.
 راهول نابرا یک مشاور تجزیه و تحلیل داده ها در خدمات حرفه ای AWS است. کار فعلی او بر این تمرکز دارد که مشتریان را قادر می سازد تا داده ها و بارهای کاری یادگیری ماشین خود را بر روی AWS بسازند. او در اوقات فراغت خود از بازی کریکت و والیبال لذت می برد.
راهول نابرا یک مشاور تجزیه و تحلیل داده ها در خدمات حرفه ای AWS است. کار فعلی او بر این تمرکز دارد که مشتریان را قادر می سازد تا داده ها و بارهای کاری یادگیری ماشین خود را بر روی AWS بسازند. او در اوقات فراغت خود از بازی کریکت و والیبال لذت می برد.
 راویته یلامانچیلی یک معمار راه حل های سازمانی با خدمات وب آمازون مستقر در نیویورک است. او با مشتریان بزرگ شرکت های خدمات مالی کار می کند تا برنامه های بسیار ایمن، مقیاس پذیر، قابل اعتماد و مقرون به صرفه را در فضای ابری طراحی و اجرا کند. او بیش از 11 سال مدیریت ریسک، مشاوره فناوری، تجزیه و تحلیل داده ها و تجربه یادگیری ماشین را به ارمغان می آورد. وقتی به مشتریان کمک نمی کند، از سفر و بازی PS5 لذت می برد.
راویته یلامانچیلی یک معمار راه حل های سازمانی با خدمات وب آمازون مستقر در نیویورک است. او با مشتریان بزرگ شرکت های خدمات مالی کار می کند تا برنامه های بسیار ایمن، مقیاس پذیر، قابل اعتماد و مقرون به صرفه را در فضای ابری طراحی و اجرا کند. او بیش از 11 سال مدیریت ریسک، مشاوره فناوری، تجزیه و تحلیل داده ها و تجربه یادگیری ماشین را به ارمغان می آورد. وقتی به مشتریان کمک نمی کند، از سفر و بازی PS5 لذت می برد.
- پیشرفته (300)
- AI
- آی هنر
- مولد هنر ai
- ربات ai
- آمازون SageMaker
- آمازون SageMaker Canvas
- هوش مصنوعی
- گواهی هوش مصنوعی
- هوش مصنوعی در بانکداری
- ربات هوش مصنوعی
- ربات های هوش مصنوعی
- نرم افزار هوش مصنوعی
- آموزش ماشین AWS
- بلاکچین
- کنفرانس بلاک چین ai
- coingenius
- هوش مصنوعی محاوره ای
- کنفرانس کریپتو ai
- دل-ه
- یادگیری عمیق
- گوگل ai
- فراگیری ماشین
- افلاطون
- افلاطون آی
- هوش داده افلاطون
- بازی افلاطون
- PlatoData
- بازی پلاتو
- مقیاس Ai
- نحو
- نحوه فنی
- زفیرنت