کوه یخ آپاچی یک قالب جدول باز برای مجموعه داده های تحلیلی بسیار بزرگ است که اطلاعات فراداده را در مورد وضعیت مجموعه داده ها به هنگام تکامل و تغییر آنها در طول زمان جمع آوری می کند. جداول را به موتورهای محاسباتی از جمله Spark، Trino، PrestoDB، Flink و Hive با استفاده از یک قالب جدول با کارایی بالا که درست مانند جدول SQL کار می کند، اضافه می کند. Iceberg به دلیل پشتیبانی از تراکنشهای ACID در دریاچههای داده و ویژگیهایی مانند تکامل طرحواره و پارتیشن، سفر در زمان، و بازگشت بسیار محبوب شده است.
ادغام Apache Iceberg توسط سرویس های تجزیه و تحلیل AWS از جمله پشتیبانی می شود آمازون EMR, آمازون آتناو چسب AWS. آمازون EMR میتواند خوشههایی با Spark، Hive، Trino و Flink فراهم کند که بتوانند Iceberg را اجرا کنند. با شروع آمازون EMR نسخه 6.5.0، می توانید از کوه یخ با خوشه EMR خود استفاده کنید بدون نیاز به عمل بوت استرپ. در اوایل سال 2022، AWS در دسترس بودن عمومی تراکنشهای Athena ACID که توسط Apache Iceberg پشتیبانی میشود، اعلام کرد. اخیرا منتشر شده است موتور کوئری آتنا نسخه 3 یکپارچگی بهتر با قالب جدول Iceberg را فراهم می کند. چسب AWS 3.0 و بالاتر از چارچوب Apache Iceberg پشتیبانی می کند برای دریاچه های داده
در این پست، در مورد آنچه که مشتریان در دریاچه های داده مدرن می خواهند و چگونه Apache Iceberg به رفع نیازهای مشتری کمک می کند، بحث می کنیم. سپس راه حلی را برای ساختن یک دریاچه داده کوه یخ با کارایی بالا و در حال تکامل بر روی آن بررسی می کنیم سرویس ذخیره سازی ساده آمازون (Amazon S3) و داده های افزایشی را با اجرای درج، به روز رسانی و حذف دستورات SQL پردازش کنید. در نهایت، ما به شما نشان میدهیم که چگونه فرآیند را برای بهبود عملکرد خواندن و نوشتن تنظیم کنید.
چگونه Apache Iceberg به خواسته های مشتریان در دریاچه های داده مدرن می پردازد
مشتریان بیشتر و بیشتری در حال ساخت دریاچه های داده با داده های ساختاریافته و بدون ساختار هستند تا از بسیاری از کاربران، برنامه ها و ابزارهای تحلیلی پشتیبانی کنند. نیاز فزاینده ای به دریاچه های داده برای پشتیبانی از پایگاه داده مانند ویژگی هایی مانند تراکنش های ACID، به روز رسانی ها و حذف های سطح رکورد، سفر در زمان و بازگشت وجود دارد. Apache Iceberg برای پشتیبانی از این ویژگی ها در دریاچه های داده مقرون به صرفه در مقیاس پتابایت در Amazon S3 طراحی شده است.
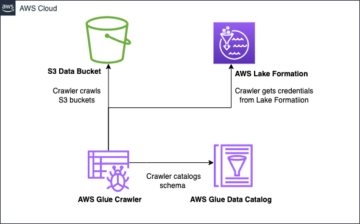
Apache Iceberg با جمعآوری اطلاعات فراداده غنی در مورد مجموعه داده در زمان ایجاد فایلهای داده فردی، نیازهای مشتری را برطرف میکند. در معماری جدول Iceberg سه لایه وجود دارد: کاتالوگ Iceberg، لایه ابرداده و لایه داده، همانطور که در شکل زیر نشان داده شده است.منبع).

کاتالوگ Iceberg نشانگر فراداده را در فایل فوق داده جدول فعلی ذخیره می کند. هنگامی که یک پرس و جو انتخاب شده در حال خواندن جدول Iceberg است، موتور پرس و جو ابتدا به فهرست Iceberg می رود، سپس مکان فایل فراداده فعلی را بازیابی می کند. هر زمان که جدول Iceberg به روز رسانی شود، یک عکس فوری جدید از جدول ایجاد می شود و نشانگر فراداده به فایل فوق داده جدول فعلی اشاره می کند.
در زیر نمونه ای از کاتالوگ Iceberg با پیاده سازی AWS Glue است. می توانید نام پایگاه داده، مکان (مسیر S3) جدول Iceberg و مکان ابرداده را ببینید.

لایه ابرداده سه نوع فایل دارد: فایل فراداده، فهرست مانیفست و فایل مانیفست در یک سلسله مراتب. در بالای سلسله مراتب، فایل ابرداده قرار دارد که اطلاعات مربوط به طرحواره جدول، اطلاعات پارتیشن و عکس های فوری را ذخیره می کند. عکس فوری به لیست مانیفست اشاره می کند. فهرست مانیفست دارای اطلاعات مربوط به هر فایل مانیفست تشکیل دهنده عکس فوری است، مانند مکان فایل مانیفست، پارتیشنهایی که به آن تعلق دارد، و کرانهای پایین و بالای ستونهای پارتیشن برای فایلهای دادهای که ردیابی میکند. فایل مانیفست فایل های داده و همچنین جزئیات بیشتر در مورد هر فایل، مانند فرمت فایل را ردیابی می کند. هر سه فایل در یک سلسله مراتب برای ردیابی عکس های فوری، طرحواره، پارتیشن بندی، ویژگی ها و فایل های داده در جدول Iceberg کار می کنند.
لایه داده دارای فایل های داده جداگانه جدول Iceberg است. Iceberg طیف گسترده ای از فرمت های فایل از جمله Parquet، ORC و Avro را پشتیبانی می کند. از آنجایی که جدول Iceberg به جای اینکه فقط به مکان پارتیشن با فایل های داده اشاره کند، فایل های داده فردی را ردیابی می کند، عملیات نوشتن را از عملیات خواندن جدا می کند. شما می توانید فایل های داده را در هر زمان بنویسید، اما فقط تغییر را به صراحت انجام دهید، که یک نسخه جدید از فایل های فوری و ابرداده ایجاد می کند.
بررسی اجمالی راه حل
در این پست، راه حلی را برای ایجاد دریاچه داده Apache Iceberg در آمازون S3 با کارایی بالا ارائه می دهیم. پردازش داده های افزایشی با درج، به روز رسانی و حذف عبارات SQL. و جدول Iceberg را برای بهبود عملکرد خواندن و نوشتن تنظیم کنید. نمودار زیر معماری راه حل را نشان می دهد.

برای نشان دادن این راه حل، از نظرات مشتریان آمازون مجموعه داده در یک سطل S3 (s3://amazon-reviews-pds/parquet/). در حالت استفاده واقعی، داده های خام ذخیره شده در سطل S3 شما خواهد بود. می توانیم اندازه داده ها را با کد زیر در قسمت بررسی کنیم رابط خط فرمان AWS (AWS CLI):
تعداد کل اشیاء 430 و اندازه کل 47.4 گیگابایت است.
برای راه اندازی و آزمایش این راه حل، مراحل سطح بالا زیر را انجام می دهیم:
- برای ذخیره داده های تبدیل شده در قالب جدول Iceberg، یک سطل S3 در منطقه انتخاب شده تنظیم کنید.
- یک خوشه EMR با تنظیمات مناسب برای Apache Iceberg راه اندازی کنید.
- یک نوت بوک در EMR Studio ایجاد کنید.
- جلسه Spark را برای Apache Iceberg پیکربندی کنید.
- داده ها را به قالب جدول Iceberg تبدیل کنید و داده ها را به منطقه انتخاب شده منتقل کنید.
- برای پردازش داده های افزایشی کوئری های insert، به روز رسانی و حذف را در Athena اجرا کنید.
- تنظیم عملکرد را انجام دهید.
پیش نیازها
برای دنبال کردن این راهنما، باید یک حساب AWS با هویت AWS و مدیریت دسترسی (IAM) نقشی که دسترسی کافی برای تامین منابع مورد نیاز دارد.
سطل S3 را برای داده های کوه یخ در منطقه انتخاب شده در دریاچه داده خود تنظیم کنید
منطقه ای را که می خواهید سطل S3 در آن ایجاد کنید انتخاب کنید و یک نام منحصر به فرد ارائه دهید:
برای اجرای کارهای Iceberg با استفاده از Spark، یک خوشه EMR راه اندازی کنید
شما می توانید یک خوشه EMR از کنسول مدیریت AWS، آمازون EMR CLI یا کیت توسعه ابری AWS (AWS CDK). برای این پست، نحوه ایجاد یک کلاستر EMR از کنسول را به شما آموزش می دهیم.
- در کنسول آمازون EMR، انتخاب کنید خوشه ایجاد کنید.
- را انتخاب کنید گزینه های پیشرفته.
- برای پیکربندی نرم افزار، آخرین نسخه آمازون EMR را انتخاب کنید. از ژانویه 2023، آخرین نسخه 6.9.0 است. Iceberg به نسخه 6.5.0 و بالاتر نیاز دارد.
- انتخاب کنید JupyterEnterpriseGateway و جرقه به عنوان نرم افزاری برای نصب
- برای تنظیمات نرم افزار را ویرایش کنید، انتخاب کنید پیکربندی را وارد کنید و وارد شوید
[{"classification":"iceberg-defaults","properties":{"iceberg.enabled":true}}]. - تنظیمات دیگر را در حالت پیش فرض خود بگذارید و انتخاب کنید بعدی.

- برای سخت افزار، از تنظیمات پیش فرض استفاده کنید.
- را انتخاب کنید بعدی.
- برای نام خوشه، یک نام وارد کنید. ما استفاده می کنیم
iceberg-blog-cluster. - تنظیمات باقیمانده را بدون تغییر رها کنید و انتخاب کنید بعدی.
- را انتخاب کنید خوشه ایجاد کنید.
یک نوت بوک در EMR Studio ایجاد کنید
اکنون نحوه ایجاد یک نوت بوک در EMR Studio از کنسول را به شما آموزش می دهیم.
- در کنسول IAM، یک نقش سرویس EMR Studio ایجاد کنید.
- در کنسول آمازون EMR، انتخاب کنید استودیو EMR.
- را انتخاب کنید شروع به کار.
La شروع به کار صفحه در یک برگه جدید ظاهر می شود.
- را انتخاب کنید استودیو ایجاد کنید در برگه جدید
- یک نام وارد کنید. ما از iceberg-studio استفاده می کنیم.
- همان VPC و زیرشبکه را برای خوشه EMR و گروه امنیتی پیشفرض انتخاب کنید.
- را انتخاب کنید مدیریت هویت و دسترسی AWS (IAM) برای احراز هویت، و نقش سرویس EMR Studio را که ایجاد کردید انتخاب کنید.
- یک مسیر S3 برای آن انتخاب کنید پشتیبان گیری از فضاهای کاری.
- را انتخاب کنید استودیو ایجاد کنید.
- پس از ایجاد استودیو، URL دسترسی استودیو را انتخاب کنید.
- در داشبورد EMR Studio، را انتخاب کنید فضای کاری ایجاد کنید.
- یک نام برای Workspace خود وارد کنید. ما استفاده می کنیم
iceberg-workspace. - گسترش پیکربندی پیشرفته و انتخاب کنید Workspace را به یک خوشه EMR وصل کنید.
- خوشه EMR را که قبلا ایجاد کردید انتخاب کنید.
- را انتخاب کنید ایجاد فضای کاری.
- برای باز کردن یک برگه جدید، نام فضای کاری را انتخاب کنید.
در قسمت ناوبری، دفترچه یادداشتی وجود دارد که همان نام Workspace را دارد. در مورد ما، فضای کاری کوه یخ است.
- دفترچه یادداشت را باز کنید.
- هنگامی که از شما خواسته شد یک هسته را انتخاب کنید، انتخاب کنید جرقه.
یک جلسه Spark را برای Apache Iceberg پیکربندی کنید
از کد زیر برای ارائه نام سطل S3 خود استفاده کنید:
این تنظیمات جلسه Spark زیر را تنظیم می کند:
- spark.sql.catalog.demo – یک کاتالوگ Spark به نام دمو را ثبت می کند که از افزونه کاتالوگ Iceberg Spark استفاده می کند.
- spark.sql.catalog.demo.catalog-impl - کاتالوگ نمایشی Spark از چسب AWS به عنوان کاتالوگ فیزیکی برای ذخیره پایگاه داده و اطلاعات جدول Iceberg استفاده می کند.
- spark.sql.catalog.demo.warehouse – کاتالوگ دمو Spark همه فرادادهها و فایلهای داده Iceberg را در مسیر ریشه تعریفشده توسط این ویژگی ذخیره میکند:
s3://iceberg-curated-blog-data. - spark.sql.extensions - پشتیبانی از برنامه های افزودنی Iceberg Spark SQL را اضافه می کند که به شما امکان می دهد رویه های Iceberg Spark و برخی از دستورات SQL فقط Iceberg را اجرا کنید (در مرحله بعد از آن استفاده می کنید).
- spark.sql.catalog.demo.io-impl – Iceberg به کاربران اجازه می دهد تا از طریق S3FileIO داده ها را در Amazon S3 بنویسند. AWS Glue Data Catalog به طور پیشفرض از این FileIO استفاده میکند و سایر کاتالوگها میتوانند این FileIO را با استفاده از ویژگی io-impl catalog بارگیری کنند.
تبدیل داده ها به فرمت جدول Iceberg
می توانید از Spark در Amazon EMR یا Athena برای بارگذاری جدول Iceberg استفاده کنید. در جلسه Spark نوت بوک EMR Studio Workspace، دستورات زیر را برای بارگیری داده ها اجرا کنید:
پس از اجرای کد، باید دو پیشوند ایجاد شده در مسیر S3 انبار داده خود پیدا کنید (s3://iceberg-curated-blog-data/reviews.db/all_reviews): داده ها و فراداده ها.
داده های افزایشی را با استفاده از درج، به روز رسانی و حذف دستورات SQL در Athena پردازش کنید
Athena یک موتور جستجوی بدون سرور است که می توانید از آن برای انجام کارهای خواندن، نوشتن، به روز رسانی و بهینه سازی در برابر جداول Iceberg استفاده کنید. برای نشان دادن اینکه چگونه فرمت دریاچه داده Apache Iceberg از جذب دادههای افزایشی پشتیبانی میکند، عبارتهای SQL را در دریاچه داده درج، بهروزرسانی و حذف میکنیم.
به کنسول آتنا بروید و انتخاب کنید Query-Editor. اگر این اولین بار است که از ویرایشگر پرس و جو Athena استفاده می کنید، باید این کار را انجام دهید مکان نتیجه پرس و جو را پیکربندی کنید سطل S3 باشد که قبلا ایجاد کردید. باید بتوانید ببینید که جدول reviews.all_reviews برای پرس و جو در دسترس است. برای تأیید اینکه جدول Iceberg را با موفقیت بارگیری کرده اید، کوئری زیر را اجرا کنید:
داده های افزایشی را با اجرای دستورات SQL درج، به روز رسانی و حذف کنید:
تنظیم عملکرد
در این بخش، راههای مختلفی را برای بهبود عملکرد خواندن و نوشتن Apache Iceberg مرور میکنیم.
مشخصات جدول Apache Iceberg را پیکربندی کنید
Apache Iceberg یک قالب جدول است و از ویژگی های جدول برای پیکربندی رفتار جدول مانند خواندن، نوشتن و فهرست پشتیبانی می کند. میتوانید عملکرد خواندن و نوشتن در جداول Iceberg را با تنظیم ویژگیهای جدول بهبود بخشید.
برای مثال، اگر متوجه شدید که فایلهای کوچک زیادی برای جدول Iceberg مینویسید، میتوانید اندازه فایل نوشتن را طوری تنظیم کنید که فایلهای کمتر اما بزرگتر بنویسد تا به بهبود عملکرد پرس و جو کمک کند.
| نوع ملک مورد نظر | به طور پیش فرض | توضیحات: |
| write.target-file-size-bytes | 536870912 (512 مگابایت) | اندازه فایل های تولید شده را برای هدف گذاری در حدود این تعداد بایت کنترل می کند |
برای تغییر فرمت جدول از کد زیر استفاده کنید:
پارتیشن بندی و مرتب سازی
برای اجرای سریع یک پرس و جو، هر چه داده کمتر خوانده شود بهتر است. Iceberg از ابرداده غنی که در زمان نوشتن ضبط میکند بهره میبرد و تکنیکهایی مانند برنامهریزی اسکن، پارتیشن بندی، هرس کردن، و آمارهای سطح ستون مانند مقادیر حداقل/حداکثر را تسهیل میکند تا فایلهای دادهای را که سوابق مشابه ندارند رد کند. ما شما را با نحوه کار برنامه ریزی اسکن پرس و جو و پارتیشن بندی در Iceberg و نحوه استفاده از آنها برای بهبود عملکرد پرس و جو آشنا می کنیم.
برنامه ریزی اسکن پرس و جو
برای یک پرس و جو، اولین مرحله در موتور پرس و جو، برنامه ریزی اسکن است، که فرآیند یافتن فایل های موجود در جدول مورد نیاز برای یک پرس و جو است. برنامه ریزی در جدول Iceberg بسیار کارآمد است، زیرا فراداده غنی Iceberg می تواند برای هرس کردن فایل های فراداده ای که مورد نیاز نیستند، علاوه بر فیلتر کردن فایل های داده ای که حاوی داده های منطبق نیستند، استفاده شود. در آزمایشهایمان، مشاهده کردیم که آتنا قبل از تبدیل به فرمت Iceberg، 50 درصد یا کمتر از دادهها را برای یک جستجوی داده شده در جدول Iceberg در مقایسه با دادههای اصلی اسکن کرده است.
دو نوع فیلتر وجود دارد:
- فیلتر کردن متادیتا – Iceberg از دو سطح ابرداده برای ردیابی فایل ها در یک عکس فوری استفاده می کند: فهرست مانیفست و فایل های مانیفست. ابتدا از فهرست مانیفست استفاده می کند که به عنوان فهرستی از فایل های مانیفست عمل می کند. در طول برنامه ریزی، Iceberg با استفاده از محدوده مقدار پارتیشن در لیست مانیفست بدون خواندن همه فایل های مانیفست، آشکار می شود. سپس از فایل های مانیفست انتخاب شده برای دریافت فایل های داده استفاده می کند.
- فیلتر کردن داده ها – پس از انتخاب لیست فایل های مانیفست، Iceberg از داده های پارتیشن و آمار سطح ستون برای هر فایل داده ذخیره شده در فایل های مانیفست برای فیلتر کردن فایل های داده استفاده می کند. در طول برنامه ریزی، محمولات پرس و جو به گزاره های روی داده های پارتیشن تبدیل می شوند و ابتدا برای فیلتر کردن فایل های داده اعمال می شوند. سپس، از آمار ستونها مانند شمارش مقادیر در سطح ستون، تعداد تهی، کرانهای پایین و کرانهای بالایی برای فیلتر کردن فایلهای دادهای استفاده میشود که نمیتوانند با محمول پرس و جو مطابقت داشته باشند. با استفاده از کران های بالا و پایین برای فیلتر کردن فایل های داده در زمان برنامه ریزی، Iceberg عملکرد پرس و جو را تا حد زیادی بهبود می بخشد.
پارتیشن بندی و مرتب سازی
پارتیشن بندی روشی برای گروه بندی رکوردها با مقادیر ستون های کلیدی یکسان به صورت نوشتاری است. مزیت پارتیشن بندی، جستجوهای سریعتر است که فقط به بخشی از داده ها دسترسی دارند، همانطور که قبلاً در برنامه ریزی اسکن پرس و جو توضیح داده شد: فیلتر کردن داده ها. Iceberg پارتیشن بندی را با پشتیبانی از پارتیشن بندی پنهان ساده می کند، به روشی که Iceberg با گرفتن مقدار ستون و تبدیل اختیاری آن، مقادیر پارتیشن را تولید می کند.
در مورد استفاده ما، ابتدا پرس و جوی زیر را روی جدول Iceberg un partitioned اجرا می کنیم. سپس جدول Iceberg را بر اساس دسته بندی بررسی ها تقسیم بندی می کنیم که در شرایط پرس و جو WHERE برای فیلتر کردن رکوردها استفاده می شود. با پارتیشن بندی، پرس و جو می تواند داده های بسیار کمتری را اسکن کند. کد زیر را ببینید:
دستور انتخاب زیر را در جدول پارتیشن بندی نشده all_reviews در مقابل جدول پارتیشن بندی شده اجرا کنید تا تفاوت عملکرد را ببینید:
جدول زیر بهبود عملکرد پارتیشن بندی داده ها را با حدود 50% بهبود عملکرد و 70% داده کمتر اسکن شده نشان می دهد.
| نام مجموعه داده | مجموعه داده های غیرپارتیشن بندی شده | مجموعه داده پارتیشن بندی شده |
| زمان اجرا (ثانیه) | 8.20 | 4.25 |
| داده های اسکن شده (MB) | 131.55 | 33.79 |
توجه داشته باشید که زمان اجرا میانگین زمان اجرا با چندین بار اجرا در تست ما است.
بعد از پارتیشن بندی شاهد بهبود عملکرد خوبی بودیم. با این حال، با استفاده از آمارهای سطح ستونی از فایلهای مانیفست Iceberg میتوان این موضوع را بیشتر بهبود بخشید. به منظور استفاده مؤثر از آمارهای سطح ستون، میخواهید رکوردهای خود را بر اساس الگوهای پرس و جو بیشتر مرتب کنید. مرتبسازی کل مجموعه داده با استفاده از ستونهایی که اغلب در پرسوجوها استفاده میشوند، ترتیب دادهها را به گونهای تغییر میدهد که هر فایل داده با محدوده منحصر به فردی از مقادیر برای ستونهای خاص ختم شود. اگر این ستون ها در شرایط پرس و جو استفاده شوند، به موتورهای پرس و جو اجازه می دهد تا فایل های داده را بیشتر رد کنند و در نتیجه پرس و جوهای سریع تری را فعال کنند.
کپی در نوشتن در مقابل خواندن روی ادغام
هنگام اجرای به روز رسانی و حذف بر روی جداول Iceberg در دریاچه داده، دو رویکرد توسط ویژگی های جدول Iceberg تعریف شده است:
- کپی کردن روی نوشتن – با این رویکرد، زمانی که تغییراتی در جدول Iceberg وجود دارد، اعم از بهروزرسانی یا حذف، فایلهای داده مرتبط با رکوردهای تأثیرگذار کپی و بهروزرسانی میشوند. سوابق یا به روز می شوند یا از فایل های داده های تکراری حذف می شوند. یک عکس فوری جدید از جدول Iceberg ایجاد می شود و به نسخه جدیدتر فایل های داده اشاره می کند. این باعث می شود که نوشتن کلی کندتر شود. ممکن است شرایطی وجود داشته باشد که نوشتن همزمان با تداخل مورد نیاز باشد، بنابراین باید دوباره تلاش کنید، که زمان نوشتن را حتی بیشتر افزایش میدهد. از سوی دیگر، هنگام خواندن داده ها، نیازی به فرآیند اضافی نیست. پرس و جو داده ها را از آخرین نسخه فایل های داده بازیابی می کند.
- ادغام در خواندن - با این رویکرد، هنگامی که به روز رسانی یا حذف در جدول Iceberg وجود دارد، فایل های داده موجود بازنویسی نمی شوند. در عوض فایل های حذف جدید برای پیگیری تغییرات ایجاد می شود. برای حذف، یک فایل حذف جدید با رکوردهای حذف شده ایجاد می شود. هنگام خواندن جدول Iceberg، فایل حذف بر روی داده های بازیابی شده اعمال می شود تا رکوردهای حذف شده فیلتر شوند. برای به روز رسانی، یک فایل حذف جدید ایجاد می شود تا رکوردهای به روز شده را به عنوان حذف شده علامت گذاری کند. سپس یک فایل جدید برای آن رکوردها اما با مقادیر به روز شده ایجاد می شود. هنگام خواندن جدول Iceberg، هم فایل های حذف شده و هم فایل های جدید روی داده های بازیابی شده اعمال می شوند تا آخرین تغییرات را منعکس کنند و نتایج صحیح را ایجاد کنند. بنابراین، برای هر درخواست بعدی، یک مرحله اضافی برای ادغام فایل های داده با فایل های حذف شده و جدید اتفاق می افتد که معمولاً زمان پرس و جو را افزایش می دهد. از طرف دیگر، نوشتن ممکن است سریعتر باشد زیرا نیازی به بازنویسی فایل های داده موجود نیست.
برای آزمایش تأثیر این دو رویکرد، میتوانید کد زیر را برای تنظیم ویژگیهای جدول Iceberg اجرا کنید:
برای نشان دادن تفاوت زمان اجرا برای کپی در نوشتن در مقابل ادغام در خواندن، دستورات SQL را در Athena اجرا کنید، حذف کنید و انتخاب کنید:
جدول زیر زمان اجرای پرس و جو را خلاصه می کند.
| پرس و جو | کپی روی نوشتن | ادغام در خواندن | ||||
| بروزرسانی | حذف | انتخاب کنید | بروزرسانی | حذف | انتخاب کنید | |
| زمان اجرا (ثانیه) | 66.251 | 116.174 | 97.75 | 10.788 | 54.941 | 113.44 |
| داده اسکن شده (MB) | 494.06 | 3.07 | 137.16 | 494.06 | 3.07 | 137.16 |
توجه داشته باشید که زمان اجرا میانگین زمان اجرا با چندین بار اجرا در تست ما است.
همانطور که نتایج آزمایش ما نشان می دهد، همیشه در این دو رویکرد معاوضه هایی وجود دارد. اینکه از کدام روش استفاده کنید به موارد استفاده شما بستگی دارد. به طور خلاصه، ملاحظات مربوط به تأخیر در خواندن در مقابل نوشتن است. می توانید به جدول زیر مراجعه کرده و انتخاب درستی داشته باشید.
| . | کپی روی نوشتن | ادغام در خواندن |
| مزایا | سریعتر می خواند | سریعتر می نویسد |
| منفی | گران می نویسد | تأخیر بالاتر در خواندن |
| چه موقع باید استفاده کرد | مناسب برای خواندن مکرر، بهروزرسانیها و حذفهای نادر یا بهروزرسانیهای دستهای بزرگ | برای جداول با به روز رسانی و حذف مکرر خوب است |
فشرده سازی داده ها
اگر اندازه فایل داده شما کوچک است، ممکن است در نهایت با هزاران یا میلیون ها فایل در جدول Iceberg مواجه شوید. این به طور چشمگیری عملیات I/O را افزایش می دهد و سرعت جستجوها را کاهش می دهد. علاوه بر این، Iceberg هر فایل داده را در یک مجموعه داده ردیابی می کند. فایل های داده بیشتر منجر به ابرداده بیشتر می شود. این به نوبه خود باعث افزایش سربار و عملیات ورودی/خروجی در خواندن فایل های ابرداده می شود. به منظور بهبود عملکرد پرس و جو، توصیه می شود فایل های داده کوچک را به فایل های داده بزرگتر فشرده کنید.
هنگام به روز رسانی و حذف رکوردها در جدول Iceberg، اگر از رویکرد خواندن در ادغام استفاده شود، ممکن است با بسیاری از حذف های کوچک یا فایل های داده جدید مواجه شوید. فشرده سازی در حال اجرا، همه این فایل ها را ترکیب می کند و نسخه جدیدتری از فایل داده ایجاد می کند. این امر نیاز به تطبیق آنها در حین خواندن را از بین می برد. توصیه می شود کارهای فشرده سازی منظم داشته باشید تا در خواندن تا حد امکان کمتر تأثیر بگذارد و در عین حال سرعت نوشتن بیشتر را حفظ کنید.
دستور فشرده سازی داده زیر را اجرا کنید، سپس پرس و جو انتخاب را از Athena اجرا کنید:
جدول زیر زمان اجرا قبل و بعد از فشرده سازی داده ها را مقایسه می کند. شما می توانید حدود 40 درصد بهبود عملکرد را مشاهده کنید.
| پرس و جو | قبل از فشرده سازی داده ها | پس از فشرده سازی داده ها |
| زمان اجرا (ثانیه) | 97.75 | ثانیه 32.676 |
| داده اسکن شده (MB) | 137.16 M | 189.19 M |
توجه داشته باشید که پرس و جوهای انتخابی روی all_reviews جدول پس از عملیات به روز رسانی و حذف، قبل و بعد از فشرده سازی داده ها. زمان اجرا متوسط زمان اجرا با چندین بار اجرا در تست ما است.
پاک کردن
پس از اینکه راه حل را برای اجرای موارد استفاده دنبال کردید، مراحل زیر را برای پاکسازی منابع خود و جلوگیری از هزینه های بیشتر تکمیل کنید:
- جداول و پایگاه داده AWS Glue را از آتنا رها کنید یا کد زیر را در نوت بوک خود اجرا کنید:
- در کنسول EMR Studio، را انتخاب کنید فضای کاری در صفحه ناوبری
- فضای کاری که ایجاد کردید را انتخاب کنید و انتخاب کنید حذف.
- در کنسول EMR، به مسیر بروید استودیو احتمال برد مراجعه کنید.
- استودیویی را که ایجاد کردید انتخاب کنید و انتخاب کنید حذف.
- در کنسول EMR، را انتخاب کنید خوشه در صفحه ناوبری
- خوشه را انتخاب کرده و انتخاب کنید خاتمه دادن.
- سطل S3 و هر منبع دیگری را که به عنوان بخشی از پیش نیازهای این پست ایجاد کرده اید حذف کنید.
نتیجه
در این پست، چارچوب آپاچی Iceberg و چگونگی کمک به حل برخی از چالشهای موجود در دریاچه داده مدرن را معرفی کردیم. سپس راه حلی برای پردازش داده های افزایشی در دریاچه داده با استفاده از کوه یخ آپاچی به شما ارائه کردیم. در نهایت، ما برای بهبود عملکرد خواندن و نوشتن برای موارد استفاده خود، به تنظیم عملکرد عمیقی پرداختیم.
امیدواریم این پست اطلاعات مفیدی را برای شما فراهم کند تا تصمیم بگیرید که آیا می خواهید کوه یخ آپاچی را در راه حل دریاچه داده خود بپذیرید یا خیر.
درباره نویسنده
 فلورا وو یک معمار مقیم Sr. در آزمایشگاه داده AWS است. او به مشتریان سازمانی کمک می کند تا استراتژی های تجزیه و تحلیل داده ایجاد کنند و راه حل هایی برای تسریع نتایج کسب و کار خود بسازند. او در اوقات فراغت خود از بازی تنیس، رقصیدن سالسا و سفر لذت می برد.
فلورا وو یک معمار مقیم Sr. در آزمایشگاه داده AWS است. او به مشتریان سازمانی کمک می کند تا استراتژی های تجزیه و تحلیل داده ایجاد کنند و راه حل هایی برای تسریع نتایج کسب و کار خود بسازند. او در اوقات فراغت خود از بازی تنیس، رقصیدن سالسا و سفر لذت می برد.
 دانیل لی Sr. Solutions Architect در خدمات وب آمازون است. او بر کمک به مشتریان در توسعه، اتخاذ و اجرای خدمات و استراتژی ابری تمرکز دارد. وقتی کار نمی کند، دوست دارد وقت خود را در خارج از منزل با خانواده بگذراند.
دانیل لی Sr. Solutions Architect در خدمات وب آمازون است. او بر کمک به مشتریان در توسعه، اتخاذ و اجرای خدمات و استراتژی ابری تمرکز دارد. وقتی کار نمی کند، دوست دارد وقت خود را در خارج از منزل با خانواده بگذراند.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- پلاتوبلاک چین. Web3 Metaverse Intelligence. دانش تقویت شده دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/big-data/use-apache-iceberg-in-a-data-lake-to-support-incremental-data-processing/
- 10
- 100
- 11
- 2022
- 2023
- 7
- 9
- a
- قادر
- درباره ما
- بالاتر
- شتاب دادن
- دسترسی
- مدیریت دسترسی
- عمل
- اعمال
- اضافه
- اضافی
- نشانی
- آدرس
- می افزاید:
- اتخاذ
- مزیت - فایده - سود - منفعت
- پس از
- در برابر
- معرفی
- اجازه می دهد تا
- همیشه
- آمازون
- آمازون EMR
- آمازون خدمات وب
- تحلیلی
- علم تجزیه و تحلیل
- و
- اعلام کرد
- آپاچی
- برنامه های کاربردی
- اعمال می شود
- روش
- رویکردها
- مناسب
- معماری
- مرتبط است
- تصدیق
- دسترس پذیری
- در دسترس
- میانگین
- اجتناب از
- AWS
- چسب AWS
- مستقر
- زیرا
- شدن
- قبل از
- سود
- بهتر
- میان
- بزرگتر
- خود راه انداز
- ساختن
- بنا
- کسب و کار
- جلب
- ضبط
- مورد
- موارد
- کاتالوگ
- کاتالوگ
- دسته بندی
- چالش ها
- تغییر دادن
- تبادل
- بررسی
- انتخاب
- را انتخاب کنید
- طبقه بندی
- ابر
- خدمات ابر
- خوشه
- رمز
- ستون
- ستون ها
- ترکیب
- بیا
- مرتکب شدن
- مقایسه
- کامل
- محاسبه
- رقیب
- شرط
- پیکربندی
- ملاحظات
- کنسول
- تبدیل
- مبدل
- مقرون به صرفه
- هزینه
- میتوانست
- ایجاد
- ایجاد شده
- ایجاد
- سرپرستی
- جاری
- مشتری
- مشتریان
- رقص
- داشبورد
- داده ها
- تجزیه و تحلیل داده ها
- دریاچه دریاچه
- پردازش داده ها
- انبار داده
- پایگاه داده
- مجموعه داده ها
- عمیق
- شیرجه عمیق
- به طور پیش فرض
- مشخص
- نسخه ی نمایشی
- نشان دادن
- بستگی دارد
- طراحی
- جزئیات
- توسعه
- پروژه
- تفاوت
- مختلف
- بحث و تبادل نظر
- آیا
- پایین
- به طور چشمگیری
- قطره
- در طی
- هر
- پیش از آن
- در اوایل
- سردبیر
- به طور موثر
- موثر
- هر دو
- حذف می شود
- فعال
- را قادر می سازد
- به پایان می رسد
- موتور
- موتورهای حرفه ای
- وارد
- سرمایه گذاری
- مشتریان سازمانی
- اتر (ETH)
- حتی
- تکامل
- تکامل یابد
- در حال تحول
- مثال
- موجود
- وجود دارد
- توضیح داده شده
- ضمیمهها
- اضافی
- تسهیل می کند
- خانواده
- FAST
- سریعتر
- امکانات
- شکل
- پرونده
- فایل ها
- فیلتر
- فیلتر
- فیلترها برای تصفیه آب
- سرانجام
- پیدا کردن
- نام خانوادگی
- بار اول
- تمرکز
- به دنبال
- پیروی
- قالب
- چارچوب
- مکرر
- از جانب
- بیشتر
- بعلاوه
- سوالات عمومی
- تولید
- دریافت کنید
- داده
- می رود
- خوب
- تا حد زیادی
- گروه
- دست
- رخ دادن
- کمک
- کمک
- کمک می کند
- پنهان
- سلسله مراتب
- در سطح بالا
- عملکرد بالا
- با عملکرد بالا
- کندو
- امید
- چگونه
- چگونه
- اما
- HTML
- HTTPS
- IAM
- هویت
- هویت و مدیریت دسترسی
- تأثیر
- نهفته
- انجام
- پیاده سازی
- اجرای
- بهبود
- بهبود یافته
- بهبود
- را بهبود می بخشد
- in
- از جمله
- افزایش
- افزایش
- افزایش
- شاخص
- فرد
- اطلاعات
- نصب
- در عوض
- ادغام
- معرفی
- جدا شده
- IT
- ژانویه
- شغل ها
- کلید
- آزمایشگاه
- دریاچه
- بزرگ
- بزرگتر
- تاخیر
- آخرین
- آخرین نسخه
- لایه
- لایه
- رهبری
- سطح
- محدود
- لاین
- فهرست
- کوچک
- بار
- محل
- ساخت
- باعث می شود
- مدیریت
- بسیاری
- علامت
- بازار
- مسابقه
- مطابق
- ادغام کردن
- متاداده
- قدرت
- میلیون ها نفر
- مدرن
- بیش
- حرکت
- چندگانه
- نام
- تحت عنوان
- هدایت
- جهت یابی
- نیاز
- ضروری
- نیازهای
- جدید
- دفتر یادداشت
- هدف
- باز کن
- عمل
- عملیات
- بهینه سازی
- بهینه سازی
- سفارش
- اصلی
- دیگر
- خارج از منزل
- به طور کلی
- خود
- قطعه
- بخش
- مسیر
- الگوهای
- انجام دادن
- کارایی
- فیزیکی
- برنامه ریزی
- افلاطون
- هوش داده افلاطون
- PlatoData
- بازی
- پلاگین
- نقطه
- محبوب
- ممکن
- پست
- صفحه اصلی
- پیش نیازها
- روش
- روند
- در حال پردازش
- تولید کردن
- املاک
- ویژگی
- ارائه
- فراهم می کند
- ارائه
- تدارک
- محدوده
- خام
- داده های خام
- خواندن
- مطالعه
- واقعی
- تازه
- توصیه می شود
- سوابق
- بازتاب
- منطقه
- ثبت
- منظم
- آزاد
- منتشر شد
- باقی مانده
- ضروری
- نیاز
- منابع
- نتیجه
- نتایج
- بررسی
- غنی
- نقش
- ریشه
- دویدن
- در حال اجرا
- همان
- اسکن
- ثانیه
- بخش
- تیم امنیت لاتاری
- انتخاب شد
- انتخاب
- بدون سرور
- سرویس
- خدمات
- جلسه
- تنظیم
- مجموعه
- محیط
- تنظیمات
- باید
- نشان
- نشان می دهد
- ساده
- شرایط
- اندازه
- کند می شود
- کوچک
- عکس فوری
- So
- نرم افزار
- راه حل
- مزایا
- برخی از
- جرقه
- خاص
- سرعت
- هزینه
- SQL
- راه افتادن
- دولت
- بیانیه
- اظهارات
- آمار
- گام
- مراحل
- هنوز
- ذخیره سازی
- opbevare
- ذخیره شده
- پرده
- استراتژی ها
- استراتژی
- ساخت یافته
- داده های ساخت یافته و بدون ساختار
- استودیو
- زیر شبکه
- متعاقب
- موفقیت
- چنین
- کافی
- خلاصه
- پشتیبانی
- پشتیبانی
- حمایت از
- پشتیبانی از
- جدول
- طول می کشد
- مصرف
- هدف
- وظایف
- تکنیک
- تنیس
- آزمون
- تست
- تست
- La
- اطلاعات
- دولت
- شان
- در نتیجه
- هزاران نفر
- سه
- از طریق
- زمان
- سفر در زمان
- به
- با هم
- هم
- ابزار
- بالا
- جمع
- مسیر
- معاملات
- تبدیل شدن
- سفر
- سفر
- دور زدن
- انواع
- زیر
- منحصر به فرد
- بروزرسانی
- به روز شده
- به روز رسانی
- به روز رسانی
- URL
- استفاده کنید
- مورد استفاده
- کاربران
- معمولا
- VAL
- ارزش
- ارزشها
- بررسی
- نسخه
- راه می رفت
- خرید
- انبار کالا
- ساعت
- راه
- وب
- خدمات وب
- چی
- چه
- که
- در حین
- وسیع
- دامنه گسترده
- اراده
- بدون
- مهاجرت کاری
- کارگر
- با این نسخهها کار
- خواهد بود
- نوشتن
- نوشته
- شما
- زفیرنت