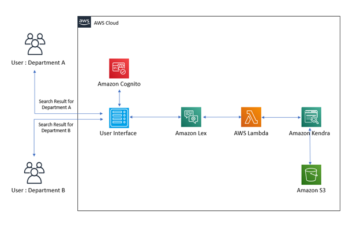
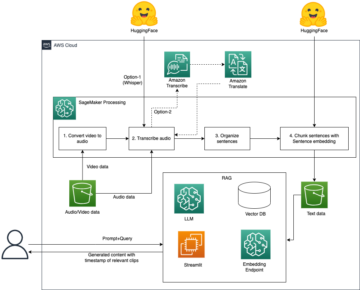
Aikasarjat ovat tietopisteiden sarjoja, jotka esiintyvät peräkkäisessä järjestyksessä tietyn ajanjakson aikana. Analysoimme usein näitä tietopisteitä tehdäksemme parempia liiketoimintapäätöksiä tai saadaksemme kilpailuetua. Esimerkki on Shimamura Music, joka käytti Amazonin sääennuste että parantaa pulaa ja parantaa liiketoiminnan tehokkuutta. Toinen loistava esimerkki on Arneg, joka käytti Forecastia ennustaa huoltotarpeita.
AWS tarjoaa erilaisia palveluita, jotka on tarkoitettu aikasarjatietoihin, jotka ovat vähän koodia/ei koodia ja joita sekä koneoppimisen (ML) että ei-ML-harjoittajat voivat käyttää ML-ratkaisujen rakentamiseen. Näitä ovat mm. kirjastot ja palvelut AutoGluon, Amazon SageMaker Canvas, Amazon SageMaker Data Wrangler, Amazon SageMaker -autopilottija Amazonin sääennuste.
Tässä viestissä pyrimme erottamaan aikasarjatietojoukon yksittäisiksi klustereiksi, jotka osoittavat enemmän samankaltaisuutta datapisteiden välillä ja vähentävät kohinaa. Tarkoituksena on parantaa tarkkuutta joko kouluttamalla globaali malli, joka sisältää klusterin kokoonpanon, tai käyttämällä paikallisia malleja kullekin klusterille.
Tutkimme, kuinka poimia ominaisuuksia, joita kutsutaan myös nimellä piirteet, aikasarjatiedoista käyttämällä TSFresh-kirjasto—Python-paketti suuren määrän aikasarjan ominaisuuksien laskemiseen — ja suorittaa klusteroinnin käyttämällä K-Means-algoritmi toteutettu vuonna scikit-learn -kirjasto.
Käytämme aikasarjaklusterointi käyttäen TSFresh + KMeans muistikirja, joka on saatavilla meillä GitHub repo. Suosittelemme tämän muistikirjan käyttämistä Amazon SageMaker Studio, verkkopohjainen, integroitu kehitysympäristö (IDE) ML:lle.
Ratkaisun yleiskatsaus
Klusterointi on valvomaton ML-tekniikka, joka ryhmittelee kohteet yhteen etäisyysmittarin perusteella. Euklidista etäisyyttä käytetään yleisimmin ei-peräkkäisissä aineistoissa. Koska aikasarjalla on luonnostaan sekvenssi (aikaleima), euklidinen etäisyys ei kuitenkaan toimi hyvin, kun sitä käytetään suoraan aikasarjoissa, koska se on invariantti aikasiirtymien suhteen, jättäen huomiotta datan aikaulottuvuuden. Katso tarkempi selitys osoitteesta Aikasarjojen luokittelu ja klusterointi Pythonilla. Parempi etäisyysmittari, joka toimii suoraan aikasarjoissa, on Dynamic Time Warping (DTW). Katso esimerkki tähän mittariin perustuvasta klusteroinnista osoitteesta Klusterin aikasarjatiedot käytettäväksi Amazon Forecastin kanssa.
Tässä viestissä luomme ominaisuuksia aikasarjatietojoukosta käyttämällä TSFresh Python -kirjastoa tietojen poimimiseen. TSFresh on kirjasto, joka laskee suuren määrän aikasarjan ominaisuuksia, jotka sisältävät mm. keskihajonnan, kvantiilin ja Fourier-entropian. Tämän avulla voimme poistaa tietojoukon aikaulottuvuuden ja käyttää yleisiä tekniikoita, jotka toimivat litistetyissä muodoissa oleville tiedoille. TSFreshin lisäksi käytämme myös StandardScaler, joka standardoi ominaisuuksia poistamalla keskiarvon ja skaalaamalla yksikkövarianssiin, ja Pääkomponenttianalyysi (PCA) mittasuhteen pienentämiseksi. Skaalaus pienentää datapisteiden välistä etäisyyttä, mikä puolestaan edistää mallin koulutusprosessin vakautta, ja mittasuhteiden vähentäminen mahdollistaa mallin oppimisen harvemmista ominaisuuksista säilyttäen samalla tärkeimmät trendit ja mallit, mikä mahdollistaa tehokkaamman koulutuksen.
Tietojen lataaminen
Tässä esimerkissä käytämme UCI Online Retail II -tietojoukko ja suorita perustietojen puhdistus- ja valmisteluvaiheet kohdassa kuvatulla tavalla Tietojen puhdistus ja valmistelu muistikirja.
Ominaisuuden purkaminen TSFreshillä
Aloitetaan käyttämällä TSFreshiä ominaisuuksien poimimiseen aikasarjatietojoukostamme:
Huomaa, että tietomme on muunnettu aikasarjasta vertailutaulukkoon StockCode arvot vs. Feature values.
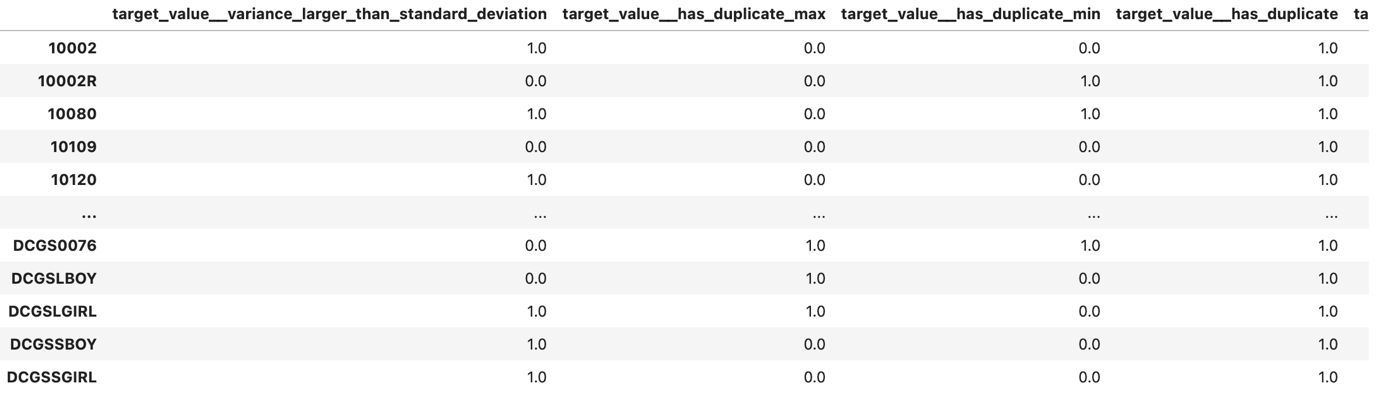
Seuraavaksi jätämme kaikki ominaisuudet pois n/a arvoja käyttämällä dropna menetelmä:
Sitten skaalaamme ominaisuuksia käyttämällä StandardScaler. Poimittujen ominaisuuksien arvot koostuvat sekä negatiivisista että positiivisista arvoista. Siksi käytämme StandardScaler sijasta MinMaxScaler:
Käytämme PCA:ta mittasuhteiden pienentämiseen:
Ja määritämme PCA:lle optimaalisen komponenttien määrän:
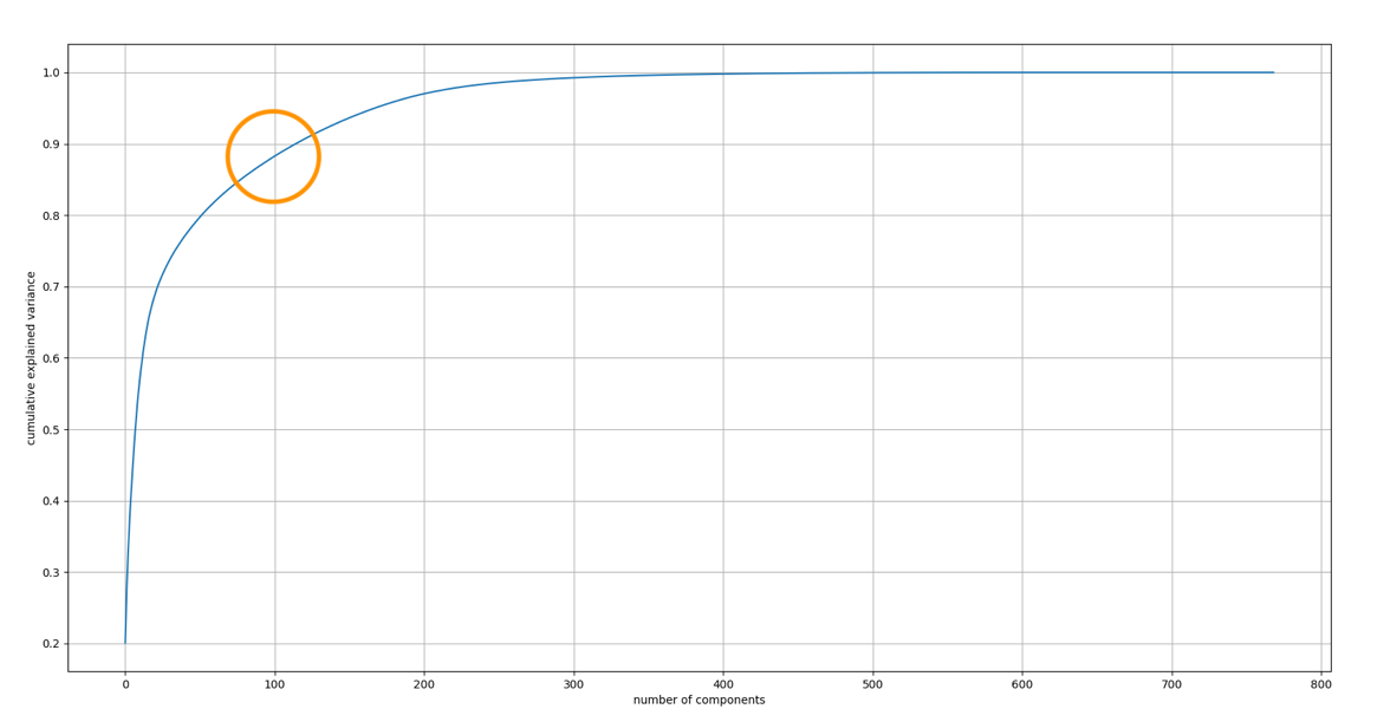
Selitetty varianssisuhde on kunkin valitun komponentin varianssiprosentti. Yleensä määrität malliin sisällytettävien komponenttien lukumäärän lisäämällä kumulatiivisesti kunkin komponentin selitetyn varianssisuhteen, kunnes saavutat arvon 0.8–0.9, jotta vältytään liialliselta sovittamiselta. Optimaalinen arvo löytyy yleensä kyynärpäästä.
Kuten seuraavassa taulukossa näkyy, kyynärpään arvo on noin 100. Siksi käytämme PCA:n komponenttien lukumääränä 100:aa.
Klusterointi K-Meansin avulla
Käytetään nyt K-Meansia euklidisen etäisyysmetriikan kanssa klusterointiin. Seuraavassa koodinpätkässä määritämme optimaalisen klusterien määrän. Lisää klustereita pienentää inertia-arvoa, mutta se myös vähentää kunkin klusterin sisältämää tietoa. Lisäksi enemmän klustereita tarkoittaa enemmän ylläpidettäviä paikallisia malleja. Siksi haluamme pienen klusterin koon suhteellisen alhaisella inertia-arvolla. Kyynärpääheuristiikka toimii hyvin optimaalisen klusterimäärän löytämisessä.
Seuraava kaavio havainnollistaa havaintojamme.
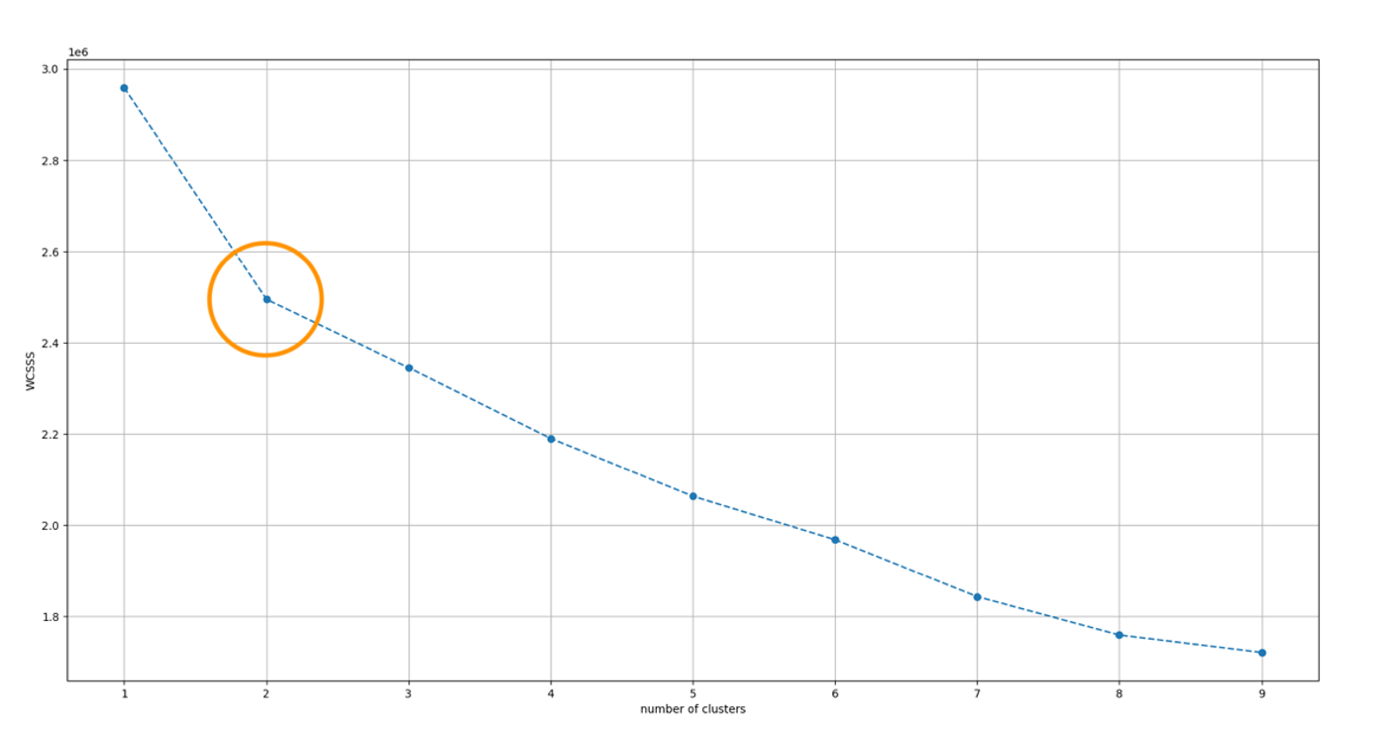
Tämän kaavion perusteella olemme päättäneet käyttää kahta klusteria K-Meansille. Teimme tämän päätöksen, koska klusterin sisäinen neliösumma (WCSS) pienenee suurimmalla nopeudella yhden ja kahden klusterin välillä. On tärkeää tasapainottaa huollon helppous mallin suorituskyvyn ja monimutkaisuuden kanssa, koska vaikka WCSS laskee edelleen klustereiden lisääntyessä, lisäklusterit lisäävät yliasennusriskiä. Lisäksi pienet vaihtelut tietojoukossa voivat yllättäen heikentää tarkkuutta.
On tärkeää huomata, että molemmat klusterointimenetelmät, K-Means euklidisen etäisyyden kanssa (käsitelty tässä viestissä) ja K-keinoalgoritmi DTW:llä, joilla on vahvuutensa ja heikkoutensa. Paras lähestymistapa riippuu tietojesi luonteesta ja käyttämistäsi ennustemenetelmistä. Siksi suosittelemme kokeilemaan molempia lähestymistapoja ja vertailemaan niiden tehokkuutta kokonaisvaltaisemman käsityksen saamiseksi tiedoistasi.
Yhteenveto
Tässä viestissä keskustelimme aikasarjatietojen ominaisuuksien poimimisen ja klusteroinnin tehokkaista tekniikoista. Erityisesti osoitimme, kuinka voit käyttää TSFreshiä, suosittua Python-kirjastoa piirteiden poimimiseen, aikasarjatietojen esikäsittelyyn ja merkityksellisten ominaisuuksien hankkimiseen.
Kun klusterointivaihe on valmis, voit kouluttaa useita ennustemalleja kullekin klusterille tai käyttää klusterin määritystä ominaisuutena. Viittaavat Amazon Forecast -kehittäjäopas tietoja varten tietojen nieleminen, ennustaja koulutusja ennusteiden luominen. Jos sinulla on nimikkeiden metatietoja ja niihin liittyviä aikasarjatietoja, voit myös sisällyttää ne syöttötietojoukkoihin Ennuste-koulutukseen. Lisätietoja on kohdassa Aloita onnistunut matkasi aikasarjaennusteilla Amazon Forecastin avulla.
Viitteet
Tietoja Tekijät
 Aleksandr Patrušev on AI/ML Specialist Solutions -arkkitehti AWS:ssä Luxemburgissa. Hän on intohimoinen pilvestä ja koneoppimisesta sekä tavasta, jolla ne voivat muuttaa maailmaa. Työn ulkopuolella hän nauttii vaeltamisesta, urheilusta ja perheen kanssa viettämisestä.
Aleksandr Patrušev on AI/ML Specialist Solutions -arkkitehti AWS:ssä Luxemburgissa. Hän on intohimoinen pilvestä ja koneoppimisesta sekä tavasta, jolla ne voivat muuttaa maailmaa. Työn ulkopuolella hän nauttii vaeltamisesta, urheilusta ja perheen kanssa viettämisestä.
 Chong En Lim on ratkaisuarkkitehti AWS:ssä. Hän etsii jatkuvasti tapoja auttaa asiakkaita innovoimaan ja parantamaan työnkulkuaan. Vapaa-ajallaan hän tykkää katsoa animea ja kuunnella musiikkia.
Chong En Lim on ratkaisuarkkitehti AWS:ssä. Hän etsii jatkuvasti tapoja auttaa asiakkaita innovoimaan ja parantamaan työnkulkuaan. Vapaa-ajallaan hän tykkää katsoa animea ja kuunnella musiikkia.
 Egor Miasnikov on ratkaisuarkkitehti AWS:ssä Saksassa. Hän on intohimoinen elämämme, liiketoimintojemme ja itse maailman digitaalisesta muutoksesta sekä tekoälyn roolista tässä muutoksessa. Työn ulkopuolella hän lukee seikkailukirjoja, vaeltaa ja viettää aikaa perheensä kanssa.
Egor Miasnikov on ratkaisuarkkitehti AWS:ssä Saksassa. Hän on intohimoinen elämämme, liiketoimintojemme ja itse maailman digitaalisesta muutoksesta sekä tekoälyn roolista tässä muutoksessa. Työn ulkopuolella hän lukee seikkailukirjoja, vaeltaa ja viettää aikaa perheensä kanssa.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- Platoblockchain. Web3 Metaverse Intelligence. Tietoa laajennettu. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/machine-learning/boost-your-forecast-accuracy-with-time-series-clustering/
- :On
- 1
- 10
- 100
- 7
- 8
- 9
- a
- Meistä
- tarkkuus
- Lisäksi
- lisä-
- Lisäksi
- etuja
- Seikkailu
- AI / ML
- algoritmi
- Kaikki
- mahdollistaa
- Vaikka
- aina
- Amazon
- keskuudessa
- analysoida
- ja
- Anime
- Toinen
- käyttää
- lähestymistapa
- lähestymistavat
- suunnilleen
- OVAT
- keinotekoinen
- tekoäly
- AS
- At
- saatavissa
- välttää
- AWS
- Balance
- perustua
- perustiedot
- koska
- PARAS
- Paremmin
- välillä
- Kirjat
- edistää
- Rakentaminen
- liiketoiminta
- yritykset
- by
- laskee
- nimeltään
- CAN
- muuttaa
- ominaisuudet
- Kaavio
- luokittelu
- Siivous
- pilvi
- Cluster
- klustereiden
- koodi
- Yhteinen
- yleisesti
- vertaamalla
- kilpailukykyinen
- täydellinen
- monimutkaisuus
- komponentti
- osat
- tietojenkäsittely
- Konfigurointi
- sisältää
- jatkuu
- muunnetaan
- voisi
- Asiakkaat
- tiedot
- datapisteet
- aineistot
- päätti
- päätös
- päätökset
- vähentää
- Aste
- riippuu
- yksityiskohtainen
- Määrittää
- Kehittäjä
- Kehitys
- poikkeama
- digitaalinen
- Digital Transformation
- Ulottuvuus
- suoraan
- keskusteltiin
- etäisyys
- ei
- Pudota
- dynaaminen
- kukin
- tehokas
- myöskään
- mahdollistaa
- ympäristö
- Eetteri (ETH)
- esimerkki
- näyttely
- selitti
- selitys
- tutkia
- Tutkiminen
- uute
- uuttaminen
- perhe
- Ominaisuus
- Ominaisuudet
- löytäminen
- jälkeen
- varten
- Ennuste
- Ilmainen
- alkaen
- Lisäksi
- Saada
- tuottaa
- Saksa
- Global
- gluoni
- suuri
- Ryhmän
- Olla
- auttaa
- korkeampi
- suurin
- erittäin
- retkeily
- kokonaisvaltainen
- Miten
- Miten
- Kuitenkin
- HTML
- http
- HTTPS
- i
- ICS
- täytäntöön
- tuoda
- tärkeä
- parantaa
- in
- sisältää
- sisältää
- Kasvaa
- henkilökohtainen
- inertia
- tiedot
- innovoida
- panos
- sen sijaan
- integroitu
- Älykkyys
- IT
- kohdetta
- SEN
- itse
- matka
- suuri
- OPPIA
- oppiminen
- kirjastot
- Kirjasto
- pitää
- Kuunteleminen
- Lives
- paikallinen
- Matala
- Luxemburg
- kone
- koneoppiminen
- tehty
- ylläpitää
- huolto
- merkittävä
- tehdä
- mielekäs
- välineet
- Metadata
- menetelmä
- menetelmät
- metrinen
- ML
- malli
- mallit
- lisää
- tehokkaampi
- eniten
- moninkertainen
- Musiikki
- luonto
- negatiivinen
- Melu
- muistikirja
- numero
- saada
- of
- on
- ONE
- verkossa
- online vähittäiskaupan
- optimaalinen
- tilata
- Muuta
- ulkopuolella
- paketti
- intohimoinen
- kuviot
- osuus
- suorittaa
- suorituskyky
- aika
- Platon
- Platonin tietotieto
- PlatonData
- pistettä
- Suosittu
- positiivinen
- Kirje
- voimakas
- prosessi
- edistää
- tarjoaa
- tarkoitus
- Python
- hinta
- Hinnat
- suhde
- tavoittaa
- Lukeminen
- suositella
- vähentää
- vähentää
- liittyvä
- suhteellisesti
- poistaa
- poistamalla
- vähittäiskauppa
- säilyttäen
- Riski
- Rooli
- juoksu
- sagemaker
- Asteikko
- skaalaus
- etsiä
- valittu
- erillinen
- Järjestys
- Sarjat
- Palvelut
- Vuorot
- puute
- esitetty
- Koko
- pieni
- Ratkaisumme
- jonkin verran
- asiantuntija
- erityinen
- erityisesti
- menot
- Urheilu
- neliöitä
- Pysyvyys
- standardi
- Alkaa
- Vaihe
- Askeleet
- vahvuudet
- onnistunut
- taulukko
- tekniikat
- että
- -
- tiedot
- maailma
- heidän
- siten
- siksi
- Nämä
- aika
- Aikasarja
- aikaleima
- että
- yhdessä
- Juna
- koulutus
- Muutos
- Trendit
- VUORO
- tyypillisesti
- ymmärtäminen
- yksikkö
- us
- käyttää
- yleensä
- Hyödyntämällä
- arvo
- arvot
- eri
- vs
- katsomassa
- Tapa..
- tavalla
- Web-pohjainen
- HYVIN
- joka
- vaikka
- KUKA
- with
- Referenssit
- työnkulkuja
- toimii
- maailman-
- Sinun
- zephyrnet