Viime vuosien tutkimukset ovat osoittaneet, että koneoppimismallit (ML) ovat haavoittuvia kontradiktoriset panokset, jossa vastustaja voi luoda syötteitä muuttaakseen strategisesti mallin tulosta (in kuvan luokittelu, puheentunnistustai petosten havaitseminen). Kuvittele esimerkiksi, että olet ottanut käyttöön mallin, joka tunnistaa työntekijäsi heidän kasvojensa kuvien perusteella. Kuten valkoisessa paperissa osoitetaan Rikokseen osallistuminen: Todelliset ja salakavalat hyökkäykset huippuluokan kasvojentunnistusta vastaan, pahantahtoiset työntekijät voivat tehdä hienovaraisia, mutta huolellisesti suunniteltuja muutoksia imagoonsa ja huijata mallia tunnistaakseen heidät muina työntekijöinä. On selvää, että sellaisilla vastakkaisilla panoksilla – varsinkin jos niitä on huomattava määrä – voi olla tuhoisa vaikutus liiketoimintaan.
Ihannetapauksessa haluamme havaita joka kerta, kun malliin lähetetään kilpaileva syöttö, jotta voidaan kvantifioida, kuinka kilpailevat panokset vaikuttavat malliisi ja liiketoimintaasi. Tätä varten laaja joukko menetelmiä analysoi yksittäisten mallien syötteitä kilpailevan käyttäytymisen tarkistamiseksi. Aktiivinen kilpailevan ML:n tutkimus on kuitenkin johtanut yhä kehittyneempiin kilpaileviin tuloksiin, joista monien tiedetään tekevän havaitsemisen tehottomana. Syynä tähän puutteeseen on se, että yksittäisen panoksen perusteella on vaikea tehdä johtopäätöksiä siitä, onko se vastakkainen vai ei. Tätä varten viimeaikainen menetelmäluokka keskittyy jakelutason tarkistuksiin analysoimalla useita syötteitä kerrallaan. Näiden uusien menetelmien perusideana on, että useiden syötteiden huomioon ottaminen kerralla mahdollistaa tehokkaamman tilastollisen analyysin, joka ei ole mahdollista yksittäisillä syötteillä. Kuitenkin, jos edessä on määrätietoinen vastustaja, jolla on syvällinen malli tuntemus, jopa nämä edistyneet tunnistusmenetelmät voivat epäonnistua.
Voimme kuitenkin voittaa nämäkin päättäväiset vastustajat antamalla puolustusmenetelmille lisätietoa. Tarkemmin sanottuna pelkän mallisyötteiden analysoinnin sijaan syvän hermoverkon välikerroksista kerättyjen piilevien esitysten analysointi vahvistaa merkittävästi puolustusta.
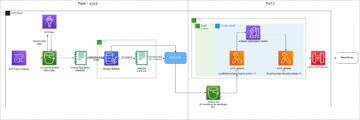
Tässä viestissä opastamme sinua, kuinka voit havaita vastakkaiset syötteet käyttämällä Amazon SageMaker -mallimonitori ja Amazon SageMaker -korjaamo kuvan luokitusmallille, jota isännöidään Amazon Sage Maker.
Toistaaksesi tässä viestissä luetellut eri vaiheet ja tulokset, kloonaa arkisto Detection-adversarial-samples-using-sagemaker Amazon SageMaker -muistikirjan ilmentymään ja suorita muistikirja.
Vastakkaisten syötteiden havaitseminen
Näytämme sinulle, kuinka voit havaita kontradiktoriset syötteet käyttämällä syvästä hermoverkosta kerättyjä esityksiä. Seuraavat neljä kuvaa näyttävät alkuperäisen harjoituskuvan vasemmalla (otettu Tiny ImageNet -tietojoukosta) ja kolme kuvaa, jotka on tuotettu Projected Gradient Descent (PGD) -hyökkäyksellä [1] erilaisilla häiriöparametreilla ϵ. Tässä käytetty malli oli ResNet18. ϵ-parametri määrittää kuviin lisätyn vastakkaisen kohinan määrän. Alkuperäinen kuva (vasemmalla) on oikein ennustettu luokkaan 67 (goose). Vastuullisesti muokatut kuvat 2, 3 ja 4 on virheellisesti ennustettu luokkaan 51 (mantis) ResNet18-mallilla. Voimme myös nähdä, että pienellä ϵ:llä luodut kuvat ovat havainnollisesti mahdottomia erottaa alkuperäisestä syöttökuvasta.

Seuraavaksi luomme joukon normaaleja ja vastustavia kuvia ja käytämme niitä t-Hajautettu stokastinen naapuri upottaminen (t-SNE [2]) vertaillakseen niiden jakaumia visuaalisesti. t-SNE on ulottuvuuden vähentämismenetelmä, joka kartoittaa korkeadimensionaaliset tiedot 2- tai 3-ulotteiseen tilaan. Jokainen datapiste seuraavassa kuvassa esittää syötekuvan. Oranssit tietopisteet esittävät testisarjasta otettuja normaaleja syötteitä, ja siniset datapisteet osoittavat vastaavat vastustavat kuvat, jotka on luotu epsilonilla 0.003. Jos normaalit ja kontradiktoriset syötteet ovat erotettavissa, odotamme erilliset klusterit t-SNE-visualisoinnissa. Koska molemmat kuuluvat samaan klusteriin, tämä tarkoittaa, että tunnistustekniikka, joka keskittyy yksinomaan mallin syöttöjakauman muutoksiin, ei pysty erottamaan näitä syötteitä.

Tarkastellaan lähemmin ResNet18-mallin eri kerrosten tuottamia kerrosesityksiä. ResNet18 koostuu 18 kerroksesta; seuraavassa kuvassa visualisoimme t-SNE-upotukset kuudelle näistä tasoista.

Kuten edellinen kuva osoittaa, luonnolliset ja kontradiktoriset syötteet erottuvat paremmin ResNet18-mallin syvemmistä kerroksista.
Näiden havaintojen perusteella käytämme tilastollista menetelmää, joka mittaa erotettavuutta hypoteesitestauksella. Menetelmä koostuu a kahden näytteen testi käyttämällä suurin keskimääräinen poikkeama (MMD). MMD on ytimeen perustuva mittari, jolla mitataan kahden datan tuottavan jakelun samankaltaisuutta. Kahden näytteen testi ottaa kaksi joukkoa, jotka sisältävät syötteitä kahdesta jakaumasta, ja määrittää, ovatko nämä jakaumat samat. Vertaamme opetustiedoissa havaittujen syötteiden jakautumista ja vertaamme sitä päättelyn aikana saatujen syötteiden jakautumiseen.
Menetelmämme käyttää näitä syötteitä p-arvon arvioimiseen MMD:n avulla. Jos p-arvo on suurempi kuin käyttäjäkohtainen merkitsevyyskynnys (tapauksessamme 5 %), päättelemme, että molemmat jakaumat ovat erilaisia. Kynnys säätää väärien positiivisten ja väärien negatiivisten välisen kompromissin. Korkeampi kynnys, kuten 10 %, vähentää vääriä negatiivista määrää (tapauksia, joissa molemmat jakautumat olivat erilaiset, on vähemmän, mutta testi ei osoittanut sitä). Se johtaa kuitenkin myös enemmän vääriin positiivisiin tuloksiin (testi osoittaa, että molemmat jakaumat ovat erilaisia, vaikka näin ei olisikaan). Toisaalta alempi kynnys, kuten 1 %, johtaa vähemmän vääriin positiivisiin, mutta enemmän vääriin negatiivisiin.
Sen sijaan, että käyttäisimme tätä menetelmää vain mallin raakatuloissa (kuvissa), käytämme mallimme välikerrosten tuottamia piileviä esityksiä. Sen todennäköisyyden huomioon ottamiseksi käytämme hypoteesitestiä 100 kertaa 100 satunnaisesti valitulle luonnolliselle syötteelle ja 100 satunnaisesti valitulle kontradiktoriselle syötteelle. Sitten raportoimme havaitsemissuhteen niiden testien prosenttiosuutena, jotka johtivat havaitsemistapahtumaan 5 %:n merkitsevyyskynnyksemme mukaisesti. Korkeampi havaitsemisnopeus on vahvempi osoitus siitä, että nämä kaksi jakaumaa ovat erilaisia. Tämä menettely antaa meille seuraavat havaitsemisnopeudet:
- Taso 1: 3 %
- Taso 4: 7 %
- Taso 8: 84 %
- Taso 12: 95 %
- Taso 14: 100 %
- Taso 15: 100 %
Alkukerroksissa havaitsemisnopeus on melko alhainen (alle 10 %), mutta nousee 100 prosenttiin syvissä kerroksissa. Tilastollisen testin avulla menetelmä voi luotettavasti havaita vastustavia syötteitä syvemmistä kerroksista. Usein riittää, että käytetään yksinkertaisesti toiseksi viimeisen kerroksen (mallin viimeinen kerros ennen luokituskerrosta) generoimia esityksiä. Kehittyneemmille vastavuoroisille syötteille on hyödyllistä käyttää muiden tasojen esityksiä ja koota havaitsemisnopeudet.
Ratkaisun yleiskatsaus
Edellisessä osiossa näimme kuinka havaita vastakkaiset syötteet käyttämällä esityksiä toiseksi viimeisestä kerroksesta. Seuraavaksi näytämme kuinka automatisoida nämä testit SageMakerissa käyttämällä Model Monitoria ja Debuggeria. Tätä esimerkkiä varten koulutamme ensin kuvaluokituksen ResNet18-mallin pienessä ImageNet-tietojoukossa. Seuraavaksi otamme mallin käyttöön SageMakerissa ja luomme mukautetun Model Monitor -aikataulun, joka suorittaa tilastollisen testin. Jälkeenpäin teemme päätelmiä normaaleista ja kontradiktorisista syötteistä nähdäksemme kuinka tehokas menetelmä on.
Kaappaa tensorit Debuggerilla
Mallin koulutuksen aikana käytämme Debuggeria kaapataksemme toiseksi viimeisen kerroksen generoimat esitykset, joita käytetään myöhemmin johtamaan tietoa normaalien syötteiden jakautumisesta. Debugger on SageMakerin ominaisuus, jonka avulla voit kaapata ja analysoida tietoja, kuten malliparametreja, gradientteja ja aktivaatioita mallin harjoittelun aikana. Nämä parametri-, gradientti- ja aktivointitensorit ladataan kohteeseen Amazonin yksinkertainen tallennuspalvelu (Amazon S3) koulutuksen aikana. Voit määrittää sääntöjä, jotka analysoivat näitä ongelmia, kuten liiallisia ja katoavia liukuvärejä varten. Meidän käyttötapauksessamme haluamme vain kaapata mallin toiseksi viimeisen kerroksen (.*avgpool_output) ja mallin tulosteet (ennusteet). Määritämme Debugger-koukun kokoonpanon, joka määrittää säännöllisen lausekkeen kerättäville tasoesityksille. Määrittelemme myös a save_interval joka käskee Debuggerin keräämään nämä tiedot vahvistusvaiheen aikana joka 100 eteenpäin. Katso seuraava koodi:
Suorita SageMaker-koulutus
Välitämme Debugger-kokoonpanon SageMaker-estimaattoriin ja aloitamme harjoittelun:
Ota käyttöön kuvien luokitusmalli
Kun mallin koulutus on valmis, otamme mallin käyttöön SageMakerin päätepisteenä. Määritämme an päättelyskripti joka määrittelee model_fn ja transform_fn toimintoja. Nämä toiminnot määrittävät, kuinka malli ladataan ja kuinka saapuvat tiedot on esikäsiteltävä mallipäätelmän suorittamiseksi. Käyttötapauksessamme sallimme Debuggerin kaapata oleellisia tietoja päättelyn aikana. Vuonna model_fn funktio, määritämme Debugger-koukun ja a save_config joka määrittää, että jokaiselle päättelypyynnölle mallin syötteet (kuvat), mallin lähdöt (ennusteet) ja toiseksi viimeinen kerros tallennetaan (.*avgpool_output). Sitten rekisteröimme koukun malliin. Katso seuraava koodi:
Nyt otamme mallin käyttöön, jonka voimme tehdä kannettavasta kahdella tavalla. Voimme joko soittaa pytorch_estimator.deploy() tai luo PyTorch-malli, joka osoittaa Amazon S3:n malliartefakttitiedostoihin, jotka on luotu SageMaker-harjoitustyön avulla. Tässä viestissä teemme jälkimmäisen. Tämän ansiosta voimme siirtää ympäristömuuttujia Docker-säilöyn, jonka SageMaker on luonut ja ottanut käyttöön. Tarvitsemme ympäristömuuttujan tensors_output kertoaksesi skriptille, mihin SageMaker Debuggerin päättelyn aikana keräämät tensorit ladataan. Katso seuraava koodi:
Seuraavaksi otamme ennustajan käyttöön ml.m5.xlarge ilmentymätyypissä:
Luo mukautettu mallinvalvontaaikataulu
Kun päätepiste on käytössä, luomme mukautetun Model Monitor -aikataulun. Tämä on SageMaker-käsittelytyö joka toimii säännöllisin väliajoin (kuten tunneittain tai päivittäin) ja analysoi johtopäätöstiedot. Model Monitor tarjoaa esikonfiguroidun säilön, joka analysoi ja havaitsee tiedon siirtymisen. Meidän tapauksessamme haluamme mukauttaa sen hakemaan virheenkorjaustiedot ja suorittamaan MMD-kahden näytteen testin haetuille kerrosesityksille.
Mukautaksemme sitä määritämme ensin Model Monitor -objektin, joka määrittää, millä ilmentymätyypillä nämä työt ajetaan, ja mukautetun Model Monitor -säilön sijainnin:
Haluamme suorittaa tämän työn tuntiperusteisesti, joten tarkennamme CronExpressionGenerator.hourly() ja tulostuspaikat, joihin analyysitulokset ladataan. Sitä varten meidän on määriteltävä ProcessingOutput SageMaker-käsittelytulosteen osalta:
Katsotaanpa tarkemmin, mitä mukautettu Model Monitor -säilömme käyttää. Luomme an arviointiskripti, joka lataa Debuggerin keräämät tiedot. Luomme myös a koekohde, jonka avulla voimme käyttää, tehdä kyselyitä ja suodattaa Debuggerin tallentamia tietoja. Kokeiluobjektin avulla voimme iteroida päättely- ja koulutusvaiheiden aikana tallennettuja vaiheita trial.steps(mode).
Ensin noudetaan mallin tulosteet (trial.tensor("ResNet_output_0")) sekä toiseksi viimeinen kerros (trial.tensor_names(regex=".*avgpool_output")). Teemme tämän koulutuksen päättely- ja validointivaiheita varten (modes.EVAL ja modes.PREDICT). Validointivaiheen tensorit toimivat normaalijakauman estimaattina, jota käytämme sitten johtopäätöstietojen jakautumisen vertailuun. Loimme luokan LADIS (Kiinnostavien syötejakaumien havaitseminen Layerwise Statisticsin kautta). Tämä luokka tarjoaa tarvittavat toiminnot kahden näytteen testin suorittamiseen. Se ottaa tensoriluettelon päättely- ja validointivaiheista ja suorittaa kahden näytteen testin. Se palauttaa tunnistussuhteen, joka on arvo välillä 0–100 %. Mitä suurempi arvo, sitä todennäköisemmin päättelydata noudattaa erilaista jakaumaa. Lisäksi laskemme kullekin näytteelle pistemäärän, joka osoittaa, kuinka todennäköistä on, että näyte on vastakkainen, ja 100 parasta näytettä kirjataan, jotta käyttäjät voivat tarkastaa niitä edelleen. Katso seuraava koodi:
Testaa vastustavia syötteitä
Nyt kun mukautettu Model Monitor -aikataulumme on otettu käyttöön, voimme tuottaa joitain johtopäätöksiä.
Ensin suoritamme datan holdout-joukosta ja sitten kontradiktorisilla syötteillä:
Voimme sitten tarkistaa Model Monitor -näytön Amazon SageMaker Studio tai käyttö amazonin pilvikello lokit nähdäksesi, löytyikö ongelma.

Seuraavaksi käytämme kontradiktorisia syötteitä SageMakerissa isännöityä mallia vastaan. Käytämme Tiny ImageNet -tietojoukon testiaineistoa ja käytämme PGD-hyökkäystä, joka aiheuttaa häiriöitä pikselitasolla, jotta malli ei tunnista oikeita luokkia. Seuraavissa kuvissa vasemmassa sarakkeessa näkyy kaksi alkuperäistä testikuvaa, keskimmäinen sarake näyttää niiden kiistan häiritsevät versiot ja oikea sarake näyttää eron molempien kuvien välillä.

Nyt voimme tarkistaa Model Monitor -tilan ja nähdä, että osa päättelykuvista on otettu eri jakelusta.

Tulokset ja käyttäjän toimet
Mukautettu Model Monitor -työ määrittää kullekin päättelypyynnölle pisteet, jotka osoittavat, kuinka todennäköisesti näyte on kontradiktorinen MMD-testin mukaan. Nämä pisteet kerätään kaikista päättelypyynnöistä. Heidän pisteensä vastaavalla Debuggerin vaihenumerolla tallennetaan JSON-tiedostoon ja ladataan Amazon S3:een. Kun Model Monitoring -työ on valmis, lataamme JSON-tiedoston, haemme vaihenumerot ja käytämme Debuggeria näiden vaiheiden vastaavien mallisyötteiden noutamiseen. Tämän avulla voimme tarkastaa kuvia, jotka havaittiin kilpaileviksi.
Seuraava koodilohko piirtää kaksi ensimmäistä kuvaa, jotka on tunnistettu todennäköisimmin kilpaileviksi:
Esimerkkikoeajossamme saamme seuraavan tulosteen. Meduusakuva ennustettiin väärin oranssiksi ja kamelin kuva pandaksi. Ilmeisesti malli epäonnistui näillä tuloilla eikä edes ennustanut samanlaista kuvaluokkaa, kuten kultakalaa tai hevosta. Vertailun vuoksi näytämme oikealla puolella myös vastaavat luonnonnäytteet testisarjasta. Voimme havaita, että hyökkääjän aiheuttamat satunnaiset häiriöt näkyvät hyvin molempien kuvien taustalla.


Mukautettu Model Monitor -työ julkaisee havaitsemisnopeuden CloudWatchille, jotta voimme tutkia, kuinka tämä nopeus on muuttunut ajan myötä. Merkittävä muutos kahden datapisteen välillä voi osoittaa, että vastustaja yritti huijata mallia tietyllä aikavälillä. Lisäksi voit myös piirtää kussakin Model Monitor -työssä käsiteltävien päättelypyyntöjen määrän ja perustason tunnistussuhteen, joka lasketaan vahvistustietojoukon perusteella. Perustaso on yleensä lähellä nollaa ja toimii vain vertailumittarina.
Seuraavassa kuvakaappauksessa näkyvät testiajojemme luomat tiedot, jotka suorittivat kolme Model Monitoring -työtä 3 tunnin aikana. Kukin työ käsittelee noin 200–300 päättelypyyntöä kerrallaan. Havaintosuhde on 100 % klo 5-00 ja laskee sen jälkeen.

Lisäksi voimme myös tarkastella mallin välikerrosten generoimien esitysten jakaumia. Debuggerin avulla voimme päästä käsiksi koulutustyön validointivaiheen tietoihin ja päättelyvaiheen tensoreihin sekä t-SNE:n avulla visualisoida niiden jakautuminen tietyille ennustetuille luokille. Katso seuraava koodi:
Testitapauksessamme saamme seuraavan t-SNE-visualisoinnin toiselle kuvaluokalle. Voimme havaita, että kontradiktoriset näytteet ovat ryhmittyneet eri tavalla kuin luonnolliset.

Yhteenveto
Tässä viestissä osoitimme, kuinka käyttää kahden otoksen testiä käyttämällä suurinta keskimääräistä ristiriitaa kilpailevien syötteiden havaitsemiseen. Osoitimme, kuinka voit ottaa käyttöön tällaisia tunnistusmekanismeja käyttämällä Debuggeria ja Model Monitoria. Tämän työnkulun avulla voit tarkkailla SageMakerissa isännöityjä mallejasi mittakaavassa ja havaita kilpailevat syötteet automaattisesti. Jos haluat lisätietoja siitä, tutustu meidän GitHub repo.
Viitteet
[1] Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras ja Adrian Vladu. Kohti syvää oppimismalleja, jotka kestävät vastakkaisia hyökkäyksiä. Sisään Kansainvälinen konferenssi oppimisedustuksista, 2018.
[2] Laurens van der Maaten ja Geoffrey Hinton. Datan visualisointi t-SNE:n avulla. Journal of Machine Learning Research, 9:2579–2605, 2008. URL http://www.jmlr.org/papers/v9/vandermaaten08a.html.
Tietoja Tekijät
 Nathalie Rauschmayr on vanhempi sovellettu tutkija AWS:ssä, jossa hän auttaa asiakkaita kehittämään syväoppimissovelluksia.
Nathalie Rauschmayr on vanhempi sovellettu tutkija AWS:ssä, jossa hän auttaa asiakkaita kehittämään syväoppimissovelluksia.
 Yigitcan Kaya on viidennen vuoden tohtoriopiskelija Marylandin yliopistossa ja soveltava tutkijaharjoittelija AWS:ssä. Hän työskentelee koneoppimisen turvallisuuden ja koneoppimisen sovellusten parissa.
Yigitcan Kaya on viidennen vuoden tohtoriopiskelija Marylandin yliopistossa ja soveltava tutkijaharjoittelija AWS:ssä. Hän työskentelee koneoppimisen turvallisuuden ja koneoppimisen sovellusten parissa.
 Bilal Zafar on AWS:n soveltava tutkija, joka työskentelee koneoppimisen oikeudenmukaisuuden, selitettävyyden ja turvallisuuden parissa.
Bilal Zafar on AWS:n soveltava tutkija, joka työskentelee koneoppimisen oikeudenmukaisuuden, selitettävyyden ja turvallisuuden parissa.
 Sergul Aydore on AWS:n vanhempi soveltuva tutkija, joka työskentelee koneoppimisen yksityisyyden ja turvallisuuden parissa
Sergul Aydore on AWS:n vanhempi soveltuva tutkija, joka työskentelee koneoppimisen yksityisyyden ja turvallisuuden parissa
- Coinsmart. Euroopan paras Bitcoin- ja kryptopörssi.
- Platoblockchain. Web3 Metaverse Intelligence. Tietoa laajennettu. VAPAA PÄÄSY.
- CryptoHawk. Altcoinin tutka. Ilmainen kokeilu.
- Lähde: https://aws.amazon.com/blogs/machine-learning/detect-adversarial-inputs-using-amazon-sagemaker-model-monitor-and-amazon-sagemaker-debugger/
- "
- 10
- 100
- 67
- 9
- Meistä
- pääsy
- Mukaan
- Tili
- aktiivinen
- lisä-
- kehittynyt
- Kaikki
- Amazon
- määrä
- analyysi
- sovellukset
- Hakeminen
- suunnilleen
- AWS
- tausta
- Lähtötilanne
- perusta
- tulevat
- ovat
- Tukkia
- liiketoiminta
- soittaa
- kaapata
- tapauksissa
- muuttaa
- Tarkastukset
- luokka
- luokat
- luokittelu
- lähempänä
- koodi
- kerätä
- Sarake
- Laskea
- Konferenssi
- Konfigurointi
- Kontti
- edistävät
- luotu
- Rikollisuus
- asiakassuhde
- Asiakkaat
- tiedot
- syvempää
- Puolustus
- osoittivat
- sijoittaa
- käyttöön
- havaittu
- Detection
- kehittää
- eri
- vaikea
- näyttö
- jakelu
- Satamatyöläinen
- ei
- Tehokas
- työntekijää
- mahdollistaa
- päätepiste
- ympäristö
- arvio
- tapahtuma
- esimerkki
- odottaa
- Kasvot
- kasvot
- Ominaisuus
- Kuva
- Etunimi
- keskittyy
- jälkeen
- Eteenpäin
- löytyi
- FRAME
- koko
- toiminto
- edelleen
- tuottaa
- menee
- suurempi
- auttaa
- tätä
- korkeampi
- Miten
- Miten
- HTTPS
- ajatus
- kuva
- Vaikutus
- indeksi
- henkilökohtainen
- tiedot
- panos
- tutkia
- kysymys
- kysymykset
- IT
- Job
- Työpaikat
- päiväkirja
- avain
- tuntemus
- tunnettu
- tarrat
- suuri
- OPPIA
- oppiminen
- Led
- Taso
- Todennäköisesti
- Lista
- lueteltu
- sijainti
- sijainnit
- kone
- koneoppiminen
- Kartat
- Maryland
- Metrics
- MIT
- ML
- malli
- mallit
- monitori
- seuranta
- lisää
- eniten
- moninkertainen
- Luonnollinen
- luonto
- verkko
- Melu
- normaali
- muistikirja
- numero
- numerot
- Muut
- osuus
- vaihe
- Kohta
- mahdollinen
- voimakas
- ennustaa
- ennustus
- Ennusteet
- esittää
- yksityisyys
- Tietosuoja ja turvallisuus
- Prosessit
- tuottaa
- valmistettu
- tarjoaa
- tarjoamalla
- Hinnat
- raaka
- tunnistaa
- ilmoittautua
- säännöllinen
- merkityksellinen
- raportti
- säilytyspaikka
- pyyntö
- pyynnöt
- tutkimus
- tulokset
- Tuotto
- säännöt
- ajaa
- juoksu
- Asteikko
- Tiedemies
- turvallisuus
- valittu
- setti
- merkittävä
- samankaltainen
- Yksinkertainen
- SIX
- pieni
- So
- jonkin verran
- hienostunut
- Tila
- erityisesti
- Alkaa
- huippu-
- tilastollinen
- tilasto
- tilastot
- Tila
- Levytila
- opiskelija
- testi
- Testaus
- testit
- Kautta
- aika
- ylin
- kohti
- koulutus
- oikeudenkäynti
- yliopisto
- us
- käyttää
- Käyttäjät
- yleensä
- arvo
- näkyvä
- visualisointi
- Haavoittuva
- Mitä
- onko
- vaikka
- Whitepaper
- wikipedia
- työskentely
- olisi
- vuosi
- vuotta