Joka päivä Amazon-laitteet käsittelevät ja analysoivat miljardeja tapahtumia maailmanlaajuisilta toimitus-, varasto-, kapasiteetti-, tarjonta-, myynti-, markkinointi-, tuottaja- ja asiakaspalvelutiimeiltä. Näitä tietoja käytetään laitteiden varaston hankinnassa Amazonin asiakkaiden tarpeiden täyttämiseksi. Datavolyymien prosentuaalinen kasvu oli kaksinumeroista vuositasolla ja COVID-pandemia häiritsi maailmanlaajuista logistiikkaa vuonna 2021, joten lähes reaaliaikaisen datan skaalaamisesta ja tuottamisesta tuli kriittisempi.
Tämä viesti näyttää, kuinka siirryimme palvelimettomaan AWS:ään rakennettuun datajärveen, joka kuluttaa tietoja automaattisesti useista lähteistä ja eri muodoista. Lisäksi se loi lisää mahdollisuuksia datatieteilijöillemme ja insinööreillemme käyttää tekoäly- ja koneoppimispalveluita tietojen jatkuvaan syöttämiseen ja analysointiin.
Haasteet ja suunnitteluhuolet
Vanhaa arkkitehtuuriamme käytetään ensisijaisesti Amazonin elastinen laskentapilvi (Amazon EC2) poimimaan tiedot useista sisäisistä heterogeenisistä tietolähteistä ja REST-sovellusliittymistä yhdistämällä Amazonin yksinkertainen tallennuspalvelu (Amazon S3) ladataksesi tiedot ja Amazonin punainen siirto lisäanalyysiä ja ostotilausten luomista varten.
Huomasimme, että tämä lähestymistapa johti muutamiin puutteisiin, ja sen vuoksi parannuksia seuraavilla alueilla:
- Kehittäjän nopeus – Kaavojen yhdistämisen ja löytämisen puutteen vuoksi, jotka ovat ensisijaisia syitä ajonaikaisiin virheisiin, kehittäjät käyttivät usein aikaa käyttö- ja ylläpitoongelmien käsittelemiseen.
- skaalautuvuus – Suurin osa näistä tietojoukoista on jaettu ympäri maailmaa. Siksi meidän on täytettävä skaalausrajat, kun haemme tietoja.
- Minimaalinen infrastruktuurin huolto – Nykyinen prosessi kattaa useita laskutoimituksia tietolähteestä riippuen. Siksi infrastruktuurin ylläpidon vähentäminen on kriittistä.
- Reagointi tietolähteen muutoksiin – Nykyinen järjestelmämme saa tietoa erilaisista heterogeenisistä tietovarastoista ja palveluista. Kaikki päivitykset näihin palveluihin vievät kuukausien kehittäjäjaksoja. Näiden tietolähteiden vasteajat ovat kriittisiä keskeisille sidosryhmillemme. Siksi meidän on valittava tietopohjainen lähestymistapa korkean suorituskyvyn arkkitehtuurin valitsemiseksi.
- Varastointi ja redundanssi – Heterogeenisten tietovarastojen ja mallien vuoksi oli haastavaa tallentaa erilaisten sidosryhmien tietojoukkoja. Siksi versioinnin sekä inkrementaali- ja differentiaalitietojen vertailu tarjoaa huomattavan mahdollisuuden luoda entistä optimoitumpia suunnitelmia
- Karkoilu ja saavutettavuus – Logistiikan epävakaasta luonteesta johtuen muutamalla liiketoiminnan sidosryhmätiimellä on vaatimus analysoida kysyntätietoja ja luoda lähes reaaliaikainen optimaalinen suunnitelma ostotilauksille. Tämä tuo mukanaan sekä kyselyn että tiedon työntämisen, jotta niitä voidaan käyttää ja analysoida lähes reaaliajassa.
Toteutusstrategia
Näiden vaatimusten perusteella muutimme strategioita ja aloimme analysoida jokaista ongelmaa löytääksemme ratkaisun. Arkkitehtonisesti valitsimme palvelimettoman mallin, ja data Lake -arkkitehtuurin toimintalinja viittaa kaikkiin arkkitehtonisiin aukkoihin ja haastaviin ominaisuuksiin, jotka totesimme osaksi parannuksia. Suunnittelimme toiminnallisesta näkökulmasta uuden jaetun vastuun mallin tiedonkäsittelyyn AWS-liima sisäisten palvelujen (REST API:iden) sijaan, jotka on suunniteltu Amazon EC2:ssa tietojen purkamiseen. Käytimme myös AWS Lambda tietojen käsittelyä varten. Sitten valitsimme Amazon Athena kuin kyselypalvelumme. Lisäsimme optimoidaksemme ja parantaaksemme kehittäjien nopeutta datakuluttajillemme Amazon DynamoDB metatietovarastona datajärveen laskeutuville eri tietolähteille. Nämä kaksi päätöstä ohjasivat jokaista suunnittelu- ja toteutuspäätöstämme.
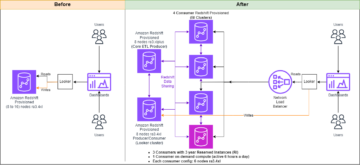
Seuraava kaavio havainnollistaa arkkitehtuuria

Seuraavissa osissa tarkastellaan jokaista arkkitehtuurin komponenttia yksityiskohtaisemmin, kun kuljemme prosessin läpi.
AWS-liima ETL:lle
Jotta voimme vastata asiakkaiden kysyntään ja tukea uusien yritysten tietolähteiden laajuutta, meille oli tärkeää, että meillä on korkea ketteryys, skaalautuvuus ja reagointikyky eri tietolähteiden kyselyissä.
AWS Glue on palvelimeton tietojen integrointipalvelu, jonka avulla analytiikkakäyttäjien on helppo löytää, valmistella, siirtää ja integroida tietoja useista lähteistä. Voit käyttää sitä analytiikkaan, ML:ään ja sovellusten kehittämiseen. Se sisältää myös lisätuottavuuden ja DataOps-työkalut luomiseen, töiden suorittamiseen ja liiketoiminnan työnkulkujen toteuttamiseen.
AWS Gluen avulla voit löytää ja muodostaa yhteyden yli 70 eri tietolähteeseen ja hallita tietojasi keskitetyssä tietoluettelossa. Voit visuaalisesti luoda, suorittaa ja valvoa poimia, muuntaa ja ladata (ETL) putkilinjoja ladataksesi tietoja datajärviisi. Voit myös etsiä ja tehdä kyselyitä luetteloituista tiedoista välittömästi käyttämällä Athenaa, Amazonin EMRja Amazonin punasiirtospektri.
AWS Glue helpotti yhteyden muodostamista eri tietovarastojen tietoihin, tietojen muokkaamista ja puhdistamista tarpeen mukaan sekä tietojen lataamista AWS:n tarjoamaan varastoon yhtenäisen näkymän saamiseksi. AWS-liimatyöt voidaan ajoittaa tai kutsua pyynnöstä tietojen poimimiseksi asiakkaan resurssista ja datajärvestä.
Jotkut näiden tehtävien velvollisuudet ovat seuraavat:
- Lähdeentiteetin purkaminen ja muuntaminen tietokokonaisuudeksi
- Paranna dataa sisältämään vuosi, kuukausi ja päivä parantaaksesi luettelointia ja sisällytä tilannekuvan tunnus parantaaksesi kyselyitä
- Suorita syötteen validointi ja polun luominen Amazon S3:lle
- Yhdistä akkreditoidut metatiedot lähdejärjestelmän perusteella
REST-sovellusliittymien kysely sisäisistä palveluista on yksi ydinhaasteistamme, ja minimaalisen infrastruktuurin vuoksi halusimme käyttää niitä tässä projektissa. AWS Glue -liittimet auttoivat meitä noudattamaan vaatimusta ja tavoitetta. Käytimme PySpark- ja JDBC-moduuleita tietojen kyselyyn REST-sovellusliittymistä ja muista tietolähteistä.
AWS Glue tukee monenlaisia liitäntätyyppejä. Katso lisätietoja osoitteesta AWS-liiman ETL-liitäntätyypit ja -vaihtoehdot.
S3-kauha laskeutumisvyöhykkeenä
Käytimme poimittujen tietojen välittömänä laskeutumisvyöhykkeenä S3-ämpäriä, jota edelleen käsitellään ja optimoidaan.
Lambda AWS Glue ETL Triggerinä
Otimme käyttöön S3-tapahtumailmoitukset S3-säilössä käynnistämään Lambdan, mikä edelleen osittaa tietomme. Tiedot on jaettu seuraaviin osioihin: InputDataSetName, Year, Month ja Date. Mikä tahansa näiden tietojen päällä toimiva kyselyprosessori skannaa vain osan tiedoista kustannusten ja suorituskyvyn optimoimiseksi. Tietomme voidaan tallentaa eri muodoissa, kuten CSV, JSON ja Parketti.
Raakadata ei ole ihanteellinen useimpiin käyttötapauksiin optimaalisen suunnitelman luomiseen, koska niissä on usein päällekkäisyyksiä tai vääriä tietotyyppejä. Mikä tärkeintä, tiedot ovat useissa muodoissa, mutta muokkasimme tietoja nopeasti ja havaitsimme merkittäviä kyselyn suorituskyvyn parannuksia Parketti-muodon käytöstä. Tässä käytimme yhtä suoritusvinkkeistä Top 10 suorituskyvyn viritysvinkkiä Amazon Athenalle.
AWS-liimatyöt ETL:lle
Halusimme parempaa tietojen erottelua ja käytettävyyttä, joten valitsimme erilaisen S3-sämpön suorituskyvyn parantamiseksi entisestään. Käytimme samoja AWS Glue -töitä tietojen muuntamiseen ja lataamiseen vaadittuun S3-säihöön ja osan puretuista metatiedoista DynamoDB:hen.
DynamoDB metatietovarastona
Nyt kun meillä on tiedot, useat yritysten sidosryhmät kuluttavat niitä edelleen. Tämä jättää meille kaksi kysymystä: mikä lähdedata on datajärvessä ja mikä versio. Valitsimme DynamoDB:n metatietosäilöksemme, joka tarjoaa viimeisimmät tiedot kuluttajille tietojen tehokkaaseen kyselyyn. Jokainen järjestelmämme tietojoukko tunnistetaan yksilöllisesti tilannevedostunnuksella, jota voimme etsiä metatietosäilöstämme. Asiakkaat pääsevät tähän tietovarastoon API:n avulla.
Amazon S3 datajärvenä
Tietojen laadun parantamiseksi poimimme rikastetut tiedot toiseen S3-säihöön, jossa oli sama AWS-liimatyö.
AWS-liimatelakone
Indeksointirobotit ovat "salainen kastike", jonka avulla voimme reagoida skeeman muutoksiin. Koko prosessin aikana päätimme tehdä jokaisesta vaiheesta mahdollisimman skeemaagnostisen, mikä mahdollistaa skeeman muutosten kulkemisen, kunnes ne saavuttavat AWS-liiman. Indeksointirobotin avulla voimme ylläpitää skeemaan tapahtuvat agnostiset muutokset. Tämä auttoi meitä automaattisesti indeksoimaan Amazon S3:n tiedot ja luomaan skeeman ja taulukot.
AWS-liimatietoluettelo
Data Catalog auttoi meitä ylläpitämään luetteloa tietojen sijainnin, skeeman ja ajonaikaisten mittareiden indeksinä Amazon S3:ssa. Tietokatalogissa olevat tiedot tallennetaan metatietotaulukoiksi, joissa jokainen taulukko määrittää yhden tietovaraston.
Athena SQL-kyselyille
Athena on interaktiivinen kyselypalvelu, jonka avulla on helppo analysoida tietoja Amazon S3:ssa tavallisella SQL:llä. Athena on palvelimeton, joten hallittavaa infrastruktuuria ei ole, ja maksat vain suorittamistasi kyselyistä. Pitimme toiminnan vakautta ja kasvavaa kehittäjänopeutta tärkeimpinä parannustekijöinämme.
Optimoimme edelleen prosessia Athena-kyselyn tekemiseksi, jotta käyttäjät voivat liittää arvot ja kyselyt saadakseen tietoja Athenasta luomalla seuraavat:
- An AWS Cloud Development Kit (AWS CDK) -malli Athena-infrastruktuurin luomiseen ja AWS-henkilöllisyyden ja käyttöoikeuksien hallinta (IAM) -rooleja, joiden avulla pääset käyttämään Data Lake S3 -säilöjä ja Data Catalogia miltä tahansa tililtä
- Kirjasto, jotta asiakas voi tarjota IAM-roolin, kyselyn, tietomuodon ja tulostussijainnin aloittaakseen Athena-kyselyn ja saadakseen kyselyn tilan ja tuloksen ajettavaksi valitsemassaan ämpäriin.
Athena-kyselyn tekeminen on kaksivaiheinen prosessi:
- StartQueryExecution – Tämä käynnistää kyselyn ja saa ajon tunnuksen. Käyttäjät voivat antaa lähtöpaikan, johon kyselyn tulos tallennetaan.
- GetQueryExecution – Tämä saa kyselyn tilan, koska ajo on asynkroninen. Kun onnistut, voit kysyä tulostetta S3-tiedostossa tai kautta API.
Apumenetelmä kyselyn käynnistämiseen ja tuloksen saamiseen olisi kirjastossa.
Data Lake -metatietopalvelu
Tämä palvelu on räätälöity ja se on vuorovaikutuksessa DynamoDB:n kanssa saadakseen metatiedot (tietojoukon nimi, tilannevedoksen tunnus, osiomerkkijono, aikaleima ja S3-linkki) REST API:n muodossa. Kun skeema löydetään, asiakkaat käyttävät Athenaa kyselyprosessorina tietojen kyselyyn.
Koska kaikilla tietojoukoilla on tilannevedoksen tunnus, ne on osioitu, liittymiskysely ei johda koko taulukon tarkistukseen, vaan ainoastaan osion tarkistukseen Amazon S3:ssa. Käytimme Athenaa kyselyprosessorina, koska se ei pysty hallitsemaan kyselyinfrastruktuuriamme. Myöhemmin, jos tunnemme tarvitsevamme jotain enemmän, voimme käyttää joko Redshift Spectrumia tai Amazon EMR:ää.
Yhteenveto
Amazon Devices -tiimit löysivät merkittävää arvoa siirtymällä data Lake -arkkitehtuuriin AWS Glue -liiman avulla, mikä mahdollisti useiden globaalien yritysten sidosryhmien nielemisen tuottavammin. Tämän ansiosta tiimit pystyivät luomaan optimaalisen suunnitelman laitteiden ostotilausten tekemiseen analysoimalla eri tietojoukot lähes reaaliajassa asianmukaisella liiketoimintalogiikalla toimitusketjun, kysynnän ja ennusteen ongelmien ratkaisemiseksi.
Toiminnallisesta näkökulmasta investointi on jo alkanut tuottaa tulosta:
- Se standardoi vastaanotto-, tallennus- ja hakumekanismimme, mikä säästää käyttöönottoaikaa. Ennen tämän järjestelmän käyttöönottoa yhden tietojoukon käyttöönotto kesti kuukauden. Uuden arkkitehtuurimme ansiosta pystyimme ottamaan käyttöön 1 uutta tietojoukkoa alle kahdessa kuukaudessa, mikä paransi ketteryyttämme 15 %.
- Se poisti skaalauksen pullonkaulat ja loi homogeenisen järjestelmän, joka voi skaalata nopeasti tuhansiin ajoihin.
- Ratkaisu lisäsi skeeman ja tietojen laadun tarkistuksen ennen syötteiden hyväksymistä ja hylkäämistä, jos tietojen laaturikkomuksia havaitaan.
- Se helpotti tietojoukkojen noutamista samalla kun se tukee tulevia simulaatioita ja takatestauslaitteiden käyttötapauksia, jotka vaativat versioituja syötteitä. Tämä tekee mallien käynnistämisestä ja testaamisesta yksinkertaisempaa.
- Ratkaisu loi yhteisen infrastruktuurin, joka voidaan helposti laajentaa muihin DIAL-tiimeihin, joilla on samanlaisia ongelmia tietojen käsittelyn, tallennuksen ja haun käyttötapauksissa.
- Toimintakulumme ovat laskeneet lähes 90 %.
- Tietojen tutkijat ja insinöörit voivat käyttää tätä datajärveä tehokkaasti tehdäkseen muita analyyttisia menetelmiä ja käyttääkseen ennakoivaa lähestymistapaa tulevaisuuden mahdollisuutena luoda tarkkoja suunnitelmia ostotilauksille.
Tämän viestin vaiheet voivat auttaa sinua suunnittelemaan samanlaisen nykyaikaisen tietostrategian käyttämällä AWS-hallittuja palveluja tietojen keräämiseen eri lähteistä, luomaan automaattisesti metatietoluetteloita, jakamaan tietoja saumattomasti datajärven ja tietovaraston välillä ja luomaan hälytyksiä tapahtumassa. koordinoidun tiedon työnkulun epäonnistumisesta.
Tietoja kirjoittajista
 Avinash Kolluri on AWS:n vanhempi ratkaisuarkkitehti. Hän työskentelee Amazon Alexassa ja Devicesissa nykyaikaisten hajautettujen ratkaisujen arkkitehtuurissa ja suunnittelussa. Hänen intohimonsa on rakentaa kustannustehokkaita ja erittäin skaalautuvia ratkaisuja AWS:lle. Vapaa-ajallaan hän nauttii fuusioreseptien laittamisesta ja matkustamisesta.
Avinash Kolluri on AWS:n vanhempi ratkaisuarkkitehti. Hän työskentelee Amazon Alexassa ja Devicesissa nykyaikaisten hajautettujen ratkaisujen arkkitehtuurissa ja suunnittelussa. Hänen intohimonsa on rakentaa kustannustehokkaita ja erittäin skaalautuvia ratkaisuja AWS:lle. Vapaa-ajallaan hän nauttii fuusioreseptien laittamisesta ja matkustamisesta.
 Vipul Verma on vanhempi ohjelmistoinsinööri osoitteessa Amazon.com. Hän on työskennellyt Amazonilla vuodesta 2015 lähtien ja ratkaissut todellisia haasteita tekniikan avulla, joka vaikuttaa suoraan Amazonin asiakkaiden elämään ja parantaa niitä. Vapaa-ajallaan hän harrastaa patikointia.
Vipul Verma on vanhempi ohjelmistoinsinööri osoitteessa Amazon.com. Hän on työskennellyt Amazonilla vuodesta 2015 lähtien ja ratkaissut todellisia haasteita tekniikan avulla, joka vaikuttaa suoraan Amazonin asiakkaiden elämään ja parantaa niitä. Vapaa-ajallaan hän harrastaa patikointia.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- Platoblockchain. Web3 Metaverse Intelligence. Tietoa laajennettu. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/big-data/how-amazon-devices-scaled-and-optimized-real-time-demand-and-supply-forecasts-using-serverless-analytics/
- 1
- 10
- 100
- 2021
- 70
- a
- kyky
- pystyy
- pääsy
- Accessed
- saavutettavuus
- valtuutettu
- tarkka
- poikki
- Toiminta
- lisä-
- lisä-
- AI
- Alexa
- Kaikki
- mahdollistaa
- jo
- Amazon
- amazon alexa
- Amazon EC2
- Amazonin EMR
- Amazon.com
- analyysi
- Analytics
- analysoida
- analysointi
- ja
- Toinen
- api
- API
- Hakemus
- Application Development
- lähestymistapa
- sopiva
- arkkitehtuurin
- arkkitehtuuri
- alueet
- kirjoittaminen
- automaattisesti
- AWS
- AWS-liima
- takaisin
- perustua
- koska
- ennen
- Paremmin
- välillä
- miljardeja
- rakentaa
- rakennettu
- liiketoiminta
- nimeltään
- Koko
- tapauksissa
- luettelo
- luettelot
- keskitetty
- ketju
- haasteet
- haastava
- Muutokset
- valinta
- valitsi
- asiakas
- asiakkaat
- pilvi
- KOM
- yhdistelmä
- Yhteinen
- verrata
- komponentti
- Laskea
- kytkeä
- liitäntä
- harkittu
- ottaen huomioon
- kuluttaa
- Kuluttajat
- jatkuvasti
- ruoanlaitto
- Ydin
- Hinta
- kustannustehokas
- kustannukset
- voisi
- Covidien
- tela
- luoda
- luotu
- Luominen
- kriittinen
- Nykyinen
- asiakassuhde
- asiakas
- Asiakaspalvelu
- Asiakkaat
- jaksoa
- tiedot
- datan integraatio
- Datajärvi
- tietojenkäsittely
- tiedon laatu
- tietostrategia
- tietovarasto
- data-driven
- aineistot
- Päivämäärä
- päivä
- tekemisissä
- päätös
- päätökset
- Aste
- Kysyntä
- vaatii
- Riippuen
- Malli
- suunniteltu
- yksityiskohta
- yksityiskohdat
- määritetty
- kehitetty
- Kehittäjä
- kehittäjille
- Kehitys
- Laitteet
- eri
- suoraan
- löytää
- löysi
- löytö
- jaettu
- useat
- ei
- kaksoiskappaleet
- kukin
- helposti
- tehokkaasti
- tehokkaasti
- myöskään
- käytössä
- mahdollistaa
- insinööri
- Engineers
- rikastettu
- kokonaisuus
- Eetteri (ETH)
- tapahtuma
- Joka
- uute
- poimia tiedot
- tekijät
- Epäonnistuminen
- Fallen
- Ominaisuudet
- harvat
- filee
- virtaus
- jälkeen
- seuraa
- Ennuste
- muoto
- muoto
- löytyi
- alkaen
- koko
- edelleen
- Lisäksi
- fuusio
- tulevaisuutta
- voitto
- tuottaa
- tuottaa
- sukupolvi
- saada
- saada
- Global
- globaalin liiketoiminnan
- maapallo
- tavoite
- Kasvu
- ottaa
- auttaa
- auttanut
- tätä
- Korkea
- korkea suorituskyky
- erittäin
- retkeily
- Miten
- HTML
- HTTPS
- IAM
- ihanteellinen
- tunnistettu
- tunnistaa
- Identiteetti
- Välitön
- heti
- Vaikutus
- täytäntöönpano
- täytäntöönpanosta
- parantaa
- parani
- parannus
- parannuksia
- in
- sisältää
- sisältää
- lisää
- indeksi
- tiedot
- Infrastruktuuri
- panos
- sen sijaan
- yhdistää
- integraatio
- vuorovaikutteinen
- vuorovaikutuksessa
- sisäinen
- Esittelee
- inventaario
- investointi
- kysymys
- kysymykset
- IT
- Job
- Työpaikat
- yhdistää
- json
- avain
- Lack
- järvi
- lasku
- uusin
- käynnistäminen
- oppiminen
- Perintö
- Kirjasto
- elämä
- rajat
- linja
- LINK
- kuormitus
- sijainti
- logistiikka
- katso
- kone
- koneoppiminen
- tehty
- ylläpitää
- huolto
- tehdä
- TEE
- hoitaa
- toimitusjohtaja
- Marketing
- Tavata
- Metadata
- menetelmä
- Metrics
- minimi
- ML
- malli
- mallit
- Moderni
- muokattu
- Moduulit
- monitori
- Kuukausi
- kk
- lisää
- eniten
- liikkua
- liikkuvat
- moninkertainen
- nimi
- luonto
- Tarve
- tarvitaan
- Uusi
- ilmoitukset
- Laivalla
- perehdytyksessä
- ONE
- toiminta
- toiminta-
- Mahdollisuudet
- Tilaisuus
- optimaalinen
- optimointi
- Optimoida
- optimoitu
- Vaihtoehdot
- määräys
- Muut
- pandeeminen
- osa
- intohimo
- polku
- Maksaa
- osuus
- suorittaa
- suorituskyky
- näkökulma
- Paikka
- suunnitelma
- suunnitelmat
- Platon
- Platonin tietotieto
- PlatonData
- mahdollinen
- Kirje
- Valmistella
- pääasiallisesti
- ensisijainen
- ongelmia
- prosessi
- käsittely
- Suoritin
- tuottajat
- tuottava
- tuottavuus
- projekti
- toimittaa
- tarjoaa
- osto
- Työnnä
- laatu
- kysymykset
- nopeasti
- hinta
- raaka
- raakadata
- tavoittaa
- todellinen maailma
- reaaliaikainen
- syistä
- reseptit
- vähentämällä
- viittaa
- huomattava
- poistettu
- tarvitaan
- vaatimus
- vaatimukset
- resurssi
- vastaus
- vastuut
- vastuu
- herkkä
- REST
- johtua
- Rooli
- roolit
- ajaa
- juoksu
- myynti
- sama
- tallentaa
- skaalautuvuus
- skaalautuva
- Asteikko
- skaalaus
- skannata
- suunniteltu
- tutkijat
- saumattomasti
- Haku
- osiot
- vanhempi
- serverless
- palvelu
- Palvelut
- Jaa:
- yhteinen
- Lähetys
- Näytä
- merkittävä
- samankaltainen
- Yksinkertainen
- koska
- single
- Kuva
- So
- Tuotteemme
- Software Engineer
- ratkaisu
- Ratkaisumme
- SOLVE
- Solving
- jotain
- lähde
- Lähteet
- jännevälien
- spektri
- käytetty
- SQL
- Pysyvyys
- sidosryhmien
- sidosryhmien
- standardi
- Alkaa
- alkoi
- Aloita
- alkaa
- Tila
- Vaihe
- Askeleet
- Levytila
- verkkokaupasta
- tallennettu
- varastot
- strategiat
- Strategia
- onnistunut
- niin
- toimittaa
- toimitusketju
- Tukea
- Tukee
- järjestelmä
- taulukko
- ottaa
- vie
- tiimit
- Elektroniikka
- sapluuna
- Testaus
- -
- Lähde
- heidän
- siksi
- tuhansia
- Kautta
- kauttaaltaan
- aika
- kertaa
- aikaleima
- vinkit
- että
- ylin
- Liiketoimet
- Muuttaa
- Matkustaminen
- laukaista
- tyypit
- yhdistynyt
- Päivitykset
- us
- käyttää
- Käyttäjät
- validointi
- arvo
- arvot
- lajike
- eri
- Nopeus
- versio
- kautta
- Näytä
- rikkomukset
- haihtuva
- volyymit
- halusi
- Varasto
- tavalla
- Mitä
- joka
- vaikka
- leveä
- tulee
- työnkulku
- työnkulkuja
- toimii
- olisi
- vuosi
- Sinun
- zephyrnet