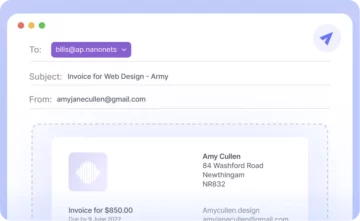
Tässä artikkelissa kerrotaan erilaisista menetelmistä PDF-tiedoston muuntamiseksi Google-taulukoiksi.
Opit myös, miten nanonetit voivat automatisoida koko työnkulku PDF-tiedostojen muuntamiseksi Google Sheetsiksi verkossa.
Ennen kuin tarkastelemme PDF-tiedoston muuntamista Google Sheetsiksi, katsotaanpa, miksi tämä on tärkeää.
Miksi PDF-tiedostot muunnetaan Google Sheetsiksi?
Tämän Google-blogi virallisella Google-blogisivulla, yli 5 miljoonaa yritystä käyttää heidän G Suite -ratkaisuaan. Samaan aikaan monet yritykset ovat myös alkaneet käyttää Google Sheets -integraatioita tehtävien automatisointiin.
Tarkastellaanpa tyypillistä käyttötapausta. Ostoreskontratiimisi saa laskun tavallisessa PDF-muodossa. Joku käy manuaalisesti läpi laskun ja näppäilee tarvittavat tiedot Google Sheets -asiakirjaksi ennen kuin lähettää sen edelleen Talous-osioon. Talousosasto maksaa toimittajallesi ja tekee merkinnän yrityksen pääkirjaan.
Sen lisäksi, että prosessi on pitkä, se on altis virheille, ja olisi paljon järkevämpää yksinkertaisesti automatisoida se.
Nyt kun PDF-tiedostojen muuntaminen Google-taulukkolomakkeeksi on selvä, katsotaanpa PDF-dokumenttien rakennetta ja haasteita niiden jäsentämisessä.
Haluatko muuntaa PDF tiedostoja Google-arkkia ? Tarkista Nanonetsit Ilmainen PDF-CSV-muunnin. Tai ota selvää miten automatisoi koko PDF Google Sheets -työnkulku Nanonetsilla.
PDF-dokumentin jäsentämisen haasteet
Kannettava asiakirjamuoto oli Adoben alun perin kehittämä tiedostomuoto, joka julkaistiin myöhemmin avoimena standardina. Se on sittemmin otettu laajalti käyttöön, koska se on agnostinen taustalla olevan käyttöjärjestelmän suhteen.
Joten miksi PDF-tiedoston jäsentäminen ja sen sisällön muuntaminen toiseen muotoon on niin haastavaa? Seuraavat kuvat puhuvat enemmän kuin tuhat sanaa ja vievät asian kotiin.
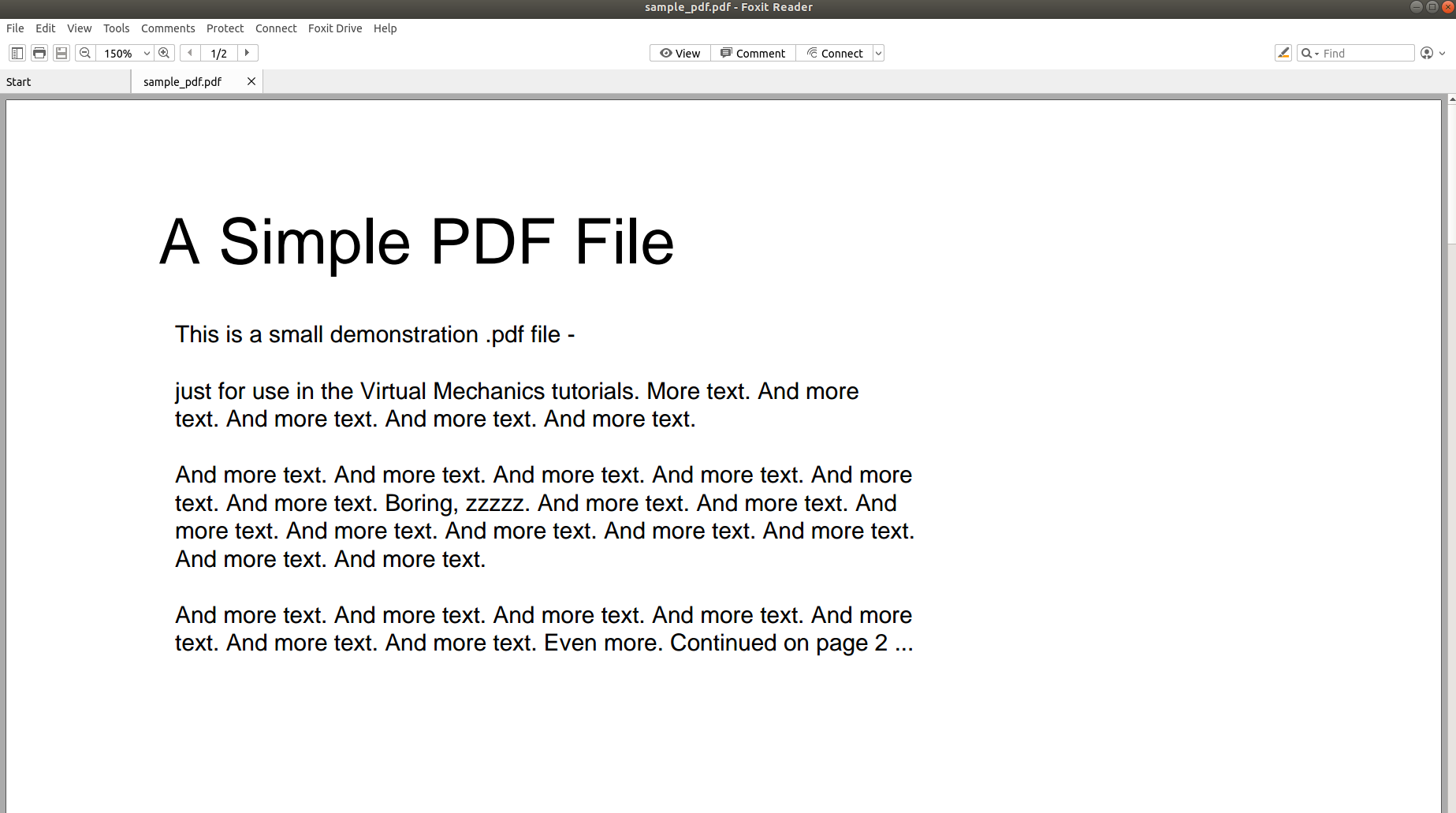
Yllä oleva kuva näyttää kuvakaappauksen PDF-dokumentista, joka avataan PDF-lukijalla. Yritetään avata sama PDF-dokumentti tekstieditorilla.
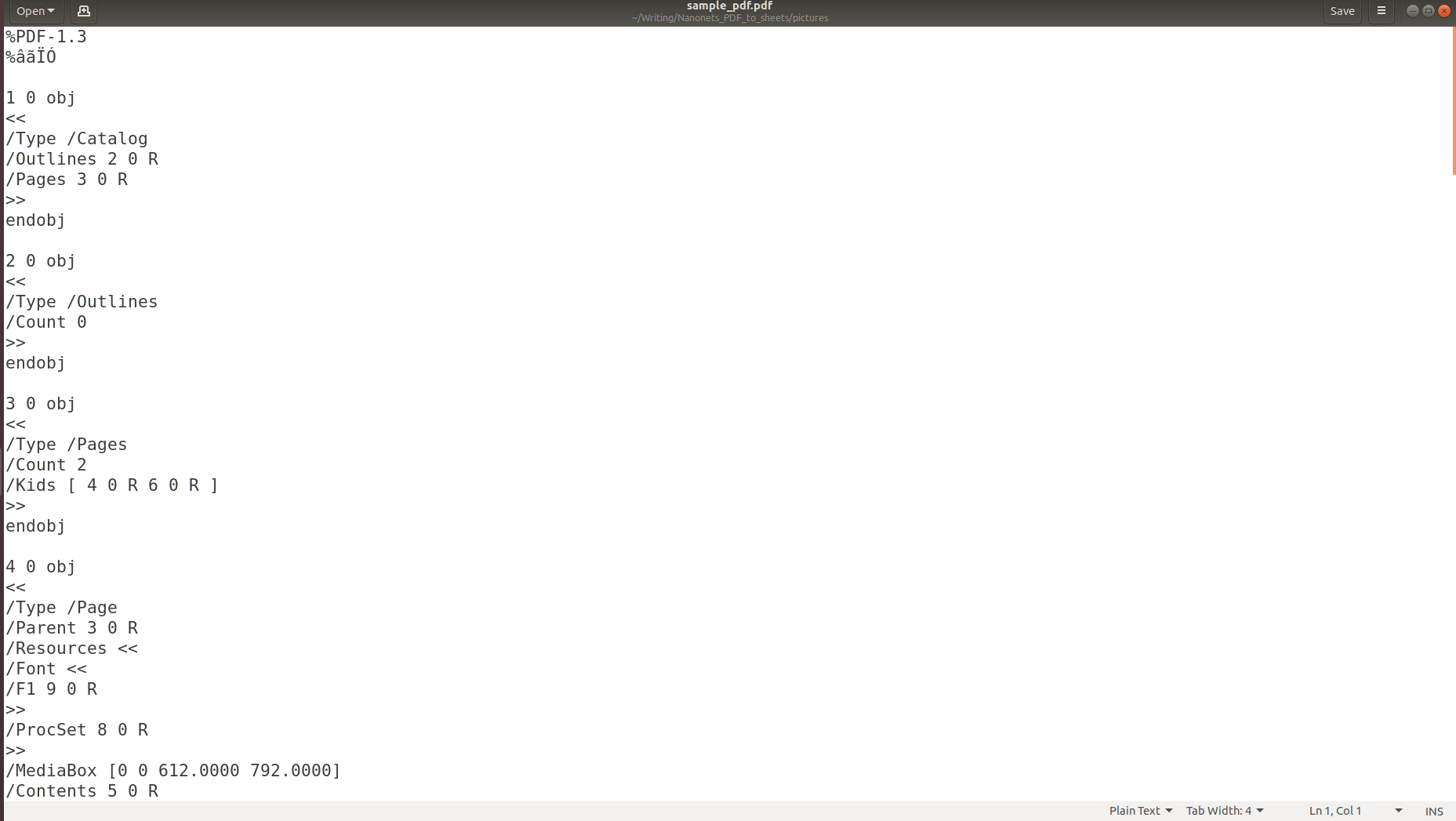
Yllä olevista kuvista käy selväksi, että kun tiedot tallennetaan PDF-tiedostoon, sen alkuperäinen rakenne katoaa kokonaan. Tämä johtuu siitä, että PDF-muoto koostuu yksinkertaisesti ohjeista kuinka tulostaa/piirtää merkkisarja sivulle.
Jos luulet, että tekstin purkaminen on vaikeaa, taulukoissa olevien tietojen purkaminen on vieläkin haastavampaa käytettyjen laajasti vaihtelevien taulukkomuotojen vuoksi.
Toivottavasti olet vakuuttunut siitä, että PDF-dokumentin muuntaminen Google Sheets -lomakkeeksi ei ole kävelyä puistossa. Seuraavassa osiossa käsitellään useimpien nykyaikaisten PDF-jäsentäjien lähestymistapaa tunnistaa/jäsentää tietoja PDF-dokumentista.
Moderni lähestymistapa PDF-dokumenttien jäsentämiseen
Useimmat nykyaikaiset PDF-jäsentimet käyttävät alla kuvattua kulkua jäsentääkseen PDF-dokumenttien jäsentämättömiä tietoja.
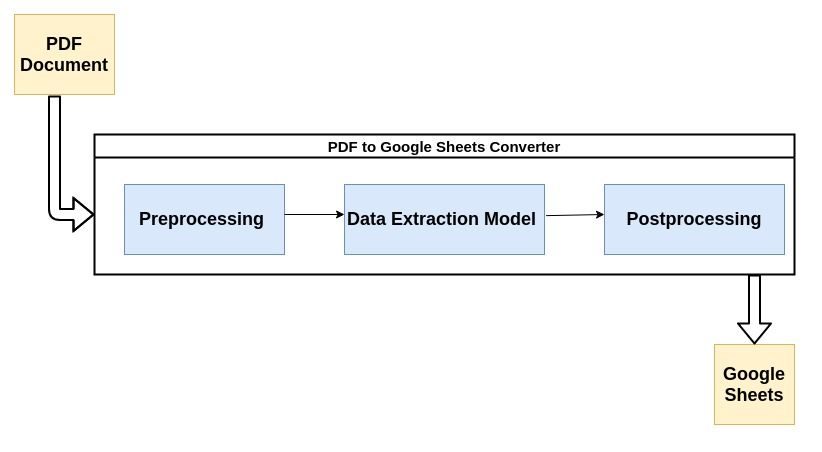
Katsotaanpa lyhyesti prosessin jokaista vaihetta:
1. Esikäsittely tai tietojen puhdistaminen:
Mitä paremmalta PDF näyttää, sitä helpompi koneoppimismallisi on purkaa tai kaappaa tietoja siitä. Jos esimerkiksi PDF-dokumentti on skannattu, se sisältää varmasti joitain skannausvirheitä, jotka voivat vaikuttaa muuntimen suorituskykyyn.
Melunpoisto käyttämällä sopivia suodattimia, binarisointi, vinouden korjaus jne. ovat joitain yleisimmistä esikäsittelyvaiheista. Seuraava Nanonets-postaus Nanonets Tesseract Post sisältää hienoja esimerkkejä siitä, kuinka asiakirjoja voidaan esikäsitellä ennen Optinen luku(OCR) ajetaan niillä.
Tässä suurin osa taikuudesta tapahtuu. Tietojen poiminta suoritetaan yleensä koneoppimismallilla (ML). Useimmat ML-mallit, joita käytetään tietojen poimimiseen PDF-tiedostoista, sisältävät yhdistelmän optisia merkintunnistustyökaluja, tekstin ja kuvion tunnistustyökaluja jne.
Tätä viestiä varten voimme käsitellä mallia mustana laatikkona, joka ottaa PDF-dokumenttisi syötteenä ja sylkee jäsennetyt tiedot. Lisäksi, koska sen ytimessä on ML, se voidaan kouluttaa uudelleen mukautetuilla tiedoilla yrityksesi käyttötapaukseen sopiviksi.
3. Jälkikäsittely:
Tässä vaiheessa poimitut tiedot muunnetaan vaadittuun muotoon, kuten CSV, XML, JSON jne. Tekoälyn tekemien ennusteiden päälle lisätään myös käyttäjän määrittelemiä lisäsääntöjä. Tämä voi sisältää sääntöjä tulosteen muotoilulle, lisärajoituksia poimiville tiedoille jne.
Seuraavassa osiossa tarkastellaan joitain mittareita, joita voimme käyttää PDF-jäsentimen suorituskyvyn mittaamiseen.
Haluatko muuntaa PDF tiedostoja Google-arkkia ? Tarkista Nanonetsit Ilmainen PDF-CSV-muunnin. Opi automatisoimaan koko PDF-tiedostosi Google Sheetsiin Nanonetsin avulla.

Mittarit PDF-muuntimen suorituskyvyn mittaamiseen
Koska useimpia PDF-muuntimia käytetään laskujen käsittelyyn tai niihin liittyviin tehtäviin, PDF-dokumentista taulukon poiminnan tarkkuus ja nopeus on kriittinen tekijä arvioitaessa PDF-muuntimen suorituskykyä.
2. Monikielinen ominaisuus:
Useimmat suuret yritykset saavat laskut useilla eri kielillä. PDF-jäsentimen tulee joko tukea monikielistä jäsentämistä heti valmiiksi tai sen tulee tarjota vaihtoehto, jonka avulla käyttäjät voivat kouluttaa mallia mukautettujen tietojen avulla.
3. Integrointi kirjanpitoohjelmistoon:
Ihanteellisen PDF-muuntimen tulisi olla plug and play -moduuli, joka voidaan helposti lisätä olemassa olevaan asiakirjan työnkulku. Sen pitäisi tukea integrointia suosittuihin kirjanpitoohjelmistoihin, kuten QuickBooks, Xero, Wave jne.
4. Helppo ja intuitiivinen:
Työkalua käyttävät todennäköisesti muut kuin tekniset käyttäjät. Olisi edullista, jos sitä voidaan käyttää minimaalisella teknisellä tiedolla.
Erilaisia menetelmiä PDF-tiedostojen muuntamiseen Google Sheetsiksi
1. Google-dokumenttien käyttäminen PDF-tiedostojen muuntamiseen Google Sheetsiksi
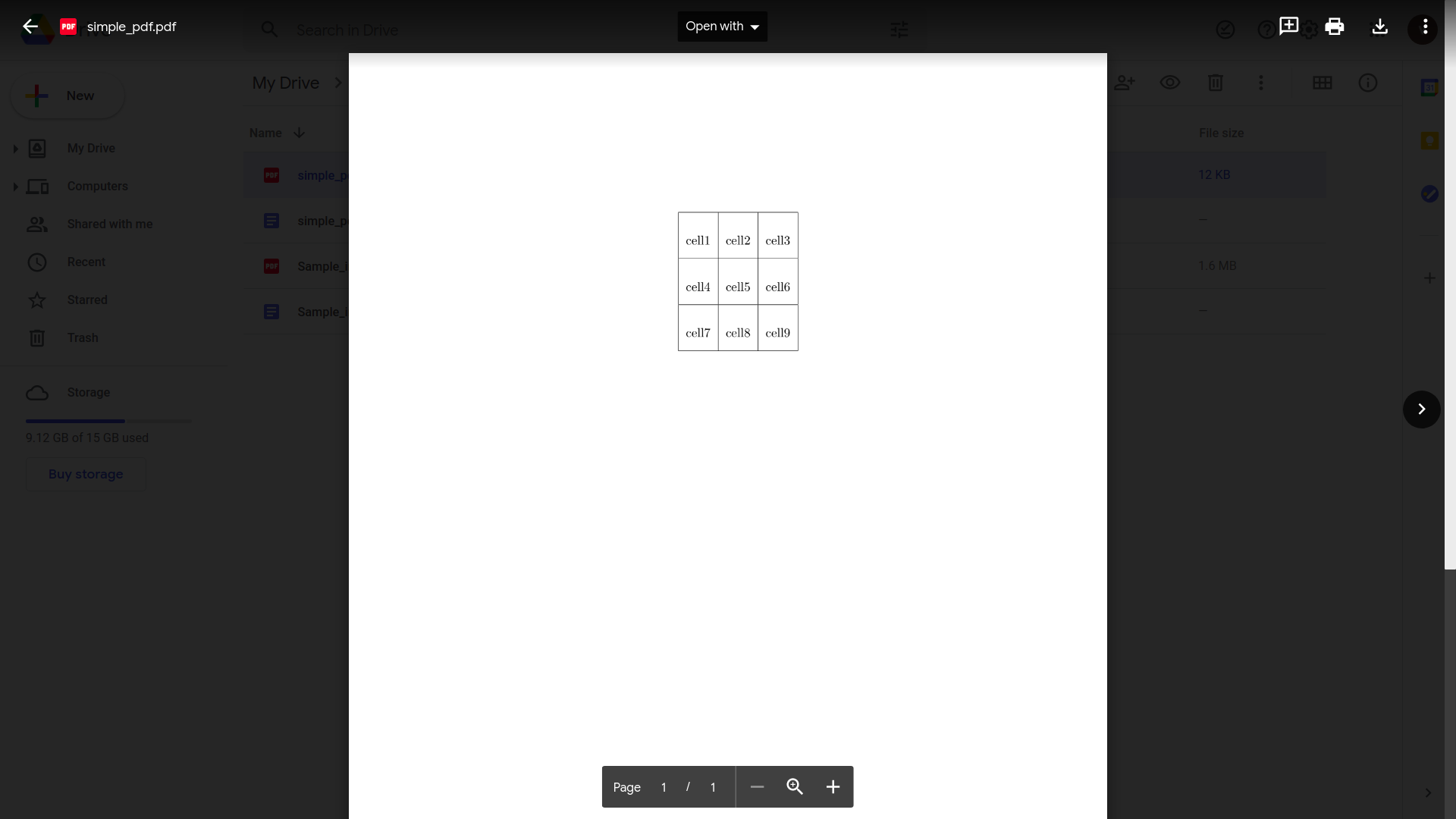
Google Drivessa on sisäänrakennettu kyky tunnistaa taulukoita ja tekstiä yksinkertaisissa PDF-dokumenteissa. Sinun tarvitsee vain:
-
Lataa PDF-tiedostosi Google Driveen
-
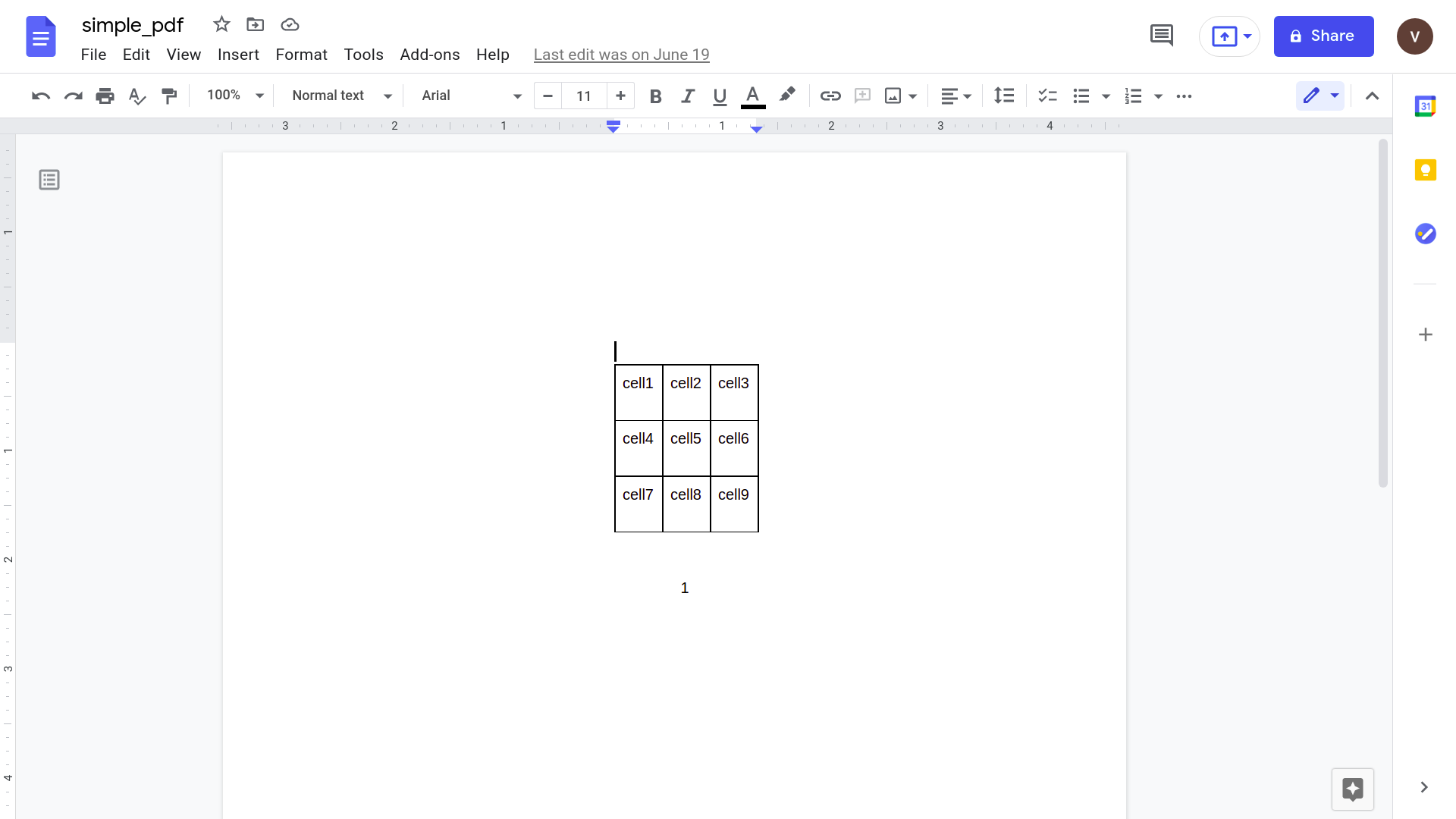
Napsauta "Avaa Google Docsilla"
-
Kopioi haluamasi tiedot ja liitä ne Google Sheetsiin
Vaikka se näyttää toimivan hyvin, kokeillaan jotain hieman käytännöllisempää. Harkitse tätä yksinkertaista laskua.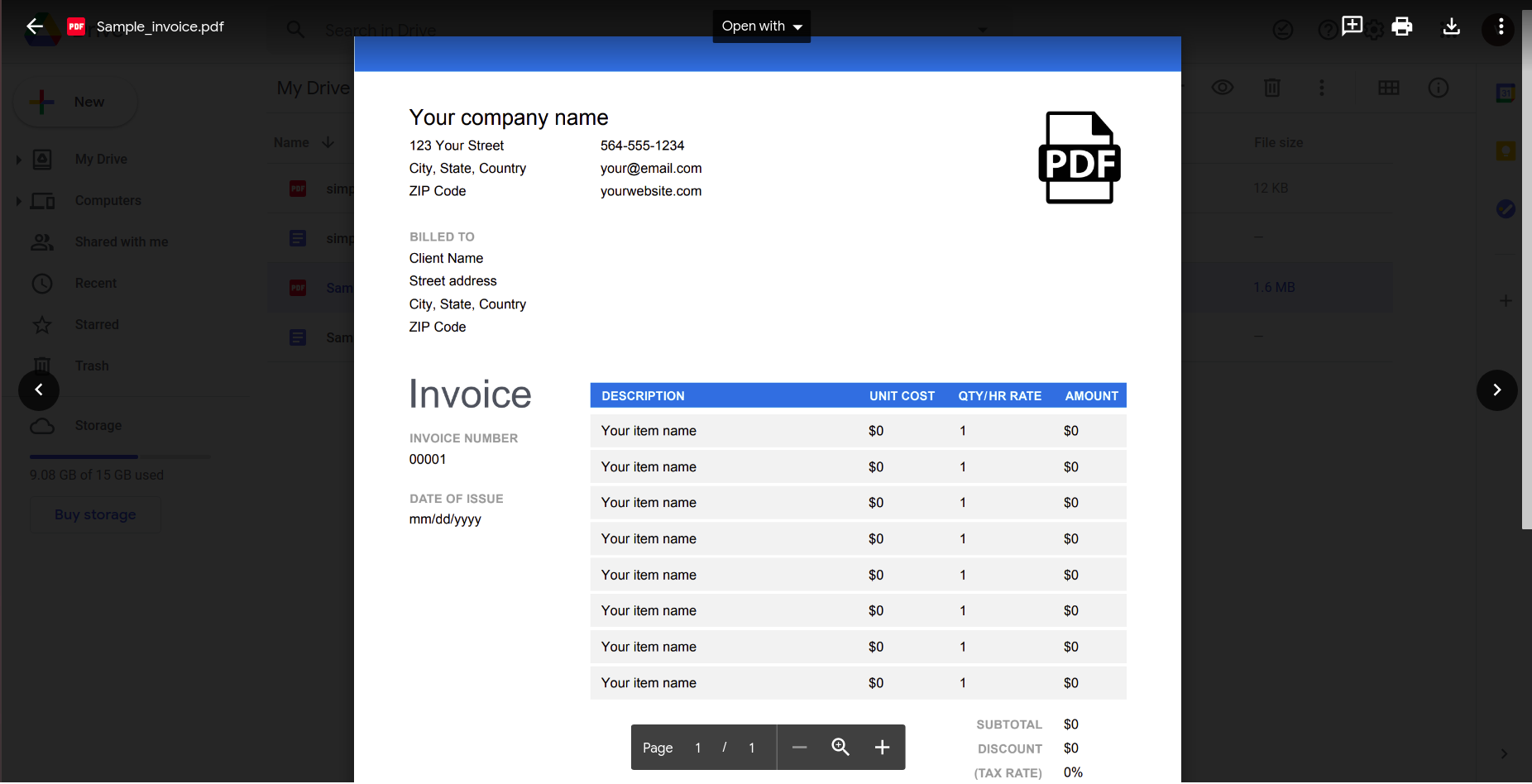
Tämän avaaminen Google docs -sovelluksella antaa seuraavan tuloksen.
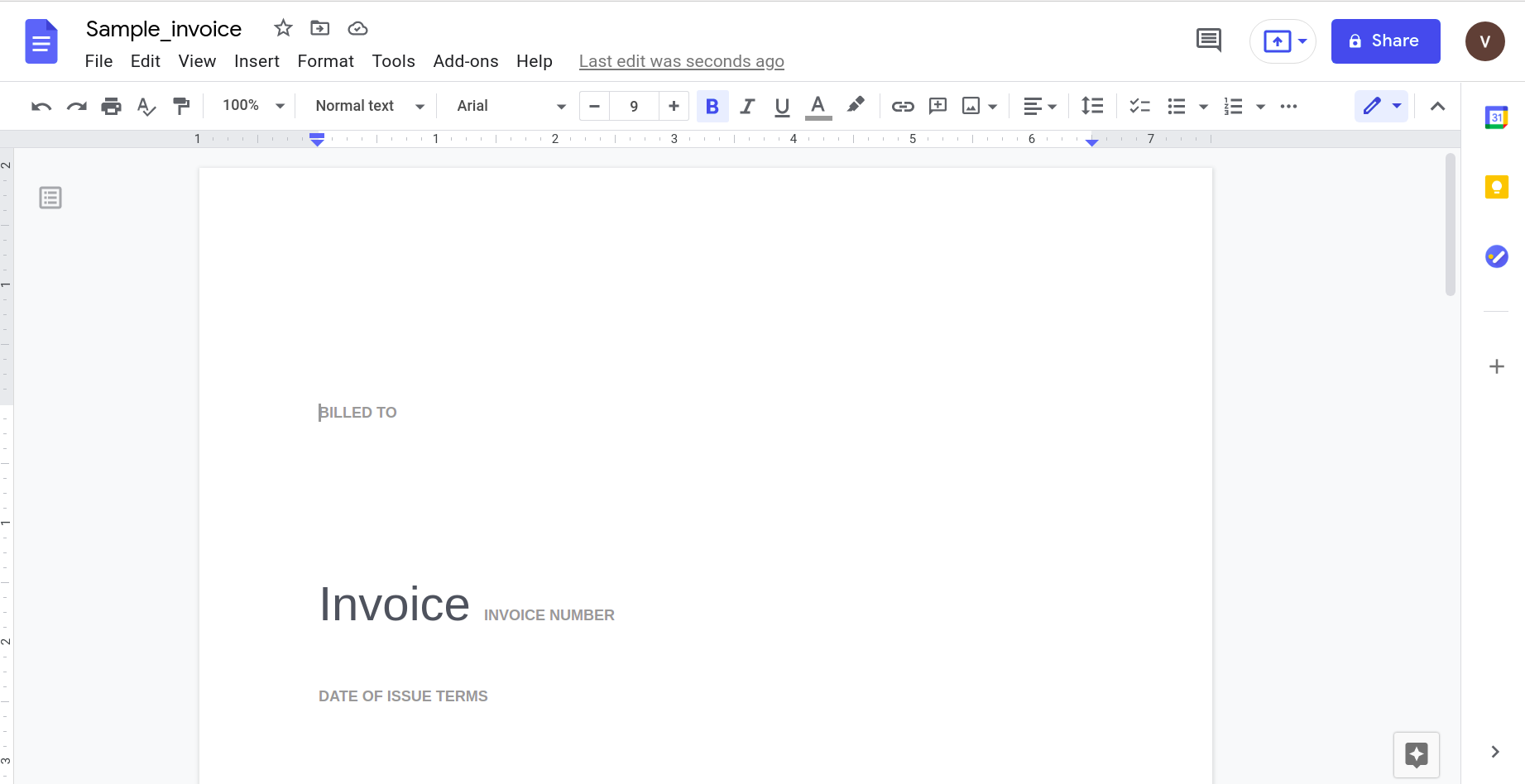
On selvää, että kun asiakirjan monimutkaisuus lisääntyy, meidän on turvauduttava kehittyneempiin työkaluihin tietojen tunnistamisessa.
2. Online-työkalujen käyttäminen:
Useat online-työkalut, kuten PDF-taulukoiden purku, Online2PDF jne., integroituvat suoraan Google Driveen ja tarjoavat valmiin mahdollisuuden muuntaa PDF-dokumentteja Google-taulukoiksi.
Kuitenkin, kun näitä työkaluja testattiin käyttämällä yllä näkyvää esimerkkilaskun PDF-tiedostoa, taulukoita ei useimmissa tapauksissa havaittu.
Haluatko muuntaa PDF tiedostoja Google-arkkia ? Tarkista Nanonetsit Ilmainen PDF-CSV-muunnin. Opi automatisoimaan koko PDF Google Sheets -työnkulku Nanonetsilla alla olevan kuvan mukaisesti.
PDF-tiedostojen Google Sheets -muunnosprosessin automatisointi
Voimme täysin automatisoida PDF-tiedoston jäsentämisen ja tietojen purkamisen Google Sheets -lomakkeelle käyttämällä seuraavia työkaluja.
1. Webhooksin käyttäminen:
Webhookit ovat mukautettuja HTTP-pyyntöjä. Ne laukeavat yleensä tapahtumasta eli tapahtuman sattuessa sovellus lähettää tiedot ennalta määritettyyn URL-osoitteeseen.
Kuinka voit käyttää tätä työnkulkusi automatisointiin? Tarkastellaan tyypillistä laskujen käsittelyn käyttötapausta. Saat toimittajiltasi useita laskuja ja syötät ne PDF-tiedostoon Google Sheets -muuntimeesi, joka sijaitsee pilvessä. Mistä tiedät, kun malli on käsitellyt asiakirjat?
Sen sijaan, että tarkistaisit manuaalisesti, onko muunnos suoritettu loppuun, voit yksinkertaisesti käyttää webhookia, joka ilmoittaa sinulle, kun PDF-tiedoston tiedot on purettu Google Sheets -asiakirjaan.
2. API:iden käyttö
API tulee sanoista Application Programming Interface. Asianmukaisia API-kutsuja käyttämällä PDF-dokumenttien muuntaminen Google Sheetsiksi saattaa olla yhtä helppoa kuin seuraavien koodirivien kirjoittaminen:
#Feed the PDF documents into the PDF to Google sheets converter
Success_code, unique_id = NanonetsAPI.uploaddata(PDF_documents)
Jos yrityksesi on jo määrittänyt integroinnin Webhooksin kanssa, saat ilmoituksen, kun PDF-asiakirjasi on muunnettu onnistuneesti. Voit sitten ladata Google Sheets -lomakkeen alla olevan sovellusliittymän avulla.
#Download Google Sheets forms
Google_sheets_data = NanonetsAPI.downloaddata(unqiue_id)
PDF Google Sheetsiin nanonettien avulla
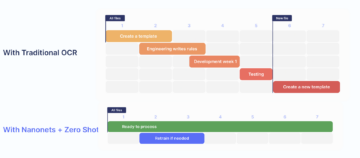
Nanonets PDF -jäsennin tekee jäsentämisestä ja muuntamisesta helppoa ja tarkkaa. PDF-jäsennintä käytettiin mallilaskun jäsentämiseen. Tämä osa osoittaa työkalun helppokäyttöisyyden ja tarkkuuden. Sen sijaan, että puhuisit siitä, kuinka hieno se on, seuraavat kuvat havainnollistavat asiaa osuvasti.
Alla oleva kuva on kuvakaappaus mallilaskusta, joka syötettiin Nanonetsin PDF-jäsentäjään.
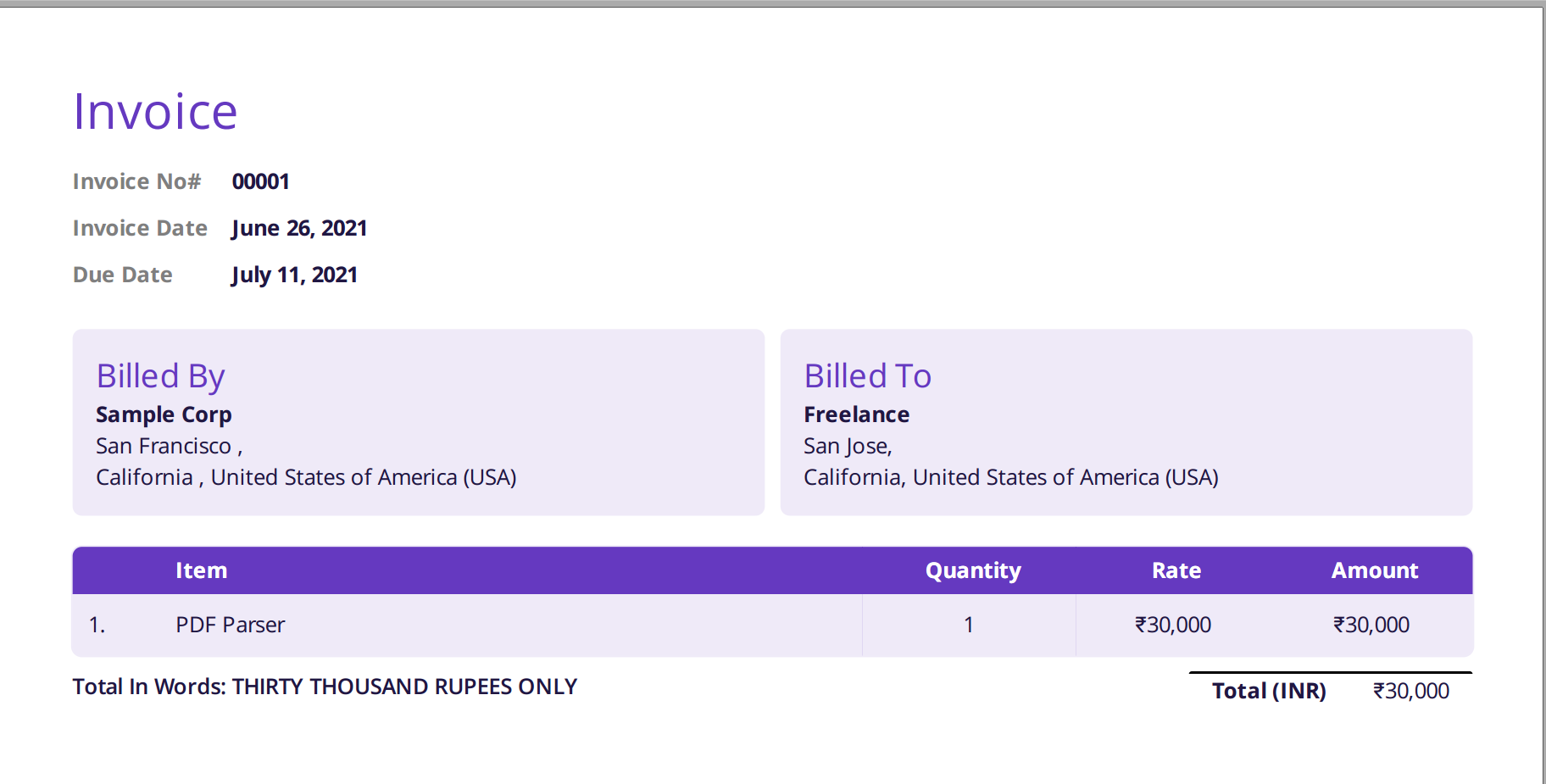
Siirry vain Nanonetsin verkkosivustolle ja lataa lasku. Muuntaminen kestää vain muutaman sekunnin, minkä jälkeen jäsennetyt tiedot voidaan ladata useissa eri muodoissa, kuten CSV, XLSX jne. (katso Nanonets' PDF-CSV-muunnin)
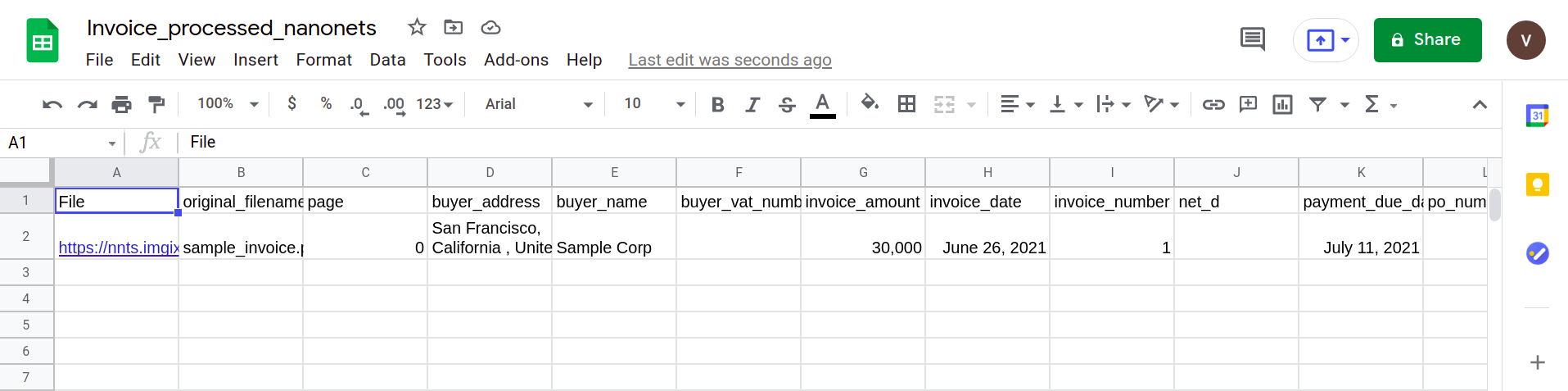
Seuraava kuva näyttää kuvakaappauksen CSV-tiedostosta, joka sisältää jäsennetyt tiedot PDF-dokumentista.

Lopuksi, jos haluat muuntaa CSV-tiedoston Google Shes -lomakkeeksi, sinun tarvitsee vain ladata XLSX/CSV-tiedosto Google Driveen. Tämä vaihe voidaan automatisoida käyttämällä Google Drive -sovellusliittymiä.
Seuraavassa osiossa näytetään, kuinka yksinkertainen liukuhihna voidaan luoda käyttämällä Nanonets PDF-jäsennintä.
Haluatko poimia tietoja PDF-dokumenteista ja muuntaa/lisätä ne Google Sheets -asiakirjaksi? Tutustu Nanonetsiin™ automatisoida minkä tahansa tiedon vienti mistä tahansa PDF-dokumentista Google Sheetsiin!
Yksinkertaisen putkilinjan luominen
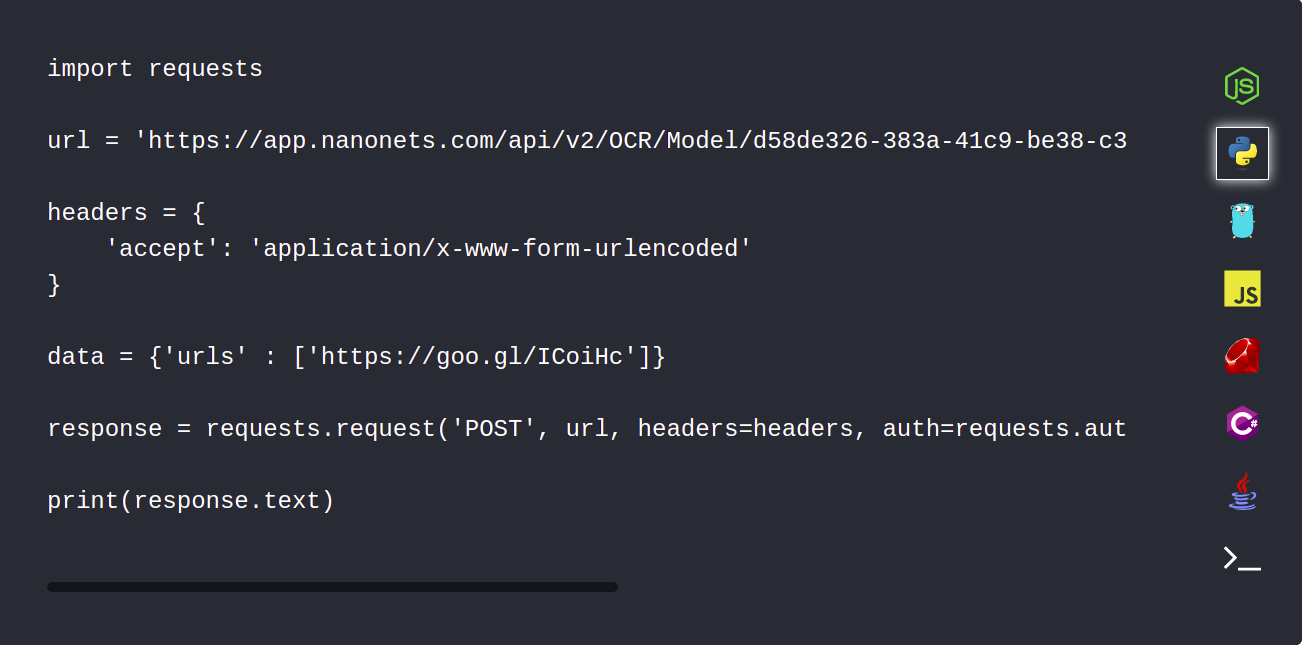
1. Lataa PDF-asiakirjasi automaattisesti Nanonets API:n avulla
Nanonets-sovellusliittymän avulla voit ladata automaattisesti tiedostot, jotka täytyy jäsentää. Seuraava koodinpätkä näyttää, kuinka tämä voidaan tehdä pythonilla.
2. Käytä webhooks-integraatiota saadaksesi ilmoituksen jäsentämisen valmistumisesta
Webhookit voidaan määrittää ilmoittamaan automaattisesti, kun asiakirjat on jäsennetty.
3. Tarkista ja lataa Google Sheetsiin
Lataa ja tarkista CSV-tiedostot varmistaaksesi, että kaikki on kunnossa, ja lataa tiedot Google Sheetsiin Google Drive -sovellusliittymän avulla.
Nanonets Edge
Tässä on joitain Nanonets PDF Parserin ominaisuuksia, jotka tekevät siitä ihanteellisen työkalun yrityksellesi.
1. Ulkoiset integraatiot:
Nanonets-malli voidaan helposti integroida MySql:iin, Quickbookeihin, Salesforceen jne. Tämä tarkoittaa, että nykyinen työnkulkusi pysyy häiriöttömänä ja nanonets-muunnin voidaan yksinkertaisesti kytkeä lisämoduuliksi.
2. Suuri tarkkuus ja lyhyet käsittelyajat:
Nanonetsin PDF-jäsennystyökalun tarkkuus on yli 95 %, mikä on paljon parempi verrattuna sen kilpailijoihin.
3. Hienot jälkikäsittelyominaisuudet:
Oletetaan, että tietokanta on integroitu nanoverkkomalliin. Malli täyttää automaattisesti jotkin kentät (tietokannan tiedoilla) dokumentista poimittujen tietojen perusteella. Esimerkiksi:
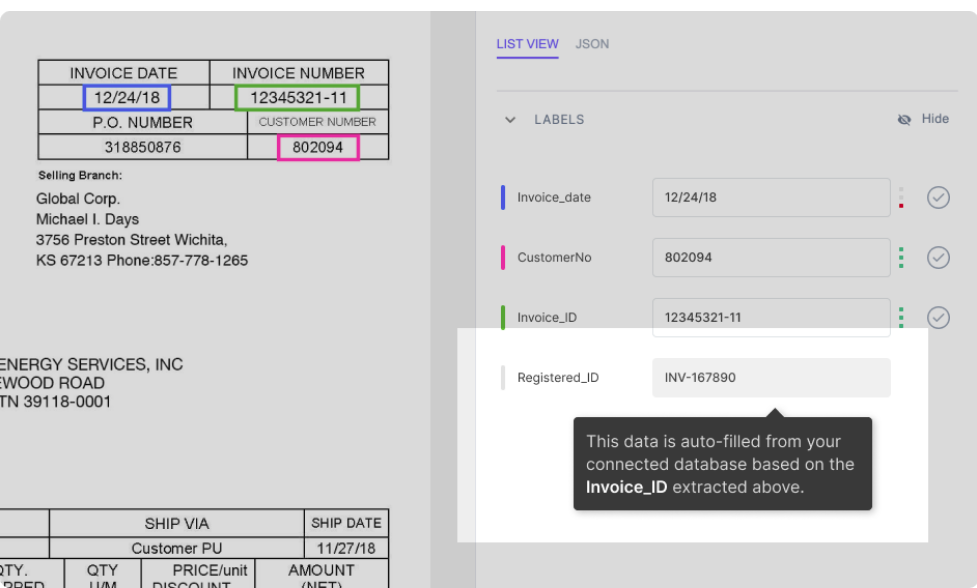
Kuten kuvasta näkyy, Rekisteröity_ID-kenttä täytetään automaattisesti (tietokannan haulla) PDF-tiedostosta poimitun laskun_tunnuksen perusteella.
4. Yksinkertainen ja intuitiivinen käyttöliittymä
Vaikka tämä ominaisuus on aliarvioitu, huomasin käyttöliittymän ja UX:n olevan kohdallaan. Koko rekisteröityminen, asiakirjan lataaminen ja tietojen jäsentäminen kesti alle 5 minuuttia. Se on melkein sama kuin aika, joka kannettavan tietokoneeni käynnistyy!
5. Valtava asiakaskunta
Jos sinulla on edelleen varauksia käyttää Nanonetsia työnkulkusi automatisointiin, katso vain joitain yrityksiä, jotka käyttävät heidän palveluitaan.
- Deloitte
- Sherwin Williams
- DoorDash
- P&G
Haluatko poimia tietoja PDF-dokumenteista ja muuntaa/lisätä ne Google Sheets -asiakirjaksi? Tutustu Nanonetsiin™ automatisoida minkä tahansa tiedon vienti mistä tahansa PDF-dokumentista Google Sheetsiin!
Yhteenveto
Tässä viestissä tarkastelimme, kuinka voit automatisoida työnkulkusi käyttämällä PDF-tiedostosta Google Sheets -muunninta. Aluksi saimme tietää tarpeesta muuntaa PDF-dokumentit Google Sheetsiksi ja sen jälkeen tämän prosessin aikana kohtaamat haasteet. Sitten sukelsimme lähestymistapoihin, joita nykyaikaiset jäsentimet käyttävät PDF-dokumenttien jäsentämiseen, ja otimme myös käyttöön joitain yleisiä lähestymistapoja. Opimme myös, kuinka voimme täysin automatisoida muuntamisen käyttämällä ulkoisia integraatioita, kuten webhookeja ja API:ita. Lopuksi käytimme Nanonets-työkalua mallilaskun jäsentämiseen, tietojen purkamiseen Google Sheets -lomakkeeseen ja tutkimme myös sen hienoja jälkikäsittelyominaisuuksia.
Oletko kokeillut Nanonets-mallia? Jos näin on, jätä alle kommentti kokemuksistasi työkalusta. Jos ei, mene eteenpäin ja kokeile sitä. Se voi vain piristää päivääsi!
- AI
- Tekoäly ja koneoppiminen
- ai taide
- ai taiteen generaattori
- ai robotti
- tekoäly
- tekoälyn sertifiointi
- tekoäly pankkitoiminnassa
- tekoäly robotti
- tekoälyrobotit
- tekoälyohjelmisto
- blockchain
- blockchain-konferenssi ai
- coingenius
- keskustelullinen tekoäly
- kryptokonferenssi ai
- dall's
- syvä oppiminen
- google ai
- koneoppiminen
- pdf google taulukoihin
- Platon
- plato ai
- Platonin tietotieto
- Platon peli
- PlatonData
- platopeliä
- mittakaava ai
- syntaksi
- zephyrnet