Amazonin punainen siirto on nopea, skaalautuva, turvallinen ja täysin hallittu tietovarasto, jonka avulla voit analysoida kaikki tietosi tavallisella SQL:llä helposti ja kustannustehokkaasti. Amazon Redshift Tietojen jakaminen antaa asiakkaille mahdollisuuden jakaa turvallisesti reaaliaikaisia, tapahtumien kannalta yhdenmukaisia tietoja yhdessä Amazon Redshift -klusterissa toisen Amazon Redshift -klusterin kanssa tilien ja alueiden välillä ilman, että sinun tarvitsee kopioida tai siirtää tietoja klusterista toiseen.
Amazon Redshift Data Sharing lanseerattiin alun perin vuonna maaliskuu 2021, ja siihen lisättiin tuki tilien väliselle tietojen jakamiselle elokuu 2021. Alueiden välinen tuki tuli yleisesti saataville vuonna helmikuu 2022. Tämä tarjoaa täyden joustavuuden ja ketteryyden tietojen jakamiseen Redshift-klusterien välillä samalla AWS-tilillä, eri tileillä tai eri alueilla.
Amazon Redshift Data Sharingia käytetään Amazon Redshift -käyttöönottoarkkitehtuurien perustavaa laatua olevaan uudelleenmäärittelyyn keskuspuolaiseksi, dataverkkomalliksi, jotta se vastaa paremmin suoritustason SLA-sopimuksia, tarjoaa työkuorman eristyksen, suorittaa ryhmien välistä analytiikkaa, ottaa helposti käyttöön uusia käyttötapauksia ja mikä tärkeintä tämä ilman tietojen siirtämisen ja kopioinnin monimutkaisuutta. Jotkut yleisimmistä kysymyksistä, joita kysytään tiedon jakamisen käyttöönoton aikana, ovat "Kuinka suuria kuluttajaklusterini ja tuottajaklusterini pitäisi olla?" ja "Kuinka saan parhaan hintasuorituksen työkuormituksen eristämisestä?". Koska työkuorman ominaisuudet, kuten tiedon koko, käsittelynopeus, kyselymalli ja ylläpitotoimet, voivat vaikuttaa tiedon jakamisen suorituskykyyn, tulisi ottaa käyttöön jatkuva strategia sekä kuluttaja- että tuottajaklusterien kokoamiseksi suorituskyvyn maksimoimiseksi ja kustannusten minimoimiseksi. Tässä viestissä tarjoamme vaiheittaisen lähestymistavan, joka auttaa sinua määrittämään tuottaja- ja kuluttajaklusterikoot parhaan hintasuorituskyvyn saavuttamiseksi työmääräsi perusteella.
Yleiset kuluttajan mitoitusohjeet
Seuraavat vaiheet näyttävät yleisen strategian tuottaja- ja kuluttajaklusterien kokoamiseksi. Voit käyttää sitä lähtökohtana ja muokata vastaavasti vastaamaan erityistä käyttötapausskenaariota.
Kokoa tuottajaklusterisi
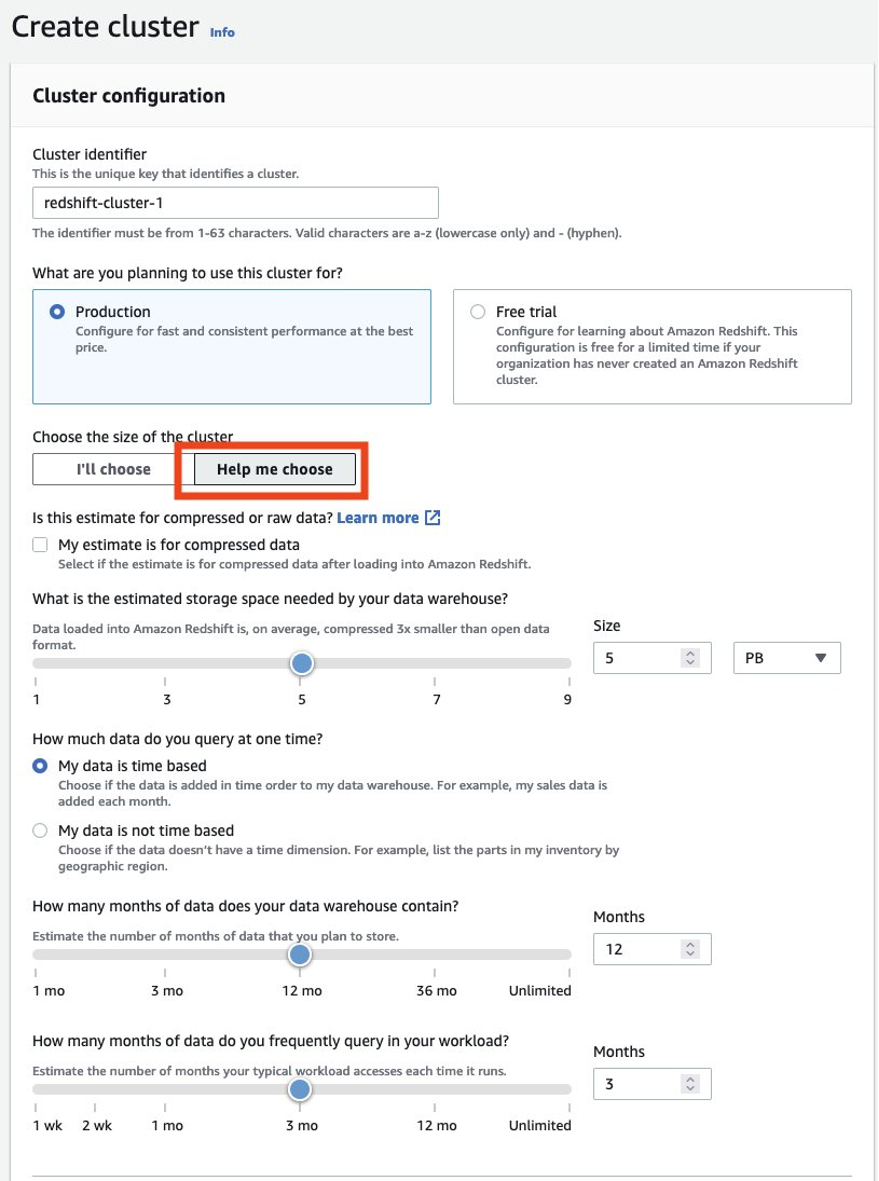
Varmista aina, että kokoat tuottajaklusterisi oikein, jotta saat SLA:si edellyttämän suorituskyvyn. Voit hyödyntää Amazon Redshift -konsolin kokolaskuria saadaksesi suosituksen tuottajaklusterille tietosi koon ja kyselyn ominaisuuden perusteella. Etsiä Auta minua valitsemaan konsolissa AWS-alueilla, jotka tukevat RA3-solmutyyppejä, jotta voit käyttää tätä kokolaskuria. Huomaa, että tämä on vain aloitussuositus, ja sinun tulee testata koko työkuormasi suorittamista alkuperäisen kokoluokan klusterissa ja muuttaa klusterin kokoa joustavasti ylös- ja alaspäin saadaksesi parhaan hintasuorituksen.
Alkuperäisen kuluttajaklusterin koko ja asennus
Kuluttajaklusterin koko tulee aina määrittää laskentatarpeesi mukaan. Yksi tapa aloittaa on noudattaa yleistä klusterin kokoopasta, joka on samanlainen kuin yllä oleva tuottajaklusteri.
Määritä Amazon Redshift -tietojen jakaminen
Määritä tietojen jakaminen tuottajalta kuluttajalle, kun olet määrittänyt sekä tuottajan että kuluttajaklusterin. Katso tästä posti saadaksesi ohjeita tietojen jakamisen määrittämiseen.
Testaa vain kuluttajan työkuormitus alkuperäisessä kuluttajaklusterissa
Testaa vain kuluttajan työkuormitusta uudessa alkuperäisessä kuluttajaklusterissa. Tämä voidaan tehdä osoittamalla kuluttajasovellukset, kuten ETL-työkalut, BI-sovellukset ja SQL-asiakkaat, uuteen kuluttajaklusteriin ja suorittamalla työkuorma uudelleen arvioidaksesi suorituskykyä vaatimuksiasi vastaavasti.
Testaa vain kuluttajan työkuormitusta eri kuluttajaklusterikokoonpanoissa
Jos alkuperäisen kuluttajaklusterin koko täyttää tai ylittää työkuorman suorituskykyvaatimukset, voit joko jatkaa tämän klusterin kokoonpanon käyttöä tai testata pienemmissä kokoonpanoissa nähdäksesi, voitko edelleen vähentää kustannuksia ja silti saada tarvitsemasi suorituskyvyn.
Toisaalta, jos alkuperäisen kokoinen kuluttajaklusteri ei täytä työkuorman suorituskykyvaatimuksiasi, voit testata lisää suurempia määrityksiä saadaksesi SLA:si vastaavan kokoonpanon.
Nyrkkisääntönä on, että kuluttajaklusterin kokoa on kaksinkertaistettava klusterin alkuperäiseen kokoonpanoon asteittain, kunnes se täyttää työkuormitusvaatimukset.
Kun olet suunnitellut, mitä kokoonpanoa haluat testata, käytä elastista koonmuutosta alkuperäisen klusterin koon muuttamiseksi kohdeklusterin kokoonpanoksi. Kun elastinen koonmuutos on valmis, suorita sama työkuormitustesti ja arvioi suorituskyky suhteessa SLA:han. Valitse hintatehokkuustavoitteesi mukainen kokoonpano.
Testaa vain tuottajan kuormitusta eri tuottajaklusterikokoonpanoissa
Kun siirrät kuluttajatyökuormasi kuluttajaklusteriin, jossa on optimaalinen hintasuorituskyky, saattaa olla mahdollisuus vähentää tuottajan laskentaresursseja kustannusten säästämiseksi.
Tämän saavuttamiseksi voit suorittaa vain tuottajan työkuorman uudelleen 1/2x alkuperäisen tuottajan koosta ja arvioida työkuorman suorituskykyä. Klusterin koon muuttaminen ylös ja alas vastaavasti riippuu tuloksesta, ja sitten valitset tuottajan vähimmäiskokoonpanon, joka täyttää työkuorman suorituskykyvaatimukset.
Arvioi uudelleen täyden työkuorman jälkeen ajan mittaan
Kun Amazon Redshift kehittyy jatkuvasti ja suorituskykyä ja skaalautuvuutta parantavia julkaisuja julkaistaan jatkuvasti, tiedon jakamisen suorituskyky paranee edelleen. Lisäksi lukuisat muuttujat voivat vaikuttaa tiedonjakokyselyjen suorituskykyyn. Seuraavassa on vain muutamia esimerkkejä:
- Sisäänottonopeus ja tiedon määrä muuttuvat
- Kyselymalli ja ominaisuus
- Työmäärän muutokset
- samanaikaisuuden
- Huoltotoimet, esimerkiksi tyhjiö, analysointi ja ATO
Tästä syystä sinun on ajoittain arvioitava tuottaja- ja kuluttajaklusterin koko uudelleen yllä olevan strategian avulla, etenkin täyden työkuorman käyttöönoton jälkeen, saadaksesi klusterin kokoonpanosta uuden parhaan hintakehityksen.
Automaattiset mitoitusratkaisut
Jos ympäristösi sisälsi monimutkaisempaa arkkitehtuuria, esimerkiksi useilla työkaluilla tai sovelluksilla (BI, sisäänotto tai suoratoisto, ETL, datatiede), ei ehkä ole mahdollista käyttää yllä olevan yleisen ohjeen manuaalista menetelmää. Sen sijaan voit hyödyntää tässä osiossa olevia ratkaisuja toistaaksesi tuotantoklusterin työtaakan automaattisesti testikuluttaja- ja tuottajaklustereissa suorituskyvyn arvioimiseksi.
Yksinkertainen Replay-apuohjelma käytetään automaattisena ratkaisuna, joka opastaa sinua oikean tuottaja- ja kuluttajaklusterin koon hankkimisessa parhaan hintasuorituksen saavuttamiseksi.
Simple Replay on työkalu, jolla voit tehdä mitä jos -analyysin ja arvioida, kuinka työmääräsi toimii eri skenaarioissa. Työkalun avulla voit esimerkiksi vertailla todellista työmäärääsi uudella ilmentymätyypillä, kuten RA3:lla, arvioida uutta ominaisuutta tai arvioida erilaisia klusterikokoonpanoja. Se sisältää myös parannetun tuen tiedonkeruu- ja vientiputkien toistamiselle COPY- ja UNLOAD-käskyillä. Aloita ja toista työmääräsi lataamalla työkalu osoitteesta Amazon Redshift GitHub -tietovarasto.
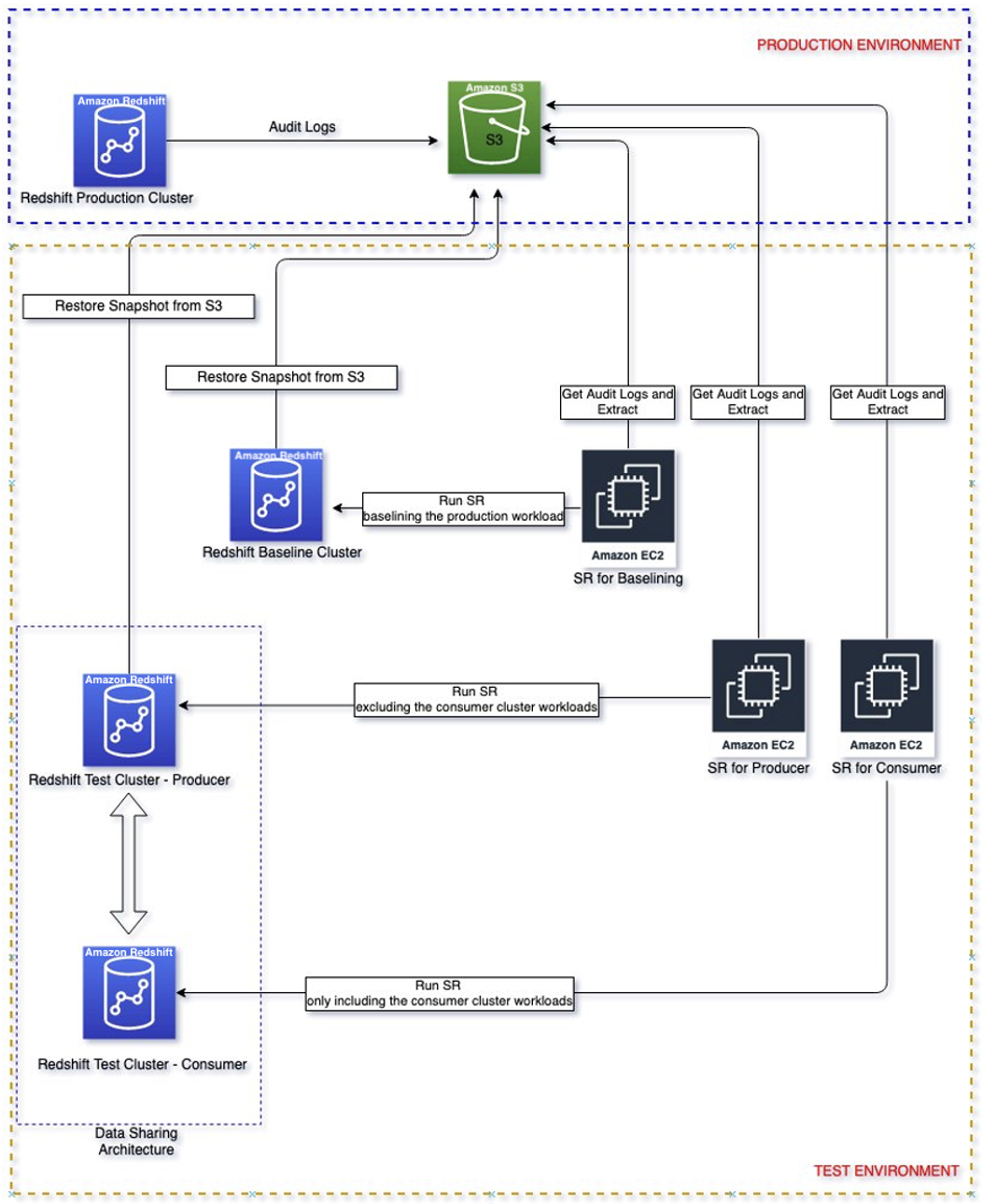
Tässä käymme läpi vaiheet, joiden avulla voit purkaa työkuormituslokit lähdetuotantoklusterista ja toistaa ne uudelleen eristetyssä ympäristössä. Tämän avulla voit suorittaa suoran vertailun näiden Amazon Redshift -klusterien välillä saumattomasti ja valita klusterikokoonpanot, jotka parhaiten vastaavat hintatavoitteesi.
Seuraava kaavio näyttää ratkaisuarkkitehtuurin.
Ratkaisun läpikäynti
Seuraa näitä ohjeita, kun haluat käydä läpi ratkaisun, jolla voit mitoittaa kuluttaja- ja tuottajaklusterisi.
Kokoa tuotantoklusterisi
Sinun tulee aina varmistaa, että nykyinen tuotantoklusterisi koko on oikein, jotta saat tarvitsemasi suorituskyvyn työkuormitusvaatimuksiesi täyttämiseen. Voit hyödyntää Amazon Redshift -konsolin kokolaskuria saadaksesi suosituksen tuotantoklusterista tietosi koon ja kyselyn ominaisuuden perusteella. Etsiä Auta minua valitsemaan konsolissa AWS-alueilla, jotka tukevat RA3-solmutyyppejä, jotta voit käyttää tätä kokolaskuria. Huomaa, että tämä on vain ensimmäinen suositus aloittaaksesi. Sinun tulisi testata koko työkuormasi suorittamista alkuperäisen kokoluokan klusterissa ja muuttaa klusterin kokoa joustavasti ylös- ja alaspäin vastaavasti saadaksesi parhaan hintasuorituksen.
Tunnista eristettävä työmäärä
Alkuperäisessä klusterissasi saattaa olla erilaisia työkuormia, mutta ensimmäinen askel on tunnistaa yritykselle kriittisin työkuorma, jonka haluamme eristää. Tämä johtuu siitä, että haluamme varmistaa, että uusi arkkitehtuuri täyttää työtaakkavaatimukset. Tämä posti on hyvä viite tietojen jakamisen työkuorman eristämisen käyttötapaukseen, joka voi auttaa sinua päättämään, mikä työkuorma voidaan eristää.
Yksinkertaisen toiston asetukset
Kun tiedät kriittisen työmääräsi, sinun täytyy ota tarkastusloki käyttöön tuotantoklusterissasi, jossa yllä mainittu kriittinen työkuorma on käynnissä kyselytoimintojen kaappaamiseksi ja tallentamiseksi Amazonin yksinkertainen tallennuspalvelu (Amazon S3). Huomaa, että voi kestää jopa kolme tuntia, ennen kuin tarkastuslokit toimitetaan Amazon S3:lle. Kun tarkastusloki on saatavilla, jatka kohtaan asetukset Simple Replay ja sitten uute kriittistä työmäärää tarkastuslokista. Huomaa, että alkamisaikaa ja lopetusaikaa voidaan käyttää parametreina kriittisen työmäärän suodattamiseen, jos työkuormat suoritetaan tiettyinä ajanjaksoina, esimerkiksi klo 9–11. Muuten se purkaa kaikki kirjatut toiminnot.
Perustyökuormitus
Luo perusklusteri, jolla on samat kokoonpanot kuin tuottajaklusterilla, palauttamalla se tuotannon tilannekuvasta. Samalla kokoonpanolla aloittamisen tarkoitus on perustaa suorituskyky eristetylle ympäristölle.
Kun perusklusteri on saatavilla, kuunnella poimittu työkuormitus perusklusterissa. Tämän toiston tulos on lähtötaso, jota käytetään verrattaessa myöhempiä toistoja eri kuluttajakokoonpanoissa.
Määritä alkuperäiset tuottaja- ja kuluttajatestiklusterit
Luo tuottajaklusteri, jolla on sama tuotantoklusterin konfiguraatio, palauttamalla tuotannon tilannevedos. Luo kuluttajaklusteri, jossa on edellisen ohjeen suositeltu alkuperäinen kuluttajakoko. Lisäksi määritä tietojen jakaminen tuottajan ja kuluttajan välillä.
Toista työtaakka alkuperäiselle tuottajalle ja kuluttajalle
Replay tuottaja kuormittaa vain alkuperäisen kokoisen tuottajaklusterin. Tämä voidaan saavuttaa käyttämällä "Sulje"-suodatinparametria kuluttajakyselyjen poissulkemiseksi, esimerkiksi kuluttajakyselyitä suorittavan käyttäjän.
Replay kuluttaja kuormittaa vain alkuperäisen kokoisen kuluttajaklusterin. Tämä voidaan saavuttaa käyttämällä "Sisällytä"-suodatinparametria, joka sulkee pois kuluttajakyselyt, esimerkiksi kuluttajakyselyitä suorittavan käyttäjän.
Arvioi näiden toistojen suorituskykyä perustason ja työkuorman suorituskykyvaatimusten perusteella.
Toista kuluttajan työkuormitus eri kokoonpanoissa
Jos alkuperäisen kuluttajaklusterin koko täyttää tai ylittää työkuorman suorituskykyvaatimukset, voit joko käyttää tätä klusterin kokoonpanoa tai testata pienempiä kokoonpanoja noudattamalla näitä ohjeita nähdäksesi, voitko edelleen vähentää kustannuksia ja silti saada tarvitsemasi suorituskyvyn.
Vertaa alkuperäisiä kuluttajan suoritustuloksia työtaakkavaatimuksiisi:
- Jos tulos ylittää työkuorman suorituskykyvaatimukset, voit pienentää kuluttajaklusterin kokoa asteittain, alkaen 1/2x, yrittää uudelleentoistoa ja arvioida tehokkuutta ja muuttaa sitten kokoa ylös- tai alaspäin vastaavasti tuloksen perusteella, kunnes se vastaa työkuormaasi. vaatimukset. Tarkoituksena on löytää suloinen paikka, jossa olet tyytyväinen suorituskykyvaatimuksiin ja saat edullisimman mahdollisen hinnan.
- Jos tulos ei täytä työkuorman suorituskykyvaatimuksia, voit kasvattaa klusterin kokoa asteittain, alkaen 2x alkuperäisestä koosta, yrittää uudelleentoistoa ja arvioida suorituskykyä, kunnes se täyttää työkuorman suorituskykyvaatimukset.
Toista tuottajan työmäärä eri kokoonpanoissa
Kun jaat työkuormasi kuluttajaklustereille, tuottajaklusterin kuormitusta tulisi vähentää ja sinun tulee arvioida tuottajaklusterin työkuorman suorituskykyä etsiäksesi mahdollisuutta pienentää kokoa kustannusten säästämiseksi.
Vaiheet ovat samanlaisia kuin kuluttajan uudelleentoisto. Joustava muuttaa tuottajaklusterin kokoa asteittain alkaen 1/2-kertaisesta alkuperäisestä koosta, toista vain tuottajan työkuorma ja arvioi suorituskykyä. Muuta sitten kokoa edelleen ylös- tai alaspäin, kunnes se täyttää työkuorman suorituskykyvaatimukset. Tarkoituksena on löytää suloinen paikka, jossa olet tyytyväinen työkuorman suorituskykyvaatimuksiin ja saat edullisimman mahdollisen hinnan. Kun olet saanut halutun tuottajaklusterin kokoonpanon, yritä toistaa kuluttajaklusterin kuluttajatyökuormat uudelleen varmistaaksesi, että tuottajaklusterin kokoonpanomuutokset eivät vaikuttaneet suorituskykyyn. Lopuksi sinun tulee toistaa sekä tuottajan että kuluttajan työmäärät samanaikaisesti varmistaaksesi, että suorituskyky saavutetaan täydessä työkuormassa.
Arvioi uudelleen täyden työkuorman jälkeen ajan mittaan
Kuten yleisessä ohjeessa, sinun tulee joskus arvioida tuottaja- ja kuluttajaklustereiden kokoa uudelleen käyttämällä edellistä strategiaa, etenkin täyden työkuorman käyttöönoton jälkeen, jotta saat klusterin kokoonpanosta uuden parhaan hintakehityksen.
Puhdistaa
Näiden kokotestien suorittamisella AWS-tililläsi voi olla joitain kustannusvaikutuksia, koska se tarjoaa uusia Amazon Redshift -klustereita, jotka voidaan veloittaa on-demand-esiintyminä, jos sinulla ei ole Varattuja esiintymiä. Kun olet suorittanut arvioinnit, suosittelemme Amazon Redshift -klusterien poistamista kustannusten säästämiseksi. Suosittelemme myös keskeyttämään klusterit, kun ne eivät ole käytössä.
Amazon Redshiftin ja tiedon jakamisen parhaiden käytäntöjen soveltaminen
Sekä tuottaja- että kuluttajaklustereiden oikea koko antaa sinulle hyvän alun saadaksesi parhaan hintasuorituksen Amazon Redshift -asetuksestasi. Koko ei kuitenkaan ole ainoa tekijä, joka voi maksimoida suorituskykysi. Tässä tapauksessa parhaiden käytäntöjen ymmärtäminen ja noudattaminen on yhtä tärkeää.
Yleiset Amazon Redshift -suorituskyvyn säätämisen parhaat käytännöt soveltuvat tiedon jakamiseen. Varmista, että käyttöönottosi noudattaa näitä parhaat käytännöt.
On olemassa lukuisia tiedon jakamiseen liittyviä parhaita käytäntöjä, joita sinun tulee noudattaa varmistaaksesi, että maksimoit suorituskyvyn. Katso tästä posti lisätietoja.
Yhteenveto
Tuottaja- ja kuluttajaklusterikoosta ei ole olemassa kaikille sopivaa suositusta. Se vaihtelee työkuormien ja suoritustason SLA:n mukaan. Tämän postauksen tarkoituksena on antaa sinulle ohjeita siitä, miten voit arvioida tietyn datan jakamisen työkuorman suorituskykyä ja määrittää sekä kuluttaja- että tuottajaklusterikoot parhaan hintasuorituskyvyn saavuttamiseksi. Harkitse työkuormituksen testaamista tuottajan ja kuluttajan parissa käyttämällä yksinkertaista toistoa ennen sen käyttöönottoa tuotannossa parhaan hintasuorituksen saamiseksi.
Tietoja Tekijät
 BP Yau on AWS:n tuotepäällikkö. Hän haluaa auttaa asiakkaita suunnittelemaan big data -ratkaisuja datan käsittelyyn mittakaavassa. Ennen AWS:ää hän auttoi Amazon.com Supply Chain Optimization Technologiesia siirtämään Oracle-tietovarastonsa Amazon Redshiftiin ja rakentamaan seuraavan sukupolven big datan analytiikkaalustan AWS-tekniikoilla.
BP Yau on AWS:n tuotepäällikkö. Hän haluaa auttaa asiakkaita suunnittelemaan big data -ratkaisuja datan käsittelyyn mittakaavassa. Ennen AWS:ää hän auttoi Amazon.com Supply Chain Optimization Technologiesia siirtämään Oracle-tietovarastonsa Amazon Redshiftiin ja rakentamaan seuraavan sukupolven big datan analytiikkaalustan AWS-tekniikoilla.
 Sidhanth Muralidhar on pääasiallinen tekninen asiakaspäällikkö AWS:ssä. Hän työskentelee suurten yritysasiakkaiden kanssa, jotka suorittavat työmääränsä AWS:llä. Hän on intohimoinen työskennellä asiakkaiden kanssa ja auttaa heitä suunnittelemaan työkuormia kustannusten, luotettavuuden, suorituskyvyn ja toiminnan erinomaisuuden mittakaavassa pilvimatkallaan. Hän on kiinnostunut myös Data Analyticsista.
Sidhanth Muralidhar on pääasiallinen tekninen asiakaspäällikkö AWS:ssä. Hän työskentelee suurten yritysasiakkaiden kanssa, jotka suorittavat työmääränsä AWS:llä. Hän on intohimoinen työskennellä asiakkaiden kanssa ja auttaa heitä suunnittelemaan työkuormia kustannusten, luotettavuuden, suorituskyvyn ja toiminnan erinomaisuuden mittakaavassa pilvimatkallaan. Hän on kiinnostunut myös Data Analyticsista.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- Platoblockchain. Web3 Metaverse Intelligence. Tietoa laajennettu. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/big-data/how-to-get-best-price-performance-from-your-amazon-redshift-data-sharing-deployment/
- 100
- a
- Meistä
- edellä
- sen mukaisesti
- Tili
- Tilit
- Saavuttaa
- saavutettu
- poikki
- toiminta
- lisä-
- hyväksymällä
- Jälkeen
- vastaan
- Kaikki
- mahdollistaa
- aina
- Amazon
- Amazon.com
- määrä
- analyysi
- Analytics
- analysoida
- ja
- Toinen
- sovelletaan
- sovellukset
- lähestymistapa
- arkkitehtuuri
- tilintarkastus
- Automatisoitu
- automaattisesti
- saatavissa
- AWS
- perustua
- Lähtötilanne
- koska
- ennen
- benchmark
- PARAS
- parhaat käytännöt
- Paremmin
- välillä
- Iso
- Big Data
- rakentaa
- liiketoiminta
- kaapata
- tapaus
- tapauksissa
- tietty
- ketju
- Muutokset
- ominainen
- ominaisuudet
- peritään
- asiakkaat
- pilvi
- Cluster
- KOM
- mukava
- Yhteinen
- verrata
- vertailu
- täydellinen
- Valmistunut
- monimutkainen
- monimutkaisuus
- Laskea
- johtavat
- Konfigurointi
- Harkita
- johdonmukainen
- Console
- kuluttaja
- jatkaa
- jatkuu
- jatkuva
- Hinta
- kustannukset
- voisi
- luoda
- kriittinen
- Asiakkaat
- tiedot
- Data Analytics
- tietojenkäsittely
- tietojen jakaminen
- toimitettu
- riippuu
- käyttöönotto
- yksityiskohdat
- Määrittää
- eri
- ohjata
- Dont
- alas
- download
- aikana
- helposti
- myöskään
- mahdollistaa
- tehostettu
- yritys
- ympäristö
- yhtä
- erityisesti
- Eetteri (ETH)
- arvioida
- arvioinnit
- kehittyvä
- esimerkki
- Esimerkit
- ylittää
- Erinomaisuus
- olemassa
- vienti
- uute
- epäonnistuu
- FAST
- mahdollinen
- Ominaisuus
- suodattaa
- Vihdoin
- Etunimi
- Joustavuus
- seurata
- jälkeen
- seuraa
- alkaen
- koko
- pohjimmiltaan
- edelleen
- Lisäksi
- Saada
- yleensä
- sukupolvi
- saada
- saada
- GitHub
- Antaa
- Go
- hyvä
- ohjaavat
- auttaa
- auttanut
- auttaa
- TUNTIA
- Miten
- Miten
- Kuitenkin
- HTTPS
- tunnistettu
- tunnistaa
- Vaikutus
- vaikutti
- täytäntöön
- vaikutukset
- tärkeä
- parannus
- parantaminen
- in
- sisältää
- Kasvaa
- ensimmäinen
- ensin
- esimerkki
- sen sijaan
- korko
- osallistuva
- yksittäinen
- eristäminen
- IT
- matka
- Innokas
- Tietää
- suuri
- suurempi
- käynnistettiin
- Lets
- Vaikutusvalta
- elää
- kuormitus
- katso
- huolto
- tehdä
- johtaja
- manuaalinen
- Maksimoida
- Tavata
- Meets
- menetelmä
- ehkä
- vaeltaa
- minimi
- malli
- lisää
- eniten
- liikkua
- liike
- moninkertainen
- Tarve
- tarvitsevat
- tarpeet
- Uusi
- seuraava
- solmu
- useat
- tilaisuus
- Laivalla
- ONE
- toiminta-
- Tilaisuus
- optimointi
- optimaalinen
- oraakkeli
- alkuperäinen
- Muut
- muuten
- parametri
- parametrit
- intohimoinen
- Kuvio
- suorittaa
- suorituskyky
- suorittaa
- aikoja
- suunnitelma
- foorumi
- Platon
- Platonin tietotieto
- PlatonData
- Kohta
- mahdollinen
- Kirje
- käytännöt
- edellinen
- hinta
- Pääasiallinen
- prosessi
- tuottaja
- Tuotteet
- tuotepäällikkö
- tuotanto
- asianmukaisesti
- toimittaa
- tarjoaa
- tarkoitus
- kysymykset
- hinta
- suositella
- Suositus
- suositeltu
- vähentää
- Vähentynyt
- alueet
- Tiedotteet
- luotettavuus
- vaatimukset
- varattu
- resurssi
- palauttaminen
- johtua
- tulokset
- Sääntö
- ajaa
- juoksu
- sama
- Säästä
- skaalautuvuus
- skaalautuva
- Asteikko
- skenaariot
- tiede
- saumattomasti
- Osa
- turvallinen
- turvallisesti
- etsiä
- palvelu
- setup
- Jaa:
- jakaminen
- shouldnt
- näyttää
- Näytä
- samankaltainen
- Yksinkertainen
- Koko
- koot
- pienempiä
- Kuva
- ratkaisu
- Ratkaisumme
- jonkin verran
- lähde
- erityinen
- jakaa
- Kaupallinen
- standardi
- Alkaa
- alkoi
- Aloita
- lausuntoja
- Vaihe
- Askeleet
- Yhä
- Levytila
- verkkokaupasta
- Strategia
- streaming
- myöhempi
- toimittaa
- toimitusketju
- Toimitusketjun optimointi
- tuki
- makea
- ottaa
- Kohde
- Tekninen
- Technologies
- testi
- Testaus
- testit
- -
- Lähde
- heidän
- kolmella
- Kautta
- aika
- että
- työkalu
- työkalut
- tyypit
- ymmärtäminen
- käyttää
- käyttölaukku
- käyttäjä
- tyhjiö
- Mitä
- joka
- KUKA
- tulee
- ilman
- työskentely
- toimii
- Sinun
- zephyrnet