Aikasarjatiedot ovat laajalti läsnä elämässämme. Osakkeiden hinnat, asuntojen hinnat, säätiedot ja ajan mittaan kerätyt myyntitiedot ovat vain muutamia esimerkkejä. Kun yritykset etsivät yhä useammin uusia tapoja saada merkityksellisiä oivalluksia aikasarjatiedoista, kyky visualisoida dataa ja toteuttaa haluttuja muunnoksia ovat tärkeitä vaiheita. Aikasarjatiedoilla on kuitenkin ainutlaatuisia ominaisuuksia ja vivahteita muihin taulukkotietoihin verrattuna, ja ne vaativat erityisiä huomioita. Esimerkiksi vakiotaulukko- tai poikkileikkaustiedot kerätään tiettynä ajankohtana. Sitä vastoin aikasarjatiedot kerätään toistuvasti ajan mittaan, ja jokainen peräkkäinen datapiste riippuu sen aiemmista arvoista.
Koska useimmat aikasarja-analyysit perustuvat tietoihin, jotka on kerätty peräkkäisten havaintojen joukosta, puuttuvat tiedot ja luontainen harvalukuisuus voivat heikentää ennusteiden tarkkuutta ja aiheuttaa harhaa. Lisäksi useimmat aikasarja-analyysimenetelmät perustuvat yhtäläiseen datapisteiden väliseen etäisyyteen, toisin sanoen jaksoittaisuuteen. Siksi kyky korjata datavälin epäsäännöllisyydet on kriittinen edellytys. Lopuksi aikasarjaanalyysi vaatii usein lisäominaisuuksien luomista, jotka voivat auttaa selittämään syöttötietojen ja tulevaisuuden ennusteiden välisen luontaisen suhteen. Kaikki nämä tekijät erottavat aikasarjaprojektit perinteisistä koneoppimisskenaarioista (ML) ja vaativat erillistä lähestymistapaa sen analysointiin.
Tämä viesti opastaa käyttöä Amazon SageMaker Data Wrangler soveltaa aikasarjamuunnoksia ja valmistella tietojoukkosi aikasarjojen käyttötapauksia varten.
Data Wranglerin käyttötapaukset
Data Wrangler tarjoaa koodittoman/matalakoodiratkaisun aikasarja-analyysiin, jossa on ominaisuuksia, jotka mahdollistavat tietojen nopeamman puhdistamisen, muuntamisen ja valmistelun. Sen avulla datatieteilijät voivat myös valmistella aikasarjatietoja ennustemallinsa syöttömuotovaatimusten mukaisesti. Seuraavassa on muutamia tapoja, joilla voit käyttää näitä ominaisuuksia:
- Kuvaava analyysi– Yleensä datatiedeprojektin ensimmäinen vaihe on datan ymmärtäminen. Kun piirrämme aikasarjatietoja, saamme korkean tason yleiskatsauksen sen kuvioista, kuten trendistä, kausivaihteluista, syklistä ja satunnaisista vaihteluista. Se auttaa meitä päättämään oikean ennustemenetelmän näiden mallien tarkkaan esittämiseen. Piirustus voi myös auttaa tunnistamaan poikkeamat ja ehkäisemään epärealistisia ja epätarkkoja ennusteita. Data Wranglerin mukana tulee a kausivaihtelun ja trendin hajoamisen visualisointi aikasarjan komponenttien esittämiseen ja an outlier havaitsemisen visualisointi poikkeamien tunnistamiseksi.
- Selittävä analyysi– Monimuuttujaisissa aikasarjoissa kyky tutkia, tunnistaa ja mallintaa kahden tai useamman aikasarjan välinen suhde on olennainen mielekkäiden ennusteiden saamiseksi. The Ryhmän mukaan transform in Data Wrangler luo useita aikasarjoja ryhmittelemällä tiedot tiettyihin soluihin. Lisäksi Data Wranglerin aikasarjamuunnokset mahdollistavat tarvittaessa lisätunnussarakkeiden määrittämisen ryhmitettäviksi, mikä mahdollistaa monimutkaisen aikasarjaanalyysin.
- Tietojen valmistelu ja ominaisuussuunnittelu– Aikasarjatiedot ovat harvoin aikasarjamallien edellyttämässä muodossa. Raakatietojen muuntaminen aikasarjakohtaisiksi ominaisuuksiksi vaatii usein tietojen valmistelua. Haluat ehkä vahvistaa, että aikasarjatiedot ovat säännöllisesti tai tasavälein ennen analyysiä. Käyttötapausten ennustamista varten saatat haluta sisällyttää myös muita aikasarjaominaisuuksia, kuten autokorrelaatiota ja tilastollisia ominaisuuksia. Data Wranglerin avulla voit nopeasti luoda aikasarjaominaisuuksia, kuten viivesarakkeita useille viivejaksoille, ottaa dataa uudelleen useisiin aikatarkkoihin ja poimia automaattisesti aikasarjan tilastollisia ominaisuuksia muutamia ominaisuuksia mainitaksesi.
Ratkaisun yleiskatsaus
Tässä postauksessa käsitellään tarkemmin sitä, kuinka datatieteilijät ja analyytikot voivat käyttää Data Wrangleria aikasarjatietojen visualisointiin ja valmisteluun. Käytämme bitcoinin kryptovaluuttatietojoukkoa salaustietojen lataus bitcoin-kaupan yksityiskohdilla näiden ominaisuuksien esittelemiseksi. Puhdistamme, validoimme ja muunnamme raakatietojoukon aikasarjaominaisuuksilla ja luomme myös bitcoin-määrän hintaennusteita käyttämällä muunnettua tietojoukkoa syötteenä.
Otos bitcoin-kaupan tiedoista on ajalta 1.–19, ja siinä on 2021 464,116 datapistettä. Tietojoukon attribuutit sisältävät hintatietueen aikaleiman, avaushinnan tai ensimmäisen hinnan, jolla kolikko vaihdettiin tiettynä päivänä, korkeimman hinnan, jolla kolikko vaihdettiin sinä päivänä, viimeisen hinnan, jolla kolikko vaihdettiin päivä, vaihdettu määrä kryptovaluutan arvona päivänä BTC:ssä ja vastaava USD-valuutta.
Edellytykset
Lataa Bitstamp_BTCUSD_2021_minute.csv Tiedosto salaustietojen lataus ja lataa se osoitteeseen Amazonin yksinkertainen tallennuspalvelu (Amazon S3).
Tuo bitcoin-tietojoukko Data Wrangleriin
Aloita Data Wrangleriin käsittelyprosessi suorittamalla seuraavat vaiheet:
- On SageMaker Studio konsoli filee valikosta, valitse Uusi, valitse sitten Data Wrangler Flow.
- Nimeä kulku uudelleen haluamallasi tavalla.
- varten Tuo päivämäärät, valitse Amazon S3.
- Lataa
Bitstamp_BTCUSD_2021_minute.csvtiedosto S3-ämpäristäsi.
Voit nyt esikatsella tietojoukkoasi.
- In Lisätiedot ruutu, valitse Lisäasetukset ja poista valinta Ota otanta käyttöön.
Tämä on suhteellisen pieni tietojoukko, joten emme tarvitse otantaa.
- Valita Tuo.
Vuokaavion luominen onnistui ja olet valmis lisäämään muunnosvaiheita.

Lisää muunnoksia
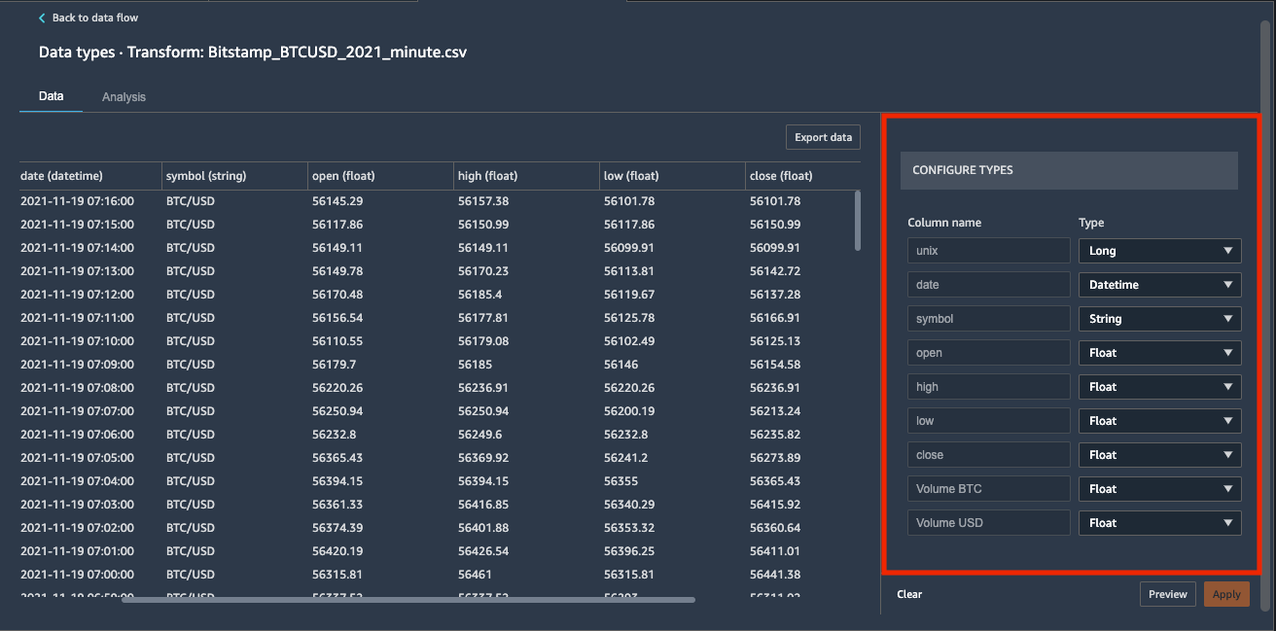
Voit lisätä datamuunnoksia valitsemalla plusmerkin vieressä Tietotyypit Ja valitse Muokkaa tietotyyppejä.

Varmista, että Data Wrangler päätteli automaattisesti oikeat tietotyypit tietosarakkeille.
Meidän tapauksessamme päätellyt tietotyypit ovat oikein. Oletetaan kuitenkin, että yksi tietotyyppi on virheellinen. Voit muokata niitä helposti käyttöliittymän kautta, kuten seuraavassa kuvakaappauksessa näkyy.
Aloitetaan analyysi ja aloitetaan muunnosten lisääminen.
Tietojen puhdistus
Suoritamme ensin useita tietojen puhdistusmuunnoksia.
Pudota sarake
Aloitetaan pudottamalla unix sarake, koska käytämme date sarake hakemistona.
- Valita Takaisin tietovirtaan.
- Valitse vieressä oleva plusmerkki Tietotyypit Ja valitse Lisää muunnos.
- Valita + Lisää vaihe vuonna LÄHETYKSET ruudussa.
- Valita Hallitse sarakkeita.
- varten Muuttaa, valitse Pudota sarake.
- varten Sarake pudotettavaksi, valitse unix.
- Valita preview.
- Valita Lisää vaiheen tallentamiseksi.
Kahva puuttuu
Puuttuvat tiedot on tunnettu ongelma reaalimaailman tietojoukoissa. Siksi on paras käytäntö tarkistaa puuttuvien tai nolla-arvojen olemassaolo ja käsitellä niitä asianmukaisesti. Tietojoukkomme ei sisällä puuttuvia arvoja. Mutta jos olisi, käyttäisimme Kahva puuttuu aikasarjamuutos niiden korjaamiseksi. Yleisesti käytettyjä puuttuvien tietojen käsittelystrategioita ovat puuttuvien arvojen rivien pudottaminen tai puuttuvien arvojen täyttäminen kohtuullisilla arvioilla. Koska aikasarjatiedot perustuvat tietopisteiden sarjaan ajan kuluessa, puuttuvien arvojen täyttäminen on suositeltava tapa. Puuttuvien arvojen täyttämisprosessia kutsutaan nimellä syyksi lukeminen. Kahva puuttuu aikasarjamuunnos antaa sinun valita useista imputointistrategioista.
- Valita + Lisää vaihe vuonna LÄHETYKSET ruudussa.
- Valitse Aikasarja muuttaa.
- varten Muuttaa, Valitse Kahva puuttuu.
- varten Aikasarjan syöttötyyppi, valitse Pylvään varrella.
- varten Menetelmä arvojen laskemiseksi, valitse Täyttö eteenpäin.
- Täyttö eteenpäin menetelmä korvaa puuttuvat arvot puuttuvia arvoja edeltävillä ei-puuttuvilla arvoilla.
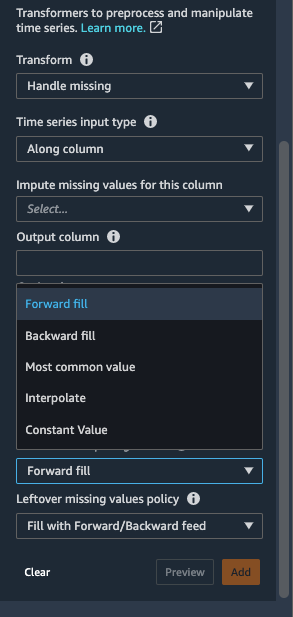
Täyttö taaksepäin, Vakioarvo, Yleisin arvo ja Interpoloida ovat muita imputointistrategioita, jotka ovat saatavilla Data Wranglerissa. Interpolointitekniikat luottavat viereisiin arvoihin puuttuvien arvojen täyttämiseksi. Aikasarjatiedot osoittavat usein korrelaatiota naapuriarvojen välillä, mikä tekee interpoloinnista tehokkaan täyttöstrategian. Katso lisätietoja funktioista, joita voit käyttää interpoloinnin soveltamiseen pandas.DataFrame.interpolate.
Vahvista aikaleima
Aikasarjaanalyysissä aikaleimasarake toimii indeksisarakkeena, jonka ympärillä analyysi pyörii. Siksi on tärkeää varmistaa, että aikaleima-sarake ei sisällä virheellisiä tai väärin muotoiltuja aikaleima-arvoja. Koska käytämme date sarake aikaleimasarakkeena ja hakemistona, tarkistetaan, että sen arvot on muotoiltu oikein.
- Valita + Lisää vaihe vuonna LÄHETYKSET ruudussa.
- Valitse Aikasarja muuttaa.
- varten Muuttaa, valita Vahvista aikaleimat.
- Vahvista aikaleimat muunnos antaa sinun tarkistaa, ettei tietojoukkosi aikaleimasarakkeessa ole arvoja, joissa on virheellinen aikaleima tai puuttuvat arvot.
- varten Aikaleima-sarake, valitse data.
- varten Käytäntö pudotusvalikosta, valitse Ilmoita.
- Ilmoita käytäntöasetus luo Boolen sarakkeen, joka osoittaa, onko aikaleimasarakkeen arvo kelvollinen päivämäärä/aikamuoto. Muita vaihtoehtoja varten Käytäntö sisältää:
- Virhe – Antaa virheen, jos aikaleimasarake puuttuu tai on virheellinen
- Pudota – Pudottaa rivin, jos aikaleimasarake puuttuu tai se on virheellinen
- Valita preview.
Uusi Boolen sarake nimeltä date_is_valid luotiin, kanssa true arvot osoittavat oikean muodon ja ei-nolla-merkinnät. Tietojoukkomme ei sisällä virheellisiä aikaleima-arvoja date sarakkeessa. Mutta jos näin kävi, voit käyttää uutta Boolen saraketta näiden arvojen tunnistamiseen ja korjaamiseen.
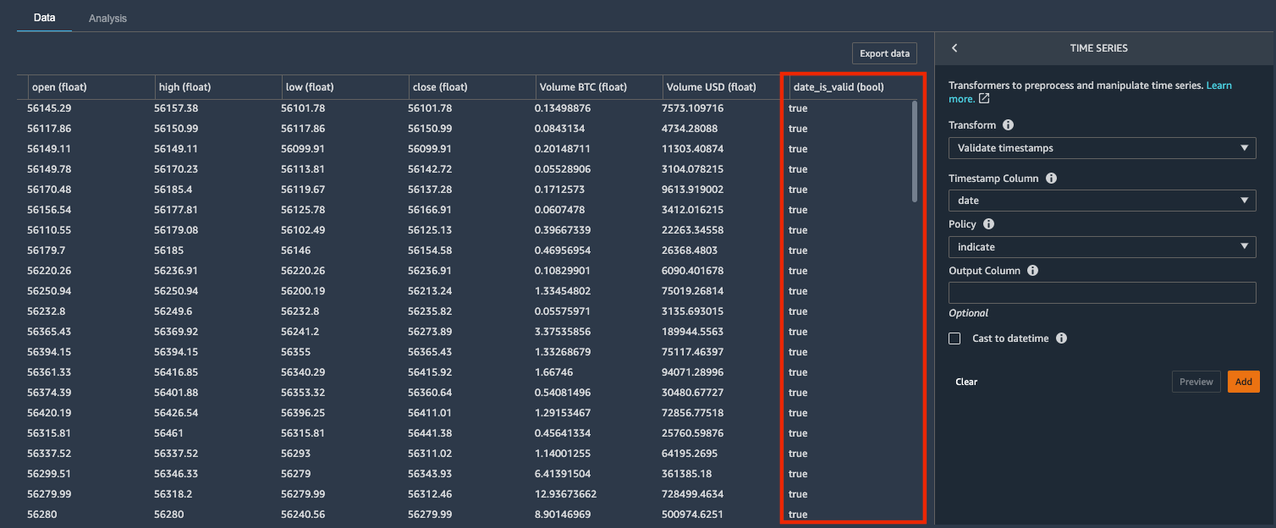
- Valita Lisää tämän vaiheen tallentamiseksi.
Aikasarjan visualisointi
Kun olemme puhdistaneet ja vahvistaneet tietojoukon, voimme visualisoida tiedot paremmin ymmärtääksemme sen eri komponentteja.
resample
Koska olemme kiinnostuneita päivittäisistä ennusteista, muutetaan tietojen tiheys päivittäisiksi.
- resample muunnos muuttaa aikasarjan havaintojen tiheyden tiettyyn tarkkuuteen, ja mukana tulee sekä ylös- että alasnäytteenottovaihtoehtoja. Ylösnäytteenotto lisää havaintojen tiheyttä (esimerkiksi päivittäisestä tuntikohtaiseksi), kun taas alasnäytteenotto vähentää havaintojen tiheyttä (esimerkiksi tunneista päivittäiseksi).
Koska tietojoukkomme on pienikokoinen, käytetään alasnäytteenottovaihtoehtoa.
- Valita + Lisää vaihe.
- Valitse Aikasarja muuttaa.
- varten Muuttaa, valitse resample.
- varten Aikaleima, valitse data.
- varten Taajuusyksikkö, valitse Kalenteri päivä.
- varten Taajuusmäärä, kirjoita 1.
- varten Numeeristen arvojen aggregointimenetelmä, valitse tarkoittaa.
- Valita preview.
Tietojoukkomme tiheys on muuttunut minuutista päivittäiseksi.

- Valita Lisää tämän vaiheen tallentamiseksi.
Kausi-trendin hajoaminen
Uudelleennäytteenoton jälkeen voimme visualisoida muunnetun sarjan ja siihen liittyvät STL-komponentit (Seasonal and Trend decomposition using LOESS) käyttämällä Seasonal-Trend-hajoaminen visualisointi. Tämä jakaa alkuperäiset aikasarjat erillisiin trendeihin, kausivaihteluihin ja jäännöskomponentteihin, mikä antaa meille hyvän käsityksen kunkin mallin käyttäytymisestä. Voimme käyttää tietoja myös ennusteongelmien mallintamiseen.
Data Wrangler käyttää LOESSia, joka on vankka ja monipuolinen tilastollinen menetelmä trendien ja kausikomponenttien mallintamiseen. Sen taustalla oleva toteutus käyttää polynomiregressiota arvioimaan aikasarjan komponenteissa (kausiluonteisuus, trendi ja jäännös) esiintyviä epälineaarisia suhteita.
- Valita Takaisin tietovirtaan.
- Valitse plusmerkki vierestä Askeleet on Tietovirta.
- Valita Lisää analyysi.
- In Luo analyysi ruutu, varten Analyysin tyyppi, valita Aikasarja.
- varten Visualisointi, valitse Kausi-trendin hajoaminen.
- varten Analyysin nimi, kirjoita nimi.
- varten Aikaleima-sarake, valitse data.
- varten Arvosarake, valitse Volyymi USD.
- Valita preview.
Analyysin avulla voimme visualisoida syötetyt aikasarjat ja hajautetut kausivaihtelut, trendit ja jäännös.

- Valita Säästä analyysin tallentamiseksi.
Kanssa kausittaisen trendin hajoamisen visualisointi, voimme luoda neljä mallia, kuten edellisessä kuvakaappauksessa näkyy:
- Alkuperäinen – Alkuperäinen aikasarja otettu uudelleen päivittäiseen tarkkuuteen.
- Trend – Polynominen trendi, jonka yleinen negatiivinen trendimalli vuodelle 2021 viittaa laskuun
Volume USDarvoa. - Kausi – Kerrannaisvaikutus, jota edustavat vaihtelevat värähtelykuviot. Näemme kausivaihtelun vähenemisen, jolle on ominaista heilahtelujen amplitudin pieneneminen.
- jäljelle jäävä – Jäljellä oleva jäännöskohina tai satunnainen kohina. Jäännössarja on tuloksena saatu sarja, kun trendi- ja kausikomponentit on poistettu. Tarkemmin tarkasteltuna havaitsemme piikkejä tammi-maaliskuussa ja huhti-kesäkuussa, mikä viittaa tällaisten tapahtumien mallintamiseen historiallisten tietojen avulla.
Nämä visualisoinnit antavat datatieteilijöille ja analyytikoille arvokkaita vihjeitä olemassa oleviin malleihin ja voivat auttaa sinua valitsemaan mallinnusstrategian. On kuitenkin aina hyvä käytäntö vahvistaa STL-hajoamisen tulos kuvailevan analyysin ja toimialueasiantuntemuksen avulla kerätyillä tiedoilla.
Yhteenvetona voidaan todeta, että havaitsemme laskevan trendin, joka on yhdenmukainen alkuperäisen sarjavisualisoinnin kanssa, mikä lisää luottamusta trendien visualisoinnin välittämän tiedon sisällyttämiseen loppupään päätöksentekoon. Sitä vastoin kausiluonteisuuden visualisointi auttaa tiedottamaan kausiluonteisuuden olemassaolosta ja sen poistamisen tarpeesta käyttämällä erilaisia tekniikoita, kuten erotusta, se ei tarjoa haluttua yksityiskohtaista tietoa erilaisista esiintyvistä kausiluonteisista malleista, mikä vaatii syvempää analysointia.
Ominaisuuksien suunnittelu
Kun olemme ymmärtäneet tietojoukossamme olevat mallit, voimme alkaa suunnitella uusia ominaisuuksia, joilla pyritään lisäämään ennustemallien tarkkuutta.
Esitä päivämäärä-aika
Aloitetaan ominaisuuden suunnitteluprosessi yksinkertaisemmilla päivämäärä- ja aikaominaisuuksilla. Päivämäärä/aika-ominaisuudet luodaan timestamp sarakkeessa ja tarjota datatieteilijöille optimaalinen tapa aloittaa ominaisuuden suunnitteluprosessi. Aloitamme kanssa Esitä päivämäärä-aika aikasarjamuunnos lisätäksesi kuukauden, kuukauden, päivän, vuoden, viikon ja vuosineljänneksen ominaisuudet tietojoukkoomme. Koska tarjoamme päivämäärä- ja aikakomponentit erillisinä ominaisuuksina, sallimme ML-algoritmien havaita signaalit ja kuviot ennustetarkkuuden parantamiseksi.
- Valita + Lisää vaihe.
- Valitse Aikasarja muuttaa.
- varten Muuttaa, valita Esitä päivämäärä-aika.
- varten Syötesarake, valitse data.
- varten Tulosarake, tulla sisään
date(tämä vaihe on valinnainen). - varten Tulostustilassa, valitse järjestysluku.
- varten Tulostusmuoto, valitse Pylväät.
- Jos haluat poimia päivämäärän/ajan ominaisuudet, valitse Kuukausi, Päivä, Vuoden viikko, Vuoden päiväja Neljännes.
- Valita preview.
Tietojoukko sisältää nyt uusia sarakkeita nimeltä date_month, date_day, date_week_of_year, date_day_of_yearja date_quarter. Näistä uusista ominaisuuksista haetut tiedot voivat auttaa datatieteilijöitä saamaan lisänäkemyksiä tiedoista ja syöttöominaisuuksien ja tulosteiden välisestä suhteesta.
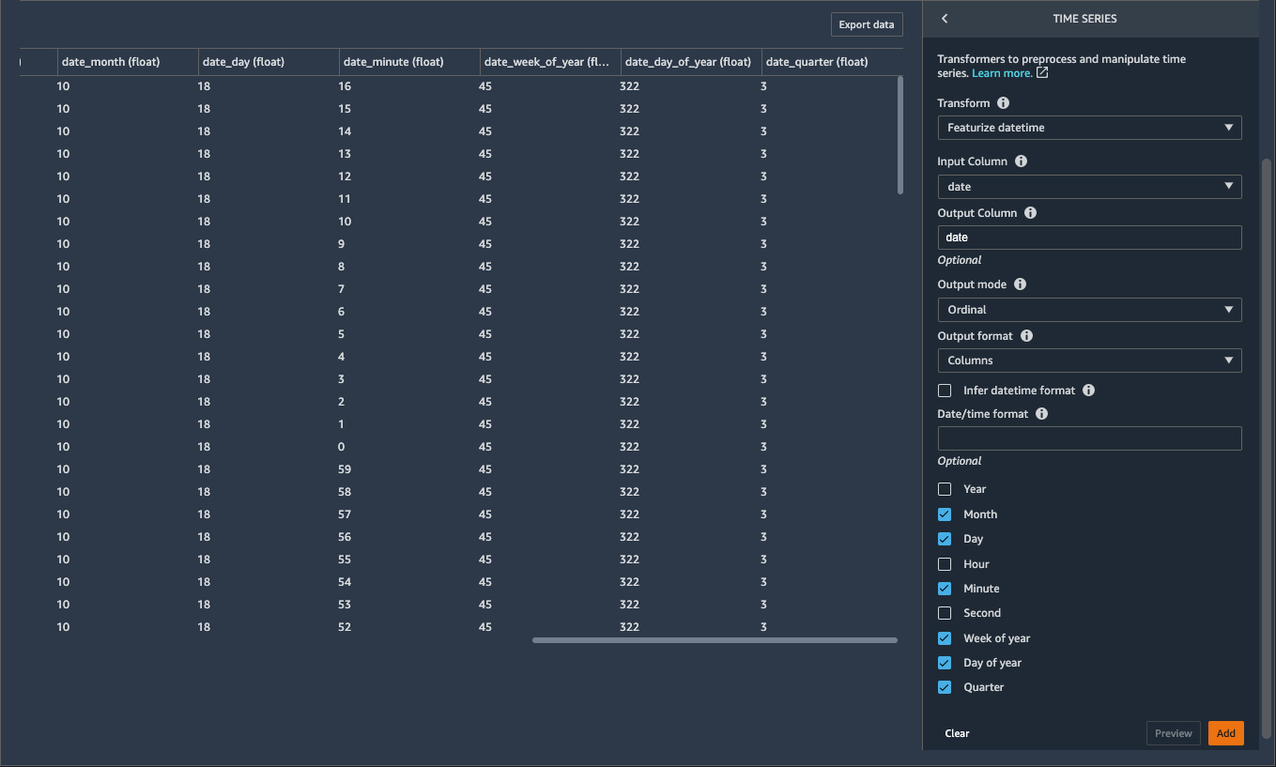
- Valita Lisää tämän vaiheen tallentamiseksi.
Koodaa kategorinen
Päivämäärä/aika-ominaisuudet eivät rajoitu kokonaislukuarvoihin. Voit myös harkita tiettyjä poimittuja päivämäärä/aika -ominaisuuksia kategorisina muuttujina ja esittää ne yksitoimisina koodattuina ominaisuuksina, jolloin jokainen sarake sisältää binääriarvoja. Äskettäin luotu date_quarter sarake sisältää arvot välillä 0-3, ja se voidaan koodata neljällä binäärisarakkeella. Luodaan neljä uutta binaariominaisuutta, joista jokainen edustaa vuoden vastaavaa neljännestä.
- Valita + Lisää vaihe.
- Valitse Koodaa kategorinen muuttaa.
- varten Muuttaa, valitse Yksi kuuma koodaus.
- varten Syöttösarake, valitse päivämäärä_neljännes.
- varten Tulostustyyli, valitse Pylväät.
- Valita preview.
- Valita Lisää lisätä askel.

Viive-ominaisuus
Luodaan seuraavaksi viiveominaisuudet kohdesarakkeelle Volume USD. Aikasarjaanalyysin viiveominaisuudet ovat aikaisempien aikaleimojen arvoja, joiden katsotaan auttavan tulevien arvojen päättämisessä. Ne auttavat myös tunnistamaan autokorrelaation (tunnetaan myös nimellä sarjakorrelaatio) jäännössarjan kuvioita kvantifioimalla havainnon suhde aikaisempien aikavaiheiden havaintoihin. Autokorrelaatio on samanlainen kuin tavallinen korrelaatio, mutta sarjan arvojen ja sen aikaisempien arvojen välillä. Se muodostaa perustan ARIMA-sarjan autoregressiivisille ennustemalleille.
Data Wranglerin kanssa Viive-ominaisuus muunnos, voit helposti luoda viiveominaisuuksia n jakson välein. Lisäksi haluamme usein luoda useita viiveominaisuuksia eri viiveillä ja antaa mallin päättää merkityksellisimmät ominaisuudet. Tällaista skenaariota varten Viiveominaisuudet muunnos auttaa luomaan useita viivesarakkeita määritetyn ikkunakoon yli.
- Valita Takaisin tietovirtaan.
- Valitse plusmerkki vierestä Askeleet on Tietovirta.
- Valita + Lisää vaihe.
- Valita Aikasarja muuttaa.
- varten Muuttaa, valitse Viiveominaisuudet.
- varten Luo viiveominaisuudet tälle sarakkeelle, valitse Volyymi USD.
- varten Aikaleima-sarake, valitse data.
- varten Joukkue, tulla sisään
7. - Koska olemme kiinnostuneita seuraamaan enintään seitsemän edellistä viivearvoa, valitaan Sisällytä koko viiveikkuna.
- Luo uusi sarake kullekin viivearvolle valitsemalla Tasoita ulostulo.
- Valita preview.
Lisätään seitsemän uutta saraketta, joiden pääte on lag_number avainsana kohdesarakkeeseen Volume USD.
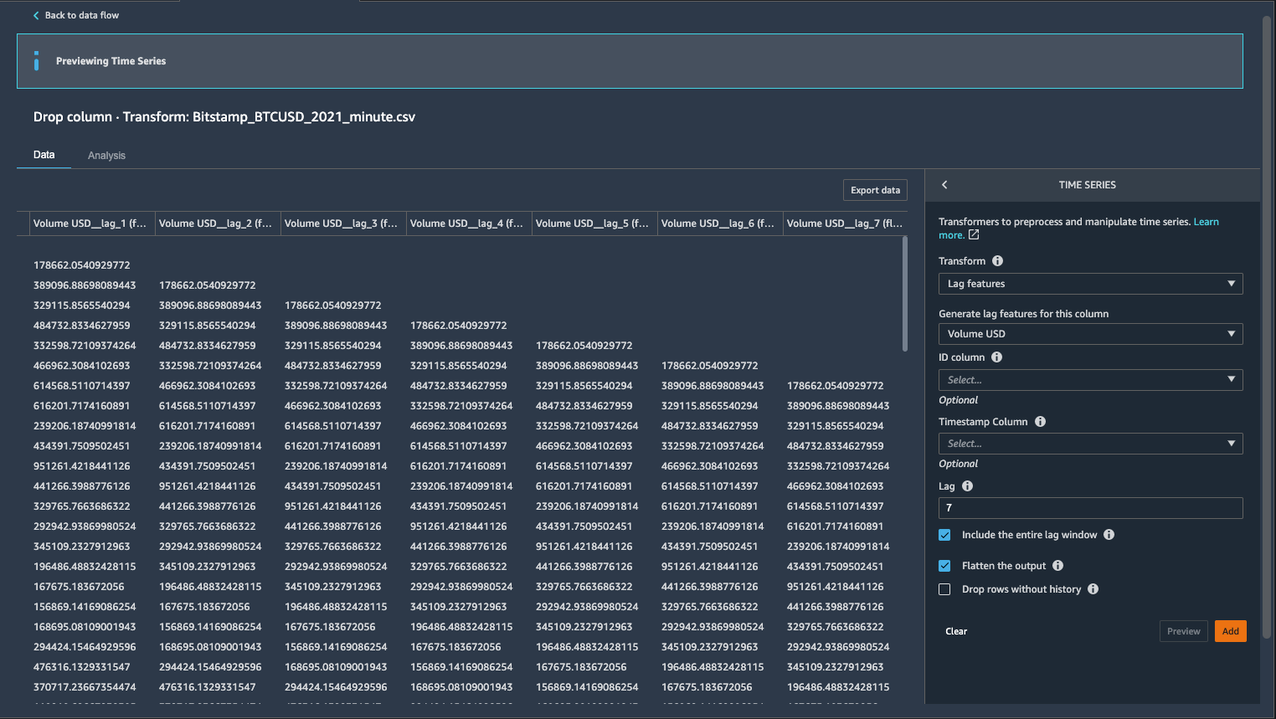
- Valita Lisää vaiheen tallentamiseksi.
Pyörivän ikkunan ominaisuudet
Voimme myös laskea merkityksellisiä tilastollisia yhteenvetoja eri arvoalueilta ja sisällyttää ne syöttöominaisuuksiksi. Poimitaanpa yleisiä tilastollisia aikasarjoja.
Data Wrangler toteuttaa automaattisen aikasarjaominaisuuksien poimintaominaisuudet avoimen lähdekoodin avulla tsfresh paketti. Aikasarjan ominaisuuspoiminnan muunnoksilla voit automatisoida ominaisuuden poimintaprosessin. Tämä eliminoi ajan ja vaivan, joka muuten kuluu signaalinkäsittelykirjastojen manuaaliseen toteuttamiseen. Tätä viestiä varten poimimme ominaisuuksia käyttämällä Pyörivän ikkunan ominaisuudet muuttaa. Tämä menetelmä laskee tilastolliset ominaisuudet ikkunan koon määrittelemien havaintojen joukosta.
- Valita + Lisää vaihe.
- Valitse Aikasarja muuttaa.
- varten Muuttaa, valitse Pyörivän ikkunan ominaisuudet.
- varten Luo rullaavan ikkunan ominaisuuksia tälle sarakkeelle, valitse Volyymi USD.
- varten Aikaleima-sarake, valitse data.
- varten Ikkunan koko, tulla sisään
7.
Ikkunan koon määrittäminen 7 laskee ominaisuudet yhdistämällä nykyisen aikaleiman arvon ja edellisen seitsemän aikaleiman arvot.
- valita litistää luodaksesi uuden sarakkeen jokaiselle laskennalliselle ominaisuudelle.
- Valitse strategiasi Minimaalinen osajoukko.
Tämä strategia poimii kahdeksan ominaisuutta, jotka ovat hyödyllisiä loppupään analyyseissä. Muita strategioita ovat mm Tehokas osajoukko, Muokattu osajoukkoja Kaikki ominaisuudet. Katso täydellinen luettelo poistettavissa olevista ominaisuuksista kohdasta Yleiskatsaus poimituista ominaisuuksista.
- Valita preview.
Näemme kahdeksan uutta saraketta, joissa on määritetty ikkunan koko 7 heidän nimissään, liitettynä tietoaineistoomme.
- Valita Lisää vaiheen tallentamiseksi.

Vie tietojoukko
Olemme muuntaneet aikasarjatietojoukon ja olemme valmiita käyttämään muunnettua tietojoukkoa ennustealgoritmin syötteenä. Viimeinen vaihe on viedä muunnettu tietojoukko Amazon S3:een. Data Wranglerissa voit valita Vie vaihe luoda automaattisesti Jupyter-muistikirjan Amazon SageMaker Processing -koodilla muunnetun tietojoukon käsittelemiseksi ja viemiseksi S3-säihöön. Koska tietojoukossamme on kuitenkin hieman yli 300 tietuetta, hyödynnämme Vie tietoja vaihtoehto Lisää muunnos näkymää viedäksesi muunnetun tietojoukon suoraan Amazon S3:een Data Wranglerista.
- Valita Vie tietoja.
- varten S3 sijainti, valitse selain ja valitse S3-kauhasi.
- Valita Vie tietoja.

Nyt kun olemme onnistuneesti muuntaneet bitcoin-tietojoukon, voimme käyttää sitä Amazonin sääennuste luoda bitcoin-ennusteita.
Puhdistaa
Jos olet lopettanut tämän käyttötapauksen, puhdista luomasi resurssit välttääksesi lisäkuluja. Data Wranglerissa voit sammuttaa taustalla olevan ilmentymän, kun se on valmis. Viitata Sammuta Data Wrangler dokumentaatiota saadaksesi lisätietoja. Vaihtoehtoisesti voit jatkaa Osa 2 tästä sarjasta käyttääksesi tätä tietojoukkoa ennustamiseen.
Yhteenveto
Tämä viesti osoitti, kuinka Data Wrangleria käytetään yksinkertaistamaan ja nopeuttamaan aikasarjaanalyysiä sen sisäänrakennettujen aikasarjaominaisuuksien avulla. Tutkimme, kuinka datatieteilijät voivat helposti ja vuorovaikutteisesti puhdistaa, muotoilla, validoida ja muuntaa aikasarjatietoja haluttuun muotoon mielekästä analysointia varten. Tutkimme myös, kuinka voit rikastuttaa aikasarja-analyysiäsi lisäämällä kattavan joukon tilastollisia ominaisuuksia Data Wranglerin avulla. Lisätietoja aikasarjamuunnoksista Data Wranglerissa on kohdassa Muuta tietoja.
kirjailijasta
 Roop Bains on AWS:n ratkaisuarkkitehti, joka keskittyy AI/ML:ään. Hän on intohimoinen auttamaan asiakkaita innovoimaan ja saavuttamaan liiketoimintatavoitteensa tekoälyn ja koneoppimisen avulla. Vapaa-ajallaan Roop pitää lukemisesta ja patikoinnista.
Roop Bains on AWS:n ratkaisuarkkitehti, joka keskittyy AI/ML:ään. Hän on intohimoinen auttamaan asiakkaita innovoimaan ja saavuttamaan liiketoimintatavoitteensa tekoälyn ja koneoppimisen avulla. Vapaa-ajallaan Roop pitää lukemisesta ja patikoinnista.
 Nikita Ivkin on soveltuva tutkija, Amazon SageMaker Data Wrangler.
Nikita Ivkin on soveltuva tutkija, Amazon SageMaker Data Wrangler.
- "
- 100
- 116
- 2021
- 7
- 9
- Meistä
- kiihdyttää
- poikki
- lisä-
- Etu
- algoritmi
- algoritmit
- Kaikki
- Amazon
- analyysi
- sovelletaan
- Hakeminen
- lähestymistapa
- huhtikuu
- noin
- keinotekoinen
- tekoäly
- Keinotekoinen älykkyys ja koneoppiminen
- saatavissa
- AWS
- perusta
- PARAS
- Bitcoin
- bitcoin kaupankäynti
- reunus
- BTC
- sisäänrakennettu
- liiketoiminta
- yritykset
- kyvyt
- tapauksissa
- maksut
- Siivous
- koodi
- Kolikko
- Sarake
- Yhteinen
- verrattuna
- monimutkainen
- komponentti
- luottamus
- Console
- sisältää
- jatkaa
- voisi
- kryptovaluutta
- valuutta
- Nykyinen
- Asiakkaat
- tiedot
- tietojenkäsittely
- tietojoukko
- päivä
- syvempää
- Kysyntä
- Detection
- DID
- eri
- ei
- verkkotunnuksen
- alas
- helposti
- Tehokas
- mahdollistaa
- insinööri
- Tekniikka
- olennainen
- arviot
- Tapahtumat
- esimerkki
- odotettu
- asiantuntemus
- otteet
- tekijät
- nopeampi
- Ominaisuus
- Ominaisuudet
- Vihdoin
- Etunimi
- Korjata
- virtaus
- jälkeen
- muoto
- lomakkeet
- koko
- tulevaisuutta
- tuottaa
- Antaminen
- hyvä
- Ryhmä
- Käsittely
- auttaa
- hyödyllinen
- auttaa
- Talo
- Miten
- Miten
- HTTPS
- tunnistaa
- Muilla
- sisältää
- Kasvaa
- indeksi
- tiedot
- oivalluksia
- Älykkyys
- IT
- tammikuu
- tunnettu
- OPPIA
- oppiminen
- Taso
- rajallinen
- Lista
- näköinen
- kone
- koneoppiminen
- Tekeminen
- maaliskuu
- ML
- malli
- mallit
- eniten
- Uudet ominaisuudet
- Melu
- muistikirja
- avata
- avoimen lähdekoodin
- avaaminen
- Vaihtoehto
- Vaihtoehdot
- Muut
- muuten
- Kuvio
- aikoja
- politiikka
- ennustus
- Ennusteet
- esittää
- estää
- preview
- hinta
- Ongelma
- prosessi
- projekti
- hankkeet
- toimittaa
- tarjoaa
- Neljännes
- nopeasti
- alue
- raaka
- Lukeminen
- kohtuullinen
- ennätys
- asiakirjat
- vähentää
- säännöllinen
- yhteys
- Ihmissuhteet
- edellyttää
- vaatimukset
- Esittelymateriaalit
- arviot
- myynti
- tiede
- Tiedemies
- tutkijat
- Sarjat
- palvelu
- setti
- sulkeminen
- samankaltainen
- Yksinkertainen
- Koko
- pieni
- So
- Ratkaisumme
- määrittely
- Alkaa
- tilastollinen
- Varastossa
- Levytila
- strategiat
- Strategia
- Onnistuneesti
- Kohde
- tekniikat
- Kautta
- aika
- kaupankäynti
- perinteinen
- Muuttaa
- Muutos
- ui
- ymmärtää
- unique
- us
- USD
- käyttää
- yleensä
- käyttää
- arvo
- Näytä
- visualisointi
- tilavuus
- viikko
- sanoja
- vuosi