Kun OpenAI julkaisi kolmannen sukupolven koneoppimismallistaan (ML), joka on erikoistunut tekstin luomiseen heinäkuussa 2020, tiesin, että jokin oli toisin. Tämä malli löi hermoja kuin kukaan sitä edeltänyt. Yhtäkkiä kuulin ystävien ja työtovereiden, jotka saattavat olla kiinnostuneita tekniikasta, mutta eivät yleensä välitä paljoakaan AI/ML-avaruuden viimeisimmistä saavutuksista, puhuvan siitä. Jopa Guardian kirjoitti artikkeli siitä. Tai tarkemmin sanottuna malli kirjoitti artikkelin ja Guardian muokkasi ja julkaisi sen. Sitä ei voinut kieltää - GPT-3 oli pelin vaihtaja.
Mallin julkaisun jälkeen ihmiset alkoivat heti keksiä sille mahdollisia sovelluksia. Viikkojen sisällä luotiin monia vaikuttavia demoja, jotka löytyvät sivustolta GPT-3 verkkosivusto. Yksi erityinen sovellus, joka pisti silmään, oli tekstin yhteenveto - tietokoneen kyky lukea tietty teksti ja tehdä yhteenveto sen sisällöstä. Se on yksi tietokoneen vaikeimmista tehtävistä, koska siinä yhdistyvät kaksi luonnollisen kielenkäsittelyn (NLP) alaa: luetun ymmärtäminen ja tekstin luominen. Siksi GPT-3-demot tekivät minuun niin vaikutuksen tekstin yhteenvetoa varten.
Voit kokeilla niitä Hugging Face Spaces -verkkosivusto. Suosikkini tällä hetkellä on an hakemus joka luo yhteenvedot uutisartikkeleista ja syöttää vain artikkelin URL-osoitteen.
Tässä kaksiosaisessa sarjassa ehdotan käytännön opasta organisaatioille, jotta voit arvioida verkkotunnuksesi tekstitiivistelmämallien laatua.
Opetusohjelman yleiskatsaus
Monilla organisaatioilla, joiden kanssa työskentelen (hyväntekeväisyysjärjestöt, yritykset, kansalaisjärjestöt), on valtava määrä tekstejä, jotka heidän on luettava ja tehtävä yhteenveto – talousraportteja tai uutisartikkeleita, tieteellisiä tutkimuksia, patenttihakemuksia, juridisia sopimuksia ja paljon muuta. Luonnollisesti nämä organisaatiot ovat kiinnostuneita näiden tehtävien automatisoinnista NLP-tekniikalla. Havainnollistaakseni mahdollisuuksien taitoa käytän usein tekstiyhteenvetodemoja, jotka eivät lähes koskaan epäonnistu.
Mutta mitä nyt?
Haasteena näille organisaatioille on se, että he haluavat arvioida tekstien yhteenvetomalleja useiden asiakirjojen yhteenvetojen perusteella – ei yksi kerrallaan. He eivät halua palkata harjoittelijaa, jonka ainoa tehtävä on avata hakemus, liittää asiakirja, painaa Yhteenveto -painiketta, odota tulostetta, arvioi, onko yhteenveto hyvä, ja tee sama uudelleen tuhansille asiakirjoille.
Kirjoitin tämän opetusohjelman neljän viikon takaista itseäni mielessäni – se on opetusohjelma, jonka toivoin saavani silloin, kun aloitin tällä matkalla. Tässä mielessä tämän tutoriaalin kohdeyleisö on joku, joka tuntee tekoälyn/ML:n ja on käyttänyt Transformer-malleja aiemmin, mutta on tekstitiivistelmämatkansa alussa ja haluaa sukeltaa siihen syvemmälle. Koska sen on kirjoittanut "aloittelija" ja se on tarkoitettu aloittelijoille, haluan korostaa sitä tosiasiaa, että tämä opetusohjelma on a käytännön opas – ei Ishayoiden opettaman käytännön opas. Ole hyvä ja kohtele sitä kuin jos George EP Box oli sanonut:
![]()
Mitä tulee siihen, kuinka paljon teknistä tietämystä tässä opetusohjelmassa vaaditaan: Se sisältää jonkin verran koodausta Pythonissa, mutta suurimman osan ajasta käytämme koodia vain API:iden kutsumiseen, joten syvällistä koodausosaamista ei myöskään tarvita. On hyödyllistä tuntea tietyt ML:n käsitteet, kuten mitä se tarkoittaa juna ja sijoittaa malli, käsitteet koulutus, validointija testitietojoukot, ja niin edelleen. Myös harrastettuaan Muuntajien kirjasto ennen saattaa olla hyödyllistä, koska käytämme tätä kirjastoa laajasti tämän opetusohjelman ajan. Lisään myös hyödyllisiä linkkejä näiden käsitteiden lisälukemista varten.
Koska tämän opetusohjelman on kirjoittanut aloittelija, en odota NLP-asiantuntijoiden ja edistyneiden syväoppimisen ammattilaisten saavan paljon osaa tästä opetusohjelmasta. Ei ainakaan teknisestä näkökulmasta – saatat silti nauttia lukemisesta, joten älä lähde vielä! Mutta sinun on oltava kärsivällinen yksinkertaistamiseni suhteen – yritin elää ajatuksen mukaan tehdä kaikesta tässä opetusohjelmassa mahdollisimman yksinkertaista, mutta en yksinkertaisempaa.
Tämän opetusohjelman rakenne
Tämä sarja ulottuu neljään kahteen postaukseen jaettuun osioon, joissa käymme läpi tekstin yhteenvetoprojektin eri vaiheita. Ensimmäisessä viestissä (osio 1) aloitamme ottamalla käyttöön mittarin tekstin yhteenvetotehtäviä varten – suorituskyvyn mittarin, jonka avulla voimme arvioida, onko yhteenveto hyvä vai huono. Esittelemme myös tietojoukon, josta haluamme tehdä yhteenvedon, ja luomme perusviivan no-ML-mallilla – käytämme yksinkertaista heuristiikkaa luodaksemme yhteenvedon tietystä tekstistä. Tämän perustason luominen on elintärkeä askel missä tahansa ML-projektissa, koska sen avulla voimme kvantifioida kuinka paljon edistymme tekoälyn avulla eteenpäin. Sen avulla voimme vastata kysymykseen "Onko todella kannattavaa investoida tekoälyteknologiaan?"
Toisessa viestissä käytämme mallia, joka on jo valmiiksi koulutettu luomaan yhteenvetoja (osio 2). Tämä on mahdollista nykyaikaisella lähestymistavalla ML:ssä nimeltä siirrä oppimista. Se on toinen hyödyllinen vaihe, koska otamme periaatteessa valmiin mallin ja testaamme sitä tietojoukossamme. Tämän avulla voimme luoda toisen perusviivan, joka auttaa meitä näkemään, mitä tapahtuu, kun todella harjoittelemme mallia tietojoukossamme. Lähestymistapa on ns nolla laukaus yhteenveto, koska malli ei ole altistunut tietojoukollemme.
Sen jälkeen on aika käyttää esikoulutettua mallia ja harjoitella sitä omalla tietojoukollamme (osio 3). Tätä kutsutaan myös hienosäätö. Sen avulla malli voi oppia datamme malleista ja omituisuuksista ja mukautua siihen hitaasti. Kun olemme kouluttaneet mallin, käytämme sitä tiivistelmien luomiseen (osio 4).
Yhteenvetona:
- Osa 1:
- Osa 1: Käytä no-ML-mallia perustaaksesi
- Osa 2:
- Osa 2: Luo yhteenvedot nollakuvan mallilla
- Osa 3: Harjoittele yhteenvetomalli
- Osa 4: Arvioi koulutettu malli
Tämän opetusohjelman koko koodi on saatavilla seuraavassa GitHub repo.
Mitä olemme saavuttaneet tämän opetusohjelman loppuun mennessä?
Tämän opetusohjelman loppuun mennessä me eivät on tekstin yhteenvetomalli, jota voidaan käyttää tuotannossa. Meillä ei ole edes a hyvä yhteenvetomalli (lisää scream emoji tähän)!
Sen sijaan meillä on lähtökohta projektin seuraavalle vaiheelle, joka on kokeiluvaihe. Tässä tulee esiin datatieteen "tiede", koska nyt on kyse eri mallien ja asetusten kokeilemisesta, jotta ymmärretään, voidaanko käytettävissä olevalla harjoitusdatalla kouluttaa riittävän hyvää yhteenvetomallia.
Ja ollakseni täysin läpinäkyvä, on hyvä mahdollisuus, että johtopäätös on, että tekniikka ei vain ole vielä kypsä ja että hanketta ei toteuteta. Ja sinun on valmisteltava liiketoimintasi sidosryhmät tähän mahdollisuuteen. Mutta se on toisen postauksen aihe.
Osa 1: Käytä no-ML-mallia perustaaksesi
Tämä on tekstin yhteenvetoprojektin perustamista käsittelevän opetusohjelman ensimmäinen osa. Tässä osiossa määritämme perusviivan käyttämällä hyvin yksinkertaista mallia käyttämättä ML:ää. Tämä on erittäin tärkeä askel missä tahansa ML-projektissa, koska sen avulla voimme ymmärtää, kuinka paljon arvoa ML lisää projektin aikana ja kannattaako siihen investoida.
Tutoriaalin koodi löytyy seuraavasta GitHub repo.
Tiedot, tiedot, tiedot
Jokainen ML-projekti alkaa datasta! Mikäli mahdollista, tulee aina käyttää dataa, joka liittyy siihen, mitä tekstin yhteenvetoprojektilla haluamme saavuttaa. Esimerkiksi, jos tavoitteenamme on tehdä yhteenveto patenttihakemuksista, meidän tulisi myös käyttää patenttihakemuksia mallin kouluttamiseen. Suuri varoitus ML-projektille on, että harjoitustiedot on yleensä merkittävä. Tekstin yhteenvedon yhteydessä tämä tarkoittaa, että meidän on annettava tiivistettävä teksti sekä tiivistelmä (etiketti). Vain tarjoamalla molemmat mallit voivat oppia, miltä hyvä yhteenveto näyttää.
Tässä opetusohjelmassa käytämme julkisesti saatavilla olevaa tietojoukkoa, mutta vaiheet ja koodi pysyvät täsmälleen samoina, jos käytämme mukautettua tai yksityistä tietojoukkoa. Ja vielä kerran, jos sinulla on tavoite tekstin yhteenvetomallillesi ja sinulla on vastaavaa tietoa, käytä sen sijaan tietojasi saadaksesi kaiken irti tästä.
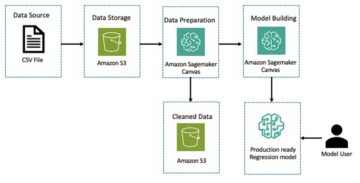
Käyttämämme data on arXiv-tietojoukko, joka sisältää tiivistelmiä arXiv-papereista sekä niiden otsikot. Käytämme tarkoituksessamme abstraktia tekstinä, jonka haluamme tiivistää, ja otsikkoa viitetiivistelmänä. Kaikki tietojen lataamisen ja esikäsittelyn vaiheet ovat saatavilla seuraavassa muistikirja. Vaadimme an AWS-henkilöllisyyden ja käyttöoikeuksien hallinta (IAM) -rooli, joka mahdollistaa tietojen lataamisen sisään ja sieltä Amazonin yksinkertainen tallennuspalvelu (Amazon S3) käyttääksesi tätä muistikirjaa onnistuneesti. Aineisto kehitettiin osana paperia ArXivin käytöstä tietojoukona ja on lisensoitu Creative Commons CC0 1.0 Universal Public Domain Dedication.
Tiedot on jaettu kolmeen tietojoukkoon: koulutus-, validointi- ja testitiedot. Jos haluat käyttää omia tietojasi, varmista, että näin on myös. Seuraava kaavio havainnollistaa, kuinka käytämme erilaisia tietojoukkoja.
![]()
Luonnollisesti yleinen kysymys tässä vaiheessa on: Kuinka paljon tietoa tarvitsemme? Kuten luultavasti jo arvaatte, vastaus on: se riippuu. Se riippuu siitä, kuinka erikoistunut toimialue on (patenttihakemusten yhteenveto on aivan eri asia kuin uutisartikkelien yhteenveto), kuinka tarkka mallin tulee olla hyödyllinen, kuinka paljon mallin koulutuksen tulisi maksaa ja niin edelleen. Palaamme tähän kysymykseen myöhemmin, kun harjoittelemme mallia, mutta sen lyhyt puoli on, että meidän on kokeiltava erilaisia datakokoja, kun olemme projektin kokeiluvaiheessa.
Mikä tekee hyvän mallin?
Monissa ML-projekteissa mallin suorituskyvyn mittaaminen on melko yksinkertaista. Tämä johtuu siitä, että mallin tulosten oikeellisuus on yleensä vähän epäselvää. Tietojoukon tunnisteet ovat usein binaarisia (tosi/epätosi, kyllä/ei) tai kategorisia. Joka tapauksessa tässä skenaariossa on helppoa verrata mallin tulosta tarraan ja merkitä se oikeaksi tai vääräksi.
Tekstiä luotaessa tämä muuttuu haastavammaksi. Tietojoukossamme tarjoamamme yhteenvedot (tunnisteet) ovat vain yksi tapa tehdä yhteenveto tekstistä. Mutta on monia mahdollisuuksia tehdä yhteenveto tietystä tekstistä. Joten vaikka malli ei vastaisi etikettiämme suhteessa 1:1, tulos saattaa silti olla kelvollinen ja hyödyllinen yhteenveto. Joten miten voimme verrata mallin yhteenvetoa tarjoamaamme yhteenvetoon? Useimmiten mallin laadun mittaamisessa tekstiyhteenvedossa käytetty mittari on ROUGE-pisteet. Jos haluat ymmärtää tämän mittarin mekaniikkaa, katso Ultimate Performance Metric NLP:ssä. Yhteenvetona ROUGE-pistemäärä mittaa päällekkäisyyttä n-grammaa (jatkuva sekvenssi n kohdat) mallin yhteenvedon (kandidaattiyhteenvedon) ja viiteyhteenvedon (tietojoukossamme tarjoamamme tunniste) välillä. Mutta tämä ei tietenkään ole täydellinen toimenpide. Jos haluat ymmärtää sen rajoitukset, tarkista ROUGE:lle vai ei ROUGElle?
Joten miten laskemme ROUGE-pisteet? Tämän mittarin laskemiseen on olemassa useita Python-paketteja. Johdonmukaisuuden varmistamiseksi meidän tulisi käyttää samaa menetelmää koko projektissamme. Koska käytämme tämän opetusohjelman myöhemmässä vaiheessa Transformers-kirjaston harjoitusskriptiä oman kirjoittamisen sijaan, voimme vain kurkistaa lähdekoodi komentosarjasta ja kopioi koodi, joka laskee ROUGE-pisteet:
Käyttämällä tätä menetelmää pistemäärän laskemiseen varmistamme, että vertaamme aina omenoita omenoihin koko projektin ajan.
Tämä funktio laskee useita ROUGE-pisteitä: rouge1, rouge2, rougeLja rougeLsum. "Summa" sisään rougeLsum viittaa siihen, että tämä mittari lasketaan koko yhteenvedon perusteella, kun taas rougeL lasketaan yksittäisten lauseiden keskiarvona. Joten mitä ROUGE-pisteitä meidän pitäisi käyttää projektissamme? Jälleen meidän on kokeiltava erilaisia lähestymistapoja kokeiluvaiheessa. Minkä arvoinen se on, alkuperäinen ROUGE-paperi toteaa, että "ROUGE-2 ja ROUGE-L toimivat hyvin yksittäisen asiakirjan yhteenvetotehtävissä", kun taas "ROUGE-1 ja ROUGE-L suoriutuvat erinomaisesti lyhyiden yhteenvetojen arvioinnissa."
Luo perusviiva
Seuraavaksi haluamme luoda perusviivan käyttämällä yksinkertaista, ei-ML-mallia. Mitä tuo tarkoittaa? Tekstin yhteenvedon alalla monet tutkimukset käyttävät hyvin yksinkertaista lähestymistapaa: ne ottavat ensimmäisen n tekstin lauseita ja julistaa se ehdokastiivistelmäksi. Sitten he vertaavat ehdokasyhteenvetoa vertailuyhteenvetoon ja laskevat ROUGE-pistemäärän. Tämä on yksinkertainen mutta tehokas lähestymistapa, jonka voimme toteuttaa muutamalla koodirivillä (koko koodi tälle osalle on seuraavassa muistikirja):
Käytämme tähän arviointiin testiaineistoa. Tämä on järkevää, koska mallin harjoittamisen jälkeen käytämme samaa testiaineistoa myös lopullisessa arvioinnissa. Kokeilemme myös erilaisia numeroita n: aloitamme vain ensimmäisestä virkkeestä ehdokastiivistelmänä, sitten kahdesta ensimmäisestä virkkeestä ja lopuksi kolmesta ensimmäisestä virkkeestä.
Seuraava kuvakaappaus näyttää ensimmäisen mallimme tulokset.
![]()
ROUGE-pisteet ovat korkeimmat, ja vain ensimmäinen virke on ehdokkaan yhteenveto. Tämä tarkoittaa, että useamman kuin yhden lauseen ottaminen tekee yhteenvedosta liian monisanaisen ja johtaa alhaisempaan pisteeseen. Tämä tarkoittaa, että käytämme yhden lauseen yhteenvetojen pisteitä lähtökohtanamme.
On tärkeää huomata, että tällaisessa yksinkertaisessa lähestymistavassa nämä luvut ovat itse asiassa melko hyviä, etenkin rouge1 pisteet. Voimme viitata näiden numeroiden kontekstiin Pegasus-mallit, joka näyttää huippuluokan mallin pisteet eri tietojoukoille.
Johtopäätös ja mitä seuraavaksi
Sarjamme osassa 1 esittelimme tietojoukon, jota käytämme koko yhteenvetoprojektissa, sekä mittarin yhteenvetojen arvioimiseen. Sitten loimme seuraavan perusviivan yksinkertaisella, ei-ML-mallilla.
![]()
In Seuraava viesti, käytämme zero-shot -mallia – erityisesti mallia, joka on erityisesti koulutettu tekemään yhteenvetoja julkisista uutisartikkeleista. Tätä mallia ei kuitenkaan opeteta lainkaan tietojoukossamme (tästä syystä nimi "zero-shot").
Jätän kotitehtävänäsi arvailla, kuinka tämä nollakuva-malli toimii verrattuna hyvin yksinkertaiseen perusviivaamme. Toisaalta se on paljon kehittyneempi malli (se on itse asiassa hermoverkko). Toisaalta sitä käytetään vain yhteenvedon tekemiseen uutisartikkeleista, joten se saattaa kamppailla arXiv-tietojoukolle luontaisten mallien kanssa.
kirjailijasta
![]() Heiko Hotz on tekoälyn ja koneoppimisen vanhempi ratkaisuarkkitehti ja johtaa Natural Language Processing (NLP) -yhteisöä AWS:ssä. Ennen tätä tehtävää hän toimi Amazonin EU-asiakaspalvelun datatieteen johtajana. Heiko auttaa asiakkaitamme menestymään AI/ML-matkallaan AWS:ssä ja on työskennellyt organisaatioiden kanssa monilla toimialoilla, mukaan lukien vakuutus-, rahoitus-, media- ja viihde-, terveydenhuolto-, yleishyödylliset ja tuotantolaitokset. Vapaa-ajallaan Heiko matkustaa niin paljon kuin mahdollista.
Heiko Hotz on tekoälyn ja koneoppimisen vanhempi ratkaisuarkkitehti ja johtaa Natural Language Processing (NLP) -yhteisöä AWS:ssä. Ennen tätä tehtävää hän toimi Amazonin EU-asiakaspalvelun datatieteen johtajana. Heiko auttaa asiakkaitamme menestymään AI/ML-matkallaan AWS:ssä ja on työskennellyt organisaatioiden kanssa monilla toimialoilla, mukaan lukien vakuutus-, rahoitus-, media- ja viihde-, terveydenhuolto-, yleishyödylliset ja tuotantolaitokset. Vapaa-ajallaan Heiko matkustaa niin paljon kuin mahdollista.
- Coinsmart. Euroopan paras Bitcoin- ja kryptopörssi.
- Platoblockchain. Web3 Metaverse Intelligence. Tietoa laajennettu. VAPAA PÄÄSY.
- CryptoHawk. Altcoinin tutka. Ilmainen kokeilu.
- Lähde: https://aws.amazon.com/blogs/machine-learning/part-1-set-up-a-text-summarization-project-with-hugging-face-transformers/
- '
- "
- &
- 100
- 2020
- Meistä
- TIIVISTELMÄ
- pääsy
- tarkka
- saavutettu
- kehittynyt
- edistysaskeleet
- AI
- Kaikki
- jo
- Amazon
- epäselvyys
- määrät
- Toinen
- API
- Hakemus
- sovellukset
- lähestymistapa
- noin
- Art
- artikkeli
- artikkelit
- yleisö
- saatavissa
- keskimäärin
- AWS
- Lähtötilanne
- Pohjimmiltaan
- Alku
- ovat
- liiketoiminta
- soittaa
- joka
- kiinni
- haaste
- koodi
- Koodaus
- Yhteinen
- yhteisö
- Yritykset
- verrattuna
- täysin
- Laskea
- käsite
- sisältää
- pitoisuus
- sopimukset
- Luominen
- asiakassuhde
- Asiakaspalvelu
- Asiakkaat
- tiedot
- tietojenkäsittely
- syvempää
- kehitetty
- eri
- asiakirjat
- ei
- verkkotunnuksen
- Viihde
- erityisesti
- perustaa
- EU
- kaikki
- esimerkki
- odottaa
- asiantuntijat
- silmä
- Kasvot
- Fields
- Vihdoin
- taloudellinen
- rahoituspalvelut
- Etunimi
- jälkeen
- Eteenpäin
- löytyi
- toiminto
- edelleen
- peli
- tuottaa
- sukupolvi
- tavoite
- menee
- hyvä
- suuri
- holhooja
- ohjaavat
- ottaa
- pää
- terveydenhuollon
- hyödyllinen
- auttaa
- tätä
- vuokraus
- Miten
- HTTPS
- valtava
- Identiteetti
- toteuttaa
- täytäntöön
- tärkeä
- sisältää
- Mukaan lukien
- henkilökohtainen
- teollisuuden
- vakuutus
- käyttöön
- investoimalla
- IT
- Job
- heinäkuu
- avain
- tuntemus
- tarrat
- Kieli
- uusin
- Liidit
- OPPIA
- oppiminen
- jättää
- juridinen
- Kirjasto
- Licensed
- linkit
- vähän
- kone
- koneoppiminen
- TEE
- Tekeminen
- valmistus
- Merkitse
- ottelu
- mitata
- Media
- mielessä
- ML
- malli
- mallit
- lisää
- eniten
- Luonnollinen
- verkko
- uutiset
- muistikirja
- numerot
- avata
- tilata
- organisaatioiden
- Muut
- Paperi
- patentti-
- Ihmiset
- suorituskyky
- näkökulma
- vaihe
- Kohta
- mahdollisuuksia
- mahdollisuus
- mahdollinen
- Viestejä
- mahdollinen
- voimakas
- yksityinen
- tuotanto
- projekti
- hankkeet
- ehdottaa
- toimittaa
- tarjoamalla
- julkinen
- tarkoitus
- laatu
- kysymys
- alue
- RE
- Lukeminen
- Raportit
- edellyttää
- tarvitaan
- tutkimus
- tulokset
- ajaa
- Said
- tiede
- tunne
- Sarjat
- palvelu
- Palvelut
- setti
- asetus
- Lyhyt
- Yksinkertainen
- So
- Ratkaisumme
- Joku
- jotain
- hienostunut
- Tila
- tilat
- erikoistunut
- erikoistunut
- erityisesti
- jakaa
- Alkaa
- alkoi
- alkaa
- huippu-
- Valtiot
- Levytila
- stressi
- opinnot
- onnistunut
- Onnistuneesti
- Puhua
- Kohde
- tehtävät
- Tekninen
- Elektroniikka
- testi
- tuhansia
- Kautta
- kauttaaltaan
- aika
- Otsikko
- koulutus
- läpinäkyvä
- kohdella
- lopullinen
- ymmärtää
- Yleismaailmallinen
- us
- käyttää
- yleensä
- arvo
- odottaa
- Mitä
- onko
- KUKA
- wikipedia
- sisällä
- ilman
- Referenssit
- työskenteli
- arvoinen
- kirjoittaminen
- X
- nolla-