Dernière mise à jour: janvier 2021.
Ce blog est un aperçu complet de l'utilisation de l'OCR avec n'importe quel outil RPA pour automatiser vos flux de travail de documents. Nous explorons comment les dernières technologies OCR basées sur l'apprentissage automatique ne nécessitent pas de règles ou de configuration de modèle.

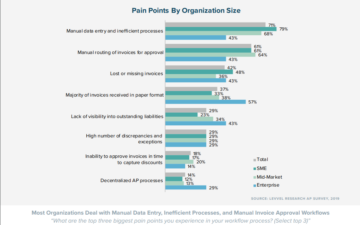
Les RPA ou l'automatisation des processus robotiques sont des outils logiciels visant à éliminer les tâches commerciales répétitives. De plus en plus de DSI se tournent vers eux pour réduire les coûts et aider les employés à se concentrer sur un travail commercial à plus haute valeur. Les exemples incluent la réponse aux commentaires sur les sites Web ou le traitement des commandes des clients. Les tâches légèrement plus complexes incluent la gestion de documents tels que formes manuscrites ainsi que factures – ceux-ci doivent généralement être déplacés d'un système existant à l'autre – disons votre client de messagerie à votre système SAP ERP où vous devez extraire des données. C'est la partie problématique.
La plupart des outils OCR qui capturent les données de ces documents sont basés sur des modèles (par exemple Abbyy Flexicapture) et ne s'adaptent pas bien aux documents semi-structurés. Il existe des solutions basées sur l'apprentissage automatique de nouvelle génération qui fournissent généralement des API
intégrations qui peuvent capturer des paires clé-valeur à partir de documents - les systèmes d'entreprise sont généralement hérités et ne peuvent pas être intégrés à des API externes. De l'autre côté, les RPA sont conçus pour gérer ces flux de travail système hérités, tels que l'ingestion de documents à partir de dossiers et la saisie des résultats dans des ERP ou des CRM.
Alors que l'automatisation des processus robotiques (RPA) et le ML évoluent vers une hyper-automatisation, nous pouvons utiliser des bots logiciels en conjonction avec le ML pour gérer des tâches complexes telles que la classification de documents, l'extraction et la reconnaissance optique de caractères. Dans une étude récente, il a été dit qu'en automatisant seulement 29% des fonctions d'une tâche à l'aide de RPA, les services financiers économisent à eux seuls plus de 25,000 heures de retouches causées par des erreurs humaines au coût de 878,000 USD par an pour une organisation de 40 personnel comptable du temps [1]. Dans ce blog, nous allons apprendre à utiliser les OCR avec les RPA et approfondir les flux de travail de compréhension de documents. Voici la table des matières.
Définitions et aperçu
La RPA, en général, est une technologie qui permet d'automatiser les tâches administratives via des robots logiciels-matériels. Ces robots tirent parti des interfaces utilisateur ; pour capturer les données et manipuler les applications comme le font les humains. Par exemple, une RPA peut examiner une série de tâches effectuées dans une interface graphique, par exemple déplacer des curseurs, se connecter à des API, copier-coller les données et formuler la même séquence d'actions dans une structure filaire RPA qui se traduit en code. De plus, ces tâches peuvent être effectuées sans intervention humaine à l'avenir. La reconnaissance optique de caractères (OCR) est une caractéristique cruciale de toute solution d'automatisation des processus robotiques (RPA) fonctionnelle. Cette technologie est utilisée pour lire et extraire du texte de différentes sources comme des images ou pdfs dans un format numérique sans le capturer manuellement.
D'autre part, la compréhension de document est le terme utilisé pour décrire automatiquement la lecture, l'interprétation et l'action sur les données du document. Le plus important dans ce processus est que les robots logiciels effectuent eux-mêmes toutes les tâches. Ces robots exploitent la puissance de l'intelligence artificielle et de l'apprentissage automatique pour comprendre les documents comme des assistants numériques. De cette façon, nous pouvons dire que la compréhension des documents émerge à l'intersection du traitement des documents, de l'IA et de la RPA.

Comment les robots peuvent apprendre à comprendre les documents avec OCR et ML
Avant de nous plonger dans la compréhension des documents, parlons du rôle des robots pour la compréhension des documents. Ces aides totalement invisibles rendent notre vie beaucoup plus confortable. Contrairement aux films et aux séries, ces robots ne sont pas des appareils physiques ou des programmes d'intelligence artificielle placés sur un bureau et des boutons poussoirs pour effectuer des tâches. Nous pouvons les considérer comme des assistants numériques formés pour traiter des documents en lisant et en utilisant des applications comme nous le faisons. Sur le plan fonctionnel, les robots sont efficaces pour améliorer les performances et l'efficacité d'un processus. Pourtant, étant un logiciel autonome, ne peut pas évaluer le processus et prendre des décisions cognitives. Cependant, si l'apprentissage automatique est intégré avec succès, la robotique deviendra plus dynamique et adaptative. Par exemple, les robots utilisés pour le traitement des documents, la gestion des données et d'autres fonctions dans le front et le middle office effectueront des actions plus intelligentes, telles que l'élimination des entrées en double ou la résolution d'exceptions système inconnues dans le processus. De plus, les robots sont formés pour lire, extraire, interpréter et agir sur les données des documents à l'aide de l'intelligence artificielle (IA).
Comment les entreprises peuvent-elles intégrer l'OCR intelligent à la RPA pour améliorer les flux de travail?
L'extraction des données documentaires est un élément crucial pour la compréhension des documents. Dans cette section, nous discuterons de la façon dont nous pouvons intégrer l'OCR avec RPA ou vice-versa. Premièrement, nous savions tous qu'il existe différents types de documents en termes de modèles, de style, de formatage et parfois de langue. Par conséquent, nous ne pouvons pas nous fier à une technique OCR simple pour extraire les données de ces documents. Pour résoudre ce problème, nous utiliserons à la fois des approches basées sur des règles et des approches basées sur des modèles dans l'OCR pour gérer les données de différentes structures de document. Nous allons maintenant voir comment les entreprises faisant de l'OCR peuvent intégrer les RPA dans leur système existant en fonction du type de documents.
Documents structurés: Dans ce type de documents, les mises en page et les modèles sont généralement fixes et presque cohérents. Par exemple, considérons une organisation qui fait du KYC avec des pièces d'identité émises par le gouvernement comme un passeport ou un permis de conduire. Tous ces documents seront identiques et auront les mêmes champs que le numéro d'identification, le nom de la personne, l'âge et quelques autres aux mêmes positions. Mais seuls les détails varient. Il peut y avoir peu de contraintes telles que le débordement de table ou les données non classées.
En général, l'approche recommandée utilise un modèle ou un moteur basé sur des règles pour extraire les informations des documents structurés. Ceux-ci peuvent inclure des expressions régulières ou un simple mappage de position et OCR. Par conséquent, pour intégrer des robots logiciels pour automatiser l'extraction d'informations, nous pouvons soit utiliser des modèles préexistants, soit créer des règles pour nos données structurées. L'approche basée sur des règles présente un inconvénient, car elle repose sur des parties fixes, même des modifications mineures de la structure du formulaire peuvent entraîner la rupture des règles.
Documents semi-structurés: Ces documents ont les mêmes informations mais sont disposés dans des positions différentes. Par exemple, considérez factures contenant 8 à 12 champs identiques. Dans quelques factures, l'adresse du commerçant peut être située en haut, et dans d'autres, elle peut être trouvée en bas. Généralement, ces approches basées sur des règles ne donnent pas des précisions élevées ; par conséquent, nous intégrons des modèles d'apprentissage automatique et d'apprentissage en profondeur pour l'extraction d'informations à l'aide de la ROC. Alternativement, dans certains cas, nous pouvons utiliser des modèles hybrides impliquant à la fois des règles et des modèles ML. Quelques modèles pré-entraînés populaires sont FastRCNN, Attention OCR, Graph Convolutions pour l'extraction d'informations dans les documents. Cependant, encore une fois, ces modèles présentent peu d'inconvénients ; par conséquent, nous mesurons les performances de l'algorithme à l'aide de métriques telles que la précision ou le score de confiance. Parce que le modèle apprend des modèles, plutôt que d'opérer à partir de règles concrètes, il peut faire des erreurs au début juste après les corrections. Cependant, la solution à ces inconvénients - plus le modèle ML traite d'échantillons, plus il apprend de modèles pour garantir la précision.
Documents non structurés: RPA, aujourd'hui, est incapable de gérer directement les données non structurées, ce qui oblige les robots à extraire et à créer des données structurées à l'aide de l'OCR. Contrairement aux documents structurés et semi-structurés, les données non structurées n'ont pas quelques paires clé-valeur. Par exemple, dans quelques factures, nous voyons une adresse marchande quelque part sans aucun nom de clé ; de même, nous observons la même chose pour d'autres champs comme la date, l'identifiant de la facture. Pour que les modèles ML les traitent avec précision, les robots doivent apprendre à traduire le texte écrit en données exploitables, comme un e-mail, un numéro de téléphone, une adresse, etc. Le modèle apprendra alors que les modèles de nombres à 7 ou 10 chiffres doivent être extraits. sous forme de numéros de téléphone et de texte énorme contenant des codes à cinq chiffres et des noms différents sous forme de texte. Pour rendre ces modèles plus précis, nous pouvons également utiliser des techniques de traitement du langage naturel (NLP) telles que la reconnaissance d'entités nommées et l'intégration de mots.
Dans l'ensemble, pour la compréhension des documents, il est d'abord essentiel de comprendre les données, puis de mettre en œuvre l'OCR avec les RPA. Ensuite, plutôt que de cartographier un processus étape par étape, nous pouvons apprendre à un robot à «faire ce que je fais» en enregistrant le processus tel qu'il se passe avec de puissantes capacités OCR comme indiqué ci-dessus, en intégrant des règles et des algorithmes d'apprentissage automatique. Le robot logiciel suit vos clics et vos actions à l'écran, puis les transforme en un flux de travail modifiable. Si vous travaillez entièrement dans des programmes locaux, c'est tout ce que vous devez savoir.
Défis OCR rencontrés par les développeurs RPA
Nous avons vu comment nous pouvons intégrer l'OCRR aux RPA pour différents documents, mais il existe quelques cas de défis où les robots doivent bien gérer. Discutons-en maintenant!
- Données faibles ou incohérentes: Les données jouent un rôle crucial dans la compréhension des documents. Dans la plupart des cas, les documents sont numérisés à l'aide d'appareils photo où il y a un risque de perdre le formatage du document pendant la numérisation de texte (c'est-à-dire que le gras, l'italique et le souligné ne sont pas toujours reconnus). Parfois, l'OCR peut extraire le texte de la mauvaise manière, ce qui entraîne des fautes d'orthographe, des sauts de paragraphe irréguliers, ce qui réduit les performances globales des robots. Par conséquent, la gestion de toutes les valeurs manquantes et la capture des données avec une plus grande précision sont essentielles pour obtenir une précision plus élevée pour l'OCR.
- Orientation de page incorrecte dans les documents: L'orientation et l'inclinaison de la page sont également l'un des problèmes courants qui conduisent à une correction incorrecte du texte de l'OCR. Cela se produit généralement lorsque les documents ne sont pas correctement numérisés pendant la phase de collecte de données. Pour surmonter cela, nous devrons déclarer quelques fonctions aux robots comme l'ajustement automatique à la page, le filtre automatique afin qu'ils puissent activer l'augmentation de la qualité du document numérisé et recevoir des données correctes en sortie.
- Problèmes d'intégration: Tous les outils RPA ne fonctionnent pas bien sur les environnements de bureau à distance - ils provoquent des pannes et des problèmes critiques d'automatisation. De plus, le développeur RPA doit savoir quelle solution OCR sera la meilleure pour un cas spécifique. En outre, pour travailler avec des outils d'automatisation spécifiques, le développeur RPA doit choisir uniquement la technologie OCR limitée créée par Microsoft, Google. Par conséquent, l'intégration de nos algorithmes et modèles personnalisés est parfois difficile.
- Tout le texte est du texte brouillé: Pour les cas d'utilisation réels, le texte capturé par un OCR générique est entièrement brouillé et ne contient aucune information significative que les robots peuvent utiliser pour effectuer des opérations importantes. Les développeurs RPA ont besoin d'un support ML solide pour pouvoir créer des applications utiles.
Pipeline pour le flux de travail de compréhension des documents
Dans les sections précédentes, nous avons vu comment les bots aident à effectuer l'OCR pour différents types de documents. Mais l'OCR n'est qu'une technique qui convertit des images ou d'autres fichiers en texte. Maintenant, dans cette section, nous allons examiner le flux de travail Compréhension des documents dès le début de la collecte de documents pour enfin les enregistrer des informations significatives dans le format souhaité.

- Ingérer le document à partir d'un dossier à l'aide de votre Bot: Il s'agit de la première étape de la compréhension des documents via des bots. Ici, nous allons récupérer le document situé soit sur une plate-forme cloud (à l'aide d'une API), soit sur une machine locale. Dans quelques cas, si nos documents sont sur des pages Web, nous pouvons automatiser les scripts de scraping via des robots où ils peuvent récupérer les documents en temps opportun.
- Type de document: Après avoir récupéré les données, il est essentiel de comprendre le type de document et le format avec lequel ils sont enregistrés dans nos systèmes, car parfois, nous recevons des données de différentes sources dans divers formats de fichiers tels que PDF, PNG et JPG. Non seulement les types de fichiers, parfois lorsque les documents sont numérisés avec des caméras de téléphone, quelques problèmes difficiles tels que l'asymétrie de l'image, la rotation, la luminosité ou la basse résolution doivent également être traités. Ainsi, nous devrons nous assurer que les robots classent ces documents dans la catégorie structurée, semi-structurée ou non structurée, les enregistrant ainsi dans un format générique. La tâche de classification est réalisée en comparant les documents avec des modèles et en analysant des fonctionnalités telles que les polices, la langue, la présence de paires clé-valeur, les tableaux, etc.
- Extraction des données avec OCR: D'accord, maintenant que les robots ont organisé nos documents dans un format générique et les ont classés, il est temps pour nous de les numériser en utilisant la technique OCR. Avec cela, nous aurons le texte, son emplacement en co-coordonnées à partir des images. Cela permet de standardiser les documents et les données pour les étapes suivantes. Nous en rencontrons également quelques-uns lorsque le logiciel OCR ne pouvait pas distinguer correctement les caractères, tels que «t» contre «i» ou «0» contre «O». Les erreurs mêmes que vous souhaitez éviter à l'aide du logiciel OCR peuvent devenir de nouveaux casse-tête lorsque la technologie OCR est incapable d'analyser les nuances d'un document en fonction de sa qualité ou de sa forme originale. C'est là qu'intervient le Machine Learning, dont nous parlerons à l'étape suivante.
- Tirer parti de ML / DL pour l'OCR intelligent à l'aide de bots: Une fois les données numérisées, le logiciel OCR doit comprendre le type de document avec lequel il travaille et ce qui est pertinent. Mais le logiciel OCR traditionnel peut avoir du mal à faire évoluer les efforts de classification des documents. Par conséquent, les robots logiciels doivent être formés avec des capacités cognitives en tirant parti des techniques d'apprentissage automatique et d'apprentissage en profondeur pour rendre les OCR plus intelligents. Les solutions OCR basées sur le ML peuvent identifier un type de document et le comparer à un type de document connu utilisé par votre entreprise. Ils peuvent également analyser et comprendre des blocs de texte dans des documents non structurés. Une fois que la solution en sait plus sur le document lui-même, elle peut commencer à extraire des informations pertinentes en fonction de l'intention et de la signification.
- Meilleure extraction et classification des données: L'extraction de données est au cœur de la compréhension des documents. Comme indiqué dans la section précédente sur l'intégration des RPA avec l'OCR dans cette étape, optez pour la technique d'extraction de données en fonction du type de document. Grâce aux RPA, nous pouvons facilement configurer l'extracteur à utiliser, qu'il s'agisse d'une technique OCR basée sur des règles ou basée sur le ML ou sur un modèle hybride. Sur la base des mesures de confiance et de performance renvoyées après l'extraction des informations, les robots logiciels les enregistreront dans le format souhaité pour une analyse plus approfondie. Vous trouverez ci-dessous une image de la façon dont nous pouvons configurer les extracteurs et définir le niveau de confiance dans un outil RPA par UIPath.

6. Validation et renforcement des connaissances: Les modèles OCR et Machine Learning ne sont pas précis à cent pour cent en termes d'extraction d'informations, donc l'ajout d'une couche d'intervention humaine à l'aide de robots peut résoudre le problème. La façon dont cette validation fonctionne est que chaque fois que les robots traitent avec une faible précision et des exceptions, elle soulève immédiatement une notification au centre d'action où un employé peut recevoir une demande de validation des données ou de gérer des exceptions et peut résoudre les incertitudes en quelques clics. De plus, nous pouvons libérer le potentiel de l'intelligence artificielle pour documenter les données au fil du temps pour faire des prédictions et identifier les anomalies potentielles qui peuvent indiquer une fraude, une duplication et d'autres erreurs.
Avantages de l'intégration des robots avec la compréhension des documents
- Automatiser le processus: L'intégration de bots pour la compréhension des documents a pour principale raison d'automatiser l'ensemble du processus du début à la fin. Tout ce que nous devons faire est de créer un flux de travail pour que les robots apprennent, s'asseyent et se détendent. Au cours du processus de validation, nous pourrions avoir besoin de résoudre les problèmes signalés par les bots lorsque des erreurs ou des fraudes sont identifiées.
- Bots avec Machine Learning: Pendant le processus d'automatisation, nous pouvons rendre les bots résilients à l'apprentissage automatique. Cela signifie que les robots peuvent également apprendre les performances des modèles d'apprentissage automatique et ainsi améliorer les modèles pour obtenir une précision et des performances plus élevées pour l'extraction de texte et d'informations des documents.
- Processus large gamme de traitement de documents: Pour les tâches générales telles que l'extraction de tables et d'informations, nous devrons créer différents pipelines d'apprentissage en profondeur pour différents types de documents. Cela conduit à créer plusieurs applications et à déployer divers modèles sur différents serveurs, ce qui nécessite beaucoup d'efforts et de temps. Lorsque les bots sont dans l'image pour un large éventail de documents, nous ne pourrions avoir qu'un seul pipeline dans lequel les bots peuvent les classer et ensuite utiliser le modèle approprié pour différentes tâches. Nous pouvons également intégrer divers services via des API et communiquer avec d'autres organisations en termes de récupération des données.
- Facile à déployer: Pour la compréhension des documents après la création des pipelines, le processus de déploiement ne prend qu'une minute. Nous pouvons soit faire exporter des API par des bots après la formation, soit créer une solution RPA personnalisée qui peut être utilisée dans nos systèmes locaux. Ce type de déploiement peut également optimiser les entreprises et réduire les dépenses avec des risques très minimes.
Entrez Nanonets
NanoNets est une plate-forme d'apprentissage automatique qui permet aux utilisateurs de capturer des données à partir de factures, reçus et autres documents sans configuration de modèle. Nous avons à l'arrière des algorithmes d'apprentissage en profondeur et de vision par ordinateur de pointe qui peuvent gérer tout type de tâches de compréhension de documents telles que l'OCR, l'extraction de tables, l'extraction de paires clé-valeur. Ils sont généralement exportés en tant qu'API ou peuvent être déployés sur site en fonction de différents cas d'utilisation. Voici quelques exemples,
- Modèle de facture : identifiez les champs clés de Factures comme le nom de l'acheteur, l'identifiant de la facture, la date, le montant, etc.
- Modèle de reçus: identifiez les champs clés des reçus tels que le nom du vendeur, le numéro, la date, le montant, etc.
- Permis de conduire (États-Unis): identifiez les champs clés tels que le numéro de licence, la date de naissance, la date d'expiration, la date d'émission, etc.
- CV: Extrayez l'expérience, la formation, les compétences, les informations sur les candidats, etc.
Pour rendre ces flux de travail plus rapides et robustes, nous utilisons UiPath, un outil RPA pour une automatisation transparente de vos documents sans aucun modèle. Dans la section suivante, nous verrons comment vous pouvez utiliser UiPath Connect avec Nanonets pour la compréhension des documents. Les 3 plus grands acteurs du marché RPA sont UiPath, Automation Anywhere et Prisme Bleu. Ce blog se concentre sur Uipath.
NanoNets avec UiPath
Nous avons appris à créer un pipeline de compréhension de documents dans nos sections précédentes. Cela nécessite des connaissances de base en OCR, RPA et Machine Learning, car il existe différentes approches et algorithmes pour différentes tâches à différents moments. En outre, nous devons consacrer beaucoup d'efforts à la création de réseaux de neurones qui comprennent nos modèles, les entraînent et les déploient. Par conséquent, pour être à l'aise et automatiser tout, du téléchargement des documents, de leur classification, de la création de l'OCR, de l'intégration de modèles ML, chez Nanonets, nous travaillons sur Ui Path pour créer un pipeline transparent pour la compréhension des documents. Vous trouverez ci-dessous une image de la façon dont cela fonctionne.

Passons maintenant en revue chacun de ces éléments et apprenons comment nous pouvons intégrer les nanonets à UiPath.
Étape 1: Inscrivez-vous sur UiPath et téléchargez UiPath Studio
Pour créer un workflow, nous devons d'abord créer un compte dans UiPath. Si vous êtes un utilisateur existant, vous pouvez vous connecter directement à votre compte, en redirigeant votre tableau de bord UiPath. Ensuite, vous devrez télécharger et installer UiPath Studio (Community Edition), qui est gratuit.
Étape 2: Téléchargez le composant Nanonets
Ensuite, pour configurer votre pipeline de traitement des factures, vous devrez télécharger le connecteur Nanonets à partir du lien ci-dessous.
-> NanoNets OCR - Composant RPA
Vous trouverez ci-dessous une capture d'écran du marché UiPath et du composant Nanonets. Aussi, pour télécharger ceci, assurez-vous que vous êtes connecté à UiPath à partir d'un système d'exploitation Windows.

Vos fichiers téléchargés doivent contenir les fichiers répertoriés ci-dessous,
UiPath OCR Predict ├── Main.xaml
└── project.json
Étape 3: Ouvrez le fichier Main.xaml Nanonets Component
Pour vérifier si Nanonets UiPath fonctionne ou non, vous pouvez ouvrir votre fichier Main.xml à partir du composant Nanonets téléchargé à l'aide de Ui Path Studio. Ensuite, vous pouvez voir votre pipeline déjà créé pour vous pour le traitement des documents.

Étape 4: Collectez votre ID de modèle, votre clé API et votre point de terminaison API à partir de l'application Nanonets
Ensuite, vous pouvez utiliser l'un des modèles OCR formés à partir de l'application Nanonets et collecter l'ID de modèle, la clé API et le point de terminaison. Vous trouverez ci-dessous plus de détails pour les retrouver rapidement.
ID du modèle: Connectez-vous à votre compte Nanonets et accédez à «Mes modèles». Vous pouvez entraîner un nouveau modèle ou copier l'ID d'application d'un modèle existant.

Point de terminaison API: Vous pouvez choisir n'importe quel modèle existant et cliquer sur Intégrer pour trouver votre point de terminaison API. Vous trouverez ci-dessous un exemple de l'apparence de vos points de terminaison.
https://app.nanonets.com/api/v2/OCR/Model/XXXXXXX-4840-4c27-8940-d3add200779e/LabelUrls/

3. Clé API: accédez à l'onglet Clé API et vous pouvez copier n'importe quelle clé API existante ou en créer une nouvelle.

Étape 5: Ajoutez une requête HTTP pour obtenir votre méthode et vos variables dans le chemin de l'interface utilisateur
Maintenant, pour intégrer votre modèle de Nanonets au chemin de l'interface utilisateur, vous aurez le premier clic sur HTTP Request et ajoutez le point final, qui se trouve dans la navigation de gauche sous la section Entrée. Ci-dessous, une capture d'écran.

Plus tard, ajoutez toutes vos variables pour établir une connexion de votre studio UiPath à l'API Nanonets. Vous pouvez trouver cette section dans le volet inférieur de l'onglet "Variables". Ci-dessous la capture d'écran, vous devrez mettre à jour / copier votre clé API, votre point de terminaison et l'ID de modèle de votre modèle ici.

Étape 6: Ajouter un emplacement de fichier pour les prédictions
Enfin, vous pouvez ajouter l'emplacement de votre fichier sous l'onglet attributs, comme indiqué dans la capture d'écran ci-dessous, et appuyer sur le bouton de lecture de votre navigation supérieure pour prédire vos sorties.

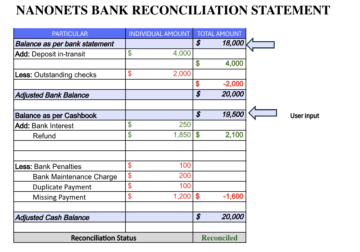
Voila! Voici nos résultats pour le document que nous avons demandé dans la capture d'écran ci-dessous. Pour en traiter plus, vous pouvez simplement ajouter vos emplacements de fichiers et cliquer sur le bouton Exécuter.

Étape 7 - Poussez la sortie dans CSV / ERP
Enfin, pour personnaliser notre sortie dans le format souhaité, nous pouvons ajouter de nouveaux blocs à votre pipeline dans le fichier Main.XML. Nous pouvons également pousser cela dans tous les systèmes ERP existants via des fichiers hors ligne ou des appels API.

Pour toute aide contactez-nous sur support@nanonets.com
Webinaire

Rejoignez-nous pour un webinaire mardi prochain sur l'OCR avec RPA, Inscrivez-vous ici.
Bibliographie
Compréhension des documents - Traitement de documents AI
RPA OCR - automatisation des processus élévateurs | AGRÉABLE
Comment utiliser l'IA pour optimiser la compréhension des documents
https://www.uipath.com/product/document-understanding
Utilisation de NanoNets dans UiPath Workflow pour l'OCR des factures
Lectures complémentaires
Vous pourriez être intéressé par nos derniers articles sur:
Mettre à jour:
Ajout de plus de matériel de lecture sur l'utilisation et l'impact de l'OCR, RPA dans la compréhension des documents.
Source : https://nanonets.com/blog/ocr-with-rpa-and-document-understanding-uipath/
- '
- &
- 000
- 2021
- 7
- Compte
- Comptabilité
- Action
- Avantage
- AI
- algorithme
- algorithmes
- Tous
- selon une analyse de l’Université de Princeton
- api
- Apis
- appli
- Candidature
- applications
- L'art
- intelligence artificielle
- Intelligence artificielle (AI)
- L'INTELLIGENCE ARTIFICIELLE ET LE MACHINE LEARNING
- Automation
- automatisation n'importe où
- LES MEILLEURS
- Le plus grand
- Blog
- Bot
- les robots
- construire
- Développement
- la performance des entreprises
- de CAMÉRAS de surveillance
- cas
- Causes
- causé
- reconnaissance des caractères
- classification
- le cloud
- cloud Platform
- code
- cognitif
- Collecte
- commentaires
- Commun
- Communautés
- Sociétés
- composant
- Vision par ordinateur
- confiance
- contenu
- Corrections
- Costs
- tableau de bord
- données
- gestion des données
- affaire
- l'apprentissage en profondeur
- Développeur
- mobiles
- Compatibles
- numérique
- INSTITUTIONNELS
- Esquive
- conduite
- Éducation
- efficace
- employés
- Endpoint
- Entreprise
- etc
- extraire les données
- extraction
- Fonctionnalité
- Fonctionnalités:
- Des champs
- finalement
- finance
- Prénom
- Focus
- formulaire
- le format
- fraude
- Test d'anglais
- avenir
- Gartner
- Général
- gif
- Bien
- guide
- Maniabilité
- maux de tête
- ici
- Haute
- Comment
- How To
- HTTPS
- majeur
- Les êtres humains
- Hybride
- identifier
- image
- Impact
- Améliore
- info
- d'information
- extraction d'informations
- Intelligence
- intention
- vous aider à faire face aux problèmes qui vous perturbent
- IT
- clés / KEY :
- spécialisées
- KYC
- langue
- Nouveautés
- conduire
- conduisant
- APPRENTISSAGE
- savant
- apprentissage
- Niveau
- Levier
- Licence
- limité
- LINK
- locales
- emplacement
- machine learning
- gestion
- Marché
- marché
- Match
- mesurer
- Commerçant
- Métrique
- Microsoft
- ML
- modèle
- Films
- Langage naturel
- Traitement du langage naturel
- Navigation
- réseaux
- Neural
- les réseaux de neurones
- nlp
- déclaration
- numéros
- OCR
- ouvert
- d'exploitation
- le système d'exploitation
- Opérations
- reconnaissance optique de caractères
- de commander
- Autre
- Autres
- passeport
- performant
- image
- plateforme
- Populaire
- Poteaux
- power
- La précision
- Prédictions
- Process Automation
- Programmes
- Projet
- qualité
- soulève
- gamme
- RE
- en cours
- réduire
- Résultats
- Avis
- systèmes de robot
- Automatisation des processus robotiques
- robotique
- Collaboratif
- rpa
- Courir
- pour le running
- sève
- économie
- Escaliers intérieurs
- balayage
- grattage
- pour écran
- fluide
- Sellers
- Série
- Services
- set
- étapes
- So
- Logiciels
- Bots logiciels
- Solutions
- RÉSOUDRE
- passer
- Commencer
- Région
- Étude
- Support
- combustion propre
- Système
- extraction de table
- Les technologies
- Technologie
- El futuro
- fiable
- top
- Formation
- ui
- UiPath
- Mises à jour
- us
- États-Unis
- cas d'utilisation
- utilisateurs
- Plus-value
- Versus
- vision
- web
- en direct
- sites Internet
- WHO
- fenêtres
- dans les
- Activités:
- workflow
- vos contrats
- XML
- an
- Youtube